Курсовая работа: Нові тенденції і прикладні аспекти інженерії знань
Психосемантика
1.1 Семантичні простори і психологічне градуювання
Психосемантика досліджує структури свідомості через моделювання індивідуальної системи знань [1] і виявлення тих категоріальних структур свідомості, які можуть не усвідомлюватися.
Основним методом експериментальної психосемантики є метод реконструкції суб’єктивних семантичних просторів. Тут психосемантика тісно сплітається з психолінгвістикою і лінгвістичною семантикою – з методологією виявлення значень слів, лексикографією, «відмінковою граматикою» і структурними дослідженнями [2]. Проте лінгвістичні методи в основному направлені на аналіз текстів, відчужених від суб’єкта, від його мотивів і задумів.
Психолінгвістичні методи звертаються безпосередньо до випробовуваного. Більшість з них пов’язана з різними формами суб’єктивного градуювання. Перед випробовуваним ставиться завдання оцінити «схожість знань» за допомогою деякої градуйованої шкали, наприклад від 0 до 5 або від 0 до 9. В цьому випадку дослідник отримує в руки чисельно представлені стандартизовані дані що легко піддаються статистичній обробці.
Психосемантика, як один з молодих напрямів сучасної психології [3], відразу була оцінена фахівцями в області штучного інтелекту як перспективний інструмент, що дозволяє реконструювати семантичний простір пам’яті як психологічну модель глибинної структури знань експерта. Вже перші додатки психосемантики в штучному інтелекті в середині 80-х років минулого століття дозволили отримати достатньо наочні результати. У психології семантичні простори виступають як модель категоріальної структури індивідуальної свідомості. При концептуальному аналізі знань структуру семантичного простору експерта можна вважати основою для формування поля знань. При цьому окремі параметри семантичного простору відповідають різним компонентам поля (розмірність простору співвідноситься зі складністю поля, виділені понятійні структури з метапоняттями, змістовні зв’язки між поняттями-стимулами – це суть відношення тощо).
Найлегше познайомитися з експериментальною психосемантикою на прикладі, пов’язаному з виявленням структури і розмірності семантичного простору знань з деякої предметної області [3].
В основі побудови семантичних просторів, як правило, лежить статистична процедура (наприклад, факторний аналіз [4], багатомірне градуювання [5] або кластерний аналіз [6]), що дозволяє групувати ряд окремих ознак опису в більш місткі категорії-чинники. Кажучи на мові поля знань, це – побудова концептів вищого рівня абстракції. При геометричній інтерпретації семантичного простору значення окремої ознаки відображається як крапка або вектор із заданими координатами усередині n-мірного простору, координатами якого виступають виділені чинники. Побудова семантичного простору, таким чином, включає перехід до опису предметної області на більш високому рівні абстракції, тобто перехід від мови, що містить великий алфавіт ознак опису, до більш місткої мови концептуалізації, що містить менше число концептів і виступає своєрідною метамовою по відношенню до першої.
Залежно від досвіду і професійної компетентності тих, кого випробовують, розмірність простору і розташування в ній первинних понять може істотно варіюватися. Ця особливість семантичних просторів може бути використана на стадії контролю в процесах навчання, при тестуванні експериментів і користувачів.
На підставі отримуваних методами психосемантики моделей можна проводити контроль знань. При аналізі індивідуальних семантичних просторів виявляються питання, які не засвоєні і не уклалися в систему. Контроль структури знань проводиться на основі зіставлення семантичних просторів хороших фахівців і новачків (студентів, слухачів, молодих фахівців). Ступінь узгодженості семантичних просторів (їх розмірності, ознаки і конфігурації понять) визначатиме рівень знань новачка.
Проте тут необхідно врахувати, що семантичні простори двох кваліфікованих фахівців можуть бути різними, оскільки містять індивідуальні відмінності сприйняття, що відображають досвід і характер діяльності людини. Тому не завжди можна формально порівняти семантичні простори експерта і новачка, слід заздалегідь вивчити семантичні простори декількох фахівців, а потім вже проводити порівняння.
У роботі Кука й Макдональда [7] описаний подібний експеримент. Були отримані когнітивні структури знань досвідченого пілота-винищувача і пілота-новачка, з використанням двох методів: багатовимірного градуювання (алгоритм MDS – Alscal) і мережевого градуювання із зваженими зв’язками (алгоритм Pathfinder). Обидва алгоритми засновано на використанні оцінок психологічної близькості. Досвідчений пілот і пілот-новачок оцінювали всі можливі парні поєднання 30 пов’язаних з польотом понять, приписуючи числа від 0 до 9 кожній парі, де «нулем» позначали найслабший ступінь зв’язку між поняттями, а «дев’яткою» – найсильніший. Ці оцінки потім оброблялися із застосуванням обох алгоритмів градуювання.
Відповідно до алгоритмів MDS кожен концепт, що виражає деяке поняття, поміщається в k-вимірний простір таким чином, що відстань між точками відображає психологічну близькість відповідних концептів.
Алгоритм Pathfinder будує семантичну мережу. Дуги можуть бути або орієнтованими (несиметричне відношення), або неорієнтованими (симетричне відношення). Обидва методи забезпечують стиснення великих об’ємів даних (у формі попарних оцінок) до меншого набору параметрів; проте націлені вони на виявлення різних властивостей досліджуваних структур.
Якщо в алгоритмі Pathfinder центром уваги є локальні відношення між концептами, то алгоритм MDS забезпечує ширше розуміння властивостей метризованого простору концептів.
Результуючі когнітивні структури виявилися близькими для пілотів-винищувачів з однаковим рівнем досвіду, але були різними для різних груп випробовуваних. Автори експериментів виявили, що за когнітивною структурою, характерній для пілота-винищувача, можна встановити, новачок він чи досвідчений пілот.
В результаті, проведений Куком й Макдональдом аналіз когнітивних структур виявив наявність концептів і відношень, загальних для представлень досвідченого фахівця і новачка, і, крім того, ряд концептів і відношень, які з’явилися тільки в одному з представлень. Прямим розвитком розглянутої роботи стала експертна система управління повітряним боєм ACES [8].
Аналогічне дослідження механізмів накопичення досвіду було проведене в області програмування на ЕОМ [9]. За допомогою методів градуювання було показано, що один з аспектів досвіду програміста включає організацію знань відповідно до задуму програми, або семантики, а не відповідно до синтаксису.
Всі згадані вище методи, в тому числі і кластерний аналіз, можна віднести до методів психологічного градуювання. Їх основу складають алгоритми перетворення складних структур даних в більш зрозумілу форму, яка передбачається психологічно змістовною. Результуюче уявлення залежить від методу:
· кластерний аналіз породжує деревовидну структуру;
· багатовимірне градуювання і аналіз чинника – просторову;
· алгоритм MDS;
· репертуарні решітки породжують конструкти або метавимірювання [10].
Формальна методологія психосемантичного градуювання дозволяє частково автоматизувати процес структуризації знань і отримувати «когнітивний розріз» його уявлень про наочну область. Методологія градуювання дозволяє виявляти структури знання непрямим шляхом при отриманні відповідей від експертів на досить прості питання (наприклад, «наскільки близькі поняття x1 і x2» замість «скажіть, який зв’язок між x1 і x2 та як вони впливають один на одного»).
Майже всі експерименти дозволили виявити одну закономірність. Розмірність семантичного простору з підвищенням рівня професіоналізму зменшується. Цей висновок узгоджується з відомими положеннями когнітивної психології про те, що процес пізнання супроводжується узагальненням. Побудова семантичного простору зазвичай включає три послідовні етапи:
1. Вибір і застосування відповідного методу оцінки семантичної схожості. Цей етап включає експеримент з випробовуваними, яким пропонується оцінити спільність стимулюючих ознак, що пред’являються, на деякій шкалі.
2. Побудова структури семантичного простору на основі математичного аналізу отриманої матриці подібності. При цьому відбувається зменшення числа досліджуваних понять за рахунок узагальнення і отримання генералізованих осей.
3. Ідентифікація, інтерпретація виділених факторних структур, кластерів або груп об’єктів, осей тощо. На цьому етапі необхідно знайти значеннєві еквіваленти, мовні «ярлики» для виділених структур. Тут великого значення набуває лінгвістичне чуття і професіоналізм фахівця, який здійснює дослідження, і випробуваних експертів. Часто до інтерпретації залучають групу експертів.
1.2 Методи багатовимірного градуювання
Надалі розвиток методів психосемантики йшов по лінії розробки зручних пакетів прикладних програм, заснованих на методах багатовимірного градуювання, аналізу чинника, а також спеціалізованих методів (статистичного) опрацювання репертуарних решіток. Прикладами пакетів такого типу є системи KELLY [11], MADONNA [12], MEDIS [13]. З іншого боку, специфіка ряду конкретних додатків, в першу чергу – в інженерії знань, вимагала також розвитку інших (не чисельних) методів обробки психосемантичних даних, що використовують, в тій або іншій формі, парадигму логічного виводу на знаннях. Яскравим прикладом цього напряму є система AQUINAS [14]. Проте аналіз практичного застосування систем обох типів до завдань інженерії знань приводить до висновку про недосконалість наявних методик і необхідність їх розвитку відповідно до сучасних вимог інженерії знань. Найбільші перспективи в цій області, мабуть, у методів багатовимірного градуювання.
Сьогодні багатовимірне градуювання – це математичний інструментарій, призначений для обробки даних про попарну схожість, зв’язки або відношення між аналізованими об’єктами з метою представлення цих об’єктів у вигляді точок деякого координатного простору. Багатовимірне градуювання є одним з розділів прикладної статистики, наукової дисципліни, що розробляє і систематизує поняття, прийоми, математичні методи і моделі, призначені для збору, стандартного запису, систематизації і обробки статистичних даних з метою їх лаконічного представлення, інтерпретації і отримання наукових і практичних висновків. Традиційно багатовимірне градуювання використовується для вирішення трьох типів завдань:
§ пошук і інтерпретація латентних (тобто прихованих, безпосередньо не спостережуваних) змінних, що пояснюють задану структуру попарних відстаней (зв’язків, близькостей);
§ верифікація геометричної конфігурації системи аналізованих об’єктів в координатному просторі латентних змінних;
§ стиснення початкового масиву даних з мінімальними втратами в їх інформативності.
Незалежно від завдання багатовимірне градуювання завжди використовується як інструмент наочного представлення (візуалізації) початкових даних. Багатовимірне градуювання широко застосовується в дослідженнях щодо антропології, педагогіки, психології, економіки, соціології [15].
В основі даного підходу лежить інтерактивна процедура суб’єктивного градуювання, коли випробовуваному (тобто експертові) пропонується оцінити схожість між різними елементами за допомогою деякої градуйованої шкали (наприклад, від 0 до 9, або від -2 до +2). Після такої процедури аналітик розташовує чисельно представленими стандартизованими даними, що піддаються обробці існуючими пакетами прикладних програм, що реалізовують різні алгоритми формування концептів вищого рівня абстракції і що будують геометричну інтерпретацію семантичного простору в евклідової системі координат.
Основний тип даних в багатовимірному градуюванні – заходи близькості між двома об’єктами (i, j) – dij. Якщо міра близькості така, що найбільші значення dij відповідають парам найбільш схожих об’єктів, то dij – міра подібності, якщо, навпаки, найменше схожим, то dij – міра відмінності.
Багатовимірне градуювання використовує дистанційну модель відмінності, використовуючи поняття відстані в геометрії як аналогію схожості і відмінності понять. Для того, щоб функція d, визначена на парах об’єктів (а, b), була евклідовою відстанню, вона повинна задовольняти наступні чотири аксіоми:
![]()
![]()
![]()
![]()
Тоді, згідно звичайній формулі евклідова відстань, міра відмінності двох об’єктів i та j із значеннями ознаки k у об’єктів i та j відповідно xik та xjk:
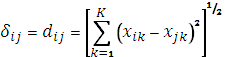
Дистанційна модель була багато разів перевірена в соціології і психології [16], що дає можливість оцінити її придатність для використання.
У більшості робіт по багатовимірному градуюванню використовується матрична алгебра. Геометрична інтерпретація дозволяє представити абстрактні поняття матричної алгебри в конкретній графічній формі. Для полегшення інтерпретації рішення задачі багатовимірного градуювання до попередньо оціненої матриці координат стимулів X застосовується обертання.
Серед безлічі алгоритмів багатовимірного градуювання широко використовуються різні модифікації метричних методів Торгерсона [17], а також неметричні моделі, наприклад Крускала [18].
При порівнянні методів багатовимірного градуювання з іншими методами аналізу, теоретично застосовними в інженерії знань (ієрархічний кластерний аналіз або аналіз чинника), багатовимірне градуювання виграє за рахунок можливості дати наочне кількісне координатне уявлення, що переважно є простішим і тому легше інтерпретується експертами.
1.3 Використання метафор для виявлення «прихованих» структур знань
Не дивлячись на близькість завдань, інженерія знань і психосемантика істотно відрізняються як в теоретичних підставах, на яких вони базуються, так і в практичних методиках. Але головна відмінність полягає в тому, що інженерія знань направлена на виявлення, як остаточного результату, моделі міркувань, динамічній або операційної складової ментального простору (або функціональної структури поля знань Sf), тоді як психосемантика, намагаючись представити ментальний простір у вигляді евклідового простору, дозволяє робити видимою статичну структуру взаємного «розташування» об’єктів в пам’яті, у вигляді проекцій скупчень об’єктів (концептуальна структура Sk).
Крім цього слід зазначити ряд недоліків методів психосемантики з погляду практичної інженерії знань.
Оскільки в основі психосемантичного експерименту лежить процедура вимірювання суб’єктивних відстаней між стимулами, що пред’являються, то і результати обробки такого експерименту, як правило, використовують геометричну інтерпретацію – евклідовий простір невеликого числа вимірювань (найчастіше – двовимірне). Таке сильне спрощення моделі пам’яті може привести до неадекватних баз знань.
Природність ієрархії як глобальної моделі понятійних структур свідомості служить методологічною базою ОСП. Крім того, і в природній мові поняття явно тяжіють до різних рівнів узагальнення. Проте в більшості прикладних пакетів не передбачено розбиття семантичного простору на рівні, що відображають різні ступені спільності понять, включених в експериментальний план. В результаті отримувані кластери понять, просторово ізольовані в геометричній моделі градуювання, носять таксономічно неоднорідний характер і важко піддаються інтерпретації.
Єдині відносини, що виявляються процедурами психосемантики, – це «далеко – близько» за деякою шкалою. Для проектування і побудови баз знань виявлення відношень є на порядок складнішим завданням, ніж виявлення понять. Тому семантичні простори, отримані в результаті градуювання і кластеризації, повинні бути піддані подальшій обробці на предмет визначення відношень, особливо функціональних і каузальних.
Не варто очікувати, що ці протиріччя можуть бути вирішені швидко й безболісно, оскільки, математичний апарат, покладений в основу всіх пакетів прикладних програм з психосемантики, має певні межі застосування. Однак одним з можливих шляхів зближення без порушення чистоти процедури бачиться розширення простору конкретних об’єктів-стимулів предметної області за рахунок додавання деяких абстрактних об’єктів зі світу метафор, які змусять випробуваного експерта вийти за рамки об’єктивності у світ суб’єктивних уявлень, які найчастіше більшою мірою впливають на його міркування й модель прийняття рішень, ніж традиційні правильні погляди.
2. Метод репертуарних решіток
2.1 Основні поняття
Серед методів когнітивної психології – науки, що вивчає те, як людина пізнає і сприймає світ, інших людей і самого себе, як формується цілісна система уявлень і відношень конкретної людини, – особливе місце займає такий метод особової психодіагностики, як метод репертуарних решіток (repertory grid).
Вперше метод був сформульований автором теорії особистісних конструктів Джорджем Келлі в 1955 р. Чим ширший набір особистісних конструктів у суб’єкта, тим більш багатовимірним, диференційованим є образ світу, людини, інших явищ і предметів, тобто тим вище його когнітивна складність.
Репертуарна решітка є матрицею, яку заповнює або сам випробовуваний, або експериментатор в процесі обстеження або бесіди. Стовпцю матриці відповідає певна група об’єктів, або, інакше, елементів. Як об’єкти можуть виступати люди, предмети, поняття, відношення, звуки, кольори – все, що цікавить психодіагностика. Рядками матриці є конструкти – біполярні ознаки, параметри, шкали, альтернативні протилежні відношення або способи поведінки. Конструкти або задаються дослідником, або виявляються у випробовуваного за допомогою спеціальних прийомів і процедур виявлення. Вводячи поняття конструкта, Келлі об’єднує дві функції: функцію узагальнення (встановлення схожості) і функцію зіставлення. Він пропонує декілька визначень поняття «конструкт». Одне з яких:
Конструкт – це деяка ознака або властивість, за якою два або декілька об’єктів схожі між собою і, відповідно, відмінні від третього або декількох інших об’єктів.
Наприклад, виділення з трьох предметів «диван, крісло, стілець» двох «диван і крісло» виявляє конструкт «м’якість меблів». Келлі в своїх роботах підкреслює біполярність конструктів. Він вважає, що, стверджуючи що-небудь, ми завжди одночасно щось заперечуємо. Саме біполярність конструктів робить можливою побудову репертуарних решіток. Наприклад, північ – південь – це референтна вісь: елементи, які в одному контексті є «північчю», в іншому стають «півднем».
Можливості конструкта обмежені. Вони можуть бути застосовані тільки до деяких об’єктів. Це знайшло своє віддзеркалення в понятті «діапазону придатності» конструкта. Англійські психологи Франселла і Банністер вважають правило «діапазону придатності» відмінною рисою техніки репертуарних решіток. Під діапазоном придатності можна розуміти область уявлень людини про світ, поняття якої можна співвіднести з конкретною референтною віссю конструкта, що виділявся. Психологічно осмислений результат вийде тільки в тому випадку, якщо елементи, використовувані в репертуарних решітках; потраплятимуть в «діапазон придатності» конструктів випробовуваного.
Конструкти – не ізольовані утворення. Вони взаємодіють один з одним, причому характер цієї взаємодії не випадковий, а має цілісний системний характер.
В процесі заповнення репертуарних решіток випробовуваний повинен оцінити кожен об’єкт по кожному конструкту або іншим чином поставити у відповідність елементи конструктам.
Визначення репертуару означає, що елементи вибираються за певними правилами так, щоб вони відповідали певній області і всі разом були зв’язані смисловим чином (контекстом) аналогічно репертуару ролей в п’єсі. Передбачається, що, змінюючи репертуар елементів, можна «настроювати» методики на виявлення конструктів різних рівнів спільності і що відносяться до різних систем.
При перекладі з англійської мови термін матриця не використовується, оскільки репертуарні решітки не завжди є матрицею в точному значенні цього терміну: у ній на перетині рядків і стовпців не обов’язково стоять числа, не завжди витримується прямокутний формат, рядки можуть бути різної довжини.
Другий зміст цього визначення полягає в тому, що в техніці репертуарних решіток часто елементи задаються у вигляді узагальнених інструкцій, репертуару ролей, на місце яких кожна конкретна людина в думках підставляє своїх знайомих людей або конкретні предмети, якщо як елементи задані назви предметів.
Репертуарні решітки краще вважати специфічним різновидом структурованого інтерв’ю. Зазвичай ми досліджуємо систему конструктів іншої людини в ході розмови з нею. В процесі бесіди ми поступово починаємо розуміти, як вона бачить світ, що з чим пов’язане, що з чого виходить, що для чого важливе, а що ні, як вона оцінює інших людей, події і ситуації.
Решітки формалізують цей процес і дають математичне обґрунтування зв’язків між конструктами певної людини, дозволяють детальніше вивчити окремі підсистеми конструктів, помітити індивідуальне, специфічне у структурі й змісті світогляду людини.
Важливе положення техніки репертуарних решіток: орієнтація на виявлення власних конструктів випробовуваного, а не нав’язування їх йому ззовні.
Гнучкість і ефективність репертуарних решіток, якість і кількість одержуваної інформації роблять їх придатними для вирішення широкого кола завдань. Методики цього типу використовуються в різних галузях практичної діяльності: у педагогіці й соціології, у медицині, рекламі й дизайні. Метод репертуарних решіток виявився ідеально пристосованим для реалізації у вигляді діалогових програм на комп’ютері, що також сприяло його широкому розповсюдженню. Достоїнства й переваги цього методу повністю розкриваються тоді, коли є можливість, здійснивши дослідження, швидко опрацювати результати й проаналізувати їх для того, щоб уже при наступній зустрічі з випробуваним можна було уточнити й перевірити виниклі припущення, скласти й уточнити репертуарні решітки іншого типу, а якщо це необхідно, і доповниш колишню, змінивши репертуар елементів або вибірку конструктів.
2.2 Методи виявлення конструктів. Метод мінімального контексту
Метод мінімального контексту або метод тріад найчастіше використовується для виявлення конструктів. Елементи подаються групами по три. Це мінімальне число, що дозволяє визначити подібність і розходження.
Випробовуваній особі надаються три елементи з усього списку й пропонується назвати яку-небудь важливу якість, за якою два з них подібні між собою й, отже, відмінні від третього. Після того як експериментатор запише відповідь, респондента просять назвати, у чому конкретно полягає відмінність третього елемента від двох інших (якщо випробовуваний не вказав, які саме два елементи були оцінені як подібні між собою, то його просять зробити це). Відповідь на це запитання і являє собою протилежний полюс конструкта. Випробовуваному надається стільки тріад елементів, скільки вважає за потрібне експериментатор. Специфічних правил не існує. Все залежить лише від величини вибірки, тобто від кількості конструктів, що підлягають дослідженню.
Приклад
Є список із назв фруктів. Береться тріада «яблуко-груша-апельсин». Респондент виділяє два подібних об’єкти – «яблуко й груша»; якість, що визначає подібність, «відсутність алергічної реакції в респондента», відмінність третього об’єкта – «алергічність». Так виявлено особистісний конструкт «алергічність/її відсутність».
Інші методи виявлення конструктів
Франселла й Банністер описують методи, які також використовують тріади:
♦ послідовний метод;
♦ метод самоідентифікації;
♦ метод рольової персоніфікації.
У двох останніх методах у тріаду включається елемент «я сам». Келлі запропонував використовувати тріади для виявлення конструктів, оскільки цей метод відбивав його теоретичні уявлення про те, як конструкти вперше виникають. Однак у зв’язку з тим, що у випробовуваного виявляються вже сформовані конструюй, не обов’язково використовувати неодмінно три елементи. Тріада не є єдиним способом виявлення протилежною полюса.
Для виявлення конструктів можна використовувати два елементи (виявлення конструктів за допомогою діод елементів) або більш, ніж три, як це робиться в методі повного контексту. Часто використовуваний метод техніка сходового спускання Хінкла:
ü конструкти видобувають стандартним методом;
ü із приводу окремого конструкта задається запитання «До якого полюса цього конструкта ви б хотіли бути віднесені?»;
ü потім: «Чому Ви віддаєте перевагу цьому полюсу?». «Що протистоїть цьому?».
Таким чином утворюється новий конструкт, більше узагальнений, ніж вихідний.
Процес повторюється, і виділяється ієрархія конструктів.
2.3 Аналіз репертуарних решіток
Аналіз репертуарних решіток дозволяє визначити силу й спрямованість зв’язків між конструктами респондента, виявити найбільш важливі й значимі параметри (глибинні конструкти), що лежать в основі конкретних оцінок і відношень, побудувати цілісну підсистему конструктів, що дозволяє описувати й пророкувати оцінки й відношення людини.
Аналіз одиничних репертуарних решіток
Можна використовувати форму кластерного аналізу для групування конструктів. Цей алгоритм структурує конструюй в лінійний порядок так, що конструкти. які перебувають близько в просторі, також виявляються близькими в порядку. Цей алгоритм має переваги під час демонстрації, тому що подання просто реорганізує решітки, показуючи сусідство конструктів і елементів. Отже, формуються дві матриці: одна – для елементів, інша – для конструктів. Кластери визначаються вибором найбільших значень у цих матрицях тобто найбільш зв’язаних складових матриці доти, поки всі елементи й конструкти не будуть включені в кластери с черево. Програма робить ієрархічну кластеризацію системи конструктів експерта й відображає видобуті знання.
Крім того, для кожного конструкта є чисельні значення в решітках як вектор величин, пов’язаних з розташуванням елементів щодо полюсів цього конструкта. Із нього погляду кожний конструкт може бути зображений як точка в багатомірному просторі, а його площина визначається кількістю пов’язаних з ним елементів. Природною мірою відношення між конструктами с відстанню між ними в цьому багатовимірному просторі. Два конструкти з нульовою відстанню між ними – це конструкти, стосовно яких елементи структуруються однаково. Отже, можна вважати, що вони використовуються однаково. У деякому сенсі – це еквівалентні конструкти.
Для нееквівалентних конструктів можна аналізувати їхні просторові відношення, визначаючи ряд осей як проекцію кожного конструкта на вісь, найбільш віддалену від них, проекцію на другу вісь, пов’язану з відстанями, що залишилися, і т.д. Це метод аналізу головних компонент простору конструктів. Він пов’язаний з факторним аналізом семантичною простору, використаного у вивченні семантичного диференціала. Метод аналізу головних компонент дозволяє подати елементи й конструкти так, що між ними можуть бути виявлені взаємозв’язки. Можна побудувати логічний аналіз репертуарних решіток, використовуючи конструкти як предикати щодо елементів.
Аналіз декількох репертуарних решіток
Досить часто виникає ситуація, коли потрібно зрівняти кілька репертуарних решіток. Аналіз серії репертуарних решіток, заповнюваних тією самою людиною в різні моменти часу, дозволяє стежити за динамікою конструктів і оцінок, будувати траєкторії зміни стану людини в системі його власних суб’єктивних шкал.
Проаналізуємо кілька репертуарних решіток, заповнюваних різними людьми.
Аналіз пар системних конструктів використовується для вимірювання згоди й порозуміння між людьми. Для цього два експерти, що мають різні точки зору, створюють і заповнюють решітки зі спільної області знань. При цьому кожний незалежно від іншого вибирає елементи, виявляє конструкти й оцінює їх. Потім кожний робить дві порожні копії своїх решіток, залишаючи елементи й конструкти без значень їхньої оцінки. Обидві ці решітки заповнюються партнерами. При цьому одна заповнюється так, як він сам собі це уявляє, а друга так, як він уявляє собі заповнення оригінальної решітки її автором. Порівняння пар решіток допомагають досягти згоди й порозуміння між двома людьми. Існують три способи порівняння двох решіток.
1. Зчеплення решіток, що мають спільні елементи, і їхня подальше опрацювання одним з описаних алгоритмів так, ніби вони становлять одну більшу решітку. Таким чином можна досліджувати взаємодію ідей через перевірку змішаних кластерів конструктів з різних решіток.
2. Цей шлях вимагає наявності двох решіток з однаковими назвами елементів і конструктів і показує розбіжності між ними через вимірювання відстані між тими самими назвами. Результати показують згоду в розумінні й виявляють розходження між двома решітками, заснованими на однакових назвах і конструктах.
3. Цей спосіб також використовує дві решітки з однаковими назвами елементів і конструктів. знаходить елементи й конструкти. що змінюються найбільше, й видаляє їх із решіток. Таким чином визначаються базові елементи й конструкти, які показують згоду й порозуміння.
Аналіз груп системних конструктів.
Аналізується серія репертуарних решіток, отриманих від групи людей, що використовували однакові елементи. Порівнюється кожна пара й показується «групова мережа», що відображає зв’язки подібних конструктів усередині групи. Створюються решітки, що відображають конструкти, які розуміються більшістю груп, і це служить підставою для подальшого аналізу. Кожний конструкт, невикористаний у рамках групи, оцінюється за силою зв’язаності з іншими конструктами.
2.4 Автоматизовані методи
Уперше автоматизоване створення репертуарних решіток і видобування з експертів конструктів було реалізовано в системі PLANET. Подальшим розвитком системи PLANET є інтегроване середовище KITTEN, що підтримує ряд методів видобування знань. Д. Буза у системі ETS використав метод репертуарних решіток для виявлення понятійної системи предметної області. Нащадками ETS є система NewETS та інтегроване середовище для видобування експертних знань AQUINAS [19].
Відомо багато прототипів експертних систем, для створення яких використовувалася ETS. Серед них:
Ø порадник вибору інструментарію для розробників експертних систем;
Ø консультант з мов програмування;
Ø аналізатор геологічних даних;
Ø порадник із налагодження Фортран-програм;
Ø консультант із систем керування базами даних та ін.
Проте сфера застосування ETS обмежена видобуванням експертних знань для нескладних завдань аналізу, що не вимагають для свого рішення процедурних, каузальних і стратегічних знань.
ETS взаємодіє з експертом у діалоговому режимі: проводить з ним інтерв’ю і допомагає аналізувати створювану базу знань. В архітектурі ETS можуть бути виділені підсистеми:
· видобування елементів;
· виявлення конструктів;
· побудови репертуарних решіток;
· побудови графа імплікативних зв’язків;
· генерації продукційних правил;
· тестування баз знань; корекції баз знань;
· генерації баз знань для різних інструментальних засобів створення експертних систем.
У діагностичній системі MORE [20] використано принципи, подібні до тих, які лежать в основі обох описаних вище систем. Тут уперше використано кілька різних стратегій інтерв’ю. Техніка інтерв’ю, використана в MORE, спрямована на виявлення таких сутностей:
♦ гіпотези – підтвердження яких має своїм результатом діагноз;
♦ симптоми – спостереження яких наближає наступне прийняття гіпотези;
♦ умови – деяка множина подій, що не є безпосередньо симптоматичною для якої-небудь гіпотези, але яка може мати діагностичне значення для деяких інших подій;
♦ зв’язки – з’єднання сутностей;
♦ шляхи – виділений тип зв’язку, що з’єднує гіпотези із симптомами.
Відповідно до цього в системі використовуються такі стратегії інтерв’ю: диференціація гіпотез, розрізнення симптомів, симптомна обумовленість, розподіл шляху й деякі інші.
Стратегія диференціації гіпотез спрямована на пошук симптомів, які забезпечують точніше розрізнення гіпотез. Найпотужнішими є ті симптоми, які спостерігаються під час однієї події, яку піддають діагностиці.
Стратегія розрізнення симптомів виявляє специфічні характеристики симптому, які, з одного боку, ідентифікують його як наслідок деякої гіпотези, з іншого боку – протиставляють іншим.
Стратегія симптомної обумовленості спрямована на виявлення негативних симптомів, тобто симптомів, відсутність яких має більшу діагностичну вагу, ніж їхня присутність.
Стратегія розподілу шляхів забезпечує знаходження симптоматичних подій, які лежать на шляху до вже знайденого симптому. Якщо такий симптом існує, то він має більше діагностичне значення, ніж знайдений раніше. У системі KRITON [21] для видобування знань використовуються два джерела:
· експерт із його знаннями, отриманими на практиці;
· книжкові знання, документи, описи, інструкції (ці знання добре структуровані й фіксовані традиційними засобами).
Для видобування знань із першого джерела в KRITON застосовано техніку інтерв’ю, що використовує стратегію репертуарних решіток – розбивання на щаблі. Стратегія розбивання на щаблі спрямована на вияв¬лення спадкової структури предметної області. Акцент робиться на виявленні струкгури родових і видових понять (супертииів). При цьому типи, виявлені на черговому кроці застосування стратегії, стають базисом для подальшого її застосування.
У системі застосований прийом перемикання стратегій: якщо при роботі стратегії репертуарних решіток, надаючи трійки семантично зв’язаних понять, експерт не в змозі назвати ознаку, що відрізняє два з них від третього, система запускає стратегію розбивання на щаблі й, задаючи експертові запитання про поняття, пов’язані з попередніми відношеннями «рід – вид», робить спробу з’ясувати таксономічну структуру цих понять з метою виявлення ознак, що їх розрізняють.
3. Керування знаннями
3.1 Що таке «керування знаннями»?
Поняття «керування знаннями» (KM – Knowledge Management) виникло в середині 90-х років XX ст. у великих корпораціях, де проблеми опрацювання інформації набули особливої гостроти й стали критичними. При цьому стало очевидним, що основним вузьким місцем є опрацювання знань, накопичених фахівцями компанії, тому що саме знання забезпечують переваги над конкурентами. Часто інформації в компаніях накопичено навіть більше, ніж вони здатні опрацювати. Різні компанії намагаються вирішував н це питання по-різному, але при цьому кожна компанія прагне збільшити ефективність опрацювання знань [22].
Ресурси знань розрізняються залежно від галузей індустрії й додатків, але, як правило, включають керівництва, листи, новини, інформацію про замовників, відомості про конкурентів і дані, що нагромадилися в процесі розроблення. Для застосування КМ-систем використовуються різноманітні технології:
ü електронна пошта;
ü бази й сховища даних (Data Wharehouse);
ü системи групової підтримки;
ü браузери й системи пошуку;
ü корпоративні мережі й Інтернет;
ü експертні системи й бази знань; інтелектуальні системи.
Традиційно проектувальники КМ-систем орієнтувалися лише на окремі групи споживачів – головним чином менеджерів. Сучасніші КМ-системи спроектовані вже з розрахунку на цілу організацію.
Сховища даних, які працюють за принципом центрального складу, були одним з перших інструментаріїв KM. Як правило, сховища містять багаторічні версії звичайної бази даних, фізично розташовані в тій самій базі. Коли всі дані утримуються в єдиному сховищі, вивчення зв’язків між окремими елементами може бути більш плідним.
При цьому активи знань можуть перебувати в різних місцях: у базах даних, базах знань, у картотечних блоках, у фахівців і можуть бути розосереджені по всьому підприємству. Занадто часто одна частина підприємства повторює роботу іншої частини просто тому, що неможливо знаходити й використовувати знання, що перебувають в інших частинах підприємства.
Керування знаннями – це сукупність процесів, які керують створенням, поширенням, опрацюванням й використанням знань усередині підприємства.
Необхідність розроблення систем KM обумовлена такими причинами:
· працівники підприємства витрачають занадто багато часу на пошук необхідної інформації;
· досвід провідних і найбільш кваліфікованих співробітників використовується тільки ними самими;
· цінна інформація міститься у величезній кількості документів і даних, доступ до яких ускладнений;
· помилки, що потім так дорого коштують, повторюються через недостатню інформованість та ігнорування попереднього досвіду.
Важливість систем KM обумовлена також тим, що знання, що не використовуються й не примножуються, в остаточному підсумку стають застарілими й марними, так само, як гроші, які зберігаються не для того, щоб стати оборотним капіталом, в остаточному підсумку втрачають свою вартість, поки не знеціняться. Тоді як знання, що поширюються, здобуваються й обмінюються, генерують нові знання.
3.2 Керування знаннями і корпоративна пам’ять
Більшість оглядів концепції керування знання (KM) приділяють увагу тільки первинному опрацюванню корпоративної інформації типу електронної пошти, програмного забезпечення колективної роботи або гіпертекстових баз даних. Вони формують істотну частину з необхідної, але виразно недостатньої, технічної інфраструктури для керування знаннями.
Одним з нових рішень щодо керування знаннями є поняття корпоративної пам’яті (corporate memory), що за аналогією з людською пам’яттю дозволяє користуватися попереднім досвідом і уникати повторення помилок.
Корпоративна пам’ять фіксує інформацію з різних джерел підприємства іі робить цю інформацію доступною для фахівців з метою вирішення виробничих завдань.
Корпоративна пам’ять не дозволяє зникнути знанням фахівців, що вибувають (вихід на пенсію, звільнення та ін.). Вона зберігає великі обсяги даних, інформації й знань із різних джерел підприємства. Вони відображені в різних формах, таких як бази даних, документи й бази знань (Додаток А).
Введемо два рівні корпоративної пам’яті (так звані явні й неявні знання).
Рівень 1. Рівень матеріальної або явної інформації – це дані й знання, які можуть бути знайдені в документах організації у формі повідомлень, листів, статей, довідників, патентів, креслень, відео- і аудіозаписів, програмного забезпечення тощо.
Рівень 2. Рівень персональної або прихованої інформації – це персональні знання, невідривно пов’язані з індивідуальним досвідом. Вони можуть бути передані через прямий контакт – «віч-на-віч», через процедури видобування знань. Саме приховане знання – те практичне знання, що є ключовим при ухваленні рішення й керуванні технологічними процесами.
У дійсності ці два типи інформації, подібні до двох сторін однієї й тої самої медалі, однаково важливі у структурі корпоративної пам’яті (Додаток А).
При розроблені систем KM можна виділити ряд етапів.
1. Нагромадження. Стихійне й безсистемне нагромадження інформації в організації.
2. Видобування. Процес, ідентичний традиційному видобуванню знань для експертних систем. Це один з найбільш складних і трудомістких етапів. Від його успішності залежить подальша життєздатність системи.
3. Структурування. На цьому етапі повинні бути виділені основні поняття, вироблена структура подання інформації, що має максимальну наочність, простоту зміни й доповнення.
4. Формалізація. Подання структурованої інформації у форматах машинного опрацювання, тобто на мовах опису даних і знань.
5. Обслуговування. Під процесом обслуговування розуміється коректування формалізованих даних і знань (додавання, відновлення): «чищення», тобто видалення застарілої інформації; фільтрація даних і знань для пошуку інформації, необхідної користувачам.
Якщо перші чотири етапи звичайні для інженерії знань, то останній є специфічним для систем керування знаннями. Як уже було сказано, він розпадається на три дрібніших процеси:
§ коректування формалізованих знань (додавання, відновлення);
§ видалення застарілої інформації;
§ фільтрація знань для пошуку інформації, необхідної користувачеві, виділяє компоненти даних і знань, що відповідають вимогам конкретного користувача. За допомогою тої самої процедури користувач може довідатися про місцезнаходження інформації, що його цікавить.
Розглянута вище класифікація не є єдиною, але вона дозволяє зрозуміти, що відбувається в реальних системах керування знаннями.
3.3 Системи OMIS
Автоматизовані системи KM, або Organizational Memory Information Systems (OMIS), призначені для нагромадження й керування знаннями підприємства [23]. OMIS включають роботу як на рівні 1 – з явним знанням компанії у формі баз даних і електронних архівів, так і на рівні 2 – зі схованим знанням, фіксуючи його в певному (більш-менш формальному) поданні у формі експертних систем або баз даних.
OMIS часто використовують допоміжні довідкові системи, так звані helpdesk-додатки.
Вкажемо основні функції OMIS.
ü Збирання і систематична організація інформації з різних джерел у централізоване й структурне інформаційне сховище.
ü Інтеграція з наявними автоматизованими системами. На технічному рівні це означає, що корпоративна пам’ять повинна бути безпосередньо пов’язана за допомогою інтерфейсу з інструментальними засобами, які в цей час використовуються в організації (наприклад, текстові процесори, електронні таблиці, системи).
ü Забезпечення погрібної інформації на запит (пасивна форма) і при необхідності – активна форма. Занадто часті помилки – це наслідок недостатньої інформованості. Цього неможливо уникнути за допомогою пасивної інформаційної системи, тому що службовці часто надто зайняті, щоб шукати інформацію, або просто не знають, що потрібна інформація існує. Корпоративна пам’ять може нагадувати службовцям про корисну інформацію й бути компетентним партнером для спільного вирішення завдань.
Кінцева мета OMIS полягає в тому, щоб забезпечити доступ до знань щоразу, коли це необхідно. Щоб забезпечити це, OMIS реалізує активний підхід поширення знань, що не надається на запити користувачів, а автоматично забезпечує корисні для рішення завдання знання. Щоб запобігати інформаційному перевантаженню, цей підхід має бути поєднаний з високою вибірковою оцінкою доречності. Закінчена система повинна діяти як інтелектуальний помічник користувача.
Використання корпоративної пам’яті часто переслідує більш помірковані цілі, ніж використання інтелектуальних систем. Це пов’язано з тим, що технології опрацювання даних (баз даних і гіпертекстових систем) застосовуються набагато ширше, ніж технології систем, заснованих на знаннях. OMIS зберігають і забезпечують видачу на запит погрібної інформації, але залишають її інтерпретацію й оцінку в специфічному контексті завдання головне користувачеві.
З іншого боку, корпоративна пам’ять розширює ці технології роботою зі знаннями, щоб поліпшити якість рішення завдань. Так, OMIS включає підсистеми пояснень, які дозволяють безпосередньо відповідати на запитання: «Чому?» і «Чому немає?». У простій базі даних або гіпертекстовій системі користувачі повинні були б шукати потрібну інформацію для відповіді на такі запитання безпосередньо, а для цього необхідно відфільтрувати велику кількість потенційно потрібної інформації, що, однак, не буде застосовуватися у специфічному випадку.
У Додатку Б зображена архітектура для OMIS і корпоративної пам’яті (частково з роботи). Ядром системи є Інформаційне сховище (Information Depository).
Додаток Б також дає уявлення про деякі види інформації, що включається до корпоративної пам’яті. Якщо сховища даних містять, в основному, кількісну інформацію, то сховища знань більше орієнтовані на якісний матеріал. КМ-системи генерують системи із широкого діапазону даних, сховищ даних, статей новин, зовнішніх баз, WWW-сторінок.
Програмний інструментарій для OMIS включає як оригінальні розроблення, наприклад, KARAT, так і стандартні засоби, наприклад, LOTUS NOTES, яка забезпечила один з перших інструментаріїв зберігання якісною й документальною інформацією. Але сьогодні у зв’язку з бурхливим розвитком Інтернету, КМ-системи все частіше використовують Web-технологію.
4. Візуальне проектування баз знань як інструмент пізнання
Візуальні методи специфікації і проектування баз знань і розробка концептуальних структур є достатньо ефективним гносеологічним інструментом (інструментом пізнання). Використання методів інженерії знань як дидактичних інструментів і як формалізмів представлення знань сприяє швидшому і повнішому розумінню структури знань даної предметної області, що є особливо цінним для новачків на стадії вивчення особливостей професійної діяльності.
Методи візуальної інженерії знань можна широко використовувати в різних навчальних закладах – від шкіл до університетів – як для поглиблення процесу розуміння, так і для контролю знань. Більшість учнів і студентів опановують навики візуальної структуризації протягом декількох годин.
4.1 Від понятійних карт до семантичних мереж
Якщо поле знань – це умовний неформальний опис основних понять і взаємозв’язків між поняттями предметної області, виявлених із системи експерта, у вигляді графа, діаграми, таблиці чи тексту, то це визначення дозволяє інженерові по знаннях трактувати форму представлення поля досить широко, зокрема семантичні мережі або понятійні карти (concept maps) є можливою формою представлення. Це означає, що сам процес побудови семантичних мереж допомагає усвідомлювати пізнавальні структури.
Програми візуалізації є інструментом, що дозволяє зробити видимими семантичні мережі пам’яті людини.
Мережі складаються з вузлів і впорядкованих співвідношень або зв’язків, що сполучають ці вузли. Вузли виражають поняття або припущення, а зв’язки описують відношення між цими вузлами. Тому розробка семантичних мереж включає аналіз структурних взаємодій між окремими поняттями предметної області.
В процесі створення семантичних мереж експерт і аналітик вимушені аналізувати структури своїх власних знань, що допомагає їм включати нові знання в структури вже наявних знань. Результатом цього є більш осмислене використання придбаних знань.
Візуальні специфікації у формі мереж можуть використовуватися новачками і експертами як інструменти для оцінки змін, подій в їх мисленні. Якщо погодитися, що семантична мережа є достатньо повним представленням пам’яті людини, то процес навчання з цієї точки зору можна розглядати як реорганізацію семантичної пам’яті.
Козма, один з розробників програми організації семантичної мережі Learning Tool, вважає, що ці засоби є інструментами пізнання, що підсилюють і розширюють пізнання людини. Розробка семантичних мереж вимагає від учнів:
· реорганізації знань;
· вичерпного опису понять і зв’язків між ними;
· глибокої обробки знань, що сприяє кращому запам’ятовуванню і витяганню з пам’яті знань, а також підвищує здібності застосовувати знання в нових ситуаціях;
· зв’язування нових понять з існуючими поняттями і уявленнями, що покращує розуміння;
· просторового вивчення за допомогою просторового представлення понять в області, що вивчається [24].
Корисність семантичних мереж і карт понять, мабуть, краще всього демонструється їх зв’язками з іншими формами мислення вищого порядку. Вони тісно пов’язані з формальним обґрунтуванням в хімії і здатністю аргументувати свої вислови в біології. Також було показано, що семантичні мережі мають зв’язок з виконанням досліджень.
4.2 База знань як пізнавальний інструмент
Коли семантична мережа створюється як прообраз бази знань, розробник повинен фактично моделювати знання експерта. Особливо глибокого розуміння вимагає розробка функціональної структури.
Визначення структури «Якщо…, то…» області знань вимагає чітко формулювати принципи ухвалення рішення. Не можна вважати, що просто розробка поля знань системи обов’язково приведе до отримання повних функціональних знань в даній області.
Розробка експертних систем почала використовуватися як інструмент пізнання порівняно недавно.
Наприклад, Лей встановив, що після того, як студенти-медики створять медичну експертну систему, вони підвищать своє уміння в плані аргументації і отримають глибші знання по предмету, що вивчається.
Шість студентів-першокурсників фізичного факультету, які використовували експертні системи для складання питань, ухвалення рішень, формулювання правил і пояснень щодо руху частинки відповідно до законів класичної фізики, отримали глибші знання в даній області завдяки ретельній роботі, пов’язаній з кодуванням інформації і обробкою великого матеріалу для отримання ясного і зв’язного змісту, а отже, і більшої семантичної глибини [25].
Таким чином, створення бази знань експертної системи сприяє глибшому засвоєнню знань, а візуальна специфікація підсилює прозорість і наочність уявлень.
Коли комп’ютери використовуються в навчанні як інструмент пізнання, а не як контрольно-навчальні системи (навчальні комп’ютери), вони розширюють можливості автоматизованих навчальних систем, одночасно розвиваючи розумові здібності і знання учнів. Результатом такої співпраці учня і комп’ютера є значне підвищення ефективності навчання.
Комп’ютери не можуть і не повинні управляти процесом навчання. Комп’ютери повинні використовуватися для того, щоб допомогти учням придбати знання.
Висновок
У даній роботі розглянуті прикладні аспекти інженерії знань, використання латентних структур знань та психосемантики для видобування глибинних знань, а також описаний метод репертуарних решіток, керування знаннями та проектування бази знань.
Всі ці методи створені і використовуються для спрощення «співпраці» користувача з комп’ютером, для мінімізації труднощів видобування та формалізації знань. Таким чином, розглянуті основні шляхи розв’язання достатньо поширених на сьогодні проблем інженерії знань.
Список використаних джерел
1. Петренко В.Ф. Введение в эксперементальную психосемантику: исследование форм репрезентации в обыденном сознании / В.Ф. Петренко. – М.: МГУ, 1983. – 175 с.
2. Анисимов А.В. система обработки текстов на естественном языке / А.В. Анисимов, А.А. Марченко // Научно-теоретический журнал «Искуственный интелект», ІПШІ «Наука і освіта». – 2002. – Вип. 4 – С. 157–163.
3. Петренко В.Ф. Психосемантика сознания / В.Ф. Петренко. – М.: Издательство МГУ, 1988. – 207 с.
4. Аверкин А.Н. Нечеткие множества в моделях управления и искуственного интеллекта / А.Н. Аверкин, И.З. Батыршин, А.Ф. Блишун. – М.: Наука, 1986. – 312 с.
5. Тиори Т. Проектирование структур баз даннях: В 2-х кн. / Т. Тиори, Дж. Фрай. – М.: Мир, 1985. – 288 с.
6. Дюран Б. Кластерныйанализ / Б. Дюран, П. Оделл. – М.: Статистика, 1977. – 128 с.
7. Кук Н.М. Формальная методология приобретения и представления экспертных знаний / Н.М. Кук, Дж. Макдональд // ТИИЭР. – 1986. – Т. 74. – №10. – С. 145–155.
8. Gruber T.R. A translation approach to portable ontologies // Knowledge Acquisition. – 1993. – №5 (2). – P. 199–220.
9. Гаврилова Т.А. Представление знаний в экспертной диагностической системе АВ-ТАНТЕСТ / Т.А. Гаврилова // Изв. АН СССР. Техническая кибернетика. – 1984. – №5. – С. 165–173.
10. Франселла Ф. Новый метод исследования личности: руководство по репертуарным личностным методикам / Ф. Франселла, Д. Баннистер. – М.: Прогресс, 1987. – 588 с.
11. Похилько В.И. Система КЕПУ / В.И. Похилько, Н.Н. Страхов. – М.: МГУ, 1990. – 35 с.
12. Терехина А.Ю. Представление структуры знаний методами многомерного шкалирования / А.Ю. Терехина. – М.: ВИНИТИ, 1988. – 97 с.
13. Шенк Р. Обработка концептуальной информации / Р. Шенк. – М.: Энергия, 1980. – 361 с.
14. Bosse J.H. Transforming repertory grids to shell-based knowledge based using AQUINAS, a knowledge acquisition workbench / Bosse J.H., Bradshaw J.H., Shema D.B. // Proceedings of the AAAI-88 Integration of Knowledge Acquisition and Performance Systems Workshop. St. Paul.
15. Дэйвисон М. Многомерное шкалирование. Методы наглядного представления данных / М. Дэйвисон. – М.: Финансы и статистика, 1988. – 254 с.
16. Musen M.A. Automated support for building and extending expert models // Machine Learning, 4. – 1989. – pp. 347–376.
17. TOVE, 1999. TOVE Manual. – Department of Industrial Engeneering, University of Toronto.
18. Kuehn O. Corporate Memories for Knowledge Management in Industrial Practice: Prospects and Challenges / Kuehn O., Abecker A. – 1998. – 189 p.
19. Assadi H. Knowledge acquisition from texts. Proceedings of the 35th Annual Meeting of the Association for Computational Linguistics (ACL’97), Madrid? Spain, 1997.
20. Kelly G.A. The Psychology of Personal Constructs. – N.Y.: Norton, 1955. – 493 p.
21. E. Fiesler and H.J. Caulfield, «Neural network formalization», Computer Standarts and Interfaces, 1994 – vol. 16 (3), – pp. 231–239.
22. Maedche A. Ontology learning for the semantic web / Maedche A., Staab S. // IEEE Intelligent Systems 16 (2). – 2001. – pp. 72–79.
23. L. Smith. Using a framework to specify a network of temporal neurons, Technical Report, University of Stirling, 1996. – 289 p.
24. Furna G.W. Multitrees: Enriching and Reusing Hierarchical Structure // Human Factors in Computing Systems. Conference Proceedings. Boston, Ms, 1994. – pp. 330–334.
25. M.A. Atencia, G. Joya and F. Sandoval, «A formal model for definition and simulation of generic neural networks», Neural Processing Letters, Kluwer Academic Publishers. – vol. 11. – 2000. – pp. 87–105.