Реферат: Модели и методы решения проблемы выбора в условиях неопределенности
Введение
Неопределенность – это фундаментальное свойство природы, а еще более (и точнее) - свойство, характеризующее неточность, незамкнутость, неокончательность, неполноту наших представлений о внешнем мире, и принципиальную непредсказуемость будущих его состояний для сознания, мыслящего этот мир в динамических категориях.
Исследование всех эффектов, влияющих на условие неопределенности, – задача, конечно, колоссальной сложности, и ее решение, по всей вероятности, возможно лишь на пути объединения усилий не только экономистов-теоретиков и экспериментаторов, но и психологов, социологов, философов, математиков в рамках масштабной междисциплинарной исследовательской программы.
Условия риска и неопределенности
Особенности принятия управленческих решений в условиях риска и неопределенности
Для большинства управленческих решений, которые требуют рассмотрения сложных и случайных процессов в будущем, характерно наличие риска и неопределенности. Ни в одной другой сфере управления (менеджмента) не существует столько путаницы, ошибок и перекосов, сколько в той, которую называют принятием решений.
Понятно, что решения различны по своим масштабам и серьезности, а следовательно, последствиям. Однако масштаб кардинально не влияет на процесс принятия решений, просто в больших делах последний должен быть намного тоньше и тщательнее. Не совсем правильно и утверждение, что важные решения принимать значительно труднее, чем относительно неважные, т.е. что важность и трудность решения находятся в прямой зависимости. Ведь человек, который принимает серьезные решения и занимает высокое положение благодаря своей личной квалификации и опыту, имеет больше возможностей, например, пользоваться информацией и практическим опытом, полученным в ходе контроля и проверок, которые сводят к минимуму опасность серьезных ошибок.
При принятии управленческих решений всегда важно учитывать риск. Понятие «риск» используется здесь не в смысле опасности. Риск, скорее, относится к уровню определенности, с которой можно прогнозировать результат. Руководитель должен прогнозировать возможные результаты с учетом разных обстоятельств или влияния природы.
Развитие рыночных отношений в украинской экономике обусловило необходимость поиска новых подходов к управлению. По мере обострения конкуренции, усложнения условий хозяйственной деятельности возрастают и требования к качеству управленческих решений. Поэтому при принятии управленческого решения необходимо помнить о существующем риске.
Внешние условия с точки зрения принятия решения могут характеризоваться:
1) определенностью;
2) риском;
3) неопределенностью.
Неопределенность. Решение принимается в условиях неопределенности, когда руководитель точно не знает результат каждого из альтернативных вариантов выбора. О состоянии внешней среды не известно, имеется ряд стратегий реализации управленческого решения, поэтому существует проблема выбора.
Почти все реальные ситуации связаны с некоторой степенью неопределенности в оценках исхода по данной стратегии действий.
В подобной ситуации для принятия решения по выбору стратегии может служить максимизация ожидаемой выгоды. Она представляет собой средневзвешенную выгоду, которую могут дать все исходы по данной стратегии. Весом каждого исхода будет вероятность его реализации. Так, можно получить информацию о будущем в одном количественном показателе, оценивая вероятности появления различных исходов.
Моделирование системы в условиях неопределенности
В большинстве реальных больших систем не обойтись без учета “состояний природы” — воздействий стохастического типа, случайных величин или случайных событий. Это могут быть не только внешние воздействия на систему в целом или на отдельные ее элементы. Очень часто и внутренние системные связи имеют такую же, “случайную” природу.
Важно понять, что стохастичность связей между элементами системы и уж тем более внутри самого элемента (связь “вход-выход”) является основной причиной риска выполнить вместо системного анализа совершенно бессмысленную работу, получить в качестве рекомендаций по управлению системой заведомо непригодные решения.
Выше уже оговаривалось, что в таких случаях вместо самой случайной величины X приходится использовать ее математическое ожи-дание Mx. Все вроде бы просто — не знаем, так ожидаем. Но насколько оправданы наши ожидания? Какова уверенность или какова вероятность ошибиться?
Такие вопросы решаются, ответы на них получить можно — но для этого надо иметь информацию о законе распределения СВ. Вот и приходится на данном этапе системного анализа (этапе моделирования) заниматься статистического исследованиями, пытаться получить ответы на вопросы:
· А не является ли данный элемент системы и производимые им операции “классическими”?
· Нет ли оснований использовать теорию для определения типа распределения СВ (продукции, денег или информационных сообщений)? Если это так — можно надеяться на оценки ошибок при принятии решений, если же это не так, то приходится ставить вопрос иначе.
· А нельзя ли получить искомое распределение интересующей нас СВ из данных эксперимента? Если этот эксперимент обойдется дорого или физически невозможен, или недопустим по моральным причинам, то может быть “для рагу из зайца использовать хотя бы кошку” — воспользоваться апостериорными данными, опытом прошлого или предсказаниями на будущее, экспертными оценками?
Если и здесь нет оснований принимать положительное решение, то можно надеяться еще на один выход из положения.
Не всегда, но все же возможно использовать текущее состояние уже действующей большой системы, ее реальную “жизнь” для получения глобальных показателей функционирования системы.
Этой цели служат методы планирования эксперимента, теоретической и методологической основой которых является особая область системного анализа —факторный анализ.
Методы решения проблемы выбора. Факторный анализ
Общепризнанно, что в наши дни можно выделить три подхода к решению задач, в которых используются статистические данные.
· Алгоритмический подход, при котором мы имеем статистические данные о некотором процессе и по причине слабой изученности процесса его основная характеристика (например, эффективность экономической системы) мы вынуждены сами строить “разумные” правила обработки данных, базируясь на своих собственных представлениях об интересующем нас показателе.
· Аппроксимационный подход, когда у нас есть полное представление о связи данного показателя с имеющимися у нас данными, но неясна природа возникающих ошибок — отклонений от этих представлений.
· Теоретико-вероятностный подход, когда требуется глубокое проникновение в суть процесса для выяснения связи показателя со статистическими данными.
В настоящее время все эти подходы достаточно строго обоснованы научно и “снабжены” апробированными методами практических действий.
Но существуют ситуации, когда нас интересует не один, а несколько показателей процесса и, кроме того, мы подозреваем наличие нескольких, влияющих на процесс, воздействий — факторов, которые являются не наблюдаемыми, скрытыми или латентными.
Наиболее интересным и полезным в плане понимания сущности факторного анализа — метода решения задач в этих ситуациях, является пример использования наблюдений при эксперименте, который ведет природа, Ни о каком планировании здесь не может идти речи — нам приходится довольствоваться пассивным экспериментом.
Удивительно, но и в этих “тяжелых” условиях ТССА предлагает методы выявления таких факторов, отсеивания слабо проявляющих себя, оценки значимости полученных зависимостей показателей работы системы от этих факторов.
Пусть мы провели по n наблюдений за каждым из k измеряемых показателей эффективности некоторой экономической системы и данные этих наблюдений представили в виде матрицы (таблицы).
Матрица исходных данных E[n·k]
| E 11 | E12 | … | E1i | … | E1k |
| E 21 | E22 | … | E2i | … | E2k |
| … | … | … | … | … | … |
| E j1 | Ej2 | … | Eji | … | Ejk |
| … | … | … | … | … | … |
| E n1 | En2 | … | Eni | … | Enk |
Пусть мы предполагаем, что на эффективность системы влияют и другие — ненаблюдаемые, но легко интерпретируемые (объяснимые по смыслу, причине и механизму влияния) величины — факторы.
Сразу же сообразим, что чем больше n и чем меньше таких число факторов m (а может их и нет вообще!), тем больше надежда оценить их влияние на интересующий нас показатель E.
Столь же легко понять необходимость условия m < k, объяснимого на простом примере аналогии — если мы исследуем некоторые предметы с использованием всех 5 человеческих чувств, то наивно надеяться на обнаружение более пяти “новых”, легко объяснимых, но неизмеряемых признаков у таких предметов, даже если мы “испытаем” очень большое их количество.
Вернемся к исходной матрице наблюдений E[n·k] и отметим, что перед нами, по сути дела, совокупности по n наблюдений над каждой из k случайными величинами E1, E2, … E k. Именно эти величины “подозреваются” в связях друг с другом — или во взаимной коррелированности.
Из рассмотренного ранее метода оценок таких связей следует, что мерой разброса случайной величины E i служит ее дисперсия, определяемая суммой квадратов всех зарегистрированных значений этой величины S(Eij)2 и ее средним значением (суммирование ведется по столбцу).
Если мы применим замену переменных в исходной матрице наблюдений, т.е. вместо Ei j будем использовать случайные величины
Xij
= 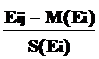 ,
,
то мы преобразуем исходную матрицу в новую
X[n·k]
| X 11 | X12 | … | X1i | … | X1k |
| X 21 | X22 | … | X2i | … | X2k |
| … | … | … | … | … | … |
| X j1 | Xj2 | … | Xji | … | Xjk |
| … | … | … | … | … | … |
| X n1 | Xn2 | … | Xni | … | Xnk |
Отметим, что все элементы новой матрицы X[n·k] окажутся безразмерными, нормированными величинами и, если некоторое значение Xij составит, к примеру, +2, то это будет означать только одно - в строке j наблюдается отклонение от среднего по столбцу i на два среднеквадратичных отклонения (в большую сторону).
Выполним теперь следующие операции.
· Просуммируем квадраты всех значений столбца 1 и разделим результат на (n - 1) — мы получим дисперсию (меру разброса) случайной величины X1 , т.е. D1. Повторяя эту операцию, мы найдем таким же образом дисперсии всех наблюдаемых (но уже нормированных) величин.
· Просуммируем произведения соответствующих строк (от j =1 до j = n) для столбцов 1,2 и также разделим на (n -1). То, что мы теперь получим, называется ковариацией C12 случайных величин X1 , X2 и служит мерой их статистической связи.
· Если мы повторим предыдущую процедуру для всех пар столбцов, то в результате получим еще одну, квадратную матрицу C[k·k], которую принято называть ковариационной.
Эта матрица имеет на главной диагонали дисперсии случайных величин Xi, а в качестве остальных элементов — ковариации этих величин ( i =1…k).
Ковариационная матрица C[k·k]
| D1 | C12 | C13 | … | … | C1k |
| C21 | D2 | C23 | … | … | C2k |
| … | … | … | … | … | … |
| Cj1 | Cj2 | … | Cji | … | Cjk |
| … | … | … | … | … | … |
| Cn1 | Cn2 | … | Cni | … | Dk |
Если вспомнить, что связи случайных величин можно описывать не только ковариациями, но и коэффициентами корреляции, то в соответствие матрице {3-29} можно поставить матрицу парных коэффициентов корреляции или корреляционную матрицу
R [k·k]
| 1 | R12 | R13 | … | … | R1k |
| R21 | 1 | R23 | … | … | R2k |
| … | … | … | … | … | … |
| Rj1 | Rj2 | … | Rji | … | Rjk |
| … | … | … | … | … | … |
| Rn1 | Rn2 | … | Rni | … | 1 |
в которой на диагонали находятся 1, а внедиагональные элементы являются обычными коэффициентами парной корреляции.
Так вот, пусть мы полагали наблюдаемые переменные Ei независящими друг от друга, т.е. ожидали увидеть матрицу R[k·k] диагональной, с единицами в главной диагонали и нулями в остальных местах. Если теперь это не так, то наши догадки о наличии латентных факторов в какой-то мере получили подтверждение.
Но как убедиться в своей правоте, оценить достоверность нашей гипотезы — о наличии хотя бы одного латентного фактора, как оценить степень его влияния на основные (наблюдаемые) переменные? А если, тем более, таких факторов несколько — то как их проранжировать по степени влияния?
Ответы на такие практические вопросы призван давать факторный анализ. В его основе лежит все тот же “вездесущий” метод статистического моделирования (по образному выражению В.В.Налимова — модель вместо теории).
Дальнейший ход анализа при выяснению таких вопросов зависит от того, какой из матриц мы будем пользоваться. Если матрицей ковариаций C[k·k], то мы имеем дело с методом главных компонент, если же мы пользуемся только матрицей R[k·k], то мы используем метод факторного анализа в его “чистом” виде.
Остается разобраться в главном — что позволяют оба эти метода, в чем их различие и как ими пользоваться. Назначение обоих методов одно и то же — установить сам факт наличия латентных переменных (факторов), и если они обнаружены, то получить количественное описание их влияния на основные переменные Ei.
Ход рассуждений при выполнении поиска главных компонент заключается в следующем. Мы предполагаем наличие некоррели-рованных переменных Zj ( j=1…k), каждая из которых представляется нам комбинацией основных переменных (суммирование по i =1…k):
Zj = S Aj i ·X
и, кроме того, обладает дисперсией, такой что
D(Z1) ³ D(Z2) ³ … ³ D(Zk).
Поиск коэффициентов Aj i (их называют весом j-й компонеты в содержании i-й переменной) сводится к решению матричных уравнений и не представляет особой сложности при использовании компьютерных программ. Но суть метода весьма интересна и на ней стоит задержаться.
Как известно из векторной алгебры, диагональная матрица [2·2] может рассматриваться как описание 2-х точек (точнее — вектора) в двумерном пространстве, а такая же матрица размером [k·k]— как описание k точек k-мерного пространства.
Так вот, замена реальных, хотя и нормированных переменных Xi на точно такое же количество переменных Z j означает не что иное, как поворот k осей многомерного пространства.
“Перебирая” поочередно оси, мы находим вначале ту из них, где дисперсия вдоль оси наибольшая. Затем делаем пересчет дисперсий для оставшихся k-1 осей и снова находим “ось-чемпион” по дисперсии и т.д.
Образно говоря, мы заглядываем в куб (3-х мерное пространство) по очереди по трем осям и вначале ищем то направление, где видим наибольший “туман” (наибольшая дисперсия говорит о наибольшем влиянии чего-то постороннего); затем “усредняем” картинку по оставшимся двум осям и сравниваем разброс данных по каждой из них — находим “середнячка” и “аутсайдера”. Теперь остается решить систему уравнений — в нашем примере для 9 переменных, чтобы отыскать матрицу коэффициентов (весов) A[k·k].
Если коэффициенты Aj i найдены, то можно вернуться к основным переменным, поскольку доказано, что они однозначно выражаются в виде (суммирование по j=1…k)
X i = S Aji·Z j .
Отыскание матрицы весов A[k·k] требует использования ковариационной матрицы и корреляционной матрицы.
Таким образом, метод главных компонент отличается прежде все тем, что дает всегда единственное решение задачи. Правда, трактовка этого решения своеобразна.
· Мы решаем задачу о наличии ровно стольких факторов, сколько у нас наблюдаемых переменных, т.е. вопрос о нашем согласии на меньшее число латентных факторов невозможно поставить;
· В результате решения, теоретически всегда единственного, а практически связанного с громадными вычислительными трудностями при разных физических размерностях основных величин, мы получим ответ примерно такого вида — фактор такой-то (например, привлекательность продавцов при анализе дневной выручки магазинов) занимает третье место по степени влияния на основные переменные.
Этот ответ обоснован — дисперсия этого фактора оказалась третьей по крупности среди всех прочих. Всё… Больше ничего получить в этом случае нельзя. Другое дело, что этот вывод оказался нам полезным или мы его игнорируем — это наше право решать, как использовать системный подход!
Несколько иначе осуществляется исследование латентных переменных в случае применения собственно факторного анализа. Здесь каждая реальная переменная рассматривается также как линейная комбинация ряда факторов Fj , но в несколько необычной форме
X i = S B ji · Fj + D i.
причем суммирование ведется по j=1…m , т.е. по каждому фактору.
Здесь коэффициент Bji принято называть нагрузкой на j-й фактор со стороны i-й переменной, а последнее слагаемое в {3-33} рассматривать как помеху, случайное отклонение для Xi. Число факторов m вполне может быть меньше числа реальных переменных n и ситуации, когда мы хотим оценить влияние всего одного фактора (ту же вежливость продавцов), здесь вполне допустимы.
Обратим внимание на само понятие “латентный”, скрытый, непосредственно не измеримый фактор. Конечно же, нет прибора и нет эталона вежливости, образованности, выносливости и т.п. Но это не мешает нам самим “измерить” их — применив соответствующую шкалу для таких признаков, разработав тесты для оценки таких свойств по этой шкале и применив эти тесты к тем же продавцам. Так в чем же тогда “ненаблюдаемость”? А в том, что в процессе эксперимента (обязательно) массового мы не можем непрерывно сравнивать все эти признаки с эталонами и нам приходится брать предварительные, усредненные, полученные совсем не в “рабочих” условиях данные.
Можно отойти от экономики и обратиться к спорту. Кто будет спорить, что результат спортсмена при прыжках в высоту зависит от фактора — “сила толчковой ноги”. Да, это фактор можно измерить и в обычных физических единицах (ньютонах или бытовых килограммах), но когда?! Не во время же прыжка на соревнованиях!
А ведь именно в это, рабочее время фиксируются статистические данные, накапливается материал для исходной матрицы.
Несколько более сложно объяснить сущность самих процедур факторного анализа простыми, элементарными понятиями (по мнению некоторых специалистов в области факторного анализа — вообще невозможно). Поэтому постараемся разобраться в этом, используя достаточно сложный, но, к счастью, доведенный в практическом смысле до полного совершенства, аппарат векторной или матричной алгебры.
До того как станет понятной необходимость в таком аппарате, рассмотрим так называемую основную теорему факторного анализа. Суть ее основана на представлении модели факторного анализа в матричном виде
X [k·1] = B [k·m] · F [m·1] + D [k·1]
и на последующем доказательстве истинности выражения
R [k·k] = B [k·m] · B*[m·k],
для “идеального” случая, когда невязки D пренебрежимо малы.
Здесь B*[m·k] это та же матрица B [k·m], но преобразованная особым образом (транспонированная).
Трудность задачи отыскания матрицы нагрузок на факторы очевидна — еще в школьной алгебре указывается на бесчисленное множество решений системы уравнений, если число уравнений больше числа неизвестных. Грубый подсчет говорит нам, что нам понадобится найти k·m неизвестных элементов матрицы нагрузок, в то время как только около k2 / 2 известных коэффициентов корреляции. Некоторую “помощь” оказывает доказанное в теории факторного анализа соотношение между данным коэффициентом парной корреляции (например R12) и набором соответствующих нагрузок факторов:
R12 = B11 · B21 + B12 · B22 + … + B1m · B2m .
Таким образом, нет ничего удивительного в том утверждении, что факторный анализ (а, значит, и системный анализ в современных условиях) — больше искусство, чем наука. Здесь менее важно владеть “навыками” и крайне важно понимать как мощность, так и ограниченные возможности этого метода.
Есть и еще одно обстоятельство, затрудняющее профессиональную подготовку в области факторного анализа — необходимость быть профессионалом в “технологическом” плане, в нашем случае это, конечно же, экономика.
Но, с другой стороны, стать экономистом высокого уровня вряд ли возможно, не имея хотя бы представлений о возможностях анализировать и эффективно управлять экономическими системами на базе решений, найденных с помощью факторного анализа.
Не следует обольщаться вульгарными обещаниями популяризаторов факторного анализа, не следует верить мифам о его всемогущности и универсальности. Этот метод “на вершине” только по одному показателю — своей сложности, как по сущности, так и по сложности практической реализации даже при “повальном” использовании компьютерных программ. К примеру, есть утверждения о преимуществах метода главных компонент — дескать, этот метод точнее расчета нагрузок на факторы.
Классификационная схема характеристик сложности задачи выбора пути в условиях неопределённости
Наличие особых ситуаций на террайне зависит от характеристик его сложности. Ниже приведена возможная классификационная схема характеристик сложности задачи выбора пути в условиях неопределенности.
Для исследования задачи выбора эффективного алгоритма маршрутизации о априорно известному графу использовались следующие десять характеристик сложности задачи [1]:
1. Время построения пути.
2. Длина построенного пути.
3. Число ребер пути.
4. Число отброшенных ребер вдоль пути.
5. Размер фронта волны поиска (массива открытых вершин) на заключительной итерации.
6. Размер тела волны поиска (массив закрытых вершин) на заключительной итерации.
7. Число итераций.
8. Число элементов в волне на момент завершения поиска (сумма пятой и шестой характеристик).
9. Целенаправленность (число ребер в пути, деленное на восьмую характеристику, не считая начальной вершины).
10. Максимальная длина фронта волны поиска (массива открытых вершин).
Для характеристики сложности всего графа могут использоваться гистограммы указанных выше характеристик для выбранного тестового набора задач (в которые могут входить и все возможные задачи на данном графе). Численные эксперименты показали, что для алгоритмов выбора пути по априорно известному графу выполняется свойство несравнимости любых двух алгоритмов даже в пределах достаточно узкого множества возможных задач. Это означает, что если рассматриваются 2 алгоритма А и В, то существует задача, где алгоритм А эффективнее алгоритма В, и существует задача, где алгоритм В эффективнее алгоритма А.
Для исследования алгоритмов выбора пути в условиях неопределенности на террайнах могут использоваться три способа. Первый заключается в том, что на террайне выделяется конечный магистральный граф, для которого может использоваться указанный выше подход.
Второй способ заключается в построении характеристик структуры террайна.
Поскольку террайн представляет собой граф с континуумом вершин и ребер, построенных на основе отношений видимости, то на нем могут быть аналогично определены следующие две основные структурные характеристики графа: диаметр и число доминирования.
Целочисленная метрика k(x,y), задаваемая на точках носителя террайна определяется как минимальное число ребер в допустимом пути (ломаной) из x в y и наоборот. Максимум этой функции по точкам x, y и определяет диаметр террайна. Таким образом, диаметр террайна равен минимально необходимому числу сеансов измерений для передвижения между любыми двумя выбранными точками (в случае, если нет ограничений на радиус действия измерительной системы). Ниже эта характеристика будет обозначаться как γ(V).
Аналогом числа доминирования для террайна является навигационное число. Пусть А – множество точек на террайне, а V – носитель террайна. Если V(A)=V (это означает, что множество видимых из А вершин совпадает со всем террайном), то А называется навигационным множеством. Навигационное множество называется навигационным базисом, если при удалении из А любого элемента оставшееся подмножество точек уже не является навигационным.
Нетрудно видеть, что навигационное множество есть аналог доминирующего множества для конечного графа, а навигационный базис – аналог независимого доминирующего множества. Соответствующие термины для террайна подчеркивают тот факт, что ориентиры на местности должны образовывать навигационое множество для того, чтобы привязка по этим ориентирам была всюду определена.
Навигационное множество называется навигационным множеством k-го порядка, если для любой точки x |A(x)|≥k
Для стандартного террайна множество вершин Р является навигационным множеством по крайней мере четвертого порядка. Пусть nmin(V) и nmax(V) соответствуют минимальной и максимальной возможным размерностям (числу элементов) для навигационного базиса. Очевидно, что эти два числа могут быть различны (см. рис.1).
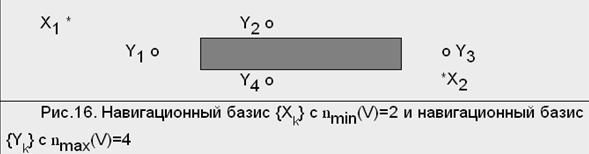
Рисунок 1
Указанные числа называются минимальным и максимальным навигационными числами террайна.
Список литературы
Райфа Г. Анализ решений. Введение в проблемы выбора в условиях неопределенности. М.: Наука, 1977.
Кирильченко А.А. Обоснование алгоритмов выбора пути в условиях неопределенности. // Препринт Ин-та прикл. матем. им. М.В. Келдыша АН СССР, 1991, N 108, 25 с.
Кирильченко А.А. Об исследовании эффективности алгоритмов выбора пути в условиях неопределенности. 2. Атлас особых ситуаций и атлас "неустойчивого доминирования" //М.:Препринт Ин-та прикл.матем. им. М.В. Келдыша РАН, 1997, N 44.-27с.
Гафт М.Г. Принятие решений при многих критериях.
Кини Р.Л., Райфа Х. Принятие решений при многих критериях.