Курсовая работа: Порівняльний аналіз ефективності та складності швидких алгоритмів сортування масивів
Міністерство освіти і науки України
Курсова робота на тему:
"Порівняльний аналіз ефективності та складності швидких алгоритмів сортування масивів"
Зміст
Вступ
Розділ І. Прямі методи сортування масивів
1.1 Сортування прямим включенням
1.2 Сортування бінарним включенням
1.3 Сортування прямим вибором
1.4 Сортування прямим обміном
Розділ ІІ. Швидкі методи сортування масивів
2.1 Сортування включенням із зменшуваними відстанями – алгоритм Шелла (1959)
2.2 Сортування обміном на великих відстанях – алгоритм Quick Sort
2.3 Сортування вибором при допомозі дерева – алгоритм Тree Sort
2.4 Сортування вибором при допомозі дерева – алгоритм Heap Sort
2.5 Порівняльна характеристика швидкодії деяких швидких алгоритмів сортування
Висновки
Література
Вступ
В наш час нові інформаційні технології посідають дуже важливе місце не лише в спеціалізованих, але й в повсякденних сферах життя. Комп’ютери застосовуються в бізнесі, менеджменті, торгівлі, навчанні та багатьох інших сферах діяльності людини.
Комп’ютерні технології дуже зручні для виконання різноманітних операцій, але в різних сферах застосування ці операції різні. Тому, кожна окрема галузь, яка використовує специфічні технічні засоби, потребує своїх власних програм, які забезпечують роботу комп’ютерів.
Розробкою програмного забезпечення займається така галузь науки, як програмування. Вона набуває все більшого й більшого значення останнім часом, адже з кожним днем комп’ютер стає все більш необхідним, все більш повсякденним явищем нашого життя. Адже обчислювальна техніка минулих років вже майже повністю вичерпала себе і не задовольняє тим потребам, що постають перед людством.
Таким чином, нові інформаційні технології дуже актуальні в наш час і потребують багато уваги для подальшої розробки та вдосконалення. Поряд з цим, велике значення має також і програмування, яке є одним із фундаментальних розділів інформатики і тому не може залишатись осторонь.
Програмування містить цілу низку важливих внутрішніх задач. Однією з найбільш важливих таких задач для програмування є задача сортування. Під сортуванням звичайно розуміють перестановки елементів будь-якої послідовності у визначеному порядку. Ця задача є однією з найважливіших тому, що її метою є полегшення подальшої обробки певних даних і, насамперед, задачі пошуку. Так, одним з ефективних алгоритмів пошуку є бінарний пошук. Він працює швидше ніж, наприклад, лінійний пошук, але його можливо застосовувати лише за умови, що послідовність вже упорядкована, тобто відсортована.
Взагалі, відомо, що в будь-якій сфері діяльності, що використовує комп’ютер для запису, обробки та збереження інформації, усі дані зберігаються в базах даних, які також потребують сортування. Певна впорядкованість для них дуже важлива, адже користувачеві набагато легше працювати з даними, що мають певний порядок. Так, можна розташувати всі товари по назві або відомості про співробітників чи студентів за прізвищем або роком народження, тощо.
Задача сортування в програмуванні не вирішена повністю. Адже, хоча й існує велика кількість алгоритмів сортування, все ж таки метою програмування є не лише розробка алгоритмів сортування елементів, але й розробка саме ефективних алгоритмів сортування. Ми знаємо, що одну й ту саму задачу можна вирішити за допомогою різних алгоритмів і кожен раз зміна алгоритму приводить до нових, більш або менш ефективних розв’язків задачі. Основними вимогами до ефективності алгоритмів сортування є перш за все ефективність за часом та економне використання пам’яті. Згідно цих вимог, прості алгоритми сортування (такі, як сортування вибором і сортування включенням) не є дуже ефективними.
Алгоритм сортування обмінами, хоча і завершує свою роботу (оскільки він використовує лише цикли з параметром і в тілі циклів параметри примусово не змінюються) і не використовує допоміжної пам’яті, але займає багато часу. Навіть, якщо внутрішній цикл не містить жодної перестановки, то дії будуть повторюватись до тих пір, поки не завершиться зовнішній цикл.
Алгоритм сортування вибором ефективніше сортування обмінами за критерієм М(n), тобто за кількістю пересилань, але також є не дуже ефективним. З цих причин було розроблено деякі нові алгоритми сортування, що отримали назву швидких алгоритмів сортування. Це такі алгоритми, як сортування деревом, пірамідальне сортування, швидке сортування Хоара та метод цифрового сортування.
Метою нашої дослідницької роботи є ознайомлення з цими швидкими алгоритмами сортування, спроба проаналізувати їх і висвітлити кожен з них і написати програму, яка б виконувала сортування деякої послідовності за допомогою різних швидких алгоритмів сортування.
Сортування варто розуміти, як процес перегрупування заданої множини об'єктів в деякому конкретному порядку. Мета сортування - полегшити наступний пошук елементів в такій відсортованій множині.
Вибір алгоритму залежить від структури даних, що обробляються. У випадку сортування ця залежність настільки велика, що відповідні методи навіть були розбиті на дві групи - сортування масивів і сортування файлів (послідовностей). Іноді їх називають внутрішнім і зовнішнім і сортуванням, оскільки масиви зберігаються в швидкій внутрішній пам’яті (оперативній) із довільним доступом, а файли розміщуються в менш швидкій, проте більш об'ємній зовнішній пам'яті.
Метод сортування називається стійким, якщо в процесі впорядкування відносне розміщення елементів з рівними значеннями не міняється. Стійкість сортування часто буває бажаною, якщо йде мова про елементи, що вже впорядковані по деяких вторинних ключах (тобто ознаках), які не впливають на основний ключ.
Нехай дано масив N елементів деякого абстрактного типу basetype:
a : array [1..N] of basetype.
Не обмежуючи загальності, зупинимося на впорядкуванні його компонентів по зростанню.
Основна умова: обраний метод сортування масивів повинен економно використовувати доступну пам’ять. Це означає, що перестановки, які приводять елементи в порядок, повинні виконуватися "на тому ж місці". Тобто методи, в яких елементи масиву a передаються в результуючий масив b, не мають практичної цінності.
Алгоритми сортування окрім критерію економії пам’яті будуть класифікуватися по швидкості, тобто по часу їх роботи. Оскільки на різних типах ЕОМ одні і ті ж методи показуватимуть відмінні результати, то в якості міри ефективності алгоритму можуть бути прийняті числа: C - кількість необхідних порівнянь ключів; M - кількість перестановок елементів. Очевидно, що ці числа є функціями від кількості елементів в масиві N. Згідно із введеними критеріями швидкодії алгоритми сортування поділяють на два типи - прямі та швидкі.
Прямі методи зручні для пояснення і розбору основних рис більшості сортувань, легко програмуються і відлагоджуються, а самі програми - короткі, що теж важливо для економії пам’яті. В основі їх лежить повторення N етапів обробки масиву із зменшенням на кожному з них кількості порівнюваних елементів. Ефективність даних алгоритмів є величиною порядку O(N2). Такі методи зручно використовувати на так званих "коротких" масивах.
Швидкі методи вимагають невеликої кількості етапів обробки, однак ці етапи досить складні. На кожному з них окрім переміщення чергового елемента на "своє" місце відбувається перегрупування решти відносно цього елемента. Звичайно виграш по ефективності для таких алгоритмів отримується на "довгих" масивах.
Методи сортування "на тому ж місці" у відповідності із визначаючими їх принципами розбиваються на три основні категорії :
- сортування включенням;
- сортування вибором;
- сортування обміном.
У курсовій роботі ми детально розглянемо швидкі алгоритми сортування елементів масиву, проведемо їх порівняльний аналіз. Крім цього, розглянемо і прямі методи сортування, їх позитиви і недоліки, що дасть змогу краще визначити ефективність і складність швидких алгоритмів сортування.
Розділ І. Прямі методи сортування масивів
1.1 Сортування прямим включенням
В основі розглядуваного методу лежить пошук для чергового елемента масиву відповідного місця у відсортованій частині із наступним включенням його в знайдену позицію. Таким чином елементи масиву умовно діляться на дві групи - вже "готову" послідовність a 1 , a 2 , ..., a i та вихідну послідовність. На кожному етапі, починаючи з i=2 та збільшуючи i кожен раз на 1, із вихідної послідовності вибирається один елемент і вставляється в потрібне місце у вже впорядковану послідовність. Очевидно, що початкова ліва послідовність буде "готовою", оскільки одноелементний масив завжди впорядкований. Цей алгоритм можна записати у вигляді послідовності команд :
for i:=2 to N do
begin
x:=a[i];
включення x на потрібне місце серед a[1], ..., a[i]
end;
Процес просіювання (пошуку потрібного місця для включення елемента x ) може припинитися при виконанні однієї із двох умов :
1) знайдено елемент a j з ключем, меншим ніж ключ у x ;
2) досягнутий лівий кінець "готової" послідовності.
Таким чином програмна реалізація методу прямого включення матиме вигляд процедури :
Procedure Straight_Insertion;
Var
i, j : integer; x : basetype;
Begin
for i:=2 to N do
begin
x:=a[i]; a[0]:=x; j:=i;
while x<a[j-1] do
begin
a[j]:=a[j-1];
j:=j-1
end;
a[j]:=x
end
End;
Використання додаткового елемента в масиві - "бар’єра" a[0]=x забезпечує гарантоване припинення процесу просіювання. Це дозволяє зменшити кількість логічних умов в заголовку цикла while до однієї, а кількість логічних операцій від 2i-1 до i на кожному етапі. Звичайно, при цьому необхідно попередньо розширити на один елемент масив a та діапазон допустимих значень індекса. На жаль, таке покращення ефективності по кількості порівнянь не зменшує об’єму перестановок елементів.
Аналіз прямого включення. Кількість порівнянь ключів Ci при i-ому просіюванні найбільше дорівнює i, найменше - 1, а середньоймовірна кількість - i/2. Кількість же перестановок (переприсвоєнь ключів), включаючи бар’єр, Mi=Ci+2. Тому для оцінки ефективності алгоритму у випадках початково впорядкованого, зворотньо впорядкованого та довільного масиву можна скористатися наступними співвідношеннями:
 ;
; ;
;
 ;
;
 ;
;
 ;
;
 .
.
Очевидно, що розглянутий алгоритм описує процес стійкого сортування.
1.2 Сортування бінарним включенням
Алгоритм прямого включення можна значно покращити, якщо врахувати, що "готова" послідовність є вже впорядкованою. Тому можна скористатися бінарним пошуком точки включення в "готову" послідовність. Програмна реалізація такого модифікованого методу включення матиме вигляд процедури:
Procedure Binary_Insertion;
Var
i, j, m, L, R : integer; x : basetype;
Begin
for i:=2 to N do
begin
x:=a[i]; L:=1; R:=i;
while L<R do
begin
m:=(L+R) div 2;
if a[m]<=x then L:=m+1 else R:=m
end;
for j:=i downto R+1 do
a[j]:=a[j-1];
a[R]:=x
end
End;
Аналіз бінарного включення. Зрозуміло, що кількість порівнянь у такому алгоритмі фактично не залежить від початкового порядку елементів. Місце включення знайдено, якщо L=R. Отже вкінці пошуку інтервал повинен бути одиничної довжини. Таким чином ділення його пополам на i-ому етапі здійснюється log(i) раз. Тому кількість операцій порівняння буде:
 , де
, де ![]() ,
, ![]() .
.
Апроксимуючи цю суму інтегралом, отримаємо наступну оцінку :
 , де
, де  .
.
Однак істинна кількість порівнянь на кожному етапі може бути більшою ніж log(i) на 1. Тому
![]() .
.
Нажаль покращення, що породженні введенням бінарного пошуку, стосується лише кількості операцій порівняння, а не кількості потрібних переміщень елементів. Фактично кількість перестановок M залишається величиною порядку N2. Для досить швидких сучасних ЕОМ рух елемента, тобто самого ключа і зв’язаної з ним інформації, займає значно більше часу, ніж порівняння самих ключів. Крім того сортування розглядуваним методом вже впорядкованого масиву за рахунок log(i) операцій порівняння вимагатиме більше часу, ніж у випадку послідовного сортування з прямим включенням. Очевидно, що кращий результат дадуть алгоритми, де перестановка, нехай і на велику відстань, буде пов’язана лише з одним елементом, а не з переміщенням на одну позицію цілої групи.
1.3 Сортування прямим вибором
На відміну від включення, коли для чергового елемента відшукувалося відповідне місце в "готовій" послідовності, в основу цього методу покладено вибір відповідного елемента для певної позиції в масиві. Цей прийом базується на таких принципах :
1) на i-ому етапі серед елементів a i , a i+1 , ..., a N вибирається елемент з найменшим ключем a min ; 2) проводиться обмін місцями a min та a i .
Процес послідовного вибору і перестановки проводиться поки не залишиться один єдиний елемент - з самим найбільшим ключем.
Такий алгоритм можна записати у вигляді послідовності команд :
for i:=1 to N-1 do
begin
k:=номер найменшого ключа серед a[i], ..., a[N];
обмін місцями a[k] та a[i]
end;
А програмна реалізація методу прямого вибору матиме вигляд процедури
Procedure Straight_Selection;
Var
i, j, k : integer; x : basetype;
Begin
for i:=1 to N-1 do
begin
x:=a[i]; k:=i;
for j:=i+1 to N do
if a[j]<x then begin x:=a[j]; k:=j end;
x:=a[k]; a[k]:=a[i]; a[i]:=x
end
End;
Аналіз прямого вибору. Очевидно, що кількість порівнянь ключів Ci на i-ому виборі не залежить від початкового розміщення елементів і дорівнює N-i. Таким чином

Кількість же перестановок залежить від стартової впорядкованості масиву. Це стосується переприсвоєнь у внутрішньому циклі по j при пошуку найменшого ключа.
В найкращому випадку початково впорядкованого масиву Mi=4 ; в найгіршому випадку зворотно впорядкованого масиву Mi=Ci+4 ; для довільного масиву рівномовірно можливе значення Mi=Ci/2+4. Тому для оцінки ефективності алгоритму по перестановках можна скористатися наступними співвідношеннями:
 ;
;
 ;
;
 .
.
Як і в попередньому випадку алгоритм прямого вибору описує процес стійкого сортування.
1.4 Сортування прямим обміном
Даний метод базується на повторенні етапів порівняння сусідніх ключів при русі вздовж масиву. Якщо наступний елемент виявиться меншим від попереднього, то відбувається обмін (звідси і назва методу). Таким чином, при русі з права наліво за один етап найменший ключ переноситься на початок масиву. Зрозуміло, що кожен наступний прохід можна закінчувати після позиції знайденого на попередньому етапі мінімального елемента, оскільки всі елементи перед ним вже впорядковані. Розглядуваний процес дещо нагадує виштовхування силою Архімеда бульбашки повітря у воді. Тому цей алгоритм ще називають "бульбашковим" сортуванням.
Програмна реалізація методу прямого обміну або "бульбашки" матиме вигляд процедури:
Procedure Buble_Sort;
Var
i, j : integer; x : basetype;
Begin
for i:=2 to N do
for j:=N downto i do
if a[j-1]>a[j] then begin x:=a[j]; a[j]:=a[j-1]; a[j-1]:=x end
End;
Якщо етапи порівняння та обміну проводити зліва направо, то відбуватиметься виштовхування найбільшого елемента вкінець масиву. Очевидно такий процес відповідає опусканню під дією сили тяжіння камінця у воді. Назвемо цей алгоритм "камінцевим" сортуванням :
Procedure Stone_Sort;
Var
i, j : integer; x : basetype;
Begin
for i:=1 to N-1 do
for j:=1 to N-i do
if a[j]>a[j+1] then begin x:=a[j]; a[j]:=a[j+1]; a[j+1]:=x end
End;
Обидва алгоритми згідно із визначаючим принципом вимагають досить великої кількості обмінів. Тому виникає питання, чи не вдасться підвищити їх ефективність хоча б за рахунок зменшення операцій порівняння? Цього можна добитися при допомозі наступних покращень:
1) фіксувати, чи були перестановки в процесі деякого етапу. Якщо ні, то - кінець алгоритму ;
2) фіксувати крім факту обміну ще і положення (індекс) останнього обміну. Очевидно, що всі елементи перед ним або після нього відповідно для сортування "бульбашкою" або "камінцем" будуть впорядковані ;
3) почергово використовувати алгоритми "бульбашки" і "камінця". Тому що для чистої "бульбашки" за один прохід "легкий" елемент виштовхується на своє місце, а "важкий" опускається лише на один рівень. Аналогічна ситуація з точністю до навпаки і для "камінця". Такий алгоритм називається "шейкерним" сортуванням.
Читачу пропонується самостійно модифікувати наведені вище процедури з врахуванням цих покращень.
Аналіз прямого обміну. Розглянемо спочатку чисту "бульбашку". Для "камінця" оцінки будуть такими ж самими. Зрозуміло, що кількість порівнянь ключів Ci на i-ому проході не залежить від початкового розміщення елементів і дорівнює N-i. Таким чином
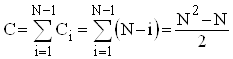
Кількість же перестановок залежить від стартової впорядкованості масиву. В найкращому випадку початково впорядкованого масиву Mi=0 ; в найгіршому випадку зворотньо впорядкованого масиву Mi=Ci*3; для довільного масиву рівноймовірно можливе значення Mi=Ci*3/2. Тому для оцінки ефективності алгоритму по перестановках можна скористатися наступними співвідношеннями:
![]() ;
;
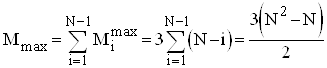 ;
;
 .
.
Очевидно, що і цей алгоритм, аналогічно з іншими прямими методами, описує процес стійкого сортування.
Розглянемо тепер покращений варіант "шейкерного"
сортування. Для цього алгоритму характерна залежність кількості операцій
порівняння від початкового розміщення елементів в масиві. В найкращому випадку
вже впорядкованої послідовності ця величина буде ![]() . У випадку зворотньо
впорядкованого масиву вона співпадатиме з ефективністю для чистої "бульбашки".
. У випадку зворотньо
впорядкованого масиву вона співпадатиме з ефективністю для чистої "бульбашки".
Як видно, всі покращення не змінюють кількості переміщень елементів (переприсвоєнь), а лише зменшують кількість повторюваних порівнянь. На жаль операція обміну місцями елементів в пам’яті є "дорожчою" ніж порівняння ключів. Тому очікуваного виграшу буде небагато. Таким чином "шейкерне" сортування вигідне у випадках, коли відомо, що елементи майже впорядковані. А це буває досить рідко.
Розділ ІІ. Швидкі методи сортування масивів
2.1 Сортування включенням із зменшуваними відстанями – алгоритм Шелла (1959)
Шелл вдосконалив пряме включення. Він запропонував проводити послідовне впорядкування підмасивів з елементів, які знаходяться на великих відстанях. При цьому на кожному наступному етапі відстані між елементами в групах мають зменшуватися.
Для ілюстрації алгоритму розглянемо його покрокове
описання. Не обмежуючи загальності, в якості прикладу спочатку зупинимося на
масиві з кількістю елементів, що є степенем двійки, тобто ![]() :
:
1) на першому етапі окремо групуються і сортуються елементи, розміщені на відстані N/2 . Це є впорядкування N/2 підмасиві по 2 елементи, яке називатимемо N/2-сортування .
2) на другому етапі виконується впорядку вання N/4 підмасивів по 4 елементи на відстані N/4 - N/4-сортування і т.д.
На останньому етапі виконується одинарне сортування (впорядкування на відстані 1). Наприклад :
44 55 12 42 94 18 06 67
етап I-сортування
44 18 06 42 94 55 12 67
етап II-сортування
06 18 12 42 44 55 94 67
етап III-сортування
06 12 18 42 44 55 67 94
Виникає питання, чи використання багатьох процесів сортування із залученням всіх елементів не збільшить кількість операцій, тобто складність алгоритму? Але на кожному проході або впорядковується відносно мало елементів (початкові етапи), або елементи вже досить добре впорядковані і вимагається відносно мало перестановок (кінцеві етапи). Кожне i-те сортування об’єднує дві групи, вже впорядковані 2i-тим сортуванням. Очевидно, що відстань між елементами груп можна зменшувати по-різному, головне, щоб остання була одиничною. Останній прохід в найгіршому випадку і виконує основну роботу. Варто зауважити, що такий довільний підхід при зменшенні відстаней не погіршує результату і у випадку кількості елементів N, що не є степенем двійки.
Нехай виконується t етапів. Відстані між елементами в окремих групах на кожному етапі позначимо : h1 , h2 , ..., h t , де h t=1, h i+1<h i , i=1, 2, ..., t-1. Таким чином розглядаються h-ті сортування. Кожне h-те сортування можна реалізувати будь-яким із прямих методів. Зокрема, вибір включення оправданий кращою в порівнянні з іншими алгоритмами ефективністю по перестановках ключів. Однак, чи варто для спрощення умови припинення пошуку місця включення чергового елемента користуватися методом бар’єрів? Оскільки кожне h-те сортування потребує свого власного бар’єра, то прийдеться розширити масив не на одну компоненту a0 , а на h1 компонент. На першому етапі - це практично половина всіх елементів. У випадку "довгих" масивів прийдеться порушити правило сортування "на своєму місці". Тому не варто заради економії однієї логічної операції на кожному етапі впорядкування жертвувати такими об’ємами пам’яті.
Кількість етапів сортування t як і відстані на кожному з них можна вибирати довільно. Зокрема, це може бути кількість цілочисельних поділів числа N на 2, тобто t=[log(N)]. В якості прикладу пропонується процедура сортування методом Шелла для масиву із 16 елементів :
Procedure Shell_Sort;
Const t=4;
Var
m, i, j, k : integer;
h : array [1..t] of integer;
x : basetype;
Begin
h[1]:=8; h[2]:=4; h[3]:=2; h[4]:=1;
for m:=1 to t do
begin
k:=h[m];
for i:=k+1 to N do
begin
x:=a[i]; j:=i-k;
while (x<a[j]) and (j>0) do
begin
a[j+k]:=a[j]; j:=j-k
end;
a[j+k]:=x
end
end
End;
Аналіз алгоритму Шелла. Поки що не має чітко обгрунтованих виборів відстаней, які давали б найкращу ефективність. Самим цікавим є те, що ці відстані не повинні бути множниками один одного, а тим більше степенями деяких чисел. Це дозволяє уникнути явища, коли на певному етапі взаємодіють дві групи, які до цього ніде ще не перетиналися. Взагалі, бажано, щоб взаємодія окремих ланцюгів відбувалася якомога частіше. Вірною є наступна теорема :
Теорема. Якщо k-відсортовану послідовність i-відсортувати, то вона при цьому залишиться k-відсортованою.
Кнут рекомендує використовувати такі послідовності відстаней, записані в зворотньому порядку :
1, 4, 13, 40, 121, ... , де h i-1=3h i+1 , h t=1 , t=[log 3 N]-1 , або
1, 3, 7, 15, 31, ... , де h i-1=2h i+1 , h t=1 , t=[log 2 N]-1.
З обчислювальної практики відомо, що загалом метод Шелла має ефективність порядку O(N1,2).
2.2 Сортування обміном на великих відстанях – алгоритм Quick Sort
Основна причина повільної роботи алгоритму прямого обміну полягає в тому, що всі порівняння і перестановки елементів в послідовності a 1 , a 2 , ..., a N відбуваються для пар із сусідніх елементів. При такому способі потрібно відносно більше часу, щоб поставити деякий ключ, який знаходиться не на своєму місці, в потрібну позицію у сортованій послідовності. Природньо попробувати пришвидшити цей процес, порівнюючи пари елементів, що знаходяться далеко один від одного в масиві. К. Хоор розробив алгоритм Quick Sort із середнім часом роботи порядку O(N*lnN).
Припустимо, що перший елемент масиву, що сортується, є хорошим наближенням елемента, який вкінці опиниться на своєму місці у відсортованій послідовності. Приймемо його значення в якості ведучого елемента, відносно якого ключі будуть мінятися місцями. Для зручності реалізації алгоритму використаємо два вказівники I, J, перший з яких вестиме відлік вздовж розглядуваної частини масиву зліва, а другий - справа. Початково їх значення будуть відповідно I=1, J=N. Таким чином ведучим елементом буде значення a[I]. Перестановки ключів проводяться за такими принципами :
1) порівнюються елементи a[I] та a[J]; якщо a[I]£a[J], то здійснюється крок вліво J:=J-1 і порівняння повторюється; зменшення J продовжується доти, поки не виконається умова a[I]> a[J];
2) якщо при порівнянні елементів досягнута умова a[I]> a[J], то проводиться обмін місцями кючів a[I] та a[J] і здійснюється крок вправо I:=I+1; таким чином ведучий елемент перейшов в позицію J; порівняння ключів із збільшенням I продовжується доти, поки знову не виконається умова a[I]> a[J];
3) у випадку виконання умови a[I]> a[J] проводиться обмін місцями кючів a[I] та a[J] і здійснюється крок вліво J:=J-1; при цьому ведучий елемент знову повертається в позицію I.
Цей процес із почерговим зменшенням J та збільшенням I повторюється з обох кінців послідовності до "середини"до тих пір, поки не досягнеться I=J.
Тепер мають місце два факти. По-перше, ключ, що був першим у вихідній послідовності, в результаті такого впорядкування опиняється на "своєму" місці. По-друге, всі елементи зліва будуть меншими за нього, а всі ключі справа - більшими.
Ту ж саму процедуру можна використати для впорядкування лівої і правої підпослідовностей і т. д. до повного сортування всьго масиву. Таким чином розглянутий алгоритм має чітко виражений рекурсивний характер. Виходячи з цього, значення індексів крайніх елементів меншої з двох невідсортованих підпослідовностей варто помістити в стекову структуру даних, і приступити до впорядкування більшої підпослідовності.
Оскільки короткі послідовності скоріше сортуються при допомозі прямих методів, то алгоритм Quick Sort матиме вхідний параметр - деяке число S, що визначає нижню межу його використання. Провівши нескладний математичний аналіз нерівності, яка пов’язує ефективності алгоритму Quick Sort та прямих алгоритмів сортування
 ,
,
можна встановити значення числа S, яке буде нижньою
межею використання швидкого сортування. Остання нерівність дає результат ![]() .
.
Однак, якщо крім основних операцій порівняння ключів ще враховувати порівняння індексів та перестановки елементів, то це значення можна збільшити в 2-3 рази.
В якості прикладу наводиться програмна реалізація цього алгоритму у вигляд процедури Quick_Sort. В ній використовується два масиви left і right, де зберігатимуться індексні номери відповідно лівої і правої границь підпослідовностей, які ще будуть впорядковуватися на наступних етапах.
Procedure Quick_Sort;
Const S=20;
Var
k, L, R, i, j : integer;
x : basetype;
left, right : array [1..N] of integer;
Begin
k:=1; left[k]:=1; right[k]:=N;
while k>0 do
begin
L:=left[k]; R:=right[k]; k:=k-1;
while R-L>S do
begin
i:=L; j:=R; x:=a[i];
while j>i do
begin
while x<a[j] do j:=j-1;
if j>i then begin
a[i]:=a[j]; a[j]:=x; i:=i+1
end;
while a[i]<x do i:=i+1;
if j>i then begin
a[j]:=a[i]; a[i]:=x; j:=j-1
end
end;
k:=k+1;
if R-i<=i-L then
begin
left[k]:=i+1; right[k]:=R; R:=i-1
end
else
begin
left[k]:=L; right[k]:=i-1; L:=i+1
end
end;
for i:=L+1 to R do
begin
x:=a[i]; j:=i-1;
while (x<a[j]) and (j>=L) do
begin
a[j+1]:=a[j]; j:=j-1
end;
a[j+1]:=x
end
end
End;
Аналіз алгоритму Quick Sort. Щоб оцінити ефективність алгоритму, позначимо через Q(N) середню кількість кроків, необхідних для впорядкування N елементів. Припустимо також, S=1, тобто не використовується сортування прямими методами на коротких послідовностях.
При першому проходженні Quick Sort порівнює всі елементи з
ведучим і виконується не більше ніж за C*N кроків, де C - деяка
константа. Потім потрібно відсортувати дві підпослідовності довжинами I-1
та N-I. Тому середня кількість кроків, потрібних для впорядкування N елементів,
залежить від середньої кількості кроків, потрібних для впорядкування I-1
та N-I елементів відповідно. Оскільки всі можливі значення ![]() є
рівноймовірними, то спрведлива наступна оцінка :
є
рівноймовірними, то спрведлива наступна оцінка :
 .
.
Врахувавши, що
 ,
,
отримаємо
 .(1)
.(1)
Покажемо за індукцією по N, що ![]() для
для ![]() , де K=2C+2B, B=Q(0)=Q(1).
Останнє співвіднощення означає, що Quick Sort вимагає постійної однакової
кількості кроків для впорядкування 0 або 1 елемента.
, де K=2C+2B, B=Q(0)=Q(1).
Останнє співвіднощення означає, що Quick Sort вимагає постійної однакової
кількості кроків для впорядкування 0 або 1 елемента.
1) N=2 : ![]() ;
;
2) припустимо, що ![]() для I=2, 3, ..., N-1 ;
для I=2, 3, ..., N-1 ;
3) перевіримо справедливість для I=N. Співвідношення (1) з врахуванням попереднього припущення можна переписати у вигляді
 або
або
 .(2)
.(2)
Оскільки функція I*ln(I) є опуклою вниз, то для цілих значень аргументу справедлива оцінка

Врахувавши останню нерівність, із співвідношення (2) одержимо
 .
.
Оскільки ![]() , то
, то
![]() .
.
Остаточно отримаємо
![]() .(3)
.(3)
Таким чином ефективність алгоритму Quick Sort є величина порядку O(N*ln(N)).
Всі наведені викладки справедливі для аналізу по операціях порівняння. Кількість же перестановок залежить від початкового розміщення елементів у послідовності. Характерно, що для цього методу у випадку зворотньо впорядкованого масиву об’єм переміщень ключів не буде максимальним. Адже на кожному етапі ведучий елемент буде найбільшим і опиниться на своєму місці після першого ж порівняння і перестановки, тобто M=N-1. Максимальна кількість переприсвоєнь ключів співпадатиме з кількістю порівнянь, мінімальна - рівна нулю.
Алгоритм Quick Sort, як і розглянуті прямі методи, описує процес стійкого сортування.
2.3 Сортування вибором при допомозі дерева – алгоритм Тree Sort
Алгоритм сортування деревом ТreeSort власне кажучи є поліпшенням алгоритму сортування вибором. Процедура вибору найменшого елемента удосконалена як процедура побудови так званого сортуючого дерева. Сортуюче дерево - це структура даних, у якій представлений процес пошуку найменшого елемента методом попарного порівняння елементів, що стоять поруч. Алгоритм сортує масив у два етапи.
I етап : побудова сортуючого дерева;
II етап : просівання елементів по сортуючому дереву.
Розглянемо приклад: Нехай масив A складається з 8 елементів. Другий рядок складається з мінімумів елементів першого рядка, які стоять поруч. Кожний наступний рядок складений з мінімумів елементів, що стоять поруч, попереднього рядка.
Ця структура даних називається сортуючим деревом. У корені сортуючого дерева розташований найменший елемент. Крім того, у дереві побудовані шляхи елементів масиву від листів до відповідного величині елемента вузла -розгалуження.
Коли дерево побудоване, починається етап просівання елементів масиву по дереву. Мінімальний елемент пересилається у вихідний масив B і усі входження цього елемента в дереві заміняються на спеціальний символ M. Потім здійснюється просівання елемента уздовж шляху, відзначеного символом M, починаючи з листка, сусіднього з M і до кореня. Крок просівання - це вибір найменшого з двох елементів, що зустрілися на шляху до кореня дерева і його пересилання у вузол, відзначений M.
a6 = min(M, a6)
a6 = min(a6, a8)
a3 = min(a3, a6)
b2 := a3
Просівання елементів відбувається доти, поки весь вихідний масив не буде заповнений символами M, тобто n раз:
For і := 1 to n do begin
Відзначити шлях від кореня до листка символом M;
Просіяти елемент уздовж відзначеного шляху;
B[I] := корінь дерева
end;
Обґрунтування правильності алгоритму очевидно, оскільки кожне чергове просівання викидає в масив У найменший з елементів масиву А, що залишилися.
Сортуюче дерево можна реалізувати, використовуючи або двовимірний масив, або одномірний масиві ST[1..N], де N = 2n-1.
Аналіз алгоритму Tree Sort.
Оцінимо складність алгоритму в термінах M(n), C(n). Насамперед відзначимо, що алгоритм Tree Sort працює однаково на усіх входах, так що його складність у гіршому випадку збігається зі складністю в середньому.
Припустимо, що n - ступінь 2 (n = 2l). Тоді сортуюче дерево має l + 1 рівень (глибину l). Побудова рівня I вимагає n / 2I порівнянь і пересилань. Таким чином, I-ий етап має складність:
C1(n) = n/2+n/4+ ... + 2+1 = n-1, M1(n) = C1(n) = n - 1
Для того, щоб оцінити складність II-го етапу С2(n) і M2(n) помітимо, що кожен шлях просівання має довжину l, тому кількість порівнянь і пересилань при просіванні одного елемента пропорційно l. Таким чином,
M2(n) = O(l n),
C2(n) = O(l n).
Оскільки l = log2n, M2(n)=O(n log2 n)), C2(n)=O(n log2 n), Але З(n) = C1(n) + C2(n), M(n) = M1(n) + M2(n). Тому що C1(n) < C2(n), M1(n) < M2(n),остаточно одержуємо оцінки складності алгоритму Tree Sort за часом:
M(n) = O(n log2 n), C(n) = O(n log2 n),
У загальному випадку, коли n не є ступенем 2, сортуюче дерево будується трохи інакше. "Зайвий" елемент (елемент, для якого немає пари) переноситься на наступний рівень. Легко бачити, що при цьому глибина сортуючого дерева дорівнює [log2 n] + 1. Удосконалення алгоритму II етапу очевидно. Оцінки при цьому змінюють лише мультиплікативні множники. Алгоритм Tree Sort має істотний недолік: для нього потрібно додаткова пам'ять розміру 2n - 1.
2.4Сортування вибором при допомозі дерева – алгоритм Heap Sort
Прямий вибір - повторюваний пошук найменшого елемента серед N елементів, N-1 елементів, N-2 і т.д. Кількість порівнянь при цьому (N2-N)/2. Для підвищення ефективності необхідно залишати після кожного етапу побільше інформації окрім ідентифікації найменшого ключа.
Після N/2 порівнянь можна знайти в кожній парі елементів найменший, після N/4 порівнянь - менший із пари вже вибраних на попередньому кроці і т.д. Виконавши загалом N/2+N/4+...+2+1=N-1 порівнянь, можна побудувати дерево вибору та ідентифікувати його корінь як шуканий найменший елемент. Наприклад
крок I \ / \ / \ / \ /
44 12 06
крок II \ / \ /
12 06
крок III \ /
06
На наступному етапі сортування проводиться рух вздовж віток, які відмічені мінімальними елементом, і вилучення його з дерева шляхом заміни на пустий елемент.
44[]
\ / \ / \ / \ /
44 12 18 []
\ / \ /
12 []
\ /
[]
Далі здійснюється заповнення "дірок" у дереві. На першому рівні залишається "дірка" від вилученого елемента, а на наступних знову вибирається менший із двох сусідніх попереднього рівня. "Дірка" при порівнянні вважається як завгодно великим значенням.
44[]
\ / \ / \ / \ /
44 12 18 67
\ / \ /
12 18
\ /
12
Елемент, що опинився в корені, - знову найменший. Після N таких кроків дерево стане пустим, в ньому будуть лише одні "дірки" (сортування закінчене). На кожному з N етапів виконується log(N) порівнянь. Тому на весь процес впорядкування потрібно порядку N*log(N) операцій плюс N-1 операцій для побудови дерева. Це значно краще ніж N2 для прямих методів і навіть краще ніж N1,2 для алгоритму Шелла. Однак при цьому виникає проблема збереження додаткової інформації. Тому кожен окремий етап в алгоритмі ускладнюється.
Корисно було б, зокрема, позбутися від "дирок", якими вкінці буде заповнене все дерево, і які породжують багато непотрібних порівнянь. Крім того, виникає потреба такої організації даних за принципом дерева, яка б вимагала N одиниць пам’яті, а не 2N-1. Цього вдалося добитися в алгоритмі Heap Sort, який розробив Д. Уілльямс. Він використав спеціальну деревовидну структуру - піраміду.
Піраміда - це означене, тобто задане елементами кореневе бінарне дерево, яке визначається як послідовність ключів a L , a L+1 , ..., a R , для якої справедливі нерівності
![]() та
та ![]() для
для ![]() .(1)
.(1)
Таким чином бінарне дерево сортувань виду
a1
/ \
a2=42a3=06
/ \ / \
a4=55a5=94a6=18a7=12
являє собою піраміду, а елемент a1 буде найменшим в розглядуваній множині : a1=min(a 1 , a 2 , ..., a N).
Припустимо, що є деяка піраміда із заданими елементами a L+1 , ..., a R для певних значень L та R, і потрібно ввести новий елемент x, утворюючи таким чином розширену піраміду a L , a L+1 , ..., a R . В якості вихідної візьмемо піраміду a 1 , a 2 , ..., a 7 із попереднього прикладу і добавимо до неї зліва елемент a 1=44. Нова піраміда отримується так : спочатку x ставиться зверху деревовидної структури, а потім він поступово опускається вниз кожен раз в напрямку меншого з двох прилеглих до нього елементів, а сам цей менший елемент переміщується вгору. Процес просіювання продовжується доти, поки в жодній з прилеглих вершин не буде елемента меншого за нововведеного. В розглядуваному прикладі ключ 44 спочатку поміняється місцями з ключем 06, а потім з 12, і в результаті отримується таке дерево
06
/ \
42
/ \ / \
94 18
Характерно, що такий метод просіювання залишає незмінними умови (1), які визначають піраміду.
Р. Флойд запропонував певний "лаконічний" алгоритм побудови піраміди "на тому ж місці". Вважається, що деяка частина елементів масиву a m , a 2 , ..., a N (m=Ndiv2) вже утворює піраміду - нижній шар відповідного бінарного дерева, для них ніякої впорядкованості не вимагається. Тепер піраміда розширюється вліво; кожен раз добавляється і просіюваннями ставитться у відповідну позицію новий елемент. Ці дії реалізуються проседурою Sift :
Procedure Sift(L, R : integer);
Var
i, j : integer; x : basetype;
Begin
i:=L; j:=2*L; x:=a[L];
if (j<R) and (a[j+1]<a[j]) then j:=j+1;
while (j<=R) and (a[j]<x) do
begin
a[i]:=a[j]; a[j]:=x; i:=j; j:=2*j;
if (j<R) and (a[j+1]<a[j]) then j:=j+1
end
End;
Таким чином, процес формування піраміди із N елементів a 1 , ..., a N "на тому ж місці" є повторюваним виконанням процедури Sift при зміні параметра L=Ndiv2, ..., 1 :
L:=N div 2 +1;
while L>1 do
begin
L:=L-1;
Sift(L, N)
end;
Для ілюстації алгоритму розглянемо попередній варіант масиву :
44 |
44 |
44 |
44 | 42
06
Тут жирним шрифтом виділені добавлювані до піраміди елементи; підкреслені - елементи, з якими проводився обмін.
Для того, щоб отримати не тільки часткове, а і повне впорядкування серед елементів послідовності, потрібно виконати N зсувних етапів. Після кожного проходу на вершину дерева виштовхуватиметься черговий найменший ключ. Знову виникає питання : де зберігати "спливаючі" верхні елементи і чи можна проводити перестановки "на тому ж місці"? Це легко реалізувати, якщо кожен раз брати останню компоненту піраміди - це буде просіюваний ключ x, ховати верхній елемент з попереднього етапу в звільнене позицію, а x зсувати на відповідне місце. Зрозуміло, що після кожного етапу розглядувана піраміда буде скорочуватися на один елемент справа. Таким чином, впорядкування масиву буде здійснено за N-1 прохід :
06 42 12 55 94 18 44 67обмін 67 і 06
67 42 12 55 94 18 44 | 06просіювання 67
12 42 18 55 94 67 44 | 06обмін 44 і 12
44 42 18 55 94 67 | 12 06просіювання 44
18 42 44 55 94 67 | 12 06обмін 67 і 18
67 42 44 55 94 | 18 12 06просіювання 67
42 55 44 67 94 | 18 12 06обмін 94 і 42
94 55 44 67 | 42 18 12 06просіювання 94
44 55 94 67 | 42 18 12 06обмін 67 і 44
67 55 94 | 44 42 18 12 06просіювання 67
55 67 94 | 44 42 18 12 06обмін 94 і 55
94 67 | 55 44 42 18 12 06просіювання 94
67 94 | 55 44 42 18 12 06обмін 94 і 67
94 | 67 55 44 42 18 12 06просіювання 94
94 | 67 55 44 42 18 12 06
Тут жирним шрифтом виділені просіювані по піраміді елементи; підкреслені - елементи, між якими проводився обмін.
Процес сортування описується за допомогою процедури Sift таким чином:
R:=N;
while R>1 do
begin
x:=a[1]; a[1]:=a[R]; a[R]:=x;
R:=R-1;
Sift(1, R)
end;
Як видно з прикладу, отриманий порядок ключів фактично є зворотнім. Це легко виправити, помінявши напрямок відношення порівняння в процедурі Sift на протилежний. Остаточно процедура сортування масиву методом Heap Sort матиме вигляд :
Procedure Heap_Sort;
Var
L, R : integer; x : basetype;
Procedure Sift(L, R : integer);
Var
i, j : integer; x : basetype;
Begin
i:=L; j:=2*L; x:=a[L];
if (j<R) and (a[j]<a[j+1]) then j:=j+1;
while (j<=R) and (x<a[j]) do
begin
a[i]:=a[j]; a[j]:=x; i:=j; j:=2*j;
if (j<R) and (a[j]<a[j+1]) then j:=j+1
end
End;
Begin
L:=N div 2 +1; R:=N;
while L>1 do
begin L:=L-1; Sift(L, N) end;
while R>1 do
begin
x:=a[1]; a[1]:=a[R]; a[R]:=x;
R:=R-1;
Sift(1, R)
end
End;
Аналіз алгоритму Heap Sort. Як вже раніше відмічалося, складність алгоритму по операціях порівняння є величиною порядку O(N*log(N)+N). Кількість переміщень елементів суттєво залежить від стартового розміщення ключів в послідовності.
Однак при початково-впорядкованому масиві не слід чекати максимальної ефективності. Адже об’єм перестановок в цьому випадку є досить великим під час просіювання "важких" елементів після побудови піраміди. Фактично на кожному етапі такого просіювання виконується log(K) перестановок плюс ще N-1 обмін перед просіюванням, де K - кількість елементів в піраміді, в якій проводиться просіювання. Таким чином, в цьому випадку
 .
.
Тому можна вважати, що розглядуваний метод як і по порівняннях так і по перестановках має ефективність порядку O(N*log(N)+N).
2.5 Порівняльна характеристика швидкодії деяких швидких алгоритмів сортування
Щоб порівняти швидкодію певних алгоритмів сортування, зокрема Quick_Sort, Heap_Sort, Shell_Sort, ми створили одновимірний масив із елементів n=50000, типу integer. При цьому розглядалися різні варіанти масиву А(n). А саме, коли вихідний масив А(n) вже є відсортований за зростанням (за спаданням), коли всі члени масиву А(n) рівні, а також, коли елементи масиву генеруються випадковим чином. За отриманими результатами ми подували таблицю, яка дає змогу проаналізувати дані, і виявити кращі алгоритми сортування у різних випадках.
| № | Алгоритм сортування | Сортування відсортованого масиву по зростанню (мс) | Сортування по зростанню відсортованого масиву по спаданню (мс) | Сортування масиву, всі елементи однакові (мс) | Сортування масиву генерованого випадковим чином (мс) |
| 1 | Quick_Sort | 17000 | 11000 | 14 | 25 |
| 2 | Heap_Sort | 40 | 40 | 8 | 55 |
| 3 | Shell_Sort | 40 | 50 | 46 | 77 |
Висновки
Отже, ми розглянули як працюють швидкі алгоритми сортування іь спробували визначити їх складність.
Застосування того чи іншого алгоритму сортування для вирішення конкретної задачі є досить складною проблемою, вирішення якої потребує не лише досконалого володіння саме цим алгоритмом, але й всебічного розглядання того чи іншого алгоритму, тобто визначення усіх його переваг і недоліків.
Звичайно, необхідність застосування саме швидких алгоритмів сортування очевидна. Адже прості алгоритми сортування не дають бажаної ефективності в роботі програми. Але завжди треба пам’ятати й про те, що кожний швидкий алгоритм сортування поряд із своїми перевагами може містити і деякі недоліки.
Так, алгоритм сортування деревом, хоча й працює однаково на всіх входах (так, що його складність в гіршому випадку співпадає зі складністю в середньому), але цей алгоритм має і досить суттєвий недолік: для нього потрібна додаткова пам’ять розміром 2n-1.
Розглядаючи такий швидкий алгоритм сортування, як пірамідальне сортування, можна зазначити, що цей алгоритм ефективніший ніж попередній, адже він сортує "на місці" , тобто він не потребує додаткових масивів. Крім того, цей алгоритм (" з точністю до мультиплікативної константи" (4,74)) оптимальний: його складність співпадає з нижньою оцінкою задачі, тобто за критеріями C(n) та M(n) він має складність O(n log2 n), але містить складний елемент в умові. Тобто, в умові A[left] має бути строго менше ніж x , а A[right] - строго більше за x. Якщо ж замість "строго більше" та "строго менше" поставити знаки, що позначають "більше, або дорівнює" та "менше, або дорівнює", то індекси left і right пробіжать увесь масив і побіжать далі. Вийти з цієї ситуації можна було б шляхом ускладнення умов продовження перегляду, але це б погіршило ефективність програми.
В нашій роботі ми розглянули деякі швидкі алгоритми сортування та їх реалізацію мовою Pascal, виконуючи курсову роботу ми реалізували програмно не лише використання швидких методів сортування, а і прямих, дослідили не лише переваги таких алгоритмів, ефективність їх використання, але й визначили деякі недоліки окремих алгоритмів, що заважають вживати їх для вирішення першої ліпшої задачі сортування. Програма, в якій міститься реалізація та демонстрація наявних прямих методів сортування називається Prjami.pas, а швидкі - Shvud.pas.
Отже, головною задачею, яку має вирішити людина, яка повинна розв’язати задачу сортування – це визначення як позитивних, так і усіх негативних характеристик різних алгоритмів сортування, передбачення кінцевого результату. До того ж , треба враховувати головне – чи , можливо, цю задачу задовольнить один з класичних простих алгоритмів сортування.
Література
1. Абрамов С. А., Зима Е. В. Начала программирования на языке Pascal. - М.: Наука, 1987.
2. Абрамов В. Г. Введение в язык Pascal: Учебное пособие для студентов вузов по специальности Прикладная математика. – М.: Наука, 1988.
3. Власик А.П. Практикум з програмування в середовищі Turbo Pascal. Ч 1.- Рівне: НУВГП, 2005. – 179 с.
4. Джонс Ж., Харроу К. Решение задач в системе Турбо-Паскаль/ Перевод с английского Улановой, Широкого. – М.: Финансы и статистика, 1991.
5. Зуев Е. А. Язык программирования Турбо Паскаль 6.0, 7.0. – М.: Радио и связь, 1993.
6. Кнут Д.Э. Искуство програмирования, том 3. Поиск и сортировка, 3-е изд.: Пер. с англ.: Уч. Пос. – М.:Издательский дом "Вильямс", 2000. – 750 с.
7. Культин Н. Б. Программирование в TurboPascal 7.0 и Delphi. - Санкт- петербург,1999.
8. Львов М. С., Співаковський О. В. Основи алгоритмізації та програмування. Херсон, 1997.
9. Перминов О. Н. Программирование на языке Паскаль. – М.: Радио и связь, 1988.
10. Перминов О. Н. Язык программирования Pascal. – М.: Радио и свіязь,1989.
11. Турбо Паскаль 7.0 Издание 10-е стереотипное. – Санкт-Петербург: "Печатный Двор", 1999.
12. Фаронов В. В. TurboPascal 7.0 . Начальный курс. – М.: "Нолидж", 2000.
13. Turbo Pascal – Издательская група К.: ВНV, 2000.