Учебное пособие: Математическая статистика
Содержание
Введение
1. Предмет и методы математической статистики
2. Основные понятия математической статистики
2.1 Основные понятия выборочного метода
2.2 Выборочное распределение
2.3 Эмпирическая функция распределения, гистограмма
Заключение
Список литературы
Введение
Математическая статистика — наука о математических методах систематизации и использования статистических данных для научных и практических выводов. Во многих своих разделах математическая статистика опирается на теорию вероятностей, позволяющую оценить надежность и точность выводов, делаемых на основании ограниченного статистического материала (напр., оценить необходимый объем выборки для получения результатов требуемой точности при выборочном обследовании).
В теории вероятностей рассматриваются случайные величины с заданным распределением или случайные эксперименты, свойства которых целиком известны. Предмет теории вероятностей — свойства и взаимосвязи этих величин (распределений).
Но часто эксперимент представляет собой черный ящик, выдающий лишь некие результаты, по которым требуется сделать вывод о свойствах самого эксперимента. Наблюдатель имеет набор числовых (или их можно сделать числовыми) результатов, полученных повторением одного и того же случайного эксперимента в одинаковых условиях.
При этом возникают, например, следующие вопросы: Если мы наблюдаем одну случайную величину — как по набору ее значений в нескольких опытах сделать как можно более точный вывод о ее распределении?
Примером такой серии экспериментов может служить социологический опрос, набор экономических показателей или, наконец, последовательность гербов и решек при тысячекратном подбрасывании монеты.
Все вышеприведенные факторы обуславливают актуальность и значимость тематики работы на современном этапе, направленной на глубокое и всестороннее изучение основных понятий математической статистики.
В связи с этим целью данной работы является систематизация, накопление и закрепление знаний о понятиях математической статистики.
1. Предмет и методы математической статистики
Математическая статистика — наука о математических методах анализа данных, полученных при проведении массовых наблюдений (измерений, опытов). В зависимости от математической природы конкретных результатов наблюдений статистика математическая делится на статистику чисел, многомерный статистический анализ, анализ функций (процессов) и временных рядов, статистику объектов нечисловой природы. Существенная часть статистики математической основана на вероятностных моделях. Выделяют общие задачи описания данных, оценивания и проверки гипотез. Рассматривают и более частные задачи, связанные с проведением выборочных обследований, восстановлением зависимостей, построением и использованием классификаций (типологий) и др.
Для описания данных строят таблицы, диаграммы, иные наглядные представления, например, корреляционные поля. Вероятностные модели обычно не применяются. Некоторые методы описания данных опираются на продвинутую теорию и возможности современных компьютеров. К ним относятся, в частности, кластер-анализ, нацеленный на выделение групп объектов, похожих друг на друга, и многомерное шкалирование, позволяющее наглядно представить объекты на плоскости, в наименьшей степени исказив расстояния между ними.
Методы оценивания и проверки гипотез опираются на вероятностные модели порождения данных. Эти модели делятся на параметрические и непараметрические. В параметрических моделях предполагается, что изучаемые объекты описываются функциями распределения, зависящими от небольшого числа (1-4) числовых параметров. В непараметрических моделях функции распределения предполагаются произвольными непрерывными. В статистике математической оценивают параметры и характеристики распределения (математическое ожидание, медиану, дисперсию, квантили и др.), плотности и функции распределения, зависимости между переменными (на основе линейных и непараметрических коэффициентов корреляции, а также параметрических или непараметрических оценок функций, выражающих зависимости) и др. Используют точечные и интервальные (дающие границы для истинных значений) оценки.
В математической статистике есть общая теория проверки гипотез и большое число методов, посвященных проверке конкретных гипотез. Рассматривают гипотезы о значениях параметров и характеристик, о проверке однородности (то есть о совпадении характеристик или функций распределения в двух выборках), о согласии эмпирической функции распределения с заданной функцией распределения или с параметрическим семейством таких функций, о симметрии распределения и др.
Большое значение имеет раздел математической статистики, связанный с проведением выборочных обследований, со свойствами различных схем организации выборок и построением адекватных методов оценивания и проверки гипотез.
Задачи восстановления зависимостей активно изучаются более 200 лет, с момента разработки К. Гауссом в 1794 г. метода наименьших квадратов. В настоящее время наиболее актуальны методы поиска информативного подмножества переменных и непараметрические методы.
Разработка методов аппроксимации данных и сокращения размерности описания была начата более 100 лет назад, когда К. Пирсон создал метод главных компонент. Позднее были разработаны факторный анализ[1] и многочисленные нелинейные обобщения.
Различные методы построения (кластер-анализ), анализа и использования (дискриминантный анализ) классификаций (типологий) именуют также методами распознавания образов (с учителем и без), автоматической классификации и др.
Математические методы в статистике основаны либо на использовании сумм (на основе Центральной Предельной Теоремы теории вероятностей) или показателей различия (расстояний, метрик), как в статистике объектов нечисловой природы. Строго обоснованы обычно лишь асимптотические результаты. В настоящее время компьютеры играют большую роль в математической статистике. Они используются как для расчетов, так и для имитационного моделирования (в частности, в методах размножения выборок и при изучении пригодности асимптотических результатов).
2. Основные понятия математической статистики
2.1 Основные понятия выборочного метода
Пусть ![]() — случайная
величина, наблюдаемая в случайном эксперименте. Предполагается, что
вероятностное пространство задано (и не будет нас интересовать).
— случайная
величина, наблюдаемая в случайном эксперименте. Предполагается, что
вероятностное пространство задано (и не будет нас интересовать).
Будем
считать, что, проведя ![]() раз этот эксперимент в
одинаковых условиях, мы получили числа
раз этот эксперимент в
одинаковых условиях, мы получили числа ![]() ,
, ![]() ,
, ![]() ,
,
![]() —
значения этой случайной величины в первом, втором, и т.д. экспериментах.
Случайная величина
—
значения этой случайной величины в первом, втором, и т.д. экспериментах.
Случайная величина ![]() имеет некоторое
распределение
имеет некоторое
распределение ![]() , которое нам
частично или полностью неизвестно.
, которое нам
частично или полностью неизвестно.
Рассмотрим
подробнее набор ![]() , называемый выборкой .
, называемый выборкой .
В серии
уже произведенных экспериментов выборка — это набор чисел. Но если эту серию
экспериментов повторить еще раз, то вместо этого набора мы получим новый набор
чисел. Вместо числа ![]() появится другое число
— одно из значений случайной величины
появится другое число
— одно из значений случайной величины ![]() . То есть
. То есть ![]() (и
(и ![]() , и
, и
![]() ,
и т.д.) — переменная величина, которая может принимать те же значения, что и
случайная величина
,
и т.д.) — переменная величина, которая может принимать те же значения, что и
случайная величина ![]() , и так же часто (с
теми же вероятностями). Поэтому до опыта
, и так же часто (с
теми же вероятностями). Поэтому до опыта ![]() — случайная величина,
одинаково распределенная с
— случайная величина,
одинаково распределенная с ![]() , а после опыта —
число, которое мы наблюдаем в данном первом эксперименте, т.е. одно из
возможных значений случайной величины
, а после опыта —
число, которое мы наблюдаем в данном первом эксперименте, т.е. одно из
возможных значений случайной величины ![]() .
.
Выборка ![]() объема
объема ![]() — это набор из
— это набор из ![]() независимых
и одинаково распределенных случайных величин («копий
независимых
и одинаково распределенных случайных величин («копий ![]() »), имеющих, как и
»), имеющих, как и ![]() ,
распределение
,
распределение ![]() .
.
Что значит
«по выборке сделать вывод о распределении»? Распределение характеризуется
функцией распределения, плотностью или таблицей, набором числовых характеристик
— ![]() ,
, ![]() ,
, ![]() и т.д. По выборке нужно уметь строить приближения
для всех этих характеристик.
и т.д. По выборке нужно уметь строить приближения
для всех этих характеристик.
2 .2 Выборочное распределение
Рассмотрим
реализацию выборки на одном элементарном исходе ![]() — набор чисел
— набор чисел ![]() ,
, ![]() ,
, ![]() .
На подходящем вероятностном пространстве введем случайную величину
.
На подходящем вероятностном пространстве введем случайную величину ![]() ,
принимающую значения
,
принимающую значения ![]() ,
, ![]() ,
, ![]() с
вероятностями по
с
вероятностями по ![]() (если какие-то из
значений совпали, сложим вероятности соответствующее число раз). Таблица
распределения вероятностей и функция распределения случайной величины
(если какие-то из
значений совпали, сложим вероятности соответствующее число раз). Таблица
распределения вероятностей и функция распределения случайной величины ![]() выглядят
так:
выглядят
так:
|
|
Распределение
величины ![]() называют эмпирическим или
выборочным распределением. Вычислим
математическое ожидание и дисперсию величины
называют эмпирическим или
выборочным распределением. Вычислим
математическое ожидание и дисперсию величины ![]() и введем обозначения
для этих величин:
и введем обозначения
для этих величин:
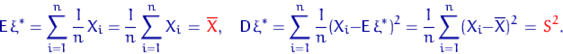
Точно так
же вычислим и момент порядка ![]()
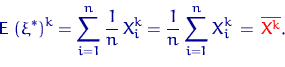
В общем
случае обозначим через ![]() величину
величину
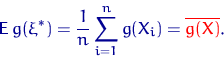
Если при
построении всех введенных нами характеристик считать выборку ![]() ,
, ![]() ,
,
![]() набором
случайных величин, то и сами эти характеристики —
набором
случайных величин, то и сами эти характеристики — ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() — станут
величинами случайными. Эти характеристики выборочного распределения используют
для оценки (приближения) соответствующих неизвестных характеристик истинного
распределения.
— станут
величинами случайными. Эти характеристики выборочного распределения используют
для оценки (приближения) соответствующих неизвестных характеристик истинного
распределения.
Причина
использования характеристик распределения ![]() для оценки
характеристик истинного распределения
для оценки
характеристик истинного распределения ![]() (или
(или ![]() ) — в
близости этих распределений при больших
) — в
близости этих распределений при больших ![]() .
.
Рассмотрим,
для примера, ![]() подбрасываний
правильного кубика. Пусть
подбрасываний
правильного кубика. Пусть ![]() —
количество очков, выпавших при
—
количество очков, выпавших при ![]() -м броске,
-м броске, ![]() . Предположим, что единица в выборке встретится
. Предположим, что единица в выборке встретится ![]() раз,
двойка —
раз,
двойка — ![]() раз и т.д. Тогда случайная величина
раз и т.д. Тогда случайная величина ![]() будет принимать
значения 1,
будет принимать
значения 1, ![]() , 6 с вероятностями
, 6 с вероятностями
![]() ,
, ![]() ,
,
![]() соответственно.
Но эти пропорции с ростом
соответственно.
Но эти пропорции с ростом ![]() приближаются к
приближаются к ![]() согласно
закону больших чисел. То есть распределение величины
согласно
закону больших чисел. То есть распределение величины ![]() в некотором смысле
сближается с истинным распределением числа очков, выпадающих при подбрасывании
правильного кубика.
в некотором смысле
сближается с истинным распределением числа очков, выпадающих при подбрасывании
правильного кубика.
Мы не станем уточнять, что имеется в виду под близостью выборочного и истинного распределений. В следующих параграфах мы подробнее познакомимся с каждой из введенных выше характеристик и исследуем ее свойства, в том числе ее поведение с ростом объема выборки.
2 .3 Эмпирическая функция распределения, гистограмма
Поскольку
неизвестное распределение ![]() можно описать,
например, его функцией распределения
можно описать,
например, его функцией распределения ![]() ,
построим по выборке «оценку» для этой функции.
,
построим по выборке «оценку» для этой функции.
Определение 1.
Эмпирической
функцией распределения, построенной по выборке ![]() объема
объема ![]() , называется случайная
функция
, называется случайная
функция ![]() , при
каждом
, при
каждом ![]() равная
равная
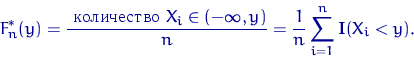
Напоминание: Случайная функция
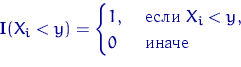
называется
индикатором события ![]() . При каждом
. При каждом ![]() это —
случайная величина, имеющая распределение Бернулли с параметром
это —
случайная величина, имеющая распределение Бернулли с параметром ![]() . почему?
. почему?
Иначе
говоря, при любом ![]() значение
значение ![]() , равное
истинной вероятности случайной величине
, равное
истинной вероятности случайной величине ![]() быть меньше
быть меньше ![]() ,
оценивается долей элементов выборки, меньших
,
оценивается долей элементов выборки, меньших ![]() .
.
Если
элементы выборки ![]() ,
, ![]() ,
, ![]() упорядочить
по возрастанию (на каждом элементарном исходе), получится новый набор случайных
величин, называемый вариационным рядом :
упорядочить
по возрастанию (на каждом элементарном исходе), получится новый набор случайных
величин, называемый вариационным рядом :
![]()
Здесь
![]()
Элемент ![]() ,
,
![]() , называется
, называется ![]() -м членом вариационного
ряда или
-м членом вариационного
ряда или ![]() -й порядковой статистикой .
-й порядковой статистикой .
Пример 1.
Выборка: ![]()
Вариационный
ряд: ![]()
|
Рис. 1. Пример 1 |
|
|
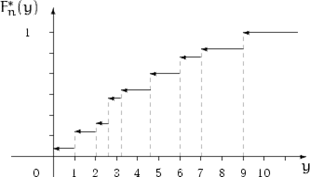
Эмпирическая
функция распределения имеет скачки в точках выборки, величина скачка в точке ![]() равна
равна
![]() ,
где
,
где ![]() — количество элементов выборки, совпадающих с
— количество элементов выборки, совпадающих с ![]() .
.
Можно построить эмпирическую функцию распределения по вариационному ряду:
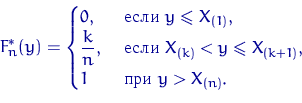
Другой характеристикой распределения является таблица (для дискретных распределений) или плотность (для абсолютно непрерывных). Эмпирическим, или выборочным аналогом таблицы или плотности является так называемая гистограмма .
Гистограмма
строится по группированным данным. Предполагаемую область значений случайной
величины ![]() (или область выборочных данных) делят независимо от выборки на
некоторое количество интервалов (не обязательно одинаковых). Пусть
(или область выборочных данных) делят независимо от выборки на
некоторое количество интервалов (не обязательно одинаковых). Пусть ![]() ,
, ![]() ,
,
![]() —
интервалы на прямой, называемые интервалами группировки .
Обозначим для
—
интервалы на прямой, называемые интервалами группировки .
Обозначим для ![]() через
через ![]() число
элементов выборки, попавших в интервал
число
элементов выборки, попавших в интервал ![]() :
:
|
|
(1) |
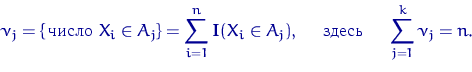
На каждом
из интервалов ![]() строят прямоугольник,
площадь которого пропорциональна
строят прямоугольник,
площадь которого пропорциональна ![]() . Общая площадь всех
прямоугольников должна равняться единице. Пусть
. Общая площадь всех
прямоугольников должна равняться единице. Пусть ![]() — длина интервала
— длина интервала ![]() .
Высота
.
Высота ![]() прямоугольника над
прямоугольника над ![]() равна
равна
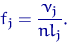
Полученная фигура называется гистограммой.
Пример 2.
Имеется вариационный ряд (см. пример 1):
![]()
Разобьем
отрезок ![]() на 4 равных отрезка. В отрезок
на 4 равных отрезка. В отрезок ![]() попали 4
элемента выборки, в
попали 4
элемента выборки, в ![]() — 6, в
— 6, в ![]() — 3, и в отрезок
— 3, и в отрезок ![]() попали 2
элемента выборки. Строим гистограмму (рис. 2). На рис. 3 — тоже гистограмма для
той же выборки, но при разбиении области на 5 равных отрезков.
попали 2
элемента выборки. Строим гистограмму (рис. 2). На рис. 3 — тоже гистограмма для
той же выборки, но при разбиении области на 5 равных отрезков.
|
Рис. 3. Пример 2 |
||
|
|
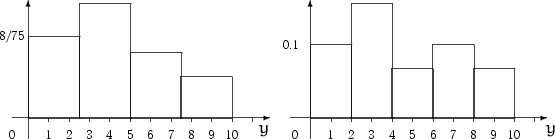
Замечание 1.
В
курсе «Эконометрика» утверждается, что наилучшим числом интервалов группировки
(«формула Стерджесса») является ![]() .
.
Здесь ![]() — десятичный логарифм, поэтому
— десятичный логарифм, поэтому ![]() ,
т.е. при увеличении выборки вдвое число интервалов группировки увеличивается на
1. Заметим, что чем больше интервалов группировки, тем лучше. Но, если брать
число интервалов, скажем, порядка
,
т.е. при увеличении выборки вдвое число интервалов группировки увеличивается на
1. Заметим, что чем больше интервалов группировки, тем лучше. Но, если брать
число интервалов, скажем, порядка ![]() , то с ростом
, то с ростом ![]() гистограмма
не будет приближаться к плотности.
гистограмма
не будет приближаться к плотности.
Справедливо следующее утверждение:
Если
плотность распределения элементов выборки является непрерывной функцией, то при
![]() так, что
так, что ![]() , имеет место
поточечная сходимость по вероятности гистограммы к плотности.
, имеет место
поточечная сходимость по вероятности гистограммы к плотности.
Так что выбор логарифма разумен, но не является единственно возможным.
Заключение
Математическая (или теоретическая) статистика опирается на методы и понятия теории вероятностей, но решает в каком-то смысле обратные задачи.
Если мы наблюдаем одновременно проявление двух (или более) признаков, т.е. имеем набор значений нескольких случайных величин — что можно сказать об их зависимости? Есть она или нет? А если есть, то какова эта зависимость?
Часто бывает возможно высказать некие предположения о распределении, спрятанном в «черном ящике», или о его свойствах. В этом случае по опытным данным требуется подтвердить или опровергнуть эти предположения («гипотезы»). При этом надо помнить, что ответ «да» или «нет» может быть дан лишь с определенной степенью достоверности, и чем дольше мы можем продолжать эксперимент, тем точнее могут быть выводы. Наиболее благоприятной для исследования оказывается ситуация, когда можно уверенно утверждать о некоторых свойствах наблюдаемого эксперимента — например, о наличии функциональной зависимости между наблюдаемыми величинами, о нормальности распределения, о его симметричности, о наличии у распределения плотности или о его дискретном характере, и т.д.
Итак, о (математической) статистике имеет смысл вспоминать, если
· имеется случайный эксперимент, свойства которого частично или полностью неизвестны,
· мы умеем воспроизводить этот эксперимент в одних и тех же условиях некоторое (а лучше — какое угодно) число раз.
Список литературы
1. Баумоль У. Экономическая теория и исследование операций. – М.; Наука, 1999.
2. Большев Л.Н., Смирнов Н.В. Таблицы математической статистики. М.: Наука, 1995.
3. Боровков А.А. Математическая статистика. М.: Наука, 1994.
4. Корн Г., Корн Т. Справочник по математике для научных работников и инженеров. - СПБ: Издательство «Лань», 2003.
5. Коршунов Д.А., Чернова Н.И. Сборник задач и упражнений по математической статистике. Новосибирск: Изд-во Института математики им. С.Л.Соболева СО РАН, 2001.
6. Пехелецкий И.Д. Математика: учебник для студентов. - М.: Академия, 2003.
7. Суходольский В.Г. Лекции по высшей математике для гуманитариев. - СПБ Издательство Санкт-петербургского государственного университета. 2003
8. Феллер В. Введение в теорию вероятностей и ее приложения. - М.: Мир, Т.2, 1984.
9. Харман Г., Современный факторный анализ. — М.: Статистика, 1972.
[1] Харман Г., Современный факторный анализ. — М.: Статистика, 1972.
| ... Основы теории вероятностей и математической статистики" в классах ... | |
|
... образовательное учреждение высшего профессионального образования "Вятский государственный гуманитарный университет" Физико-математический факультет Закономерности присущие подобным величинам, получили название случайных, изучаются теорией вероятностей и математической статистикой [15]. 2. Дискретная случайная величина имеет только 2 возможных значения х и у, причем x<y. Вероятность того, что Х примет значение х =0,6. Найти закон распределения величины Х, если ... |
Раздел: Рефераты по педагогике Тип: дипломная работа |
| Технология и автоматизация производства РЭА | |
|
2КОМИТЕТ РФ ПО ВЫСШЕМУ ОБРАЗОВАНИЮ 2МОСКОВСКИЙ ГОСУДАРСТВЕННЫЙ ИНСТИТУТ ЭЛЕКТРОНИКИ И МАТЕМАТИКИ 2(ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ) конспект лекций ... 6. Пугачев В.С. Теория вероятностей и математическая статистика. M(X) - математическое ожидание величины Х; d 5* 0 - выборочная дисперсия |
Раздел: Рефераты по радиоэлектронике Тип: реферат |
| Теоретические основы математических и инструментальных методов ... | |
|
Теоретические основы специальности. Оптимизационные методы решения экономических задач. Классическая постановка задачи оптимизации. Оптимизация ... Очевидно, что каждой выборке соответствует своя эмпирическая функция распределения, т.е. можно сказать, что - случайная функция. представляет собой ступенчатую функцию ... 2. Интервальной оценкой (с надежностью гамма) среднего квадратического отклонения сигма нормально распределенного количественного признака Х по "исправленному" выборочному среднему ... |
Раздел: Рефераты по экономико-математическому моделированию Тип: реферат |
| Психологическая интуиция искусственных нейронных сетей | |
|
министерство общего и специального образования Российской Федерации сибирский государственный технологический университет На правах рукописи Доррер ... В некоторой среде, характеризующейся плотностью распределения вероятности P(x), случайно и независимо появляются ситуации x. В этой среде функционирует преобразователь, который ... В общих чертах суть экспериментов сводилась к следующему: часть примеров исходной выборки случайным образом исключалась из процесса обучения. |
Раздел: Рефераты по информатике, программированию Тип: дипломная работа |
| Понятие о физической величине. Международная система единиц физических ... | |
|
1. ПОНЯТИЕ О ФИЗИЧЕСКОЙ ВЕЛИЧИНЕ. МЕЖДУНАРОДНАЯ СИСТЕМА ЕДИНИЦ ФИЗИЧЕСКИХ ВЕЛИЧИН СИ Под физической величиной понимают характеристику физических ... 1), где у - число отсчетов; Dxi = хi - xi+1 (i изменяется от -n до +n). С увеличением числа измерений и уменьшением интервала Dxi гистограмма переходит в непрерывную кривую ... Однако чаще всего вероятность появления величины xi в интервале (х, x + dx) в физических экспериментах описывают нормальным законом распределения - законом Гаусса (см. рис. |
Раздел: Рефераты по физике Тип: реферат |