Учебное пособие: Теория информации
Лекции по Теории информации
Подготовил В.С. Прохоров
Содержание
Введение
1. Понятие информации. Задачи и постулаты прикладной теории информации
1.1 Что такое информация
1.2 Этапы обращения информации
1.3 Информационные системы
1.4 Система передачи информации
1.5 Задачи и постулаты прикладной теории информации
2. Количественная оценка информации
2.1 Свойства энтропии
2.2 Энтропия при непрерывном сообщении
2.3 Условная энтропия
2.4 Взаимная энтропия
2.5 Избыточность сообщений
3. Эффективное кодирование
4. Кодирование информации для канала с помехами
4.1 Разновидности помехоустойчивых кодов
4.2 Общие принципы использования избыточности
4.3 Связь информационной способности кода с кодовым расстоянием
4.4 Понятие качества корректирующего кода
4.5 Линейные коды
4.6 Математическое введение к линейным кодам
4.7 Линейные коды как пространство линейного векторного пространства
4.8 Построение двоичного группового кода
4.8.1. Составление таблицы опознавателей
4.8.2. Определение проверочных равенств
4.8.3. Мажоритарное декодирование групповых кодов
4.8.4. Матричное представление линейных кодов
4.8.5. Технические средства кодирования и декодирования для групповых кодов
4.9 Построение циклических кодов
4.9.1. Общие понятия и определения
4.9.2. Математическое введение к циклическим кодам
4.9.3. Требования, предъявляемые к многочлену
4.10 Выбор образующего многочлена по заданному объему кода и заданной корректирующей способности
4.10.1. Обнаружение одиночных ошибок
4.10.2. Исправление одиночных или обнаружение двойных ошибок
4.10.3. Обнаружение ошибок кратности три и ниже
4.10.4. Обнаружение и исправление независимых ошибок произвольной кратности
4.10.5. Обнаружение и исправление пачек ошибок
4.10.6. Методы образования циклического кода
4.10.7. Матричная запись циклического кода
4.10.8. Укороченные циклические коды
4.11. Технические средства кодирования и декодирования для циклических кодов
4.11.1. Линейные переключательные схемы
4.11.2. Кодирующие устройства
4.11.3. Декодирующие устройства
Список литературы
Содержание
Введение
Теория информации является одним из курсов при подготовке инженеров, специализирующихся в области автоматизированных систем управления и обработки информации. Функционирование таких систем существенным образом связано с получением, подготовкой, передачей, хранением и обработкой информации, поскольку без осуществления этих этапов невозможно принять правильное решение и осуществить требуемое управляющее воздействие, которое является конечной целью функционирования любой системы.
Возникновение теории информации связывают обычно с появлением фундаментальной работы американского ученого К. Шеннона «Математическая теория связи» (1948). Однако в теорию информации органически вошли и результаты, полученные другими учеными. Например, Р. Хартли, впервые предложил количественную меру информации (1928), акад. В. А. Котельников, сформулировал важнейшую теорему о возможности представления непрерывной функции совокупностью ее значений в отдельных точках отсчета (1933) и разработал оптимальные методы приема сигналов на фоне помех (1946). Акад. А. Н. Колмогоров, внес огромный вклад в статистическую теорию колебаний, являющуюся математической основой теории информации (1941). В последующие годы теория информации получила дальнейшее развитие в трудах советских ученых (А. Н. Колмогорова, А. Я. Хинчина, В. И. Сифорова, Р. Л. Добрушина, М. С. Пинскера, А. Н. Железнова, Л. М. Финка и др.), а также ряда зарубежных ученых (В. Макмиллана, А. Файнстейна, Д. Габора, Р. М. Фано, Ф. М. Вудворта, С. Гольдмана, Л. Бриллюэна и др.).
К теории информации, в ее узкой классической постановке, относят результаты решения ряда фундаментальных теоретических вопросов. Это в первую очередь: анализ вопросов оценки «количества информации»; анализ информационных характеристик источников сообщений и каналов связи и обоснование принципиальной возможности кодирования и декодирования сообщений, обеспечивающих предельно допустимую скорость передачи сообщений по каналу связи, как при отсутствии, так и при наличии помех.
Если рассматривают проблемы разработки конкретных методов и средств кодирования сообщений, то совокупность излагаемых вопросов называют теорией информации и кодирования или прикладной теорией информации.
Попытки широкого использования идей теории информации в различных областях науки связаны с тем, что в основе своей эта теория математическая. Основные ее понятия (энтропия, количество информации, пропускная способность) определяются только через вероятности событий, которым может быть приписано самое различное физическое содержание. Подход к исследованиям в других областях науки с позиций использования основных идей теории информации получил название теоретико-информационного подхода. Его применение в ряде случаев позволило получить новые теоретические результаты и ценные практические рекомендации. Однако не редко такой подход приводит к созданию моделей процессов, далеко не адекватных реальной действительности. Поэтому в любых исследованиях, выходящих за рамки чисто технических проблем передачи и хранения сообщений, теорией информации следует пользоваться с большой осторожностью. Особенно это касается моделирования умственной деятельности человека, процессов восприятия и обработки им информации.
Содержание конспекта лекций ограничивается рассмотрениемвопросов теории и практики кодирования.
1. Понятие информации. Задачи и постулаты прикладной теории информации
1.1 Что такое информация
С начала 1950-х годов предпринимаются попытки использовать понятие информации (не имеющее до настоящего времени единого определения) для объяснения и описания самых разнообразных явлений и процессов.
В некоторых учебниках дается следующее определение информации:
Информация - это совокупность сведений, подлежащих хранению, передаче, обработке и использованию в человеческой деятельности.
Такое определение не является полностью бесполезным, т.к. оно помогает хотя бы смутно представить, о чем идет речь. Но с точки зрения логики оно бессмысленно. Определяемое понятие (информация) здесь подменяется другим понятием (совокупность сведений), которое само нуждается в определении.
При всех различиях в трактовке понятия информации, бесспорно, то, что проявляется информация всегда в материально-энергетической форме в виде сигналов.
Информацию, представленную в формализованном виде, позволяющем осуществлять ее обработку с помощью технических средств, называют данными.
1.2 Этапы обращения информации
Можно выделить следующие этапы обращения информации:
1) восприятие информации;
2) подготовка информации;
3) передача и хранение информации;
4) обработка информации;
5) отображение информации;
6)воздействие информации.
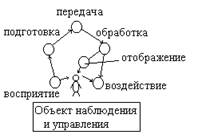
Рис.1.1 Этапы обращения информации
На этапе восприятия информации осуществляется целенаправленное извлечение и анализ информации о каком-либо объекте (процессе), в результате чего формируется образ объекта, проводится его опознание и оценка. При этом отделяют интересующую информацию от шумов.
На этапе подготовки информации получают сигнал в форме, удобной для передачи или обработки (нормализация, аналого-цифровое преобразование и т.д.).
На этапе передачи и хранения информация пересылается либо из одного места в другое, либо от одного момента времени до другого.
На этапе обработки информации выделяются ее общие и существенные взаимозависимости для выбора управляющих воздействий (принятия решений).
На этапе отображения информации она представляется человеку в форме, способной воздействовать на его органы чувств.
На этапе воздействия информация используется для осуществления необходимых изменений в системе.
1.3 Информационные системы
В основе решения многих задач лежит обработка информации. Для облегчения обработки информации создаются информационные системы (ИС). Автоматизированными называют ИС, в которых применяют технические средства, в частности ЭВМ. Большинство существующих ИС являются автоматизированными, поэтому для краткости просто будем называть их ИС. В широком понимании под определение ИС подпадает любая система обработки информации. По области применения ИС можно разделить на системы, используемые в производстве, образовании, здравоохранении, науке, военном деле, социальной сфере, торговле и других отраслях. По целевой функции ИС можно условно разделить на следующие основные категории: управляющие, информационно-справочные, поддержки принятия решений. Заметим, что иногда используется более узкая трактовка понятия ИС как совокупности аппаратно-программных средств, задействованных для решения некоторой прикладной задачи. В организации, например, могут существовать информационные системы, на которые возложены следующие задачи: учет кадров и материально-технических средств, расчет с поставщиками и заказчиками, бухгалтерский учет и т. п. Эффективность функционирования информационной системы (ИС) во многом зависит от ее архитектуры. В настоящее время перспективной является архитектура клиент-сервер. В распространенном варианте она предполагает наличие компьютерной сети и распределенной базы данных, включающей корпоративную базу данных (КБД) и персональные базы данных (ПБД). КБД размещается на компьютере-сервере, ПБД размещаются на компьютерах сотрудников подразделений, являющихся клиентами корпоративной БД. Сервером определенного ресурса в компьютерной сети называется компьютер (программа), управляющий этим ресурсом. Клиентом — компьютер (программа), использующий этот ресурс. В качестве ресурса компьютерной сети могут выступать, к примеру, базы данных, файловые системы, службы печати, почтовые службы. Тип сервера определяется видом ресурса, которым он управляет. Например, если управляемым ресурсом является база данных, то соответствующий сервер называется сервером базы данных. Достоинством организации информационной системы по архитектуре клиент-сервер является удачное сочетание централизованного хранения, обслуживания и коллективного доступа к общей корпоративной информации с индивидуальной работой пользователей над персональной информацией. Архитектура клиент-сервер допускает различные варианты реализации.
1.4 Система передачи информации
Информация поступает в систему в форме сообщений. Под сообщением понимают совокупность знаков или первичных сигналов, содержащих информацию.
Источник сообщений в общем случае образует совокупность источника информации (ИИ) (исследуемого или наблюдаемого объекта) и первичного преобразователя (ПП) (датчика, человека-оператора и т.д.), воспринимающего информацию о протекающем в нем процессе.
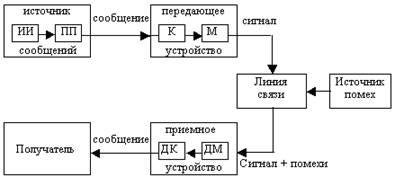
Рис. 1.2. Структурная схема одноканальной системы передачи информации.
Различают дискретные и непрерывные сообщения.
Дискретные сообщения формируются в результате последовательной выдачи источником сообщений отдельных элементов - знаков.
Множество различных знаков называют алфавитом источника сообщения, а число знаков - объемом алфавита.
Непрерывные сообщения не разделены на элементы. Они описываются непрерывными функциями времени, принимающими непрерывное множество значений (речь, телевизионное изображение).
Для передачи сообщения по каналу связи ему ставят в соответствие определенный сигнал. Под сигналом понимают физический процесс, отображающий (несущий) сообщение.
Преобразование сообщения в сигнал, удобный для передачи по данному каналу связи, называют кодированием в широком смысле слова.
Операцию восстановления сообщения по принятому сигналу называют декодированием.
Как правило, прибегают к операции представления исходных знаков в другом алфавите с меньшим числом знаков, называемых символами. При обозначении этой операции используется тот же термин “кодирование”, рассматриваемый в узком смысле. Устройство, выполняющее такую операцию, называют кодирующим или кодером. Так как алфавит символов меньше алфавита знаков, то каждому знаку соответствует некоторая последовательность символов, которую называют кодовой комбинацией.
Число символов в кодовой комбинации называют ее значностью, число ненулевых символов - весом.
Для операции сопоставления символов со знаками исходного алфавита используют термин “декодирование”. Техническая реализация этой операции осуществляется декодирующим устройством или декодером.
Передающее устройство осуществляет преобразование непрерывных сообщений или знаков в сигналы, удобные для прохождения по линии связи. При этом один или несколько параметров выбранного сигнала изменяют в соответствии с передаваемой информацией. Такой процесс называют модуляцией. Он осуществляется модулятором. Обратное преобразование сигналов в символы производится демодулятором
Под линией связи понимают среду (воздух, металл, магнитную ленту и т.д.), обеспечивающую поступление сигналов от передающего устройства к приемному устройству.
Сигналы на выходе линии связи могут отличаться от сигналов на ее входе (переданных) вследствие затухания, искажения и воздействия помех.
Помехами называют любые мешающие возмущения, как внешние, так и внутренние, вызывающие отклонение приинятых сигналов от переданных сигналов.
Из смеси сигнала с помехой приемное устройство выделяет сигнал и посредством декодера восстанавливает сообщение, которое в общем случае может отличаться от посланного. Меру соответствия принятого сообщения посланному сообщению называют верностью передачи.
Принятое сообщение с выхода системы связи поступает к абоненту-получателю, которому была адресована исходная информация.
Совокупность средств, предназначенных для передачи сообщений, называют каналом связи.
1.5 Задачи и постулаты прикладной теории информации
К теории информации относят результаты решения ряда фундаментальных теоретических вопросов:
- анализ сигналов как средства передачи сообщений, включающий вопросы оценки переносимого ими «количества информации»;
- анализ информационных характеристик источников сообщений и каналов связи и обоснование принципиальной возможности кодирования и декодирования сообщений, обеспечивающих предельно допустимую скорость передачи сообщений по каналу связи, как при отсутствии, так и при наличии помех.
В теории информации исследуются информационные системы при четко сформулированных условиях (постулатах):
1. Источник сообщения осуществляет выбор сообщения из некоторого множества с определенной вероятностью.
2. Сообщения могут передаваться по каналу связи в закодированном виде. Кодированные сообщения образуют множество, являющееся взаимно однозначным отображением множества сообщений. Правило декодирования известно декодеру (записано в его программе).
3. Сообщения следуют друг за другом, причем число сообщений может быть сколь угодно большим.
4. Сообщение считается принятым верно, если в результате декодирования оно может быть в точности восстановлено. При этом не учитывается, сколько времени прошло с момента передачи сообщения до момента окончания декодирования, и какова сложность операций кодирования и декодирования.
5. Количество информации не зависит от смыслового содержания сообщения, от его эмоционального воздействия, полезности и даже от его отношения к реальной действительности.
2. Количественная оценка информации
В качестве основной характеристики сообщения теория информации принимает величину, называемую количеством информации. Это понятие не затрагивает смысла и важности передаваемого сообщения, а связано со степенью его неопределенности.
Пусть алфавит источника сообщений состоит из m знаков, каждый из которых может служить элементом сообщения. Количество N возможных сообщений длины n равно числу перестановок с неограниченными повторениями:
N = mn
Если для получателя все N сообщений от источника являются равновероятными, то получение конкретного сообщения равносильно для него случайному выбору одного из N сообщений с вероятностью 1/N.
Ясно, что чем больше N, тем большая степень неопределенности характеризует этот выбор и тем более информативным можно считать сообщение.
Поэтому число N могло бы служить мерой информации. Однако, с позиции теории информации, естественно наделить эту меру свойствами аддитивности, т.е. определить ее так, чтобы она бала пропорциональна длине сообщения (например, при передаче и оплате сообщения - телеграммы, важно не ее содержание, а общее число знаков).
В качестве меры неопределенности выбора состояния источника с равновероятными состояниями принимают логарифм числа состояний:
I = log N = log mn = n log m.
Эта логарифмическая функция характеризует количество информации:
Указанная мера была предложена американским ученым Р.Хартли в 1928 г.
Количество информации, приходящееся на один элемент сообщения (знак, букву), называется энтропией:
![]() .
.
В принципе безразлично, какое основание логарифма использовать для определения количества информации и энтропии, т. к. в силу соотношения loga m =loga b logb m переход от одного основания логарифма к другому сводится лишь к изменению единицы измерения.
Так как современная информационная техника базируется на элементах, имеющих два устойчивых состояния, то обычно выбирают основание логарифма равным двум, т.е. энтропию выражают как:
H0 = log2 m.
Тогда единицу количества информации на один элемент сообщения называют двоичной единицей или битом. При этом единица неопределенности (двоичная единица или бит) представляет собой неопределенность выбора из двух равновероятных событий (bit — сокращение от англ. binary digit — двоичная единица)
Так как из log2 m = 1 следует m = 2, то ясно, что 1 бит - это количество информации, которым характеризуется один двоичный элемент при равновероятных состояниях 0 и 1.
Двоичное сообщение длины n содержит n бит информации.
Единица количества информации, равная 8 битам, называется байтом.
Если основание логарифма выбрать равным десяти, то энтропия выражается в десятичных единицах на элемент сообщения - дитах, причем 1 дит = log102 бит = 3,32 бит.
Пример1. Определить количество информации, которое содержится в телевизионном сигнале, соответствующем одному кадру развертки. Пусть в кадре 625 строк, а сигнал, соответствующий одной строке, представляет собой последовательность из 600 случайных по амплитуде импульсов, причем амплитуда импульса может принять любое из 8 значений с шагом в 1 В.
Решение. В рассматриваемом случае длина сообщения, соответствующая одной строке, равна числу случайных по амплитуде импульсов в ней: n = 600.
Количество элементов сообщения (знаков) в одной строке равно числу значений, которое может принять амплитуда импульсов в строке,: m = 8.
Количество информации в одной строке: I = n log m = 600 log 8, а количество информации в кадре: I¢ = 625 I = 625 600 log 8 = 1,125 × 106 бит
Пример2. Определить минимальное число взвешиваний, которое необходимо произвести на равноплечих весах, чтобы среди 27 внешне неотличимых монет найти одну фальшивую, более легкую.
Решение. Так как монеты внешне не отличимые, то они представляют источник с равновероятными состояниями, а общая неопределенность ансамбля, характеризующая его энтропию, поэтому составляет: H1= Iog227 бит.
Одно взвешивание способно прояснить неопределенность ансамбля насчитывающего три возможных исхода (левая чаша весов легче, правая чаша весов легче, весы находятся в равновесии).Так как все исходы равновероятны (нельзя заранее отдать предпочтение одному из них), то результат одного взвешивания представляет источник с равновероятными состояниями, а его энтропия составляет: H2= Iog23 бит.
Так как энтропия отвечает требованию аддитивности и при этом Н1=3Н2= 3 1og23, то для определения фальшивой монеты достаточно произвести три взвешивания.
Алгоритм определения фальшивой монеты следующий. При первом взвешивании на каждую чашку весов кладется по девять монет. Фальшивая монета будет либо среди тех девяти монет, которые оказались легче, либо среди тех, которые не взвешивались, если имело место равновесие. Аналогично, после второго взвешивания число монет, среди которых находится фальшивая монета, сократится до трех. Последнее, третье, взвешивание дает возможность точно указать фальшивую монету.
Рассмотренная выше оценка информации основана на предположении о равновероятности всех знаков алфавита.
В общем случае каждый из знаков появляется в сообщении с различной вероятностью.
Пусть на основании статистического анализа известно, что в сообщении длины n знак xi появляется ni раз, т.е. вероятность появления знака:
![]() , (i = 1, 2, 3, ... , m).
, (i = 1, 2, 3, ... , m).
Все знаки алфавита составляют полную систему случайных событий, поэтому:
![]() .
.
Число всех возможных сообщений длины n, в которых знак xi входит ni раз, где i = 1, 2, 3 ... ,m, определяется как число перестановок с повторениями из n элементов, спецификация которых {n1, n2, ..., nm}. Поэтому количество возможных сообщений определяют по формуле:
![]() .
.
Например, план застройки улицы 10 домами, среди которых 3 дома одного типа, 5 другого и 2 третьего, можно представить
![]() .
.
Количество информации можно найти по формуле:
I = log N = log n! - (log n1!+log n2!+...+log nm!).
Для достаточно больших n это выражение можно преобразовать с помощью приближенной формулы Стирлинга:
log n! » n(ln n - 1).
Воспользовавшись формулой
Стирлинга и соотношением![]() , получают:
, получают:
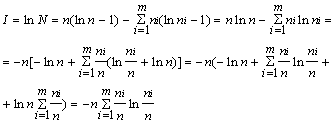
Переходя к вероятностям и произвольным основаниям логарифмов, получают формулы Шеннона для количества информации и энтропии:
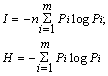
В дальнейшем в выражениях для количества информации I и энтропии H всегда используют логарифмы с основанием 2.
2.1 Свойства энтропии
При равновероятности знаков алфавита Рi = 1/m из формулы Шеннона получают:
![]() .
.
Из этого следует, что при равновероятности знаков алфовита энтропия определяется исключительно числом знаков m алфавита и по существу является характеристикой только алфавита.
Если же знаки алфавита неравновероятны, то алфавит можно рассматривать как дискретную случайную величину, заданную статистическим распределением частот ni появления знаков хi (или вероятностей Рi =ni / n) табл. 2.1:
Таблица 2.1.
|
Знаки хi |
x1 |
x2 |
. . . |
xm |
|
Частоты ni |
n1 |
n2 |
. . . |
nm |
Такие распределения получают обычно на основе статистического анализа конкретных типов сообщений (например, русских или английских текстов и т.п.).
Поэтому, если знаки алфавита неравновероятны и хотя формально в выражение для энтропии входят только характеристики алфавита (вероятности появления его знаков), энтропия отражает статистические свойства некоторой совокупности сообщений.
На основании выражения
![]()
![]() ,
,
величину log 1/Pi можно рассматривать как частную энтропию, характеризующую информативность знака хi, а энтропию H - как среднее значение частных энтропий.
Функция (Pi × log Pi) отражает вклад знака хi в энтропию H. При вероятности появления знака Pi=1 эта функция равна нулю, затем возрастает до своего максимума, а при дальнейшем уменьшении Pi стремится к нулю (функция имеет экстремум): рис.2.1.
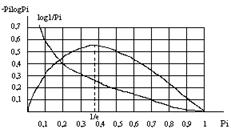
Рис. 2.1. Графики функций log 1/Pi и -Pi × log Pi
Для определения координат максимума этой функции нужно найти производную и приравнять ее к нулю.
Из условия![]() находят: Pi e = 1,где
е - основание натурального логарифма.
находят: Pi e = 1,где
е - основание натурального логарифма.
Таким образом, функция: (Pi
log Pi) при Pi = 1/e = 0,37 имеет максимум: ![]() ., т.е координаты максимума (0,37;
0,531)
., т.е координаты максимума (0,37;
0,531)
Энтропия Н - величина вещественная, неотрицательная и ограниченная, т.е. Н ³ 0 (это свойство следует из того, что такими же качествами обладают все ее слагаемые Pi log 1/Pi).
Энтропия равна нулю, если сообщение известно заранее (в этом случае каждый элемент сообщения замещается некоторым знаком с вероятностью, равной единице, а вероятности остальных знаков равны нулю).
Энтропия максимальна, если все знаки алфавита равновероятны, т.е. Нmax = log m.
Таким образом, степень неопределенности источника информации зависит не только от числа состояний, но и от вероятностей этих состояний. При неравновероятных состояниях свобода выбора источника ограничивается, что должно приводить к уменьшению неопределенности. Если источник информации имеет, например, два возможных состояния с вероятностями 0,99 и 0,01, то неопределенность выбора у него значительно меньше, чем у источника, имеющего два равновероятных состояния. Действительно, в первом случае результат практически предрешен (реализация состояния, вероятность которого равна 0,99), а во втором случае неопределенность максимальна, поскольку никакого обоснованного предположения о результате выбора сделать нельзя. Ясно также, что весьма малое изменение вероятностей состояний вызывает соответственно незначительное изменение неопределенности выбора.
Пример3. Распределение знаков алфавита имеет вид р(х1) = 0,1 р(x2) = 0,1 р(x3) = 0,1 р(x4) = 0,7. Определить число знаков другого алфавита, у которого все знаки равновероятны, а энтропия такая же как и у заданного алфавита.
Особый интерес представляют бинарные сообщения, использующие алфавит из двух знаков: (0,1). При m = 2 сумма вероятностей знаков алфавита: Р1+Р2 = 1. Можно положить Р1 = Р, тогда Р2 = 1-Р.
Энтропию можно определить по формуле:
![]() ,
,
Энтропия бинарных сообщений достигает максимального значения, равного 1 биту, когда знаки алфавита сообщений равновероятны, т.е. при Р = 0,5, и ее график симметричен относительно этого значения.(рис.2.2).
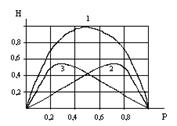
Рис. 2.2. График зависимости энтропии Н двоичных сообщений (1) и ее составляющих (2,3): - (1 - Р) log (1 - P) и - P log P от Р.
Пример 4. Сравнить неопределенность, приходящуюся на букву источника информации (алфавита русского языка), характеризуемого ансамблем, представленным в таблице 2.2, с неопределенностью, которая была бы у того же источника при равновероятном использовании букв.
Таблица 2.2.
| Буква | Вероятность | Буква | Вероятность | Буква | Вероятность | Буква | Вероятность |
| а | 0,064 | й | 0,010 | т | 0,056 | ы | 0,016 |
| б | 0,015 | к | 0,029 | у | 0,021 | э | 0,003 |
| в | 0,039 | л | 0,036 | ф | 0,02 | ю | 0,007 |
| г | 0,014 | м | 0,026 | х | 0,09 | я | 0,019 |
| д | 0,026 | н | 0,056 | ц | 0,04 | пробел | 0,143 |
| е,ё | 0,074 | о | 0,096 | ч | 0,013 | ||
| ж | 0,008 | п | 0,024 | ш | 0,006 | ||
| з | 0,015 | р | 0,041 | ш | 0,003 | ||
| и | 0,064 | с | 0,047 | ъ,ь | 0,015 |
Решение. 1. При одинаковых вероятностях появления любой из всех m = 32 букв алфавита неопределенность, приходящуюся на одну букву, характеризует энтропия
H = log m = log 32 = 5 бит.
2. Энтропию источника, характеризуемого заданным табл. 2.2 ансамблем, находят по формуле:
![]() -0,064 log 0,064 -0,015log0,015 - 0,143log0,143 » 4,43 бит.
-0,064 log 0,064 -0,015log0,015 - 0,143log0,143 » 4,43 бит.
Таким образом, неравномерность распределения вероятностей использования букв снижает энтропию источника с 5 до 4,42 бит
Пример 5. Заданы ансамбли Х и Y двух дискретных величин:
Таблица 2.3.
|
Случайные величины хi |
0,5 | 0,7 | 0,9 | 0,3 |
| Вероятности их появления | 0,25 | 0,25 | 0,25 | 0,25 |
Таблица 2.4.
|
Случайные величины уj |
5 | 10 | 15 | 8 |
| Вероятности их появления | 0,25 | 0,25 | 0,25 | 0,25 |
Сравнить их энтропии.
Решение. Энтропия не зависит от конкретных значений случайной величины. Так как вероятности их появления в обоих случаях одинаковы, то
Н(Х) = Н(Y) = ![]() - 4(0,25log0,25) = -4(1/4log1/4) =
- 4(0,25log0,25) = -4(1/4log1/4) =
= log 4 = 2 бит
2.2 Энтропия при непрерывном сообщении
В предыдущих параграфах была рассмотрена мера неопределенности выбора для дискретного источника информации. На практике в основном встречаются с источниками информации, множество возможных состояний которых составляет континуум. Такие источники называют непрерывными источниками информации.
Во многих случаях они преобразуются в дискретные посредством использования устройств дискретизации и квантования. Вместе с тем существует немало и таких систем, в которых информация передается и преобразуется непосредственно в форме непрерывных сигналов. Примерами могут служить системы телефонной связи и телевидения.
Оценка неопределенности выбора для непрерывного источника информации имеет определенную специфику. Во-первых, значения, реализуемые источником, математически отображаются случайной непрерывной величиной. Во-вторых, вероятности значений этой случайной величины не могут использоваться для оценки неопределенности, поскольку в данном случае вероятность любого конкретного значения равна нулю. Естественно, однако, связывать неопределенность выбора значения случайной непрерывной величины с плотностью распределения вероятностей этих значений. Учитывая, что для совокупности значений, относящихся к любому сколь угодно малому интервалу случайной непрерывной величины, вероятность конечна, попытаемся найти формулу для энтропии непрерывного источника информации, используя операции квантования и последующего предельного перехода при уменьшении кванта до нуля.
Для обобщения формулы Шеннона разобьем интервал возможных состояний случайной непрерывной величины Х на равные непересекающиеся отрезки Dх и рассмотрим множество дискретных состояний х1, x2, ... , xm с вероятностями Pi = p(xi)Dx (i = 1, 2, ... , m). Тогда энтропию можно вычислить по формуле:
![]()
В пределе при Dx ®0 с учетом соотношения:
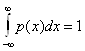 ,
,
Получим ![]() .
.
Первое слагаемое в правой части соотношения имеет конечное значение, которое зависит только от закона распределения непрерывной случайной величины Х и не зависит от шага квантования. Оно имеет точно такую же структуру, как энтропия дискретного источника.
Поскольку для определения этой величины используется только функция плотности вероятности, т. е. дифференциальный закон распределения, она получила название относительной дифференциальной энтропии или просто дифференциальной энтропии непрерывного источника информации (непрерывного распределения случайной величины Х).
Первое слагаемое в этой сумме, называемое также приведенной энтропией, целиком определяет информативность сообщений, обусловленных статистикой состояний их элементов.
Величина logDx зависит только от выбранного интервала Dx, определяющего точность квантования состояний, и при Dx =const она постоянна.
Энтропия и количество информации зависят от распределения плотности вероятностей р(х).
В теории информации большое значение имеет решение вопроса о том, при каком распределении обеспечивается максимальная энтропия Н(х).
Можно показать, что при заданной дисперсии:
![]()
![]() ,
,
наибольшей информативностью сообщение обладает только тогда, когда состояния его элементов распределены по нормальному закону:
![]()
Так как дисперсия определяет среднюю мощность сигнала, то отсюда следуют практически важные выводы.
Передача наибольшего количества информации при заданной мощности сигнала (или наиболее экономичная передача информации) достигается при такой обработке сигнала, которая приближает распределение плотности вероятности его элементов к нормальному распределению.
В то же время, обеспечивая нормальное распределение плотности вероятности элементам помехи, обеспечивают ее наибольшую “ информативность”, т.е наибольшее пагубное воздействие на прохождение сигнала. Найдем значение энтропии, когда состояния элементов источника сообщений распределены по нормальному закону:
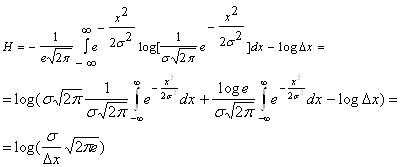 .
.
Найдем значение энтропии, когда состояния элементов распределены внутри интервала их существования а £ х £ b по равномерному закону, т.е
р(х) = 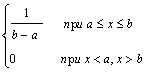
![]()
![]() .
.
Дисперсия равномерного
распределения ![]() , поэтому (b-a) = 2
, поэтому (b-a) = 2![]() . С учетом этого
можно записать
. С учетом этого
можно записать
![]() .
.
Сравнивая между собой сообщения с равномерным и нормальным распределением вероятностей при условии Нн(х) = Нр(х), получаем:
![]()
Это значит, что при одинаковой информативности сообщений средняя мощность сигналов для равномерного распределения их амплитуд должна быть на 42% больше, чем при нормальном распределении амплитуд.
Пример 7. Найдите энтропию случайной величины, распределенной по закону с плотностью вероятности
р(х) =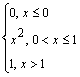
Пример 8. При организации мешающего воздействия при передаче информации можно использовать источник шума с нормальным распределением плотности и источник, имеющий в некотором интервале равномерную плотность распределения. Определить, какой источник шума применять экономичнее, каков при этом выигрыш в мощности.
Решение. Сравнение источников следует проводить из условия обеспечения равенства энтропий, когда каждый источник вносит одинаковое мешающее воздействие при передаче информации, но, очевидно, затрачивая при этом не одинаковые мощности.
Как было показано выше, значение энтропии, когда состояния элементов распределены по нормальному закону, можно найти по формуле:
![]() ,
,
где Dx = 1 Ом, а ![]() , т.е. sг2 - дисперсия, характеризующая мощность, выделяемую на
резистора с сопротивлением 1Ом.
, т.е. sг2 - дисперсия, характеризующая мощность, выделяемую на
резистора с сопротивлением 1Ом.
Для равномерного распределения энтропию можно найти по формуле:
Нр(х) = ![]()
Так как дисперсия равномерного распределения
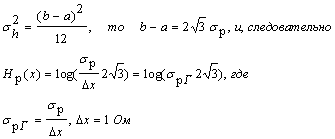
Так как 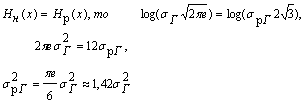
Поэтому следует выбирать источник шума с нормальным распределением плотности распределения амплитуд, т.к. при той же неопределенности, вносимой им в канал связи, можно выиграть в мощности 42%.
Поэтому следует выбирать источник шума с нормальным распределением плотности, т.к. при той же неопределенности, вносимой им в канал связи, можно выиграть в мощности 42%.
2.3 Условная энтропия
До сих пор предполагалось, что все элементы сообщения независимы, т.е. появление каждого данного элемента никак не связано с предшествующими элементами.
Рассмотрим теперь два ансамбля
Х = (х1, x2, ... ,xr)
Y = (y1, y2, ..., ys) ,
которые определяются не только собственными вероятностями р(хi) и p(yj), но и условными вероятностями pxi(yj), pyj(xi), где i = 1, 2, ... , r ; j = 1, 2, ... , s.
Систему двух случайных величин (сообщений) Х, Y можно изобразить случайной точкой на плоскости. Событие, состоящее в попадании случайной точки (X, Y) в область D, принято обозначать в виде (X, Y) Ì D.
Закон распределения системы двух случайных дискретных величин может быть задан с помощью табл. 2.5.
 Таблица 2.5.
Таблица 2.5.
|
Y X |
y1 |
y2 |
. . . |
ys |
|
x1 |
Р11 |
Р12 |
. . . |
Р1s |
|
x2 |
Р21 |
Р22 |
. . . |
Р2s |
| : | : | : | : | : |
|
xr |
Рr1 |
Рr2 |
. . . |
Рrs |
где Рij - вероятность события, заключающегося в одновременном выполнении равенства Х = xi, Y = yj. При этом
![]() .
.
Закон распределения системы случайных непрерывных величин (Х, Y) задают при помощи функции плотности вероятности р(x, y).
Вероятность попадания случайной точки (Х,Y) в область D определяется равенством
![]() .
.
Функция плотности вероятности обладает следующими свойствами:
1) р(x,y) ³ 0
2) ![]()
Если все случайные точки (X,Y) принадлежат области D, то
![]() .
.
Условным распределением составляющей Х при Y = yj (yj сохраняет одно и то же значение при всех возможных значениях Х) называют совокупность условных вероятностей Pyj(x1), Pyj(x2), ... , Pyj(xr)
Аналогично определяется условное распределение составляющей Y.
Условные вероятности составляющих X и Y вычисляют соответственно по формулам:
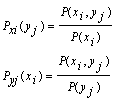
Для контроля вычислений целесообразно убедиться, что сумма вероятностей условного распределения равна единице.
Так как условная вероятность события yj при условии выполнения события xi принимается по определению
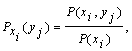
то вероятность совместного появления совокупности состояний
P(xi,yj) = P(xi) Pxi(yj).
Аналогично, условимся вероятность события xi при условии выполнения события yj:
![]() .
.
Поэтому общую энтропию зависимых ансамблей X и Y определяют по формуле Шеннона:
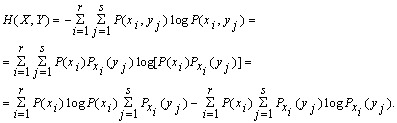
С учетом соотношения ![]() получают
получают
Н(Х,Y) = H(X) + HX(Y), где Н(Х) - энтропия ансамбля Х;
HX(Y) - условная энтропия ансамбля Y при условии, что сообщение ансамбля Х известны:
![]()
Для независимых событий Х и Y: Pxi(yj) = P(yj) и поэтому
HX(Y) = Н(Y) и, следовательно, Н(Х,Y) = H(X) + H(Y).
Если Х и Y полностью зависимы, т.е. при появлении xi неизбежно следует yj, то Р(xi,yj) равна единице при i = j и нулю при i ¹ j. Поэтому НX(Y) = 0, и , следовательно, Н(X,Y) = Н(Х), т.е. при полной зависимости двух ансамблей один из них не вносит никакой информации.
Полученное выражение для условной энтропии
![]()
можно использовать и как информативную характеристику одного ансамбля Х, элементы которого взаимно зависимы. Положив Y = X, получим
![]()
Например, алфавит состоит из двух элементов 0 и 1. Если эти элементы равновероятны, то количество информации, приходящееся на один элемент сообщения: Н0 = log m = log 2 = 1 бит. Если же, например, Р(0)=ѕ, а Р(1) = ј, то
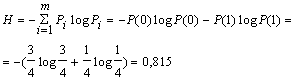
В случае же взаимной зависимости элементов, определяемой, например, условными вероятностями Р0(0) = 2/3; P0(1) = 1/3; P1(0) = 1; P1(1) = 0, то условная энтропия
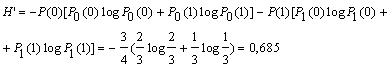
Энтропия при взаимно зависимых элементах всегда меньше, чем при независимых, т.е. H’<H.
Пример9: Задано распределение вероятностей случайной дискретной двумерной величины:
Таблица 2.6.
|
Y X |
4 | 5 |
| 3 | 0,17 | 0,10 |
| 10 | 0,13 | 0,30 |
| 12 | 0,25 | 0,05 |
Найти законы распределения составляющих Х и Y.
Решение: 1) Сложив вероятности “по строкам”, получим вероятности возможных значений Х:
Р(3) = 0,17 + 0,10 = 0,27
P(10) = 0,13 +0,30 = 0,43
P(12) = 0,25 + 0,05 = 0,30.
Запишем закон распределения составляющей Х:
Таблица 2.7.
| Х | 3 | 10 | 12 |
|
P(xi) |
0,27 | 0,43 | 0,30 |
Контроль: 0,27 + 0,43 + 0,30 = 1
2) Сложив вероятности “по столбцам”, аналогично найдем распределение составляющей Y:
Таблица 2.8.
| Y | 4 | 5 |
|
P(yj) |
0,55 | 0,45 |
Контроль: 0,55 + 0,45 = 1
Пример10: Задана случайная дискретная двумерная величина (X,Y):
Таблица 2.9.
|
Y X |
y1 = 0,4 |
y2 = 0,8 |
|
x1 = 2 |
0,15 | 0,05 |
|
x2 = 5 |
0,30 | 0,12 |
|
x3 = 8 |
0,35 | 0,03 |
Найти: безусловные законы распределения составляющих; условный закон распределения составляющей Х при условии, что составляющая Y приняла значение y1 = 0,4; условный закон распределения составляющей Y при условии, что составляющая Х приняла значение х2 = 5
Решение: 1) Сложив вероятности “по строкам”, напишем закон распределения Х.
Таблица 2.10.
| X | 2 | 5 | 8 |
| P(x) | 0,20 | 0,42 | 0,38 |
2) Сложив вероятности “по столбцам”, найдем закон распределения Y.
Таблица 2.11.
| Y | 0,4 | 0,8 |
| P(y) | 0,80 | 0,20 |
3) Найдем условные вероятности возможных значений Х при условии, что составляющая Y приняла значение y1 = 0,4
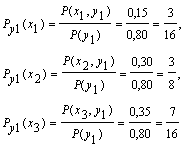
Напишем искомый условный закон распределения Х:
Таблица 2.12.
| X | 2 | 5 | 8 |
|
Py1(xi) |
3/16 | 3/8 | 7/16 |
Контроль: 3/16 + 3/8 + 7/16 = 1
Аналогично найдем условный закон распределения Y:
Таблица 2.13.
| Y | 0,4 | 0,8 |
|
Px2(yj) |
5/7 | 2/7 |
Контроль: 5/7 + 2/7 = 1.
Пример11: Закон распределения вероятностей системы, объединяющей зависимые источники информации X и Y, задан с помощью таблицы:
Таблица 2.14.
|
Y X |
y1 |
y2 |
y3 |
|
x1 |
0,4 | 0,1 | 0 |
|
x2 |
0 | 0,2 | 0,1 |
|
x3 |
0 | 0 | 0,2 |
Определить энтропии Н(Х), H(Y), HX(Y), H(X,Y).
Решение: 1. Вычислим безусловные вероятности Р(xi) и Р(yj) системы:
а) сложив вероятности “по строкам” , получим вероятности возможных значений Х: P(x1) = 0,5
P(x2) = 0,3
P(x3) = 0,2
б) сложив вероятности “по столбцам”, получим вероятности возможных значений Y:
P(y1) = 0,4
P(y2) = 0,3
P(y3) = 0,3
2. Энтропия источника информации Х:
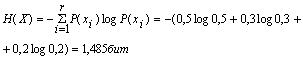
3. Энтропия источника информации Y:
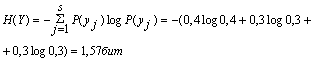
4. Условная энтропия источника информации Y при условии, что сообщения источника Х известны:
![]()
Так как условная вероятность события yj при условии выполнения события хi принимается по определению
![]()
поэтому найдем условные вероятности возможных значений Y при условии, что составляющая Х приняла значение x1:
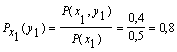
![]()
![]()
Для х2: ![]()
![]()
![]()
Для х3: 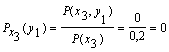
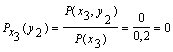
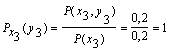
Поэтому: HX(Y) = - [0,5 (0,8 log 0,8 + 0,2 log 0,2) +
+0,3 (0,67 log 0,67 + 0,33 log 0,33) + 0,2 (1 log 1)] = 0,635
5. Аналогично, условная энтропия источника информации Х при условии, что сообщения источника Y известны:
![]()
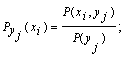
Для у1: ![]()
![]()
![]()
Для у2: ![]()
![]()
![]()
Для у3: ![]()
![]()
![]()
![]()
6. Общая энтропия зависимых источников информации Х и Y:
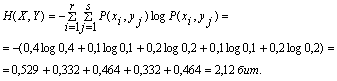
Проверим результат по формуле:
Н(Х,Y) = H(X) +HX(Y) = 1,485 + 0,635 = 2,12 бит
Н(Х,Y) = H(Y) +HY(X) = 1,57 + 0,55 = 2,12 бит
Пример12: Известны энтропии двух зависимых источников Н(Х) = 5бит; Н(Y) = 10бит. Определить, в каких пределах будет изменяться условная энтропия НХ(Y) в максимально возможных пределах.
Решение: Уяснению соотношений между рассматриваемыми энтропиями источников информации способствует их графическое отображение.
При отсутствии взаимосвязи между источниками информации:
Рис. 2.5.
Если источники информации независимы, то НХ(Y) = Н(Y) = 10 бит, а НY(X) = H(X) = 5 бит, и, следовательно, Н(X,Y) = H(X) + H(Y) = 5 +10 = 15 бит. Т.е., когда источники независимы НХ(Y) = Н(Y) = 10 бит и поэтому принимают максимальное значение.
По мере увеличения взаимосвязи источников НХ(Y) и НY(X) будут уменьшаться:

Рис. 2.6.
При полной зависимости двух источников один из них не вносит никакой информации, т.к. при появлении xi неизбежно следует уj , т.е. Р(xi, уj) равно единице при i = j и нулю при i ¹ j. Поэтому
НY(X) = 0 и, следовательно, Н(X,Y) = НХ(Y) .

Рис. 2.7.
При этом НХ(Y) = Н(Y) - Н(Х) = 10 - 5 = 5 бит. Поэтому НХ(Y) будет изменяться от 10 бит до 5 бит при максимально возможном изменении Нy(Х) от 5 бит до 0 бит.
Пример13: Определите Н(Х) и НХ(Y), если Р(х1,y1) = 0,3; P(x1,y2) = 0,2;
P(x3,y2) = 0,25; P(x3,y3) = 0,1
Пример14: Определите Н(Х), H(Y), H(X,Y), если Р(х1,y1) = 0,2; P(x2,y1) = 0,4;
P(x2,y2) = 0,25; P(x2,y3) = 0,15
2.4 Взаимная энтропия
Пусть ансамбли Х и Y относятся соответственно к передаваемому и принимаемому сообщениям. Различия между Х и Y обуславливаются искажениями в процессе передачи сообщений под воздействием помех.
При отсутствии помех различий между ансамблями Х и Y не будет, а энтропии передаваемого и принимаемого сообщений будут равны: Н(Х) = Н(Y).
Воздействие помех оценивают условной энтропией НY(X). Поэтому получаемое потребителем количество информации на один элемент сообщения равно: Е(Х,Y) = Н(Х) – НY(X)
Величину Е(Х,Y) называют взаимной энтропией.
Если ансамбли Х и Y независимы, то это означает, что помехи в канале привели к полному искажению сообщения, т.е. НY(X) = Н(Х), а получаемое потребителем количество информации на один элемент сообщения:Е(Х,Y)=0.
Если Х и Y полностью зависимы, т.е. помехи в канале отсутствуют, то НY(X) = 0 и Е(Х,Y) = H(Y).
Так как НY(X) = Н(Х,Y) – H(Y), то Е(Х,Y) = H(X) + H(Y) – H(X,Y), или
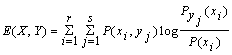 .
.
Пример15: Определите Н(Х) и Е(Х,Y), если Р(х1,y1) = 0,3; P(x1,y2) = 0,2;
P(x2,y3) = 0,1; P(x3,y2) = 0,1; P(x3,y3) = 0,25.
2.5 Избыточность сообщений
Чем больше энтропия, тем большее количество информации содержит в среднем каждый элемент сообщения.
Пусть энтропии двух источников сообщений Н1<Н2, а количество информации, получаемое от них одинаковое, т.е. I = n1H1 = n2H2, где n1 и n2 - длина сообщения от первого и второго источников. Обозначим
![]()
При передаче одинакового количества информации сообщение тем длиннее, чем меньше его энтропия.
Величина m, называемая коэффициентом сжатия, характеризует степень укорочения сообщения при переходе к кодированию состояний элементов, характеризующихся большей энтропией.
При этом доля излишних элементов оценивается коэффициентом избыточности:
![]()
Русский алфавит, включая пропуски между словами, содержит 32 элемента (см. Пример), следовательно, при одинаковых вероятностях появления всех 32 элементов алфавита, неопределенность , приходящаяся на один элемент, составляет Н0 = log 32 = 5 бит
Анализ показывает, что с учетом неравномерного появления различных букв алфавита H = 4,42 бит, а с учетом зависимости двухбуквенных сочетаний H’ = 3,52 бит, т.е. H’< H < H0
Обычно применяют три коэффициента избыточности:
1) частная избыточность, обусловленная взаимосвязью r’ = 1 - H’/H;
2) частная избыточность, зависящая от распределения r’’ = 1 - H/ H0;
3) полная избыточность r0 = 1 - H’/ H0
Эти три величины связаны зависимостью r0 = r’ + r’’ - r’r’’
Вследствие зависимости между сочетаниями, содержащими две и больше букв, а также смысловой зависимости между словами, избыточность русского языка (как и других европейских языков) превышает 50% (r0 =1 - H’/ H0 = 1 - 3,52/5 = 0,30).
Избыточность играет положительную роль, т.к. благодаря ней сообщения защищены от помех. Это используют при помехоустойчивом кодировании.
Вполне нормальный на вид лазерный диск может содержать внутренние (процесс записи сопряжен с появлением различного рода ошибок) и внешние (наличие физических разрушений поверхности диска ) дефекты. Однако даже при наличии физических разрушений поверхности лазерный диск может вполне нормально читаться за счет избыточности хранящихся на нем данных. Корректирующие коды С 1, С 2, Q - и Р - уровней восстанавливают все известные приводы, и их корректирующая способность может достигать двух ошибок на каждый из уровней С 1 и C 2 и до 86 и 52 ошибок на уровни Q и Р соответственно. Но затем, по мере разрастания дефектов, корректирующей способности кодов Рида—Соломона неожиданно перестает хватать, и диск без всяких видимых причин отказывает читаться, а то и вовсе не опознается приводом. Избыточность устраняют построением оптимальных кодов, которые укорачивают сообщения по сравнению с равномерными кодами. Это используют при архивации данных. Действие средств архивации основано на использовании алгоритмов сжатия, имеющих достаточно длинную историю развития, начавшуюся задолго до появления первого компьютера —/еще в 40-х гг. XX века. Группа ученых-математиков, работавших в области электротехники, заинтересовалась возможностью создания технологии хранения данных, обеспечивающей более экономное расходование пространства. Одним из них был Клод Элвуд Шеннон, основоположник современной теории информации. Из разработок того времени позже практическое применение нашли алгоритмы сжатия Хаффмана и Шеннона-Фано. А в 1977 г. математики Якоб Зив и Абрахам Лемпел придумали новый алгоритм сжатия, который позже доработал Терри Велч. Большинство методов данного преобразования имеют сложную теоретическую математическую основу. Суть работы архиваторов: они находят в файлах избыточную информацию (повторяющиеся участки и пробелы), кодируют их, а затем при распаковке восстанавливают исходные файлы по особым отметкам. Основой для архивации послужили алгоритмы сжатия Я. Зива и А. Лемпела. Первым широкое признание получил архиватор Zip. Со временем завоевали популярность и другие программы: RAR, ARJ, АСЕ, TAR, LHA и т. д.В операционной системе Windows достаточно четко обозначились два лидера: WinZip (домашняя страница этой утилиты находится в Internet по адресу http://www.winzip.com) и WinRAR, созданный российским программистом Евгением Рошалем (домашняя страница http://www.rarlab.com). WinRAR активно вытесняет WinZip так как имеет: удобный и интуитивно понятный интерфейс; мощную и гибкую систему архивации файлов; высокую скорость работы; более плотно сжимает файлы. Обе утилиты обеспечивают совместимость с большим числом архивных форматов. Помимо них к довольно распространенным архиваторам можно причислить WinArj (домашняя страница http://www.lasoft-oz.com). Стоит назвать Cabinet Manager (поддерживает формат CAB, разработанный компанией Microsoft для хранения дистрибутивов своих программ) и WinAce (работает с файлами с расширением асе и некоторыми другими). Необходимо упомянуть программы-оболочки Norton Commander, Windows Commander или Far Manager. Они позволяют путем настройки файлов конфигурации подключать внешние DOS-архиваторы командной строки и организовывать прозрачное манипулирование архивами, представляя их на экране в виде обычных каталогов. Благодаря этому с помощью комбинаций функциональных клавиш можно легко просматривать содержимое архивов, извлекать файлы из них и создавать новые архивы. Хотя программы архивации, предназначенные для MS-DOS, умеют работать и под управлением большинства версий Windows (в окне сеанса MS-DOS), применять их в этой операционной системе нецелесообразно. Дело в том, что при обработке файлов DOS-архиваторами их имена урезаются до 8 символов, что далеко не всегда удобно, а в некоторых случаях даже противопоказано.
Выбирая инструмент для работы с архивами, прежде всего, следует учитывать как минимум два фактора: эффективность, т. е. оптимальное соотношение между экономией дискового пространства и производительностью работы, и совместимость, т. е. возможность обмена данными с другими пользователями
Последняя, пожалуй, наиболее значима, так как по достигаемой степени сжатия, конкурирующие форматы и инструменты различаются на проценты, а высокая вычислительная мощность современных компьютеров делает время обработки архивов не столь существенным показателем. Поэтому при выборе программы-архиватора важнейшим критерием становится ее способность "понимать" наиболее распространенные архивные форматы.
При архивации надо иметь в виду, что качество сжатия файлов сильно зависит от степени избыточности хранящихся в них данных, которая определяется их типом. К примеру, степень избыточности у видеоданных обычно в несколько раз больше, чем у графических, а степень избыточности графических данных в несколько раз больше, чем текстовых. На практике это означает, что, скажем, изображения форматов BMP и TIFF, будучи помещенными в архив, как правило, уменьшаются в размере сильнее, чем документы MS Word. А вот рисунки JPEG уже заранее компрессированы, поэтому даже самый лучший архиватор для них будет мало эффективен. Также крайне незначительно сжимаются исполняемые файлы программ и архивы.
Программы-архиваторы можно разделить на три категории.
1. Программы, используемые для сжатия исполняемых файлов, причем все файлы, которые прошли сжатие, свободно запускаются, но изменение их содержимого, например русификация, возможны только после их разархивации.
2. Программы, используемые для сжатия мультимедийных файлов, причем можно после сжатия эти файлы свободно использовать, хотя, как правило, при сжатии изменяется их формат (внутренняя структура), а иногда и ассоциируемая с ними программа, что может привести к проблемам с запуском.
3. 3. Программы, используемые для сжатия любых видов файлов и каталогов, причем в основном использование сжатых файлов возможно только после разархивации. Хотя имеются программы, которые "видят" некоторые типы архивов как самые обычные каталоги, но они имеют ряд неприятных нюансов, например, сильно нагружают центральный процессор, что исключает их использование на "слабых машинах".
Принцип работы архиваторов основан на поиске в файле "избыточной" информации и последующем ее кодировании с целью получения минимального объема. Самым известным методом архивации файлов является сжатие последовательностей одинаковых символов. Например, внутри вашего файла находятся последовательности байтов, которые часто повторяются. Вместо того, чтобы хранить каждый байт, фиксируется количество повторяемых символов и их позиция. Например, архивируемый файл занимает 15 байт и состоит из следующих символов:
В В В В В L L L L L А А А А А
В шестнадцатеричной системе
42 42 42 42 42 4С 4С 4С 4С 4С 41 41 41 41 41
Архиватор может представить этот файл в следующем виде (шестнадцатеричном):
01 05 42 06 05 4С 0А 05 41
Это значит: с первой позиции пять раз повторяется символ "В", с позиции 6 пять раз повторяется символ "L" и с позиции 11 пять раз повторяется символ "А". Для хранения файла в такой форме потребуется всего 9 байт, что на 6 байт меньше исходного.
Описанный метод является простым и очень эффективным способом сжатия файлов. Однако он не обеспечивает большой экономии объема, если обрабатываемый текст содержит небольшое количество последовательностей повторяющихся символов.
Более изощренный метод сжатия данных, используемый в том или ином виде практически любым архиватором, — это так называемый оптимальный префиксный код и, в частности, кодирование символами переменной длины (алгоритм Хаффмана).
Код переменной длины позволяет записывать наиболее часто встречающиеся символы и группы символов всего лишь несколькими битами, в то время как редкие символы и фразы будут записаны более длинными битовыми строками. Например, в любом английском тексте буква Е встречается чаще, чем Z, а X и Q относятся к наименее встречающимся. Таким образом, используя специальную таблицу соответствия, можно закодировать каждую букву Е меньшим числом битов и использовать более длинный код для более редких букв.
Популярные архиваторы ARJ, РАК, PKZIP работают на основе алгоритма Лемпела-Зива. Эти архиваторы классифицируются как адаптивные словарные кодировщики, в которых текстовые строки заменяются указателями на идентичные им строки, встречающиеся ранее в тексте. Например, все слова какой-нибудь книги могут быть представлены в виде номеров страниц и номеров строк некоторого словаря. Важнейшей отличительной чертой этого алгоритма является использование грамматического разбора предшествующего текста с расположением его на фразы, которые записываются в словарь. Указатели позволяют сделать ссылки на любую фразу в окне установленного размера, предшествующего текущей фразе. Если соответствие найдено, текущая фраза заменяется указателем на своего предыдущего двойника.
При архивации, как и при компрессировании, степень сжатия файлов сильно зависит от формата файла. Графические файлы, типа TIF и GIF, уже заранее компрессированы (хотя существует разновидность формата TIFF и без компрессии), и здесь даже самый лучший архиватор мало чего найдет для упаковки. Совсем другая картина наблюдается при архивации текстовых файлов, файлов PostScript, файлов BMP и им подобных.
КОДИРОВАНИЕ ИЗОБРАЖЕНИЯ, ЗВУКА И ВИДИО
ГРАФИЧЕСКИЕ ФОРМАТЫ ДЛЯ СОХРАНЕНИЯ ИЗОБРАЖЕНИЯ
Все изображения в компьютере хранятся в том или ином графическом формате (более 50 видов). Каждый из них имеет свои особенности. Если работают с графикой или пользуются цифровым фотоаппаратом, то выбор правильного формата во многом определяет качество работ.
Все графические форматы делятся на две большие группы: растровые и векторные. Файлы первой из них содержат описание каждой точки изображения. Они представляют собой прямоугольную матрицу (bitmap), состоящую из маленьких квадратиков разного цвета — пикселей. Самыми распространенными форматами этой группы являются GIF и JPEG, использующиеся в Интернете, а также BMP (стандартный формат Windows) и TIFF, применяющийся при хранении отсканированных изображений и в полиграфии. В растровом формате хранятся фотографии, рисунки и обои Рабочего стола. Видео также является последовательностью растровых изображений.
Файлы векторных форматов содержат не растровые точки, как у фотоснимка, а математические формулы, описывающие координаты кривых. Например, прямая линия представлена координатами двух точек, а окружность — координатами центра и радиуса, поэтому достигается очень небольшой размер файла. Векторные графические форматы используют для передачи схем и рисунков, состоящих из набора линий, описываемых математическими формулами. В векторных форматах сохраняются логотипы, схематические рисунки, текст, предназначенный для вывода на печать, и другие подобные объекты.
Стандартными средствами преобразовать фотоизображение в векторный формат практически невозможно, для этого требуются специальные программы - конверторы. Наиболее распространенные расширения векторных файлов — AI для пакета Adobe Illustrator, CDR для пакета CorelDRAW и WMF (еще один «стандартный» формат Windows).
Если отбросить устаревшие форматы PCX и TIFF, то остается всего четыре – BMP, JPEG, PNG, GIF. Скоро можно будет и GIF считать не рациональным.
Формат ВМР
BMP (Windows Device Independent Bitmap) — это один из старейших форматов, к тому же являющийся «родным» форматом Windows. Основная область применения BMP — хранение файлов, использующихся внутри операционной системы (например, обоев для Рабочего стола или иконок программ). Файл, сохраненный в этом формате, прочитает любой графический редактор. Файлы, сохраненные в BMP, могут содержать как 256 цветов, так и 16 700 000 оттенков. BMP - самый простой (если не сказать примитивный) графический формат. Записанный в нем файл представляет собой массив данных, содержащий информацию о цвете каждого пиксела, т. е. изображение размером 1024x768 точек с глубиной цвета 24 бита будет занимать 1024x768x3= 2 359 296 байт (без учета служебной информации об объеме и имени файла, составляющей еще несколько сот байт). Основной недостаток формата, ограничивающий его применение, — большой размер BMP-файлов. Конечно, можно попробовать сохранить изображение в формате BMP со сжатием, однако это часто вызывает проблемы при работе с некоторыми графическими пакетами. Даже при нынешних емкостях жестких дисков хранить коллекцию 2,5-Мбайт графических файлов крайне обременительно. Да и передача графики в формате BMP по сети (по крайней мере, без сжатия с помощью различных архиваторов) — обременительно. 10—20 лет назад возможности «железа» были намного скромнее, поэтому вопрос о разработке методов сжатия графической информации до приемлемых размеров стоял очень остро.
От формата LZW к формату GIF
Как и BMP, GIF (CompuServe Graphics Interchange Format) является одним из старейших форматов. В 1977 г. израильские математики А. Лемпел и Я. Зив разработали новый класс алгоритмов сжатия без потерь, получивший название метод Лемпела—Зива. Одновременно с самим алгоритмом, именуемым LZ77 (по первым буквам фамилий ученых и последним цифрам года создания), свет увидела статья, где излагались общие идеи данного метода. Впоследствии появилась усовершенствованная версия продукта — LZ78. Многие специалисты стремились доработать его; наибольшее распространение получил вариант LZW, написанный Т. Уэлчем, сотрудником фирмы Unisys, в 1983 г. Он отличался от своего прародителя более высоким быстродействием. В 1985 г. Unisys запатентовала LZW. Этот алгоритм универсален и может использоваться для сжатия информации любого вида. Однако успешнее всего он справляется с графическими изображениями.
В 1987 г. компания CompuServe разработала на основе алгоритма LZW графический формат GIF (Graphic Interchange Format), позволивший эффективно сжимать изображения с глубиной цвета до 8 бит, а по тем временам 256 оттенков считалось огромным количеством. Он был разработан для передачи растровых изображений по сетям.
В 1989 г. CompuServe выпустила усовершенствованную версию формата, названную GIF89a. В нее были
добавлены две функции, которые и по сей день обеспечивают формату популярность
в Интернете (GIF позиционируется прежде всего как сетевой формат). Во-первых,
был курсовые - 700 р.
Работы, похожие на Учебное пособие: Теория информации
|