Реферат: Социально-экономические явления и методы исследования связей между ними
Содержание
1. Виды и формы связей социально- экономических явлений
2. Основные статистические методы выявления корреляционной связи
3. Корреляционно-регрессионный анализ. Уравнение парной регрессия: экономическая интерпретация и оценка значимости
4. Оценка качества однофакторных линейных моделей
5. Анализ и прогнозирование экономических показателей на основе регрессионных моделей
6. Измерение связей неколичественных переменных
Литература
1. Виды и формы связей социально- экономических явлений
Экономические данные представляют собой количественные характеристики каких-либо экономических объектов или процессов. Они формируются под действием множества факторов, не все из которых доступны внешнему контролю. Неконтролируемые факторы могут принимать случайные значения из некоторого множества значений и тем самым обуславливать случайность данных, которые они определяют. Стохастическая (вероятностная) природа экономических данных обуславливает необходимость применения соответствующих статистических методов для их обработки и анализа.
Статистические распределения характеризуются наличием более или менее значительной вариации в величине признака у отдельных единиц совокупности. Естественно, возникает вопрос о том, какие же причины формируют уровень признака в данной совокупности и каков конкретный вклад каждой из них. Изучение зависимости вариации признака от окружающих условий и составляет содержание теории корреляции.
Изучение действительности показывает, что вариация каждого изучаемого признака находится в тесной связи и взаимодействии с вариацией других признаков, характеризующих исследуемую совокупность единиц. Вариация уровня производительности труда работников предприятий зависит от степени совершенства применяемого оборудования, технологии, организации производства, труда и управления и других самых различных факторов.
При изучении конкретных зависимостей одни признаки выступают в качестве факторов, обусловливающих изменение других признаков. Признаки этой первой группы в дальнейшем будем называть признаками-факторами (факторными признаками); а признаки, которые являются результатом влияния этих факторов, будем называть результативными. Например, при изучении зависимости между производительностью труда рабочих и энерговооруженностью их труда уровень производительности труда является результативным признаком, а энерговооруженность труда рабочих - факторным признаком.
Рассматривая зависимости между признаками, необходимо выделить, прежде всего, две категории зависимости: 1) функциональные и 2) корреляционные.
Функциональные связи характеризуются полным соответствием между изменением факторного признака и изменением результативной величины, и каждому значению признака-фактора соответствуют вполне определенные значения результативного признака. Функциональная зависимость может связывать результативный признак с одним или несколькими факторными признаками. Так, величина начисленной заработной платы при повременной оплате труда зависит от количества отработанных часов.
В корреляционных связях между изменением факторного и результативного признака нет полного соответствия, воздействие отдельных факторов проявляется лишь в среднем при массовом наблюдении фактических данных. Одновременное воздействие на изучаемый признак большого количества самых разнообразных факторов приводит к тому, что одному и тому же значению признака-фактора соответствует целое распределение значений результативного признака, поскольку в каждом конкретном случае прочие факторные признаки могут изменять силу и направленность своего воздействия.
При сравнении функциональных и корреляционных зависимостей следует иметь в виду, что при наличии функциональной зависимости между признаками можно, зная величину факторного признака, точно определить величину результативного признака. При наличии же корреляционной зависимости устанавливается лишь тенденция изменения результативного признака при изменении величины факторного признака. В отличие от жесткости функциональной связи корреляционные связи характеризуются множеством причин и следствий и устанавливаются лишь их тенденции. Статистические показатели могут состоять между собой в следующих основных видах связи: балансовой, компонентной, факторной и др.
Балансовая связь — характеризует зависимость между источниками формирования ресурсов (средств) и их использованием.
![]()
![]() — остаток на начало отчетного
периода;
— остаток на начало отчетного
периода;
![]() — поступление за период;
— поступление за период;
![]() — выбытие в изучаемом периоде;
— выбытие в изучаемом периоде;
![]() — остаток на конец отчетного
периода.
— остаток на конец отчетного
периода.
Левая часть формулы характеризует предложение
![]() ,
,
а правая часть — использование ресурсов
![]()
Компонентные связи показателей характеризуются тем, что изменение статистического показателя определяется изменением компонентов, входящих в этот показатель, как множители:
![]()
В статистике компонентные связи
используются в индексном методе. Например, индекс товарооборота в фактических
ценах ![]() представляет произведение
двух компонентов, на пример, — индекса товарооборота в сопоставимых ценах
представляет произведение
двух компонентов, на пример, — индекса товарооборота в сопоставимых ценах ![]() и индекса цен
и индекса цен ![]() , т.е.
, т.е.
![]()
Важное значение компонентной связи состоит в том, что она позволяет определять величину одного из неизвестных компонентов:
![]() или
или ![]()
Факторные связи характеризуются тем, что они проявляются в согласованной вариации изучаемых показателей. При этом одни показатели выступают как факторные, а другие — как результативные.
Факторные связи могут рассматриваться как функциональные и корреляционные.
При функциональной связи
изменение результативного признака ![]() всецело
зависит от изменения факторного признака
всецело
зависит от изменения факторного признака ![]() :
:
При корреляционной связи
изменение результативного признака ![]() не
всецело зависит от факторного признака
не
всецело зависит от факторного признака ![]() ,
а лишь частично, так как возможно влияние прочих факторов
,
а лишь частично, так как возможно влияние прочих факторов ![]() :
:
![]()
Примером корреляционной связи
показателей является зависимость сумм издержек обращения от объема
товарооборота. В этой связи, помимо факторного признака — объема товарооборота ![]() , на результативный признак
(сумму издержек обращения
, на результативный признак
(сумму издержек обращения ![]() ) влияют
и другие факторы, в том числе и не учтенные
) влияют
и другие факторы, в том числе и не учтенные ![]() .
Поэтому корреляционные связи не являются полными (тесными) зависимостями.
.
Поэтому корреляционные связи не являются полными (тесными) зависимостями.
2. Основные статистические методы выявления корреляционной связи
К методам исследования взаимосвязей относятся: метод взаимосвязанных параллельных рядов, балансовый метод, индексный метод, метод аналитических группировок, корреляционные таблицы и графический метод.
Метод взаимосвязанных параллельных рядов состоит в установлении связей между экономическими явлениями посредством сопоставления показателей двух или нескольких рядов. Для этого признак-фактор ранжируется, т.е. располагается в порядке возрастания или убывания признака и соответственно ему записываются значения результативного признака. Путем сравнения взаимосвязанных рядов выявляется наличие связи и ее направление. Можно сравнивать временные и территориальные ряды.
Балансовый метод применяется для анализа связей и пропорций в экономике. Баланс представляет систему показателей, состоящей из равенства ресурсов и их распределения. Схема баланса может быть представлена равенством:
а + б= в + с
(Остаток начальный + Поступление = Расход + Остаток конечный).
Индексный
метод - метод анализа компонентных связей.
Это вид связей, когда изменение какого-то сложного явления целиком определяется
изменением компонентов, входящих в это сложное явление как множители (а=
бв, или ![]() ). Индексный
метод анализа позволяет определить роль отдельных компонентов в совокупном
изменении сложного явления.
). Индексный
метод анализа позволяет определить роль отдельных компонентов в совокупном
изменении сложного явления.
Метод аналитических группировок - это установление связи между двумя и более признаками группировкой единиц по факторному признаку, а затем в группах вычисление средних и относительных величин результативного признака. Для оценки тесноты связи одновременно с методом группировок рассчитываются коэффициенты детерминации и эмпирическое корреляционное отношение.
Корреляционная таблица охватывает два ряда распределения: один ряд представляет факторный признак, а другой - результативный. Концентрация частот около диагонали, соединяющей левый верхний угол с правым нижним углом таблицы, выражает прямую связь, и наоборот, концентрация частот около диагонали, соединяющей левый . нижний угол с правым верхним углом таблицы, выражает обратную связь. Интенсивная концентрация частот около диагонали таблицы указывает на существование тесной корреляционной связи. Корреляционная таблица дает более правильную характеристику связи при условии, что число групп по двум признакам одинаково.
Графический метод состоит в построении графиков. На графике значения факторного признака наносятся на ось абсцисс, а результативного признака - на ось ординат. Если нанести на график средние значения результативного признака, то получим ломаную линию, которая называется эмпирической линией регрессии.
3. Корреляционно-регрессионный анализ. Уравнение парной регрессия: экономическая интерпретация и оценка значимости
Основная задача корреляционного анализа заключается в выявлении взаимосвязи между случайными переменными путем точечной и интервальной оценки парных (частных) коэффициентов корреляции, вычисления и проверки значимости множественных коэффициентов корреляции и детерминации. Кроме того, с помощью корреляционного анализа решаются следующие задачи: отбор факторов, оказывающих наиболее существенное влияние на результативный признак, на основании измерения степени связи между ними; обнаружение ранее неизвестных причинных связей. Корреляция непосредственно не выявляет причинных связей между параметрами, но устанавливает численное значение этих связей и достоверность суждений об их наличии.
Регрессионный анализ предназначен для исследования зависимости исследуемой переменной от различных факторов и отображения их взаимосвязи в форме регрессионной модели.
В регрессионных моделях зависимая (объясняемая) переменная Y может быть представлена в виде функции f (X1, X2, X3, … Xm), где X1, X2, X3, … Xm - независимые (объясняющие) переменные, или факторы. В качестве зависимой переменной может выступать практически любой показатель, характеризующий, например, деятельность предприятия или курс ценной бумаги. В зависимости от вида функции f (X1, X2, X3, … Xm) модели делятся на линейные и нелинейные. В зависимости от количества включенных в модель факторов Х модели делятся на однофакторные (парная модель регрессии) и многофакторные (модель множественной регрессии).
Связь между переменной Y и m независимыми факторами можно охарактеризовать функцией регрессии Y= f (X1, X2, X3, … Xm), которая показывает, каково будет в среднем значение переменной yi, если переменные xi примут конкретные значения.
Данное обстоятельство позволяет использовать модель регрессии не только для анализа, но и для прогнозирования экономических явлений.
Под линейностью здесь имеется в виду, что переменная y предположительно находиться под влиянием переменной x в следующей зависимости:
![]() ,
,
где ![]() - постоянная
величина (или свободный член уравнения),
- постоянная
величина (или свободный член уравнения), ![]() -
коэффициент регрессии, определяющий наклон линии, вдоль которой рассеяны данные
наблюдений. Это показатель, характеризующий изменение переменной
-
коэффициент регрессии, определяющий наклон линии, вдоль которой рассеяны данные
наблюдений. Это показатель, характеризующий изменение переменной ![]() , при изменении значения
, при изменении значения ![]() на единицу. Если
на единицу. Если ![]() - переменные
- переменные ![]() и
и ![]() положительно
коррелированные, если
положительно
коррелированные, если ![]() < 0 – отрицательно коррелированны;
< 0 – отрицательно коррелированны; ![]() - независимые
одинаково распределенные случайные величины – остаток с нулевым математическим
ожиданием (
- независимые
одинаково распределенные случайные величины – остаток с нулевым математическим
ожиданием (![]() ) и постоянной дисперсией (
) и постоянной дисперсией (![]() ). Она отражает тот факт,
что изменение
). Она отражает тот факт,
что изменение ![]() будет неточно
описываться изменением Х – присутствуют другие факторы, неучтенные в данной
модели.
будет неточно
описываться изменением Х – присутствуют другие факторы, неучтенные в данной
модели.
Для оценки параметров регрессионного
уравнения наиболее часто используют метод наименьших квадратов (МНК),
который минимизирует сумму квадратов отклонения наблюдаемых значений ![]() от модельных
значений
от модельных
значений ![]() .
.
Согласно принципу метода
наименьших квадратов, оценки ![]() и
и
![]() находятся путем
минимизации суммы квадратов
находятся путем
минимизации суммы квадратов
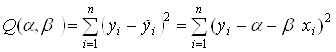
по всем возможным значениям ![]() и
и
![]() при заданных
(наблюдаемых) значениях
при заданных
(наблюдаемых) значениях![]() . Задача
сводится к известной математической задаче поиска точки минимума функции двух
переменных. Точка минимума находится путем приравнивания нулю частных
производных функции
. Задача
сводится к известной математической задаче поиска точки минимума функции двух
переменных. Точка минимума находится путем приравнивания нулю частных
производных функции ![]() по
переменным
по
переменным ![]() и
и ![]() . Это приводит к системе
нормальных уравнений
. Это приводит к системе
нормальных уравнений
![]()
![]()
решением которой и является пара ![]() ,
, ![]() . Согласно правилам
вычисления производных имеем
. Согласно правилам
вычисления производных имеем
![]()
![]()
![]()
![]()
так что искомые значения ![]() ,
,
![]() удовлетворяют соотношениям
удовлетворяют соотношениям
![]()
![]()
Эту систему двух уравнений можно записать также в виде

Эта система является системой двух линейных уравнений с двумя неизвестными и может быть легко решена, например, методом подстановки. В результате получаем
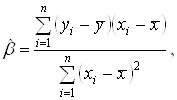 (3.2)
(3.2) ![]()
Такое решение может существовать только при выполнении условия
![]()
что равносильно отличию от нуля определителя системы нормальных уравнений. Действительно, этот определитель равен

Последнее условие называется условием
идентифицируемости модели наблюдений ![]() ,
и означает, что не все значения
,
и означает, что не все значения ![]() совпадают
между собой. При нарушении этого условия все точки
совпадают
между собой. При нарушении этого условия все точки ![]() , лежат на одной вертикальной
прямой
, лежат на одной вертикальной
прямой ![]()
Оценки ![]() и
и ![]() называют оценками
наименьших квадратов. Обратим еще раз внимание на полученное выражение
для
называют оценками
наименьших квадратов. Обратим еще раз внимание на полученное выражение
для ![]() . Нетрудно видеть, что
в это выражение входят уже знакомые нам суммы квадратов, участвовавшие ранее в
определении выборочной дисперсии
. Нетрудно видеть, что
в это выражение входят уже знакомые нам суммы квадратов, участвовавшие ранее в
определении выборочной дисперсии
![]()
Для двух переменных ![]() теоретический
коэффициент корреляции определяется следующим образом:
теоретический
коэффициент корреляции определяется следующим образом:
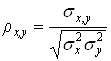 .
.
где
![]() - дисперсии случайных
переменных
- дисперсии случайных
переменных ![]() , а
, а ![]() их ковариация.
их ковариация.
Парный коэффициент корреляции является показателем тесноты связи лишь в случае линейной зависимости между переменными и обладает следующими основными свойствами:
Коэффициент корреляции принимает значение в интервале (-1,+1), или
|rxy| < 1.
Коэффициент корреляции не зависит от выбора начала отсчета и единицы измерения, т.е.
r (α1X+β; α2Y+β)= rxy,
где α1, α2, b - постоянные величины, причем α1>0, α2>0.
Случайные величины Х, Y, можно уменьшать (увеличивать) в
α раз, а также вычитать или прибавлять к значениям ![]() одно и тоже число β -
это не приведет к изменению коэффициента корреляции r.
одно и тоже число β -
это не приведет к изменению коэффициента корреляции r.
При r
= ±1 случайные величины![]() связаны линейной
зависимостью, т.е.
связаны линейной
зависимостью, т.е.
![]() .
.
При r = 0 линейная корреляционная связь отсутствует.
В практических расчетах коэффициент
корреляции r
генеральной совокупности обычно не известен. По результатам выборки может быть
найдена его точечная оценка – выборочный коэффициент корреляции r, так
как выборочная совокупность переменных ![]() случайна,
то в отличие от параметра r , r – случайная величина. Оценкой коэффициента корреляции
случайна,
то в отличие от параметра r , r – случайная величина. Оценкой коэффициента корреляции ![]() является выборочный
парный коэффициент корреляции:
является выборочный
парный коэффициент корреляции:
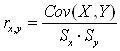 =
= 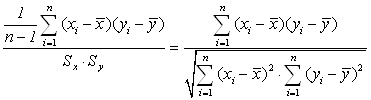 , (3.3)
, (3.3)
![]()
![]()
Для оценки значимости коэффициента корреляции применяется t - критерий Стьюдента. При этом фактическое значение этого критерия определяется по формуле:
 (3.4)
(3.4)
Вычисленное по этой формуле значение tнабл сравнивается с критическим значением t-критерия, которое берется из таблицы значений t Стьюдента с учетом заданного уровня значимости и числа степеней свободы.
Если tнабл > tкр, то полученное значение коэффициента корреляции признается значимым (то есть нулевая гипотеза, утверждающая равенство нулю коэффициента корреляции, отвергается). И таким образом делается вывод о том, что между исследуемыми переменными есть тесная статистическая взаимосвязь.
Если значение ![]() близко
к нулю, связь между переменными слабая. Если случайные величины связаны
положительной корреляцией, это означает, что при возрастании одной случайной
величины другая имеет тенденцию в среднем возрастать. Если случайные величины
связаны отрицательной корреляцией, это означает, что при возрастании одной
случайной величины, другая имеет тенденцию в среднем убывать.
близко
к нулю, связь между переменными слабая. Если случайные величины связаны
положительной корреляцией, это означает, что при возрастании одной случайной
величины другая имеет тенденцию в среднем возрастать. Если случайные величины
связаны отрицательной корреляцией, это означает, что при возрастании одной
случайной величины, другая имеет тенденцию в среднем убывать.
4. Оценка качества однофакторных линейных моделей
Качество модели регрессии связывают с адекватностью модели
наблюдаемым (эмпирическим) данным. Проверка адекватности (или соответствия)
модели регрессии наблюдаемым данным проводится на основе анализа остатков - ![]() .
.
После
построения уравнения регрессии мы можем разбить значение у, в каждом
наблюдении на две составляющих - ![]() и
и ![]() ;
; ![]() (4.1)
(4.1)
Остаток
![]() представляет собой
отклонение фактического значения зависимой переменной от значения данной
переменной, полученное расчетным путем:
представляет собой
отклонение фактического значения зависимой переменной от значения данной
переменной, полученное расчетным путем: ![]() (
(![]() ). Если
). Если ![]() (
(![]() ), то для всех наблюдений
фактические значения зависимой переменной совпадают с расчетными
(теоретическими) значениями. Графически это означает, что теоретическая линия
регрессии (линия, построенная по функции
), то для всех наблюдений
фактические значения зависимой переменной совпадают с расчетными
(теоретическими) значениями. Графически это означает, что теоретическая линия
регрессии (линия, построенная по функции ![]() ) проходит через все точки корреляционного поля, что возможно
только при строго функциональной связи. Следовательно, результативный признак
) проходит через все точки корреляционного поля, что возможно
только при строго функциональной связи. Следовательно, результативный признак ![]() полностью обусловлен
влиянием фактора
полностью обусловлен
влиянием фактора ![]() .
.
На практике, как
правило, имеет место некоторое рассеивание точек корреляционного поля
относительно теоретической линии регрессии, т. е. отклонения эмпирических
данных от теоретических (![]() ).
Величина этих отклонений и лежит в основе расчета показателей качества
(адекватности) уравнения.
).
Величина этих отклонений и лежит в основе расчета показателей качества
(адекватности) уравнения.
При анализе качества модели регрессии
используется основное положение дисперсионного анализа , согласно которому общая
сумма квадратов отклонений зависимой переменной от среднего значения ![]() может быть разложена на
две составляющие — объясненную и необъясненную уравнением регрессии дисперсии:
может быть разложена на
две составляющие — объясненную и необъясненную уравнением регрессии дисперсии:
![]() (4.2)
(4.2)
где ![]() - значения y,
вычисленные по модели
- значения y,
вычисленные по модели ![]() .
.
Разделив правую
и левую часть (4.2) на ![]()
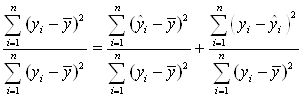
 .
.
Коэффициент детерминации определяется следующим образом:
 (4.3)
(4.3)
Коэффициент детерминации показывает долю вариации результативного признака, находящегося под воздействием изучаемых факторов, т. е. определяет, какая доля вариации признака Y учтена в модели и обусловлена влиянием на него факторов.
Чем ближе ![]() к 1,
тем выше качество модели.
к 1,
тем выше качество модели.
Для оценки качества регрессионных моделей целесообразно также использовать коэффициент множественной корреляции (индекс корреляции
R R = 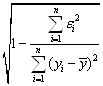 =
=  (4.4)
(4.4)
Данный коэффициент является универсальным, так как он отражает тесноту связи и точность модели, а также может использоваться при любой форме связи переменных.
При построении однофакторной модели он равен коэффициенту линейной корреляции
Очевидно, что чем меньше
влияние неучтенных факторов, тем лучше модель соответствует фактическим данным.
Также для оценки точности регрессионных
моделей целесообразно использовать среднюю относительную ошибку аппроксимации: ![]()
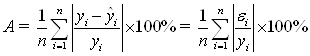 ( 4.5)
( 4.5)
Чем меньше рассеяние эмпирических точек вокруг теоретической линии регрессии, тем меньше средняя ошибка аппроксимации. Ошибка аппроксимации меньше 7 % свидетельствует о хорошем качестве модели.
После того как уравнение регрессии построено, выполняется проверка значимости построенного уравнения в целом и отдельных параметров.
Оценить значимость уравнения регрессии – это означает установить, соответствует ли математическая модель, выражающая зависимость между Y и Х, фактическим данным и достаточно ли включенных в уравнение объясняющих переменных Х для описания зависимой переменной Y
Оценка значимости
уравнения регрессии производится для того, чтобы узнать, пригодно уравнение
регрессии для практического использования (например, для прогноза) или нет. При
этом выдвигают основную гипотезу о незначимости уравнения в целом, которая
формально сводится к гипотезе о равенстве нулю параметров регрессии, или, что
то же самое, о равенстве нулю коэффициента детерминации: ![]() . Альтернативная ей гипотеза
о значимости уравнения — гипотеза о неравенстве нулю параметров регрессии.
. Альтернативная ей гипотеза
о значимости уравнения — гипотеза о неравенстве нулю параметров регрессии.
Для проверки значимости модели регрессии используется F-критерий Фишера, вычисляемый как отношение дисперсии исходного ряда и несмещенной дисперсии остаточной компоненты. Если расчетное значение с n1= k и n2 = (n - k - 1) степенями свободы, где k – количество факторов, включенных в модель, больше табличного при заданном уровне значимости, то модель считается значимой. Для модели парной регрессии:
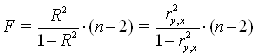 (4.6)
(4.6)
В качестве меры точности применяют
несмещенную оценку дисперсии остаточной компоненты, которая представляет собой
отношение суммы квадратов уровней остаточной компоненты к величине (n- k -1),
где k – количество факторов, включенных в модель. Квадратный корень из этой
величины (![]() ) называется стандартной
ошибкой оценки.
) называется стандартной
ошибкой оценки.
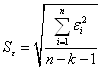 (4.7)
(4.7)
Для модели парной регрессии

Анализ статистической значимости параметров модели парной регрессии
![]()
Значения ![]() ,
соответствующие данным
,
соответствующие данным ![]() при
теоретических значениях
при
теоретических значениях ![]() и
и ![]() являются случайными.
Случайными являются и рассчитанные по ним значения коэффициентов
являются случайными.
Случайными являются и рассчитанные по ним значения коэффициентов ![]() и
и ![]() .
.
Надежность получаемых оценок ![]() и
и
![]() зависит от дисперсии
случайных отклонений (ошибок). По данным выборки эти отклонения и,
соответственно, их дисперсия не оцениваются – в расчетах используются отклонения
зависимой переменной
зависит от дисперсии
случайных отклонений (ошибок). По данным выборки эти отклонения и,
соответственно, их дисперсия не оцениваются – в расчетах используются отклонения
зависимой переменной ![]() от ее расчетных
значений
от ее расчетных
значений ![]() :
: ![]() . Так как ошибки (остатки)
. Так как ошибки (остатки) ![]() нормально распределены, то
среднеквадратическое отклонение ошибок используется для измерения этой
вариации. Среднеквадратические отклонения коэффициентов известны как стандартные
ошибки (отклонения):
нормально распределены, то
среднеквадратическое отклонение ошибок используется для измерения этой
вариации. Среднеквадратические отклонения коэффициентов известны как стандартные
ошибки (отклонения):
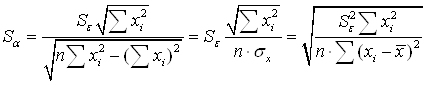
 (4.8)
(4.8)
где
![]() - среднее значение независимой
переменной х;
- среднее значение независимой
переменной х;
![]() стандартная ошибка,
вычисляемая по формуле (4.8);
стандартная ошибка,
вычисляемая по формуле (4.8);
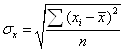 .
.
Проверка значимости отдельных коэффициентов регрессии связана с определением расчетных значений t-критерия (t–статистики) для соответствующих коэффициентов регрессии:
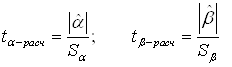 (4.9)
(4.9)
Затем расчетные значения ![]() сравниваются
с табличными tтабл. Табличное значение критерия
определяется при (n-2) степенях свободы (n - число наблюдений) и
соответствующем уровне значимости a (0,1; 0,05)
сравниваются
с табличными tтабл. Табличное значение критерия
определяется при (n-2) степенях свободы (n - число наблюдений) и
соответствующем уровне значимости a (0,1; 0,05)
Если расчетное значение t-критерия с (n - 2) степенями свободы превосходит его табличное значение при заданном уровне значимости, коэффициент регрессии считается значимым. В противном случае фактор, соответствующий этому коэффициенту, следует исключить из модели (при этом ее качество не ухудшится).
По имеющейся информации о результатах деятельности 19 Российских предприятий, стоящих по рейтингу на первых позициях, построить уравнение линейной зависимости прибыли предприятий от размера собственного капитала.
Собранный статистический материал представлен в таблице 1.
Таблица 1. Данные о величине собственного капитала и прибыли Российских предприятий за 2005
| Рейтинг | Название предприятия | Собственный капитал, млн. руб. | Прибыль, млн. руб. |
|
1 |
2 |
3 |
4 |
| 1 | "Газпром" | 2772000 | 348400 |
| 2 | РЖД | 1851000 | 237545 |
| 3 | ОАО "Сургутнефтегаз" | 707913 | 214479 |
| 4 | РАО "ЕЭС России" | 386200 | 203448 |
| 5 | Нефтяная компания "ЛУКойл" | 222156 | 126326 |
| 6 | ГМК "Норильский никель" | 208143 | 118159 |
| 7 | ТНК-ВР | 165000 | 110400 |
| 8 | "Связьинвест" | 167572 | 95700 |
| 9 | Нефтяная компания "Сибнефть" | 153000 | 84800 |
| 10 | АФК "Система" | 150844 | 76503 |
| 11 | Сбербанк России | 148000 | 62929 |
| 12 | “Татнефть” | 103653 | 36876 |
| 13 | "Северсталь" | 103275 | 34312 |
| 14 | Нефтегазовая компания "Славнефть" | 101270 | 29923 |
| 15 | Евраз Груп | 77558 | 29517 |
| 16 | "Русал" | 75600 | 28512 |
| 17 | АК "Транснефть" | 46629 | 4608 |
| 18 | АвтоВАЗ http://www.tatneft.ru/ | 43308 | 1400 |
| 19 | Магнитогорский металлургический комбинат | 28500 | 1345 |
На основании имеющихся данных найдем:
1)уравнение прямой регрессии У = а + bX , где У – прибыль предприятий (результативный признак), Х – размер собственного капитала (факторный признак).
2)тесноту связи между прибылью предприятий с помощью линейного коэффициента корреляции rху.
Получили, что коэффициенты регрессии а = 51,61 и b = 0,115. Таким образом, уравнение зависимости прибыли предприятий (У) от величины собственного капитала (Х) имеет вид: У = 51,61 + 0,115Х, т.е. при увеличении размера собственного капитала на 1 млн. руб. прибыль предприятий в среднем увеличивается на 115 тыс. руб.
Коэффициент корреляции rху = 0,867 свидетельствует о сильной и прямой связи между размером собственного капитала и прибылью организации.
Изобразим графически исходные данные о прибыли и размере собственного капитала и полученную прямую зависимости данных признаков.
5. Анализ и прогнозирование экономических показателей на основе регрессионных моделей
Регрессионные модели могут быть использованы для прогнозирования возможных ожидаемых значений зависимой переменной.
Прогнозируемое
значение переменной ![]() получается при
подстановке в уравнение регрессии
получается при
подстановке в уравнение регрессии
![]() (5.1)
(5.1)
ожидаемой величины фактора ![]() .
Данный прогноз называется точечным. Значение независимой переменной
.
Данный прогноз называется точечным. Значение независимой переменной ![]() не должно значительно отличаться от
входящих в исследуемую выборку, по которой вычислено уравнение регрессии.
не должно значительно отличаться от
входящих в исследуемую выборку, по которой вычислено уравнение регрессии.
Вероятность реализации точечного прогноза теоретически равна нулю. Поэтому рассчитывается средняя ошибка прогноза или доверительный интервал прогноза с достаточно большой надежностью.
доверительные
интервалы, зависят от стандартной ошибки , удаления ![]() от
своего среднего значения
от
своего среднего значения ![]() ,
количества наблюдений n и уровня значимости прогноза α. В
частности, для прогноза будущие значения
,
количества наблюдений n и уровня значимости прогноза α. В
частности, для прогноза будущие значения ![]() с
вероятностью (1 - α) попадут в интервал
с
вероятностью (1 - α) попадут в интервал
![]()
![]()
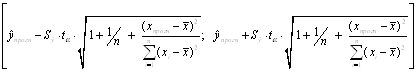 .
.
6. Измерение связей неколичественных переменных
Методы корреляционного и дисперсионного анализа не универсальны: их можно применять, если все изучаемые признаки являются количественными. При использовании этих методов нельзя обойтись без вычисления основных параметров распределения (средних величин, дисперсий), поэтому они получили название параметрических методов.
Между тем в статистической практике приходится сталкиваться с задачами измерения связи между качественными признаками, к которым параметрические методы анализа в их обычном виде неприменимы. Статистической наукой разработаны методы, с помощью которых можно измерить связь между явлениями, не используя при этом количественные значения признака, а значит, и параметры распределения. Такие методы получили название непараметрических.
Оценить тесноту связи между признаками можно с помощью коэффициентов взаимной сопряженности и коэффициентов контингенции или ассоциации.
В социально-экономических исследованиях нередко встречаются ситуации, когда признак не выражается количественно, однако единицы совокупности можно упорядочить. Такое упорядочение единиц совокупности по значению признака называется ранжированием. Примерами могут быть ранжирование студентов (учеников) по способностям, любой совокупности людей по уровню образования, профессии, по способности к творчеству и т.д.
При ранжировании каждой единице совокупности присваивается ранг, т. е. порядковый номер. При совпадении значения признака у различных единиц им присваивается объединенный средний порядковый номер. Например, если у 5-й и 6-й единиц совокупности значения признаков одинаковы, обе получат ранг, равный (5 + 6) / 2 = 5,5.
Измерение связи между ранжированными признаками производится с помощью ранговых коэффициентов корреляции Спирмена (р) и Кендэлла (X). Эти методы применимы не только для качественных, но и для количественных показателей, особенно при малом объеме совокупности, так как непараметрические методы ранговой корреляции не связаны ни с какими ограничениями относительно характера распределения признака.
Сущность метода Спирмена (Spearman) состоит в следующем:
1) располагают варианты факторного признака по возрастанию — ранжируют единицы по значению признака X;
2) для каждой единицы совокупности указывают ранг с точки зрения результативного признака У.
Если связь между признаками прямая, то с увеличением ранга признака X ранг признака У также будет возрастать; при тесной связи ранги признаков X и У в основном совпадут. При обратной связи возрастанию рангов признака X будет, как правило, соответствовать убывание рангов признака У. В случае отсутствия связи последовательность рангов признака У не будет обнаруживать никакого порядка возрастания или убывания.
Теснота связи между признаками оценивается ранговым коэффициентом корреляции Спирмена ( в случае, когда нет связанных рангов):

![]() - квадрат разности рангов;
- квадрат разности рангов;
n – число наблюдений ( число пар рангов).
Коэффициент корреляции Спирмена принимает значение в интервале (-1,+1). Чем ближе он к единице, тем более тесня связь между признаками. Знак коэффициента показывает направление связи.
Литература
1. Гусаров В.М., «Теория статистики», – М.: Аудит, ЮНИТИ, 2002;
2. Громыко Г.Л. Теория статистики: учеб. – М., Изд-во Инфра-М, 2000.
3. Ефимова М.П., Петрова Е.В., Румянцев В.Н., «Общая теория статистики», - М.: “Инфра - М”, 2003;
4. «Практикум по статистике: Учеб. пособие для вузов» / Под ред. В. М. Симчеры / ВЗФЭИ. – М.: ЗАО «Финстатинформ», 2000; Симчера В.М. Практикум по статистике: учеб. пособ. – М. Изд-во Финстатинформ, 1999.
5. Шмойлва Р.А. Практикум по теории статистики: учеб. пособ. – М., Изд-во Финансы и статистика, 2002.