Курсовая работа: Реализация АВЛ–деревьев через классы объектно–ориентированного программирования
Министерство образования и науки Украины
Запорожская государственная инженерная академия
Кафедра программного обеспечения автоматизированных систем
КУРСОВАЯ РАБОТА
По дисциплине «Объектно – ориентированное программирование »
На тему: «Реализация АВЛ – деревьев через классы объектно – ориентированного программирования»
Выполнил: ст. гр. СП – 07 – 1з Воронько О.А.
Проверил: Попивщий В.И.
Запорожье, 2009г.
ПЛАН
Введение
1. Основные термины
2. Основные операци и с АВЛ - деревьями
3. Алгоритм реализации АВЛ – деревьев через классы объектно – ориентированного программирования
Список литературы
ВВЕДЕНИЕ
Язык программирования С++ является одним из наиболее популярных средств объектно – ориентированного программирования, позволяющим разрабатывать программы, эффективные по объему кода и скорости выполнения. С++ включает большое число операций и типов данных, средства управления вычислительными процессами, механизмы модификации типов данных и методы их обработки и, как следствие, является мощным языком программирования. Он позволяет описывать процессы обработки информации, начиная с уровня отдельных разрядов, видов и адресов памяти, переходя на основе механизмов объектно – ориентированного программирования к близким конкретным предметным областям понятиям.
Первые программы для цифровых вычислительных машин редко превышали объем 1 кбайт. Объемы используемых программ и программных систем измеряются не только десятками килобайтов, но и сотнями мегабайтов. Вместе с тем удельная стоимость создания программ (нормированная объемом программы) до последнего времени менялась мало. Более того, с ростом объема программы удельная стоимость ее создания могла нелинейно возрастать. Поэтому не удивительно, что одним из основных факторов, определяющих развитие технологии программирования, является снижение стоимости проектирования и создания программных продуктов (ПП), или борьба со сложностью программирования.
Другими важнейшими факторами, влияющими на эволюцию методов проектирования и создания ПП, являются:
· изменение архитектур вычислительных средств (ВС) в интересах повышения производительности, надежности и коммуникативности;
· упрощение взаимодействия пользователей с ВС и интеллектуализация ВС.
Действие двух последних факторов, как правило, сопряжено с ростом сложности программного обеспечения ВС. Сложность представляет неотъемлемое свойство программирования и программ, которое проявляется во времени и стоимости создания программ, в объеме или длине текста программы, характеристиках ее логической структуры, задаваемой операторами передачи управления (ветвления, циклы, вызовы подпрограмм и др.).
Можно выделить 5 следующих источников сложности программирования:
1) решаемая задача;
2) язык программирования;
3) среда выполнения программы;
4) технологический процесс коллективной разработки и создания ПП;
5) стремление к универсальности и эффективности алгоритмов и типов данных.
От свойства сложности нельзя избавиться, но можно изменять характеристики его проявления путем управления или организации.
В программировании широко используется фундаментальный принцип управления сложными системами, который известен человеку с глубокой древности – devide et impera (разделяй и властвуй, лат.) и широко им применяется при разработке и проектировании любых сложных технических систем.
В настоящее время объектно – ориентированное программирование (ООП) является доминирующим стилем при создании больших программ.
1. ОСНОВНЫЕ ТЕРМИНЫ
Так исторически сложилось, что у этих деревьев есть два альтернативных названия: АВЛ - деревья и сбалансированные деревья. АВЛ произошло от фамилий изобретателей.
Идеально сбалансированным называется дерево, у которого для каждой вершины выполняется требование: число вершин в левом и правом поддеревьях различается не более, чем на 1. Однако идеальную сбалансированность довольно трудно поддерживать.
В некоторых случаях при добавлении/удалении может потребоваться значительная перестройка дерева, не гарантирующая логарифмической сложности. Поэтому Г.М. Адельсон - Вельский и Е.М. Ландис ввели менее строгое определение сбалансированности и доказали, что при таком определении можно написать программы добавления/удаления, имеющие логарифмическую сложность и сохраняющие дерево сбалансированным.
Дерево считается сбалансированным по АВЛ (в дальнейшем просто «сбалансированным»), если для каждой вершины выполняется требование: высота левого и правого поддеревьев различаются не более, чем на 1. Не всякое сбалансированное дерево идеально сбалансировано, но всякое идеально сбалансированное дерево сбалансировано.
Бинарные деревья поиска предназначены для быстрого доступа к данным. В идеале разумно сбалансированное дерево имеет высоту порядка O(log2n). Однако при некотором стечении обстоятельств дерево может оказаться вырожденным. Тогда высота его будет O(n), и доступ к данным существенно замедлится. Рассмотрим модифицированный класс деревьев, обладающих всеми преимуществами бинарных деревьев поиска и никогда не вырождающихся. Они называются сбалансированными или АВЛ - деревьями. Под сбалансированностью будем понимать то, что для каждого узла дерева высоты обоих его поддеревьев различаются не более чем на 1.
Строго говоря, этот критерий нужно называть АВЛ - сбалансированностью в отличие от идеальной сбалансированности, когда для каждого узла дерева количества узлов в левом и правом поддеревьях различаются не более чем на 1. Здесь мы всегда будем иметь в виду АВЛ - сбалансированность.
Новые методы вставки и удаления в классе АВЛ - деревьев гарантируют, что все узлы останутся сбалансированными по высоте. На рисунках 1 и 2 показаны эквивалентные представления массива АВЛ - деревом и бинарным деревом поиска. Рисунок 1 представляет простой пятиэлементный массив А (A[5] = {1,2,3,4,5}), отсортированный по возрастанию. Рисунок 2 представляет массив B (B[8] = {20, 30, 80, 40, 10, 60, 50, 70}).
Бинарное дерево поиска имеет высоту 5, в то время как высота АВЛ - дерева равна 2. В общем случае высота сбалансированного дерева не превышает O(log2n). Таким образом, АВЛ - дерево является мощной структурой хранения, обеспечивающей быстрый доступ к данным.
Для этого используем подход, при котором поисковое дерево строится отдельно от своих узлов. Сначала разрабатываем класс AVLTreeNode, а затем используем объекты этого типа для конструирования класса AVLTree. Предметом пристального внимания будут методы Insert и Delete.
Они требуют тщательного проектирования, поскольку должны гарантировать, что все узлы нового дерева останутся сбалансированными по высоте.
2. ОСНОВНЫЕ ОПЕРАЦИИ С АВЛ - ДЕРЕВЬЯМИ
Восстановление сбалансированности.
Пусть имеется дерево, сбалансированное всюду, кроме корня, а в корне показатель сбалансированности по модулю равен 2 - м. Такое дерево можно сбалансировать с помощью одного из четырех вращений. При этом высота дерева может уменьшиться на 1. Для восстановления баланса после удаления/добавления вершины надо пройти путь от места удаления/добавления до корня дерева, проводя при необходимости перебалансировку и изменение показателя сбалансированности вершин вдоль пути к корню.
Добавление элемента в сбалансированное дерево.
Алгоритм вставки нового элемента в сбалансированное дерево будет состоять из следующих трех основных шагов:
1. Поиск по дереву.
2. Вставка элемента в место, где закончился поиск, если элемент отсутствует.
3. Восстановление сбалансированности.
1 - ый и 2 - ый шаги необходимы для того, чтобы убедиться в отсутствии элемента в дереве, а также найти такое место вставки, чтобы после вставки дерево осталось упорядоченным.
3 - ий шаг представляет собой обратный проход по пути поиска: от места добавления к корню дерева. По мере продвижения по этому пути корректируются показатели сбалансированности проходимых вершин и производится балансировка там, где это необходимо. Добавление элемента в дерево никогда не требует более одного поворота.
Эффективность сортировки вставкой в АВЛ - дерево.
Ожидаемое число сравнений, необходимых для вставки узла в бинарное дерево поиска, равно O(log2n). Поскольку в дерево вставляется n элементов, средняя эффективность должна быть O(n log2n). Однако в худшем случае, когда исходный список отсортирован в обратном порядке, она составит O(n2). Соответствующее дерево поиска вырождается в связанный список. Покажем, что худший случай требует O(n2) сравнений. Первая вставка требует 0 сравнений. Вторая вставка - двух сравнений (одно с корнем и одно для определения того, в какое поддерево следует вставлять данное значение). Третья вставка требует трех сравнений, 4 - я четырех,..., n - я вставка требует n сравнений. Тогда общее число сравнений равно:
0 + 2 + 3 + ... + n = (1 + 2 + 3 + ... + n) - 1 = n(n + 1) / 2 - 1 = O(n2)
Для каждого узла дерева память должна выделяться динамически, поэтому худший случай не лучше, чем сортировка обменом.
Когда n случайных значений повторно вставляются в бинарное дерево поиска, можно ожидать, что дерево будет относительно сбалансированным. Наилучшим случаем является законченное бинарное дерево. Для этого случая можно оценить верхнюю границу, рассмотрев полное дерево глубиной d. На i-ом уровне (1≤i≤d) имеется 2i узлов. Поскольку для помещения узла на уровень i требуется i+1 сравнение, сортировка на полном дереве требует (i+1) * 2i сравнений для вставки всех элементов на уровень i.
Если вспомнить, что n = 2(d+1) - 1, то верхняя граница меры эффективности выражается следующим неравенством:
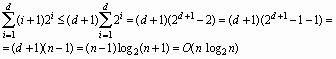
Таким образом, эффективность алгоритма в лучшем случае составит O(n log2n).
Удаление элемента из сбалансированного дерева.
Алгоритм удаления элемента из сбалансированного дерева будет выглядеть так:
1. Поиск по дереву.
2. Удаление элемента из дерева.
3. Восстановление сбалансированности дерева (обратный проход).
1 - ый и 2 - ый шаги необходимы, чтобы найти в дереве вершину, которая должна быть удалена.
3 - ий шаг представляет собой обратный проход от места, из которого взят элемент для замены удаляемого, или от места, из которого удален элемент, если в замене не было необходимости.
Операция удаления может потребовать перебалансировки всех вершин вдоль обратного пути к корню дерева, то есть порядка log(N) вершин.
Анализ операций над сбалансированным деревом.
Понятно, что в случае полного двоичного дерева мы получим сложность T(log(n)) (на каждом шаге размер дерева поиска будет сокращаться вдвое). Рассмотрим минимальное сбалансированное дерево (худший случай). Таким будет дерево, у которого для каждой вершины высота левого и правого поддеревьев различаются на 1. Для такого дерева можно записать следующую рекуррентную формулу для числа вершин (h – высота дерева):
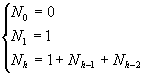
Покажем, что h<log2(Nh). Для этого необходимо и достаточно показать, что 2h>Nh. Докажем последнее методом математической индукции.а) h=0: 20>N0=0; б) h=1: 21>N1=1; в) h>1: Пусть 2h-2>Nh-2 и 2h-1>Nh-1. Тогда 2h-2+2h-1>Nh-2+ Nh-1. И далее получаем 2h>1+2h-2+2h-1>1+Nh-2+ Nh-1=Nh, что и требовалось доказать.
Таким образом алгоритмы поиска/добавления/удаления элементов в сбалансированном дереве имеют сложность T(log(n)). Г.М. Адельсон -Вельский и Е.М. Ландис доказали теорему, согласно которой высота сбалансированного дерева никогда не превысит высоту идеально сбалансированного дерева более, чем на 45%.
Основные узлы АВЛ - деревьев.
АВЛ - деревья имеют структуру, похожую на бинарные деревья поиска. Все операции идентичны описанным для бинарных деревьев, за исключением методов Insert и Delete, которые должны постоянно отслеживать соотношение высот левого и правого поддеревьев узла. Для сохранения этой информации расширяем определение объекта TreeNode, включив поле balanceFactor (показатель сбалансированности), которое содержит разность высот правого и левого поддеревьев.
Left data balanceFactor right
AVLTreeNode
balanceFactor = height(right subtree) - height(left subtree)
Если balanceFactor отрицателен, то узел «перевешивает влево», так как высота левого поддерева больше, чем высота правого поддерева. При положительном balanceFactor узел «перевешивает вправо». Сбалансированный по высоте узел имеет balanceFactor = 0.
В АВЛ - дереве показатель сбалансированности должен быть в диапазоне [-1, 1]. На рисунке 3 изображены АВЛ - деревья с пометками -1, 0 и +1 на каждом узле, показывающими относительный размер левого и правого поддеревьев.
-1: Высота левого поддерева на 1 больше высоты правого поддерева.
0: Высоты обоих поддеревьев одинаковы.
+1: Высота правого поддерева на 1 больше высоты левого поддерева.
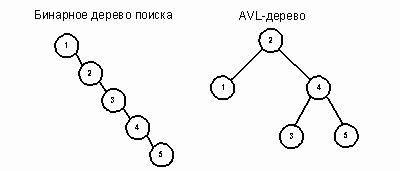
Рис. 1.
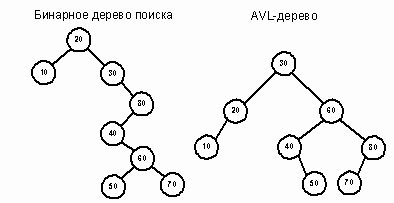
Рис. 2.
Используя свойства наследования, можно образовать класс AVLTreeNode на базе класса TreeNode. Объект типа AVLTreeNode наследует поля из класса TreeNode и добавляет к ним поле balanceFactor. Данные - члены left и right класса TreeNode являются защищенными, поэтому AVLTreeNode или другие производные классы имеют к ним доступ.
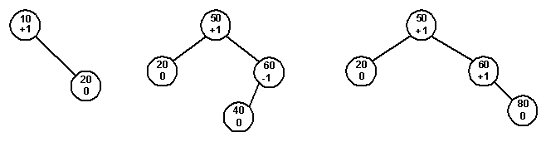
Рис. 3.
Спецификация класса AVLTreeNode.
Объявление:
// наследник класса TreeNode
template <class T>
class AVLTreeNode: public TreeNode<T>
{
private:
// дополнительный член класса balanceFactor используется методами класса AVLTree и позволяет избегать "перевешивания" узлов
int balanceFactor;
AVLTreeNode<T>* & Left(void);
AVLTreeNode<T>* & Right(void);
public:
// конструктор
AVLTreeNode(const T& item, AVLTreeNode<T> *lptr = NULL,
AVLTreeNode<T> *rptr = NULL, int balfac = 0);
// возвратить левый/правый указатель узла типа TreeNode преобразовав его к типу AVLTreeNode
AVLTreeNode<T> *Left(void) const;
AVLTreeNode<T> *Right(void) const;
// метод для доступа к новому полю данных
int GetBalanceFactor(void);
// методы класса AVLTree должны иметь доступ к Left и Right
friend class AVLTree<T>;
};
Описание:
Элемент данных balanceFactor является скрытым, так как обновлять его должны только выравнивающие баланс операции вставки и удаления. Доступ к полям - указателям осуществляется с помощью методов Left и Right. Новые определения для этих методов обязательны, поскольку они возвращают указатель на структуру AVLTreeNode.
Поскольку класс AVLTree образован на базе класса BinSTree, будем использовать деструктор базового класса и метод ClearList. Эти методы удаляют узлы с помощью оператора delete. В каждом случае указатель ссылается на объект типа AVLTreeNode, а не TreeNode. Так как деструктор базового класса TreeNode виртуальный, при вызове delete используется динамическое связывание и удаляется объект типа AVLTreeNode.
Пример:
Эта функция создает АВЛ - дерево, изображенное на рисунке 4. Каждому узлу присваивается показатель сбалансированности.
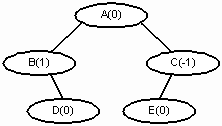
Рис. 4.
AVLTreeNode<char> *root; // корень АВЛ - дерева
void MakeAVLCharTree(AVLTreeNode<char>* &root)
{
AVLTreeNode<char> *a, *b, *c, *d, *e;
e = new AVLTreeNode<char>('E', NULL, NULL, 0);
d = new AVLTreeNode<char>('D', NULL, NULL, 0);
c = new AVLTreeNode<char>('C', e, NULL, -1);
b = new AVLTreeNode<char>('B', NULL, d, 1);
a = new AVLTreeNode<char>('A', b, c, 0);
root = a;
}
Реализация класса AVLTreeNode.
Конструктор класса AVLTreeNode вызывает конструктор базового класса и инициализирует balanceFactor.
// Конструктор инициализирует balanceFactor и базовый класс
// Начальные значения полей указателей по умолчанию, равные NULL
// инициализируют узел как лист
template <class T>
AVLTreeNode<T>::AVLTreeNode (const T& item,
AVLTreeNode<T> *lptr, AVLTreeNode<T> *rptr, int balfac):
TreeNode<T>(item, lptr, rptr), balanceFactor(balfac)
{}
Методы Left и Right в классе AVLTreeNode упрощают доступ к полям данных. При попытке обратиться к левому сыну с помощью метода Left базового класса возвращается указатель на объект типа TreeNode. Чтобы получить указатель на узел АВЛ - дерева, требуется преобразование типов.
Например:
AVLTreeNode<T> *p, *q;
q = p->Left(); // недопустимая операция
q = (AVLTreeNode<T> *)p->Left(); // необходимое приведение типа
Во избежание постоянного преобразования типа указателей мы определяем методы Left и Right для класса AVLTreeNode, возвращающие указатели на объекты типа AVLTreeNode.
template <class T>.
AVLTreeNode<T>* AVLTreeNode::Left(void)
{
return ((AVLTreeNode<T> *)left;
}
Класс AVLTree.
АВЛ - дерево представляет собой списковую структуру, похожую на бинарное дерево поиска, с одним дополнительным условием: дерево должно оставаться сбалансированным по высоте после каждой операции вставки или удаления. Поскольку АВЛ - дерево является расширенным бинарным деревом поиска, класс AVLTree строится на базе класса BinSTree и является его наследником.
Для выполнения АВЛ - условий следует изменить методы Insert и Delete. Кроме того, в производном классе определяются конструктор копирования и перегруженный оператор присвоения, так как мы строим дерево с большей узловой структурой.
Спецификация класса AVLTree.
Объявление:
// Значения показателя сбалансированности узла
const int leftheavy = - 1;
const int balanced = 0;
const int rightheavy = 1;
template <class T>
class AVLTree: public BinSTree<T>
{
private:
// выделение памяти
AVLTreeNode<T> *GetAVLTreeNode(const T& item,
AVLTreeNode<T> *lptr, AVLTreeNode<T> *rptr);
// используется конструктором копирования и оператором присваивания
AVLTreeNode<T> *CopyTree(AVLTreeNode<T> *t);
// используется методами Insert и Delete для восстановления АВЛ - условий после операций вставки/удаления
void SingleRotateLeft (AVLTreeNode<T>* &p);
void SingleRotateRight (AVLTreeNode<T>* &p);
void DoubleRotateLeft (AVLTreeNode<T>* &p);
void DoubleRotateRight (AVLTreeNode<T>* &p);
void UpdateLeftTree (AVLTreeNode<T>* &tree,
int &reviseBalanceFactor);
void UpdateRightTree (AVLTreeNode<T>* &tree,
int &reviseBalanceFactor);
// специальные версии методов Insert и Delete
void AVLInsert(AVLTreeNode<T>* &tree,
AVLTreeNode<T>* newNode, int &reviseBalanceFactor);
void AVLDelete(AVLTreeNode<T>* &tree,
AVLTreeNode<T>* newNode, int &reviseBalanceFactor);
public:
// конструкторы
AVLTree(void);
AVLTree(const AVLTree<T>& tree);
// оператор присваивания
AVLTree<T>& operator= (const AVLTree<T>& tree);
// стандартные методы обработки списков
virtual void Insert(const T& item);
virtual void Delete(const T& item);
};
Описание:
Константы leftheavy, balanced и rightheavy используются в операциях вставки/удаления для описания показателя сбалансированности узла. Метод GetAVLTreeNode управляет выделением памяти для экземпляра класса. По умолчанию balanceFactor нового узла равен нулю.
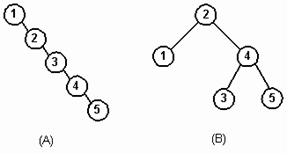
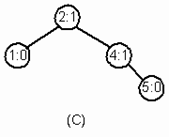
Рис. 5.
В этом классе заново определяется функция CopyTree для использования с конструктором копирования и перегруженным оператором присвоения. Несмотря на то, что алгоритм идентичен алгоритму для функции CopyTree класса BinSTree, новая версия корректно создает расширенные объекты типа AVLTreeNode при построении нового дерева.
Функции AVLInsert и AVLDelete реализуют методы Insert и Delete, соответственно. Они используют скрытые методы наподобие SingleRotateLeft. Открытые методы Insert и Delete объявлены виртуальными и подменяют соответствующие функции базового класса. Остальные операции наследуются от класса BinSTree.
Пример:
Код, приведенный ниже, создает деревья, приведенные на рисунке 5. После удаления из АВЛ - дерева (В) элемента 3 АВЛ - дерево принимает вид, изображенный на рисунке 5 (С). Цифра после двоеточия означает фактор сбалансированности.
AVLTree<int> avltree; // AVLTree - список целых чисел
BinSTree<int> bintree; // BinSTree - список целых чисел
for (int i=1; i<=5; i++)
{
bintree.Insert(i); // создать дерево А
avltree.Insert(i); // создать дерево В
}
avltree.Delete(3); // удалить 3 из АВЛ - дерева
// дерево (С) есть дерево (В) без удаленного узла 3.
Распределение памяти для AVLTree.
Класс AVLTree образован от класса BinSTree и наследует большинство его операций. Для создания расширенных объектов типа AVLTreeNode мы разработали отдельные методы выделения памяти и копирования.
// разместить в памяти объект типа AVLTreeNode, прервать программу если во время выделения памяти произошла ошибка
template <class T>
AVLTreeNode<T> *AVLTree<T>::GetAVLTreeNode(const T& item,
AVLTreeNode<T> *lptr, AVLTreeNode<T> *rptr)
{
AVLTreeNode<T> *p;
p = new AVLTreeNode<T> (item, lptr, rptr);
if (p == NULL)
{
cerr << "Ошибка выделения памяти!" << endl;
exit(1);
}
return p;
}
Для удаления узлов АВЛ - дерева достаточно методов базового класса. Метод DeleteTree из класса BinSTree задействует виртуальный деструктор класса TreeNode.
Метод Insert класса AVLTree.
Преимущество АВЛ - деревьев состоит в их сбалансированности, которая поддерживается соответствующими алгоритмами вставки/удаления. Опишем метод Insert для класса AVLTree. При реализации метода Insert для запоминания элемента используется рекурсивная функция AVLInsert. Сначала приведем код метода Insert на С++, а затем сосредоточим внимание на рекурсивном методе AVLInsert, реализующем алгоритм Адельсона - Вельского и Ландиса.
template <class T>
void AVLTree<T>::Insert(const T& item)
{
// объявить указатель АВЛ - дерева, используя метод базового класса GetRoot
// произвести приведение типов для указателей
AVLTreeNode<T> *treeRoot = (AVLTreeNode<T> *)GetRoot(),
*newNode;
// флаг, используемый функцией AVLInsert для перебалансировки узлов
int reviseBalanceFactor = 0;
// создать новый узел АВЛ - дерева с нулевыми полями указателей
newNode = GetAVLTreeNode(item, NULL, NULL);
// вызвать рекурсивную процедуру для фактической вставки элемента
AVLInsert(treeRoot, newNode, reviseBalancefactor);
// присвоить новые значения элементам данных базового класса
root = treeRoot;
current = newNode;
size++;
}
Ядром алгоритма вставки является рекурсивный метод AVLInsert. Как и его аналог в классе BinSTree, этот метод осуществляет прохождение левого поддерева, если item меньше данного узла, и правого поддерева, если item больше или равен данному узлу. При сканировании левого или правого поддерева некоторого узла анализируется флаг revisebalanceFactor, который является признаком изменения любого параметра balanceFactor в поддереве. Если он установлен, то нужно проверить, сохранилась ли АВЛ - сбалансированность всего дерева.
Если в результате вставки нового узла она оказалась нарушенной, то мы обязаны восстановить равновесие.
Алгоритм АВЛ – вставки
Процесс вставки почти такой же, что и для бинарного дерева поиска. Осуществляется рекурсивный спуск по левым и правым сыновьям, пока не встретится пустое поддерево, а затем производится пробная вставка нового узла в этом месте. В течение этого процесса мы посещаем каждый узел на пути поиска от корневого к новому элементу. Поскольку процесс рекурсивный, обработка узлов ведется в обратном порядке. При этом показатель сбалансированности родительского узла можно скорректировать после изучения эффекта от добавления нового элемента в одно из поддеревьев. Необходимость корректировки определяется для каждого узла, входящего в поисковый маршрут. Есть три возможных ситуации. В двух первых случаях узел сохраняет сбалансированность и реорганизация поддеревьев не требуется. Нужно лишь скорректировать показатель сбалансированности данного узла. В третьем случае разбалансировка дерева требует одинарного или двойного поворотов узлов.
Случай 1. Узел на поисковом маршруте изначально является сбалансированным (balanceFactor = 0). После вставки в поддерево нового элемента узел стал перевешивать влево или вправо в зависимости от того, в какое поддерево была произведена вставка.
Если элемент вставлен в левое поддерево, показателю сбалансированности присваивается -1, а если в правое, то 1. Например, на пути 40 - 50 - 60 каждый узел сбалансирован. После вставки узла 55 показатели сбалансированности изменяются (рис. 6).
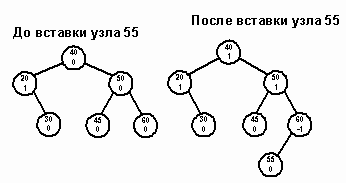
Рис. 6.
Случай 2. Одно из поддеревьев узла перевешивает, и новый узел вставляется в более легкое поддерево. Узел становится сбалансированным. Сравните, например, состояния дерева до и после вставки узла 55 (рис. 7).
Случай 3. Одно из поддеревьев узла перевешивает, и новый узел помещается в более тяжелое поддерево. Тем самым нарушается условие сбалансированности, так как balanceFactor выходит за пределы -1..1. Чтобы восстановить равновесие, нужно выполнить поворот.
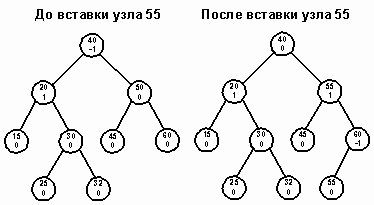
Рис. 7.
Рассмотрим пример:
Предположим, что дерево разбалансировалось слева и мы восстанавливаем равновесие, вызывая одну из функций поворота вправо. Разбалансировка справа влечет за собой симметричные действия. Сказанное иллюстрируется рисунком 8.
Метод AVLInsert.
Продвигаясь вдоль некоторого пути для вставки нового узла, рекурсивный метод AVLInsert распознает все три указанных выше случая корректировки. При нарушении условия сбалансированности восстановление равновесия осуществляется с помощью функций UpdateLeftTree и UpdateRightTree.
template <class T>
void AVLTree<T>::AVLInsert(AVLTreeNode<T>* &tree,
AVLTreeNode<T>* newNode, int &reviseBalanceFactor)
{
// флаг "Показатель сбалансированности был изменен"
int rebalanceCurrNode;
// встретилось пустое поддерево, пора вставлять новый узел
if (tree == NULL)
{
// вставить новый узел
tree = newNode;
// объявить новый узел сбалансированным
tree->balanceFactor = balanced;
// сообщить об изменении показателя сбалансированности
reviseBalanceFactor = 1;
}
// рекурсивно спускаться по левому поддереву, если новый узел меньше текущего
else if (newNode->data < tree->data)
{
AVLInsert(tree->Left(), newNode, rebalanceCurrNode);
// проверить, нужно ли корректировать balanceFactor
if (rebalanceCurrNode)
{
// вставка слева от узла, перевешивающего влево. будет нарушено
// условие сбалансированности; выполнить поворот (случай 3)
if (tree->balanceFactor == leftheavy)
UpdateLeftTree(tree, reviseBalanceFactor);
// вставка слева от сбалансированного узла.
// узел станет перевешивать влево (случай 1)
else if (tree->balanceFactor == balanced)
{
tree->balanceFactor = leftheavy;
reviseBalanceFactor = 1;
}
// вставка слева от узла, перевешивающего вправо
// узел станет сбалансированным (случай 2)
else
{
tree->balanceFactor = balanced;
reviseBalanceFactor = 0;
}
}
Else
// перебалансировка не требуется. не опрашивать предыдущие узлы
reviseBalanceFactor = 0;
}
// иначе рекурсивно спускаться по правому поддереву
else if (newNode->data < tree->data)
{
AVLInsert(tree->Right(), newNode, rebalanceCurrNode);
// проверить, нужно ли корректировать balanceFactor
if (rebalanceCurrNode)
{
// вставка справа от узла, перевешивающего вправо. будет нарушено
// условие сбалансированности; выполнить поворот (случай 3)
if (tree->balanceFactor == rightheavy)
UpdateRightTree(tree, reviseBalanceFactor);
// вставка справа от сбалансированного узла
// узел станет перевешивать вправо (случай 1)
else if (tree->balanceFactor == balanced)
{
tree->balanceFactor = rightheavy;
reviseBalanceFactor = 1;
}
// вставка справа от узла, перевешивающего влево
// узел станет сбалансированным (случай 2)
else
{
tree->balanceFactor = balanced;
reviseBalanceFactor = 0;
}
}
else
// перебалансировка не требуется. не опрашивать предыдущие узлы
reviseBalanceFactor = 0;
}
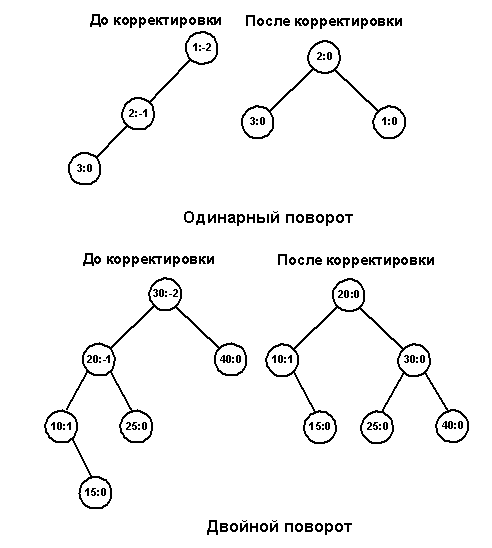
Рис. 8.
Метод AVLInsert распознает случай 3, когда нарушается АВЛ - условие. Для выполнения перебалансировки используются методы UpdateLeftTree и UpdateRightTree. Они выполняют одинарный или двойной поворот для уравновешивания узла, а затем сбрасывают флаг reviseBalanceFactor. Перед тем, как обсудить специфические детали поворотов, приведем код функции UpdateLeftTree.
template <class T>
void AVLTree<T>::UpdateLeftTree(AVLTreeNode<T>* &p,
int reviseBalanceFactor)
{
AVLTreeNode<T> *lc;
lc = p->Left();
// перевешивает левое поддерево?
if (lc->balanceFactor == leftheavy)
{
SingleRotateRight(p); // однократный поворот
reviseBalanceFactor = 0;
}
// перевешивает правое поддерево?
else if (lc->balanceFactor == rightheavy)
{
// выполнить двойной поворот
DoubleRotateRight(p);
// теперь корень уравновешен
reviseBalanceFactor = 0;
}
Вращения (Повороты) АВЛ - деревьев.
При операциях добавления и удаления может произойти нарушение сбалансированности дерева. В этом случае потребуются некоторые преобразования, не нарушающие упорядоченности дерева и способствующие лучшей сбалансированности.
Рассмотрим такие преобразования.
В каждой вершине дерева помимо значения элемента будем хранить показатель сбалансированности в данной вершине. Показатель сбалансированности - разница между высотами правого и левого поддеревьев.
PTree = ^TTree;
TTree = record
Item: T; {элемент дерева}
Left, Right: PTree; {указатели на поддеревья}
Balance: ShortInt; {показатель сбалансированности}
end;
В сбалансированном дереве показатели сбалансированности всех вершин лежат в пределах от -1 до 1. При операциях добавления/удаления могут появляться вершины с показателями сбалансированности -2 и 2.
Малое левое вращение.
Пусть показатель сбалансированности вершины, в которой произошло нарушение баланса, равен -2, а показатель сбалансированности корня левого поддерева равен -1. Тогда восстановить сбалансированность такого поддерева можно следующим преобразованием, называемым малым левым вращением (рис. 9.):
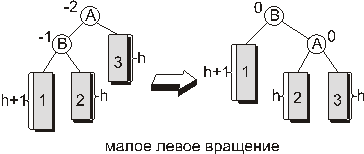
Рис. 9.
На приведенном рисунке прямоугольниками обозначены поддеревья. Рядом с поддеревьями указана их высота. Поддеревья помечены арабскими цифрами. Кружочками обозначены вершины. Цифра рядом с вершиной - показатель сбалансированности в данной вершине. Буква внутри кружка - условное обозначение вершины. Как видно из рисунка после малого левого вращения показатель сбалансированности вершины, в которой было нарушение баланса, становится равным нулю.
Малое правое вращение.
В случае, когда показатель сбалансированности вершины, в которой произошло нарушение баланса, равен 2, а показатель сбалансированности корня правого поддерева равен 1, восстановить сбалансированность в вершине можно с помощью преобразования, называемого малым правым вращением. Это вращение симметрично малому левому и схематично изображено на рисунке 10:
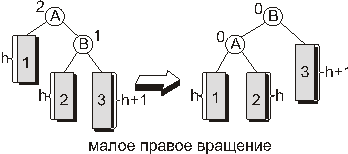
Рис. 10.
Большое левое вращение.
Несколько сложнее случай, когда показатель сбалансированности в вершине, в которой произошло нарушение баланса равен -2, а показатель сбалансированности в корне левого поддерева равен 1 или 0. В этом случае применяется преобразование, называемое большим левым вращением. Как видно из рисунка 11 здесь во вращении участвуют три вершины, а не две как в случае малых вращений.
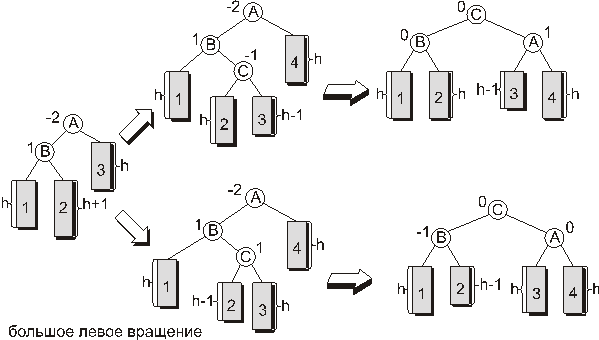
Рис. 11.
Большое правое вращение.
Большое правое вращение применяется, когда показатель сбалансированности вершины, в которой произошло нарушение баланса, равен 2, а показатель сбалансированности корня правого поддерева равен -1 или 0. Большое правое вращение симметрично большому левому и схематично изображено на рисунке 12:
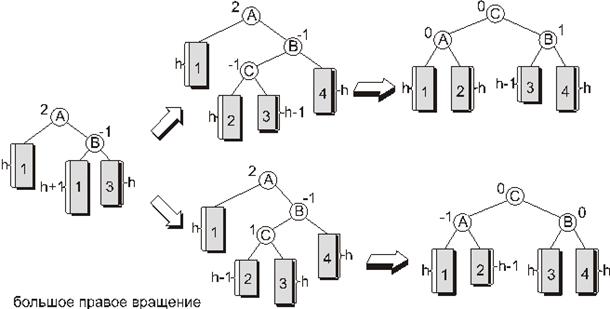
Рис. 12.
Повороты необходимы, когда родительский узел P становится разбалансированным. Одинарный поворот вправо (single right rotation) происходит тогда, когда родительский узел P и его левый сын LC начинают перевешивать влево после вставки узла в позицию X. В результате такого поворота LC замещает своего родителя, который становится правым сыном. Бывшее правое поддерево узла LC (ST) присоединяется к P в качестве левого поддерева. Это сохраняет упорядоченность, так как узлы в ST больше или равны узлу LC, но меньше узла P. Поворот уравновешивает как родителя, так и его левого сына (рис. 13).
// выполнить поворот по часовой стрелке вокруг узла p
// сделать lc новой точкой вращения
template <class T>
void AVLTree<T>::SingleRotateRight (AVLTreeNode<T>* &p)
{
// левое, перевешивающее поддерево узла p
AVLTreeNode<T> *lc;
// назначить lc левым поддеревом
lc = p->Left();
// скорректировать показатель сбалансированности для родительского узла и его левого сына
p->balanceFactor = balanced;
lc->balanceFactor = balanced;
// правое поддерево узла lc в любом случае должно оставаться справа от lc, выполнить это условие, сделав st левым поддеревом узла p
p->Left() = lc->Right();
// переместить p в правое поддерево узла lc
// сделать lc новой точкой вращения
lc->Right() = p;
p = lc;
}
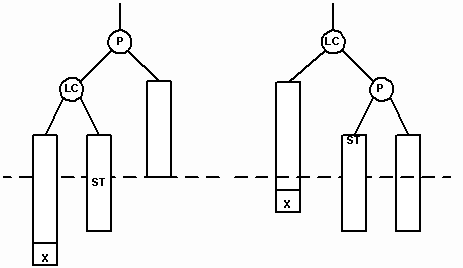
Рис. 13
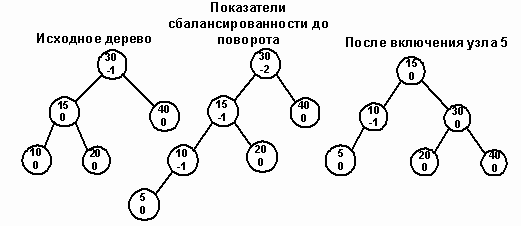
Рис. 14.
Попытка вставить узел 5 в изображенное на рисунке 14 АВЛ - дерево нарушает АВЛ - условие для узла 30. Одновременно левое поддерево узла 15 (LC) становится перегруженным.
Для переупорядочения узлов вызывается процедура SingleRotateRight. В результате родительский узел (30) становится сбалансированным, а узел 10 перевешивающим влево. Двойной поворот вправо (double right rotation) нужен тогда, когда родительский узел (P) становится перевешивающим влево, а его левый сын (LC) перевешивающим вправо. NP – корень правого перевешивающего поддерева узла LC. Тогда в результате поворота узел NP замещает родительский узел. На рисунках 15 и 16 показаны случаи вставки нового узла в качестве сына узла NP. В обоих случаях NP становится родительским узлом, а бывший родитель P становится правым сыном NP.
На рисунке 15 мы видим сдвиг узла X1, после того как он был вставлен в левое поддерево узла NP. На рисунке 16 изображено перемещение узла X2 после его вставки в правое поддерево NP.
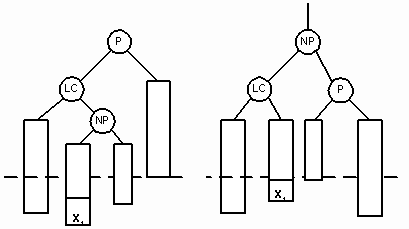
Рис. 15.
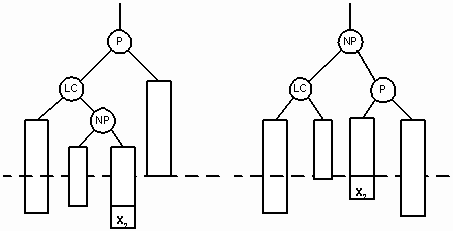
Рис. 16
// двойной поворот вправо вокруг узла p
template <class T>
void AVLTree<T>::DoubleRotateRight (AVLTreeNode<T>* &p)
{
// два поддерева, подлежащих повороту
AVLTreeNode<T> *lc, *np;
// узел lc <= узел np < узел p
lc = p->Left(); // левый сын узла p
np = lc->Right(); // правый сын узла lc
// обновить показатели сбалансированности в узлах p, lc и np
if (np->balanceFactor == rightheavy)
{
p->balanceFactor = balanced;
lc->balanceFactor = rightheavy;
}
else
{
p->balanceFactor = rightheavy;
lc->balanceFactor = balanced;
}
np->balanceFactor = balanced;
// перед тем как заменить родительский узел p, следует отсоединить его от старых детей и присоединить к новым
lc->Right() = np->Left();
np->Left() = lc;
p->Left() = np->Right();
np->Right() = p;
p = np;
}
Двойной поворот иллюстрируется на дереве, изображенном на рисунке 17. Попытка вставить узел 25 разбалансирует корневой узел 50. В этом случае узел 20 (LC) приобретает слишком высокое правое поддерево и требуется двойной поворот.
Новым родительским узлом (NP) становится узел 40. Старый родительский узел становится его правым сыном и присоединяет к себе узел 45, который также переходит с левой стороны дерева.
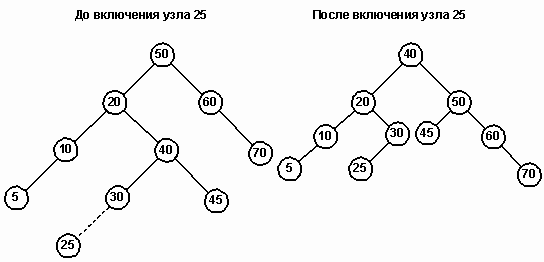
Рис. 17.
Оценка сбалансированных АВЛ - деревьев.
Обоснованность применения АВЛ - деревьев неоднозначна, поскольку они требуют дополнительных затрат на поддержание сбалансированности при вставке или удалении узлов. Если в дереве постоянно происходят вставки и удаления элементов, эти операции могут значительно снизить быстродействие.
С другой стороны, если ваши данные превращают бинарное дерево поиска в вырожденное, вы теряете поисковую эффективность и вынуждены использовать АВЛ - дерево. В большинстве случаев в программах используются алгоритмы, когда сначала заполняется список, а потом производится поиск по этому списку с небольшим количеством изменений. Поэтому на практике использование АВЛ - деревьев предпочтительно.
Для АВЛ - дерева не существует наихудшего случая, так как оно является почти полным бинарным деревом. Сложность операции поиска составляет O(log2n). Опыт показывает, что повороты требуются примерно в половине случаев вставок и удалений. Сложность балансировки обусловливает применение АВЛ - деревьев только там, где поиск является доминирующей операцией.
Оценка производительности АВЛ – деревьев.
Эта программа сравнивает сбалансированное и обычное бинарные деревья поиска, каждое из которых содержит N случайных чисел. Исходные данные для этих деревьев берутся из единого массива. Для каждого элемента массива осуществляется его поиск в обоих деревьях. Длины поисковых путей суммируются, а затем подсчитывается средняя длина поиска по каждому дереву. Программа прогоняется на 1000- и на 10000-элементном массивах.
Обратите внимание, что на случайных данных поисковые характеристики АВЛ - дерева несколько лучше. В самом худшем случае вырожденное дерево поиска, содержащее 1000 элементов, имеет среднюю глубину 500, в то время как средняя глубина АВЛ - дерева всегда равна 9.
#include <iostream.h>
#include "bstree.h"
#include "avltree.h"
#include "random.h"
// загрузить из массива числа в бинарное поисковое дерево и АВЛ – дерево
void SetupLists(BinSTree<int> &Tree1, AVLTree<int> &Tree2, int A[], int n)
{
int i;
RandomNumber rnd;
// запомнить случайное число в массиве А, а также вставить его в бинарное дерево поиска и в АВЛ - дерево
for (i=0; i<n; i++)
{
A[i] = rnd.Random(1000);
Tree1.Insert(A[i]);
Tree2.Insert(A[i]);
}
// поиск элемента item в дереве t
// при этом накапливается суммарная длина поиска
template <class T>
void PathLength(TreeNode<T> *t, long &totallength, int item)
{
// возврат, если элемент найден или отсутствует в списке
if (t == NULL || t->data == item)
return;
else
{
// перейти на следующий уровень, увеличить суммарную длину пути поиска
totallength++;
if (item < t->data)
PathLength(t->Left(), totallength, item);
else
PathLength(t->Right(), totallength, item);
}
void main(void);
{
// переменные для деревьев и массива
BinSTree<int> binTree;
AVLTree<int> avlTree;
int *A;
// суммарные длины поисковых путей элементов массива в бинарном дереве поиска и в АВЛ - дереве
long totalLengthBintree = 0, totalLengthAVLTree = 0;
int n, i;
cout << "Сколько узлов на дереве? ";
cin >> n;
// загрузить случайными числами массив и оба дерева
SetupLists(binTree, avlTree, A, n);
for (i=0; i<n; i++)
{
PathLength(binTree.GetRoot(), totalLengthBintree, A[i]);
PathLength((TreeNode<int> *)avlTree.getRoot(),
totalLengthAVLTree, A[i]);
}
cout << "Средняя длина поиска для бинарного дерева = "
<< float(totalLengthBintree)/n << endl;
cout << "Средняя длина поиска для сбалансированного дерева = "
<< float(totalLengthAVLTree)/n << endl;
}
Прогон 1:Сколько узлов на дереве? 1000
Средняя длина поиска для бинарного дерева = 10.256.
Средняя длина поиска для сбалансированного дерева = 7.901.
Прогон 2:Сколько узлов на дереве? 10000
Средняя длина поиска для бинарного дерева = 12.2822.
Средняя длина поиска для сбалансированного дерева = 8.5632.
Итераторы АВЛ - деревьев.
Сканирование узлов дерева более сложно, чем сканирование массивов и последовательных списков, так как дерево является нелинейной структурой и существует несколько способов прохождения дерева. Проблема каждого из них состоит в том, что до завершения рекурсивного процесса из него невозможно выйти. Нельзя остановить сканирование, проверить содержимое узла, выполнить какие-нибудь операции с данными, а затем вновь продолжить сканирование со следующего узла дерева.
Используя же итератор, клиент получает средство сканирования узлов дерева, как если бы они представляли собой линейный список, без обременительных деталей алгоритмов прохождения, лежащих в основе процесса. Наш класс использует класс Stack и наследуется от базового класса итератора. Поэтому сначала опишем класс Stack и базовый класс итератора.
Спецификация класса Stack.
Объявление:
#include <iostreani.h>
#include <stdlib.h>
const int MaxStackSize = 50;
class Stack
{
private:
DataType stacklist[MaxStackSize];
int top;
public:
// конструктор; инициализирует вершину
Stack(void);
// операции модификации стека
void Push(const DataType& item);
DataType Pop(void);
void ClearStack(void);
// доступ к стеку
DataType Peek(void) const;
// методы проверки состояния стека
int StackEmpty(void) const;
int StackFull(void) const; // для реализации, основанной на массиве
};
Описание:
Данные в стеке имеют тип DataType, который должен определяться с использованием оператора typedef. Пользователь должен проверять, полный ли стек, перед попыткой поместить в него элемент и проверять, не пустой ли стек, перед извлечением данных из него. Если предусловия для операции push или pop не удовлетворяются, печатается сообщение об ошибке и программа завершается. StackEmpty возвращает TRUE, если стек пустой, и FALSE - в противном случае. Используйте StackEmpty, чтобы определить, может ли выполняться операция Pop.
StackFull возвращает TRUE, если стек полный, и FALSE - в противном случае. Используйте StackFull, чтобы определить, может ли выполняться операция Push. ClearStack делает стек пустым, устанавливая top = -1. Этот метод позволяет использовать стек для других целей.
Реализация класса Stack.
Конструктор Stack присваивает индексу top значение -1, что эквивалентно условию пустого стека.
//инициализация вершины стека
Stack::Stack (void) : top(-l)
{ }
Операции стека.
Две основные операции стека вставляют (Push) и удаляют (Pop) элемент из стека. Класс содержит функцию Peek, позволяющую получать данные элемента, находящегося в вершине стека, не удаляя в действительности этот элемент. При помещении элемента в стек, top увеличивается на 1, и новый элемент вставляется в конец массива stacklist. Попытка добавить элемент в полный стек приведет к сообщению об ошибке и завершению программы.
// поместить элемент в стек
void Stack::Push (const DataTypes item)
{
// если стек полный, завершить выполнение программы
if (top == MaxStackSize-1)
{
cerr << "Переполнение стека!" << endl;
exit(l);
}
// увеличить индекс top и копировать item в массив stacklist
top++;
stacklist[top] = item;
}
Операция Pop извлекает элемент из стека, копируя сначала значение из вершины стека в локальную переменную temp и затем увеличивая top на 1. Переменная temp становится возвращаемым значением. Попытка извлечь элемент из пустого стека приводит к сообщению об ошибке и завершению программы.
// взять элемент из стека
DataType Stack::Pop (void)
DataType temp;
// стек пуст, завершить программу
if (top == -1)
{
cerr << "Попытка обращения к пустому стеку! " << end.1;
exit(1);
}
// считать элемент в вершине стека
temp = stacklist[top];
// уменьшить top и возвратить значение из вершины стека
top--;
return temp;
}
Операция Peek в основном дублирует определение Pop с единственным важным исключением. Индекс top не уменьшается, оставляя стек нетронутым.
// возвратить данные в вершине стека
DataType Stack::Peek (void) const
{
// если стек пуст, завершить программу
if (top == -1)
{
cerr << "Попытка считать данные из пустого стека!" << end.1;
exit(l);
}
return stacklist[top];
}
Условия тестирования стека.
Во время своего выполнения операции стека завершают программу при попытках клиента обращаться к стеку неправильно; например, когда мы пытаемся выполнить операцию Peek над пустым стеком. Для защиты целостности стека класс предусматривает операции тестирования состояния стека. Функция StackEmpty проверяет, является ли top равным -1. Если - да, стек пуст и возвращаемое значение - TRUE; иначе возвращаемое значение - FALSE.
// тестирование стека на наличие в нем данных
int Stack::StackEmpty(void) const
{
return top == -1;
}
Функция StackFull проверяет, равен ли top значению MaxStackSize - 1. Если так, то стек заполнен и возвращаемым значением будет TRUE; иначе, возвращаемое значение - FALSE.
// проверка, не переполнен ли стек
int Stack::StackFuli(void) const
{
return top == MaxStackSize-1;
}
Метод ClearStack переустанавливает вершину стека на -1. Это восстанавливает начальное условие, определенное конструктором.
// удалить все элементы из стека
void Stack::ClearStack(void)
{
top = -1;
}
Стековые операции Push и Pop используют прямой доступ к вершине стека и не зависят от количества элементов в списке.
Абстрактный базовый класс Iterator.
Класс Iterator позволяет абстрагироваться от тонкостей реализации алгоритма перебора, что дает независимость от деталей реализации базового класса. Мы определяем абстрактный класс Iterator как шаблон для итераторов списков общего вида.
Спецификация класса Iterator.
Объявление:
template <class T>
class Iterator
{
protected:
// Флаг, показывающий, достиг ли итератор конца списка должен поддерживаться производными классами
int iterationComplete;
public:
// конструктор
Iterator(void);
// обязательные методы итератора
virtual void Next(void) = 0;
virtual void Reset(void) = 0;
// методы для выборки/модификации данных
virtual T& Data(void) = 0;
// проверка конца списка
virtual int EndOfList(void) const;
};
Обсуждение:
Итератор является средством прохождения списка. Его основные методы: Reset (установка на первый элемент списка), Next (переход на следующий элемент), EndOfList (определение конца списка). Функция Data осуществляет доступ к данным текущего элемента списка.
Итератор симметричного метода прохождения.
Симметричное прохождение бинарного дерева поиска, в процессе которого узлы посещаются в порядке возрастания их значений, является полезным инструментом.
Объявление:
// итератор симметричного прохождения бинарного дерева использует базовый класс Iterator
template <class T>
class InorderIterator: public Iterator<T>
{
private:
// поддерживать стек адресов узлов
Stack< TreeNode <T> * > S;
// корень дерева и текущий узел
TreeNode<T> *root, *current;
// сканирование левого поддерева используется функцией Next
TreeNode<T> *GoFarLeft(TreeNode<T> *t);
public:
// конструктор
InorderIterator(TreeNode<T> *tree);
// реализации базовых операций прохождения
virtual void Next(void);
virtual void Reset(void);
virtual T& Data(void);
// назначение итератору нового дерева
void SetTree(TreeNode<T> *tree);
};
Описание:
Класс InorderIterator построен по общему для всех итераторов образцу. Метод EndOfList определен в базовом классе Iterator. Конструктор инициализирует базовый класс и с помощью GoFarLeft находит начальный узел сканирования.
Пример:
TreeNode<int> *root; // бинарное дерево
InorderIterator treeiter(root); // присоединить итератор
// распечатать начальный узел сканирования для смешанного прохождения это самый левый узел дерева
cout << treeiter.Data();
// сканирование узлов и печать их значений
for (treeiter.Reset(); !treeiter.EndOfList(); treeiter.Next())
cout << treeiter.Data() << " ";
Реализация класса InorderIterator.
Итерационный симметричный метод прохождения эмулирует рекурсивное сканирование с помощью стека адресов узлов. Начиная с корня, осуществляется спуск вдоль левых поддеревьев. По пути указатель каждого пройденного узла запоминается в стеке. Процесс останавливается на узле с нулевым левым указателем, который становится первым посещаемым узлом в симметричном сканировании. Спуск от узла t и запоминание адресов узлов в стеке выполняет метод GoFarLeft. Вызовом этого метода с t=root ищется первый посещаемый узел (рис. 18).
// вернуть адрес крайнего узла на левой ветви узла t
// запомнить в стеке адреса всех пройденных узлов
template <class T>
TreeNode<T> *InorderIterator<T>::GoFArLeft(TreeNode<T> *t)
{
// если t=NULL, вернуть NULL
if (t == NULL)
return NULL;
// пока не встретится узел с нулевым левым указателем, спускаться по левым ветвям, запоминая в стеке S адреса пройденных узлов. Возвратить указатель на этот узел
while (t->Left() != NULL)
{
S.Push(t);
t = t->Left();
}
return t;
}
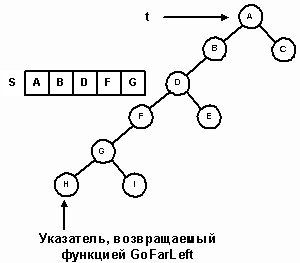
Рис. 18.
После инициализации базового класса конструктор присваивает элементу данных root адрес корня бинарного дерева поиска. Узел для начала симметричного сканирования получается в результате вызова функции GoFarLeft с root в качестве параметра. Это значение запоминается в переменной сurrent.
// инициализировать флаг iterationComplete. Базовый класс сбрасывает его, но
// дерево может быть пустым. начальный узлел сканирования - крайний слева узел.
template <class T>
InorderIterator<T>::InorderIterator(TreeNode<T> *tree):
Iterator<T>(), root(tree)
{
iterationComplete = (root == NULL);
current = GoFarLeft(root);
}
Метод Reset по существу является таким же, как и конструктор, за исключением того, что он очищает стек. Перед первым обращением к Next указатель current уже указывает на первый узел симметричного сканирования. Метод Next работает по следующему алгоритму. Если правая ветвь узла не пуста, перейти к его правому сыну и осуществить спуск по левым ветвям до узла с нулевым левым указателем, попутно запоминая в стеке адреса пройденных узлов.
Если правая ветвь узла пуста, то сканирование его левой ветви, самого узла и его правой ветви завершено. Адрес следующего узла, подлежащего обработке, находится в стеке. Если стек не пуст, удалить следующий узел. Если же стек пуст, то все узлы обработаны и сканирование завершено. Итерационное прохождение дерева, состоящего из пяти узлов, изображено на рисунке 19.
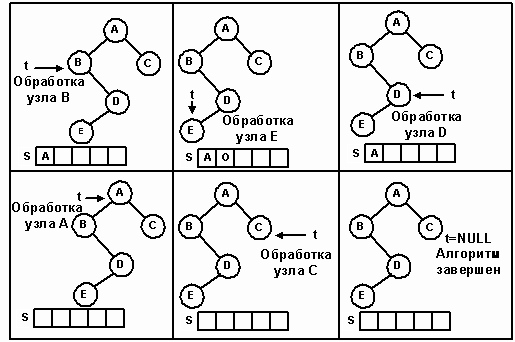
Рис. 19.
template <class T>
void InorderIterator<T>::Next(void)
{
// ошибка, если все узлы уже посещались
if (iterationComplete)
{
cerr << "Next: итератор прошел конец списка!" << endl;
exit(1);
}
// current - текущий обрабатываемый узел
// если есть правое поддерево, спуститься до конца по его левой ветви, попутно запоминая в стеке адреса пройденных узлов
if (current->Right() != NULL)
current = GoFarLeft(current->Right());
// правого поддерева нет, но в стеке есть другие узлы, подлежащие обработке.
// Вытолкнуть из стека новый текущий адрес, продвинуться вверх по дереву
else if (!S.StackEmpty())
current = S.Pop();
// нет ни правого поддерева, ни узлов в стеке. Сканирование завершено
else
iterationComplete = 1;
}
Алгоритм TreeSort.
Когда объект типа InorderIterator осуществляет прохождение дерева поиска, узлы проходятся в сортированном порядке и, следовательно, можно построить еще один алгоритм сортировки, называемый TreeSort. Этот алгоритм предполагает, что элементы изначально хранятся в массиве. Поисковое дерево служит фильтром, куда элементы массива копируются в соответствии с алгоритмом вставки в бинарное дерево поиска. Осуществляя симметричное прохождение этого дерева и записывая элементы снова в массив, мы получаем в результате отсортированный список. На рисунке 20 показана сортировка 8 - элементного массива.
#include "bstree.h"
#include "treeiter.h"
// использование бинарного дерева поиска для сортировки массива
template <class T>
void TreeSort(T arr[], int n)
{
// бинарное дерево поиска, в которое копируется массив
BinSTree<T> sortTree;
int i;
// вставить каждый элемент массива в поисковое дерево
for (i=0; i<n; i++)
sortTree.Insert(arr[i]);
// объявить итератор симметричного прохождения для sortTree
InorderIterator<T> treeSortIter(sortTree.GetRoot());
// выполнить симметричное прохождение дерева
// скопировать каждый элемент снова в массив
i = 0;
while (!treeSortIter.EndOfList())
{
arr[i++] = treeSortIter.Data();
treeSortIter.Next();
}
}
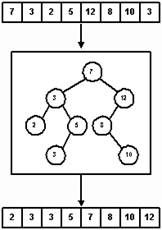
Рис. 20.
3. Алгоритм реализации АВЛ – деревьев через классы объектно – ориентированного программирования.
Программа создана на объектно – ориентированном языке программирования C++ в среде быстрой разработки (RAD) Bolrand C++ Builder 6.0, имеет графический интерфейс.
Текст программы.
#pragma once
template <typename KEY,typename VALUE> class AvlTree
{
public:
KEY key;
VALUE value;
int balance;
AvlTree<KEY, VALUE>* left;
AvlTree<KEY, VALUE>* right;
bool empty;//заполнены ключ и значение или нет
AvlTree()
{
empty=true;
left = NULL;
right = NULL;
balance = 0;
}
AvlTree(KEY Key,VALUE Value)
{
empty=false;
key = Key;
value = Value;
left = NULL;
right = NULL;
balance = 0;
}
int add(KEY Key, VALUE Value)//добавление узла, возвращает изменился баланс(1) или нет (0)
{ //при добавлении в правую ветку баланс узла увеличиваю на результат добавления
if (empty) //в левую уменьшаю
{ //после каждого вызова add(...) вызываю TurnAround();
key = Key; //дерево перестраивается пока потомок текущего узла в нужном направлении не будет NULL
value = Value; //потом в этого потомка записываем новые значения
empty=false;
return 0;
}
if (Key == key)
throw CString(L"Уже есть");
int a = balance;
if (Key > key)
{
if (right != NULL)
{
balance += right->add(Key, Value);
TurnAround();
}
else
{
right = new AvlTree<KEY, VALUE>(Key, Value);
balance++;
}
}
else
{
if (left != NULL)
{
balance -= left->add(Key, Value);
TurnAround();
}
else
{
left = new AvlTree<KEY, VALUE>(Key, Value);
balance--;
}
}
if (balance != a)
{
return 1;
}
else
{
return 0;
}
}
void TurnAround() //нормализация дерева, если баланс не равномерный смещаю(поворачиваю) узел так,
{ //чтобы количество потомков справа и слева не отличалось больше , чем на 1
if (balance == 2)
{
if (right->balance >= 0)
{
KEY tKey = key;
VALUE tValue = value;
key = right->key;
value = right->value;
right->key = tKey;
right->value = tValue;
AvlTree<KEY, VALUE>*tNode=right->right;
right->right = right->left;
right->left = left;
left = right;
right = tNode;
balance = left->balance - 1;
left->balance = 1 - left->balance;
}
else
{
KEY tKey = key;
VALUE tValue = value;
key = right->left->key;
value = right->left->value;
right->left->key = tKey;
right->left->value = tValue;
AvlTree<KEY, VALUE>* tNode = right->left->right;
right->left->right = right->left->left;
right->left->left = left;
left = right->left;
right->left = tNode;
balance = 0;
right->balance = (left->balance == -1) ? (1) : (0);
left->balance = (left->balance == 1) ? (-1) : (0);
}
}
else
{
if (balance == -2)
{
if (left->balance <= 0)
{
KEY tKey = key;
VALUE tValue = value;
key = left->key;
value = left->value;
left->key = tKey;
left->value = tValue;
AvlTree<KEY, VALUE>* tNode = left->left;
left->left = left->right;
left->right = right;
right = left;
left = tNode;
balance = 1 + right->balance;
right->balance = -1 - right->balance;
}
else
{
KEY tKey = key;
VALUE tValue = value;
key = left->right->key;
value = left->right->value;
left->right->key = tKey;
left->right->value = tValue;
AvlTree<KEY, VALUE>* tNode = left->right->left;
left->right->left = left->right->right;
left->right->right = right;
right = left->right;
left->right = tNode;
balance = 0;
left->balance = (right->balance == 1) ? (-1) : (0);
right->balance = (right->balance == -1) ? (1) : (0);
}
}
}
}
typename AvlTree<KEY, VALUE>* getNode(KEY Key)//поиск узла по ключу
{
AvlTree<KEY, VALUE>* node=this;
while (true)
{
if (node == NULL)
throw CString(L"Не найдено");
if (node->key == Key)
return node;
if (node->key < Key)
{
node = node->right;
}
else
{
node = node->left;
}
}
}
int remove(KEY Key,AvlTree<KEY, VALUE>*parent=NULL) //удаление узла, перемещаюсь по дереву, по ключу
{ //при прохождении узла опять меняю баланс в зависимости от направления и поворачиваю его TurnAround()
int a = balance; // как дошел до нужного узла перемещаю его , пока оба его потомка не будут NULL
if (key == Key) // и удаляю
{
if (right == NULL && left == NULL)
{
if(parent->left->key==this->key)
{
parent->left=NULL;
}
else
{
parent->right=NULL;
}
return 1;
}
else
{
if (balance >= 0)
{
if (right != NULL)
{
AvlTree<KEY, VALUE>* tNode = right;
while (tNode->left != NULL)
{
tNode = tNode->left;
}
KEY tKey = key;
VALUE tValue = value;
key = tNode->key;
value = tNode->value;
tNode->key = tKey;
tNode->value = tValue;
balance -= right->remove(Key,this);
}
}
else
{
if (left != NULL)
{
AvlTree<KEY, VALUE>* tNode = left;
while (tNode->right != NULL)
{
tNode = tNode->right;
}
KEY tKey = key;
VALUE tValue = value;
key = tNode->key;
value = tNode->value;
tNode->key = tKey;
tNode->value = tValue;
balance += left->remove(Key,this);
}
}
}
}
else
{
if (Key > key)
{
if (right!=NULL)
{
balance -= right->remove(Key,this);
TurnAround();
}
else
{
throw CString("Не найдено");
}
}
else
{
if (left!=NULL)
{
balance += left->remove(Key,this);
TurnAround();
}
else
{
throw CString("Не найдено");
}
}
}
if (balance != a)
{
return (balance == 0) ? (1) : (0);
}
else
{
return 0;
}
}
~AvlTree()
{
}
};
СПИСОК ЛИТЕРАТУРЫ
1. Каррано Ф.М., Причард Дж.Дж. К26 Абстракция данных и решение задач на С++ - I -. Стены и зеркала, 3-е издание.: Пер.с англ. - М.: Издательский дом «Вильяме», 2003. - 848 с: ил. - Парал. тит. англ.
2. Ж.-Л. Лорьер. Системы искусственного интеллекта. – М.: Мир, 1991.
3. Бабэ Б. Просто и ясно о Borland С++: пер. с англ. – СПб.: Питер, 1997. – 464 с.
4. Ирэ П. Объектно – ориентированное программирование с использованием С++: пер. с англ. К.: НИПФ ДиаСофтЛтд, 1995. – 480 с.
5. Программирование. Учебник под ред. Свердлика А.Н., МО СССР, 1992. – 608 с.
6. Сван Т. Программирование для Windows в Borland С++: пер. с англ. – М.: БИНОМ. – 480 с.
7. Шамис В.А. Borland С++ Builder. Программирование на С++ без проблем. – М.: Нолидж, 1997. – 266 с.
8. Шилдт Г. Теория и практика С++: пер. с англ. – СПб.: BHV – Санкт – Петербург, 1996. – 416 с.
9. http://www.rsdn.ru/article/alg/bintree/avl.xml.
| Сборник экзаменационных билетов по английскому языку | |
|
Экзаменационный билет по предмету АНГЛИЙСКИЙ ЯЗЫК. БАЗОВЫЙ КУРС ДЛЯ НЕЛИНГВИСТОВ Билет № 1 Translate from English: A contract implied in law is one in ... His first steps to fame and fortune began when he was only nine; I don"t think you are quite right. Don"t take the key along which is often the case with absent-minded guests, leave it at the desk. |
Раздел: Рефераты по языковедению Тип: билеты |
| Двоичные деревья поиска | |
|
Роман Акопов Определение Двоичного Дерева Поиска (Binary Search Tree, BST) Двоичным деревом поиска (ДДП) называют дерево, все вершины которого ... Имеется два крайних случая - сбалансированное бинарное дерево (где каждый уровень имеет полный набор вершин) и вырожденное дерево, где на каждый уровень приходится по одной вершине ... При реализации дерева помимо значения ключа (key) и данных также хранятся три указателя: на родителя (net), левого (left) и правого (right) потомков. |
Раздел: Рефераты по информатике, программированию Тип: реферат |
| Основы дискретной математики | |
|
Федеральное агентство по образованию Новомосковский институт (филиал) Государственного образовательного учреждения высшего профессионального ... Предполагая, что Key содержит значение, хранимое в данном узле, мы можем сказать, что бинарное дерево обладает следующим свойством: у всех узлов, расположенных слева от данного ... all values to the left of the pivot are $ pivot |
Раздел: Рефераты по информатике, программированию Тип: учебное пособие |
| Сравнительный анализ алгоритмов построения выпуклой оболочки на ... | |
|
Аннотация Тема данной курсовой работы - " Сравнительный анализ алгоритмов построения выпуклой оболочки на плоскости". Для сравнения взяты четыре ... Для каждого узла в этом дереве мы должны иметь возможность получать доступ к самой левому узлу. t^.x:=random(2*Range.Value+1)-Range.Value; |
Раздел: Рефераты по математике Тип: реферат |
| Алгоритмы преобразования ключей | |
|
СОДЕРЖАНИЕ ВВЕДЕНИЕ ГЛАВА 1. АЛГОРИТМЫ ПРЕОБРАЗОВАНИЯ КЛЮЧЕЙ (РАССТАНОВКА) ГЛАВА 2. ПРАКТИЧЕСКАЯ ЧАСТЬ 2.1 ВСТАВКА ЭЛЕМЕНТА В В-ДЕРЕВО 2.2 ОБРАБОТКА ... Поскольку дерево упорядочено, то Items[1].Value<Items[2].Value<.< Items[Count].Value. Поэтому (и из-за разной структуры узлов) алгоритмы включения/удаления принципиально различны, хотя цель их в обоих случаях одна - поддерживать сбалансированность дерева. |
Раздел: Рефераты по информатике, программированию Тип: курсовая работа |