Реферат: Элементы теории вероятности
Содержание
ВВЕДЕНИЕ………………………………………………………………………3
Анализ различных подходов к определению вероятности.. 4
Примеры стохастических зависимостей в экономике. 6
Проверка ряда гипотез о свойствах распределения вероятностей для случайной компоненты как один из этапов эконометрического исследования.. 9
Заключение. 14
Список использованной литературы.. 16
Введение
Сегодня деятельность в любой области экономики (управлении, учете, финансово- кредитной сфере, маркетинге, аудите) требует от специалиста применения современных методов работы, знания достижений мировой экономической мысли, понимания научного языка. Большинство современных методов основано на эконометрических моделях, концепциях, приемах. Без глубоких знаний эконометрики научиться их использовать невозможно. На практике далеко не все экономические явления и процессы можно свести к функциональным зависимостям, когда величине факторного показателя соответствует единственная величина результативного показателя.
Чаще в экономических исследованиях встречаются стохастические зависимости, которые отличаются приблизительностью, неопределенностью. Они проявляются только в среднем по значительному количеству объектов (наблюдений). Здесь каждой величине факторного показателя (аргумента) может соответствовать несколько значений результативного показателя (функции). Например, увеличение фондовооруженности труда рабочих дает разный прирост производительности труда на разных предприятиях даже при очень выровненных прочих условиях. Это объясняется тем, что все факторы, от которых зависит производительность труда, действуют в комплексе, взаимосвязано. В зависимости от того, насколько оптимально сочетаются разные факторы, будет неодинаковой степень воздействия каждого из них на величину результативного показателя.
Целью настоящей работы является изучение эконометрических методов и использование стохастических зависимостей в эконометрике.
Для достижения данной цели поставлены следующие задачи:
· проанализировать различных подходов к определению вероятности: априорный подход, апостсриорно-частотный подход, апостериорно - модельный подход.
· рассмотреть примеры стохастических зависимостей в экономике, их особенности и теоретико-вероятностные способы их изучения.
· рассмотреть ряд гипотез о свойствах распределения вероятностей для случайной компоненты как один из этапов эконометрического исследования.
Объектом исследования данной работы являются эконометрические методы и стохастических зависимости, которые используются в эконометрике.
Предметом исследования работы является методы эконометрического исследования.
В данной работе использованы следующие методы исследования: графический, статистический, абстрактно-логический, эконометрический, сравнительного анализа.
Анализ различных подходов к определению вероятности
Вероятность любого события А определяется как сумма вероятностей всех элементарных событий, составляющих событие А, т.е. если использовать символику Р{А} для обозначения вероятности события А, то
![]() (1)
(1)
Отсюда следует, что всегда 0<Р{А}<1, причем вероятность достоверного события равна единице, а вероятность невозможного события равна нулю..
Таким образом, для исчерпывающего описания механизма исследуемого случайного эксперимента (в дискретном случае) необходимо задать конечное или счетное множество всех возможных элементарных исходов и каждому элементарному исходу поставить в соответствие некоторую неотрицательную (не превосходящую единицы) числовую характеристику p, интерпретируемую как вероятность появления исхода (будем обозначать эту вероятность символами P{wi}).
Вероятностное пространство является понятием, формализующим описание механизма случайного эксперимента. Задать вероятностное пространство - это значит задать пространство элементарных событии и определить в нем вышеуказанное соответствие типа:
![]() (2)
(2)
Очевидно, соответствие типа (2) может быть задано различными способами: с помощью таблиц, графиков, аналитических формул, наконец, алгоритмически.
Чтобы определить из конкретных условий решаемой задачи вероятности P{wi} отдельных элементарных событий используется один из следующих трех подходов.
Априорный подход к вычислению вероятностей P{wi} заключается в теоретическом, умозрительном анализе специфических условий данного конкретного случайного эксперимента (до проведения самого эксперимента). В ряде ситуаций этот предопытный анализ позволяет теоретически обосновать способ определения искомых вероятностей. Например, возможен случай, когда пространство всех возможных элементарных исходов состоит из конечного числа N элементов, причем условия производства исследуемого случайного эксперимента таковы, что вероятности осуществления каждого из этих N элементарных исходов нам представляются равными (именно в такой ситуации мы находимся при подбрасывании симметричной монеты, бросании правильной игральной кости, случайном извлечении игральной карты из хорошо перемешанной колоды и т.п.). В силу аксиомы, вероятность каждого элементарного события равна в этом случае 1/N. Это позволяет получить простой рецепт и для подсчета вероятности любого события: если событие А содержит NA элементарных событий, то в соответствии с определением (3)
![]()
Смысл формулы (3) состоит в том, что вероятность события в данном классе ситуаций может быть определена как отношение числа благоприятных исходов (т. е. элементарных исходов, входящих в это событие) к числу всех возможных исходов (так называемое классическое определение вероятности). В современной трактовке формула (3) не является определением вероятности: она применима лишь в том частном случае, когда все элементарные исходы равновероятны.
Апостериорно-частотный подход к вычислению вероятностей Р{wi} отталкивается, по существу, от определения вероятности, принятого так называемой частотной концепцией вероятности. В соответствии с этой концепцией вероятность Р{wi} определяется как предел относительной частоты появления исхода в процессе неограниченного увеличения общего числа случайных экспериментов n, т.е. (4)
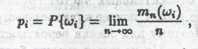
где mn(wi) - число случайных экспериментов (из общего числа n произведенных случайных экспериментов), в которых зарегистрировано появление элементарного события wi. Соответственно для практического (приближенного) определения вероятностей pi предлагается брать относительные частоты появления события в достаточно длинном ряду случайных экспериментов.
Апостериорно-модельный подход к заданию вероятностей Р{wi}, отвечающему конкретно исследуемому реальному комплексу условий, является в настоящее время, пожалуй, наиболее распространенным и наиболее практически удобным. Логика этого подхода следующая. С одной стороны, в рамках априорного подхода, т. е. в рамках теоретического, умозрительного анализа возможных вариантов специфики гипотетичных реальных комплексов условий разработан и исследован набор модельных вероятностных пространств (биномиальное, пуассоновское, нормальное, показательное и т.п.). С другой стороны, исследователь располагает результатами ограниченного ряда случайных экспериментов. Далее с помощью специальных математико-статистических приемов исследователь как бы прилаживает гипотетичные модели вероятностных пространств к имеющимся у него результатам наблюдения (отражающим специфику изучаемой реальной действительности) и оставляет для дальнейшего использования лишь ту модель или те модели, которые не противоречат этим результатам и в некотором смысле наилучшим образом им соответствуют.
Примеры стохастических зависимостей в экономике
Первая принципиальная идея, с которой встречается каждый изучающий экономист – идея о взаимосвязи между экономическими переменными. Формирующийся на рынке спрос на некоторый товар рассматривается как функция его цены; затраты, связанные с изготовлением какого-либо продукта, предполагаются зависящими от объема производства; потребительские расходы могут быть функцией дохода ит.д. Все это примеры связей между двумя переменными, одна из которых (спрос на товар, производственные затраты, потребительские расходы) играет роль объясняемой переменной (или результирующего показателя), а другие интерпретируются как объясняющие переменные (или факторы-аргументы). Однако для большей реалистичности в каждое такое соотношение приходится вводить несколько объясняющих переменных и остаточную случайную составляющую, отражающую влияние на результирующий показатель всех неучтенных факторов. Спрос на товар можно рассматривать как функцию его цены, потребительского дохода и цен на конкурирующие и дополняющие товары; производственные затраты будут зависеть от объема производства, от его динамики и от цен на основные производственные ресурсы; потребительские расходы можно определить как функцию дохода, ликвидных активов и предыдущего уровня потребления. При этом участвующая в каждом из этих соотношений случайная составляющая, отражающая влияние на анализируемый результирующий показатель всех неучтенных факторов, обусловливает стохастический характер зависимости, а именно: даже зафиксировав на определенных уровнях значения объясняющих переменных, скажем, цены на сам товар и на конкурирующие с ним или дополняющие товары, а также потребительский доход, мы не можем ожидать, что тем самым однозначно определяете спрос на этот товар. Другими словами, переходя в своих наблюдениях спроса от одного временного или пространственного такта к другому, мы обнаружим случайное варьирование величины спроса около некоторого уровня даже при сохранении значений всех объясняющих переменных неизменными.
В прикладном статистическом анализе анализируются различные варианты формализации понятия стохастической зависимости между результирующим показателем у и объясняющими переменными х(1),х (2),…,х (р).
Наиболее распространенной в эконометрических приложениях формой представления стохастической зависимости является аддитивная линейная форма, которая и будет главным предметом исследования в нашем изложении:
![]() (5)
(5)
Здесь yt - значение результирующей (объясняемой) переменной, измеренное в t-u временном (или пространственном) такте, х t(1),х t (2)…х t (р) - значения участвующих в соотношении объясняющих переменных, полученные в том же t-м измерении, θ1, θ2,..., θ t - некоторые параметры (как правило, не известные до проведения соответствующего статистического анализа), δ t - случайная составляющая, характеризующая разницу между модельный и наблюденным значениями анализируемой результирующей переменной, зафиксированную в t-м измерении. Под модельный значением результирующей переменной ỹt здесь и в дальнейшем мы будем понимать ее значение, восстановленное по заданным величинам объясняющих переменных при условии, что коэффициенты θ 1, θ 2,..., θ p нам известны, т.е.
![]() (6)
(6)
При такой интерпретации модельного значения результирующей переменной случайную составляющую можно интерпретировать как случайную ошибку прогноза у по заданным значениям х (1),х (2),х (р), причем, чтобы исключить систематическую ошибку в оценке yt по ỹt, обычно полагают, что среднее значение случайной составляющей t при всех значениях t равно нулю (т.е. Еδ t =0). Очевидно, чем больше информации заключено в значениях объясняющих переменных х t(1),х t (2),…,х t (р) относительно величины у, тем надежнее будет прогноз и тем меньше будет ошибка прогноза δ. Малость случайной величины - это значит, что ее значения сосредоточены в окрестности нуля с малой дисперсией.
Следующий шаг в развитии экономических теорий состоит в группировке отдельных соотношений в модель. Всякая математическая модель является лишь упрощенным формализованным представлением реального объекта (явления, процесса), и искусство ее построения состоит в том, чтобы совместить как можно большую лаконичность параметризации модели с достаточной адекватностью описания именно тех сторон моделируемой реальности, которые интересуют исследователя. Количество связей, включаемых в экономическую модель, зависит от условий, при которых эта модель конструируется, и от подробности объяснения, к которой мы стремимся. Например, традиционная модель спроса и предложения должна объяснять соотношения между ценой и объемом выпуска, характерные для некоторого определенного рынка. Она содержит три уравнения, а именно: уравнение спроса, уравнение предложения и уравнение реакции рынка. В эти уравнения, помимо интересующих нас объема выпуска и цены, будут входить и другие переменные; так, например, в уравнение спроса войдет потребительский доход, а в уравнение предложения - цена. Объяснение, достигнутое с помощью такой модели, обусловлено значениями некоторых «внешних» по отношению к модели переменных и в этом смысле модель является неполной, или условной. Более претенциозные модели содержат гораздо больше уравнений и с их помощью пытаются отразить поведение существенно большего числа переменных; однако и они остаются условными, поскольку тоже содержат переменные, не определяемые или не объясняемые моделью.
Все экономические модели, независимо от того, относятся они ко всему хозяйству или к его элементам (т. е. к макроэкономике, отрасли, фирме или рынку), имеют некоторые общие особенности. Во-первых, они основаны на предположении, что поведение экономических переменных определяется с помощью совместных и одновременных операций с некоторым числом экономических соотношений. Во-вторых, принимается гипотеза, в силу которой модель, допуская упрощение сложной действительности, тем не менее улавливает главные характеристики изучаемого объекта. В-третьих, создатель модели полагает, что на основе достигнутого с ее помощью понимания реальной системы удастся предсказать ее будущее движение и, возможно, управлять им в целях улучшения экономического благосостояния.
Чтобы проиллюстрировать сказанное и наметить пути для выяснения специфической роли эконометрики, рассмотрим пример весьма общей и приближенной макромодели.
Пример1:
Предположим, что экономист-теоретик сформулировал следующие положения:
• потребление есть возрастающая функция от имеющегося в наличии дохода, но возрастающая, видимо, медленнее, чем рост дохода;
• объем инвестиций есть возрастающая функция национального дохода и убывающая функция характеристики государственного регулирования (например, нормы процента);
• национальный доход есть сумма потребительских, инвестиционных и государственных закупок товаров и услуг.
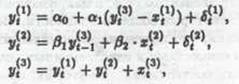 Наша первая задача - перевести эти положения на
математический язык. И тут мы немедленно сталкиваемся с многообразием открывающихся
перед нами возможных способов удовлетворения сформулированным априорным
требованиям теоретика. Какие соотношения выбрать между переменными - линейные
или нелинейные? Если остановиться на нелинейных, то какими они должны быть -
логарифмическими, полиномиальными или какими-либо еще? Даже определив форму
конкретного соотношения, мы оставляем еще нерешенной проблему выбора для различных
уравнений запаздываний по времени. Будут ли, например, инвестиции текущего
периода реагировать только на национальный доход, произведенный в последнем
периоде, или же на них скажется динамика не скольких предыдущих периодов?
Обычный выход из этих трудностей состоит в выборе при первоначальном анализе наиболее
простой из возможных форм этих соотношений. Тогда появляется возможность
записать на основе указанных выше положений следующую линейную относительно
анализируемых переменных и аддитивную относительно случайных составляющих
модель:
Наша первая задача - перевести эти положения на
математический язык. И тут мы немедленно сталкиваемся с многообразием открывающихся
перед нами возможных способов удовлетворения сформулированным априорным
требованиям теоретика. Какие соотношения выбрать между переменными - линейные
или нелинейные? Если остановиться на нелинейных, то какими они должны быть -
логарифмическими, полиномиальными или какими-либо еще? Даже определив форму
конкретного соотношения, мы оставляем еще нерешенной проблему выбора для различных
уравнений запаздываний по времени. Будут ли, например, инвестиции текущего
периода реагировать только на национальный доход, произведенный в последнем
периоде, или же на них скажется динамика не скольких предыдущих периодов?
Обычный выход из этих трудностей состоит в выборе при первоначальном анализе наиболее
простой из возможных форм этих соотношений. Тогда появляется возможность
записать на основе указанных выше положений следующую линейную относительно
анализируемых переменных и аддитивную относительно случайных составляющих
модель:
где априорные ограничения выражены неравенствами
![]()
Эти три соотношения вместе с ограничениями образуют модель. В ней уt(1) обозначает потребление, у t(2),- инвестиции, у t(3) - национальный доход, х t(1) - подоходный налог, х t(2) - норму процента как инструмент государственного регулирования, хt(3) - государственные закупки товаров и услуг, измеренные в «момент времени» t.
Присутствие в уравнениях (6а) и (6б) «остаточных» случайных составляющих δt(1) и δt(2) обусловлено необходимостью учесть влияние соответственно на у t(1) и у t(2) ряда неучтенных факторов. Действительно, нереалистично ожидать, что величина потребления уt(1) будет однозначно определяться уровнями национального дохода (у t(3) ) и подоходного налога (хt(1)); аналогично величина инвестиций у t(2) зависит, очевидно, не только от достигнутого в предыдущий год уровня национального дохода (у t-1(3)) и от величины нормы процента (х t(2)), но и от ряда не учтенных в уравнении ( 6б ) факторов. Полученная модель содержит два уравнения, объясняющие поведение потребителей и инвесторов, и одно тождество. Модель сформулирована для дискретных периодов времени и имеет запаздывание (лаг) в один период для отражения воздействия национального дохода на инвестиции.
Этот пример объясняет общие черты одного из важнейших этапов эконометрического моделирования, в процессе которого исследователь математически формализует отдельные положения экономической теории и объединяет их в систему. В дальнейшем мы используем этот пример для пояснения ряда основных понятий эконометрического моделирования.
Проверка ряда гипотез о свойствах распределения вероятностей для случайной компоненты как один из этапов эконометрического исследования
По своему назначению и характеру решаемых задач статистические критерии чрезвычайно разнообразны. Однако их объединяет общность логической схемы, по которой они строятся. Коротко эту логическую схему можно описать так.
1.Выдвигается гипотеза Н0.
Задаются
величиной так называемого уровня значимости критерия
ά. Дело в том, что всякое статистическое решение, т. е. решение, принимаемое
на основании ограниченного ряда наблюдений, неизбежно сопровождается
некоторой, хотя, возможно, может и очень малой, вероятностью ошибочного
заключения как в ту, так и в другую сторону. Скажем, в какой-то небольшой доле
случаев а гипотеза Н0 может оказаться отвергнутой, в то время как
на самом деле она является справедливой, или, наоборот, в какой-то небольшой
доле случаев β мы можем принять нашу гипотезу, в то время как на самом
деле она ошибочна, а справедливым оказывается некоторое конкурирующее с ней
предположение - альтернативная гипотеза Н1. При фиксированном
объеме выборочных данных величину вероятности одной из этих ошибок мы можем
выбирать по своему усмотрению. Если же объем выборки можно как угодно
увеличивать, то имеется принципиальная возможность добиваться как угодно малых
вероятностей обеих ошибок ά и β при любом фиксированном конкурирующем
предположительном утверждении Н1. В частности, при фиксированном
объеме выборки обычно задаются величиной а вероятности ошибочного отвержения
проверяемой гипотезы Н0, которую часто называют «основной» или
«нулевой». Эту вероятность ошибочного отклонения «нулевой» гипотезы принято
называть уровнем значимости или размером критерия. Выбор величины уровня
значимости а зависит от сопоставления потерь, которые мы понесем в случае
ошибочных заключений в ту или иную сторону: чем весомее для нас потери от
ошибочного отвержения высказанной гипотезы Н0, тем меньшей
выбирается величина ά.
3. Задаются некоторой функцией от результатов наблюдения (критической статистикой) γ(n)= γ (х1, х2,…, х3). Эта критическая статистика γ(n), как и всякая функция от результатов наблюдения, сама является случайной величиной и в предположении справедливости гипотезы Н0 подчинена некоторому хорошо изученному (затабулированному) закону распределения с плотностью f γ(n)(u).
4.Из таблиц распределения f γ(n)(u) находятся 100(1 - ά/2)%-ная точка γminά/2 и 100 ά/2%-ная точка γmaxά/2, разделяющие всю область мыслимых значений случайной величины γ(n) на три части: область неправдоподобно малых (I), неправдоподобно больших (III) и естественных или правдоподобных (в условиях справедливости гипотезы Н0) значений (II) (рис.1). В тех случаях, когда основную опасность для нашего утверждения представляют только односторонние отклонения, т.е. только «слишком маленькие» или только «слишком большие» значения критической статистики γ(n) находят лишь одну процентную точку: либо 100(1 -ά) %- ную точку γminά, которая будет разделять весь диапазон значений γ(n) на две части: область неправдоподобно малых и область правдоподобных значений; либо 100 ά %-ную точку γ(max)ά, она будет разделять весь диапазон значений γ(n) на область неправдоподобно больших и область правдоподобных значений.
5. В функцию γ(n) подставляют имеющиеся конкретные выборочные данные х1,...,х2 и подсчитывают численную величину γ(n). Если окажется, что вычисленное значение принадлежит области правдоподобных значении γ(n) то гипотеза Н0 считается не противоречащей выборочным данным. В противном случае, т. е. если γ(n) слишком мала или слишком велика, делается вывод, что γ(n) на самом деле не подчиняется закону f γ(n)(u), и это несоответствие мы вынуждены объяснить ошибочностью высказанного нами предположения Н0 и, следовательно, отказаться от него.
На разных стадиях статистического исследования и моделирования возникает необходимость в формулировке и экспериментальной проверке некоторых предположительных утверждений (гипотез) относительно природы или величины неизвестных параметров анализируемой стохастической системы. Например, исследователь высказывает предположение: «исследуемые наблюдения извлечены из нормальной генеральной совокупности» или «среднее значение анализируемой генеральной совокупности равно нулю».
Процедура обоснованного сопоставления высказанной гипотезы с имеющимися в нашем распоряжении выборочными данными х1,х2…хn, сопровождаемая количественной оценкой степени достоверности получаемого вывода, осуществляется с помощью того или иного статистического критерия и называется статистической проверкой гипотез.
Результат подобного сопоставления может быть либо отрицательным (данные наблюдения противоречат высказанной гипотезе, а потому от этой гипотезы следует отказаться), либо неотрицательным (данные наблюдения не противоречат высказанной гипотезе), а потому ее можно принять в качестве одного из естественных и допустимых решений. При этом неотрицательный результат статистической проверки гипотезы не означает, что высказанное нами предположительное утверждение является наилучшим, единственно подходящим: просто она не противоречит имеющимся у нас выборочным данным, однако таким же свойством могут наряду с H обладать и другие гипотезы.
По своему прикладному содержанию высказываемые в ходе статистической обработки данных гипотезы можно подразделить на несколько основных типов.
При обработке ряда наблюдений х1,х2…хn , (5)
исследуемой случайной величины ξ очень важно понять механизм формирования выборочных значений хi, т.е. подобрать и обосновать некоторую модельную функцию распределения Fмод(x), с помощью которой можно адекватно описать исследуемую функцию распределения Fξ(x). На определенной стадии исследования это приводит к необходимости проверки гипотез типа: (6)
![]()
где гипотетичная модельная функция может быть как заданной однозначно (тогда Fξ(x) = F0(x), где F0(x) - полностью известная функция), так и заданной с точностью до принадлежности к некоторому параметрическому семейству (тогда Fмод(x) = F(х;θ), где θ - некоторый, вообще говоря, к-мерный параметр, значения которого неизвестны, но могут быть оценены по выборке (5).
Проверка гипотез типа (6) осуществляется с помощью так называемых критериев согласия и опирается на ту или иную меру различия между анализируемой эмпирической функцией распределения Fξ(n)(x) и гипотетическим модельным законом Fмод(x).
Наиболее типичные задачи такого рода характеризуются следующей обшей ситуацией. Пусть мы имеем несколько «порций» выборочных данных типа(5):
 (7)
(7)
Эти порции могли образоваться, например, естественным образом - в ходе проведения выборочного обследования (скажем, за счет разделенности условий их регистрации во времени или пространстве). Обозначая функцию распределения, описывающую вероятностный закон, которому подчиняются наблюдения j-й выборки, с помощью Fj(x) и снабжая тем же индексом все интересующие нас эмпирические и теоретические характеристики этого закона (средние значения âj и аj; дисперсии σ2j и σ2j ).
В случае неотрицательного результата проверки этих гипотез говорят, что соответствующие выборочные характеристики (например, а1, а2,..,аi) различаются статистически незначимо.
Пусть, например, ряд наблюдений (5) дает нам значения некоторого параметра изделий, измеренные на n изделиях, случайно отобранных из массовой продукции определенного станка автоматической линии, и пусть а0 заданное номинальное значение этого параметра. Каждое отдельное значение хi - может, естественно, как-то отклоняться от заданного номинала. Очевидно, для того чтобы проверить правильность настройки этого станка, надо убедиться в том, что среднее значение параметра у производимых на нем изделий будет соответствовать номиналу, т. е. проверить гипотезу типа
![]() (11)
(11)
В общем случае гипотезы подобного типа имеют вид:
![]() (12)
(12)
где θ - некоторый параметр (многомерный), от которого зависит исследуемое распределение, а Δ0 - область его конкретных гипотетических значений, которая может состоять всего из одной точки.
Статистическая проверка гипотез о числовых значениях параметров играет важную роль в эконометрическом моделировании, регрессионном анализе, в широком спектре задач статистического исследования зависимостей, существующих между анализируемыми показателями. В частности, принятие решения о включении или исключении той или иной переменной в анализируемую регрессионную (эконометрическую) модель, о наличии-отсутствии статистической связи между наблюдаемыми признаками существенно опирается обычно на проверку гипотез типа (12) при Δ0= 0.
Заключение
На основании проделанной работы можно сделать следующие выводы.
Вероятность любого события А определяется как сумма вероятностей всех элементарных событий, составляющих событие.
Априорный подход к вычислению вероятностей P{wi} заключается в теоретическом, умозрительном анализе специфических условий данного конкретного случайного эксперимента. Вероятность события в данном классе ситуаций может быть определена как отношение числа благоприятных исходов (т. е. элементарных исходов, входящих в это событие) к числу всех возможных исходов (так называемое классическое определение вероятности).
В соответствии с апостериорно-частотным подходом, вероятность Р{wi} определяется как предел относительной частоты появления исхода в процессе неограниченного увеличения общего числа случайных экспериментов n.
Апостериорно-модельный подход заключается в следующем: в рамках априорного подхода разработан и использован набор модельных вероятностных пространств. Исследователь располагает результатами ограниченного ряда случайных экспериментов, согласно которому он выбирает ту или иную вероятностную модель или модели, которые соответствуют этим результатам наилучшим способом.
Стохастические зависимости проявляются только в массовых процессах и при большом числе единиц совокупности. При стохастической зависимости для заданного значения объясняющей переменной можно указать ряд значений зависимой переменной, случайным образом рассеянных в интервале, то есть каждому фиксированному значению аргумента соответствует определенное статистиче5ское распределение значений функции. Это объясняется тем, что зависимая переменная кроме выделенной переменной подвержена влиянию ряда не контролируемых факторов, а также тем, измерения переменных неизбежно сопровождаются случайными ошибками. Наиболее распространенной в эконометрических приложениях формой представления стохастической зависимости является аддитивная линейная форма.
Процедура обоснованного сопоставления высказанного исследователем предположительного утверждения (гипотезы) относительно природы или величины неизвестных параметров рассматриваемой стохастической системы с имеющимися в его распоряжении результатами наблюдения, сопровождаемая количественной оценкой степени достоверности получаемого вывода, осуществляется с помощью того или иного статистического критерия и называется статистической проверкой гипотез.
По своему прикладному содержанию гипотезы, высказываемые в ходе статистического анализа и моделирования, подразделяют на следующие типы: об общем виде закона распределения исследуемой случайной величин; об однородности двух или нескольких обрабатываемых выборок; о числовых значениях параметров исследуемой генеральной совокупности; об общем виде зависимости, существующей между компонентами исследуемого многомерного признака; о независимости и стационарности ряда наблюдений.
Все статистические критерии строятся по общей логической схеме. Построить статистический критерий - это значит: а) определить тип проверяемой гипотезы; б) предложить и обосновать конкретный вид функции от результатов наблюдения (критической статистики на основании значений которой принимается окончательное решение; в) указать такой способ выделения из области возможных значений критической статистики области отклонения проверяемой гипотезы Но, чтобы было соблюдено требование к величине вероятности ошибочного отклонения гипотезы Но (т.е. к уровню значимости критерия а).
Список использованной литературы
1.
Айвазян С.А.,
Мхитарян B.C. Прикладная статистика и основы
эконометрики. - М.: ЮНИТИ, 1998.
2. Вентцель Е.С. Теория вероятностей. - М.: Высшая школа, 1998.
3. Эконометрика. /Под ред. Елисеевой И.И. - М.: Финансы и статистика, 2001.