Лабораторная работа: Парный регрессионный анализ
МИНЕСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РЕСПУБЛИКИ
КАЗАХСТАН
СЕВЕРО-КАЗАХСТАНСКИЙ ГОСУДАРСВЕННЫЙ УНИВЕРСИТЕТ
ИМ. М. КОЗЫБАЕВА
ЛАБОРАТОРНАЯ РАБОТА №1
ВАРИАНТ №13
НА ТЕМУ: ПАРНЫЙ РЕГРЕССИОННЫЙ АНАЛИЗ
|
Выполнила: студент Фамилия: Проверила: преподаватель Ф.И.О: |
ПО ДИСЦИПЛИНЕ: ЭКОНОМЕТРИКА
Петропавловск, 2008год
СОДЕРЖАНИЕ
1. ОПИСАНИЕ ЗАДАНИЯ
2. ОПИСАНИЕ РЕШЕНИЯ ЛАБОРАТОРНОЙ РАБОТЫ
Построение линейной регрессионной модели
Построение степенной регрессионной модели
3. Сравнительный анализ расчетов, произведенных с помощью формул Excel и с использованием «Пакета анализа»
1. ОПИСАНИЕ ЗАДАНИЯ
На основании данных нижеприведенной таблицы построить линейное и степенное уравнения регрессии.
Для построенных уравнений вычислить:
1) коэффициент корреляции;
2) коэффициент детерминации;
3) дисперсионное отношение Фишера;
4) стандартные ошибки коэффициентов регрессии;
5) t — статистики Стьюдента;
6) доверительные границы коэффициентов регрессии;
7) усредненное значение коэффициента эластичности;
8) среднюю ошибку аппроксимации.
На одном графике построить исходные данные и теоретическую прямую.
Дать содержательную интерпретацию коэффициента регрессии построенной модели. Все расчеты провести в Excel с использованием формул и с помощью «Пакета анализа». Результаты, полученные по формулам и с помощью «Пакета анализа», сравнить между собой.
По нижеприведенным данным исследуются данные по среднедневной заработной плате yi, (усл.ед.) и среднедушевому прожиточному минимуму в день одного трудоспособного xi, (усл.ед.):
| Yi | 132 | 156 | 143 | 138 | 144 | 155 | 136 | 159 | 127 | 159 | 127 | 136 | 149 | 156 |
| Xi | 84 | 96 | 89 | 80 | 86 | 97 | 91 | 102 | 83 | 115 | 72 | 86 | 95 | 100 |
| Yi | 141 | 162 | 148 | 155 | 171 | 157 | 130 | 158 | 136 | 142 | 144 | 130 | 157 | 145 |
| Xi | 91 | 96 | 77 | 82 | 108 | 102 | 88 | 97 | 81 | 97 | 88 | 76 | 94 | 91 |
| Yi | 125 | 138 | 145 | 171 | 127 | 133 | 164 | 134 | ||||||
| Xi | 76 | 85 | 102 | 115 | 72 | 86 | 100 | 76 |
а) Выполнить прогноз заработной платы yi при прогнозном значении среднедушевого прожиточного минимума xi, составляющем 117% от среднего уровня.
б) Оценить точность прогноза, рассчитав ошибку прогноза и его доверительный интервал.
2 ОПИСАНИЕ РЕШЕНИЯ ЛАБОРАТОРНОЙ РАБОТЫ
Построение линейной регрессионной модели
Линейное уравнение регрессии:
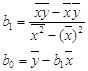
![]()
,
где
Чтобы
рассчитать значения ![]() ,
, ![]() мы добавляем к таблице
дополнительные столбцы x*y, х2, рассчитываем их
общую сумму по 36 регионам и их среднее значение.
мы добавляем к таблице
дополнительные столбцы x*y, х2, рассчитываем их
общую сумму по 36 регионам и их среднее значение.
При вычислении b1 и b0 получены результаты:
b1 = 0,991521606,
b0 = 54,33774319
Значит линейное уравнение регрессии примет вид:
![]() = 54,33774319 + 0,991521606x
= 54,33774319 + 0,991521606x
Индекс b1 = 0,991521606 говорит нам о том, что при увеличении заработную плату на 1 ед. прожиточный минимум увеличивается на 0,991521606.
Зная линейное уравнение
регрессии, заполняем соответствующую колонку ![]() для каждого из регионов. В результате
мы можем посчитать общую сумму
для каждого из регионов. В результате
мы можем посчитать общую сумму ![]() для 36 регионов. Она равна 2320 (усл.ед.).
Эта сумма равна общей сумме y для 36
регионов, т.е.
для 36 регионов. Она равна 2320 (усл.ед.).
Эта сумма равна общей сумме y для 36
регионов, т.е. ![]() , следовательно,
коэффициенты регрессии b1
и b0 рассчитаны, верно.
, следовательно,
коэффициенты регрессии b1
и b0 рассчитаны, верно.
1. Рассчитаем коэффициент корреляции:
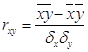 , где
, где 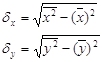
Для этого надо еще добавить в таблицу значения y2 и рассчитать общую сумму по 36 регионам и его среднее значение.
При
вычислении ![]() и
и ![]() получены результаты:
получены результаты:
![]() =9,765812498
=9,765812498
![]() = 93,87081405
= 93,87081405
Следовательно, rxy = 0,103152553. Значит можно сделать вывод, что между х и у, то есть между постоянными расходами и объемом выпускаемой продукции не наблюдается никакой связи.
Рассчитаем коэффициент детерминации:
D = r2xy * 100
D = 1,064044912%
Следовательно, величина постоянных расходов только на 1,064044912% объясняется величиной объема выпускаемой продукции.
2. Рассчитаем дисперсионное отношение Фишера:
![]() , где n – число
регионов
, где n – число
регионов
Следовательно, n = 36
F расч = 0,150568403
Найдем Fтабличное: k1 = m, m = 1(т.к. на y влияет только один фактор х),
k2 = n- m-1. Значит k1 = 1, k2 = 36-1-1= 34. Находим табличное значение F на пересечении k1 и k2. Получаем, что Fтабличное = 2,145.
Так как Fрасчетное < Fтабличное значит уравнение статистически не значимо.
3. Рассчитаем стандартные ошибки коэффициентов регрессии:
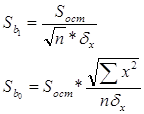
где 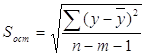
Для
этого надо еще добавить в таблицу значения y - ![]() , (y -
, (y - ![]() )2, и рассчитать общую
сумму по 36 регионам и их среднее значение.
)2, и рассчитать общую
сумму по 36 регионам и их среднее значение.
При вычислении Sост было получено, что
Sост = 382,9325409.
Следовательно,
Sb1 = 27,7984546,
Sb0 = 918,3564058
4. Рассчитаем доверительные границы коэффициентов регрессии:
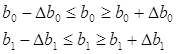 , где
, где 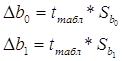
tтабл находится по таблице t-критерия Стьюдента при уровне значимости 0,05 и числе степенной свободы равной 34.
Значит tтабл =2,145.
![]() = 1969,87449
= 1969,87449
![]() = 59,62768512
= 59,62768512
Следовательно, можно рассчитать доверительные границы коэффициентов регрессии:
![]()
Значит можно сделать вывод, что коэффициенты b1 и b0 значимы, так как они лежат в этих интервалах, то есть модель адекватна.
5. Рассчитаем t — статистики Стьюдента:
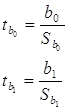
Получается, что ![]() = 0,05916847,
= 0,05916847, ![]() = 0,035668228. Значит
коэффициент tb1 не значим, т.к. tb1 меньше tтабл и tb0 не значим,
так как меньше tтабл, .
= 0,035668228. Значит
коэффициент tb1 не значим, т.к. tb1 меньше tтабл и tb0 не значим,
так как меньше tтабл, .
Рассчитаем индекс корреляции:
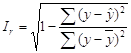
Для
этого надо еще добавить в таблицу значения y - ![]() , (y -
, (y - ![]() )2, и рассчитать общую
сумму по 36 регионам и их среднее значение.
)2, и рассчитать общую
сумму по 36 регионам и их среднее значение.
В результате получаем, что Ir =0,103152553=rxy. Следовательно, индекс корреляции и коэффициент корреляции рассчитаны, верно.
6. Рассчитаем значение коэффициента эластичности:
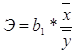
В результате Э = 0,625256944. Коэффициента эластичности показывает, что на 0,625256944% изменится среднедневная заработная плата (у) при изменении на 1% среднедушевой прожиточный минимум(х).
7. Оценить качество модели можно с помощью коэффициента аппроксимации:
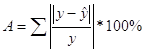
Для
этого надо еще добавить в таблицу значения |(y - ![]() )/y| и рассчитать общую сумму по 36 регионам.
)/y| и рассчитать общую сумму по 36 регионам.
В результате получаем, что А = 3,100451368, следовательно, коэффициент аппроксимации не принадлежит интервалу [0,7;1]. Значит можно сделать вывод о том, что модель не качественная.
Рассчитаем точность прогноза:
![]() , где
, где ![]()
хр= 10698,1875
![]() =-46434,55
=-46434,55
Значит точность прогноза удельных постоянных расходов при прогнозном значении объема выпускаемой продукции, составляющей 119% от среднего уровня составляет 46434.
Рассчитаем ошибку прогноза:
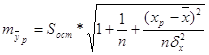
![]() = 6907,6
= 6907,6
Значит, ошибка прогноза составляет 6907,6. Вычислим теперь на основе выше рассчитанного доверительный интервал:
![]()
![]()
Построение степенной регрессионной модели
Степенное уравнение регрессии имеет следующий вид:
![]() , где
, где 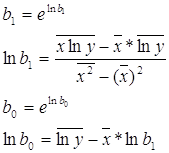
Для этого надо еще добавить в таблицу значения lny и x* lny , рассчитать общую сумму по 28 предприятиям и их среднее значение.
При вычислении b1 и b0 получены результаты:
b1 = 0, 90
b0 = 167325, 81
Значит степенное уравнение регрессии примет вид:
![]() = 167325,81*0,90х
= 167325,81*0,90х
1. Рассчитаем коэффициент корреляции:
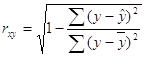
Следовательно, rxy = 0,96. Значит можно сделать вывод, что между Х и у, то есть между постоянными расходами и объемом выпускаемой продукции связь не тесная.
2. Рассчитаем коэффициент детерминации:
D = r2xy * 100
D =92, 95830 (%)
Следовательно, величина постоянных расходов только на 92, 27 % объясняется величиной объема выпускаемой продукции.
3. Рассчитаем дисперсионное отношение Фишера:
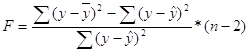
F расч = 343,233.
Fтабл = 4, 20. (нахождение см. в линейной регрессионной модели)
Так как Fрасчетное > Fтабличное значит уравнение статистически значимо.
4. Рассчитаем стандартные ошибки коэффициентов регрессии:
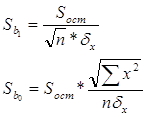
, где
При вычислении Sост было получено, что
Sост = 6758,991.
Следовательно,
Sb1 = 316,97
Sb0 = 3563,99.
6. Рассчитаем доверительные границы коэффициентов регрессии:
, где
табл находится по таблице t-критерия Стьюдента при уровне значимости 0,05 и числе степенной свободы равной 26.
Значит tтабл = 2,0555.
![]() = 7325,59
= 7325,59
![]() = 651,33
= 651,33
Следовательно, можно рассчитать доверительные границы коэффициентов регрессии:
![]()
Значит можно сделать вывод, что коэффициенты b1 и b0 значимы, так как они лежат в этих интервалах, то есть модель адекватна.
5. Рассчитаем t — статистики Стьюдента:
Получается, что ![]() = 33,61,
= 33,61, ![]() = -18,53. Значит
коэффициент tb1 не значим, т.к. tb1 меньше tтабл и tb0 значим, так как
больше tтабл, следовательно, один коэффициент tb0
оказывает воздействие на результативный признак.
= -18,53. Значит
коэффициент tb1 не значим, т.к. tb1 меньше tтабл и tb0 значим, так как
больше tтабл, следовательно, один коэффициент tb0
оказывает воздействие на результативный признак.
Рассчитаем индекс корреляции:
В результате получаем, что Ir = 0,96351 = rxy. Следовательно, индекс корреляции и коэффициент корреляции рассчитаны, верно.
7. Рассчитаем значение коэффициента эластичности:
В результате Э = 0,000161736. Коэффициента эластичности показывает, что на 0,000161736 % изменится результат постоянных расходов (у) при изменении на 1% объема выпускаемой продукции (х.).
8. Оценить качество модели можно с помощью коэффициента аппроксимации:
В результате получаем, что А = 0,341604171, следовательно, коэффициент аппроксимации не принадлежит интервалу [0,7;1]. Значит можно сделать вывод о том, что модель не качественная.
Рассчитаем точность прогноза:
![]() , где
, где ![]()
хр= 13,5687
![]() =46432,58
=46432,58
Значит точность прогноза удельных постоянных расходов при прогнозном значении объема выпускаемой продукции, составляющей 142,7% от среднего уровня составляет 168444,9249.
Рассчитаем ошибку прогноза:
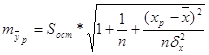
![]() = 6947,015806
= 6947,015806
Значит, ошибка прогноза составляет 6907,6. Вычислим теперь на основе выше рассчитанного доверительный интервал:
![]()
![]()
3.Сравнительный анализ расчетов, произведенных с помощью формул Excel и с использованием «Пакета анализа»
Если сравнивать между собой результаты, полученные при расчетах линейной и степенной регрессионной модели, то можно выделить следующее:
1. Значение b1 в линейной регрессионной модели < b1 в степенной регрессионной модели, т.е. -5870,33<0,90 на 5871,23
2. Значение b0 в линейной регрессионной модели < b0 в степенной регрессионной модели, т.е 119784,3<167325,81 на 47541,51
3. rxy в линейной регрессионной модели >rxy в степенной регрессионной модели,
4. т.е 0,964148>0,96056 на 0,003588
5. D в линейной регрессионной модели < D в степенной регрессионной модели, т.е 92.95825<92, 95830 на 0.00005
6. F в линейной регрессионной модели > F в степенной регрессионной модели, т.е 310,27>343,233.на 32.963
7. Sост в линейной регрессионной модели > Sост в степенной регрессионной модели, т.е 6758.98>6758,991на 0,011
8. Sb1 в линейной регрессионной модели < Sb1 в степенной регрессионной модели, т.е 316.87<316,97 на 0,10
9. Sb0 в линейной регрессионной модели > Sb0 в степенной регрессионной модели, т.е 89,52>89,51 на 0,01.
Так же за счет того, что
![]() в линейной регрессионной модели
отличается от
в линейной регрессионной модели
отличается от ![]() в степенной регрессионной модели
доверительные границы коэффициентов регрессий разные, так же различаются
в степенной регрессионной модели
доверительные границы коэффициентов регрессий разные, так же различаются ![]() и
и ![]() .
.
1.
![]() в линейной регрессионной модели <
в линейной регрессионной модели <
![]() в степенной регрессионной
модели, т.е 33,61>40,63 на 7.02
в степенной регрессионной
модели, т.е 33,61>40,63 на 7.02
2.
![]() в линейной регрессионной
модели <
в линейной регрессионной
модели < ![]() в степенной регрессионной
модели, т.е. -18,53<1,18 на 19.71
в степенной регрессионной
модели, т.е. -18,53<1,18 на 19.71
3. Ir в линейной регрессионной модели < Ir в степенной регрессионной модели, т.е 0,960563<0,96351 на 0, 002947
4. Э в линейной регрессионной модели > Э в степенной регрессионной модели, т.е -1,06>0,000161736 на 1.2058
5. А в линейной регрессионной модели < А в степенной регрессионной модели, т.е 2,83<0,341604 на 2.488396
Из выше сказанного, можно
сказать, что практически все значения, полученные в степенной регрессионной
модели больше, чем результаты, полученные в ходе вычисления линейной
регрессионной модели. Прежде всего, это происходит за счет того, что ![]() в линейной регрессионной модели
больше
в линейной регрессионной модели
больше ![]() в степенной регрессионной модели.
в степенной регрессионной модели.
Если сравнивать значения, полученные в линейной регрессионной модели с помощью Excel с «Пакетом анализа», то значения получаются те же самые, т.е. наблюдается полное совпадение результатов.
При построении графиков исходных данных с теоретической прямой можно сказать, что есть небольшое различие при построении теоретической прямой в линейной регрессионной модели и в степенной регрессионной модели. В степенной регрессионной модели теоретическая прямая немного отклоняется от прямой в линейной регрессионной модели. Так же можно наглядно увидеть, что на промежутке от 900 до 1050 (ед.) наблюдается наибольшая концентрация «наших значений», т.е. на этом промежутке происходит наибольшее пересечение объема выпускаемой продукции с постоянными расходами.
| Теория экономического прогнозирования | |
|
Министерство образования Российской Федерации Тюменский государственный нефтегазовый университет В.Г.НАНИВСКАЯ, И.В.АНДРОНОВА ТЕОРИЯ ЭКОНОМИЧЕСКОГО ... Коэффициент ранговой корреляции можно рассматривать как дополнительный измеритель точности прогнозирования при Pi=Fi и г, близким к 1, так как критерий р инвариантен относительно ... Так, если прогнозирование осуществляется статистическими методами, то, вероятно, понятие точности прогноза можно сделать более узким, а именно связав априорную точность прогноза с ... |
Раздел: Рефераты по экономико-математическому моделированию Тип: реферат |
| Экономическое планирование методами математической статистики | |
|
Министерство образования Украины Харьковский государственный технический университет радиоэлектроники Кафедра ПОЭВМ Комплексная курсовая работа по ... РЕГРЕССИОННЫЙ АНАЛИЗ, МНОЖЕСТВЕННАЯ ЛИНЕЙНАЯ РЕГРЕССИЯ, УРОВЕНЬ ЗНАЧИМОСТИ, КРИТЕРИЙ СЕРИЙ, КРИТЕРИЙ ИНВЕРСИЙ, КРИТЕРИЙ , ВРЕМЕННЫЕ РЯДЫ, МУЛЬТИПЛИКАТИВНО-АДИТИВНАЯ МОДЕЛЬ, ТРЕНД. Для оценки степени зависимости между переменными модели построим корреляционную матрицу, и для каждого коэффициента корреляции в матрице рассчитаем V-функцию, которая служит для ... |
Раздел: Рефераты по экономико-математическому моделированию Тип: реферат |
| Билеты на государственный аттестационный экзамен по специальности ... | |
|
1 Кибернетический подход к информационной системе как системе управления. Понятие кибернетической системы связано с процессами управления и ... Чтобы обеспечить прогноз вероятностью, необходимо найденный доверительный интервал перенести к точкам прогноза. Подобный анализ называется также регрессионным анализом (регрессионный анализ - форма статистического анализа, используемого для прогнозов; Регрессионный анализ позволяет оценить ... |
Раздел: Рефераты по информатике, программированию Тип: реферат |
| Расчет и анализ статистических показателей | |
|
... относительных, средних величин, показателей вариации, построение и анализ рядов распределения, дисперсионный и корреляционно-регрессионный анализ 1.1 ... в) рассчитать линейный коэффициент корреляции; Был проведен корреляционно-регриссионный анализ, построено поле корреляции, рассчитаны коэффициенты регрессии и элластичности. |
Раздел: Рефераты по экономике Тип: курсовая работа |
| Теоретические основы математических и инструментальных методов ... | |
|
Теоретические основы специальности. Оптимизационные методы решения экономических задач. Классическая постановка задачи оптимизации. Оптимизация ... Линейную регрессию, как математическую модель, можно использовать для того, чтобы делать какие-то прогнозы или предсказания. Коэффициент корреляции определяет тесноту линейной корреляционной связи между двумя случайными переменными x и y. Однако корреляционная связь между переменными не обязательно ... |
Раздел: Рефераты по экономико-математическому моделированию Тип: реферат |