Учебное пособие: Организация баз данных
кафедра компьютерных и информационных технологий
курс лекций
В настоящем курсе рассматриваются вопросы организации баз данных и знаний. Это важная тема, без основательного знакомства с которой, в наше время, невозможно стать квалифицированным специалистом в сфере информационных технологий.
Основное назначение данного курса – систематическое введение в идеи и методы, используемые в современных системах управления базами данных. В курсе не рассматривается какая-либо одна популярная СУБД; излагаемый материал в равной степени относится к любой современной системе. Как показывает опыт, без знания основ теории баз данных трудно на серьезном уровне работать с конкретными системами, как бы хорошо они не были документированы.
Содержание
ЛЕКЦИЯ 1. Понятие СУБД. Функции СУБД............................................... 7
1.1 Введение..................................................................................................... 7
1.2 Понятие БД и СУБД................................................................................... 7
1.3 Уровни абстракции в СУБД. Функции абстрактных данных.................. 9
1.4 Представления.......................................................................................... 10
1.5 Функции СУБД......................................................................................... 11
1.6 Экспертные системы и базы знаний........................................................ 11
ЛЕКЦИЯ 2. Модели БД.............................................................................. 13
2.1 Обзор ранних (дореляционных) СУБД.................................................. 13
2.2 Системы, основанные на инвертированных списках.............................. 13
2.3 Иерархическая модель............................................................................. 14
2.4 Сетевая модель......................................................................................... 16
2.5 Основные достоинства и недостатки ранних СУБД............................... 17
ЛЕКЦИЯ 3. Реляционная модель и ее характеристики. Целостность в реляционной модели 18
3.1 Представление информации в реляционных БД.................................... 18
3.2 Домены 19
3.3 Отношения. Свойства и виды отношений............................................... 20
3.4 Целостность реляционных данных......................................................... 21
3.5 Потенциальные и первичные ключи....................................................... 22
3.6 Внешние ключи........................................................................................ 22
3.7 Ссылочная целостность........................................................................... 23
3.8 Значения NULL и поддержка ссылочной целостности........................... 24
ЛЕКЦИЯ 4. Реляционная алгебра.............................................................. 25
4.1 Понятие реляционной алгебры............................................................... 25
4.2 Замкнутость в реляционной алгебре....................................................... 25
4.3 Традиционные операции над множествами............................................ 25
4.4 Свойства основных операций реляционной алгебры............................ 27
4.5 Специальные реляционные операции..................................................... 28
ЛЕКЦИЯ 5. Вопросы проектирования БД................................................. 34
5.1 Понятие проектирования БД................................................................... 34
5.2 Функциональные зависимости................................................................. 35
5.3 Тривиальные и нетривиальные зависимости.......................................... 36
5.4 Замыкание множества зависимостей и правила вывода Армстронга... 36
5.5 Неприводимое множество зависимостей................................................. 38
5.6 Нормальные формы – основные понятия............................................... 38
5.7 Декомпозиция без потерь и функциональные зависимости................... 39
5.8 Диаграммы функциональных зависимостей........................................... 40
ЛЕКЦИЯ 6. Проектирование БД. Нормальные формы отношений......... 42
6.1 Первая нормальная форма. Возможные недостатки отношения в 1НФ 42
6.2 Вторая нормальная форма. Возможные недостатки отношения во 2НФ 44
6.3 Третья нормальная форма. Возможные недостатки отношения в 3НФ 45
6.4 Нормальная форма Бойса-Кодда............................................................ 46
ЛЕКЦИЯ 7. Проектирование БД. Нормальные формы отношений (продолжение) 49
7.1 Многозначные зависимости..................................................................... 49
7.2 Четвертая нормальная форма.................................................................. 51
7.3 Зависимости соединения.......................................................................... 51
7.4 Пятая нормальная форма........................................................................ 53
7.5 Итоговая схема процедуры нормализации............................................ 53
ЛЕКЦИЯ 8. Проектирование БД методом сущность-связь. ER-диаграммы 55
8.1 Возникновение семантического моделирования.................................... 55
8.2 Основные понятия метода........................................................................ 55
8.3 Диаграммы ER-экземпляров и ER-типа.................................................. 56
8.4 Правила формирования отношений....................................................... 59
8.5 Методология IDEF1 (самостоятельное изучение).................................. 62
ЛЕКЦИЯ 9. Язык SQL................................................................................ 66
9.1 История создания и развития SQL.......................................................... 66
9.2 Основные понятия SQL............................................................................ 66
9.3 Запросы на чтение данных. Оператор SELECT..................................... 71
9.4 Многотабличные запросы на чтение (объединения).............................. 75
ЛЕКЦИЯ 10. Язык SQL (продолжение)....................................................... 77
10.1 Объединения и стандарт SQL2.............................................................. 77
10.2 Итоговые запросы на чтение. Агрегатные функции............................. 80
10.3 Запросы с группировкой (предложение GROUP BY).......................... 80
10.4 Вложенные запросы............................................................................... 82
ЛЕКЦИЯ 11. Язык SQL. (продолжение)...................................................... 86
11.1 Внесение изменений в базу данных....................................................... 86
11.2 Удаление существующих данных (Оператор DELETE)...................... 87
11.3 Обновление существующих данных (Оператор UPDATE)................. 87
11.4 Определение структуры данных в SQL................................................ 88
11.5 Понятие представления.......................................................................... 91
11.6 Представления в SQL............................................................................. 92
11.7 Системный каталог (самостоятельное изучение).................................. 93
ЛЕКЦИЯ 12. Обеспечение безопасности БД................................................ 99
12.1 Общие положения.................................................................................. 99
12.2 Методы обеспечения безопасности..................................................... 100
12.3 Избирательное управление доступом................................................. 101
12.4 Обязательное управление доступом................................................... 102
12.5 Шифрование данных............................................................................ 102
12.6 Контрольный след выполняемых операций....................................... 102
12.7 Поддержка мер обеспечения безопасности в языке SQL................... 103
12.8 Директивы GRANT и REVOKE.......................................................... 103
12.9 Представления и безопасность............................................................ 105
ЛЕКЦИЯ 13. Физическая организация БД: структуры хранения и методы доступа 106
13.1 Доступ к базе данных........................................................................... 106
13.2 Кластеризация...................................................................................... 108
13.3 Индексирование................................................................................... 108
13.4 Структуры типа Б-дерева.................................................................... 111
13.5 Хеширование........................................................................................ 114
ЛЕКЦИЯ 14. Оптимизация запросов......................................................... 116
14.1 Оптимизация в реляционных СУБД.................................................... 116
14.2 Пример оптимизации реляционного выражения............................... 116
14.3 Обзор процесса оптимизации.............................................................. 117
14.4 Преобразование выражений................................................................ 119
ЛЕКЦИЯ 15. Восстановление после сбоев................................................. 123
15.1 Понятие восстановления системы........................................................ 123
15.2 Транзакции........................................................................................... 123
15.3 Алгоритм восстановления после сбоя системы.................................. 125
15.4 Параллелизм. Проблемы параллелизма............................................. 127
15.5 Понятие блокировки............................................................................ 129
15.6 Решение проблем параллелизма......................................................... 130
15.7 Тупиковые ситуации............................................................................ 132
15.8 Способность к упорядочению............................................................. 133
15.9 Уровни изоляции транзакции.............................................................. 134
15.10 Поддержка в языке SQL.................................................................... 135
ЛЕКЦИЯ 16. Технологии СУБД................................................................. 136
16.1 Распределенные базы данных............................................................. 136
16.2 Принципы функционирования распределенной БД........................... 136
16.3 Системы типа клиент/сервер................................................................ 139
16.4 Серверы баз данных............................................................................ 139
ЛЕКЦИЯ 17. Современные постреляционные модели БД........................ 141
17.1 Системы управления базами данных следующего поколения........... 141
17.2 Ориентация на расширенную реляционную модель.......................... 141
17.3 Объектно-ориентированные СУБД..................................................... 143
ЛЕКЦИЯ 1. Понятие СУБД. Функции СУБД1.1 Введение
1.2 Понятие БД и СУБД
1.3 Уровни абстракции в СУБД. Функции абстрактных данных
1.4 Представления
1.5 Функции СУБД
1.6 Экспертные системы и базы знаний
1.1 Введение
Исторически сложившееся развитие вычислительных систем обусловило необходимость хранения в электронном (машиночитаемом) виде все большего количества информации. Одновременно с совершенствованием и дальнейшим развитием вычислительных систем росли объемы информации, подлежащей обработке и хранению. Сложности, возникшие при решении на практике задач структурированного хранения и эффективной обработки возрастающих объемов информации, стимулировали исследования в соответствующих областях. Задачи хранения и обработки данных были формализованы. Была создана теоретическая база для решения задач такого класса, результатом реализации на практике которой стали системы, предназначенные для организации обработки, хранения и предоставления доступа к информации. Позже такие системы стали называть системами баз данных.
Одновременно с развитием систем баз данных, происходило интенсивное развитие средств вычислительной техники, используемой для работы с большими объемами информации. Вычислительная мощность и, особенно, объемы запоминающих устройств первых вычислительных систем были недостаточны для хранения и обработки информации в объемах, необходимых на практике.
По мере развития систем баз данных, менялись принципы организации данных в них: первоначально данные представлялись на основе иерархической, а в последствии сетевой модели. В конце 1970-х – начале 1980-х годов начали появляться первые реляционные продукты. В настоящее время системы баз данных на основе реляционной модели занимают лидирующее положение, несмотря на заявления многих исследователей о скором переходе к объектно-ориентированным системам. В настоящее время объектно-ориентированные системы, тем не менее, развиваются, хотя темпы их развития и сдерживаются медленным принятием соответствующих стандартов. Кроме того, многие коммерческие реляционные системы приобретают объектно-ориентированные черты. На основании этого, можно предположить, что в будущем объектно-ориентированные системы будут постепенно вытеснять реляционные.
В настоящее время ведутся исследования в следующих направлениях:
1. дедуктивные системы;
2. экспертные системы;
3. расширяемые системы;
4. объектно-ориентированные системы.
1.2 Понятие БД и СУБД
Система баз данных – это компьютеризированная система основная задача которой – хранение информации и предоставление доступа к ней по требованию.
Система баз данных включает в себя (рис. 1.1):
1. данные, непосредственно сохраняемые в базе данных;
2. аппаратное обеспечение;
3. программное обеспечение;
4. пользователей:
4.1. прикладные программисты;
4.2. конечные пользователи;
4.3. администраторы баз данных.
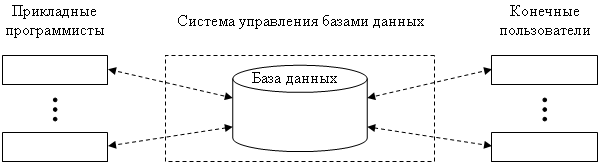 рис. 1.1 Система баз данных.
рис. 1.1 Система баз данных.
1.2.1 Данные.
Данные в базе данных являются интегрированными и, как правило, общими. Понятие интегрированных данных подразумевает возможность представления базы данных как объединение нескольких отдельных файлов данных, полностью или частично не перекрывающихся. Понятие общие подразумевает возможность использования отдельных областей данных, в базе данных несколькими различными пользователями.
1.2.2 Аппаратное обеспечение.
К аппаратному обеспечению системы относятся накопители для хранения информации, вместе с устройствами ввода-вывода, контролерами устройств и т.д.; вычислительная техника, используемая для поддержки работы ПО системы.
1.2.3 Программное обеспечение.
Программное обеспечение является промежуточным слоем между собственно физической базой данных и пользователями системы и называется диспетчером базы данных или системой управления базами данных, СУБД (DBMS). Все запросы пользователей обрабатываются СУБД.
Таким образом, СУБД – это специализированное программное обеспечение, предоставляющее пользователю базы данных возможность работать с ней, не вникая в детали хранения информации на уровне программного обеспечения.
1.2.4 Пользователи.
Прикладные программисты – отвечают за написание прикладных программ, использующих базу данных.
Конечные пользователи – работают с базой данных непосредственно, через рабочую станцию или терминал. Конечный пользователь может получить доступ к базе данных используя соответствующее прикладное ПО.
Администраторы базы данных – технические специалисты, осуществляющие создание БД, технический контроль работы СУБД и др. операции. Администраторы базы данных отвечают за реализацию решений администратора данных. Администратор данных решает, какие данные необходимо хранить в БД, обеспечивает поддержание порядка при обслуживании и использовании хранимых в БД данных.
Функции администратора базы данных:
1. определение концептуальной схемы. Администратор БД определяет какие именно данные необходимо сохранять в БД. Этот процесс обычно называют логическим (или концептуальным) проектированием БД. После определения содержимого БД на абстрактном уровне, администратор БД создает соответствующую концептуальную схему, с помощью концептуального ЯОД.
2. Определение внутренней схемы. Администратор БД решает, как данные должны быть представлены в хранимой БД. Этот процесс называют физическим проектированием. После завершения физического проектирования администратор БД с помощью внутреннего ЯОД должен создать соответствующую структуру хранения, а также определить отображение между внутренней и концептуальной схемой.
3. Взаимодействие с пользователями. Администратор БД обеспечивает пользователей необходимыми им данными. Для этого администратор БД должен написать (или оказать пользователям помощь в написании) необходимых внешних схем. Кроме этого необходимо определить отображение между внешней и концептуальной схемами.
4. Определение правил безопасности и целостности.
5. Определение процедур резервного копирования и восстановления.
6. Управление производительностью и реагирование на изменяющиеся требования.
База данных состоит из некоторого набора постоянных данных, которые используются прикладными системами какого-либо предприятия. Под словом "постоянные" подразумеваются данные, которые отличаются от других, более изменчивых данных, таких, как промежуточные данные и вообще все транзитные данные. "Постоянные" данные на самом деле могут недолго оставаться таковыми, поскольку данные в БД должны отражать об изменчивых объектах реального мира и отношениях между ними.
Использование баз данных для хранения информации позволяет организовать централизованное управление данными, что обеспечивает следующие преимущества:
1. возможность сокращения избыточности;
2. возможность устранения (до некоторой степени) противоречивости;
3. возможность общего доступа к данным;
4. возможность соблюдения стандартов;
5. возможность введения ограничений для обеспечения безопасности
6. возможность обеспечения целостности данных;
7. возможность сбалансировать противоречивые требования;
8. возможность обеспечения независимости данных. Поскольку программное обеспечение отделяется от данных, хранимых БД, изменения, вносимые в структуру БД, в большинстве случаев не приводят к необходимости внесения радикальных изменений в программное обеспечение.
1.3 Уровни абстракции в СУБД. Функции абстрактных данных
Существует 3 уровня архитектуры СУБД (рис. 1.2):
1. Внутренний уровень - наиболее близкий к физическому хранению. Он связан со способами хранения информации на физических устройствах хранения;
2. Внешний уровень - наиболее близкий к пользователям. Он связан со способами представления данных для отдельных пользователей;
3. Концептуальный уровень - является промежуточным между двумя первыми. Этот уровень связан с обобщенными представлениями пользователей, в отличие от внешнего уровня, связанного с индивидуальными представлениями пользователей.
1.4 Представления
Соответственно трем уровням архитектуры выделяют три уровня абстракции данных в СУБД.
1.4.1 Внешний уровень – внешнее представление
Внешний уровень - индивидуальный уровень пользователя. Пользователь может быть как прикладным программистом, так и конечным пользователем с любым уровнем профессиональной подготовки. Каждый пользователь имеет свой язык общения с СУБД. Для программиста - это какой-либо язык программирования, для пользователя - язык запросов или язык, основанный на формах и меню. Любой из этих языков включает подъязык данных, т.е. множество операторов всего языка, связанное только с объектами и операциями баз данных. Т.о. подъязык данных встроен в базовый язык пользователя, который также обеспечивает на связанные с БД возможности.
Представление отдельного пользователя о БД на внешнем уровне архитектуры называют внешним представлением. Т.о. внешнее представление - это содержимое БД, каким его видит отдельный пользователь. Например, сотрудник отдела кадров видит БД как набор записей о сотрудниках плюс набор записей о подразделениях. В общем случае внешнее представление состоит из множества экземпляров каждого типа внешней записи, которые не обязательно совпадают с хранимыми записями. Подъязык данных пользователя определен в терминах внешних записей. Каждое внешнее представление определяется средствами внешней схемы, которая, в основном, состоит из определений каждого типа записей во внешнем представлении.
1.4.2 Концептуальный уровень – концептуальное представление
Концептуальное представление - это представление всей информации БД в несколько более абстрактной форме по сравнению с физическим способом хранения данных. Концептуальное представление представляет данные такими, какими они есть на самом деле, а не такими, какими их вынужден видеть пользователь в рамках определенного языка. Концептуальное представление состоит из множества экземпляров каждого типа концептуальной записи, хотя в некоторых системах в способы концептуального представления данных могут быть другими - например, в виде объектов и связей между ними. Концептуальное представление определяется средствами концептуальной схемы, которая состоит из определений каждого типа концептуальных записей. При определении концептуальной схемы используется концептуальный язык определения данных, определения которого относятся только к содержанию информации. Концептуальное представление, т.о. обеспечивает независимость данных от способа их хранения.
1.4.3 Внутренний уровень – внутреннее представление
Внутреннее представление - это представление нижнего уровня всей БД. Оно состоит из множества экземпляров каждого типа внутренней записи. Внутренняя запись соответствует хранимой записи. Внутреннее представление не связано с физическим уровнем и в нем не рассматриваются физические записи. Внутреннее представление предполагает существование бесконечного линейного адресного пространства. Подробности отображения этого пространства на физические устройства хранения не включены в общую архитектуру из-за сильной зависимости от системы.
Внутреннее представление описывается с помощью внутренней схемы, которая описывается с помощью внутреннего языка определения данных.
Между тремя уровнями представлений имеются два уровня отображений. Отображения концептуального уровня на внутренний и внешнего уровня на концептуальный. Отображения сохраняют независимость данных случае внесения в структуру БД изменений.
1.5 Функции СУБД
1. Определение данных. СУБД должна допускать определения данных (внешние схемы, концептуальную и внутреннюю схемы, соответствующие отображения). Для этого СУБД включает в себя языковый процессор для различных языков определений данных.
2. Обработка данных. СУБД должна обрабатывать запросы пользователя на выборку, а также модификацию данных. Для этого СУБД включает в себя компоненты процессора языка обработки данных.
3. Безопасность и целостность данных. СУБД должна контролировать запросы и пресекать попытки нарушения правил безопасности и целостности.
4. Восстановление данных и дублирование. СУБД должна обеспечить восстановление данных после сбоев.
5. Словарь данных. СУБД должна обеспечить функцию словаря данных. Сам словарь можно считать системной базой данных, которая содержит данные о данных пользовательской БД, т.е. содержит определения других объектов системы. Словарь интегрирован в определяемую им БД и, поэтому, содержит описание самого себя.
6. Производительность. СУБД должна выполнять свои функции с максимальной производительностью.
1.6 Экспертные системы и базы знаний
В последнее время появилась необходимость хранения и использования слабоструктурированных данных, каковыми являются, например, человеческие знания в экспертных системах.
Экспертная система – система искусственного интеллекта, включающая знания об определенной слабо структурированной и трудно формализуемой узкой предметной области и способная предлагать и объяснять пользователю разумные решения. Экспертная система состоит из базы знаний, механизма логического вывода и подсистемы объяснений.
База знаний – семантическая модель, описывающая предметную область и позволяющая отвечать на такие вопросы из этой предметной области, ответы на которые в явном виде не присутствуют в базе. База знаний является основным компонентом интеллектуальных и экспертных систем.
Для хранения баз знаний в современных экспертных системах используются либо промышленные СУБД и специализированное промежуточное ПО, либо специализированное ПО.
В настоящем курсе основное внимание уделяется проектированию БД и организации хранения в них структурированной информации. Проектирование и создание баз знаний будет подробно рассматриваться в других курсах, связанных с изучением интеллектуальных систем.
Литература:
1. Дейт К.Дж. Введение в системы баз данных. –Пер. с англ. –6-е изд. –К. Диалектика, 1998. Стр. 36–75.
ЛЕКЦИЯ 2. Модели БД2.1 Обзор ранних (дореляционных) СУБД
2.2 Системы, основанные на инвертированных списках
2.3 Иерархическая модель
2.4 Сетевая модель
2.5 Основные достоинства и недостатки ранних СУБД
2.1 Обзор ранних (дореляционных) СУБД
Рассмотрим системы, исторически предшествовавшие реляционным, что необходимо для правильного понимания причин повсеместного перехода к реляционным системам. Кроме того, внутренняя организация реляционных систем во многом основана на использовании методов ранних систем. И, наконец, некоторое знание в области ранних систем будет полезно для понимания путей развития постреляционных СУБД.
Ограничимся рассмотрением только общих подходов к организации трех типов ранних систем, а именно, систем, основанных на инвертированных списках, иерархических и сетевых систем управления базами данных. Не будем касаться особенностей каких-либо конкретных систем, поскольку это привело бы к изложению многих технических деталей. Детали можно найти в соответствующей литературе.
Рассмотрим некоторые наиболее общие характеристики ранних систем:
1. Эти системы активно использовались в течение многих лет, дольше, чем используется многие из реляционных СУБД. На самом деле некоторые из ранних систем используются даже в наше время, накоплены громадные базы данных, и одной из актуальных проблем информационных систем является использование этих систем совместно с современными системами.
2. Все ранние системы не основывались на каких-либо абстрактных моделях. Понятие модели данных фактически вошло в обиход специалистов в области БД только вместе с реляционным подходом. Абстрактные представления ранних систем появились позже на основе анализа и выявления общих признаков у различных конкретных систем.
3. В ранних системах доступ к БД производился на уровне записей. Пользователи этих систем осуществляли явную навигацию в БД, используя языки программирования, расширенные функциями СУБД. Интерактивный доступ к БД поддерживался только путем создания соответствующих прикладных программ с собственным интерфейсом.
4. Навигационная природа ранних систем и доступ к данным на уровне записей заставляли пользователя самого производить всю оптимизацию доступа к БД, без какой-либо поддержки системы.
5. После появления реляционных систем большинство ранних систем было оснащено "реляционными" интерфейсами. Однако в большинстве случаев это не сделало их по‑настоящему реляционными системами, поскольку оставалась возможность манипулировать данными в естественном для них режиме.
2.2 Системы, основанные на инвертированных списках
К числу наиболее известных и типичных представителей таких систем относятся Datacom/DB компании Applied Data Research, Inc. (ADR), ориентированная на использование на машинах основного класса фирмы IBM, и Adabas компании Software AG.
Организация доступа к данным на основе инвертированных списков используется практически во всех современных реляционных СУБД, но в этих системах пользователи не имеют непосредственного доступа к инвертированным спискам (индексам).
2.2.1 Структуры данных
В базе данных, организованной с помощью инвертированных списков хранимые таблицы и пути доступа к ним видны пользователям. При этом:
1. Строки таблиц упорядочены системой в некоторой физической последовательности.
2. Физическая упорядоченность строк всех таблиц может определяться и для всей БД (так делается, например, в Datacom/DB).
3. Для каждой таблицы можно определить произвольное число ключей поиска, для которых строятся индексы. Эти индексы автоматически поддерживаются системой, но явно видны пользователям.
2.2.2 Манипулирование данными
Поддерживаются два класса операторов:
1. Операторы, устанавливающие адрес записи, среди которых:
1.1. прямые поисковые операторы (например, найти первую запись таблицы по некоторому пути доступа);
1.2. операторы, находящие запись в терминах относительной позиции от предыдущей записи по некоторому пути доступа.
2. Операторы над адресуемыми записями
Типичный набор операторов:
1. Найти первую запись таблицы T в физическом порядке;
2. Найти первую запись таблицы T с заданным значением ключа поиска K;
3. Найти запись, следующую за записью с заданным адресом в заданном пути доступа;
4. Найти следующую запись таблицы T в порядке пути поиска с заданным значением K;
5. Найти первую запись таблицы T в порядке ключа поиска K cо значением ключевого поля, большим заданного значения K;
6. Выбрать запись с указанным адресом;
7. Обновить запись с указанным адресом;
8. Удалить запись с указанным адресом;
9. Включить запись в указанную таблицу; операция генерирует адрес записи.
2.2.3 Ограничения целостности
Общие правила определения целостности БД отсутствуют. В некоторых системах поддерживаются ограничения уникальности значений некоторых полей, но в основном все возлагается на прикладную программу.
2.3 Иерархическая модель
Типичным представителем (наиболее известным и распространенным) является Information Management System (IMS) фирмы IBM. Первая версия появилась в 1968 г. До сих пор поддерживается много баз данных, что создает существенные проблемы с переходом как на новую технологию БД, так и на новую технику.
2.3.1 Иерархические структуры данных
Иерархическая БД состоит из упорядоченного набора деревьев; более точно, из упорядоченного набора нескольких экземпляров одного типа дерева.
Тип дерева (рис. 2.1) состоит из одного "корневого" типа записи и упорядоченного набора из нуля или более типов поддеревьев (каждое из которых является некоторым типом дерева). Тип дерева в целом представляет собой иерархически организованный набор типов записи.
рис. 2.1  Пример типа
дерева (схемы иерархической БД)
Пример типа
дерева (схемы иерархической БД)
Здесь (рис. 2.1) Группа является предком для Куратора и Студенты, а Куратор и Студенты – потомки Группа. Между типами записи поддерживаются связи.
База данных с такой схемой могла бы выглядеть следующим образом (рис. 2.2):
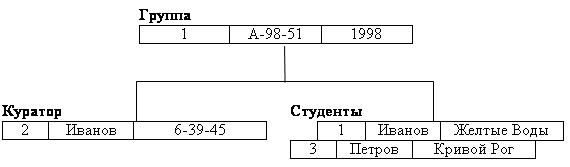 рис. 2.2 Один экземпляр дерева.
рис. 2.2 Один экземпляр дерева.
Все экземпляры данного типа потомка с общим экземпляром типа предка называются близнецами. Для БД определен полный порядок обхода – сверху-вниз, слева-направо.
В IMS использовалась оригинальная и нестандартная терминология: "сегмент" вместо "запись", а под "записью БД" понималось все дерево сегментов.
2.3.2 Манипулирование данными
Примерами типичных операторов манипулирования иерархически организованными данными могут быть следующие:
1. Найти указанное дерево БД (например, отдел 310);
2. Перейти от одного дерева к другому;
3. Перейти от одной записи к другой внутри дерева (например, от отдела - к первому сотруднику);
4. Перейти от одной записи к другой в порядке обхода иерархии;
5. Вставить новую запись в указанную позицию;
6. Удалить текущую запись.
2.3.3 Ограничения целостности
Автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя. Заметим, что аналогичное поддержание целостности по ссылкам между записями, не входящими в одну иерархию, не поддерживается (примером такой "внешней" ссылки может быть содержимое поля Каф_Номер в экземпляре типа записи Куратор).
В иерархических системах поддерживалась некоторая форма представлений БД на основе ограничения иерархии. Примером представления приведенной выше БД может быть иерархия, изображенная на рис. 2.3.
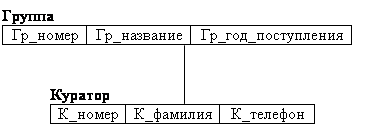 рис. 2.3 Пример представления иерархической БД.
рис. 2.3 Пример представления иерархической БД.
2.4 Сетевая модель
Типичным представителем является Integrated Database Management System (IDMS) компании Cullinet Software, Inc., предназначенная для использования на машинах основного класса фирмы IBM под управлением большинства операционных систем. Архитектура системы основана на предложениях Data Base Task Group (DBTG) Комитета по языкам программирования Conference on Data Systems Languages (CODASYL), организации, ответственной за определение языка программирования Кобол. Отчет DBTG был опубликован в 1971г., а в 70-х годах появилось несколько систем, среди которых IDMS.
2.4.1 Сетевые структуры данных
Сетевой подход к организации данных является расширением иерархического. В иерархических структурах запись-потомок должна иметь в точности одного предка; в сетевой структуре данных потомок может иметь любое число предков.
Сетевая БД состоит из набора экземпляров каждого типа записи и набора экземпляров каждого типа связи (рис. 2.4).
Тип связи определяется для двух типов записи: предка и потомка. Экземпляр типа связи состоит из одного экземпляра типа записи предка и упорядоченного набора экземпляров типа записи потомка. Для данного типа связи L с типом записи предка P и типом записи потомка C должны выполняться следующие два условия:
1. Каждый экземпляр типа P является предком только в одном экземпляре L;
2. Каждый экземпляр C является потомком не более, чем в одном экземпляре L.
На формирование типов связи не накладываются особые ограничения; возможны, например, следующие ситуации:
1. Тип записи потомка в одном типе связи L1 может быть типом записи предка в другом типе связи L2 (как в иерархии).
2. Данный тип записи P может быть типом записи предка в любом числе типов связи.
3. Данный тип записи P может быть типом записи потомка в любом числе типов связи.
4. Может существовать любое число типов связи с одним и тем же типом записи предка и одним и тем же типом записи потомка; и если L1 и L2 – два типа связи с одним и тем же типом записи предка P и одним и тем же типом записи потомка C, то правила, по которым образуется родство, в разных связях могут различаться.
5. Типы записи X и Y могут быть предком и потомком в одной связи и потомком и предком – в другой.
6. Предок и потомок могут быть одного типа записи.
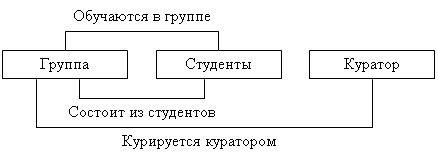 рис. 2.4 Простой пример сетевой схемы БД.
рис. 2.4 Простой пример сетевой схемы БД.
2.4.2 Манипулирование данными
Примерный набор операций может быть следующим:
1. Найти конкретную запись в наборе однотипных записей (инженера Сидорова);
2. Перейти от предка к первому потомку по некоторой связи (к первому сотруднику отдела 310);
3. Перейти к следующему потомку в некоторой связи (от Сидорова к Иванову);
4. Перейти от потомка к предку по некоторой связи (найти отдел Сидорова);
5. Создать новую запись;
6. Уничтожить запись;
7. Модифицировать запись;
8. Включить в связь;
9. Исключить из связи;
10. Переставить в другую связь и т.д.
2.4.3 Ограничения целостности
В принципе их поддержание не требуется, но иногда требуется целостности по ссылкам (как в иерархической модели).
2.5 Основные достоинства и недостатки ранних СУБД
Сильные места ранних СУБД:
1. Развитые средства управления данными во внешней памяти на низком уровне;
2. Возможность построения вручную эффективных прикладных систем;
3. Возможность экономии памяти за счет разделения подобъектов (в сетевых системах).
Недостатки:
1. Слишком сложно пользоваться;
2. Фактически необходимы знания о физической организации;
3. Прикладные системы зависят от этой организации;
4. Их логика перегружена деталями организации доступа к БД.
Литература:
1. Сергей Кузнецов, “Основы современных баз данных”. Центр Информационных Технологий, http://www.citforum.ru/database/osbd/contents.shtml
ЛЕКЦИЯ 3. Реляционная модель и ее характеристики. Целостность в реляционной модели3.1 Представление информации в реляционных БД
3.2 Домены
3.3 Отношения. Свойства и виды отношений
3.4 Целостность реляционных данных
3.5 Потенциальные и первичные ключи
3.6 Внешние ключи
3.7 Ссылочная целостность
3.8 Значения NULL и поддержка ссылочной целостности
3.1 Представление информации в реляционных БД
Реляционный подход является наиболее распространенным в настоящее время, хотя наряду с общепризнанными достоинствами обладает и рядом недостатков. К числу достоинств реляционного подхода можно отнести:
1. наличие небольшого набора абстракций, которые позволяют сравнительно просто моделировать большую часть распространенных предметных областей и допускают точные формальные определения, оставаясь интуитивно понятными;
2. наличие простого и в то же время мощного математического аппарата, опирающегося главным образом на теорию множеств и математическую логику и обеспечивающего теоретический базис реляционного подхода к организации баз данных;
3. возможность ненавигационного манипулирования данными без необходимости знания конкретной физической организации баз данных во внешней памяти.
Однако реляционные системы далеко не сразу получили широкое распространение. В то время, как основные теоретические результаты в этой области были получены еще в 70-х, и тогда же появились первые прототипы реляционных СУБД, долгое время считалось невозможным добиться эффективной реализации таких систем. Однако отмеченные выше преимущества и постепенное накопление методов и алгоритмов организации реляционных баз данных и управления ими привели к тому, что уже в середине 80-х годов реляционные системы практически вытеснили с мирового рынка ранние СУБД.
В настоящее время основным предметом критики реляционных СУБД является не их недостаточная эффективность, а следующие недостатки:
1. присущая этим системам некоторая ограниченность (прямое следствие простоты) при использовании в так называемых нетрадиционных областях (наиболее распространенными примерами являются системы автоматизации проектирования), в которых требуются предельно сложные структуры данных.
2. невозможность адекватного отражения семантики предметной области. Другими словами, возможности представления знаний о семантической специфике предметной области в реляционных системах очень ограничены. Современные исследования в области постреляционных систем главным образом посвящены именно устранению этих недостатков.
В реляционной модели рассматриваются три аспекта данных:
1. структура данных (объекты данных);
2. целостность данных;
3. обработка данных (операторы).
Рассмотрим специальную терминологию, применяемую в рамках аспекта "структура данных" (рис. 3.1).
 рис. 3.1 Отношение.
рис. 3.1 Отношение.
3.2 Домены
Домен является наименьшей семантической единицей данных, которая предполагается отдельным значением данных (таким как номер студента, фамилия студента и т.д.). Такие значения называют скалярами. Скалярные значения представляют собой наименьшую семантическую единицу данных в том смысле, что они являются атомарными: в реляционной модели у них отсутствует внутренняя структура. Следует обратить внимание, что отсутствие внутренней структуры при рассмотрении в реляционной модели вовсе не значит, что внутренняя структура отсутствует вообще. Например, название города имеет внутреннюю структуру (оно состоит из последовательности букв) однако, разложив название по буквам мы потеряем значение. Значение станет понятным лишь в том случае, если буквы сложены вместе и в правильной последовательности.
Таким образом, домен – именованное множество скалярных значений одного типа. Например, домен городов это множество всех возможных названий городов. Домены являются общими совокупностями значений из которых берутся реальные значения атрибутов.
Следует обратить внимание, что обычно в любой момент времени в домене будут значения, не являющиеся значением ни одного из атрибутов, соответствующих этому домену.
Основное значение доменов в том, что домены ограничивают сравнения. Сравнение будет иметь смысл для атрибутов, основанных на одном и том же домене. Например, можно сравнивать числовой код студента и оценку, полученную студентом на экзамене - и то и другое - целые числа, однако такое сравнение будет лишено смысла.
Домены, прежде всего, имеют концептуальную природу. Они могут быть или не быть явно сохранены в базе данных как реальные наборы значений (фактически, в большинстве случаев они не сохраняются), но они должны быть, по крайней мере, определены в рамках определений базы данных. Тогда каждое определение атрибута должно включать ссылку на соответствующий домен, таким образом, системе будет известно, какие атрибуты можно сравнивать, а какие - нет.
3.3 Отношения. Свойства и виды отношений
Вокруг понятия "отношение" сложилась некоторая двусмысленность из-за отсутствия четкого разграничения между переменными отношений и значениями отношений. Переменная отношения – это обычная переменная, такая же, как и в языках программирования, т.е. именованный объект, значение которого может изменяться со временем. А значение этой переменной в любой момент будет значением отношения.
Отношение R, определенное на множестве доменов D1, D2, …, Dn (не обязательно различных), содержит две части – заголовок и тело:
1. заголовок содержит фиксированное множество атрибутов или, точнее, пар <имя‑атрибута : имя‑домена>:
2.
{<A1:D1>, <A2:D2>, …, <An:Dn>},
причем каждый атрибут Aj соответствует одному и только одному из лежащих в
основе доменов Dj (j=1,2, …, n). Все имена атрибутов A1, A2, …, An разные.
3.
Тело состоит из
множества кортежей. Каждый кортеж, в свою очередь содержит множество пар
<имя‑атрибута : значение‑атрибута>:
{<A1:Vi1>, <A2:Vi2>, …, <An:Vin>},
(i=1, 2, …, m, где m - количество кортежей в этом множестве). В каждом таком
кортеже есть одна такая пара <имя‑атрибута : значение‑атрибута>,
т.е. <Aj:Vij>, для каждого атрибута Aj в заголовке. Для любой такой пары
<Aj:Vij> Vij является значением из уникального домена Dj, который связан
с атрибутом Aj.
Значения m и n называются соответственно кардинальным числом и степенью отношения R.
3.3.1 Свойства отношений
1. В отношении отсутствуют одинаковые кортежи.
Это свойство следует из того факта - что тело отношения – это математическое множество (кортежей), а множества в математике по-определению не содержат одинаковых элементов. Это свойство служит иллюстрацией различия между отношением и таблицей т.к. таблица, в общем случае может содержать одинаковые строки.
Важным следствием того, что не существует одинаковых строк является то, что всегда существует первичный ключ. Так как кортежи уникальны, по крайней мере комбинация всех кортежей будет обладать свойством уникальности, а значит, при необходимости, может служить первичным ключом.
2. Кортежи не упорядочены сверху вниз.
Это свойство также следует из того, что тело отношения – это математическое множество, а простые множества в математике не упорядочены. Второе свойство также служит иллюстрацией того факта, что отношение и таблица – не одно и тоже так как строки таблицы упорядочены сверху вниз, в то время, как кортежи отношения – нет.
3. атрибуты не упорядочены слева на право.
И это свойство следует из того, что заголовок отношения определен как множество атрибутов. Аналогично второму свойству, можно заметить отличия между таблицей и отношением – в таблице столбцы упорядочены слева на право.
4. все значения атрибутов атомарные.
Это свойство является следствием того, что все лежащие в основе домены содержат только атомарные значения. Отношение, удовлетворяющее этому условию, называется нормализованным, или представленном в первой нормальной форме. Это означает, что с точки зрения реляционной модели все отношения нормализованы.
3.3.2 Виды отношений
Определим некоторые виды отношений, встречающиеся в реляционных системах.
1. Именованное отношение – это переменная отношения, определенная в СУБД посредством операторов создания отношений.
2. Базовым отношением называется именованное отношение, которое не является производным (т.е. базовое отношения является автономным).
3. Производным отношением называется отношение, определенное (посредством реляционного выражения) через другие именованные выражения и, в конечном счете, через базовые отношения.
4. Выражаемое отношение – отношение, которое можно получить из набора именованных отношений посредством некоторого реляционного выражения. Множество всех выражаемых отношений – это в точности множество всех базовых отношений и всех производных отношений.
5. Представление – это именованное производное отношение. Представления, как и базовые отношения являются переменными отношений. Представления виртуальны – они представлены в системе исключительно через определение в терминах других именованных отношений.
6. Снимки – это именованные производные отношения, в отличии от представлений являются реальными и представлены в системе не только в виде определений в терминах других именованных отношений, но и своими данными.
7. Результатом запроса называется неименованное производное отношение, служащее результатом некоторого определенного запроса.
8. Промежуточным результатом называется неименованное производное отношение, являющееся результатом некоторого реляционного выражения, вложенного в другое, большее выражение.
9. Хранимое отношение – отношение, которое поддерживается непосредственно в физической памяти.
Каждое отношение в реляционной модели имеет некоторую интерпретацию, причем пользователи должны ее знать для эффективного использования БД.
Например: студент с номером SNo имеет фамилию SurName и проживает в городе City. При этом нет двух студентов с одинаковыми номерами.
Формально, подобное утверждение называют предикатом, или функцией значения истинности. В последнем примере – функцией трех аргументов. Подстановка значений этих аргументов эквивалентна вызову функции и приводит к получению выражения, называемого высказыванием, которое может быть либо истинным либо ложным.
Предикат данного отношения составляет критерий возможности обновления для этого отношения. Для того, чтобы система могла определить допустимость обновления данного отношения, ей должен быть известен предикат этого отношения. СУБД, чтобы определить допустимость обновления отношения использует определенные для данного отношения правила целостности.
3.4 Целостность реляционных данных
Большинство БД подчиняются множеству правил целостности. В любой момент времени любая база данных содержит некую определенную конфигурацию значений данных, и предполагается, что эта конфигурация отображает действительность – т.е. является моделью части реального мира. Просто определенная конфигурация значений не имеет смысла, если значения в этой конфигурации не представляют определенного состояния реального мира. Исходя из сказанного выше, определение базы данных нуждается в расширении, включающем правила целостности, назначение которых в том, чтобы информировать СУБД о разного рода ограничениях реального мира. В реляционной модели есть два общих особых правил целостности. Эти правила относятся к потенциальным (и первичным) ключам и ко внешним ключам.
3.5 Потенциальные и первичные ключи
Пусть R – некоторое отношение. Тогда потенциальный ключ, скажем, K для R – это подмножество множества атрибутов R, обладающее следующими свойствами:
1. Свойство уникальности – нет двух разных кортежей в отношении R с одинаковым значением K.
2. Свойство не избыточности – никакое из подмножеств K не обладает свойством уникальности.
Следует обратить внимание, что данное выше определение потенциального ключа относится к самому отношению (т.е. к значениям отношения), а не к переменным отношения.
При рассмотрении потенциальных ключей необходимо заметить следующее:
1. На практике большинство отношений имеют только один потенциальный ключ, хотя в общем случае их может быть несколько.
2. Потенциальные ключи определены как множества атрибутов. Потенциальный ключ, состоящий из нескольких атрибутов называется составным, состоящий из одного атрибута – простым.
3. Понятие не избыточности. Если определить "потенциальный ключ" не являющийся не избыточным, системе не будет известно об этом и она не сможет обеспечить должным образом соответствующее ограничение целостности. Например: в отношении с данными о студентах можно определить избыточный потенциальный ключ, состоящий из уникального кода студента StNo и названия города, в котором он проживает City. В таком случае система не сможет соблюдать ограничение, обеспечивающее уникальность номера студента в глобальном смысле, вместо этого будет выполняться более слабое ограничение, обеспечивающее уникальность номера студента в пределах города.
Причина важности потенциальных ключей заключается в том, что они обеспечивают основной механизм адресации на уровне кортежей в реляционной системе. Единственный способ точно указать на какой-либо кортеж – это указать точное значение потенциального ключа.
Отношение может иметь более одного потенциального ключа. В этом случае в реляционной модели, один из них выбирается в качестве первичного в базовом отношении, а остальные потенциальные ключи, если они есть будут называться альтернативными ключами.
Если множество потенциальных ключей содержит более одного элемента, выбор первичного ключа, в общем случае, осуществляется произвольно.
3.6 Внешние ключи
Пусть R2 – базовое отношение. Тогда внешний ключ – FK в отношении R2 – это подмножество множества атрибутов R2 такое, что:
1. существует базовое отношение R1 (R1 и R2 не обязательно различны) с потенциальным ключом CK.
2. каждое значение FK в текущем значении R2 всегда совпадает со значением CK некоторого кортежа в текущем значении R1.
Следует отметить, что:
1. Внешние ключи как и потенциальные определены как множества атрибутов.
2. Данный внешний ключ будет составным (т.е. будет состоять из более чем одного атрибута) тогда и только тогда, когда соответствующий потенциальный ключ также будет составным. Он будет простым тогда и только тогда, когда соответствующий потенциальный ключ также будет простым.
3. Каждый атрибут, входящий в данный внешний ключ, должен быть определен на том же домене, что и соответствующий атрибут соответствующего потенциального ключа.
4. Для внешнего ключа не требуется, чтобы он был компонентом первичного ключа или какого-либо потенциального ключа в содержащем его отношении.
5. Значение внешнего ключа представлено ссылкой к кортежу, содержащему соответствующее значение потенциального ключа (ссылочный кортеж или целевой кортеж). Проблема обеспечения того, что БД не включает никаких неверных значений внешних ключей, известна как проблема ссылочной целостности. Ограничение, по которому значения данного внешнего ключа должны быть адекватны значениям соответствующего потенциального ключа называют ссылочным ограничением. Отношение, содержащее внешний ключ называют ссылающимся отношением, а отношение которое содержит соответствующий потенциальный ключ – ссылочным или целевым отношением.
6. Связи, существующие в базе данных отображают с помощью ссылочных диаграмм. Groups ¬ Students ® Cities
7. Отношение может быть и ссылочным и ссылающимся одновременно Students ® Groups ® Department
8. В определении внешних ключей сказано, что R1 и R2 не обязательно различны. Т.е. отношение может ссылаться само на себя. Такие отношения иногда называют самоссылающимися.
9. Самоссылающиеся отношения представляют собой частный случай ситуации, когда могут возникнуть ссылочные циклы, которые можно отобразить на ссылочной диаграмме следующим образом: Rn ® R(n-1) ® R(n-2) ® … ® R2 ® R1 ®Rn
3.7 Ссылочная целостность
База данных не должна содержать несогласованных значений внешних ключей. Несогласованное значение внешнего ключа – это такое значение внешнего ключа, для которого не существует отвечающего ему значения соответствующего потенциального ключа в соответствующем целевом отношении.
Понятия внешний ключ и ссылочная целостность определены в терминах друг друга.
3.7.1 Правила внешних ключей
Сформулированное ранее правило целостности, выражено исключительно в терминах состояний базы данных. Любое состояние базы данных, не удовлетворяющее этому правилу некорректно. Для того, чтобы избежать некорректных состояний для каждого внешнего ключа необходимо установить правила, на основании которых СУБД будет действовать при попытке удалить объект ссылки внешнего ключа или обновить потенциальный ключ, на который ссылается внешний ключ. Для каждого из этих случаев можно предусмотреть по меньшей мере две возможности.
1. При попытке удалить объект ссылки внешнего ключа:
1.1. Ограничить – приостановить операцию удаления, до момента, когда не будет существовать ссылающихся объектов.
1.2. Каскадировать – каскадировать операцию удаления, удалив соответствующие ссылающиеся объекты.
2. При попытке обновить потенциальный ключ, на который ссылается внешний ключ:
2.1. Ограничить – приостановить операцию обновления, до момента, когда не будет существовать ссылающихся объектов.
2.2. Каскадировать – каскадировать операцию обновления, обновив значение внешнего ключа в соответствующих ссылающихся объектах.
При каскадных обновлениях удавлениях и обновлениях следует учесть возможность наличия ссылочных циклов, которые могут привести к усложнению процедуры модификации БД.
3.8 Значения NULL и поддержка ссылочной целостности
Значения NULL используются для обозначения факта отсутствия информации. Например: дата рождения человека может быть неизвестна. При этом следует учесть, что значения NULL отличаются от числового значения 0 или символьных пробелов. Значение NULL вообще не является реальным значением. Для данного атрибута может быть разрешено или запрещено содержать значения NULL.
Возможность присутствия в отношении значений NULL приводит к необходимости формирования правила целостности объектов. Целостность объектов – ни один элемент первичного ключа не может содержать значения NULL.
Правило ссылочной целостности также должно быть расширено с учетом возможности присутствия значений NULL.
Возможность присутствия значений NULL приводит к возникновению ряда трудноразрешимых проблем и осуждается некоторыми исследователями (например, К. Дж. Дейтом в книге [1]).
Литература:
1. Дейт К.Дж. Введение в системы баз данных. –Пер. с англ. –6-е изд. –К. Диалектика, 1998. Стр. 79–134.
ЛЕКЦИЯ 4. Реляционная алгебра4.1 Понятие реляционной алгебры
4.2 Замкнутость в реляционной алгебре
4.3 Традиционные операции над множествами
4.4 Свойства основных операций реляционной алгебры
4.5 Специальные реляционные операции
4.1 Понятие реляционной алгебры
Основным компонентом той части реляционной модели, которая касается операторов, является так называемая реляционная алгебра, которая в основном состоит из набора операторов, использующих отношения в качестве операндов и возвращающих отношения в качестве результата.
Реляционная алгебра, определенная Коддом в, состоит из восьми операторов, составляющих две группы, по четыре оператора в каждой:
1. Традиционные операции над множествами: объединение, пересечение, вычитание и декартово произведение (модифицированные с учетом того, что их операндами являются отношения, а не произвольные множества).
2. Специальные реляционные операции: выборка, проекция, соединение и деление.
4.2 Замкнутость в реляционной алгебре
Результат каждой операции над отношением (или реляционной операции) также является отношением. Это реляционное свойство называется свойством замкнутости. Поскольку результат любой операции имеет тот же тип, что и исходные объекты (отношения), то результат одной операции может использоваться в качестве исходных данных для другой. Таким образом, имеется возможность, например, взять или проекцию от объединения, или соединение от двух выборок, или объединение соединения и пересечения и т.д.
Другими словами, можно записывать вложенные выражения, т.е. выражения, в которых операнды сами представлены выражениями вместо простых имен отношений.
Если рассматривать замкнутость более строго, каждая реляционная операция должна быть определена таким образом, чтобы выдавать результат с надлежащим заголовком (т.е. с соответствующим набором необходимых имен атрибутов). Причина такого требования к результирующим отношениям заключается в необходимости иметь возможность обращаться к именам атрибутов в последующих операциях, например в дальнейших операциях, расположенных на более глубоких уровнях вложенного выражения. Другими словами, необходим такой набор правил наследования имен атрибутов, встроенный в алгебру, чтобы можно было предсказывать имена атрибутов на выходе произвольной реляционной операции, зная имена атрибутов на входе этой операции.
4.3 Традиционные операции над множествами
4.3.1 Объединение
Объединение в реляционной алгебре не полностью совпадает с математическим объединением, вернее, это особая форма объединения, в которой требуется, чтобы два исходных отношения были совместимо по типу.
Будем говорить, что два отношения совместимы по типу, если у них идентичные заголовки, а точнее,
1. если каждое из них имеет одно и то же множество имен атрибутов (следовательно, заметьте, они заведомо должны иметь одну и ту же степень);
2. если соответствующие атрибуты (т.е. атрибуты с теми же самыми именами в двух отношениях) определены на одном и том же домене.
Операции объединения, пересечения и вычитания требуют от операндов совместимости по типу.
Объединением двух совместимых по типу отношений А и В (A UNION B) называется отношение с тем же заголовком, как и в отношениях А и В, и с телом, состоящим из множества всех кортежей, принадлежащих А или В или обоим отношениям.
Пример операции объединения отношений приведен на рис. 4.1 – рис. 4.2.
| A | B | |||||
| CityNo | CityName | RgNo | CityNo | CityName | RgNo | |
| 1 | Желтые Воды | 1 | 2 | Кривой Рог | 1 | |
| 2 | Кривой Рог | 1 | 3 | Пятихатки | 1 | |
| 3 | Пятихатки | 1 | 4 | Львов | 2 |
рис. 4.1 Исходные отношения
| A UNION B | ||
| CityNo | CityName | RgNo |
| 1 | Желтые Воды | 1 |
| 2 | Кривой Рог | 1 |
| 3 | Пятихатки | 1 |
| 4 | Львов | 2 |
рис. 4.2 Результат объединения отношений A и B.
4.3.2 Пересечение
Пересечением двух совместимых по типу отношений А и В (A INTERSECT B) называется отношение с тем же заголовком, как и в отношениях А и В, и с телом, состоящим из множества всех кортежей, принадлежащих одновременно обоим отношениям A и B.
Пример операции пересечения отношений приведен на рис. 4.1 и рис. 4.3.
| A INTERSECT B | ||
| CityNo | CityName | RgNo |
| 2 | Кривой Рог | 1 |
| 3 | Пятихатки | 1 |
рис. 4.3 Результат операции пересечения отношений A и B.
4.3.3 Вычитание
Вычитанием двух совместимых по типу отношений А и В (A MINUS B) называется отношение с тем же заголовком, как и в отношениях А и В, и с телом, состоящим из множества всех кортежей, принадлежащих отношению A и не принадлежащих отношению B.
Пример операции вычитания отношений приведен на рис. 4.1 и рис. 4.4.
| A MINUS B | B MINUS A | |||||
| CityNo | CityName | RgNo | CityNo | CityName | RgNo | |
| 1 | Желтые Воды | 1 | 4 | Львов | 2 |
рис. 4.4 Результат операции вычитания отношений A минус B и B минус A.
4.3.4 Произведение
В математике декартово произведение (или для краткости произведение) двух множеств является множеством всех таких упорядоченных пар элементов, что первый элемент в каждой паре берется из первого множества, а второй элемент в каждой паре берется из второго множества. Следовательно, декартово произведение двух отношений, должно быть множеством упорядоченных пар кортежей. Но опять-таки необходимо сохранить свойство замкнутости; иначе говоря, результат должен содержать кортежи, а не упорядоченные пары кортежей.
Декартово произведение двух отношений А и В (A TIMES B), где А и В не имеют общих имен атрибутов, определяется как отношение с заголовком, который представляет собой сцепление двух заголовков исходных отношений А и В, и телом, состоящим из множества всех кортежей t, таких, что t представляет собой сцепление кортежа a, принадлежащего отношению А, и кортежа b, принадлежащего отношению В. Кардинальное число результата равняется произведению кардинальных чисел исходных отношений А и В, а степень равняется сумме их степеней. Пример операции декартова произведения представлена на рис. 4.5
| A | B | ||||
| CityNo | CityName | A_RgNo | B_RgNo | RgName | |
| 1 | Желтые Воды | 1 | 1 | Днепропетровская | |
| 2 | Кривой Рог | 1 | 2 | Львовская | |
| 3 | Пятихатки | 1 |
| A TIMES B | ||||
| CityNo | CityName | A_RgNo | B_RgNo | RgName |
| 1 | Желтые Воды | 1 | 1 | Днепропетровская |
| 1 | Желтые Воды | 1 | 2 | Львовская |
| 2 | Кривой Рог | 1 | 1 | Днепропетровская |
| 2 | Кривой Рог | 1 | 2 | Львовская |
| 3 | Пятихатки | 1 | 1 | Днепропетровская |
| 3 | Пятихатки | 1 | 2 | Львовская |
рис. 4.5 Результат операции декартово произведение отношений A и B.
Явное использование операции декартова произведения требуется только для очень сложных запросов. Эта операция включена в реляционную алгебру главным образом по концептуальным соображениям. Декартово произведение требуется как промежуточный шаг при определении операции Q-соединения которая используется довольно часто.
4.4 Свойства основных операций реляционной алгебры
Операции объединения, пересечения и декартова произведения (но не вычитания) обладают свойствами ассоциативности и коммутативности.
Пусть А, В и С – произвольные реляционные выражения (дающие совместимые по типу отношения). Тогда операция объединения:
(A UNION В) UNION С
Эквивалентна операции:
А UNION (В UNION С) (свойство ассоциативности), а .операция объединения:
А UNION B эквивалентна операции:
В UNION A (свойство коммутативности). Аналогично свойства ассоциативности и коммутативности определяются для остальных операций.
Свойство ассоциативности позволяет записывать последовательные операторы объединения (пересечения и декартова произведения) без использования круглых скобок; таким образом, выражение из предыдущего примера можно однозначно упростить:
A UNION В UNION С.
4.5 Специальные реляционные операции
4.5.1 Выборка
Выборка – это сокращенное название Q-выборки, где Q обозначает любой скалярный оператор сравнения (=, ¹, >, ³, ≤, <). Q-выборкой из отношения A по атрибутам Х и Y (в этом порядке)
A WHERE X Q Y называется отношение, имеющее тот же заголовок, что и отношение А, и тело, содержащее множество всех кортежей отношения А, для которых проверка условия X Q Y дает значение истина. Атрибуты X и Y должны быть определены на одном и том же домене, а оператор должен иметь смысл для этого домена.
На рис. 4.6приведен пример операции выборки.
| A | ||
| CityNo | CityName | RgNo |
| 1 | Желтые Воды | 1 |
| 2 | Кривой Рог | 1 |
| 3 | Пятихатки | 1 |
| 4 | Львов | 2 |
| A WHERE RgNo = 1 | ||
| CityNo | CityName | RgNo |
| 1 | Желтые Воды | 1 |
| 2 | Кривой Рог | 1 |
| 3 | Пятихатки | 1 |
рис. 4.6 Исходное отношение A и результат операции выборки кортежей из отношения A по условию RGNo = 1.
4.5.2 Проекция
Проекцией отношения А по атрибутам X, Y,..., Z, где каждый из атрибутов принадлежит отношению А
A [ X, Y, …, Z ] называется отношение с заголовком {X, Y,..., Z} и телом, содержащим множество всех кортежей {Х:х, Y:y,..., Z:z}, таких, для которых в отношении А значение атрибута Х равно х, атрибута Y равно y, ..., атрибута Z равно z.
Таким образом, с помощью оператора проекции получено "вертикальное" подмножество данного отношения, т.е. подмножество, получаемое исключением всех атрибутов, не указанных в списке атрибутов, и последующим исключением дублирующих кортежей (рис. 4.7).
A
| CityNo | CityName | RgNo |
| 1 | Желтые Воды | 1 |
| 2 | Кривой Рог | 1 |
| 3 | Пятихатки | 1 |
| 4 | Львов | 2 |
A [CityName]
| CityName |
| Желтые Воды |
| Кривой Рог |
| Пятихатки |
| Львов |
рис. 4.7 Исходное отношение A и результат операции проекции отношения A по атрибуту CityName.
Никакой атрибут не может быть указан в списке атрибутов более одного раза. Синтаксис позволяет опустить список атрибутов совсем (вместе с квадратными скобками). Действие такой операции эквивалентно указанию списка всех атрибутов исходного отношения, т.е. такая операция представляет собой тождественную проекцию. Другими словами, имя отношения является допустимым реляционным выражением. Проекция вида R[ ], т.е. такая, в которой список атрибутов не пропущен, но пустой, тоже допустима. Она представляет собой "нулевую" проекцию.
4.5.3 Естественное соединение
Операция соединения имеет несколько разновидностей. Однако наиболее важным, без сомнения, является естественное соединение, причем настолько, что для обозначения исключительно естественного соединения почти постоянно используется общий термин "соединение".
Пусть отношения А и В имеют заголовки {Xl, X2, ..., Xm, Y1, Y2, ..., Yn} и {Yl, Y2, ..., Yn, Zl, Z2, ..., Zp} соответственно; т.е. атрибуты Yl, Y2, ..., Yn (и только они) ‑ общие для двух отношений; Х1, Х2, ... ,Хm – остальные атрибуты отношения A; Zl, Z2, ..., Zp ‑ остальные атрибуты отношения В. Предположим также, что соответствующие атрибуты (т.е. атрибуты с одинаковыми именами) определены на одном и том же домене. Рассматривать выражения {X1, Х2, ..., Хm}, {Y1, Y2, ..., Yn} и {Zl, Z2, ..., Zp} как три составных атрибута X, Y и Z соответственно. Тогда естественным соединением отношений А и В (A JOIN B) называется отношение с заголовком {X, Y, Z} и телом, содержащим множество всех кортежей {Х:х, Y:y, Z:z}, таких, для которых в отношении А значение атрибута X равно х, а атрибута Y равно у, и в отношении В значение атрибута Y равно у, а атрибута Z равно z.
Пример операции естественного соединения приведен на рис. 4.8.
| A | B | ||||
| CityNo | CityName | RgNo | RgNo | RgName | |
| 1 | Желтые Воды | 1 | 1 | Днепропетровская | |
| 2 | Кривой Рог | 1 | 2 | Львовская | |
| 3 | Пятихатки | 1 |
| A JOIN B | |||
| CityNo | CityName | A_RgNo | RgName |
| 1 | Желтые Воды | 1 | Днепропетровская |
| 2 | Кривой Рог | 1 | Днепропетровская |
| 3 | Пятихатки | 1 | Днепропетровская |
рис. 4.8 Исходные отношения A и B и результат операции естественного соединения.
Соединение обладает свойствами ассоциативности и коммутативности. Отсюда следует, что выражения:
(A JOIN В) JOIN С и
A JOIN (В JOIN С) могут быть однозначно упрощены к следующему:
A JOIN В JOIN С
Кроме того, выражения:
A JOIN Ви
В JOIN A эквивалентны.
4.5.4 Q-соединение
Операция Q-соединения предназначается для тех случаев (сравнительно редких, но, тем не менее, встречающихся), когда нам нужно соединить вместе два отношения на основе некоторых условий, отличных от эквивалентности. Пусть отношения А и В не имеют общих имен атрибутов (как и в рассмотренной выше операции декартова произведения) и Q определяется так же, как и в операции выборки. Тогда Q-соединением отношения А по атрибуту Х с отношением В по атрибуту Y называется результат вычисления выражения
(A TIMES В) WHERE X Q Y
Q-соединение, таким образом, это отношение с тем же заголовком, что и при декартовом произведении отношений A и B, и с телом, содержащим множество кортежей, принадлежащих этому декартову произведению и вычисление условия XQY дает значение истина для этого кортежа. Атрибуты Х и У должны быть определены на одном и том же домене, а операция должна иметь смысл для этого домена.
4.5.5 Деление
Пусть отношения А и В имеют заголовки:
{X1, X2,..., Xm, Y1, Y2, ..., Yn} и {Y1, Y2, ..., Yn} соответственно, т.е. атрибуты Y1, Y2,..., Yn — общие для двух отношений, и отношение A имеет дополнительные атрибуты X1, Х2, ... ,Хm, а отношение В не имеет дополнительных атрибутов. (Отношения А и В представляют соответственно делимое и делитель.) Предположим также, что соответствующие атрибуты (т.е. атрибуты с одинаковыми именами) определены на одном и том же домене. Пусть теперь выражения {X1, Х2, ..., Хm} и {Y1, Y2, ..., Yn} обозначают два составных атрибута Х и Y соответственно. Тогда делением отношений А на В (A DIVIDEBY B) называется отношение с заголовком {X} и телом, содержащим множество всех кортежей {X:x}, таких что существует кортеж {Х:х, Y:y}, который принадлежит отношению A для всех кортежей {Y:y}, принадлежащих отношению В. Нестрого это можно сформулировать так: результат содержит такие X-значения из отношения А, для которых соответствующие Y-значения (из А) включают все Y-значения из отношения В.
Пример операции деления приведен на рис. 4.9. Отношение M является проекцией отношения Marks, а отношение S – проекцией отношения Subjects. Результат операции деления M DIVIDE BY S фактически содержит номера студентов, которые сдавали дисциплины с номерами 1 и 5.
| M | S | |||
| StNo | SubjNo | SubjNo | ||
| 1 | 1 | 1 | ||
| 1 | 5 | 5 | ||
| 2 | 1 | |||
| 2 | 5 | |||
| 3 | 1 | |||
| 3 | 5 | |||
| 4 | 1 | |||
| 5 | 1 | |||
| M DIVIDE BY S | ||||
| StNo | ||||
| 1 | ||||
| 2 | ||||
| 3 | ||||
рис. 4.9. Пример операции деления.
Восемь операторов Кодда не представляют минимального набора операторов, так как не все из них примитивны, их можно определить в терминах других операторов. Например, естественное соединение – это проекция выборки произведения. Фактически три операции из этого набора, а именно соединение, пересечение и деление, можно определить через остальные пять. Операции выборки, проекции, произведения, объединения и вычитания можно рассматривать как примитивные в том смысле, что ни одна из них не выражается через другие. Поэтому минимальный набор будет состоять из этих пяти примитивных операций. Однако на практике другие три операции (в особенности соединение) настолько часто используются, что имеет смысл обеспечить их непосредственную поддержку, несмотря на то что они не примитивны.
Многие авторы предлагали новые алгебраические операторы после определения Коддом первоначальных восьми. Рассмотрим два таких оператора – EXTEND (расширение) и SUMMARIZE (подведение итогов), которые удачно дополняют основной набор восьми операторов.
4.5.6 Операция расширения
С помощью операции расширения из определенного отношения создается новое отношение (по крайней мере концептуально), которое похоже на начальное, но содержит дополнительный атрибут, значения которого получены посредством некоторых скалярных вычислений. На рис. 4.10 показаны исходное отношение и результат операции расширения:
EXTEND GROUPS ADD (2002-EnterYear) AS COURCE
| GROUPS | Результат операции расширения | ||||||
| GrNo | EnterYear | GrName | GrNo | EnterYear | GrName | Cource | |
| 1 | 1998 | А–98–51 | 1 | 1998 | А–98–51 | 2 | |
| 2 | 1999 | Б–99–51 | 2 | 1999 | Б–99–51 | 1 | |
| 3 | 1998 | Б–98–51 | 3 | 1998 | Б–98–51 | 2 |
рис. 4.10 Пример выполнения операции расширения.
4.5.7 Операция подведения итогов
Пусть А1,А2,... ,An – отдельные атрибуты отношения А. Результатом операции подведения итогов
SUMMARIZE A BY (A1, A2, … An) ADD exp AS Z (которая является выражением, а не командой или оператором) будет отношение с заголовком {А1, А2, ..., An, Z} и с телом, содержащим все такие кортежи, которые являются кортежами проекции отношения А по атрибутам Al, A2, ..., An, расширенного значением для нового атрибута Z. Новое значение Z подсчитывается вычислением итогового выражения ехр по всем кортежам отношения А, которые имеют те же самые значения для атрибутов А1, А2, ..., Аn, что и кортеж t. Список атрибутов А1, А2, ..., Аn не должен включать атрибут с именем Z, а выражение ехр не должно ссылаться на атрибут Z. Кардинальное число результата равно кардинальному числу проекции отношения А по атрибутам Al, A2, ..., An, а степень результата равна степени такой проекции плюс единица.
4.5.8 Операторы обновления
Реляционная модель (точнее, ее часть, связанная с операторами) кроме реляционной алгебры может включать также операции реляционного присвоения. Такие операции имеют следующий синтаксис:
TARGET := SOURCE где source и target— реляционные выражения, представляющие совместимые по типу отношения. Вычисленное значение source присваивается отношению target, заменяя его старое значение.
В реляционных системах также существуют операции вставки INSERT, удаления DELETE и модификации UPDATE.
Оператор вставки имеет следующий вид:
INSERT source INTO target где source и target – это реляционные выражения, представляющие совместимые по типу отношения (на практике отношение target является просто именованным отношением). Значение отношения source вычисляется, и все кортежи результата вставляются в отношение target.
Оператор обновления имеет следующий вид:
UPDATE target attribute1:=scalar_expression, attribute2:=scalar_expression, …, attributeN:=scalar_expression
где target – реляционное выражение, а каждый атрибут attribute принадлежит отношению, которое является результатом вычисления указанного выражения. Все кортежи в результирующем отношении обновляются в соответствии с указанными операторами attribute2:=scalar‑expression
На практике выражение target часто будет просто ограничивающим условием для некоторого именованного отношения.
Оператор удаления имеет следующий вид:
DELETE target
где target – реляционное выражение; все кортежи в результирующем отношении удаляются.
Как и в случае с оператором обновления, выражение target часто будет просто ограничивающим условием для некоторого именованного отношения.
4.5.9 Реляционные сравнения
Реляционное сравнение имеет следующий вид:
Expression Q expression где expression –это выражения реляционной алгебры, представляющие совместимые по типу отношения, а Q – один из следующих операторов сравнения:
= (равно)
¹ (не равно)
£ (подмножество)
< (собственное подмножество)
³ (надмножество)
> (собственное надмножество).
Литература:
1. Дейт К.Дж. Введение в системы баз данных. –Пер. с англ. –6-е изд. –К. Диалектика, 1998. Стр. 135–171.
ЛЕКЦИЯ 5. Вопросы проектирования БД5.1 Понятие проектирования БД
5.2 Функциональные зависимости
5.3 Тривиальные и нетривиальные зависимости
5.4 Замыкание множества зависимостей и правила вывода Армстронга
5.5 Неприводимое множество зависимостей
5.6 Нормальные формы – основные понятия
5.7 Декомпозиция без потерь и функциональные зависимости
5.8 Диаграммы функциональных зависимостей
5.1 Понятие проектирования БД
В этой лекции речь пойдет о проектировании реляционной базы данных. В общем проблема формулируется следующим образом: как в некоторой базе данных для заданного набора данных выбрать подходящую логическую структуру? Иначе говоря, нужно решить вопрос, какие базовые отношения и с какими атрибутами следует задать.
Следует отметить следующие особенности.
1. Следует заметить, что речь здесь пойдет о логическом, а не физическом макете.
2. Физический макет может рассматриваться как отдельная сопутствующая часть. Иначе говоря, для "правильного" составления макета базы данных следует прежде всего создать логический (т.е. реляционный) макет, а затем в виде отдельного шага отобразить этот логический макет на некоторые физические структуры, поддерживаемые СУБД.
3. Физический макет по определению является специфическим для данной СУБД. Логический макет, наоборот, совершенно независим от СУБД, и для его реализации могут быть использованы строгие теоретические принципы.
К сожалению, на практике часто случается так, что реализация макета на физическом уровне может оказывать существенное обратное влияние на логический макет. Иначе говоря, в таком случае для достижения компромисса следует выполнить несколько циклов проектирования "логический макет – физический макет".
Следует также подчеркнуть, что проектирование базы данных скорее искусство, чем просто наука. Конечно, существуют некоторые научные принципы составления таких макетов, однако при проектировании базы данных возникает множество других проблем, которые не всегда можно охватить этими принципами. В результате теоретики и практики в области создания баз данных разработали большое число методологий проектирования. Среди них есть как достаточно точные и строгие, так и не очень, однако все они специализированные и предназначены для решения именно той проблемы, которая считалась неразрешимой к моменту создания данной конкретной методики. Иными словами, они были задуманы для поиска такого логического макета, который был бы, бесспорно, лучшим в данной ситуации.
Необходимо отметить некоторые допущения, используемые в дальнейшем изложении материала:
1. Проектирование базы данных — это не единственное условие получения правильной организации структуры данных, помимо этого ключевым условием является также целостность данных.
2. Далее в макет рассматривается независимо от приложения. Иначе говоря, интерес представляют сами данные, а не то, как они используются. Независимость от приложения желательна потому, что обычно в момент проектирования базы данных не известны все возможные способы использования данных. Таким образом, необходимо, чтобы макет был стабильным, т.е. оставался работоспособным даже при возникновении в приложении новых (т.е. неизвестных на момент создания исходного макета) требований к данным.
Следуя этим допущениям нужно создать концептуальную схему, т.е. абстрактный логический макет, не зависящий от аппаратного обеспечения, операционной системы, СУБД, языка программирования, пользователя и т.д.
5.2 Функциональные зависимости
Для демонстрации основных идей данного раздела используется несколько измененная версия отношения Students из учебной БД, которое в дополнение к обычным атрибутам StNo, GrNo, StName, CityNo будет содержать также атрибут RgNo, представляющий город соответствующего поставщика. Во избежание путаницы далее это измененное отношение будет называться SR. В виде таблицы оно представлено на рис. 5.1.
| SR | ||||
| StNo | GrNo | StName | CityNo | RgNo |
| 1 | 1 | Иванов | 3 | 1 |
| 2 | 1 | Петров | 3 | 1 |
| 3 | 1 | Сидоров | 3 | 1 |
| 4 | 2 | Стрельцов | 1 | 1 |
| 5 | 2 | Кузнецов | 4 | 2 |
рис. 5.1 Данные отношения SR.
Следует четко различать:
1. значение этого отношения (т.е. значение переменной отношения) в определенный момент времени;
2. набор всех возможных значений, которые данное отношение (переменная) может принимать в различные моменты времени.
При рассмотрении переменных отношения, например базовых отношений, интерес представляют не столько функциональные зависимости для определенного в некоторый момент времени значения, сколько функциональные зависимости, выполняющиеся для всех возможных значений данной переменной.
Ниже приведено определение концепции функциональной зависимости для второго пункта.
Пусть R является переменной отношения, а X и Y – произвольными подмножествами множества атрибутов отношения R. Тогда Y функционально зависимо от X, что в символическом виде записывается как
X®Y
(и читается либо
как "X функционально определяет Y ", либо как "X стрелка Y
"), тогда и только тогда, когда для любого допустимого значения отношения
R каждое значение Х связано в точности с одним значением Y.
Иначе говоря, для любого допустимого значения отношения R, когда бы два кортежа отношения R ни совпадали по значению X, они также совпадают и по значению Y. Далее термин "функциональная зависимость" будет использоваться в последнем безотносительном ко времени смысле (за исключением особо оговоренных случаев).
Например, в случае отношения SR функциональная зависимость
{StNo}®{GrNo}
выполняется для всех возможных значений SR, поскольку в любой момент времени данному студенту соответствует в точности одна группа; таким образом, любые два кортежа отношения SR в один и тот же момент времени и с одним и тем же номером студента должны соответствовать одной и той же группе. Практически утверждение, что данная функциональная зависимость выполняется "всегда" (т.е. для всех возможных значений SR), является ограничением целостности для отношения SR, поскольку при этом накладываются определенные ограничения на все допустимые значения.
Ниже перечислено несколько безотносительных ко времени функциональных зависимостей для переменной отношения SR
{StNo}®{GrNo}
{StNo}®{StName}
{StNo}®{CityNo}
{StNo}®{RgNo}
{StNo}®{GrNo, StName}
{StNo}®{GrNo, StName, CityNo, RgNo}
{StNo, GrNo}® {StName}
и другие.
Левая и правая стороны символической записи функциональной зависимости иногда называются детерминантом и зависимой частью соответственно. Как говорится в определении, детерминант и зависимая часть являются множествами атрибутов. Когда множество содержит только один атрибут, он называется одноэлементным множеством, скобки опускаются и символическая запись принимает вид:
StNo®GrNo
Обратите внимание, в частности, на функциональные зависимости, которые выполняются для таблицы на рис. 5.1, но не выполняются "всегда":
GrNo®CityNo
Следует отметить, что если X является потенциальным ключом отношения R, например X является первичным ключом, то все атрибуты Y отношения R должны быть обязательно функционально зависимы от Х (это следует из определения потенциального ключа). В обычном отношении студентов Students, например, необходимо, чтобы выполнялась зависимость
StNo®{GrNo, StName, CityNo}
Фактически, если отношение R удовлетворяет функциональной зависимости A ® B и A не является потенциальным ключом, то R будет характеризоваться некоторой избыточностью. Например, в случае отношения SR сведения о том, что каждый данный город находится в данной области, будут повторяться много раз (это хорошо видно на рис. 5.1).
На практике важно сократить множество ФЗ до компактных размеров, поскольку, функциональные зависимости являются ограничениями целостности, поэтому при каждом обновлении данных в СУБД все они должны быть проверены.
5.3 Тривиальные и нетривиальные зависимости
Очевидным способом сокращения размера множества ФЗ было бы исключение тривиальных зависимостей, т.е. таких, которые не могут не выполняться. В качестве примера приведем тривиальную ФЗ для отношения SR:
{StNo, GrNo} ® {StNo}
Фактически ФЗ тривиальна тогда и только тогда, когда правая часть символической записи данной зависимости является подмножеством (не обязательно собственным подмножеством) левой части.
5.4 Замыкание множества зависимостей и правила вывода Армстронга
Некоторые функциональные зависимости обозначают другие функциональные зависимости. Например, функциональная зависимость:
{StNo}®{GrNo, StName}
подразумевает
следующие функциональные зависимости:
{StNo}®{GrNo}
{StNo}®{StName}
Множество всех ФЗ, которые задаются данным множеством функциональных зависимостей S, называется замыканием S и обозначается символом S+.
Поскольку функциональные зависимости являются ограничениями целостности, которые должны быть проверены СУБД, желательно для заданного множества ФЗ S найти такое множество ФЗ которое было бы гораздо меньшего размера, чем множество S, причем каждая ФЗ множества S могла бы быть заменена функциональной зависимостью множества T. Для решения этой задачи следует найти способ вычисления S+ на основе S.
Первой попыткой решить эту проблему была статья Армстронга (Armstrong), в которой представлен набор правил вывода функциональных зависимостей на основе заданных (эти правила также называются аксиомами Армстронга).
Правила вывода Армстронга. Пусть в перечисленных ниже правилах А, В, С и D – произвольные подмножества множества атрибутов заданного отношения R, а символическая запись АВ означает объединение А и В.
1. Рефлексивность: если В является подмножеством А, то А®В.
2. Дополнение: если А®В, то АС®ВС.
3. Транзитивность: если А®В и В®С, то А®С.
Каждое из этих правил может быть непосредственно доказано на основе определения функциональной зависимости (первое из них — это всего лишь определение тривиальной зависимости). Более того, эти правила являются полными в том смысле, что для заданного множества функциональных зависимостей S минимальный набор ФЗ, которые подразумевают все зависимости S, может быть выведен из S на основе этих правил. Они также являются исчерпывающими, поскольку никакие дополнительные ФЗ не могут быть выведены (т.е. ФЗ, которые не подразумеваются зависимостями множества S). Иначе говоря, эти правила могут быть использованы для получения замыкания S+.
Из трех описанных выше правил для упрощения задачи практического вычисления замыкания S можно вывести несколько других правил. (Пусть D – это другое произвольное подмножество множества атрибутов R.).
1. Самоопределение: А®А.
2. Декомпозиция: если А®ВС, то А®В и А®C.
3. Объединение: если A®В и А®С, то А®ВС.
4. Композиция: если А®В и С®D, то AC®BD.
5. Если А®В и С®D, то А È (С – В) ®BD (где символ "È" обозначает объединение множеств, а символ "–" – их разность).Это правило называют также теоремой всеобщего объединения.
Например. Пусть дано некоторое отношение R с атрибутами А, В, С, D, Е, F и следующими ФЗ:
А®{ВС}
В®Е
{CD}®{EF}
Далее символами, записанными подряд, например ВС, будем обозначать множество, состоящее из атрибутов В и С, а не объединение В и С.
Этому примеру можно придать более конкретный смысл, а именно: А – номер сотрудника, В – номер отдела, С – номер руководителя (начальника) данного сотрудника, D – номер проекта, возглавляемого данным руководителем (уникальный для каждого отдельно взятого руководителя), Е – название отдела, F – доля времени, уделяемая данным руководителем заданному проекту.
Показать, что зависимость AD ® F выполняется для отношения R и таким образом принадлежит замыканию данного множества ФЗ.
1. А®ВС (дано);
2. А®С (из 1 согласно декомпозиции);
3. AD®CD (из 2 согласно дополнению);
4. CD®EF (дано);
5. AD®EF (из 3 и 4 согласно транзитивности);
6. AD®F (из 5 согласно декомпозиции).
5.5 Неприводимое множество зависимостей
Пусть S1 и S2 являются двумя множествами ФЗ. Если любая ФЗ, которая является зависимостью множества S1, также является зависимостью множества S2, т.е. если S1+ является подмножеством S2+ то S2 называется покрытием для S1. Это значит, что если накладываемые в СУБД ограничения представлены зависимостями множества S2, то в этой СУБД также наложены ограничения на основе зависимостей множества S1.
Далее, если S2 является покрытием для S1, а S1 – покрытием для S2, т.е. если S1+=S2+ , то S1 и S2 эквивалентны. Ясно, что если S1 и S2 эквивалентны и наложенные в СУБД ограничения представлены зависимостями множества S2, то эти ограничения также могут быть представлены зависимостями множества S1, верно также и обратное утверждение.
Множество ФЗ называется неприводимым тогда и только тогда, когда выполняются перечисленные ниже свойства.
1. Правая часть (зависимая часть) каждой ФЗ множества S содержит только один атрибут (т.е. является одноэлементным множеством).
2. Левая часть (детерминант) каждой ФЗ множества S является неприводимой, т.е. ни один атрибут не может быть опущен из детерминанта без изменения замыкания S+ (без конвертирования множества S в некоторое множество, не эквивалентное множеству S). В таком случае ФЗ является неприводимой слева
3. Ни одна функциональная зависимость в S не может быть опущена из S без изменения замыкания S+ (т.е. без конвертирования множества S в некоторое множество, не эквивалентное множеству S).
Множество зависимостей t, которое неприводимо и эквивалентно некоторому другому множеству зависимостей S, называется неприводимым покрытием множества S. Таким образом, с тем же успехом в системе вместо исходного множества зависимостей S может быть использовано его неприводимое покрытие t. Однако следует отметить, что для заданного множества ФЗ не всегда существует уникальное неприводимое покрытие.
5.6 Нормальные формы – основные понятия
Процесс дальнейшей нормализации, который далее будет упоминаться просто как нормализация, основывается на концепции нормальных форм. Говорят, что отношение находится в некоторой нормальной форме, если удовлетворяет заданному набору условий. Например, отношение находится в первой нормальной форме, или сокращенно в 1 НФ, тогда и только тогда, когда оно содержит только скалярные значения.
Отсюда следует, что каждое нормализованное отношение находится в первой нормальной форме. Иначе говоря, термины "нормализованное" и "1НФ" означают одно и то же. Однако следует отметить, что термин "нормализованное" часто используется для обозначения нормальной формы более высокого уровня, хотя такое обозначение не очень корректно.
 рис. 5.2 Нормальные формы отношений.
рис. 5.2 Нормальные формы отношений.
На рис. 5.2 показано несколько нормальных форм, которые определены к настоящему времени.
Все нормализованные отношения находятся в 1НФ. Некоторые отношения 1НФ находятся также в 2НФ и некоторые отношения 2НФ находятся также в ЗНФ. Мотивом для введения дополнительных определений было то, что вторая нормальная форма "более желательна", чем первая, а третья, в свою очередь, "более желательна", чем вторая. Таким образом, при проектировании базы данных вообще следует использовать отношения не только в первой или во второй, но также и в третьей форме.
Процедуру нормализации можно охарактеризовать как последовательное приведение данного набора отношений к некоторой более желательной форме. Эта процедура обратима, т.е. всегда можно использовать ее результат (например, множество отношений, находящихся в ЗНФ) для обратного преобразования (в исходное отношение, находящееся в 2НФ). Возможность выполнения обратного преобразования является весьма важной характеристикой, поскольку означает, что в процессе нормализации информация не утрачивается
5.7 Декомпозиция без потерь и функциональные зависимости
Как упоминалось ранее, процедура нормализации включает разбиение, или декомпозицию данного отношения на другие отношения, причем декомпозиция должна быть обратимой, т.е. выполняться без потерь информации. Иначе говоря, интерес представляет только те операции, которые выполняются без потерь информации. Вопрос о том, происходит ли утрата информации при декомпозиции, тесно связан с концепцией функциональной зависимости.
Рассмотрим отношение Students из учебной базы данных, с атрибутами {StNo, GrNo, StName, CityNo} (рис. 5.3).
| Students | |||
| StNo | GrNo | StName | CityNo |
| 1 | 1 | Иванов | 1 |
| 2 | 1 | Петров | 3 |
рис. 5.3 Отношение Students.
Ниже приведены две возможные декомпозиции этого отношения (рис. 5.4).
| 1. SGN | SC | ||||
| StNo | GrNo | StName | StNo | CityNo | |
| 1 | 1 | Иванов | 1 | 1 | |
| 2 | 1 | Петров | 2 | 3 |
| 2. SGN | GC | ||||
| StNo | GrNo | StName | GrNo | CityNo | |
| 1 | 1 | Иванов | 1 | 1 | |
| 2 | 1 | Петров | 1 | 3 |
рис. 5.4 Возможные декомпозиции отношения Students.
В первом случае информация не утрачивается, поскольку отношения SGN и SC все еще содержат информацию о том, что Иванов живет в городе с кодом 1, Петров – 2. Соединение этих отношений позволяет восстановить исходное отношение Students, иначе говоря первая декомпозиция является декомпозицией без потерь.
Во втором случае информация о городе, в котором проживает студент утрачивается, поскольку студенты, учащиеся в группе с кодом 1 живут в разных городах и зная код группы невозможно однозначно определить код города в котором проживает студент.
Следует отметить, что процесс, который до сих пор назывался “декомпозицией”, на самом деле называется проецированием, т.е. каждое из показанных выше отношений SGN, SC и GC – в действительности являются проекциями исходного отношения Students. Таким образом оператор декомпозиции в процедуре нормализации фактически является оператором проецирования.
Исходное отношение при этом равно соединению его проекций. Для выполнения декомпозиции отношения без потерь необходимо знать, какие условия должны быть соблюдены для того, чтобы при обратном соединении гарантировать получение исходного отношения. Ответ на этот вопрос содержится в теореме Хеза.
Теорема Хеза. Пусть R{A, B, C} является отношением, где A, B, C – атрибуты этого отношения. Если R удовлетворяет зависимости A®B, то отношение R равно соединению его проекций {A, B} и {A, C}.
5.8 Диаграммы функциональных зависимостей
Некоторое неприводимое множество зависимостей отношения R можно представить в виде диаграммы функциональных зависимостей (диаграммы ФЗ).
На рис. 5.5 и рис. 5.6 показаны диаграммы ФЗ для некоторых отношений из учебной БД.
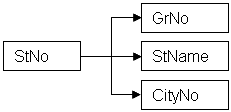 рис. 5.5 Диаграмма ФЗ для таблицы Students.
рис. 5.5 Диаграмма ФЗ для таблицы Students.
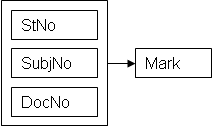 рис. 5.6 Диаграмма ФЗ для таблицы Marks.
рис. 5.6 Диаграмма ФЗ для таблицы Marks.
Как видно из рис. 5.5 и рис. 5.6 каждая стрелка начинается с потенциального ключа (на самом деле с первичного ключа) соответствующего отношения. По определению стрелки должны начинаться с каждого потенциального ключа, поскольку одному значению такого ключа всегда соответствует, по крайней мере, еще одно какое-то значение. Некоторые стрелки следовало бы исключить ввиду того, что очи вызывают определенные трудности, но стрелки, начинающиеся с потенциальных ключей, никогда не могут быть исключены.
Литература:
1. Дейт К.Дж. Введение в системы баз данных. –Пер. с англ. –6-е изд. –К. Диалектика, 1998. Стр. 259–276.
ЛЕКЦИЯ 6. Проектирование БД. Нормальные формы отношений6.1 Первая нормальная форма. Возможные недостатки отношения в 1НФ
6.2 Вторая нормальная форма. Возможные недостатки отношения во 2НФ
6.3 Третья нормальная форма. Возможные недостатки отношения в 3НФ
6.4 Нормальная форма Бойса-Кодда
6.1 Первая нормальная форма. Возможные недостатки отношения в 1НФ
Для простоты изложения предполагается, что каждое отношение имеет в точности один потенциальный ключ, который является первичным ключом. Это допущение подтверждают предлагаемые здесь доказательства. Далее в этой главе будет рассмотрен случай, когда отношение имеет два или более потенциальных ключа.
Отношение находится в первой нормальной форме тогда и только тогда, когда все используемые домены содержат только скалярные значения.
В этом определении всего лишь утверждается, что любое нормализованное отношение находится в 1НФ. Однако отношение, которое находится только в 1 НФ (т.е. не находится ни во второй, ни в третьей нормальной форме) обладает структурой, по некоторым причинам не совсем желательной. Для иллюстрации этого факта допустим, что информация о студентах и оценках содержится не в 2-х отношениях Students и Marks а в одном, назовем его SM.
SM{StNo, CityNo, GrNo, SubjNo, DocNo, Mark}
PRIMARY KEY (StNo, GrNo, SubjNo, DocNo).
Диаграмма функциональных зависимостей этого отношения будет выглядеть как показано на рис. 6.1.
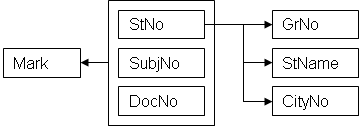 рис. 6.1 Диаграмма функциональных зависимостей отношения SM
рис. 6.1 Диаграмма функциональных зависимостей отношения SM
Обратите внимание, что диаграммы ФЗ отношения SM “сложнее”, чем диаграммы ФЗ отношений Students и Marks, из которых оно образовано. В диаграммах ФЗ отношений Students и Marks все стрелки начинаются только от первичных ключей, тогда как в диаграмме ФЗ отношения SM появляются дополнительные стрелки. Ниже приведена таблица данных для отношения SM (рис. 6.2).
| SM | ||||||
| StNo | StName | GrNo | CityNo | SubjNo | DocNo | Mark |
| 1 | Иванов | 1 | 1 | 1 | 127 | 5 |
| 1 | Иванов | 1 | 1 | 5 | 128 | 4 |
| 2 | Петров | 1 | 3 | 1 | 127 | 3 |
рис. 6.2 Данные отношения SM.
Несмотря на то, что отношение SM, как и Students и Marks находится в 1й НФ, оно очевидно обладает избыточностью, поскольку, например, в каждом кортеже для студента Иванова указан его номер “1”, код его группы – “1” и код города, в котором он проживает – “1”. Аналогичная ситуация с другими студентами.
Избыточность в отношении SM приводит к разным аномалиям обновления, получившим такое название по историческим причинам, т.е. к трудностям при выполнении операций обновления типа INSERT (вставка), DELETE (удаление) и UPDATE (обновление). Для начала рассмотрим избыточность типа студент—код города студента, соответствующую функциональной зависимости StNo ®CityNo, и перечисленные ниже проблемы с операциями обновления.
Операция вставки (INSERT). Нельзя вставить данные о студенте, проживающем в некотором городе, не указывая хотя бы одну, полученную этим студентом, оценку. Действительно, в таблице SM не показан студент Сидоров из г. Пятихатки потому, что до тех пор, пока этот студент не получит оценку по какому либо предмету, для него не задано значение первичного ключа.
Операция удаления (DELETE). Если удалить единственный кортеж отношения SM для некоторого студента, будет удалена не только информация о соответствующей оценке, но и информация о студенте и городе, в котором он проживает. Например, если в отношении SM удалить кортеж со значением Петров атрибута StName, будет утрачена вся информация об этом студенте.
Замечание. В действительности проблема заключается в том, что в отношении SM содержится очень много совместной информации, поэтому при удалении некоторого кортежа приходится удалять слишком иного другой информации. А точнее, отношение SM содержит информацию о студентах и об оценках. Таким образом, удаление информации об оценке вызывает также удаление информации о студенте. Для решения этой проблемы нужно разделить информацию на несколько частей, т.е. разместить информацию о студентах в одном отношении, а об оценках – в другом. Таким образом, неформально процедуру нормализации можно охарактеризовать как процедуру разбиения логически несвязанной информации по отдельным отношениям.
Операция модификации (UPDATE). Фамилия студента и код города, в котором он проживает повторяется в отношении SM множество раз, и это приводит к возникновению проблем при обновлении. Если студент меняет фамилию или переезжает в другой город, то возникает проблема, связанная либо с поиском в отношении SM всех кортежей, в которых присутствует информация об этом студенте, либо с получением несовместимого результата (в одном кортеже городом проживания студента будет один город, а в другом кортеже, городом проживания этого студента, будет другой город).
Для решения проблемы избыточности, которая характерна для отношения SM достаточно заменить его двумя другими:
Students{StNo, GrNo, StName, CityNo}
и
Marks{StNo, SubjNo, DocNo, Mark}
Важно отметить, что переработанная таким образом структура позволяет преодолеть все перечисленные ранее проблемы, связанные с операциями обновления.
Операция вставки (INSERT). Теперь с помощью вставки соответствующего кортежа в отношение Students можно включить информацию о студенте и городе, в котором он проживает, даже если он в настоящий момент не получил не одной оценки.
Операция удаления (DELETE). Теперь можно исключить информацию об оценке, удаляя соответствующий кортеж из отношения Marks, при этом информация о студенте и городе, в котором он проживает, не утрачивается.
Операция модификации (UPDATE). В переработанной структуре фамилия студента и информация о городе, в котором он проживает, появляется всего один раз, поскольку существует только один кортеж для данного студента в отношении Students (атрибут StNo является первичным ключом для такого отношения). Иначе говоря, избыточность данных StNo-StName-StCity устранена. Благодаря этому теперь можно один раз изменить в соответствующем кортеже отношения Students название города для какого-либо студента.
6.2 Вторая нормальная форма. Возможные недостатки отношения во 2НФ
Определим 2НФ при условии, что существует только один потенциальный ключ, который является первичным ключом.
Отношение находится во второй нормальной форме тогда и только тогда, когда оно находится в первой нормальной форме и каждый неключевой атрибут неприводимо зависим от первичного ключа.
Оба отношения, Students и Marks находятся во второй нормальной форме с первичными ключами StNp и {StNo, SubjNo, DocNo} соответственно, а отношение SM не находится в ней. Всякое отношение, которое находится в 1НФ и не находится в 2НФ, всегда можно свести к эквивалентному набору отношений, находящихся в 2НФ.
Рассмотрим другой пример. Предположим, информация о коде города, названии города и области, в которой этот город расположен находятся в одной таблице CNR{CityNo, CityName, RgNo, RgName} (рис. 6.3).
| CNR | |||
| CityNo | CityName | RgNo | RgName |
| 1 | Желтые Воды | 1 | Днепропетровская |
| 2 | Кривой Рог | 1 | Днепропетровская |
| 3 | Пятихатки | 1 | Днепропетровская |
| 4 | Львов | 2 | Львовская |
рис. 6.3 Данные отношения CNR.
Диаграмма ФЗ отношения CNR выглядит следующим образом – рис. 6.4.
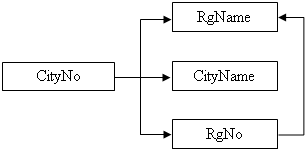 рис. 6.4 Функциональные зависимости в отношении CNR.
рис. 6.4 Функциональные зависимости в отношении CNR.
Как видно из рис. 6.3, это диаграмма ФЗ “сложнее” диаграмм ФЗ отношений Cities и Regions. Несмотря на то, что отношение CNR находится во 2НФ, оно обладает некоторой избыточностью, связанной с наличием транзитивной ФЗ между атрибутами CityNo и RgName. Транзитивная зависимость приводит к следующим аномалиям обновления.
Операция вставки (INSERT). Нельзя включить данные о некоторой области, например, нельзя указать, что существует Львовская область, до тех пор пока не появиться запись о городе, находящемся в данной области, – например о Львове.
Операция удаления (DELETE). При удалении из отношения CNR последнего кортежа для некоторого города будет удалена не только информация о данном городе, но также информация о том, в какой области этот город находился. Например, при удалении из отношения CNR кортежа для города Львов будет утрачена информация о Львовской области.
Замечание. Вновь причиной этих неприятностей является совместная информация: отношение CNR содержит информацию о городах вместе с информацией об областях. Для разрешения этой ситуации следует поступить так, как и раньше, т.е. ''разобрать" всю эту информацию и перенести в одно отношение сведения об областях, а в другое – сведения о городах.
Операция модификации (UPDATE). В отношении CNR код и название области для каждого города повторяется несколько раз (поэтому оно характеризуется некоторой избыточностью). Таким образом, при изменении кода области возникнет либо проблема необходимости поиска в отношении CNR всех кортежей для этой области (для внесения соответствующих изменений), либо проблема получения несовместимого результата.
Для решения этих проблем необходимо заменить отношение CNR двумя проекциями:
Cities{CityNo, CityName, RgNo}
Regions{RgNo, RgName}
Переработанная таким образом структура отношений позволит преодолеть все описанные проблемы с операциями обновления.
6.3 Третья нормальная форма. Возможные недостатки отношения в 3НФ
Отношение находится в третьей нормальной форме тогда и только тогда, когда оно находится во второй нормальной форме и каждый неключевой атрибут нетранзитивно зависит от первичного ключа. (Под "нетранзитивной зависимостью" подразумевается отсутствие какой-либо взаимной зависимости в изложенном выше смысле.)
Отношения Cities и Regions находятся в третьей нормальной форме. Таким образом вторым этапом нормализации является создание проекций для исключения транзитивных зависимостей.
6.3.1 Сохранение зависимости
В процессе приведения отношений часто возникают ситуации, когда данное отношение может быть подвергнуто операции декомпозиции разными способами. Рассмотрим снова приведенное выше отношение CNR с функциональными зависимостями CityNo®CityName, CityNo®RgNo, CityNo®RgNаме, RgNo®RgName и, следовательно, транзитивной зависимостью CityNo®RgName (на рис. 6.5 транзитивная зависимость показана пунктирной стрелкой).
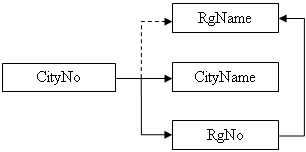 рис. 6.5 Функциональные зависимости в отношении CNR
рис. 6.5 Функциональные зависимости в отношении CNR
Выше отмечалось, что аномалии обновления, которые сопровождают отношение CNR, можно преодолеть с помощью декомпозиции с заменой этого отношения двумя проекциями в ЗНФ.
Cities{CityNo, CityName, RgNo} и Regions{RgNo, RgName}
Назовем эту декомпозицию просто "декомпозицией №1", имея в виду, что для нее существует альтернативная "декомпозиция №2":
Cities{CityNo, CityName, RgNo} и Regions{CityNo, RgName}
При этом обе проекции Cities одинаковы как для №1, так и для №2. Декомпозиция №2 происходит также без потери информации, а обе ее проекции находятся в ЗНФ. Однако по некоторым причинам декомпозиция №2 менее желательна, чем декомпозиция №1. Например, после выполнения декомпозиции №2 все еще невозможно вставить информацию о том, что некоторая область имеет определенный код, без указания города, который находится в этой области.
Рассмотрим этот пример подробнее. Прежде всего заметим, что зависимости проекций в декомпозиции №1 отмечены сплошными стрелками, тогда как одна, из зависимостей проекций декомпозиции №1 отмечена пунктирной стрелкой. В декомпозиции №1 две проекции независимы друг от друга в следующем смысле: обновления в каждой из проекций могут быть выполнены совершенно независимо друг от друга. (Конечно, за исключением ограничения целостности для Cities и Regions) Если такое обновление допустимо только в контексте данной проекции, т.е. не нарушается уникальность первичного ключа для этой проекции, то соединение этих двух проекций после обновления всегда будет равносильно отношению CNR (т.е. при соединении не будут нарушены ограничения, наложенные на ФЗ в отношении CNR). В декомпозиции №2, наоборот, обновление любой из двух проекций должно тщательно фиксироваться, чтобы гарантировать отсутствие нарушения зависимости RgNo®RgName (если два города находятся в одной и той же области, они должны иметь одинаковый код области). Иначе говоря, обе проекции декомпозиции №2 не являются независимыми одна от другой.
Основная проблема заключается в том, что в декомпозиции №2 функциональная зависимость RgNo®RgName становится ограничением между отношениями. (Следует отметить, что во многих современных программных продуктах это ограничение должно поддерживаться с помощью процедурной обработки.) В декомпозиции №1, наоборот, транзитивная зависимость SityNo®RgName является ограничением между отношениями, которое автоматически выполняется при задействовании двух ограничений внутри отношений: CityNo®RgNo и RgNo®RgName. Привести в действие эти ограничения достаточно просто за счет соответствующих ограничений, наложенных на уникальность первичных ключей.
Концепция независимых проекций, таким образом, обеспечивает критерий выбора одной из нескольких возможных декомпозиции. Декомпозиция с независимыми проекциями в приведенном выше общем смысле предпочтительнее той, в которой проекции зависимы. Риссанен (Rissanen) показал, что проекции R1 и R2 отношения R независимы в упомянутом выше смысле тогда и только тогда, когда:
1. каждая ФЗ в отношении R является логическим следствием функциональных зависимостей в проекциях R1 и R2;
2. общие атрибуты проекций R1 и R2 образуют потенциальный ключ, по крайней мере, для одной из них.
Отношение, которое не может быть подвергнуто декомпозиции с получением независимых проекций, называется атомарным. Однако это не значит, что любое неатомарное отношение может быть разбито на атомарные компоненты. Идея нормализации с декомпозицией на независимые проекции называется декомпозицией с сохранением зависимости.
6.4 Нормальная форма Бойса-Кодда
В этом разделе опускается упрощающее допущение о том, что каждое отношение имеет только один потенциальный ключ (а именно первичный ключ), и рассматривается более общий случай. Оригинальное определение Кодда для ЗНФ не совсем подходит для отношений с перечисленными ниже условиями.
1. Отношение имеет два (или более) потенциальных ключа.
2. Два потенциальных ключа являются сложными.
3. Они перекрываются (т.е. имеют, по крайней мере, один общий атрибут).
Поэтому оригинальное определение ЗНФ было впоследствии заменено более строгим определением Бойса-Кодда (Boyce/Codd), для которого было принято отдельное название – нормальная форма Бойса-Кодда, НФБК. (На самом деле строгое определение "третьей" нормальной формы, эквивалентное определению нормальной формы Бойса-Кодда, было впервые дано Хезом (Heath) в 1971 году, и этой форме следовало бы дать название "нормальная форма Хеза".)
Замечание. Комбинация условий 1, 2 и 3 не часто встречается на практике, и для отношения без этих условий ЗНФ и НФБК эквивалентны.
Отношение находится в нормальной форме Бойса-Кодда тогда и только тогда, когда каждая нетривиальная и неприводимая слева ФЗ обладает потенциальным ключом в качестве детерминанта.
Менее формальное определение имеет другую формулировку: отношение находится в нормальной форме Бойса-Кодда тогда и только тогда, когда детерминанты являются потенциальными ключами.
Иначе говоря, на диаграмме ФЗ стрелки будут начинаться только с потенциальных ключей. Согласно данному определению никакие другие стрелки не допускаются.
Примером отношения, которое находится в НФБК может служить отношение
Students, в которое курсовые - 700 р.
Работы, похожие на Учебное пособие: Организация баз данных
|