Курсовая работа: Динамічна пам'ять, принципи її організації і роботи
Курсова робота
на тему
«Динамічна пам'ять, принципи її організації і роботи»
ЗАВДАННЯ ДО КУРОСОВОЇ РОБОТИ
Варіант 3
Згідно з номером свого варіанта виконати курсову роботу у слідкуючій послідовності:
1. Розкрити тему - динамічна пам'ять, принципи її організації і роботи.
2. Розкрити тему «Представлення даних в ЕОМ».
3. Використовуючи таблицю ASCII кодів перекладіть своє прізвище або ім’я (але менш чим 5 літер) у послідовність цифр 16-річної системи числення, а потім у послідовність двійкових біт.
4. Користуючись викладеним теоретичним матеріалом доповніть послідовність двійкових біт бітами коду Хемінга.
5. Змініть значення N-ного біту отриманої послідовності на протилежне та покажіть можливість його відновлення (де N – це ваш номер за журналом академічної групи). У доповнення до N-того біту також змініть на протилежне значення (35 – N) біту. Чи є можливість тепер відновити інформацію? Наведіть пояснення.
6. Написати програму, яка дозволяє кодувати слова довжиною до 10 літер за схемою «ASCII-код → двійковий код → код Хемінга».
7. Написати програму, яка дозволяє знаходити одну помилку в двійковій послідовності коду Хемінга та відновлювати її. Програма також має бути спроможною робити перетворення за схемою «код Хемінга → двійковий код → ASCII-код». Перевірте її роботу, застосовуючи результати з попереднього завдання.
РЕФЕРАТ
Помилки у збережених даних можуть виникати з різних причин. Наприклад, сплеск напруги електроживлення обумовлює помилки в оперативній пам'яті, а порушення властивостей магнітного носія при нагріванні, електромагнітному або механічному впливі веде до зміни збереженої інформації на дисках, дискетах і магнітній стрічці. Для захисту від таких помилок використовуються коди, що можуть виявляти та виправляти помилки. При цьому кожному слову в пам'яті особливим образом додаються додаткові біти. Коли слово зчитується додаткові біти застосовуються для перевірки наявності помилок. Такі коди використовують збереження цілісності даних.
Для практичного застосування і розуміння суті збереження даних в пам’ті комп’ютера необхідне усвідомлення кола завдань, які можуть бути вирішені за допомогою кодів Хемінга. Для цього необхідним є розуміння базових принципів побудови та функціонування алгоритмів розпізнавання та виправлення помилок в кодових послідовностях.
Предметом розгляду даної курсової роботи є коди Хемінга – принципи функціонування у поєднанні з функціональними можливостями на прикладі простих кодів Хемінга.
Курсова робота містить 47 сторінок друкованого тексту, 10 малюнків, 12 таблиць, 3 формули, та 1 додаток. Використано 12 літературних джерел.
Текст документу набрано та відформатовано за допомогою текстового процесора Word 2007 фірми Microsoft.
Ключові слова: запам’ятовуючий пристрій, нагромаджувач, елемент пам’яті, кеш-пам’ять, пам’ять з прямою адресною вибіркою, субмікронна технологія, швидкодія.
ЗМІСТ
ПЕРЕЛІК УМОВНИХ ПОЗНАЧЕНЬ, СИМВОЛІВ І НЕСТАНДАРТНИХ СКОРОЧЕНЬ
ВСТУП
1 ТЕОРЕТИЧНА ЧАСТИНА.
1.1 Динамічна памя'ть, принципи її організації і роботи
1.2 Представлення даних в ЕОМ
2 ПРАКТИЧНА ЧАСТИНА
2.1 Переклад символів імені у послідовність цифр 16-річної системи числення
2.2 Доповнення послідовності двійковими бітами коду Хемінга
2.3 Заміна на протилежне значення біту і можливість його виправлення
2.4 Написання програми кодування слова
ВИСНОВКИ
ЛІТЕРАТУРНІ ДЖЕРЕЛА
ДОДАТОК А. Текст програми
ПЕРЕЛІК УМОВНИХ ПОЗНАЧЕНЬ, СИМВОЛІВ І НЕСТАНДАРТНИХ СКОРОЧЕНЬ
АЛП – арифметико-логічний пристрій
ASCII – American Standard Code for Information Interchange – американський стандартний код для обміну інформацією
ВІС – висока ступінь інтеграції
ДШу – дешифратор
DRAM – Dynamic Random Access Memory – динамічна пам’ять із довільним доступом.
ЗП – запам’ятовуючий пристрій
ЕОМ – електронно-обчислювальна машина
ЕП – елемент пам’яті
ЛЗЗ – лінії запису-зчитування
ОЗП – оперативний запам’ятовуючий пристрій
ППЗП – перепрограмованою запам’ятовуючий пристрій
ПК – персональний комп’ютер
ША – шина адреси (адресна шина)
ШД – шина даних
ШК – шина керування
КП – кеш-пам’ять
РПЗП – репрограмований запам’ятовуючий пристрій
ФЗЗ – формувачів сигналу запису-зчитування
CPU – Central Processing Unit – центральний процесор.
RAM – Random Access Mеmory – пам’ять із довільним доступом.
ROM – Read-Only Memory – пам’ять тільки для читання.
SDRAM – Synchronous Dynamic Random Access Memory – синхронна динамічна пам’ять з довільним доступом.
SRAM – Static Random Access Memory – статична пам’ять із довільним доступом.
ВСТУП
Інформація як відомості про об’єкт або явище відображається у вигляді конкретних даних, що представлені у буквенно-цифровій, числовій, текстовій, звуковій, графічній або іншій зафіксованій формі. Дані можуть передаватися, оброблятися, зберігатися.
Інформацію (повідомлення) можна виразити в різноманітних формах: від природних для людини сигналів (звуків, жестів) до їх письмових позначень. Наочним прикладом перетворення форми подання інформації може бути переклад з однієї природної мови спілкування на іншу.Для запису слів використовується алфавіт – набір символів, що дозволяє кожному слову поставити у відповідність визначену послідовність символів – літер, тобто можна сказати, що кожне слово кодується.
Залежно від того, де і яким чином представляється інформація, використовується відповідне кодування. Так для запису (кодування) чисел в десятковій системі числення використовуються 10 символів. Для запису слів літери.
Для кодування інформації в комп’ютері найзручніше (з технічних причин) використовувати мову, алфавіт якої містить всього два символи. Їх умовно позначають нулем та одиницею, а мову цю називають мовою двійкових кодів. За допомогою цих символів можна представити все розмаїття інформації. Одиницею виміру інформації є біт – він позначає «місце», на яке можна „записати” 0 або 1.
В комп’ютерах інформація кодується відповідно до алфавіту двійкових чисел – кодової таблиці. За загальноприйнятим стандартом ASCII (американський стандарт для обміну інформацією) кодами від 32 до 127 записуються цифри та літери англійського алфавіту, з 128 символу – кодування символів національних алфавітів, деяких математичних знаків тощо.
При кодуванні відбувається перетворення елементів даних у відповідні їм числа – кодові символи. Кожному елементу відповідає унікальна сукупність кодових символів, яка називається кодовою комбінацією. Множина можливих кодових символів називається кодовим алфавітом, а їхня кількість m – є основою коду.
Щоб із закодованої послідовності символів отримати інформацію, треба знати принцип кодування алфавіту, тобто знати, що означає кожен символ. І якщо ми маємо такий алфавіт, то процес отримання інформації із закодованої називається декодуванням.
У сучасному світі збереження інформації відіграє дуже важливу роль. Методи кодування і декодування являють собою інструменти, за допомогою яких інформація перетинає кілометри різної відстані, не втрачаючи первинний образ. Таким чином, на даному етапі розвитку сучасних технологій у сфері збереження інформації, на перший план виходять методи і принципи підвищення конфіденційність і збереження даних.
У даній курсовій роботі розглядаються питання, що до основних принципів і методів організації пам'ті комп'ютера та представлення в ній даних. Також піднімаються питання практичного усвідомлення процесів кодування, декодування та виправлення помилок у кодах даних.
1 ТЕОРЕТИЧНА ЧАСТИНА
1.1 Динамічна пам’ять, принципи її організації і роботи
Однією з головних задач субмікронної технології ВІС є формування структур швидкодіючих запам’ятовуючих пристроїв (ЗП) з інформаційною ємністю більше 1 М на кристалі. Саме підвищення ступені інтеграції ВІС супроводжується зменшенням площі комірки пам’яті та споживаної потужності. Проведене моделювання дозволяє зробити висновок, що при зменшенні розмірів елементів в 1/n раз, степінь інтеграції зростає в n2 разів. Мінімальним елементом для формування структур ЗП ємністю 1М є розмір 0,8-1 мкм. Подальше зменшення розмірів елементів обмежується наступними факторами:
1) при рівності нулю напруги на затворі ключового транзистора повної відсічки не проходить, бо це вимагає подачі нульової порогової напруги (UT 0), яка залежить тільки від ступені легування підкладки і температури;
2) при зниженні напруги живлення виникають проблеми, зв’язані з явищем „короткого” каналу і інжекції гарячих електронів в під затворний діелектрик;
3) рівень порогової напруги обмежується напругою плоских зон UFB, величина якої визначається матеріалом електрода затвора та постійним зарядом в підзатворному діелектрику транзистора;
4) при співударі однієї α- частинки заряд на затворі змінюється на 0,03 пКл і для того, щоб цей заряд не змінював потенціала динамічних конденсаторів пам’яті більше, ніж на 1 В, необхідно ємність такого конденсатора зробити не меншою 0,03 пФ. Тому для подальшого підвищення ступені інтеграції ВІС простого зменшення елементів недостатньо і треба також удосконалювати як технологію формування елементів структур пам’яті, так і конструкцію самої комірки структури. Проте дане питання недостатньо висвітлене в літературі і потребує певних уточнень.
Відомо, що важливі параметри ЗП - швидкодія і споживана потужність визначаються часом доступу до даних, а в більшості ЗП використовується тільки адресний доступ. Такі ЗП є найбільш проробленими і широко використовуються в мікропроцесорних системах управління. Тому в даній статті розглянемо їх конструкторсько-технологічні особливості в рамках субмікронної технології формування їх структур. Всі адресні ЗП діляться на RAM i ROM або їх ще називають оперативними ЗП (ОЗП) і постійними ЗП (ПЗП). Оперативні ЗП зберігають дані, які приймають участь в обміні при виконанні текучої програми, і можуть бути змінені в любий момент часу. В ПЗП така вже зміна не передбачається і її використовують як пам’ять для читання. Якщо такі дані в ПЗП міняються, то її вже називають репрограмованою (РПЗП) або перепрограмованою ППЗП.
RAM (ОЗП) діляться в свою чергу на статичні і динамічні. В першому варіанті запам’ятовуючим елементом є тригер, який зберігає свій стан (0,1) доки схема знаходиться під живленням і немає нового запису даних. Для другого типу дані зберігаються у вигляді заряду конденсатора (Q0, QI), що забезпечується динамічною коміркою пам’яті, побудованою на МОН структурі (транзисторі та конденсаторі). Саморозряд конденсатора веде до знищення даних, а тому такі конденсатори повинні мати високі електричні характеристики (низькі струми втрат, високі пробивні напруги і питому ємність) і періодично регенеруватись. Регенерація даних в ОЗП здійснюється з допомогою спеціальних контролерів, які також зменшують ступінь їх інтеграції. Такі ОЗП називають квазістатичними.
Статичні ОЗП називають ще SRAM, а динамічні DRAM. В свою чергу статичні ОЗП поділяються на:
1) асинхронні, в яких управляючі сигнали задаються як рівнями, так і імпульсами;
2) синхронні, в яких управляючі сигнали представляються тільки імпульсами;
3) конвеєрні , коли такі передачі даних синхронізовані з тактовою частотою мікропроцесора.
Статичні ОЗП, маючи високу швидкодію, є основою кеш-пам’яті.
Динамічні ОЗП характеризуються максимальною інформаційною ємністю і використовуються як основна пам’ять в ЕОМ чи в мікропроцесорних системах. Одним із варіантів швидкодіючої ОЗП є пам’ять типу FPM, тобто із сторінковим режимом доступу до даних і визначається її структурою.
Адресні ЗП представляються статичними і динамічними ОЗП (RAM) та постійного типу ROM. Вони мають багато спільного з точки зору використання структурних схем. Це відноситься до статичних ОЗП (SRAM) та ПЗП типу ROM. Структура динамічних ОЗП має свою специфіку і будується на транзисторно-конденсаторних елементах пам’яті (одно і багато транзисторних). Типова структура для статичного ОЗП подана на мал. 1.
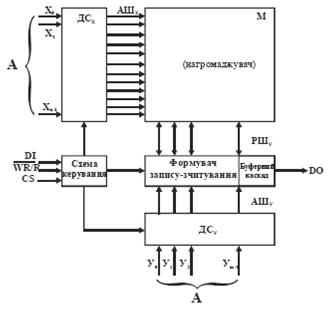
Малюнок 1. Структура схем пам’яті статичної ОЗП
На схемі адрес А є номером комірки нагромаджувача (матриці), до якого проводиться звертання. Тому розрядність адреса зв’язана з числом зберігаючих слів N співвідношенням n = log2N або N = 2n. Якщо ЗП ємністю 64 К має n = 16 розрядні адреси, то адрес виражається набором А = А15А14...А0. Сигнал CS-Chip Select або СЕ (Chip Enable) - сигнал, який дозволяє або забороняє роботу даної схеми. Сигнали WR/RD – Write/Read- сигнал запису-читання, який видає сигнал „1” на зчитування і „0” на запис. Сигнали DI, DO – Date input, Date output – шини вхідних і вихідних даних, розрядність яких визначається розрядністю ЗП (розрядністю його комірок). Запис в вибраний ЕП або зчитування з вибраного ЕП здійснюється з допомогою n-розрядних ФЗЗ, кожний із яких підключений до РШ одного із стовпців. Вихідні сигнали ДШу, що визначають конкретний стовпець, в якому проводиться вибірка ЕП, поступають по АШу на ФЗЗ, який і дозволяє роботу одного з них відповідно на режим запису або зчитування. В режимі запису інформації вибраний ФЗЗ формує через підключену до нього розрядну шину сигнал, що встановлює конкретний ЕП, який вже є в заданому рядку і на який подається сигнал, що поступив з дешифратора ДШХ в стані „0” чи „1” в залежності від того, який сигнал поданий на вхід схеми управління DI. В режимі зчитування відповідний ФЗЗ сприймає сигнал, що поступив на РШ від вибраного ЕП. Цей сигнал вказує на стан ЕП (Q = 0 чи 1) підсилюється і передається на вихід даних DO через буферний каскад (БК). Тобто, режим роботи ЗП дозволяє формування сигналу вибірки на АШХ і при сигналі WR/R = 0 схема управління формує сигнал на запис; при цьому вихід DO блокується буферним каскадом. Якщо WR/R = 1, то схема управління перемикає ФЗЗ в режим зчитування, при якому інформація з вибраного ЕП поступає вже на вихід DO, а вхід DI вже не впливає на роботу зчитування інформації. При CS = 1 реалізується режим зберігання, тобто ЕП не змінюється при дії любих сигналів на входах А, DI, WR/R, а DO при цьому відключається. Часова діаграма режимів запису, зчитування і зберігання в ОЗП приведена на мал. 2.
Основними параметрами ЗП є наступні часи:
1) t CY(A)WR – час циклу адреса в режимі запису;
2) t CY(A)RD – час циклу адреса в режимі зчитування;
3) t SU(A-CS) – час установлення сигналу вибірки CS відносно адреса А;
4) t SU(A-WR) – час установлення сигналу запису;
5) WR відносно адреса А;
6) t V(RD-A) – час зберігання адреса після зняття сигналу зчитування;
7) t W(CS) – тривалість сигналу вибірки CS;
8) t W(RD) – тривалість сигналу зчитування RD;
9) t W(WR) – тривалість сигналу запису WR;
10) t CS – час вибірки для зчитування;
11) t CS – час вибірки для зчитування;

Малюнок 2. Часова діаграма статичного ОЗП в режимах: запису, зберігання і зчитування
12) t A-A – час вибірки адреса;
13) t A-RD – час вибірки сигналу зчитування.
Основними часовими параметрами, що визначають швидкодію ЗП є:
1) t A(RD) – час циклу зчитування;
2) t SU(A-CS) – час установлення сигналу вибірки CS;
3) t SU(A-RD) – час установлення сигналу зчитування;
4) t CS – час вибірки для зчитування.
Для статичних ОЗП і пам’яті типу ROM найбільше застосування отримали структури типу 2D, 3D, 2DM. В структурі 2D (мал. 3) запам’ятовуючі елементи організовані в прямокутний нагромаджувач (матрицю) M = kxm, де k- число зберігаючи слів, а m - їх розрядність. Дешифратор DC при сигналі вибірки CS дозволяє одночасний доступ до всіх елементів вибраного рядка, що зберігає задане слово, адрес якого відповідає номеру рядка, а стовпець вибирається через команду RD/WR на зчитування або запис відповідно. В такій структурі число виходів дешифратора є рівним числу зберігаючи слів. Тому їх можна використовувати в ЗП малої інформаційної ємності до 64 К.
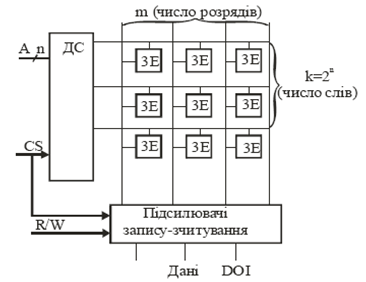
Малюнок 3. Структура ОЗП (RАМ) із словарною адресацією типу 2D
Для збільшення швидкодії запам’ятовуючих пристроїв замість адресного доступу використовують асоціативний, за допомогою якого здійснюється пошук інформації вже по визначеній ознаці (замість адресу), наприклад, по співпадінню певних полів слів, які називають тегами, з ознакою, що задається вхідним словом (теговим адресом). Таку асоціативну пам’ять називають кеш-пам’яттю (cache) або прискорюючою. Вона запам’ятовує копію інформації, що знаходиться в основній ОЗП і забезпечує швидкий доступ до неї по команді мікропроцесора. Таку швидкодіючу пам’ять, як правило, реалізують на тригерних ЕП. При читанні даних спочатку виконується звертання до КП по схемі, що зображена на мал. 4. Якщо в КП є копія даних адресованої комірки основної пам’яті ЗП, то вона виробляє сигнал Hit (співпадіння „1”) і видає дані на загальну шину. Якщо таких даних немає, то не виробляється сигнал Hit („0”) і тоді виконується читання із основної пам’яті і одночасне розміщення даних в КП. МП для прискорення передачі даних може звертатись вже безпосередньо до КП, зчитуючи ці дані і посилаючи їх через шину даних в мікропроцесорну систему. Таке поєднання адресного доступу і асоціативного прискорює роботу (звертання) МП до ЗП, тобто збільшує їх швидкодію. Таким чином, архітектура ЗП визначає не тільки швидкодію, але і значне зменшення споживаної потужності та площі як ЕП, так і ЗП.
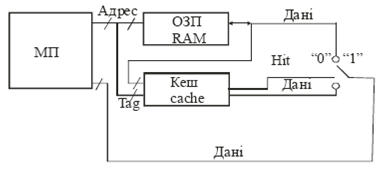
Малюнок 4. Структура взаємодії ОЗП з кеш-пам’яттю МП системи
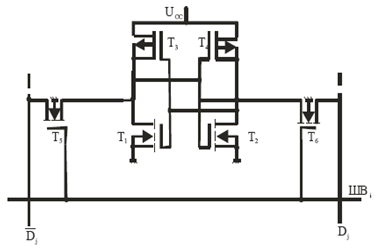
Область застосування статичних ОЗП в системах обробки інформації визначається їх високою швидкодією. Зокрема, вони широко використовуються в кеш-пам’яті, яка при любій ємності завжди має високу швидкодію. Статичну ОЗП (SRAM), як правило, мають структуру 2DM, а частина їх для кеш-пам’яті будується на структурі 2D. Запам’ятовуючим елементом статичних ОЗП є тригер, який має спеціальну установку та скид. Тому статичні ОЗП називають ще тригерними. Нами були розроблені і поставлені на серійне виробництво статичні ОЗП серій К537 РУ6 К-МОН технології і К132 РУ5,8,9 n-МОН технології. ЗЕ на n-МОН транзисторах представляє собою RS-тригер на транзисторах Т1 і Т2 (мал.5) з ключами вибірки Т3 і Т4. При звертанні до даного ЗЕ появляється високий потенціал на шині вибірки ШВі (через і,j позначені номери рядка і стовпця нагромаджувача, на перетині яких розміщений елемент пам’яті ЗЕіj). Цей потенціал відкриває ключі вибірки Т3 і Т4 по всьому рядку, а виходи тригерів рядка з’єднуються із стовбичними (розрядними) шинами запису-зчитування. Одна із цих шин зв’язана з прямим виходом тригера Dj. А друга з інверсним виходом Dj. Через розрядні шини зчитується стан тригера з використанням диференціального підсилювача зчитування. Через них можна записати дані в тригер, подаючи потенціал лог.0 на ту чи другу шину.
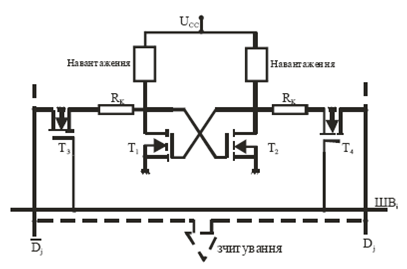

Малюнок 5. Схема тригерного ЗЕ на п-МОН транзисторах а) і варіанти навантаження б)
Запам’ятовуючі елементи статичних ОЗП, які виконані по К-МОН технології значно зменшують споживану потужність (як мінімум на порядок) і збільшують швидкодію за рахунок зменшення ємнісних струмів і відпадає необхідність в резисторах Rk та в високочутливих підсилювачів зчитування. Схема такого ЗЕ подана на мал. 6.
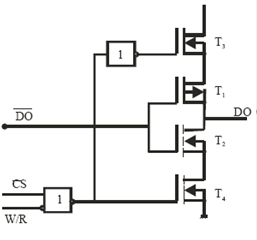
Малюнок 6. Схема статичних ОЗП на К-МОН транзисторах а) та схема буферного каскаду на три стани б)
Технологічною особливістю схеми а) є те, що тут використана багатозарядна імплантація для ретроградного формування охоронних областей та n-кишені і юстування порогових напруг UT n- і р-канальних транзисторів. Це дає можливість забезпечити перехідну характеристику інверторів з високою крутістю для збільшення швидкодії ЗП і їх високої завадозахищеності. Низький рівень сигналу CS і високий рівень сигналу W/R, що означають дозвіл виконання операції зчитування, створюють на виході елемента АБО-НЕ високий рівень лог.1, що відкриває транзистори Т3 і Т4 і, тим самим, забезпечує роботу інвертора на транзисторах Т1 і Т2, через який дані передаються на вихід DO. При інших комбінаціях сигналів CS і W/R вихід елемента АБО-НЕ має низький лог.0, при якому транзистори Т3 і Т4 є закритими і вихід DO вже знаходиться у відключеному стані. Схема передбачає також інверсний вихід DO.
В протилежність SRAM в динамічних ЗП (DRAM) дані зберігаються у вигляді зарядів ємностей МОН структур і основою ЗЕ таких схем є конденсатор певної ємності. Такий ЗЕ значно простіший тригерного (що вміщує 4-8 транзисторів) і дозволяє розмістити на кристалі в 4-5 разів більше елементів та забезпечує високу ємність ЗП. Але конденсатор, як втратний елемент, втрачає з часом свій заряд, тому для зберігання даних необхідна їх періодична регенерація (через декілька мс) спеціальними контролерами регенерації. Для збереження високої степені інтеграції ЗП типу DRAM використовують однотранзисторні ЕП, розміри яких настільки малі, що на них стали впливати навіть α-частинки, що випромінюються елементами корпусів ВІС. Тому забезпечення високої радіаційної стійкості динамічних ОЗП є актуальною і важливою задачею. Електрична схема, структура ЗЕ і схема його включення в нагромаджувач подані на мал. 7. Ключовий МОН транзистор відключає ЗЕ у вигляді конденсатора Сз від лінії запису-зчитування або підключає його до неї, тобто відіграє роль комутатора. Стік МОН транзистора не має зовнішнього виходу і утворює одну із обкладок конденсатора, а другою обкладкою конденсатора є сама кремнієва підкладка. Діелектриком такого конденсатора є підзатворний оксид, властивості якого і визначають електричні характеристики динамічного елемента пам’яті Сз.
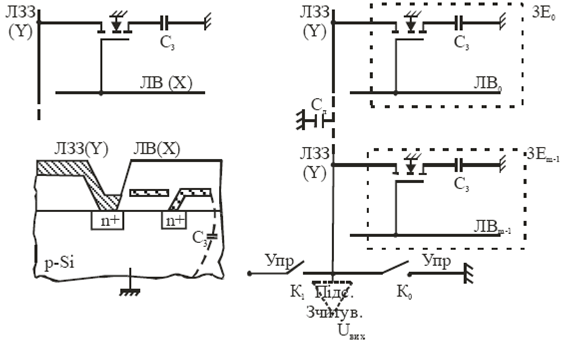
Малюнок 7. Електрична схема ЗЕ ДОЗП структура та схема його включення
В режимі зберігання напруга на шині рядка Х близька до нуля і ключовий транзистор є закритим і тим самим динамічний конденсатор Сз є відключеним від шини запису- зчитування Y. На конденсаторі зберігається, встановлена при записі, напруга U1 або U0. У випадку зберігання лог. 1 конденсатор С3 буде поступово розряджатись внаслідок існування струмів втрат (як зворотних струмів p-n-переходів) на Si-підкладку. Якщо зберігається лог.0, а напруга на шині Y додатна, то конденсатор Сз буде поступово підзаряджатись передпороговим струмом транзистора. Тому необхідне періодичне відновлення вихідної напруги U1 або U0 на конденсаторі. Цей процес називають регенерацією. Вона здійснюється шляхом зчитування інформації з ЕП, перетворення її в напругу U1, U0 з допомогою підсилювача-регенератора і запис цієї напруги в ЕП. Регенерація проводиться одночасно для всіх елементів одного рядка протягом 1-5 мс[9,10]. Таким чином, важливим параметром динамічних елементів пам’яті є:
1) високі значення напруги пробою конденсатора при малому значенні струмів втрат;
2) малі ТКЕ і tgδ;
3) високе значення діелектричної сталої, бо остання визначає площу нагромаджувача;
4) високу радіаційну стійкість до α-опромінювання. Ясно, що таким вимогам не відповідають ємності, сформовані на основі SiO2, а тільки тонкоплівкові конденсатори на основі легованих РЗМ і вуглецем плівок β-тантала.
У режимі запису на шині Y вибраного стовпця встановлюється напруга U1 або U0, а потім подається позитивний імпульс на шину вибірки рядка Х. При цьому транзистор відкривається і на конденсаторі встановлюється та ж напруга, що на шині Y. В решти запам’ятовуючих елементів вибраного рядка в цей час, як правило, іде регенерація.
Процес зчитування інформації із ЗЕ пояснює мал. 7в, де показаний фрагмент ДОЗП, де ЗЕ представлений у вигляді транзисторного ключа та динамічної ємності Сз, підсилювача запису-зчитування, та умовних ключів К1 і К0, що відповідають за запис 1 чи 0. До лінії запису-зчитування підключені ЗЕ в кількості рядків, що є в нагромаджквальній матриці. Особливе значення має ємність лінії Сd , яка може перевищувати Сз запам’ятовуючого елемента. Перед зчитуванням проводиться перезаряд ЛЗЗ. При цьому використовують 2 варіанти ЗП з перезарядом ЛЗЗ:
1) до рівня напруги живлення.Ucc;
2) до рівня половини напруги живлення 1/2Ucc.
Особливістю динамічних ЗП для підвищення їх швидкодії, як відзначалось раніше, є мультиплексування шини адресу. Адрес відповідно ділиться на два півадреса, один із яких представляє собою адрес рядка, а другий – адрес стовпця нагромаджувача ЗЕ. Півадреса подаються на одні і ті ж виводи корпуса ВІС почергово. Подача адреса рядка супроводжується відповідним стробом RAS, а друга стовпця – стробом CAS. Причиною мультиплексування адресів є зменшення числа виводів корпуса і зменшення площі структури ЗП та збільшення швидкодії. Так, наприклад, ЗП з організацією 16Мх1 має 24 – розрядний адрес, а мультиплексування дозволяє скоротити число ліній на 12. На мал. 8 показана часова діаграма та зовнішня організація динамічних ОЗП з мультиплексуванням. Таким чином, правильне поєднання у виборі архітектури, організації, структури і субмікронної технології формування топології запам’ятовуючих елементів дозволяє зменшити площу, споживану потужність, підвищити швидкодію та радіаційну стійкість ВІС пам’яті адресного типу, понизити час їх вибірки до рівня 10-30 нс, збільшити інтеграцію схем пам’яті до 1-64 М.
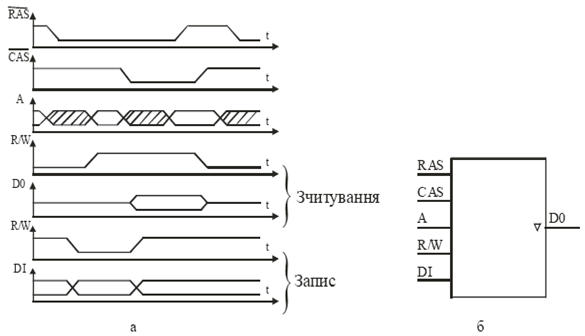
Малюнок 8. Часові діаграми динамічного ОЗП з мультиплексуванням шини адресу а) та його зовнішня організація б).
1.2 Представлення даних в ЕОМ
Подання (кодування) даних.
Щоб працювати з даними різних видів, необхідно уніфікувати форму їхнього подання, а це можна зробити за допомогою кодування. Кодуванням ми займаємося досить часто, наприклад, людина мислить досить розпливчастими поняттями, і, щоб донести думка від однієї людини до іншої, застосовується мова. Мова - це система кодування понять. Щоб записати слова мови, застосовується знову ж кодування - абетка. Проблемами універсального кодування займаються різні галузі науки, техніки, культури. Згадаємо, що креслення, ноти, математичні викладення є теж деяким кодуванням різних інформаційних об'єктів. Аналогічно, універсальна система кодування потрібно для того, щоб велика кількість різних видів інформації можна було б обробити на комп'ютері.
Підготовка даних для обробки на комп'ютері (подання даних) в інформатиці має свою специфіку, пов'язану з електронікою. Наприклад, ми хочемо проводити розрахунки на комп'ютері. При цьому нам доведеться закодувати цифри, якими записані числа. На перший погляд, представляється цілком природним кодувати цифру нуль станом електронної схеми, де напруга на деякому елементі буде дорівнює 0 вольтів, цифру одиниця - 1 вольтів, двійку - 2 вольтів і т.д., дев'ятку - 9 вольтів. Для запису кожного розряду числа в цьому випадку буде потрібно елемент електронної схеми, що має десять станів. Однак елементна база електронних схем має розкид параметрів, що може привести до появи напруги, скажемо 3,5 вольт, а воно може бути витлумачені і як трійка і як четвірка, тобто буде потрібно на рівні електронних схем "пояснити" комп'ютеру, де закінчується трійка, а де починається четвірка. Крім того, прийде створювати досить непрості електронні елементи для виробництва арифметичних операцій із числами, тобто на схемному рівні повинні бути створені та б- . особи множення - 10 х 10 = 100 схем і таблиця додавання - теж 100 схем. Для електроніки 40-х рр. (час, коли з'явилися перші обчислювальні машини) це було непосильне завдання. Ще складніше виглядало б завдання обробки текстів, адже російський алфавіт має 33 букви. Очевидно, такий шлях побудови обчислювальних систем не заможний.
У той же час досить просто реалізувалися електронні схеми із двома стійкими станами: є струм - 1, немає струму - 0; є електричне (магнітне) поле 1, немає - 0. Погляди створювачів обчислювальної техніки були звернені на двійкове кодування як універсальну форму подання даних для подальшої г обробки їхніми засобами обчислювальної техніки. Передбачається, що дані розташовуються в деяких осередках, що представляють упорядковану сукупність із двійкових розрядів, а розряд може тимчасово містити один зі станів - 0 або 1. Тоді . групою із двох двійкових розрядів (двох біт) можна закодувати 22 = 4 різні комбінації кодів (00, 01, 10, 11); аналогічно, три ц біти дадуть 23 = 8 комбінацій, вісім біт або 1 байт - 28 = 256 і т.д. .
Отже, внутрішня абетка комп'ютера дуже бідна, містить усього два символи: 0, 1, тому й виникає проблема подання . усього різноманіття типів даних - чисел, текстів, звуків, графічних зображень, відео й ін. - тільки цими двома символами, з метою подальшої обробки засобами обчислювальної техніки. Питання подання деяких типів даних ми розглянемо у наступних параграфах.
Подання чисел в двійковому коді
Існують різні способи запису чисел, наприклад: можна записати число у вигляді тексту - сто двадцять три; римські системи числення - CXXІІІ; арабської – 123.
Системи числення.
Сукупність прийомів запису й найменування чисел називається системою числення.
Числа записуються за допомогою символів, і по кількості символів, використовуваних для запису числа, системи числення підрозділяються на позиційні й непозиційні. Якщо для запису числа використається нескінченна безліч символів, то система числення називається непозиційної. Прикладом непозиційної системи числення може служити римська. Наприклад, для запису числа один використається буква Й, два й три виглядають як сукупності символів ІІ, ІІІ, але для запису числа п'ять вибирається новий символ V, шість - VІ, десять - уводиться символ - X, сто - С, тисяча - М т.д. Нескінченний ряд чисел зажадає нескінченного числа символів для запису чисел. Крім того, такий спосіб запису чисел приводить до дуже складних правил арифметики.
Позиційні системи числення для запису чисел використають обмежений набір символів, називаних цифрами, і величина числа залежить не тільки від набору цифр, але й від того, у якій послідовності записані цифри, тобто від позиції, займаною цифрою, наприклад, 125 й 215. Кількість цифр, використовуваних для запису числа, називається підставою системи числення, надалі його позначимо q.
У повсякденному житті ми користуємося десятковою позиційною системою числення, q = 10, тобто використається 10 цифр: 0 12 3 4 5 6 7 8 9.
Розглянемо правила запису чисел у позиційній десятковій системі числення. Числа від 0 до 9 записуються цифрами, для запису наступного числа цифри не існує, тому замість 9 пишуть 0, але левее нуля утвориться ще один розряд, називаний старшим, де записується (додається) 1, у результаті виходить 10. Потім підуть числа 11, 12, але на 19 знову молодший розряд заповниться й ми його знову замінимо на 0, а старший розряд збільшимо на 1, одержимо 20. Далі за аналогією 30, 40...90 , 91, 92 ... до 99. Тут заповненими виявляються два розряди відразу; щоб одержати наступне число, ми заміняємо обоє на 0, а в старшому розряді, тепер уже третьому, поставимо 1 (тобто одержимо число 100) і т.д. Очевидно, що, використовуючи кінцеве число цифр, можна записати кожне як завгодно велике число. Помітимо також, що виробництво арифметичних дій у десятковій системі числення досить просто.
Число в позиційній системі числення з підставою q може бути представлене у вигляді полінома по ступенях q. Наприклад, у десятковій системі ми маємо число:
123,45 = 1*102+ 2*101+ 3*100+ 4*10-1 + 5*10-2,
а в загальному виді це правило запишеться так (формула 1.):
X(q)= xn-1*qn-1+xn-2*qn-2 +..+ x1*q1+ x0*q0+ x-1*q-1+..+ x-m*q-m
тут X(q) - запис числа в системі числення з підставою q;
xi - натуральні числа менше q, тобто цифри;
n - число розрядів цілої частини;
m - число розрядів дробової частини.
Записуючи ліворуч праворуч цифри числа, ми одержимо закодованій запис числа в q-ичній системі числення (формула 2.):
X(q)= xn-1*xn-2*x1*x0* x-1* x-2* x-m
В інформатиці, внаслідок застосування електронних засобів обчислюваль-ної техніки, велике значення має двійкова система числення, q = 2. На ранніх етапах розвитку обчислювальної техніки арифметичні операції з дійсними числами проводилися у двійковій системі через простоту їхньої реалізації в електронних схемах обчислювальних машин. Наприклад, таблиця додавання й таблиця множення будуть мати по чотирьох правила (табл. 1).
Таблиця 1. Правила таблиці додавання та таблиці множення
| 0 + 0 = 0 | 0 x 0 = 0 |
| 0 + 1 = 1 | 0 x 1= 0 |
| 1 + 0 =1 | 1 x 0 = 0 |
| 1 + 1 = 1 | 1 x 1 = 1 |
А виходить, для реалізації порозрядної арифметики в комп'ютері будуть потрібні замість двох таблиць по сто правил у десятковій системі числення дві таблиці по чотирьох правила у двійковій. Відповідно на апаратному рівні замість двохсот електронних схем - вісім.
Але запис числа у двійковій системі числення довший запису того ж числа в десятковій системі числення в log210 разів (приблизно в 3,3 рази). Це громіздко й не зручно для використання, тому що звичайно людина може одночасно сприйняти не більше п'яти-семи одиниць інформації, тобто зручно буде користуватися такими системами числення, у яких найбільше часто використовувані числа (від одиниць до тисяч) записувалися б одними-чотирма цифрами. Як це буде показано далі, переклад числа, записаного у двійковій системі числення, у восьмеричну й шістнадцятеричну дуже сильно спрощується в порівнянні з перекладом з десяткової у двійкову. Запис же чисел у них у три рази коротше для восьмеричної й у чотири для шістнадцятеричної системи, чим у двійкової, але довжини чисел у десяткової, восьмеричної й шістнадцятеричної системах числення будуть розрізнятися ненабагато. Тому, поряд із двійковою системою числення, в інформатиці мають ходіння восьмерична й шістнадцятерична системи числення.
Восьмерична система числення має вісім цифр: 0 1 2 3 4 5 6 7. Шістнадцятерична - шістнадцять, причому перші 10 цифр збігаються за написанням із цифрами десяткової системи числення, а для позначення шести цифр, що залишилися, застосовуються більші латинські букви, тобто для шістнадцятеричної системи числення одержимо набір цифр: 0123456789ABCDEF.
Якщо з контексту не ясно, до якої системи числення ставиться запис, то підстава системи записується після числа у вигляді нижнього індексу. Наприклад, те саме число 231, записане в десятковій системі, запишеться у двійкової, восьмеричної й шістнадцятеричної системах числення в такий спосіб:
231(10) = 11100111(2) = 347(8) = Е7
Запишемо початок натурального ряду в десятковій, двійковій, восьмеричній, шістнадцятеричній системах числення (табл. 2).
Таблиця 2. Натуральний ряд чисел у різних системах числення.
| Десяткова | Двійкова | Восьмерична | Шістнадцятерична |
| 0 | 0 | 0 | 0 |
| 1 | 1 | 1 | 1 |
| 2 | 10 | 2 | 2 |
| 3 | 11 | 3 | 3 |
| 4 | 100 | 4 | 4 |
| 5 | 101 | 5 | 5 |
| 6 | 110 | 6 | 6 |
| 7 | 111 | 7 | 7 |
| 8 | 1000 | 10 | 8 |
| 9 | 1001 | 11 | 9 |
| Десяткова | Двійкова | Восьмерична | Шістнадцятерична |
| 10 | 1010 | 12 | А |
| 11 | 1011 | 13 | В |
| 12 | 1100 | 14 | С |
| 13 | 1101 | 15 | D |
| 14 | 1110 | 16 | Е |
| 15 | 1111 | 17 | F |
Подання чисел у двійковому коді.
Подання чисел у пам'яті комп'ютера має специфічну особливість, пов'язану з тим, що в пам'яті комп'ютера вони повинні розташовуватися в байтах - мінімальних по розмірі адресуємих (тобто до них можливе обіг) комірках пам'яті. Очевидно, адресою числа варто вважати адреса першого байта. У байті може втримуватися довільний код з восьми двійкових розрядів, і завдання подання полягає в тім, щоб указати правила, як в одному або декількох байтах записати число.
Дійсне число багатообразне у своїх "споживчих властивостях". Числа можуть бути цілі точні, дробові точні, раціональні, ірраціональні, дробові наближені, числа можуть бути позитивними й негативними. Числа можуть бути "карликами", наприклад, маса атома, "гігантами", наприклад, маса Землі, реальними, наприклад, кількість студентів у групі, вік, ріст. І кожне з перерахованих чисел зажадає для оптимального подання в пам'яті своя кількість байтів.
Очевидно, єдиного оптимального подання для всіх дійсних чисел створити неможливо, тому творці обчислювальних систем пішли по шляху поділу єдиного по суті безлічі чисел на типи (наприклад, цілі в діапазоні від ... до ..., наближені із плаваючою крапкою з кількістю значущих цифр ... і т.д.). Для кожного окремо типу створюється власний спосіб подання.
Цілі числа. Цілі позитивні числа від 0 до 255 можна представити безпосередньо у двійковій системі числення (двійковому коді). Такі числа будуть займати один байт у пам'яті комп'ютера (табл. 3).
Таблиця 3. Двійковій код цілих чисел.
| Число | Двійковий код числа |
| 0 | 0000 0000 |
| 1 | 0000 0001 |
| 2 | 0000 0010 |
| 3 | 0000 0011 |
| … | … |
| 255 | 1111 1111 |
У такій формі подання легко реалізується на комп'ютерах двійкова арифметика.
Якщо потрібні й негативні числа, то знак числа може бути закодований окремим битому, звичайно це старший біт; нуль інтерпретується як плюс, одиниця як мінус. У такому випадку одним байтом може бути закодовані цілі числа в інтервалі від -127 до +127, причому двійкова арифметика буде трохи ускладнена, тому що в цьому випадку існують два коди, що зображують число нуль 0000 0000 й 1000 0000, і в комп'ютерах на апаратному рівні це буде потрібно передбачити. Розглянутий спосіб подання цілих чисел називається прямим кодом. Положення з негативними числами трохи спрощується, якщо використати, так званий, додатковий код. У додатковому коді позитивні числа збігаються з позитивними числами в прямому коді, негативні ж числа виходять у результаті вирахування з 1 0000 0000 відповідного позитивного числа. Наприклад, число -3 одержить код:
_ 1 0000 0000
0000 0011
1111 1101
У додатковому коді добре реалізується арифметика, тому що кожен наступний код виходить із попереднім додатком одиниці з точністю до біта в дев'ятому розряді. Наприклад
5-3 = 5 + (-3)
0000 0101
1111 1101
1 0000 0010, тобто, відкидаючи підкреслений старший розряд, одержимо 2.
Аналогічно цілі числа від 0 так 65536 і цілі числа від -32768 до 32767 у двійковій (шістнадцатеричної) системі числення представляються у двобайтових осередках. Існують подання цілих чисел й у чотирьобайтових осередках.
Дійсні числа. Дійсні числа в математику представляються кінцевими або нескінченними дробами, тобто точність подання чисел не обмежена. Однак у комп'ютерах числа зберігаються в регістрах і комірках пам'яті, які являють собою послідовність байтів з обмеженою кількістю розрядів. Отже, нескінченні або дуже довгі числа усікаються до деякої довжини й у комп'ютерному поданні виступають як наближені. У більшості систем програмування в написанні дійсних чисел ціла й дробова частини розділяються не комі, а крапкою.
Для подання дійсних чисел, як дуже маленьких, так і дуже більших, зручно використати форму запису чисел у вигляді добутку у формулі 3.
X = m * qp
де m - мантиса числа;
q - підстава системи числення;
р - ціле число, називане порядком.
Такий спосіб запису чисел називається поданням числа із плаваючою крапкою.
Тобто число 4235,25 може бути записане в одному з видів:
4235,25 = 423,525 – 101 = 42,3525 – 102 = 4,23525 – 103 = 0,423525 – 104.
Очевидно, таке подання не однозначно. Якщо мантиса 1 / q < |m| < q (0,1 < |m| < 1 для десяткової системи числення), то подання числа стає однозначним, а така форма називається нормалізованої. Якщо "плаваюча" крапка розташована в мантисі перед першою значущою цифрою, то при фіксованій кількості розрядів, відведених під мантису, забезпечується запис максимальної кількості значущих цифр числа, тобто максимальна точність.
Дійсні числа в комп'ютерах різних типів записуються по-різному, проте існує кілька міжнародних стандартних форматів, що розрізняються по точності, але мають однакову структуру. Розглянемо на прикладі числа, що займає 4 байти (мал. 9).
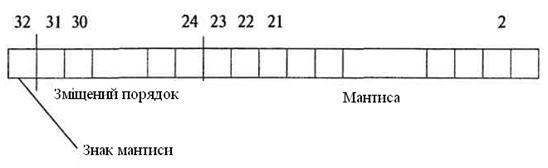
Малюнок 9. Формат числа, що займає 4 байти
Перший біт двійкового подання використається для кодування знака мантиси. Наступна група біт кодує порядок числа, а біти, що залишилися, кодують абсолютну величину мантиси. Довжини порядку й мантиси фіксуються.
Порядок числа може бути як позитивним, так і негативним. Щоб відбити це у двійковій формі, величина порядку представляється у вигляді суми щирого порядку й константи, рівній абсолютній величині максимального по модулі негативного порядку, називаної зсувом. Наприклад, якщо порядок може приймати значення від -128 до 127 (8 біт), тоді, вибравши як змішання 128, можна представити діапазон значень порядку від 0 (-128+128, порядок + зсув) до 255 (127+128),
Тому що мантиса нормалізованого числа завжди починається з нуля, деякі схеми подання його лише мають на увазі, використовуючи зайвий розряд для підвищення точності подання мантиси.
Використання зміщеної форми дозволяє робити операції над порядками як над беззнаковими числами, що спрощує операції порівняння, додавання й вирахування порядків, а також спрощує операцію порівняння самих нормалізованих чисел.
Чим більше розрядів приділяється під запис мантиси, тим вище точність подання числа. Чим більше розрядів займає порядок, тим ширше діапазон від найменшого відмінного від нуля числа до найбільшого числа, представимого в комп'ютері при заданому форматі.
Речовинні числа в пам'яті комп'ютера, залежно від необхідної точності (кількості розрядів мантиси) і діапазону значень (кількості розрядів порядку), займають від чотирьох до десяти байтів. Наприклад, чотирьобайтове речовинне число має 23 розряду мантиси (що відповідає точності числа 7-8 десяткових знаків) і 8 розрядів порядку (забезпечуючи діапазон значень 10±38). Якщо речовинне число займає десять байтів, то мантисі приділяється 65 розрядів, а порядку - 14 розрядів. Це забезпечує точність 19-20 десяткових знаків мантиси й діапазон значень 10±4931.
Поняття типу даних. Як уже говорилося, мінімально адресуемою одиницею пам'яті є байт, але подання числа вимагає більшого обсягу. Очевидно, такі числа займуть групу байт, а адресою числа буде адреса першого байта групи. Отже, довільно взятий з пам'яті байт нічого нам не скаже про те, частиною якого інформаційного об'єкта він є - цілого числа, числа із плаваючої коми або команди. Резюмуючи вищесказане, можна зробити висновок, що крім завдання подання даних у двійковому коді, паралельно вирішується зворотне завдання - завдання інтерпретації кодів, тобто як з кодів відновити первісні дані.
2 ПРАКТИЧНА ЧАСТИНА
2.1 Переклад символів імені у послідовність цифр 16-річної системи числення
Використовуючи таблицю ASCII кодів перекладіть своє прізвище або ім’я (але менш чим 5 літер) у послідовність цифр 16-річної системи числення, а потім у послідовність двійкових біт (табл. 4).
Таблиця 4. Переклад літер у 16- та 2-річну СЧ
| Ім’я | v | a | l | e | r | a |
| 16-річна система числення | 0x076 | 0x061 | 0x06C | 0x065 | 0x072 | 0x061 |
| Послідовність двійкових біт | 1110110 | 1100001 | 1101100 | 1100101 | 1110010 | 1100001 |
2.2 Доповнення послідовності двійковими бітами коду Хемінга
Користуючись викладеним теоретичним матеріалом доповніть послідовність двійкових біт бітами коду Хемінга.
Користуючись інформацією, яка викладена у методичних вказівках що до виконання курсової роботи з дисципліни "АРХІТЕКТУРА КОМП’ЮТЕРІВ" доповнюємо послідовність двійковими бітами коду Хемінга табл. 5.
Таблиця 5. Двійкова послідовність символів імені
| Позиція біта | 47 | 46 | 45 | 44 | 43 | 42 | 41 | 40 | 39 | 38 | 37 | 36 | 35 | 34 | 33 | 32 |
| Значення біта | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 |
| Позиція біта | 31 | 30 | 29 | 28 | 27 | 26 | 25 | 24 | 23 | 22 | 21 | 20 | 19 | 18 | 17 | 16 |
| Значення біта | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 0 |
| Позиція біта | 15 | 14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
|
| Значення біта | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 |
|
Доповнюємо кодову послідовність бітами коду Хемінга. Результат у табл. 6.
Таблиця 6. Двійкова послідовність символів імені з позиціями контрольних бітів.
| Позиція біта | 53 | 52 | 51 | 50 | 49 | 48 | 47 | 46 | 45 | 44 | 43 | 42 | 41 | 40 | 39 |
| Значення біта | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 |
| Позиція біта | 38 | 37 | 36 | 35 | 34 | 33 | 32 | 31 | 30 | 29 | 28 | 27 | 26 | 25 | 24 |
| Значення біта | 0 | 1 | 1 | 0 | 1 | 1 | * | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 1 |
| Позиція біта | 23 | 22 | 21 | 20 | 19 | 18 | 17 | 16 | 15 | 14 | 13 | 12 | 11 | 10 | 9 |
| Значення біта | 0 | 1 | 0 | 1 | 1 | 1 | 0 | * | 0 | 1 | 0 | 0 | 1 | 1 | 0 |
| Позиція біта | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
|
||||||
| Значення біта | * | 0 | 0 | 0 | * | 1 | * | * |
|
* - позиції, де розміщуються контрольні біти
Контрольні біти резервуються цілою ступінню двійки. Оскільки номера контрольних біт становлять ступінь двійки, то з ростом розрядності кодового слова вони розташовуються все рідше і рідше. Контрольна сума формується шляхом використання операції XoR над кодами позицій ненульових бітів. Позиції ненульових бітів приведено в таблиці 7.
Таблиця 7. Позиції ненульових бітів
| Позиція | Код |
| 3 | 000011 |
| 10 | 001010 |
| 11 | 001011 |
| 14 | 001110 |
| 18 | 010010 |
| 19 | 010011 |
| 20 | 010100 |
| 22 | 010110 |
| 24 | 011000 |
| 27 | 011011 |
| 28 | 011100 |
| 33 | 100001 |
| 34 | 100010 |
| 36 | 100100 |
| 37 | 100101 |
| 39 | 100111 |
| Позиція | Код |
| 44 | 101100 |
| 45 | 101101 |
| 48 | 110000 |
| 49 | 110001 |
| 51 | 110011 |
| 52 | 110100 |
| 53 | 110101 |
Контрольна сума приведена в таблиці 8.
Таблиця 8. Контрольна сума.
| Позиція біта | 6 | 5 | 4 | 3 | 2 | 1 |
| онтр. Сума | 0 | 0 | 0 | 1 | 1 | 1 |
Таким чином приймач буде мати з розрахованими контрольними бітами (табл. 9).
Таблиця 9. Кодова послідовність на стороні приймача.
| Позиція біта | 53 | 52 | 51 | 50 | 49 | 48 | 47 | 46 | 45 | 44 | 43 | 42 | 41 | 40 | 39 |
| Значення біта | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 |
| Позиція біта | 38 | 37 | 36 | 35 | 34 | 33 | 32 | 31 | 30 | 29 | 28 | 27 | 26 | 25 | 24 |
| Значення біта | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 1 |
| Позиція біта | 23 | 22 | 21 | 20 | 19 | 18 | 17 | 16 | 15 | 14 | 13 | 12 | 11 | 10 | 9 |
| Значення біта | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 0 |
Таблиця 9. Продовження
| Позиція біта | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| Значення біта | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 |
Просумуємо кодову послідовність за допомогою операції XoR ще раз (табл. 10) і будемо мати нуль.
Таблиця 10. Контрольна сума кодової послідовності.
| Позиція біта | 6 | 5 | 4 | 3 | 2 | 1 |
| Контр. Сума | 0 | 0 | 0 | 0 | 0 | 0 |
2.3 Заміна на протилежне значення біту і можливість його виправлення
Змініть значення N-ного біту отриманої послідовності на протилежне та покажіть можливість його відновлення (де N – це ваш номер за журналом академічної групи). У доповнення до N-того біту також змініть на протилежне значення (35 – N) біту. Чи є можливість тепер відновити інформацію? Наведіть пояснення.
Змінемо у кодовій послідовності біт (0→1) під номером (35 – N), де N = 3. Маємо змінений біт під номером 32 (табл. 11).
Таблиця 11. Кодова послідовність з помилкою.
| Позиція біта | 53 | 52 | 51 | 50 | 49 | 48 | 47 | 46 | 45 | 44 | 43 | 42 | 41 | 40 | 39 |
| Значення біта | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 |
| Позиція біта | 38 | 37 | 36 | 35 | 34 | 33 | 32 | 31 | 30 | 29 | 28 | 27 | 26 | 25 | 24 |
| Значення біта | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 1 |
| Позиція біта | 23 | 22 | 21 | 20 | 19 | 18 | 17 | 16 | 15 | 14 | 13 | 12 | 11 | 10 | 9 |
| Значення біта | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 0 |
| Позиція біта | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
|
||||||
| Значення біта | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 |
|
Просумуємо коди позицій ненульових бітів за допомогою операції XoR ще раз (табл. 12):
Таблиця 12. Контрольна сума позицій ненульових бітів з помилкою
| Позиція біта | 6 | 5 | 4 | 3 | 2 | 1 |
| Контр. Сума | 1 | 0 | 0 | 0 | 0 | 0 |
Контрольна сума дорівнює позиції біта, де сталася помилка. Для виправлення помилки приймачу треба інвертувати біт, номер якого вказаний у контрольній сумі (табл. 12).
2.4 Написання програми кодування слова
Написати програму, яка дозволяє кодувати слова довжиною до 10 літер за схемою «ASCII-код → двійковий код → код Хемінга».
Збудуємо блок-схему алгоритму функціонування програми (мал. 10.).
Користуючись блок-схемою та алгоритмом для побудови коду Хемінга напишемо програму на алгоритмічному язиці Paskal (додаток А).
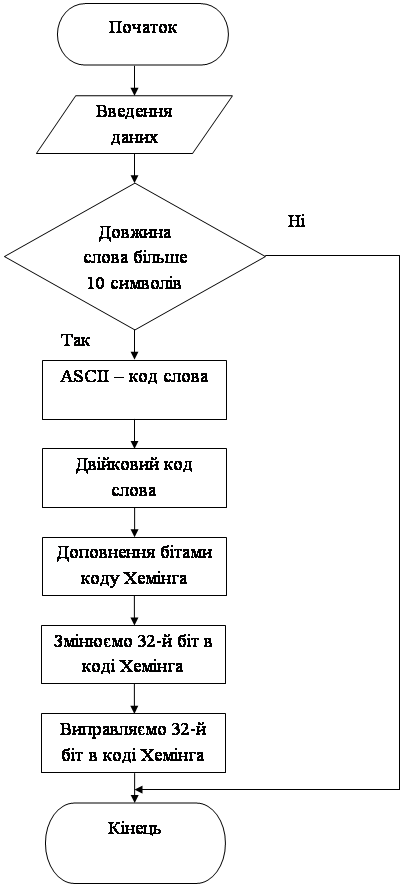
Малюнок 10. Блок-схема алгоритму програми
ВИСНОВКИ
У результаті виконаної курсової роботи було досягнуто наступних результатів:
1. У першому розділі було розглянуто питання та проблеми, пов'язані з динамічною оперативною пам'яттю (Dynamic RAM — DRAM), яка використовується в більшості систем оперативної пам'яті сучасних персональних комп'ютерів. Основна перевага пам'яті цього типу полягає в тому, що її комірки упаковані дуже щільно, тобто в невелику мікросхему можна упакувати багато бітів, а значить, на їх основі можна побудувати пам'ять великої ємкості. Елементи пам'яті в мікросхемі DRAM — це крихітні конденсатори, які утримують заряди. Саме так (наявністю або відсутністю зарядів) і кодуються біти. Проблеми, пов'язані з пам'яттю цього типа, викликані тим, що вона динамічна, тобто повинна постійно регенеруватися, оскільки інакше електричні заряди в конденсаторах пам'яті «стікатимуть» і дані будуть втрачені.
2. Термін інформація – латинського походження (informatio), означає роз’яснення, повідомлення, поінформованість. Інформація є одним з найцінніших ресурсів суспільства поряд з такими природними багатствами як нафта, газ та інші. Отже, методи та засоби переробки інформації як і переробки матеріальних ресурсів, можна визначити як технологію.
Одиницею інформації в комп’ютері є один біт. Один біт може приймати лише одне з двох можливих значень, а тому не може бути використаний для представлення великої кількості інформації. Числові величини в комп’ютері (в тому числі коди символів) представлені в двійковій позиційній системі числення (системі числення з основою 2).
Це означає, що для запису будь-якого числа можуть використовуватися лише дві цифри 0 та 1. Таким чином уся інформація в ЕОМ представлена у виді послідовності 0 та 1.
3. В елементах пам’яті, виготовлюваних у вигляді напівпровідникових ВІС, а також в процесорах підвищеної надійності використовується оперативний апаратний контроль за допомогою кодів Хемінга. У практичній частині курсової роботи були реалізовані питання, що до алгоритмів кодування Хемінга довільної послідовності кодів, та виправлення помилок у цій послідовності.
4. При роботі з кодовими послідовностями використовувались методи і принципи, які дозволяли знаходити , виправляти, корегувати та визначати помилки у послідовностях кодів Хемінга.
5. Також була написана програма, яка дозволяє кодувати слова довжиною до 10 літер за схемою «ASCII-код → двійковий код → код Хемінга».
ЛІТЕРАТУРНІ ДЖЕРЕЛА
[1] Т Кохонен. Ассоциативные запоминающие устройства. Пер. с англ. Мир, М. 384 с. (1982).
[2] Л.П.Ланцов, Л.Н.Зворыкин, И.Ф.Осипов. Цифровые устройства на комплементарных МОПинтегральных микросхемах. Радио и связь, М. 272 с. 1983.
[3] О.Н. Лебедев. Применение микросхем памяти в электронных устройствах. Радио и связь, М. 216 с. (1994).
[4] О.Н. Лебедев, А-Й.К. Марцинкчвичус, Э-Ф.К. Баганскис. Микросхемы памяти. ЦАП и АЦП. КУбК, М. 384 с. (1996).
[5] О.Н. Лебедев, А.И. Мирошниченко, В.А. Телец. Изделия электронной техники. Цифровые микросхемы.Микросхемы памяти. Микросхемы ЦАП И АЦП. Радио и связь, М. 248 с. (1994).
[6] А.Х.Мурсаев, Е.П.Угрюмов. Структуры и схемотехника современных нтегральных полупроводниковых запоминающих устройств.ГЭТУ,СПб.69 с. 1997.
[7] D. Kresta, T. Johnson. High-Level Design Methodology Comes Into Its Own // Electronic Design, 12, pp. 57-60 (1999).
[8] Y. Oshima, B. Sheu, S. Jen. High-Speed Memory Architectures for Multimedia Applications // IEEE Circuits & Devices, 1(13), pp. 8-13 (1997).
[9] Y. Takai, M. Nagase, M. Kitamura. 250 Mbyte/s Synchronous DRAM Using a 3-Stage-Pipelined Architecture //IEEE Journal of Solid State Circuits, 4(29), pp. 426-429 (1994).
[10] S. Novosiadlyi, M. Mykhalchuk, D. Fedasyuk. Basic Principles and Elements of highly effective System Technology of VLSI Microelectronics // Proceedings of the 6-th International Conference“ Mixed Design of Integrated Circuits and Sistems MIXDES'-99“, Krakov, Poland, pp. 267-270 (1999).
[11] Таненбаум Э. Архитектура компьютера. – СПб.: Питер, 2002. – 704 с.
[12] Блейхут Р. Теория и практика кодов, контролирующих ошибки. – М.: Мир, 1986. – 576 с.
ДОДАТОК А
Текст програми
Program Heming;
uses Crt;
const APower2: array[0..7] of Integer = (1, 2, 4, 8, 16, 32, 64, 128);
{ Массив степеней 2-ки}
var
ASymbol: array [1..8] of ShortInt; { Массив для хранения бинарного кода символа}
ABinCod: array [1..80] of ShortInt; { Массив для хранения бинарного кода слова}
AContrSum: array [0..7] of Integer; { Массив для хранения контрольных сумм}
AHemCod: array [1..88] of ShortInt; { Массив для хранения бинарного кода}
{ дополненного контрольными битами}
NBinCod, NHemCod: Integer; { Количество битов бинарного и кодированного} { видов слова соответственно}
i, j, k, n, NCur: Integer; { вспомогательные переменные}
NContr: Integer; { счетчик контрольных битов}
Slovo, ASCIICod, BinCod, HemCod: String;
procedure DecToBin(n: Integer); { процедура перевода десятичного числа в массив битов}
var i: Integer;
begin
for i:=1 to 8 do ASymbol[i]:=0;
i:=8;
while n>1 do
begin
ASymbol[i]:=n mod 2;
n:=n div 2;
dec(i);
end;
ASymbol[i]:=n;
end;
function CheckCod: Integer; { Процедура проверки кода на наличие повреждения}
var i, j, n, Res:Integer; { возвращаемое значение - номер поврежденного бита}
begin { или 0, если код не поврежден}
for i:=0 to 7 do { определение количества контрольных битов}
if NHemCod<APower2[i] then
begin
NContr:=i;
Break;
end;
for i:=0 to NContr-1 do AContrSum[i]:=0; { обнуление контрольных сумм}
NCur:=0;
for i:=1 to NHemCod do
if i=APower2[NCur] then inc(NCur) { если номер бита - степень 2-ки, пропускаем его}
else if AHemCod[i]>0 then { иначе если бит - 1-ца прибавляем 1 к каждому}
begin { контрольному биту, контролирующий i-й, для чего}
n:=i; { раскладываем i по степеням двойки}
for j:=NContr-1 downto 0 do
if n>=APower2[j] then
begin
inc(AContrSum[j]);
n:=n-APower2[j];
end;
end;
Res:=0; { определение номера поврежденного бита по несовпавшим}
for i:=0 to NContr-1 do { контрольным суммам}
if (AContrSum[i] mod 2)<>AHemCod[APower2[i]] then Res:=Res+APower2[i];
CheckCod:=Res;
end;
Begin
ClrScr;
Writeln(' ПРОГРАММА ДЛЯ ПЕРЕВОДА СЛОВ В КОД ХЕМИНГА');
Write('Введите слово для кодирования (максимум - 10 букв):');
Readln(Slovo);
if Length(Slovo)<1 then { проверка наличия введенных символов}
begin
Writeln('Нужно ввести слово');
Halt;
end;
if Length(Slovo)>10 then { проверка длины слова}
begin
Writeln('Длина слова - не более 10 символов');
Halt;
end;
BinCod:='';
HemCod:='';
Write('ASCII-код слова: ');
for i:=1 to Length(Slovo) do
begin
Write(Ord(Slovo[i]), ' ');
{ перевод символа в ASCII-код}
DecToBin(Ord(Slovo[i])); { перевод символа в бинарный код}
for j:=1 to 8 do
ABinCod[(i-1)*8+j]:=ASymbol[j];
{ добавление бинарного кода символа к слову}
end;
Writeln;
NBinCod:=Length(Slovo)*8;
while ABinCod[1]=0 do { удаление лидирующих нулей в двоичном виде слова}
begin
for i:=1 to NBinCod-1 do ABinCod[i]:=ABinCod[i+1];
dec(NBinCod);
end;
Write('Бинарный код слова: ');
for i:=1 to NBinCod do Write(ABinCod[i]);
Writeln;
for i:=0 to 7 do AContrSum[i]:=0; { обнуление массивов}
for i:=1 to 88 do AHemCod[i]:=0;
i:=NBinCod;
j:=1;
NContr:=0;
while i>0 do { кодируем слово начиная с конца}
begin
if j=APower2[NContr] then inc(NContr) { если номер бита - степень 2-ки резервируем его для контрольного бита}
else if ABinCod[i]>0 then { записываем информационный бит, если он - 1-ца}
begin
AHemCod[j]:=1;
n:=j;
k:=0;
while n>1 do { увеличение контрольных сумм битов, контролирующих
j-й символ кодированной строки}
begin
if Odd(n) then inc(AContrSum[k]);
n:=n div 2;
inc(k);
end;
inc(AContrSum[k]);
dec(i);
end
else dec(i); { если инф. бит 0 - переходим на следующий без увеличения
контрольных сумм}
inc(j);
end;
NHemCod:=j-1; { длина кодированной последовательности}
for i:=0 to NContr-1 do if Odd(AContrSum[i]) then AHemCod[APower2[i]]:=1;
{ расчет значений контрольных битов по контрольным суммам}
{ вывод кодированной последовательности}
Write('Код Хеминга слова: ');
for i:=NHemCod downto 1 do Write(AHemCod[i]);
Writeln;
Writeln;
Writeln('Изменяем 32-й бит в коде Хеминга');
if AHemCod[32]=1 then AHemCod[32]:=0
else AHemCod[32]:=1;
Write('Поврежденный код Хеминга: ');
for i:=NHemCod downto 1 do Write(AHemCod[i]);
Writeln;
n:=CheckCod; { определение поврежденного бита (если таковой есть)}
if n>NHemCod then { количество повреждений явно больше 1}
Writeln('По-видимому ошибок больше одной, декодирование невозможно')
else if n>0 then { вывод исправленного кода и сообщения об исправлении}
begin
if AHemCod[n]=0 then AHemCod[n]:=1 else AHemCod[n]:=0;
Writeln('Исправлен ', n, '-й бит');
Write('Исправленный код Хеминга: ');
for i:=NHemCod downto 1 do Write(AHemCod[i]);
Writeln;
end
else Writeln('Код верен. Исправления не требуется.');
Writeln;
End.