Лабораторная работа: Работа и устройство процессоров
"Мозгом" персонального компьютера является микропроцессор, или центральный процессор — CPU (Central Processing Unit). Микропроцессор выполняет вычисления и обработку данных (за исключением некоторых математических операций, осуществляемых в компьютерах, имеющих сопроцессор) и, как правило, является самой дорогостоящей микросхемой компьютера. Во всех PC-совместимых компьютерах используются процессоры, совместимые с семейством микросхем Intel, но выпускаются и проектируются они как самой Intel, так и компаниями AMD, Cyrix, IDT и Rise Technologies.В настоящее время Intel доминирует на рынке процессоров, но так было далеко не всегда. Компания Intel прочно ассоциируется с изобретением первого процессора и его появлением на рынке. Но, несмотря на это, два наиболее известных в конце 1970-х годов процессора, используемых в ПК, не принадлежали Intel (один из них, правда, являлся прямым аналогом процессора Intel). В персональных компьютерах того времени чаще всего использовались процессоры Z-80 компании Zilog и 6502 компании MOS Technologies. Процессор Z-80 представлял собой улучшенный и более дешевый аналог процессора 8080. Сегодня подобная ситуация произошла с многочисленными клонами процессоров Intel Pentium, созданными компаниями AMD, Cyrix (теперь VIA), IDT и Rise Technologies. Более того, в некоторых случаях аналог приобретал большую популярность, чем оригинал. Компания AMD в течение прошлого года заняла значительную часть рынка и в результате получила большую прибыль. Но, несмотря на это, многие утверждают, что Intel все еще играет главенствующую роль на рынке процессоров ПК.
История развития процессоров до появления первого PC
Обратите внимание, что первый процессор был выпущен за 10 лет до появления первого компьютера IBM PC. Он был разработан компанией Intel, назван Intel 4004, а его выпуск состоялся 15 ноября 1971 года. Рабочая частота этого процессора составляла всего 108 кГц (0,108 МГц!). Этот процессор содержал 2 300 транзисторов и производился по 10-микронной технологии. Шина данных имела ширину 4 разряда и позволяла адресовать 640 байт памяти. Процессор 4004 использовался в схемах управления светофоров, анализаторах крови и даже на межпланетной научно-исследовательской станции NASA Pioneer 10!15 ноября 2001 года исполнилось 30 лет со дня появления первого микропроцессора. За эти годы быстродействие процессора увеличилось более чем в 18 500 раз (с 0,108 МГцдо 2 ГГц).В апреле 1972 года Intel выпустила процессор 8008, который работал на частоте 200 кГц. Он содержал 3 500 транзисторов и производился все по той же 10-микронной технологии. Шина данных была 8-разрядной и позволяла адресовать 16 Кбайт памяти. Этот процессор предназначался для использования в терминалах и программируемых калькуляторах. Следующая модель процессора, 8080, была анонсирована в апреле 1974 года. Этот процессор содержал 6 000 транзисторов и мог адресовать уже 64 Кбайт памяти. На нем был собран первый персональный компьютер (не PC) Altair 8800. В этом компьютере использовалась операционная система CP/M, а Microsoft разработала для него интерпретатор языка BASIC. Это была первая массовая модель компьютера, для которого были написаны тысячи программ. Со временем процессор 8080 стал настолько известен, что его начали копировать. В конце 1975 года несколько бывших инженеров Intel, занимавшихся разработкой процессора 8080, создали компанию Zilog. В июле 1976 года эта компания выпустила процессор Z-80, который представлял собой значительно улучшенную версию 8080. Этот процессор был не совместим с 8080 по контактным выводам, но сочетал в себе множество различных функций, например интерфейс памяти и схему обновления ОЗУ (RAM), что давало возможность разработать более дешевые и простые компьютеры. В Z-80 был также включен расширенный набор команд процессора 8080, позволяющий использовать его программное обеспечение. В этот процессор вошли новые команды и внутренние регистры, поэтому программное обеспечение, разработанное для Z-80, могло использоваться практически со всеми версиями 8080. Первоначально процессор Z-80 работал на частоте 2,5 МГц (более поздние версии работали уже на частоте 10 МГц), содержал 8,5 тыс. транзисторов и мог адресовать 64 Кбайт памяти. Компания Radio Shack выбрала процессор Z-80 для своего первого персонального компьютера TRS-80 Model 1. Следует заметить, что Z-80 стал первым процессором, используемым во многих новаторских системах, к числу которых относятся также системы Osborne и Kaypro. Этому примеру последовали другие компании, и вскоре Z-80 стал стандартным процессором для систем, работающих с операционной системой CP/M и наиболее распространенным программным обеспечением того времени. Intel не остановилась на достигнутом и в марте 1976 года выпустила процессор 8085, который содержал 6 500 транзисторов, работал на частоте 5 МГц и производился по 3-микронной технологии. В этом же году компания MOS Technologies выпустила процессор 6502, который был абсолютно непохож на процессоры Intel. Он был разработан группой инженеров компании Motorola. Эта же группа работала над созданием процессора 6800, который в будущем трансформировался в семейство процессоров 68000. Цена первой версии процессора 8080 достигала 300 долларов, в то время как 8-разрядный процессор 6502 стоил всего около 25 долларов. Такая цена была более приемлема для Стива Возняка (Steve Wozniak), который встроил этот процессор в новые модели Apple I и Apple II. Процессор 6502 использовался также в системах, созданных компанией Commodore и другими производителями. Этот процессор и его преемники с успехом работали в игровых компьютерных системах, в число которых вошла приставка Nintendo Entertainment System (NES). Компания Motorola продолжила работу над созданием серии процессоров 68000, которые впоследствии были использованы в компьютерах Apple Macintosh. В настоящее время в этих системах применяется процессор PowerPC, являющийся преемником 68000.
В июне 1978 года Intel выпустила процессор 8086, который содержал набор команд под кодовым названием х86. Этот же набор команд до сих пор поддерживается в процессорах Pentium III. Процессор 8086 был полностью 16-разрядным — внутренние регистры и шина данных. Он содержал 29 000 транзисторов и работал на частоте 5 МГц. Благодаря 20-разрядной шине адреса он мог адресовать 1 Мбайт памяти. При создании процессора 8086, обратная совместимость с 8080 не предусматривалась. Но, в то же время значительное сходство их команд и языка позволили использовать более ранние версии программного обеспечения. Это свойство впоследствии сыграло важную роль в развитии программного обеспечения ПК, включая операционную систему CP/M (8080).Несмотря на высокую эффективность процессора 8086, его цена была все же слишком высока по меркам того времени и, что еще важнее, для его работы требовалась дорогая микросхема поддержки 16-разрядной шины данных. Чтобы уменьшить себестоимость процессора, в 1979 году компания Intel выпустила упрощенную версию 8086, которая получила название 8088. Процессор 8088 использовал те же внутреннее ядро и 16-разрядные регистры, что и 8086, мог адресовать 1 Мбайт памяти, но, в отличие от предыдущей версии, использовал внешнюю 8-разрядную шину данных. Это позволило обеспечить обратную совместимость с ранее разработанным 8-разрядным процессором 8085 и, таким образом, значительно снизить стоимость создаваемых системных плат и компьютеров. Именно поэтому IBM выбрала для своего первого ПК "урезанный" процессор 8088.Это решение имело далеко идущие последствия для всей компьютерной индустрии. Процессор 8088 был полностью программно-совместимым с 8086, что позволяло использовать 16-разрядное программное обеспечение. В процессорах 8085 и 8080 использовался очень похожий набор команд, поэтому программы, написанные для процессоров предыдущих версий, можно было достаточно легко преобразовать для процессора 8088. Это, в свою очередь, позволяло разрабатывать разнообразные программы для персонального компьютера IBM, что явилось залогом его будущего успеха. Не желая останавливаться на полпути, Intel была вынуждена обеспечить поддержку обратной совместимости 8088/8086 с большей частью процессоров, выпущенных в то время. В те годы еще поддерживалась обратная совместимость процессоров, что ничуть не мешало вводить различные новшества или дополнительные возможности. Одним из основных изменений стал переход от 16-разрядной внутренней архитектуры процессора 286 и более ранних версий к 32-разрядной внутренней архитектуре 386-го и последующих процессоров, относящихся к категории IA-32 (32-разрядная архитектура Intel). Однако до появления серийно выпускаемого программного обеспечения, поддерживающего 32-разрядные команды, оставалось еще более 10 лет. Например, в 1985 году с появлением процессора 386DX была представлена новая 32-разрядная архитектура, но только в 1995 году была выпущена Windows 95, ставшая первой широко распространенной операционной системой, поддерживающей архитектуру IA-32. Введение новой архитектуры не повлияло на обратную совместимость процессоров, так как практически все микросхемы IA-32 выполняли и 16-разрядные команды. Не так давно компания Intel выпустила процессор Itanium, представив тем самым новую 64-разрядную архитектуру Intel (IA-64). В течение ближайших нескольких лет эта архитектура будет использоваться в серверных (т. е. в более мощных и дорогих) микросхемах. Поддержка обратной совместимости процессоров IA-32, как вы знаете, выражается в возможности выполнения 16-разрядных команд. Микросхемы IA-64, в свою очередь, могут выполнять не только 32-разрядные (IA-32), но и 16-разрядные (IA-16) команды. В компании AMD была разработана конкурентоспособная, но несколько отличная 64-разрядная архитектура, получившая название x86-64; она будет использоваться в микросхемах с кодовым именем Hammer. Ее основным отличием является то, что архитектура AMD x86-64 более близка к существующей IA-32, чем новая 64-разрядная архитектура IA-64. Предполагается, что микросхемы x86-64 будут выполнять существующий 32-разрядный код быстрее, чем процессоры, созданные на основе IA-64. К сожалению, процессоры x86-64 не позволяют выполнять программный код, разработанный непосредственно для IA-64, что связано с коренными отличиями наборов команд и архитектуры. Процессор Itanium (IA-64) был выпущен в марте 2001 года и уже завоевал солидную репутацию на рынке серверов и рабочих станций. Растущая популярность IBM PC и архитектуры Intel, в некотором роде, ограничила развитие персонального компьютера. Тем не менее, успех IBM PC привел к разработке большого количества программ, периферийных устройств и аксессуаров, в результате чего PC стал промышленным стандартом. Процессор 8088, который использовался в первом PC, содержал около 30 тыс. транзисторов и работал на частоте 5 МГц. Одна из последних версий процессора Pentium III Xeon имеет кэш-память второго уровня объемом 2 Мбайт и содержит 140 млн. транзисторов — самый большой показатель за всю историю полупроводниковых устройств. На данный момент Intel выпустила процессоры, работающие на частоте свыше 3 ГГц, и следует заметить, что компания AMD практически не отстает от лидера. Все это является практическим подтверждением закона Мура, в соответствии с которым быстродействие процессоров и количество содержащихся в них транзисторов удваивается каждые 1,5-2 года.
Параметры процессоров
При описании параметров и устройства процессоров часто возникает путаница. Рассмотрим некоторые характеристики процессоров, в том числе разрядность шины данных и шины адреса, а также быстродействие. Процессоры можно классифицировать по двум основным параметрам: разрядности и быстродействию. Быстродействие процессора — довольно простой параметр. Оно измеряется в мегагерцах (МГц); 1 МГц равен миллиону тактов в секунду. Чем выше быстродействие, тем лучше (тем быстрее процессор). Разрядность процессора — параметр более сложный. В процессор входит три важных устройства, основной характеристикой которых является разрядность:
- шина ввода и вывода данных; внутренние регистры;
-шина адреса памяти.
Шина данных
Когда говорят о шине процессора, чаще всего имеют в виду шину данных, представленную как набор соединений (или выводов) для передачи или приема данных. Чем больше сигналов одновременно поступает на шину, тем больше данных передается по ней за определенный интервал времени и тем быстрее она работает. Разрядность шины данных подобна количеству полос движения на скоростной автомагистрали; точно так же, как увеличение количества полос позволяет увеличить поток машин по трассе, увеличение разрядности позволяет повысить производительность. Данные в компьютере передаются в виде цифр через одинаковые промежутки времени. Для передачи единичного бита данных в определенный временной интервал посылается сигнал напряжения высокого уровня (около 5 В), а для передачи нулевого бита данных — сигнал напряжения низкого уровня (около 0 В). Чем больше линий, тем больше битов можно передать за одно и то же время. Современные процессоры типа Pentium имеют 64-разрядные внешние шины данных. Это означает, что процессоры Pentium, включая Pentium 4, Athlon и даже Itanium, могут передавать в системную память (или получать из нее) одновременно 64 бит данных. Представим себе, что шина — это автомагистраль с движущимися по ней автомобилями. Если автомагистраль имеет всего по одной полосе движения в каждую сторону, то по ней в одном направлении в определенный момент времени может проехать только одна машина. Если вы хотите увеличить пропускную способность дороги, например, вдвое, вам придется ее расширить, добавив еще по одной полосе движения в каждом направлении. Таким образом, 8-разрядную микросхему можно представить в виде однополосной автомагистрали, поскольку в каждый момент времени по ней проходит только один байт данных (один байт равен восьми битам). Аналогично, 32-разрядная шина данных может передавать одновременно четыре байта информации, а 64-разрядная подобна скоростной автостраде с восемью полосами движения. Разрядность шины данных процессора определяет также разрядность банка памяти. Это означает, что 32-разрядный процессор, например класса 486, считывает из памяти или записывает в память 32 бита одновременно.
Шина адреса
Шина адреса представляет собой набор проводников; по ним передается адрес ячейки памяти, в которую или из которой пересылаются данные. Как и в шине данных, по каждому проводнику передается один бит адреса, соответствующий одной цифре в адресе. Увеличение количества проводников (разрядов), используемых для формирования адреса, позволяет увеличить количество адресуемых ячеек. Разрядность шины адреса определяет максимальный объем памяти, адресуемой процессором. Представьте себе следующее. Если шина данных сравнивалась с автострадой, а ее разрядность — с количеством полос движения, то шину адреса можно ассоциировать с нумерацией домов или улиц. Количество линий в шине эквивалентно количеству цифр в номере дома. Например, если на какой-то гипотетической улице номера домов не могут состоять более чем из двух цифр (десятичных), то количество домов на ней не может быть больше ста (от 00 до 99), т. е. 102. При трехзначных номерах количество возможных адресов возрастает до 103 (от 000 до 999) и т. д. В компьютерах применяется двоичная система счисления, поэтому при двухразрядной адресации можно выбрать только четыре ячейки (с адресами 00, 01, 10 и 11), т. е. 22, при трехразрядной — восемь (от 000 до 111), т. е. 23. Например, в процессорах 8086 и 8088 используется 20-разрядная шина адреса, поэтому они могут адресовать 220 (1 048 576) байт, или 1 Мбайт, памяти. Шины данных и адреса независимы, и разработчики микросхем выбирают их разрядность по своему усмотрению, но, чем больше разрядов в шине данных, тем больше их и в шине адреса. Разрядность этих шин является показателем возможностей процессора: количество разрядов в шине данных определяет способность процессора обмениваться информацией, а разрядность шины адреса — объем памяти, с которым он может работать.
Внутренние регистры
Количество битов данных, которые может обработать процессор за один прием, характеризуется разрядностью внутренних регистров. Регистр — это, по существу, ячейка памяти внутри процессора; например, процессор может складывать числа, записанные в двух различных регистрах, а результат сохранять в третьем регистре. Разрядность регистра определяет количество разрядов обрабатываемых процессором данных, а также характеристики программного обеспечения и команд, выполняемых чипом. Например, процессоры с 32-разрядными внутренними регистрами могут выполнять 32-разрядные команды, которые обрабатывают данные 32-разрядными порциями, а процессоры с 16-разрядными регистрами этого делать не могут. Во всех современных процессорах внутренние регистры являются 32-разрядными. Процессор Itanium имеет 64-разрядные внутренние регистры, которые необходимы для более полного использования функциональных возможностей новых версий операционных систем и программного обеспечения. В некоторых процессорах разрядность внутренней шины данных (а шина состоит из линий передачи данных и регистров!) больше, чем разрядность внешней. Так, например, в процессорах 8088 и 386SX разрядность внутренней шины только вдвое больше разрядности внешней шины. Такие процессоры (их часто называют половинчатыми или гибридными) обычно являются более дешевыми вариантами исходных. Например, в процессоре 386SХ внутренние операции 32-разрядные, а связь с внешним миром осуществляется через 16-разрядную внешнюю шину. Это позволяет разработчикам проектировать относительно дешевые системные платы с 16-разрядной шиной данных, сохраняя при этом совместимость с 32-разрядным процессором 386.Если разрядность внутренних регистров больше разрядности внешней шины данных, то для их полной загрузки необходимо несколько циклов считывания. Например, в процессорах 386DХ и 386SХ внутренние регистры 32-разрядные, но процессору 386SХ для их загрузки необходимо выполнить два цикла считывания, а процессору 386DХ достаточно одного. Аналогично передаются данные от регистров к системной шине. В процессорах Pentium шина данных 64-разрядная, а регистры 32-разрядные. Такое построение на первый взгляд кажется странным, если не учитывать, что в этом процессоре для обработки информации служат два 32-разрядных параллельных конвейера. Pentium во многом подобен двум 32-разрядным процессорам, объединенным в одном корпусе, а 64-разрядная шина данных позволяет быстрее заполнить рабочие регистры. Архитектура процессора с несколькими конвейерами называется суперскалярной. Современные процессоры шестого поколения, например Pentium Pro и Pentium II/III, имеют целых шесть внутренних конвейеров для выполняющихся команд. Хотя некоторые из указанных внутренних конвейеров специализированы (т. е. предназначены для выполнения специальных функций), эти процессоры могут все же выполнять три команды за один цикл. В последней версии процессора Itanium используются 10-ступенчатые параллельные конвейеры, которые позволяют выполнять до 20 операций в течение одного такта.
Быстродействие процессора
Быстродействие — это одна из характеристик процессора, которую зачастую толкуют по-разному. Быстродействие компьютера во многом зависит от тактовой частоты, обычно измеряемой в мегагерцах (МГц). Она определяется параметрами кварцевого резонатора, представляющего собой кристалл кварца, заключенный в небольшой оловянный контейнер. Под воздействием электрического напряжения в кристалле кварца возникают колебания электрического тока с частотой, определяемой формой и размером кристалла. Частота этого переменного тока и называется тактовой частотой. Микросхемы обычного компьютера работают на частоте нескольких миллионов герц. (Герц — одно колебание в секунду.) Быстродействие измеряется в мегагерцах, т. е. в миллионах циклов в секунду. Наименьшей единицей измерения времени (квантом) для процессора как логического устройства является период тактовой частоты, или просто такт. На каждую операцию затрачивается минимум один такт. Например, обмен данными с памятью процессор Pentium II выполняет за три такта плюс несколько циклов ожидания. (Цикл ожидания — это такт, в котором ничего не происходит; он необходим только для того, чтобы процессор не "убегал" вперед от менее быстродействующих узлов компьютера.) Различается и время, затрачиваемое на выполнение команд. Различное количество тактов, необходимых для выполнения команд, затрудняет сравнение производительности компьютеров, основанное только на их тактовой частоте (т. е. количестве тактов в секунду). Почему при одной и той же тактовой частоте один из процессоров работает быстрее другого? Причина кроется в производительности. Оценивать эффективность центрального процессора довольно сложно. Центральные процессоры с различными внутренними архитектурами выполняют команды по-разному: одни и те же команды в разных процессорах могут выполняться либо быстрее, либо медленнее. Чтобы найти удовлетворительную меру для сравнения центральных процессоров с различной архитектурой, работающих на разных тактовых частотах, Intel изобрела специфический ряд эталонных тестов, которые можно выполнить на микросхемах Intel, чтобы измерить относительную эффективность процессоров. Эта система тестов недавно была модифицирована для того, чтобы можно было измерять эффективность 32-разрядных процессоров; она называется индексом (или показателем) iCOMP 2.0 (intel Comparative Microprocessor Performance — сравнительная эффективность микропроцессора Intel). В настоящее время используется третья версия этого индекса — iCOMP 3.0.Почему при одной и той же тактовой частоте один из процессоров работает быстрее другого? Причина кроется в производительности. Процессор 486 обладает более высоким быстродействием по сравнению с 386-м, так как на выполнение команды ему требуется в среднем в два раза меньше тактов, чем 386-му. А процессору Pentium — в два раза меньше тактов, чем 486-му. Таким образом, процессор 486 с тактовой частотой 133 МГц (типа AMD 5x86-133) работает даже медленнее, чем Pentium с тактовой частотой 75 МГц! Это происходит потому, что при одной и той же частоте Pentium выполняет вдвое больше команд, чем процессор 486. Pentium II и III — приблизительно на 50% быстрее процессора Pentium, работающего на той же частоте, потому что они могут выполнять значительно больше команд в течение того же количества циклов.Сравнивая относительную эффективность процессоров, можно увидеть, что производительность процессора Pentium III, работающего на тактовой частоте 1 000 МГц, теоретически равна производительности процессора Pentium, работающего на тактовой частоте 1 500 МГц, которая, в свою очередь, теоретически равна производительности процессора 486, работающего на тактовой частоте 3 000 МГц, а она, в свою очередь, теоретически равна производительности процессоров 386 или 286, работающих на тактовой частоте 6 000 МГц, или же 8088-го, работающего на тактовой частоте 12 000 МГц. Если учесть, что первоначальный PC с процессором 8088 работал на тактовой частоте, равной всего лишь 4,77 МГц, то сегодняшние компьютеры работают более чем в 1,5 тыс. раз быстрее. Поэтому нельзя сравнивать производительность компьютеров, основываясь только на тактовой частоте; необходимо принимать во внимание то, что на эффективность системы влияют и другие факторы.
Эффективность процессоров
Процессоры Athlon XP, созданные в компании AMD, отличаются прекрасными рабочими характеристиками и обладают целым рядом других качеств, но при этом, к сожалению, возрождают печально известные традиции оценки эффективности. Обычно приводится некая условная величина, выраженная в мегагерцах, которая не столько определяет фактическое быстродействие той или иной микросхемы, сколько указывает на приблизительную оценку ее эффективности по отношению к процессору Intel Pentium 4 первого поколения, имеющему примерно те же параметры. Как бы странно это ни звучало, но это действительно так! Испытание рабочих характеристик, проведенное в компании AMD, показывает, что процессор Athlon, имеющий тактовую частоту 1,8 ГГц, работает примерно с той же производительностью, что и процессор Pentium 4 с рабочей частотой 2,2 ГГц. На этом основании данному процессору присваивается имя "Athlon XP 2200+", где число "2200+" обозначает его эффективность по отношению к процессору Pentium 4, выраженную в мегагерцах. Подобная схема сбыта продукции, при которой процессору присваивается значение, определяющее не столько реальную, сколько относительную оценку эффективности, ничего хорошего не дает. В определенных случаях такой маркетинг оставляет у потребителей весьма негативное впечатление, особенно когда выясняется реальная рабочая частота приобретенных ими процессоров и систем. Рабочие характеристики процессоров, приводимые AMD, можно приравнять к коэффициенту резкости погоды, который часто используется в прогнозах погоды в зимнее время. С одной стороны, существует реальная температура, а с другой — есть так называемый коэффициент резкости погоды, который представляет собой приблизительную оценку холода таким, каким он "ощущается". Расчетные значения, присваиваемые новым процессорам AMD Athlon XP, напоминают подобный "коэффициент производительности", величина которого определяет эффективность того или иного процессора по сравнению с Pentium 4. (Правда, AMD настаивает, что приводимые оценки эффективности не имеют непосредственного отношения к Pentium 4.)Проблема маркетинга AMD выражается в следующем: как продавать процессор, который выполняет те или другие операции быстрее, чем аналогичные модели основного конкурента с практически равными тактовыми частотами? Например, процессор AMD Athlon XP, имеющий тактовую частоту 1,8 ГГц, работает значительно быстрее, чем процессор Pentium 4 с частотой 1,8 ГГц, и достигает производительности, характерной для Pentium 4 с рабочей частотой 2,2 ГГц. Столь очевидная несоразмерность производительности процессоров связана с применением в микросхемах P4 совершенно новой архитектуры с более глубокой конвейерной обработкой команд. Pentium 4 имеет 20-ступенчатый конвейер, соответствующий 11-ступенчатому конвейеру процессоров Athlon или 10-ступенчатому конвейеру процессоров Pentium Ш/Celeron. При более глубокой конвейерной обработке команды разбиваются на небольшие микрокоманды, что позволяет достичь более высокой тактовой частоты при использовании одной и той же кремниевой технологии. Однако это также означает, что по сравнению с процессором Athlon (или Pentium III) в каждом цикле выполняется меньше команд.
Дело в том, что при сбоях на этапе предсказания множественного перехода или упреждающего выполнения (что свойственно процессору при попытке предварительного определения команд) происходит удаление всех имеющихся данных и повторное заполнение конвейера**. Таким образом, сравнивая рабочие характеристики процессоров Athlon, Pentium III и Pentium 4, работающих на одной и той же тактовой частоте, можно обнаружить, что при выполнении стандартных эталонных тестов процессоры Athlon и Pentium III оказываются более эффективными, поскольку выполняют в течение цикла большее количество команд, чем Pentium 4.На первый взгляд это кажется недостатком процессора Pentium 4, но в действительности мы имеем дело с особенностью его конструкции. Разработчики Intel приводят следующие аргументы: несмотря на то что использование более глубокой конвейерной обработки команд может привести к 30%-му снижению общей эффективности процессора, это позволяет увеличить его тактовую частоту по крайней мере на 50% по сравнению с процессорами Athlon или Pentium III, имеющими более короткие конвейеры. Применение 20-ступенчатого конвейера в архитектуре P4 позволяет достичь более высоких тактовых частот при использовании стандартной кремниевой технологии. Например, оригинальные процессоры Athlon XP и Pentium 4 создавались с помощью одной и той же 0,18-микронной технологии (этот показатель определяет линейную ширину компонентов, вытравленных на микросхемах). 20-ступенчатый конвейер архитектуры P4 позволяет при использовании 0,18-микронной технологии достичь тактовой частоты 2,0 ГГц, в то время как при тех же условиях частота процессора Athlon с 11-ступенчатым конвейером достигает 1,73 ГГц, а процессоров Pentium III/Celeron с 10-ступенчатым конвейером — всего лишь 1,13 ГГц. Благодаря использованию новой 0,13-микронной технологии тактовая частота процессора Pentium 4 увеличилась до 2,53 ГГц, в то время как максимальная рабочая частота Athlon XP достигла всего лишь 1,8 ГГц. Несмотря на то, что Pentium 4 выполняет в каждом цикле меньшее количество команд, более высокая частота периодической подачи импульсов позволяет в полной мере компенсировать снижение эффективности. Таким образом, сравнение процессоров Pentium 4 и Athlon XP указывает на то, что высокая тактовая частота первого процессора практически уравновешивается более высокой скоростью обработки данных второго. К сожалению, при высоких тактовых частотах оценка эффективности процессоров становится все более сложной. Это связано с тем, что в процессорах Intel с рабочей частотой более 2 ГГц использован 0,13-микронный (уменьшенный) кристалл, удвоена кэш-память второго уровня (с 256 до 512 Кбайт), а рабочая частота шины процессора увеличена с 400 до 533 МГц. Существующая система оценки эффективности, которая может использоваться только для сравнения создаваемых процессоров с более старым (и более медленным) 0,18-микронным процессором Pentium 4, не совсем подходит для более новых 0,13-микронных Pentium 4, особенно для тех, которые имеют шину процессора с тактовой частотой 533 МГц. Проблема заключается в шкале сравнительной оценки компании AMD, где в качестве точки отсчета используется некая переменная величина. Существует еще одна проблема: результаты сравнительной оценки непосредственно зависят от выполняемых эталонных тестов. Переработка приложений и операционных систем для повышения эффективности 20-ступенчатого конвейера процессора Pentium 4 позволила снизить количество командных предсказаний и возможных ошибок внутреннего процессора, что привело к уменьшению времени, необходимого для удаления имеющихся данных и повторного заполнения конвейера. В свою очередь, это привело к повышению общей эффективности выполнения команд для Pentium 4, в результате чего современное программное обеспечение, оптимизированное для более глубокого конвейера, будет выполняться процессором Pentium 4 значительно быстрее. Подобная ситуация приводит к сохранению негативного отношения к относительным оценкам компании AMD, следствием чего может быть их неточная интерпретация в будущем.Нет никаких сомнений в том, что параметры новых процессоров Athlon XP, представленные компанией AMD, достаточно точны: они превосходят менее эффективные процессоры, имеющие более высокую тактовую частоту. Единственное отличие состоит в том, что архитектура Pentium 4 позволяет достичь значительно более высокой рабочей частоты посредством одного и того же технологического процесса. Во многих системах тактовая частота процессора выводится на экран компьютера непосредственно во время начальной загрузки. В операционной системе Windows XP тактовая частота центрального процессора указана во вкладке General (Общие) меню System Properties (Система: Свойства). В то же время AMD предпочла бы не указывать непосредственное быстродействие процессора. Фактически AMD не рекомендует использовать без специальной проверки системные платы, предназначенные для Athlon XP, в том случае, если они указывают действительную тактовую частоту процессора. В будущем любопытному пользователю, желающему выяснить фактическую тактовую частоту процессора, придется воспользоваться соответствующей программой сторонних разработчиков, например SiSoft Sandra или Intel Frequency ID Utility.Одно можно сказать достаточно определенно: приблизительные значения тактовой частоты, выраженные в мегагерцах (МГц) или гигагерцах (ГГц), далеко не всегда являются надежным способом сравнения процессоров, поэтому генерирование псевдомегагерц может еще больше запутать непосвященного человека.
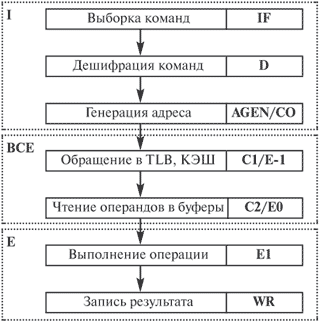
Конвейер
Конвейер (англ. conveyer, от convey — перевозить), транспортёр, машина непрерывного действия для перемещения сыпучих, кусковых или штучных грузов. Идея конвейера, давным-давно предложенная Генри Фордом, состоит в том, что производительность цепочки последовательных действий определяется не сложностью этой цепочки, а лишь длительностью самой сложной операции. Иными словами, совершенно неважно, сколько человек занимаются производством автомобиля и как долго длится его изготовление в целом, - важно то, что если каждый человек в цепочке тратит, скажем, на свою операцию одну минуту, то с конвейера будет сходить один автомобиль в минуту, ни больше и ни меньше; независимо от того, сколько операций нужно совершить с отдельным автомобилем и сколько заняла бы его сборка одним человеком. Применительно к процессорам принцип конвейера означает, что если мы сумеем разбить выполнение машинной инструкции на несколько этапов, то тактовая частота (а вернее, скорость, с которой процессор забирает данные на исполнение и выдает результаты) будет обратно пропорциональна времени выполнения самого медленного этапа. Если это время удастся сделать достаточно малым (а чем больше этапов на конвейере, тем они короче), то мы сумеем резко повысить тактовую частоту, а значит, и производительность процессора. Процедуру выполнения практически любой инструкции можно разбить как минимум на пять непересекающихся этапов:
1.Выборка инструкции (FETCH) из памяти. Из программы извлекается инструкция, которую нужно выполнить.
2.Декодирование инструкции (DECODE). Процессор обрабатывает полученную команду, и переправляет запрос на нужное исполнительное устройство.
3.Подготовка исходных данных для выполнения инструкции.
4.Собственно выполнение инструкции (EXECUTE).5.Сохранение полученных результатов.
Конвейеризация потенциально применима к любой процессорной архитектуре, независимо от набора команд и положенных в ее основу принципов. Даже самый первый x86-процессор, Intel 8086, уже содержал своеобразный примитивный "двухстадийный конвейер" - выборка новых инструкций (FETCH) и их исполнение осуществлялись в нем независимо друг от друга. Однако реализовать что-то более сложное для CISC-процессоров оказалось трудно: декодирование неоднородных CISC-инструкций и их очень сильно различающаяся сложность привели к тому, что конвейер получается чересчур замысловатым, катастрофически усложняя процессор(о CISC и RISC пойдет немного дальше). Подобных трудностей у RISC-архитектуры гораздо меньше (а SPARC и MIPS, например, и вовсе были специально оптимизированы для конвейеризации), так что конвейеризированные RISC-процессоры появились на рынке много раньше, чем аналогичные x86.Недостатки конвейера неочевидны, но, как обычно и бывает, из-за нескольких "мелочей" реализовать грамотно организованный конвейер совсем не просто.
Основных проблем три.
1.Необходимость наличия блокировок конвейера. Дело в том, что время исполнения большинства инструкций может очень сильно варьироваться. Скажем, умножение (и тем более деление) чисел требуют (на стадии EXECUTE) нескольких тактов, а сложение или побитовые операции - одного такта; а для операций Load и Store, которые могут обращаться к разным уровням кэш-памяти или к оперативной памяти, это время вообще не определено (и может достигать сотен тактов). Соответственно, должен быть какой-то механизм, который бы "притормаживал" выборку и декодирование новых инструкций до тех пор, пока не будут завершены старые. Методов решения этой проблемы много, но их развитие приводит к одному - в процессорах прямо перед исполнительными устройствами появляются специальные блоки-диспетчеры (dispatcher), которые накапливают подготовленные к исполнению инструкции, отслеживают выполнение ранее запущенных инструкций и по мере освобождения исполнительных устройств отправляют на них новые инструкции. Даже если исполнение займет много тактов - внутренняя очередь диспетчера позволит в большинстве случаев не останавливать подготавливающий все новые и новые инструкции конвейер [Новые инструкции тоже не каждый такт удается декодировать, так что возможна и обратная ситуация: новых инструкций за такт не появилось, и диспетчер отправляет инструкции на выполнение "из старых запасов"]. Так в процессоре возникает разделение на две независимо работающие подсистемы: Front-end (блоки, занимающиеся декодированием инструкций и их подготовкой к исполнению) и Back-end (блоки, собственно исполняющие инструкции).
2.Необходимость наличия системы сброса процессора. Поскольку операции FETCH и EXECUTE всегда выделены в отдельные стадии конвейера, то в тех случаях, когда в программном коде происходит разветвление (условный переход), зачастую оказывается, что по какой из веток пойти - пока неизвестно: инструкция, вычисляющая код условия, еще не выполнена. В результате процессор вынужден либо приостанавливать выборку новых инструкций до тех пор, пока не будет вычислен код условия (а это может занять очень много времени и в типичном цикле страшно затормозит процессор), либо, руководствуясь соображениями блока предсказания переходов, "угадывать", какой из переходов скорее всего окажется правильным.3.Наконец, конвейер обычно требует наличия специального планировщика (scheduler), призванного решать конфликты по данным. Если в программе идет зависимая цепочка инструкций (когда инструкция-2, следующая за инструкцией-1, использует для своих вычислений данные, только что вычисленные инструкцией-1), а время исполнения одной инструкции (от момента запуска на стадию EXECUTE и до записи полученных результатов в регистры) превосходит один такт, то мы вынуждены придержать выполнение очередной инструкции до тех пор, пока не будет полностью выполнена ее предшественница. К примеру, если мы вычисляем выражение вида A•B+C с сохранением результата в переменной X (XfA•B+C), то процессор, выполняя соответствующую выражению цепочку из двух команд типа R4fR1•R2; R0fR3+R4, должен вначале дождаться, пока первая инструкция сохранит результат умножения A•B, и только потом прибавлять к полученному результату число С. Цепочки зависимых инструкций в программах - скорее правило, нежели исключение, а исполнение команды с записью результата в регистры за один такт - наоборот, скорее исключение, нежели правило, поэтому в той или иной степени с проблемой зависимости по данным любая конвейерная архитектура обязательно сталкивается. Оттого-то в конвейере и появляются сложные декодеры, заранее выявляющие эти зависимости, и планировщики, которые запускают инструкции на исполнение, выдерживая паузу между запуском главной инструкции и зависимой от нее. Идея конвейера в процессоре очень красива на словах и в теории, однако реализовать ее даже в простом варианте чрезвычайно трудно. Но выгода от конвейеризации столь велика и несомненна, что приходится с этими трудностями мириться, ведь ничего лучшего до сих пор не придумано. В 1991-92 годах корпорация Intel, освоив производство сложнейших кристаллов с более чем миллионом транзисторов, выпустила i486 - классический CISC-процессор архитектуры x86, но с пятистадийным конвейером. Чтобы вы смогли оценить этот рывок, приведу две цифры: тактовую частоту по сравнению с i386 введение конвейера позволило увеличить втрое, а производительность на единицу частоты - вдвое. В i386 многие инструкции выполнялись за несколько тактов; а в i486 среднее "время" исполнения инструкции в тактах удалось снизить почти вдвое. Правда, расплатой за это стала чудовищная сложность ядра i486; но такие "мелочи" по меркам индустрии центральных процессоров - пустяк: быстро растущие технологические возможности кремниевой технологии уже через пару лет позволили освоить производство i486 всем желающим. Но к тому моменту RISC-архитектуры сделали еще один шаг вперед - к суперскалярным процессорам.
Кэш-память
Следует заметить, что, несмотря на повышение скорости ядра процессора, быстродействие памяти остается на прежнем уровне. При этом возникает вопрос: как добиться повышения производительности процессора, если память, используемая для передачи данных, работает довольно медленно? Ответ прост: "кэш". Попросту говоря, кэш-память представляет собой быстродействующий буфер памяти, используемый для временного хранения данных, которые могут потребоваться процессору. Это позволяет получать необходимые данные быстрее, чем при извлечении из оперативной памяти. Одним из дополнительных свойств, отличающих кэш-память от обычного буфера, являются встроенные логические функции. Кэш-память можно по праву назвать разумным буфером. Буфер содержит случайные данные, которые обычно обрабатываются по принципу "первым получен, первым выдан" или "первым получен, последним выдан". Кэш-память, в свою очередь, содержит данные, которые могут потребоваться процессору с определенной степенью вероятности. Это позволяет процессору работать практически с полной скоростью без необходимости ожидания данных, извлекаемых из более медленной оперативной памяти. Кэш-память реализована в виде микросхем статической оперативной памяти (SRAM), установленных на системной плате или встроенных в процессор. В современных ПК используются два уровня кэш-памяти, получившие название кэш-памяти первого (L1) и второго (L2) уровней.
Кэш-память первого уровня
Во всех процессорах, начиная с 486-го, имеется встроенный (первого уровня) кэш-контроллер с кэш-памятью объемом 8 Кбайт в процессорах 486DX, а также 32, 64 Кбайт и более в современных моделях. Кэш — это быстродействующая память, предназначенная для временного хранения программного кода и данных. Обращения к встроенной кэш-памяти происходят без состояний ожидания, поскольку ее быстродействие соответствует возможностям процессора, т. е. кэш-память первого уровня (или встроенный кэш) работает на частоте процессора. Использование кэш-памяти сглаживает традиционный недостаток компьютера, состоящий в том, что оперативная память работает более медленно, чем центральный процессор (так называемый эффект "бутылочного горлышка"). Благодаря кэш-памяти процессору не приходится ждать, пока очередная порция программного кода или данных поступит из относительно медленной основной памяти, что приводит к ощутимому повышению производительности. В современных процессорах встроенный кэш играет еще более важную роль, потому что он часто является единственным типом памяти во всей системе, который может работать синхронно с процессором. В большинстве современных процессоров используется множитель тактовой частоты, следовательно, они работают на частоте, в несколько раз превышающей тактовую частоту системной платы, к которой они подключены. Например, тактовая частота (1,4 ГГц), на которой работает процессор Pentium III, в 10,5 раз превышает тактовую частоту системной платы, равную 133 МГц. Поскольку оперативная память подключена к системной плате, она также может работать только на тактовой частоте, не превышающей 133 МГц. В такой системе из всех видов памяти только встроенный кэш может работать на тактовой частоте 1,4 ГГц. Рассмотренный в этом примере процессор Pentium III на 1,4 ГГц имеет встроенный кэш первого уровня общим объемом 32 Кбайт (в двух отдельных блоках по 16 Кбайт) и кэш второго уровня объемом 512 Кбайт, работающий на полной частоте ядра процессора. Если данные, необходимые процессору, находятся уже во внутренней кэш-памяти, то задержек не возникает. В противном случае центральный процессор должен получать данные из кэш-памяти второго уровня или (в менее сложных системах) из системной шины, т. е. непосредственно из основной памяти. Чтобы понять значение кэш-памяти, необходимо сравнить относительные скорости процессоров и ОЗУ Основная проблема заключается в том, что быстродействие процессора выражается обычно в МГц (в миллионах тактов в секунду), в то время как скорость памяти выражается в наносекундах (т е в миллиардных долях секунды)Для процессора, работающего на частоте 200 МГц, потребуется 4 нс памяти. Обратите внимание, что с процессором 233 МГц обычно используется системная плата с тактовой частотой 66 МГц, что соответствует скорости 15 нс на цикл. Основная память, скорость которой равна 60 нс (общий параметр практически для всех систем класса Pentium), приравнивается к тактовой частоте, примерно равной 16 МГц. Таким образом, в типичную систему Pentium 233 входит процессор, работающий на частоте 233 МГц (4,3 нс на цикл), системная плата, тактовая частота которой 66 МГц (15 нс на цикл) и основная память, работающая на частоте 16 МГц (60 нс на цикл).
Как работает кэш-память первого уровня
Для того чтобы разобраться с принципами работы кэш-памяти первого и второго уровней, рассмотрим прекрасную аналогию, написанную Скотом Мюллером. Герой нашей истории (в данном случае — вы), вкушающий различные яства, выступает в роли процессора, который извлекает необходимые данные из памяти и проводит их обработку. Кухня, на которой готовятся ваши любимые блюда, представляет собой основную оперативную память (SIMM/DIMM). Официант является кэш-контроллером, а стол, за которым вы сидите, выступает в качестве кэш-памяти первого уровня. Роль кэш-памяти второго уровня выполняет тележка с заказанными блюдами, неспешно путешествующая между кухней и вашим столом. Роли распределены, пора начинать нашу историю. Ежедневно примерно в одно и то же время вы обедаете в определенном ресторане. Входите в обеденный зал, садитесь за столик и заказываете, например, хот-дог. Для того чтобы сохранить соответствие событий, предположим, что средняя скорость поглощения пищи равна одному биту в четыре секунды (цикл процессора 233 МГц составляет около 4 нс). А также определим, что повару (т. е. кухне) для приготовления каждого заказанного блюда потребуется 60 с (значит, скорость основной памяти 60 нс). Таким образом, при первом посещении ресторана вы садитесь за столик и заказываете хот-дог, после чего приходится ждать целых 60 секунд, пока приготовят заказанное блюдо. Когда официант наконец-то приносит заказ, вы не спеша, со средней скоростью, принимаетесь за еду. Быстренько доев хот-дог, подзываете к себе официанта и заказываете гамбургер. Пока его готовят, вы снова ждете те же 60 секунд. Принесенный гамбургер съедается с той же скоростью. Подобрав последние крошки, снова зовете официанта и заказываете уже котлеты "по-киевски". После 60-секундного ожидания принесенное блюдо съедается с аналогичной скоростью. После этого вы решаете заказать на десерт, скажем, яблочный пирог. Заказанный пирог вы получаете после ставшего привычным 60-секундного ожидания. Одним словом, обед состоит главным образом из длительных ожиданий, которые перемежаются энергичным поглощением заказываемых блюд. После того как два дня подряд ровно в 18.00 вы приходите в ресторан и заказываете одни и те же блюда в одной и той же последовательности, у официанта появляется дельная мысль: "Сегодня в 18.00 снова появится этот странный посетитель и сделает свой обычный заказ: хот-дог, гамбургер, котлеты "по-киевски" и яблочный пирог на десерт. Почему бы не приготовить эти блюда заранее? Я думаю, он должным образом оценит мои старания". Итак, вы приходите в ресторан, заказываете хот-дог и официант сразу же, без малейшей паузы, ставит перед вами заказанное блюдо. После того как вы разделались с хот-догом и собираетесь заказать очередное блюдо, на столе появляется тарелка с гамбургером. Оставшаяся часть обеда проходит примерно так же. Вы стремительно, со скоростью один бит в четыре секунды, поглощаете пищу, не ожидая, пока заказанное блюдо будет приготовлено на кухне. На сей раз время обеда заполнено исключительно тщательным пережевыванием пищи, и все благодаря смекалке и практичному подходу официанта. Приведенный пример достаточно точно описывает работу кэш-памяти первого уровня в процессоре. Роль кэш-памяти первого уровня в данном случае выполняет поднос, на котором может находиться одно или несколько блюд. При отсутствии официанта пространство подноса представляет собой некий резервный запас (т. е. буфер) продуктов питания. Если буфер заполнен, значит, можно есть до тех пор, пока поднос не опустеет. Обдуманно пополнить его содержимое, к сожалению, некому. Официант представляет собой кэш-контроллер, предпринимающий определенные меры и пытающийся решить, какие же блюда следует заранее поставить на стол в соответствии с вашими возможными пожеланиями. Подобно настоящему кэш-контроллеру, официант воспользуется своим опытом для того, чтобы определить, какое блюдо будет заказано следующим. Если он определит правильно, значит, не придется долго ждать. Настал день четвертый. Вы появляетесь в ресторане, как обычно, ровно в 18.00 и начинаете с привычного хот-дога. Официант, изучивший к тому времени ваши вкусы, уже приготовил хот-дог, и вы сразу же, не ожидая, приступаете к трапезе. После хот-дога официант приносит вам гамбургер и вместо слов благодарности слышит: "Вообще-то я гамбургер не заказывал. Принесите мне, пожалуйста, отбивную". Официант ошибся в своих предположениях, и вам снова придется ждать целых 60 секунд, пока на кухне не приготовят заказанное блюдо. Подобное событие, т. е. попытка доступа к той части кэшированного файла, которая отсутствует в кэш-памяти, называется промахом кэша (cache miss). Как следствие, возникает пауза, или, если говорить о системе Pentium 233 МГц, при каждом промахе кэша быстродействие системы снижается до 16 МГц (т. е. до скорости оперативной памяти). Кэш-память первого уровня большей части процессоров Intel имеет коэффициент совпадения, равный примерно 90%.Это означает, что кэш-память содержит корректные данные 90% времени, а следовательно, процессор работает на полной скорости (в данном случае с частотой 233 МГц) примерно 90% всего времени. Оставшиеся 10% времени кэш-контроллер обращается к более медленной основной памяти, во время чего процессор находится в состоянии ожидания. Фактически происходит снижение быстродействия системы до уровня оперативной памяти, скорость которой равна 60 нс, или 16 МГц. В нашем примере, быстродействие процессора примерно в 14 раз выше скорости оперативной памяти. С развитием научного прогресса скорость памяти увеличилась с 16 МГц (60 нс) до 266 Мгц (3,8 нс), в то время как тактовая частота процессоров выросла до 2 ГГц и более. Таким образом, даже в самых современных системах память все еще в 7,5 (или более) раз медленнее процессора. Кэш-память позволяет компенсировать эту разность. Основная особенность кэш-памяти первого уровня состоит в том, что она всегда интегрирована с ядром процессора и работает на той же частоте. Это свойство в сочетании с коэффициентом совпадений, равным 90%, делает кэш-память важной составляющей эффективности системы.
Кэш-память второго уровня
Для того чтобы уменьшить ощутимое замедление системы, возникающее при каждом промахе кэша, задействуется кэш-память второго уровня. Развивая аналогию с рестораном, которая использовалась для объяснения кэш-памяти первого уровня, можно обозначить вторичный кэш как сервировочный столик с "дежурными" блюдами, расположение которого позволяет официанту принести любое из имеющихся блюд через 15 секунд. В системе класса Pentium (Socket 7) кэш-память второго уровня установлена на системной плате, т. е. работает на тактовой частоте системной платы (66 МГц, или 15 нс). Рассмотрим ситуацию, когда вы заказываете блюдо, которого нет в числе ранее принесенных. В этом случае, вместо того чтобы отправиться на кухню и через 60 секунд принести приготовленное блюдо, официант в первую очередь проверяет столик с дежурными блюдами. При наличии там заказанного блюда он возвращается уже через 15 секунд. Результат в реальной системе выражается в следующем: вместо снижения быстродействия системы с 233 до 16 Мгц и соответственно скорости основной памяти до 60 нс происходит извлечение необходимых данных из кэш-памяти второго уровня, скорость которой равна 15 нс (66 МГц). Таким образом, быстродействие системы изменяется с 233 до 66 МГц. Более современные процессоры содержат встроенную кэш-память второго уровня, которая работает на той же скорости, что и ядро процессора, причем скорости кэш-памяти первого и второго уровней одинаковы. Если описывать новые микросхемы с помощью аналогий, то в этом случае официант размещает столик с дежурными блюдами рядом с тем столиком, за которым вы сидите. При этом, если заказанного блюда на вашем столе нет (промах кэш-памяти первого уровня), официанту всего лишь необходимо дотянуться к находящемуся рядом столику с дежурными блюдами (кэш-память второго уровня), что потребует гораздо меньше времени, чем 15-секундная прогулка на кухню, как это было в более ранних конструкциях
Конструкция и эффективность кэш-памяти
Коэффициент совпадения кэш-памяти как первого, так и второго уровней составляет 90%. Таким образом, рассматривая систему в целом, можно сказать, что 90% времени она работает с полной тактовой частотой (в нашем примере 233 МГц), получая данные из кэш-памяти первого уровня. Десять процентов времени данные извлекаются из кэш-памяти второго уровня. Процессор работает с кэш-памятью второго уровня только 90% этого времени, а оставшиеся 10% вследствие промахов кэша — с более медленной основной памятью. Таким образом, объединяя кэш-память первого и второго уровней, получаем, что обычная система работает с частотой процессора 90% времени (в нашем случае 233 МГц), с частотой системной платы 9% времени (т. е. 90% от 10% при частоте 66 МГц) и с тактовой частотой основной памяти примерно 1% времени (10% от 10% при частоте 16 МГц). Это ясно демонстрирует важность кэш-памяти первого и второго уровней; при отсутствии кэш-памяти система часто обращается к ОЗУ, скорость которого значительно ниже, чем скорость процессора. Это наводит на интересные мысли. Представьте, что вы собираетесь повысить эффективность оперативной памяти или кэш-памяти второго уровня вдвое. На что же именно потратить деньги? Принимая во внимание, что оперативная память непосредственно используется примерно 1% времени, двойное увеличение ее производительности приведет к повышению быстродействия системы только в 1% времени! Нельзя сказать, что это звучит достаточно убедительно. С другой стороны, если вдвое повысить эффективность кэш-памяти второго уровня, получится двойное увеличение эффективности системы в 9% времени, что является более значимым улучшением. Системотехники и специалисты по разработке процессоров компаний Intel и AMD зря времени не теряли и разработали методы повышения эффективности кэш-памяти второго уровня. В системах класса Pentium (P5) кэш-память второго уровня обычно устанавливается на системной плате и работает соответственно с ее тактовой частотой. Intel значительно повысила производительность процессоров, переместив кэш-память с системной платы непосредственно в процессор, что повлекло за собой увеличение ее рабочей частоты до частоты процессора. Сначала микросхемы кэша устанавливались в одном корпусе вместе с основным процессором. Но такая конструкция оказалась слишком дорогой, поэтому, начиная с процессоров семейства Pentium II, компания Intel стала приобретать микросхемы кэш-памяти у сторонних производителей (Sony, Toshiba, NEC, Samsung и т. д.). Микросхемы поставлялись уже в готовом виде, в корпусном исполнении, поэтому Intel начала их устанавливать на монтажной плате рядом с процессором. Именно поэтому процессор Pentium II был изначально разработан в виде картриджа. Одна из существенных проблем заключалась в быстродействии микросхем кэш-памяти сторонних производителей. Скорость наиболее быстрых микросхем достигала 3 нс и выше, что было эквивалентно тактовой частоте 333 МГц. Но процессоры уже работали на более высоких скоростях, поэтому в Pentium II и первых моделях Pentium III кэш-память второго уровня работает на половинной частоте процессора. В некоторых моделях процессора Athlon скорость кэш-памяти второго уровня уменьшена до двух пятых или даже одной трети тактовой частоты ядра. Качественный скачок в технологии произошел с появлением процессоров Celeron 300A и выше. В этих процессорах внешние микросхемы кэш-памяти второго уровня не используются. Вместо этого кэш-память как первого, так и второго уровней была интегрирована непосредственно в ядро процессора. Таким образом, кэш-память обоих уровней работает с полной тактовой частотой процессора, что позволяет повышать ее быстродействие при возможном увеличении скорости процессора. В последних моделях Pentium III, а также во всех процессорах Xeon и Celeron кэш-память второго уровня по-прежнему работает с тактовой частотой ядра процессора, а значит, при неудачном обращении в кэш-память первого уровня ожидания или замедления операций не происходит. В современных моделях процессоров Athlon и Duron также используется встроенная кэш-память, работающая с частотой ядра. Как вы знаете, при неудачном обращении к внешней кэш-памяти происходит снижение скорости кэша до половинной частоты ядра или, что еще хуже, до частоты более медленной системной платы. Использование встроенного кэша позволяет значительно повысить эффективность процессора, так как 9% времени в системе будет использоваться кэш-память второго уровня, работающая с полной частотой ядра. К числу преимуществ встроенной кэш-памяти относится также уменьшение ее стоимости, так как она содержит меньшее число компонентов. Вернемся к рассмотренной ранее аналогии, используя в качестве примера современный процессор Pentium 4 с тактовой частотой 2 ГГц. Теперь ваша скорость поглощения пищи равна одному байту в секунду (тактовой частоте 2 ГГц соответствует длительность цикла 0,5 нс). Кэш-память первого уровня работает на этой же частоте, т. е. скорость поглощения блюд, находящихся на вашем столе, равна скорости процессора (а столик соответствует кэш-памяти первого уровня). Ощутимое повышение быстродействия происходит в том случае, когда вы заказываете блюдо, которого нет на столе (промах кэша первого уровня), и официанту приходится обращаться к столику с дежурными блюдами. В девяти случаях из десяти он находит там нужное блюдо, которое приносит через полсекунды (частота кэш-памяти второго уровня равна 2 ГГц, что соответствует скорости 0,5 нс). Итак, современные системы работают 99% времени (суммарный коэффициент совпадения кэш-памяти первого и второго уровней) с частотой 2 ГГц и, как и прежде, в одном случае из ста понижают скорость до частоты оперативной памяти (приготовление блюда на кухне). При увеличении скорости памяти до 400 МГц (2,5 нс) время ожидания заказанного блюда из кухни достигнет 2,5 с. Эх, если бы скорость обслуживания в ресторане повышалась так же, как быстродействие процессора!
Организация работы кэш-памяти
Организация кэш-памяти в процессорах 486 и семействе Pentium называется четырехстраничным набором ассоциативного кэша (four-way set associative cache), что подразумевает разделение кэш-памяти на четыре блока. Каждый блок, в свою очередь, организуется в виде 128 или 256 строк по 16 байт в каждой. Чтобы понять, как работает четырехстраничный кэш, рассмотрим следующий пример. В простейшем случае кэш состоит из одного блока, в который можно загрузить содержимое соответствующего блока основной памяти. Это похоже на закладку, используемую для того, чтобы отметить нужную страницу в книге. Если основная память — это вся книга, то по закладке можно определить, какая страница находится в кэше. Но этого бывает достаточно только в том случае, если все необходимые данные находятся на странице, отмеченной закладкой. Если же вам нужно вернуться к одной из уже прочитанных страниц, то закладка будет бесполезной. Можно воспользоваться несколькими закладками (выписками), отмечая сразу несколько мест в книге. При этом, конечно, усложняется схема процессора, но зато можно проверить сразу несколько закладок. Каждая дополнительная закладка усложняет систему, но вероятность того, что нужная страница уже отмечена (выписана), повышается. Если ограничиться четырьмя отметками-выписками, то можно получить четырехстраничный кэш. Вся кэш-память разбивается на четыре блока, в каждом из которых хранятся копии различных фрагментов основной памяти. Хорошим примером работы процессора сразу с несколькими областями памяти является использование многозадачной операционной системы Windows. Здесь четырехстраничный кэш значительно повышает производительность процессора. Содержимое кэша всегда должно соответствовать содержимому основной памяти, чтобы процессор работал с самыми свежими данными. Поэтому в семействе процессоров 486 используется кэш со сквозной записью (write-through), при которой данные, записанные в кэш, автоматически записываются и в основную память. В процессорах Pentium используется двунаправленный кэш (write-back), который работает при выполнении как операций считывания, так и операций записи. Это позволяет еще больше повысить производительность процессора. Хотя встроенный кэш в процессоре 486 используется только при чтении, внешний кэш в системе может быть двунаправленным. Кроме того, в процессорах 486 предусмотрен дополнительный 4-байтовый буфер, в котором можно хранить данные вплоть до передачи в память. Это необходимо в том случае, если шина памяти занята. Еще одна из особенностей улучшенной архитектуры кэша состоит в том, что кэш-память является неблокируемой. Это свойство позволяет уменьшать или скрывать задержки памяти, используя перекрытие операций процессора с выборкой данных. Неблокируемая кэш-память дает возможность продолжать выполнение программы одновременно с неудачными обращениями в кэш при наличии некоторых ограничений. Другими словами, кэш-память улучшает обработку промаха кэша и позволяет процессору продолжать выполнение операций, не связанных с отсутствующими данными. Кэш-контроллер, встроенный в процессор, также используется для наблюдения за состоянием системной шины при передаче управления шиной альтернативным процессорам, которые называются хозяевами шины (bus masters). Процесс наблюдения, в свою очередь, называется отслеживанием шины (bus snooping). Если устройство, управляющее передачей данных по шине (т. е. хозяин шины), записывает какие-либо данные в область памяти, копия которой хранится в кэше процессора, то содержимое кэша перестает соответствовать содержимому основной памяти. В этом случае кэш-контроллер отмечает эти данные как ошибочные и при следующем обращении к памяти обновляет содержимое кэша, поддерживая тем самым целостность всей системы. При увеличении тактовой частоты время цикла уменьшается. В новых системах не используется кэш на системной плате, поскольку быстрые модули DDR-SDRAM или RDRAM, применяемые в современных системах Pentium II/Celeron/III, могут работать на тактовой частоте системной платы. Как видите, кэш-память двух уровней улучшает взаимодействие между быстрым центральным процессором и более медленной оперативной памятью, а также позволяет минимизировать периоды ожидания, возникающие при обработке данных. Решающую роль в этом играет кэш-память второго уровня, расположенная в кристалле процессора. Это дает возможность процессору работать с тактовой частотой, наиболее близкой к его максимальной частоте.
Свойства процессора
По мере появления новых процессоров их архитектура дополняется все новыми и новыми возможностями, которые позволяют не только улучшить эффективность выполнения тех или иных приложений, но и повысить надежность центрального процессора в целом. В следующих разделах представлено краткое описание различных технологий, включая режим управления системой, суперскалярное выполнение, технологии MMX и SSE.
SMM
Задавшись целью создания все более быстрых и мощных процессоров для портативных компьютеров, Intel разработала схему управления питанием. Эта схема позволяет процессорам экономно использовать энергию батареи и таким образом продлить срок ее службы. Такая возможность впервые была реализована компанией Intel в процессоре 486SL, который является усовершенствованной версией процессора 486DX. Впоследствии, когда возможности управления питанием стали более универсальными, их начали встраивать в Pentium и во все процессоры более поздних поколений. Система управления питанием процессоров называется SMM (System Management Mode — режим управления системой).SMM физически интегрирована в процессор, но функционирует независимо. Благодаря этому она может управлять потреблением мощности, в зависимости от уровня активности процессора. Это позволяет пользователю определять интервалы времени, по истечении которых процессор будет частично или полностью выключен. Данная схема также поддерживает возможность приостановки/возобновления, которая позволяет мгновенно включать и отключать мощность, что обычно используется в портативных компьютерах. Соответствующие параметры устанавливаются в BIOS.
Суперскалярное выполнение
В процессорах Pentium пятого и последующих поколений встроен ряд внутренних конвейеров, которые могут выполнять несколько команд одновременно. Процессор 486 и все предшествующие в течение определенного отрезка времени могли выполнять только одну команду. Технология одновременного выполнения нескольких команд называется суперскалярной. Благодаря использованию данной технологии и обеспечивается дополнительная эффективность по сравнению с процессором 486.Суперскалярная архитектура обычно ассоциируется с микросхемами RISC (Reduced Instruction Set Computer — компьютер с упрощенной системой команд). Процессор Pentium — одна из первых микросхем CISC (Complex Instruction Set Computer — компьютер со сложной системой команд), в которой применяется суперскалярная технология, реализованная во всех процессорах пятого и последующих поколений. Рассмотрим на примере установки электрической лампочки инструкции CISC.
1. Возьмите электрическую лампочку.
2. Вставьте ее в патрон.
3. Вращайте до отказа.
И аналогичный пример в виде инструкций RISC.
1. Поднесите руку к лампочке.
2. Возьмите лампочку.
3. Поднимите руку к патрону.
4. Вставьте лампочку в патрон.
5. Поверните ее.
6. Лампочка поворачивается в патроне? Если да, то перейти к п. 5.
7. Конец.
Многие инструкции RISC довольно просты, поэтому для выполнения какой-либо операции потребуется больше таких инструкций. Их основное преимущество состоит в том, что процессор выполняет меньшее количество операций, что, как правило, сокращает время выполнения отдельных команд и соответственно всей задачи (программы). Можно долго спорить о том, что же в действительности лучше — RISC или CISC, хотя, если говорить честно, такого понятия, как "чистая" микросхема RISC или CISC, не существует. Подобная классификация не более чем вопрос терминологии. Процессоры Intel и совместимые с ними процессоры можно определить как микросхемы CISC. Несмотря на это, процессоры пятого и шестого поколения обладают различными атрибутами RISC и разбивают во время работы команды CISC на более простые инструкции RISC.
Технология MMX
В зависимости от контекста, MMX может означать multi-media extensions (мультимедийные расширения) или matrix math extensions (матричные математические расширения). Технология MMX использовалась в старших моделях процессоров Pentium пятого поколения в качестве расширения, благодаря которому ускоряется компрессия/декомпрессия видеоданных, манипулирование изображением, шифрование и выполнение операций ввода-вывода — почти все операции, используемые во многих современных программах. В архитектуре процессоров MMX есть два основных усовершенствования. Первое, фундаментальное, состоит в том, что все микросхемы MMX имеют больший внутренний встроенный кэш, чем их собратья, не использующие эту технологию. Это повышает эффективность выполнения каждой программы и всего программного обеспечения независимо от того, использует ли оно фактически команды MMX. Другое усовершенствование MMX состоит в расширении набора команд процессора 57 новыми командами, а также во введении новой возможности выполнения команд, называемой одиночный поток команд — множественный поток данных (Single Instruction — Multiple Data, SIMD). В современных мультимедийных и сетевых приложениях часто используются циклы; хотя они занимают около 10% (или даже меньше) объема полного кода приложения, на их выполнение может уйти до 90% общего времени выполнения. SIMD позволяет одной команде осуществлять одну и ту же операцию над несколькими данными, подобно тому, как преподаватель, читая лекцию, обращается ко всей аудитории, а не к каждому студенту в отдельности. Технология SIMD позволяет ускорить выполнение циклов при обработке графических, анимационных, видео- и аудиофайлов; в противном случае эти циклы отнимали бы время у процессора. Intel также добавила 57 новых команд, специально разработанных для более эффективной обработки звуковых, графических и видеоданных. Эти команды предназначены для выполнения с высокой степенью параллелизма последовательностей, которые часто встречаются при работе мультимедийных программ. Высокая степень параллелизма в данном случае означает, что одни и те же алгоритмы применяются ко многим данным, например к данным в различных точках при изменении графического изображения. Такие компании, как AMD и Cyrix, лицензировали у Intel технологию MMX и реализовали ее в собственных процессорах.
Инструкции SSE и SSE2
В феврале 1999 года Intel представила общественности процессор Pentium III, содержащий обновление технологии MMX, получившей название SSE (Streaming SIMD Extensions — потоковые расширения SIMD). До этого момента инструкции SSE носили имя Katmai New Instructions (KNI), так как первоначально они были включены в процессор Pentium III с кодовым именем Katmai. Процессоры Celeron 533A и выше, созданные на основе ядра Pentium III, тоже поддерживают инструкции SSE. Более ранние версии процессора Pentium II, а также Celeron 533 и ниже (созданные на основе ядра Pentium II) SSE не поддерживают. Инструкции SSE содержат 70 новых команд для работы с графикой и звуком в дополнение к существующим командам MMX. Фактически этот набор инструкций кроме названия KNI имел еще и второе название — MMX-2. Инструкции SSE позволяют выполнять операции с плавающей запятой, реализуемые в отдельном модуле процессора. В технологиях MMX для этого использовалось стандартное устройство с плавающей запятой. Инструкции SSE2, содержащие в себе 144 дополнительные команды SIMD, были представлены в ноябре 2000 года вместе с процессором Pentium 4. В SSE2 были включены все инструкции предыдущих наборов MMX и SSE. Потоковые расширения SIMD (SSE) содержат целый ряд новых команд для выполнения операций с плавающей запятой и целыми числами, а также команды управления кэш-памятью. Новые технологии SSE позволяют более эффективно работать с трехмерной графикой, потоками аудио- и видеоданных (DVD-воспроизведение), а также приложениями распознавания речи. В целом SSE обеспечивает следующие преимущества: более высокое разрешение/качество при просмотре и обработке графических изображений; улучшенное качество воспроизведения звуковых и видеофайлов в формате MPEG2, а также одновременное кодирование и декодирование формата MPEG2 в мультимедийных приложениях; уменьшение загрузки процессора и повышение точности/скорости реагирования при выполнении программного обеспечения для распознавания речи. Инструкции SSE и SSE2 особенно эффективны при декодировании файлов формата MPEG2, который является стандартом сжатия звуковых и видеоданных, используемым в DVD-дисках. Следовательно, SSE-оснащенные процессоры позволяют достичь максимальной скорости декодирования MPEG2 без использования дополнительных аппаратных средств (например, платы декодера MPEG2). Кроме того, процессоры, содержащие набор инструкций SSE, значительно превосходят предыдущие версии процессоров при распознавании речи. Одним из основных преимуществ SSE по отношению к MMX является поддержка операций SIMD с плавающей запятой, что очень важно при обработке трехмерных графических изображений. Технология SIMD, как и MMX, позволяет выполнять сразу несколько операций при получении процессором одной команды. В частности, SSE поддерживает выполнение до четырех операций с плавающей запятой за цикл; одна инструкция может одновременно обрабатывать четыре блока данных. Для выполнения операций с плавающей запятой инструкции SSE могут использоваться вместе с командами MMX без заметного снижения быстродействия. SSE также поддерживает упреждающую выборку данных (prefetching), которая представляет собой механизм предварительного считывания данных из кэш-памяти. Обратите внимание, что наилучший результат использования новых инструкций процессора обеспечивается только при их поддержке на уровне используемых приложений. Сегодня большинство компаний, занимающихся разработкой программного обеспечения, модифицировали приложения, связанные с обработкой графики и звука, что позволило в более полной мере использовать возможности SSE. Например, графическое приложение Adobe Photoshop поддерживает инструкции SSE, что значительно повышает эффективность использования SSE-оснащенных процессоров. Поддержка инструкций SSE встроена в DirectX 6.1 и в самые последние видео- и аудиодрайверы, поставляемые с операционными системами Windows 98 Second Edition, Windows Me, Windows NT 4.0 (с пакетом обновления 5 или более поздним) и Windows 2000.Инструкции SSE являются расширением технологий MMX, а SSE2 — расширением инструкций SSE. Таким образом, процессоры, поддерживающие SSE2, поддерживают также инструкции SSE, а процессоры, поддерживающие инструкции SSE, в свою очередь, поддерживают оригинальные команды MMX. Это означает, что стандартные MMX-приложения могут выполняться практически на любых системах.
3DNow и Enhanced 3DNow
Технология 3DNow разработана компанией AMD в ответ на реализацию поддержки инструкций SSE в процессорах Intel. Впервые (май 1998 года) 3DNow реализована в процессорах AMD K6, а дальнейшее развитие — Enhanced 3DNow — эта технология получила в процессорах Athlon и Duron. Аналогично SSE, технологии 3DNow и Enhanced 3DNow предназначены для ускорения обработки трехмерной графики, мультимедиа и других интенсивных вычислений.3DNow представляет собой набор из 21 инструкции SIMD, которые оперируют массивом данных в виде единичного элемента. В Enhanced 3DNow к существующим добавлены еще 24 новых инструкции. Технологии обработки данных 3DNow и Enhanced 3DNow хотя и подобны SSE, но несовместимы на уровне инструкций, поэтому производителям программного обеспечения необходимо отдельно реализовать поддержку этих технологий. Технология 3DNow, как и SSE, поддерживает операции SIMD с плавающей запятой, а также позволяет выполнять до четырех операций с плавающей запятой за один цикл. Инструкции 3DNow для операций с плавающей запятой могут использоваться вместе с командами MMX без заметного снижения быстродействия. Поддерживается и упреждающая выборка данных — механизм предварительного считывания данных из кэшпамяти. Все технологии ускорения обработки данных компаний Intel и AMD реализованы на уровне операционных систем Windows 9x и Windows NT/2000. Кроме этого, все программные интерфейсы DirectX (с версии 6) компании Microsoft и Open GL компании SGI оптимизированы для технологии 3DNow, а практически все современные видеодрайверы 3Dfx, ATI, Matrox и nVidia поддерживают 3DNow и Enhanced 3DNow. Несмотря на то что технология 3DNow поддерживается многими компьютерными играми и драйверами видеоадаптеров, существует ряд профессиональных графических приложений, к числу которых относится и Adobe Photoshop, не поддерживающих 3DNow.
Supplemental Streaming SIMD Extension 3 (SSSE3) — это обозначение, данное Intel’ом 4-му расширению системы команд. Предыдущее имело обозначение SSE3 и Intel добавил ещё один символ 'S' вместо того, чтобы увеличить номер расширения, возможно потому, что они посчитали SSSE3 простым дополнением к SSE3. Часто, до того как стало использоваться официальное обозначение SSSE3, эти новые команды назывались SSE4. Также их называли кодовыми именами Tejas New Instructions (TNI) и Merom New Instructions (MNI) по названию процессоров, где впервые Intel намеревалась поддержать эти новые команды. Появившись в Intel Core Microarchitecture, SSSE3 доступно в сериях процессоров Xeon 5100 (Server и Workstation версии), а также в процессорах Intel Core 2 (Notebook и Desktop версии).
EM64T (англ. Extended Memory 64 Technology) — реализация 64-битных расширений AMD64 процессорной архитектуры IA-32 (архитектуры x86-совместимых процессоров) фирмы Intel. Основное улучшение, обеспечиваемое EM64T — 64-битная адресация оперативной памяти, что позволяет снять присущее 32-битным процессорам ограничение в 4 гигабайта адресуемой напрямую памяти
Динамическое выполнение
Этот метод впервые использован в микросхемах P6 (процессорах шестого поколения) и позволяет процессору параллельно обрабатывать сразу несколько команд, что приводит к уменьшению времени, необходимого для выполнения той или иной задачи. Это технологическое новшество включает в себя следующие элементы.
-Предсказание множественного перехода (ветвления). Предсказание потока выполнения программы через несколько ветвлений.
-Анализ потока команд. Назначение выполнения команд по мере готовности, независимо от их порядка в оригинальной программе.
-Упреждающее выполнение. Увеличение скорости выполнения за счет опережающего просмотра счетчика команд и выполнения тех команд, к которым, вероятно, потребуется обратиться позже.
Предсказание перехода
Функция предсказания перехода, ранее применявшаяся только в универсальных процессорах старших моделей, позволяет процессору при высокоскоростном выполнении команд сохранять конвейер заполненным. Специальный модуль выборки/декодирования, включенный в процессор, использует высоко оптимизированный алгоритм предсказания перехода, позволяющий предсказывать направление и результат команд, выполняемых через несколько уровней ветвлений, обращений и возвратов. Этот модуль напоминает шахматиста, разрабатывающего несколько различных стратегий перед началом шахматной партии, предсказывая ответные действия противника на несколько ходов вперед. Благодаря предсказанию результатов выполнения команды инструкции могут выполняться практически без задержек.
Анализ потока данных
Функция анализа потока команд используется для исследования потока данных, проходящих через процессор, и выявления любых возможностей выполнения команды с изменением заданной ранее последовательности. Специальный процессорный модуль отправки/выполнения контролирует команды и позволяет выполнять их в таком порядке, который оптимизирует использование модулей множественного суперскалярного выполнения. Возможность изменять последовательность выполнения команд позволяет сохранить занятость модулей выполнения даже в случае промаха кэш-памяти или обработки каких-либо информационно-зависимых команд.
Упреждающее выполнение
Способность процессора выполнять команды с помощью опережающего просмотра существующего счетчика команд называется упреждающим выполнением. Модуль отправки/выполнения, включенный в процессор, анализирует поток данных для выполнения всех команд, существующих в буфере (накопителе) команд, и сохранения результатов их выполнения в буферных регистрах. После этого модуль изъятия анализирует содержимое пула команд на предмет наличия завершенных команд, не зависящих от данных, получаемых при выполнении других команд, или команд, имеющих неразрешенные предсказания перехода. Результаты выполнения обнаруженных завершенных команд передаются в память модулем изъятия или соответствующей стандартной архитектурой Intel в том порядке, в котором они были получены. Затем команды удаляются из буфера.В сущности, динамическое выполнение устраняет зависимость от линейной последовательности команд. Выполнение команд с изменением их последовательности позволяет максимально загрузить модуль выполнения и уменьшить время ожидания, необходимое для получения данных из памяти. Несмотря на то что порядок предсказания и выполнения команд может быть изменен, их результаты передаются в исходном порядке, для того чтобы не прерывать и не изменять течение программы. Это позволяет процессорам P6 выполнять существующее программное обеспечение архитектуры Intel точно так же, как это делали P5 (Pentium) или процессоры более ранних версий, но на целый порядок быстрее!
Архитектура двойной независимой шины
Эта архитектура (Dual Independent Bus — DIB) впервые была реализована в процессоре шестого поколения и предназначалась для увеличения пропускной способности шины процессора и повышения производительности. При наличии двух независимых шин данных для ввода-вывода процессор получает доступ к данным с любой из них одновременно и параллельно, а не последовательно, как в системе с одной шиной. Вторая, или фоновая (backside) входная шина процессора с DIB применяется кэш-памятью второго уровня, поэтому она может работать значительно быстрее, чем в том случае, если бы ей пришлось использовать (совместно с процессором) основную шину. В архитектуре DIB предусмотрено две шины: шина кэш-памяти второго уровня и шина, соединяющая процессор и основную память, или системная шина. Процессоры Pentium Pro, Celeron, Pentium II/III, Athlon и Duron могут использовать обе шины одновременно, благодаря чему снижается критичность такого параметра, как пропускная способность шины. Благодаря архитектуре двойной шины кэш-память второго уровня более современных процессоров может работать на полной скорости в ядре процессора на независимой шине, используя при этом основную шину центрального процессора (FSB) для обработки текущих данных, поступающих на микросхему и отправляемых ею. Шины работают с разной тактовой частотой. Шина FSB, или главная шина центрального процессора, соединена с системной платой, а шина кэш-памяти второго уровня — непосредственно с ядром процессора. При увеличении рабочей частоты процессора увеличивается тактовая частота кэш-памяти второго уровня. Для реализации архитектуры DIB кэш-память второго уровня перемещена с системной платы в один корпус с процессором, что позволило приблизить быстродействие кэш-памяти второго уровня к быстродействию встроенной кэш-памяти, которое значительно превосходит быстродействие памяти, помещаемой на системную плату. Чтобы поместить кэш в корпус процессора, понадобилось модифицировать гнездо процессора. DIB также позволяет системой шине выполнять одновременно несколько транзакций (а не одну последовательность транзакций), благодаря чему ускоряется поток информации внутри системы и повышается эффективность. Все средства архитектуры DIB повышают пропускную способность почти в три раза по сравнению с процессором, имеющим архитектуру одиночной шины
Производство процессоров
Основным химическим элементом, используемым при производстве процессоров, является кремний, самый распространенный элемент на земле после кислорода. Это базовый компонент, из которого состоит прибрежный песок (кремниевый диоксид); однако в таком виде он не подходит для производства микросхем. Чтобы использовать кремний в качестве материала для изготовления микросхемы, необходим длительный технологический процесс, который начинается с получения кристаллов чистого кремния по методу Жокральски (Czochralski). По этой технологии сырье, в качестве которого используется в основном кварцевая порода, преобразуется в электродуговых печах в металлургический кремний. Затем для удаления примесей полученный кремний плавится, дистиллируется и кристаллизуется в виде полупроводниковых слитков с очень высокой степенью чистоты (99,999999%). После механической нарезки слитков полученные заготовки загружаются в кварцевые тигли и помещаются в электрические сушильные печи для вытяжки кристаллов, где плавятся при температуре более 2500° по Фаренгейту. Для того чтобы предотвратить образование примесей, сушильные печи обычно устанавливаются на толстом бетонном основании. Бетонное основание, в свою очередь, устанавливается на амортизаторах, что позволяет значительно уменьшить вибрацию, которая может негативно сказаться на формировании кристалла. Как только заготовка начинает плавиться, в расплавленный кремний помещается небольшой, медленно вращающийся затравочный кристалл. По мере удаления затравочного кристалла от поверхности расплава вслед за ним вытягиваются кремниевые нити, которые, затвердевая, образуют кристаллическую структуру. Изменяя скорость перемещения затравочного кристалла (10-40 мм в час) и температуру (примерно 2500° по Фаренгейту), получаем кристалл кремния малого начального диаметра, который затем наращивается до нужной величины. В зависимости от размеров изготавливаемых микросхем, выращенный кристалл достигает 8-12 дюймов (20-30 мм) в диаметре и 5 футов (около 1,5 м) в длину.
Вес выращенного кристалла достигает нескольких сотен фунтов. Заготовка вставляется в цилиндр диаметром 200 мм (текущий стандарт), часто с плоской вырезкой на одной стороне для точности позиционирования и обработки. Затем каждая заготовка разрезается алмазной пилой более чем на тысячу круговых подложек толщиной менее миллиметра (рис2). После этого подложка полируется до тех пор, пока ее поверхность не станет зеркально гладкой. В производстве микросхем используется процесс, называемый фотолитографией. Технология этого процесса такова: на полупроводник, служащий основой чипа, один за другим наносятся слои разных материалов; таким образом, создаются транзисторы, электронные схемы и проводники (дорожки), по которым распространяются сигналы. В точках пересечения специфических схем можно создать транзистор или переключатель (вентиль). Фотолитографический процесс начинается с покрытия подложки слоем полупроводника со специальными добавками, затем этот слой покрывается фоторезистивным химическим составом, а после этого изображение микросхемы проектируется на ставшую теперь светочувствительной поверхность. В результате добавления к кремнию (который, естественно, является диэлектриком) донорных примесей получается полупроводник. Проектор использует специальный фотошаблон (маску), который является, по сути, картой данного конкретного слоя микросхемы. (Микросхема процессора Pentium III содержит пять слоев; другие современные процессоры могут иметь шесть или больше слоев. При разработке нового процессора потребуется спроектировать фотошаблон для каждого слоя микросхемы.) Проходя через первый фотошаблон, свет фокусируется на поверхности подложки, оставляя отпечаток изображения этого слоя. Затем специальное устройство несколько перемещает подложку, а тот же фотошаблон (маска) используется для печати следующей микросхемы. После того как микросхемы будут отпечатаны на всей подложке, едкая щелочь смоет те области, где свет воздействовал на фоторезистивное вещество, оставляя отпечатки фотошаблона (маски) конкретного слоя микросхемы и межслойные соединения (соединения между слоями), а также пути прохождения сигналов. После этого на подложку наносится другой слой полупроводника и вновь немного фоторезистивного вещества поверх него, затем используется следующий фотошаблон (маска) для создания очередного слоя микросхемы. Таким способом слои наносятся один поверх другого до тех пор, пока не будет полностью изготовлена микросхема.
Финальная маска добавляет так называемый слой металлизации, используемый для соединения всех транзисторов и других компонентов. В большинстве микросхем для этого слоя используют алюминий, но в последнее время стали использовать медь. Например, при производстве процессоров компании AMD на фабрике в Дрездене используется медь. Это объясняется лучшей проводимостью меди по сравнению с алюминием. Однако для повсеместного использования меди необходимо решить проблему ее коррозии.
Когда обработка круговой подложки завершится, на ней будет фотоспособом отпечатано максимально возможное количество микросхем. Микросхема обычно имеет форму квадрата или прямоугольника, по краям подложки остаются некоторые "свободные" участки, хотя производители стараются использовать каждый квадратный миллиметр поверхности. Промышленность переживает очередной переходный период в производстве микросхем. В последнее время наблюдается тенденция к увеличению диаметра подложки и уменьшению общих размеров кристалла, что выражается в уменьшении габаритов отдельных схем и транзисторов и расстояния между ними. В конце 2001 и начале 2002 года произошел переход с 0,18- на 0,13-микронную технологию, вместо алюминиевых межкристальных соединений начали использовать медные, при этом диаметр подложки увеличился с 200 мм (8 дюймов) до 300 мм (12 дюймов). Увеличение диаметра подложки до 300 мм позволяет удвоить количество изготавливаемых микросхем. Использование 0,13-микронной технологии позволяет разместить на кристалле большее количество транзисторов при сохранении его приемлемых размеров и удовлетворительного процента выхода годных изделий. Это означает сохранение тенденции увеличения объемов кэш-памяти, встраиваемой в кристалл процессора. В качестве примера того, как это может повлиять на параметры определенной микросхемы, рассмотрим процессор Pentium 4.

Диаметр стандартной подложки, используемой в полупроводниковой промышленности в течение уже многих лет, равен 200 мм или приблизительно 8 дюймов(рис). Таким образом, площадь подложки достигает 31 416 мм2. Первая версия процессора Pentium 4, изготовленного на 200-миллиметровой подложке, содержала в себе ядро Willamette, созданное на основе 0,18-микронной технологии с алюминиевыми контактными соединениями, расположенными на кристалле площадью около 217 мм2. Процессор содержал в себе 42 млн. транзисторов. На 200-миллиметровой (8-дюймовой) подложке могло разместиться до 145 подобных микросхем. Процессоры Pentium 4 с ядром Northwood, созданные по 0,13-микронной технологии, содержат в себе медную монтажную схему, расположенную на кристалле площадью 131 мм2. Этот процессор содержит уже 55 млн. транзисторов. По сравнению с версией Willamette ядро Northwood имеет удвоенный объем встроенной кэш-памяти второго уровня (512 Кбайт), что объясняет более высокое количество содержащихся транзисторов. Использование 0,13-микронной технологии позволяет уменьшить размеры кристалла примерно на 60%, что дает возможность разместить на той же 200-миллиметровой (8-дюймовой) подложке до 240 микросхем. Как вы помните, на этой подложке могло разместиться только 145 кристаллов Willamette. В начале 2002 года Intel приступила к производству кристаллов Northwood на большей, 300-миллиметровой подложке площадью 70 686 мм2. Площадь этой подложки в 2,25 раза превышает площадь 200-миллиметровой подложки, что позволяет практически удвоить количество микросхем, размещаемых на ней. Если говорить о процессоре Pentium 4 Northwood, то на 300-миллиметровой подложке можно разместить до 540 микросхем. Использование современной 0,13-микронной технологии в сочетании с подложкой большего диаметра позволило более чем в 3,7 раза увеличить выпуск процессоров Pentium 4. Во многом благодаря этому современные микросхемы зачастую имеют более низкую стоимость, чем микросхемы предыдущих версий. В 2003 году полупроводниковая промышленность перешла на 0,09-микронную технологию. При вводе новой поточной линии не все микросхемы на подложке будут годными. Но по мере совершенствования технологии производства данной микросхемы возрастет и процент годных (работающих) микросхем, который называется выходом годных. В начале выпуска новой продукции выход годных может быть ниже 50%, однако ко времени, когда выпуск продукта данного типа прекращается, он составляет уже 90%. Большинство изготовителей микросхем скрывают реальные цифры выхода годных, поскольку знание фактического отношения годных к бракованным может быть на руку их конкурентам. Если какая-либо компания будет иметь конкретные данные о том, как быстро увеличивается выход годных у конкурентов, она может скорректировать цены на микросхемы или спланировать производство так, чтобы увеличить свою долю рынка в критический момент. Например, в течение 1997 и 1998 годов у AMD был низкий выход годных, и компания утратила значительную долю рынка. Несмотря на то что AMD предпринимала усилия для решения этой проблемы, ей все же пришлось подписать соглашение, в соответствии с которым IBM Microelectronics должна была произвести и поставить AMD некоторые ею же разработанные микропроцессоры. По завершении обработки подложки специальное устройство проверяет каждую микросхему на ней и отмечает некачественные, которые позже будут отбракованы. Затем микросхемы вырезаются из подложки с помощью высокопроизводительного лазера или алмазной пилы. Когда кристаллы будут вырезаны из подложек, каждая микросхема испытывается отдельно, упаковывается и снова проходит тест. Процесс упаковки называется соединением: после того как кристалл помещается в корпус, специальная машина соединяет тонюсенькими золотыми проводами выводы кристалла со штырьками (или контактами) на корпусе микросхемы. Затем микросхема упаковывается в специальный пакет — контейнер, который, по существу, предохраняет ее от неблагоприятных воздействий внешней среды. После того как выводы кристалла соединены со штырьками на корпусе микросхемы, а микросхема упакована, выполняется заключительное тестирование, чтобы определить правильность функционирования и номинальное быстродействие. Разные микросхемы одной и той же серии зачастую обладают различным быстродействием. Специальные тестирующие приборы заставляют каждую микросхему работать в различных условиях (при разных давлениях, температурах и тактовых частотах), определяя значения параметров, при которых прекращается корректное функционирование микросхемы. Параллельно определяется максимальное быстродействие; после этого микросхемы сортируются по быстродействию и распределяются по приемникам: микросхемы с близкими параметрами попадают в один и тот же приемник. Например, микросхемы Pentium 4 2,0А, 2,2, 2,26, 2,24 и 2,53 ГГц представляют собой одну и ту же микросхему, т. е. все они были напечатаны с одного и того же фотошаблона, кроме того, сделаны они из одной и той же заготовки, но в конце производственного цикла были отсортированы по быстродействию.
Корпуса процессоров
Корпус PGA
Корпус типа PGA до недавнего времени был самым распространенным. Он использовался начиная с 1980-х годов для процессоров 286 и сегодня применяется для процессоров Pentium и Pentium Pro. На нижней части корпуса микросхемы имеется массив штырьков, расположенных в виде решетки. Корпус PGA вставляется в гнездо типа ZIF (Zero Insertion Force — нулевая сила вставки). Гнездо ZIF имеет рычаг для упрощения процедуры установки и удаления чипа. Для большинства процессоров Pentium используется разновидность PGA — SPGA (Staggered Pin Grid Array — шахматная решетка массива штырьков), где штырьки на нижней стороне чипа расположены в шахматном порядке, а не в стандартном — по строкам и столбцам. Это было сделано для того, чтобы разместить штырьки ближе друг к другу и уменьшить занимаемую микросхемой площадь. Справа на рисунке показан корпус Pentium Pro, на котором штырьки расположены по двойному шаблону SPGA; рядом с ним — обычный корпус процессора Pentium 66. Обратите внимание, что на верхней половине корпуса Pentium Pro имеются дополнительные штырьки, которые расположены среди других строк и столбцов в шахматном порядке. В ранних версиях корпуса PGA кристалл процессора устанавливался лицевой стороной вниз в специальную полость, находящуюся ниже поверхности подложки. После этого кристалл прикреплялся к корпусу микросхемы сотнями тончайших золотых проводков, соединяющих контакты микросхемы с внутренними контактами корпуса. После выполнения проводного соединения полость корпуса закрывалась специальной металлической крышкой. Подобный способ изготовления микросхем оказался слишком дорогим и трудоемким, поэтому были разработаны более дешевые и эффективные методы упаковки. Большинство современных процессоров собираются в корпусе с матричным расположением штырьковых выводов на обратной стороне кристалла (Flip-Chip Pin Grid Array — FC-PGA). Процессоры этого типа все еще устанавливаются в разъем PGA, но сам корпусстал значительно проще. При использовании корпуса FC-PGA необработанный кристалл кремния устанавливается лицевой стороной вниз на верхнюю часть подложки микросхемы. При этом проволочное соединение заменяется аккуратной пайкой контактов по периметру кристалла. Края кристалла заливаются эпоксидной смолой. В оригинальных версиях корпуса FC-PGA пользователь может увидеть тыльную часть необработанного кристалла, установленного в этой микросхеме. К сожалению, существует целый ряд проблем, связанных с закреплением радиатора на корпусе микросхемы FC-PGA. Радиатор "сидит" на верхней части кристалла, который служит его основанием. Если к одной из сторон радиатора во время его установки (например, при подсоединении зажима) приложить чрезмерное усилие, можно расколоть кристалл кремния и повредить микросхему. Поскольку радиаторы становятся больше и тяжелее, увеличивается усилие, необходимое для их установки. Компания AMD попыталась уменьшить вероятность повреждения, установив в корпуcсе процессора специальные резиновые прокладки, предотвращающие чрезмерный наклон радиатора во время его установки. К сожалению, эластичность используемых прокладок не позволяет полностью избежать опасности повреждения микросхемы при установке радиатора. В настоящее время в процессорах Athlon XP используется корпус FC-PGA с прокладками, установленными в каждом углу подложки. В компании Intel была создана новая версия корпуса FC-PGA2, используемая в более современных процессорах Pentium III и всех процессорах Pentium 4. Этот корпус включает в себя специальный теплораспределитель — металлическую защитную крышку, расположенную на верхней части кристалла. Эта крышка позволяет устанавливать большие и довольно тяжелые радиаторы, не опасаясь потенциального повреждения ядра процессора. В будущем появится корпус, получивший название безударной послойной сборки (Bumpless Build-Up Layer — BBUL), при которой кристалл полностью заключается в корпус; фактически стенки корпуса формируются вокруг кристалла и поверх него, образуя полностью герметичную конструкцию. Корпус подобного типа охватывает кристалл микросхемы, создавая при этом плоскую поверхность, необходимую для установки радиатора, а также упрощая схему внутренних соединений в корпусе.
Корпуса SEC и SEPВ период с 1997 по 2000 год в Intel и AMD использовались модули процессоров, выполненные на основе картриджей или плат. Подобная компоновка, называемая корпусом с односторонним контактом (Single Edge Contact Cartridge — SECC) или корпусом с одним процессором (Single Edge Processor Package — SEPP), включает в себя центральный процессор и несколько отдельных микросхем кэш-памяти второго уровня, собранных на монтажной плате, похожей на модули памяти большого размера и установленной в соответствующий разъем. В некоторых случаях монтажные платы закрывались специальными пластмассовыми крышками. Корпус SEC представляет собой новаторскую, правда, несколько громоздкую конструкцию, включающую в себя рабочую шину процессора и внешнюю кэш-память второго уровня. Этот корпус использовался в качестве оптимального метода интегрирования кэш-памяти второго уровня в процессор до появления возможности включения кэш-памяти непосредственно в кристалл процессора. Корпус SEP (Single Edge Processor — корпус с одним процессором) является более дешевой разновидностью корпуса SEC. В корпусе SEP нет верхней пластмассовой крышки, а также может не устанавливаться кэш-память второго уровня (или же устанавливается меньший объем). Корпус SEP вставляется в разъем Slot 1. Чаще всего в корпус SEP помещают недорогие процессоры, например Celeron. Slot 1 — это разъем системной платы, имеющий 242 контакта. Переходник с S370 к Slot 1 показан на рисунке. Корпус SEC или SEP, внутри которого находится процессор, вставляется в Slot 1 и фиксируется специальной скобой. Иногда имеется крепление для системы охлаждения процессора. На рис показаны части крышки, из которых состоит картридж SEC. Обратите внимание на большую пластину, рассеивающую тепло, выделяемое процессором. Процессор Pentium III упаковывается в корпус, который называется SECC2 (Single Edge Contact Cartridge, версия 2). Этот корпус является разновидностью корпуса SEC. Крышка расположена с одной стороны, а с другой стороны непосредственно к микросхеме прикрепляется охлаждающий элемент. Такое конструктивное решение позволяет более эффективно отводить от процессора тепло. Процессоры в этом корпусе вставляются в разъемы Slot 1. Корпус SECC2 показан на рис. Появление корпусов подобного типа было связано с невозможностью включения кэш-памяти в кристалл ядра центрального процессора. После появления конструкций, позволяющих ввести кэш-память второго уровня непосредственно в кристалл процессора, необходимость в использовании корпусов SEC и SEP исчезла. Практически все современные процессоры включают в себя интегрированную кэш-память второго уровня, поэтому при компоновке процессора разработчики снова вернулись к корпусу PGA.
Гнезда для процессоров.S370
Гнезда для процессоров Socket 370 (PGA-370)
В январе 1999 года компания Intel представила новое гнездо для процессоров класса P6. Это гнездо получило название Socket 370 (PGA-370), так как содержит 370 выводов (штырьков) и первоначально разрабатывалось для более дешевых процессоров Celeron и Pentium III версий PGA. Платформа Socket 370 предназначалась для вытеснения с рынка систем среднего и нижнего уровней архитектуры Super 7 (что ей вполне удалось), поддерживаемой компаниями AMD и Cyrix. Новое гнездо позволяет использовать менее дорогие процессоры, монтажные системы, радиаторы и т. п., тем самым уменьшая стоимость всей конструкции. Первоначально все процессоры Celeron и Pentium III выпускались в исполнении SECC или SEPP. В целом эта конструкция представляла собой монтажную плату, содержащую процессор и кэш-память второго уровня, установленную на отдельной плате, которая, в свою очередь, была подключена к системной плате через разъем Slot 1. Микросхема кэша второго уровня являлась частью процессора, но не была непосредственно в него интегрирована. Модуль многокристальной микросхемы был разработан Intel для процессора Pentium Pro, стоимость которого, однако, оказалась слишком высокой. Плата с отдельно расположенными микросхемами была гораздо дешевле, поэтому процессор Pentium II и отличался от своего предшественника.Компания Intel, начиная с процессора Celeron 300А (представленного в августе 1998 года) начинает объединять кэш-память второго уровня непосредственно с кристаллом процессора; разделенные микросхемы больше не применяются. При использовании полностью интегрированной кэш-памяти необходимость в установке процессора на отдельной плате исчезает. Следует заметить, что для снижения себестоимости Intel вернулась к гнездовой конструкции, которая была использована, в частности, в процессоре Celeron. Расположение выводов гнезда Socket 370 (PGA-370) показано на рисунке выше.Все процессоры Celeron с рабочей частотой 333 МГц и ниже доступны только в корпусе Slot 1, 366—433 МГц — как в корпусе Slot 1, так и в Socket 370, а начиная с модели 466 МГц — только в корпусе Socket 370. Процессоры в исполнении Socket 370 (PGA-370) можно устанавливать в разъем Slot 1. Для этого необходимо приобрести специальный переходник PGA-Slot 1.Обратите внимание, что некоторые системные платы Socket 370 не поддерживают процессоров Pentium III и Celeron в корпусе FC-PGA. Это связано с тем, что новые процессоры имеют два вывода RESET и им нужна поддержка спецификации питания VRM 8.4. Предшествующие системные платы, разработанные только для процессоров Celeron, относятся к традиционным системным платам, а более новые, поддерживающие второй вывод RESET и спецификацию VRM 8.4, называются улучшенными системными платами. Чтобы выяснить, относится ли гнездо к компонентам расширенных версий, обратитесь к производителям системной платы или системы. Некоторые системные платы, к числу которых принадлежит Intel CA810, поддерживают спецификацию VRM 8.4 и обеспечивают соответствующее напряжение. Однако без поддержки вывода Vtt, процессор Pentium III в корпусе FC-PGA будут удерживаться в положении RESET#.Установка нового процессора в корпусе FC-PGA в старую системную плату не приведет к выходу из строя последней. Скорее всего, можно повредить сам процессор: Pentium III, изготовленный по 0,18-микронной технологии, использует напряжение питания 1,60-1,65 В, в то время как в устаревших платах рабочее напряжение 2,00 В. Существует также вероятность того, что системная плата выйдет из строя. Это может произойти в том случае, если BIOS системной платы не сможет правильно идентифицировать напряжение процессора. Чтобы гарантировать совместимость системной платы и BIOS, обратитесь перед установкой к производителю компьютера или системной платы. Конструкция системной платы с разъемом Slot 1 позволяет поддерживать практически все процессоры Celeron, Pentium II или Pentium III, в том числе и "гнездовые" версии процессоров Celeron и Pentium III. Для этого следует воспользоваться адаптером типа Slot-socket, который иногда называется также slot-ket. Этот адаптер, по существу, представляет собой плату Slot 1, содержащую только гнездо Socket 370, что позволяет использовать процессор PGA в любой плате Slot 1.
Socket 423Гнездо ZIF-типа Socket 423 (рисунок) анонсировано в ноябре 2000 года для процессора Pentium 4 (кодовое имя Willamette).Архитектура Socket 423 поддерживает шину процессора 400 МГц, соединяющую процессор с ядром контроллера памяти (Memory Controller Hub — MCH), который является основной частью микропроцессорного набора системной платы. Процессоры Pentium 4 с рабочей частотой 2 ГГц обычно используются с разъемом Socket 423; для более быстрых версий необходим разъем Socket 478.В конструкции Socket 423 используется уникальный метод установки радиатора, состоящий в применении крепежных элементов, присоединенных к корпусу системного блока или к специальной пластине, расположенной ниже системной платы. Подобная конструкция была разработана для того, чтобы выдерживать вес большого радиатора, необходимого для работы Pentium 4. По этой причине для установки системных плат с гнездом Socket 423 часто требуется специальный блок, содержащий дополнительные элементы жесткости. К счастью, с появлением нового гнезда Socket 478, предназначенного для Pentium 4, потребность в использовании дополнительных конструктивных элементов исчезла.В процессоре используется пять выводов идентификатора напряжения (VID), которые дают возможность с помощью модуля VRM, встроенного в системную плату, задать точное значение необходимого напряжения для определенного процессора. Это позволяет автоматически устанавливать величину напряжения. Первые версии Pentium 4 используют напряжение питания 1,7 В, которое может измениться в следующих моделях. Маленькая треугольная метка в одном из углов указывает расположение вывода 1, тем самым помогая правильно установить микросхему. Существуют адаптеры для процессора Socket 478 на Socket 423
Гнезда для процессоров.S478
Socket 478Гнездо ZIF-типа Socket 478 анонсировано в октябре 2001 года для процессора Pentium 4. Это гнездо было разработано специально для поддержки дополнительных контактов будущих процессоров Pentium 4 с тактовой частотой более 2 ГГц. Монтаж радиатора выполняется по-другому, чем в ранее использовавшемся гнезде Socket 423, позволяя тем самым устанавливать на центральный процессор радиаторы больших размеров(рис 2). Гнездо Socket 478 показано на рисунке.Архитектура Socket 478 поддерживает шину процессора 400 или 533 МГц, соединяющую процессор с ядром контроллера памяти (Memory Controller Hub — MCH), который является основной частью набора микросхем системной платы.
Гнезда для процессоров.S775
Socket 775
Выход Socket 775 ознаменовался: 1.Socket 775 становится ведущей платформой для процессоров Intel. 2.LGA775 стал первой в мире десктопной x86-платформой с поддержкой памяти стандарта DDR2;3.Вместе с анонсом новых процессоров, компания анонсирует два чипсета: Intel 915P Express и Intel 925X Express. Первый позиционируется для систем нижнего и среднего уровня и поддерживает, как DDR2, так и обычную DDR-память. Intel 925X Express предназначен для высокопроизводительных десктопов и рабочих станций и поддерживает только память стандарта DDR2.4.Оба чипсета лишились поддержки шины AGP, приобретя вместо нее новую высокоскоростную шину PCI Express x16. Для прочих устройств сохранена совместимость с обычной PCI, но также поддерживается до 4 портов PCI Express 1x.

Так выглядит Socket 775 в закрытом состоянии без установленного процессора. Очень похоже на фотографию Socket 478 CPU, только перевёрнутого вверх ногами и положенного на плату. Почти так оно, в общем-то, и есть: теперь ножки являются частью сокета, а не CPU. С одной стороны, тихий ропот некоторых производителей системных плат можно понять: сам сокет, как деталь платы, по всей видимости, стал дороже, да и «нежнее» — случайно зацепив ножки, можно их погнуть. С другой стороны, в конечном итоге мы имеем всего лишь «перераспределение общей ответственности»: раньше о целостности ножек голова должна была болеть у изготовителя CPU, теперь — у изготовителя системной платы. Пользователи же по сути ничего не проиграли и не выиграли: раньше вследствие неаккуратного обращения они могли повредить ножку процессора, теперь — ножку на сокете. Кто ломал — тот будет ломать и дальше, кто соблюдает правила установки — тому, в общем-то, все равно. Кстати, к слову о возможном ущербе: процессоры Pentium 4 в среднем стоят дороже, чем платы для них...

А вот так выглядит кулер, который шел в комплекте поставки референсной системы для платформы Socket 775. Легко заметить основные особенности:
-Радиатор довольно велик по размеру;
-Имеет медный сердечник, не полностью покрывающий верхнюю крышку процессора;
-Размеры крыльчатки также вызывают уважение;
-Крепление в очередной раз кардинально изменилось — теперь кулер крепится непосредственно к системной плате;
И на последней фотографии. Старый, уже практически ушедшый с продажи S478 и его замена S778.

Гнезда для процессоров.S462(Socket A)

Socket A (Socket 462)
В июне 2000 года компания AMD представила гнездо Socket A (называемое также Socket 462), предназначенное для поддержки процессоров Athlon и Duron версии PGA. Это гнездо разрабатывалось для замены Slot A, используемого изначальным процессором Athlon. В настоящее время в процессорах Athlon и Duron используется встроенная кэш-память второго уровня, поэтому дорогой корпус, предназначенный для первых версий процессора Athlon, больше не нужен. Socket A (Socket 462) содержит 462 контакта и имеет те же размеры, что и Socket 370. Однако поместить процессор для гнезда Socket 370 в Socket A невозможно. Это гнездо поддерживает 32 значения напряжения питания в диапазоне 1,100-1,850 В с шагом 0,025 В (контакты процессора VID0-VID4). Блок регулирования напряжения питания встроен в системную плату. Внешний вид гнезда Socket A (Socket 462) показан на рисунке. Существует в общей сложности 11 заглушенных отверстий, в число которых вошли и два внешних микроотверстия. Эти отверстия используются для правильной ориентации процессора в гнезде во время его установки. Схема расположения выводов Socket A показана на рисунке.
Внимание !Возможность установки микросхемы в тот или иной разъем вовсе не означает, что она будет работать. Для корректной работы более современных версий процессоров Athlon XP требуется другое напряжение питания, а также поддержка BIOS и соответствующий набор микросхем. Как обычно, не забудьте убедиться в том, что существующая системная плата поддерживает устанавливаемый процессор.

Socket 754
AMD Athlon 64, Semrpon . Было 754 ноги. Именно эта платформа дала миру 64-битность. Теперь на процессорах находилась защитная крышка для защиты ядра от скола. Эта платформа сменила Socket A. время Socket

Через некоторое A был снят с производства.
Socket 939
Практически одновременно с 754 сокетом был разработан 939-й. Самые типовые процессоры AMD создавались преимущественно на это гнездо. Athlon 64 FX -55, 57 - были легендарными с прекрасной производительностью.
Socket 940
Серверная платформа, в корне поддерживающая многопроцессорность, что и требуется серверу. Вполне очевидно, что AMD желала сделать Socket 939 новым стандартом. Socket 940, в той или иной мере, вытеснялся, за исключением решений на Opteron. Socket 754 с одноканальным контроллером памяти оставался на рынке, однако он плавно уходил в стадию дешёвых решений. Конечно, техническое различие между Socket 940 и 939 невелико - какие-то контакты. AMD необходимо разделить рынок серверов и потребительских систем - это важно с точки зрения бизнеса. Вспомните путаницу между Athlon XP и MP: потребители знали, что оба этих процессора идентичны и приобретали два Athlon XP для двухпроцессорных систем. К тому же они были (и остаются) существенно дешевле. Платформа на Socket 939 также поддерживает работу шины HyperTransport на частоте 1 ГГц, используя при этом передачу DDR, в отличие от принятой раньше частоты 800 МГц. В результате суммарная (двунаправленная) пропускная способность составляет 8 Гбайт/с, а не прежние 6,4 Гбайт/с. Конечно, здесь необходима поддержка со стороны чипсета, но с этим уже справились nVidia, SiS и VIA. Чипсеты nForce3 250 Ultra, SiS755FX/756 и K8T800 Pro уже готовы для Socket 939. Собственно, поэтому у AMD нет никакой необходимости в разработке своего собственного чипсета.

Socket AM2 с DDR2
Теперь процессоры AMD тоже перешли на память DDR2, почти через два года после Intel. Время AMD выбрала очень удачно, поскольку рынок сегодня наводнён недорогой памятью DDR2. Но AMD пошла по другому пути: в отличие от платформы Intel интерфейс памяти интегрирован в процессор, поэтому для перехода на новую платформу уже недостаточно просто сменить чипсет. Перенос интерфейса памяти с северного моста на процессор приводит к следующим проблемам:
-нужно менять процессорное ядро;
-Требуется новый сокет.
Возникает вопрос: почему же AMD ждала именно нынешнего момента, чтобы внедрить технологию DDR2? Мы видим три возможных причины. Память DDR2 в момент своего появления стоила очень дорого, поэтому платформа AMD оказалась бы менее привлекательной по сравнению с Intel. Производители памяти теперь уже стали выпускать модули DDR2 с достаточно высокими скоростями, так что платформа уже не получит снижения производительности из-за высоких задержек памяти DDR2. Интеграция интерфейса DDR2 в процессор ранее не была возможна из-за слишком высокой стоимости или ограничений по числу транзисторов.Socket AM2 имеет точно такое же число контактов, как и оригинальный Athlon 64 на ядре Hammer (Socket 940), но сокеты несовместимы. Новые процессоры AM2 нельзя установить в Socket 940.
Напряжение питания процессоров
В последнее время явно прослеживается тенденция к снижению напряжения питания процессоров. Наиболее очевидным следствием этого является снижение потребляемой мощности. Конечно, если потребляемая мощность меньше, то функционирование системы обходится дешевле; еще более важно снижение потребляемой мощности для переносных систем, так как благодаря этому компьютер может работать намного дольше на одной и той же батарее. Именно значительное удлинение срока службы батареи, вызванное снижением потребляемой мощности, повлекло за собой множество усовершенствований, направленных на понижение напряжения питания процессора. Еще одним преимуществом является то, что при пониженном напряжении, а следовательно, и при более низкой потребляемой мощности, выделяется меньше тепла. Процессор и вентилятор можно размещать ближе к другим компонентам, т. е. упаковка системы может быть более плотной; кроме того, срок службы процессора возрастает. К преимуществам можно отнести и то, что процессор вместе с вентилятором потребляет меньшую мощность, а потому может работать быстрее. Именно благодаря снижению напряжения удалось повысить тактовую частоту процессоров. До выпуска портативных компьютеров на базе в большинстве процессоров использовалось одно и то же напряжение и для процессора, и для схем ввода-вывода. Вначале большинство процессоров, а также схемы ввода-вывода работали при напряжении, равном 5 В, которое позже было снижено до 3,5 или 3,3 В (в целях уменьшения потребляемой мощности). Когда один и тот же уровень напряжения используется для процессора, его внешней шины и сигналов схем ввода-вывода, говорят, что такой процессор использует единственный, или унифицированный, уровень напряжения. При создании процессора Pentium для переносных компьютеров компанией Intel был разработан способ, применяя который можно значительно уменьшить потребляемую мощность при сохранении совместимости с существующими наборами микросхем системной логики, микросхемами логики шины, микросхемами памяти и другими компонентами, рассчитанными на 3,3 В. Благодаря этому был создан компьютер с двумя уровнями напряжения, или с расщеплением уровня напряжения, в котором процессор использовал более низкое напряжение, а схемы ввода-вывода работали при напряжении 3,3 В. Это новшество стали называть технологией уменьшения напряжения (Voltage Reduction Technology — VRT); оно появилось в портативных вариантах процессора Pentium в 1996 году. Позже два уровня напряжения использовались также в процессорах для настольных систем; например, в Pentium MMX использовалось напряжение 2,8 В, а схемы ввода-вывода работали при напряжении 3,3 В. Теперь в большинстве современных процессоров как для переносных, так и для настольных компьютеров используются два уровня напряжения. В некоторых современных процессорах используется напряжение 1,6 В.Гнезда и разъемы процессоров Pentium имеют специальные контакты — Voltage ID (VID), которые используются процессором для сообщения системной плате точных значений необходимого напряжения. Это позволяет преобразователям напряжения, встроенным в системную плату, автоматически устанавливать правильный уровень напряжения сразу при установке процессора. Все системные платы последних версий позволяют в целях повышения производительности отменить установленное значение напряжения. Причем эту величину можно изменить вручную, ведь для разгона процессора достаточно увеличить напряжение на десятую часть вольта. Следует заметить, что в этом случае, конечно, увеличивается нагрев процессора, поэтому необходимо принять соответствующие меры по отводу избыточного тепла.
Перегрев и охлаждение
В компьютерах с быстродействующими процессорами могут возникать серьезные проблемы, связанные с перегревом микросхем. Более быстродействующие процессоры потребляют большую мощность и соответственно выделяют больше тепла. Для отвода тепла необходимо принимать дополнительные меры, поскольку встроенного вентилятора может оказаться недостаточно.
Теплоотводы
Для охлаждения процессора нужно приобрести дополнительный теплоотвод (радиатор). В некоторых случаях может потребоваться нестандартный теплоотвод с большей площадью поверхности (с удлиненными ребрами).Теплоотводы бывают пассивными и активными. Пассивные теплоотводы являются простыми радиаторами, а активные содержат небольшой вентилятор, требующий дополнительного питания. Теплоотводы могут быть прижатыми к микросхеме или приклеенными к ее корпусу. В первом случае для улучшения теплового контакта между радиатором и корпусом микросхемы их поверхности следует смазать теплопроводящей пастой. Она заполнит воздушный зазор, обеспечив лучшую передачу тепла. Эффективность теплоотводов определяется отношением температуры радиатора к рассеиваемой мощности. Чем меньше это отношение, тем эффективность рассеивания тепла выше.
Активные и пассивные теплоотводы

Для увеличения эффективности радиатора в него встраивают вентиляторы. Такие теплоотводы называются активными (рис). Разъем питания вентилятора похож на обычный разъем питания накопителя, но в последнее время выпускаются радиаторы с вентилятором, который подключается к системной плате. В активных теплоотводах используются вентилятор или какое-либо другое устройство охлаждения, для работы которого необходима электрическая энергия. Активные теплоотводы обычно подключаются к специальному разъему питания, расположенному на системной плате (а в системах более ранних версий — к разъему питания дисковода).При использовании теплооотводов с вентилятором не забывайте о том, что зачастую эти вентиляторы являются дешевыми устройствами весьма низкого качества. Например, в вентиляторах часто используется электрический двигатель с подшипниками, срок службы которых крайне непродолжителен. Я рекомендую приобретать только вентиляторы с электродвигателями на шарикоподшипниках, которые служат примерно в 10 раз дольше, чем подшипники скольжения (или подшипники втулочного типа). Конечно, подобные вентиляторы почти в два раза дороже, но их применение в конечном итоге приводит к ощутимой экономии. Покупка процессора "коробочного" типа, включающего в себя высококачественный активный теплоотвод заводского изготовления, установленный в одном корпусе с процессором, избавит от необходимости приобретения хорошего активного теплоотвода с вентилятором за 15-25 долларов.

Пассивные теплоотводы представляют собой реберные алюминиевые радиаторы, принимающие поток воздуха, поступающего из внешнего источника (рисунок). Условием хорошей работы пассивного теплоотвода является воздушный поток, огибающий ребра или пластины радиатора. Источником воздуха чаще всего служит вентилятор, встроенный в системный блок. Для повышения его эффективности обычно применяется специальная трубка, используемая для направления воздушного потока прямо через ребра радиатора. Интегрирование пассивного теплоотвода является довольно сложным занятием, поскольку необходимо обеспечить постоянный приток воздуха, поступающего из какого-либо внешнего источника. Следует заметить, что при соответствующем исполнении пассивный теплоотвод может оказаться довольно эффективным и рентабельным. Это является основной причиной, по которой во многих фирменных системах, к числу которых относятся компьютеры Dell и Gateway, часто используются пассивные теплоотводы с туннельным вентилятором. Системам, собираемым отдельными пользователями или специалистами небольших компаний, не имеющими возможности разработать нестандартную схему пассивного охлаждения, приходится полагаться на активные теплоотводы со встроенными вентиляторами. Активные теплоотводы обеспечивают надежное принудительное охлаждение процессора независимо от схемы движения воздушных потоков, используемой в данной системе. Так называемые коробочные версии процессоров Intel и AMD или процессоры, поступающие в розничную продажу, включают в себя высококачественные активные теплоотводы, предназначаемые для работы в максимально неблагоприятных условиях. Одна из основных причин, по которой я склоняюсь к приобретению процессоров коробочных версий, состоит в гарантированном получении надежного теплоотвода, предназначенного для охлаждения процессора при самых неблагоприятных внешних условиях, что является условием долгой "жизни" компьютера.
Установка теплоотвода

Для эффективной работы радиатора необходимо обеспечить надежный контакт с корпусом процессора. Даже небольшая воздушная прослойка между процессором и радиатором приведет к перегреву процессора и выходу его из строя. Для надежности соединения теплоотводных элементов иногда используются специальные крепежные материалы, например теплопроводный клей. В большинстве новых систем используется улучшенный формфактор системной платы, называемый ATX. В системах с системной платой и корпусом этого типа улучшено охлаждение процессора: он установлен близко от источника питания, а вентилятор источника питания в большинстве систем ATX установлен так, что обдувает процессор. И потому в таких системах можно использовать пассивный теплоотвод (т. е. обойтись без вентилятора процессора). В корпусе FC-PGA, используемом в современных процессорах, необработанный кристалл процессора устанавливается в перевернутом виде на верхней части микросхемы, благодаря чему этот корпус и получил свое название (flip-chip — перевернутый кристалл). Сборка процессора методом перевернутого кристалла дает возможность устанавливать теплоотвод непосредственно на кристалл, что позволяет максимально отводить тепло от работающего процессора.
Термопаста
Как известно, воздух является плохим проводником тепла. Поэтому любой зазор между процессором и кулером приводит к ухудшению теплоотвода и как следствие - перегреву процессора. Добиться от алюминиевого или медного радиатора абсолютной гладкости непросто - потребуется долгая и упорная шлифовка. Есть другой путь: заполнить любые микроскопические неровности вязким теплопроводящим веществом, называемым термопастой. Лучшие ее образцы содержат оксид серебра и других металлов и при этом не стоят слишком дорого.
Например, Titan TTG-S101 можно приобрести примерно за $1 "с копейками", и такого тюбика хватит не на один кулер. Термопаста Сooler Master HTK-001 стоит дороже -- $2,5, но она поставляется со всем необходимым для равномерного нанесения вещества на поверхность радиатора. То же относится и к более эффективной пасте Cooler Master PTK-001 стоимостью $5,5.Итак, о термопасте не забыли, остается уточнить нюансы установки радиатора. Превышение или неравномерное распределение усилия, прилагаемого при установке радиатора, является одной из основных проблем. В соответствии со спецификациями Intel средняя допустимая нагрузка, возникающая при установке радиатора на кристалл процессора, не должна превышать 20 фунтов (около 8 кг). В то же время пружинные зажимы, используемые в системах AMD для фиксации теплоотвода, имеют более высокое усилие прижима, равное 30 фунтам (примерно 12 кг). Очень часто это приводит к повреждению процессора непосредственно при установке теплоотвода. Причиной более высокой статической нагрузки на микросхемы AMD является стремление обеспечить более высокую теплопередачу, поскольку процессоры AMD нагреваются во время работы до более высокой температуры, чем микросхемы Intel. Кристалл процессора выступает над поверхностью микросхемы, поэтому установленный радиатор контактирует непосредственно только с кристаллом; при этом его края выходят далеко за границы кристалла. Слишком высокая или неравномерно распределенная нагрузка при установке радиатора может привести к физическому повреждению кристалла. В результате процессор выходит из строя, причем изготовитель микросхемы не несет никаких гарантийных обязательств, так как причиной повреждения является не заводской брак, а неправильная эксплуатация процессора. Проблема физического повреждения кристалла актуальна для процессоров компаний AMD и Intel, но более всего она касается микросхем AMD, что связано с необходимостью применять большое усилие для фиксации теплоотвода. Многие поставщики предоставляют гарантию только в том случае, если процессор продается вместе с системной платой и предварительно установленным теплоотводом. В компаниях AMD и Intel были разработаны определенные методы решения подобных проблем. Например, в процессорах AMD по углам микросхемы начали устанавливаться специальные резиновые прокладки, предназначенные для поддержки корпуса радиатора и компенсации неравномерно распределяемых усилий фиксации, приводящих к повреждению кристалла. К сожалению, использование демпфирующих прокладок не позволяет полностью избежать раскалывания кристалла при установке теплоотвода в наклонном или перекошенном положении. В компании Intel пришли к другому решению, и в более современных процессорах над кристаллом устанавливается металлическая крышка, называемая интегрированным теплораспределителем (Integrated Heat Spreader — IHS).

Эта крышка защищает кристалл от чрезмерного давления и увеличивает поверхность термического контакта между процессором и теплоотводом. Допустимое усилие прижима для многих микросхем Intel, снабженных модулем IHS, достигает 100 фунтов (около 40 кг), что практически избавляет пользователей от опасности повреждения кристалла при установке теплоотвода. Интегрированный распределитель тепла включен во все процессоры Pentium 4 и Pentium III/Celeron Tualatin, созданные по 0,13-миикронной технологии.При использовании процессоров AMD или Intel, не содержащих металлической пластины интегрированного распределителя тепла, особое внимание обращайте на ровное расположение контактных поверхностей кристалла и радиатора во время закрепления или снятия фиксатора теплоотвода.
Разгон процессора. Подготовка к бою
Оверклокинг – изменение режимов работы компонентов компьютера для увеличения итоговой производительности системы. Разгон-занятие энтузиастов, стремящихся выжать максимум со своей системы. В виду того, что сам процесс разгона стал упрощаться, и производители материнских плат сами создают оверклокерские модели, то разгоном начинает заниматься все большее и большее число пользователей. Пользователей компьютеров условно можно разделить на несколько категорий. Некоторые, знакомые с основами разгона, ограничиваются символическим поднятием тактовых частот, либо стараются оптимально поднять производительность. Цель тех, кто называет себя оверклокерами, – заплатив определенную сумму за комплектующие, получить производительность, сравнимую с показателями намного более дорогого ПК. На хороший результат разгона влияет целый комплекс факторов – от квалификации самого пользователя, тщательного подбора компонентов системы до банального везения. Но на компоненты системы следует обратить внимание особо. А потому пройдемся по основным компонентам.
Материнская плата – основа любой системы. От функциональных возможностей, богатства настроек BIOS, сбалансированности данного компонента в целом и фактических результатов представителей определенного модельного ряда будет зависеть как минимум половина успеха при разгоне. Я всегда был сторонником ASUS. Именно они славятся наиболее производительными платами с хорошим запасом для разгона. Возможно потому я сторонник, что первая моя материнская плата была ASUS на 875 чипсете, которая позволяла выжать с процессора на ядре Northwood 3.4 ГГц, что в принципе являлось пределом для этого ядра(процессор разгонялся со штатной системой охлаждения.)
Процессор. При желании добиться максимальных результатов нужно избегать покупки CPU с самыми низкими множителями (например, Core 2 Duo Е6300). Если представляется возможность – отобрать наиболее удачный в плане оверклокерского потенциала экземпляр. Неплохим потенциалом обладает Core 2 Duo Е6400.
Оперативная память с низкой частотой работы может стать ограничивающим фактором при попытке полного раскрытия возможностей процессора. Идеально подходят для разгона дорогие оверклокерские модули от именитых брендов, однако даже среди самых дешевых предложений попадаются экземпляры на хороших чипах, обладающие схожим потенциалом. Основной критерий правильного выбора, если нет возможности проверить ОЗУ на практике, – поиск нужной информации по той или иной линейке продуктов в Сети.
Система охлаждения процессора зачастую определяет максимальный предел повышения частоты в заданных условиях. Правда, при умеренном форсировании режима работы CPU (например, разгоне Core 2 Duo до 3–3,3 GHz) и незначительном поднятии питающего напряжения вполне достаточно и боксового кулера, ну а при попытке выжать побольше штатной СО не обойтись.
Температура чипсета материнской платы и силовых транзисторов. Стоит проверить и ее, в случае необходимости смените штатную СО. Простой вариант проверить температуру – во время работы ПК дотронуться до радиаторов рукой. Они могут быть горячими, но не обжигать.
Блок питания обеспечивает стабильное функционирование всей системы. При его недостаточной мощности/некачественной компонентной базе/высоком уровне энергопотребления всех компонентов о серьезном оверклокинге приходится забыть или же искать достойную замену. Большинству энтузиастов даже с учетом растущих требований по питанию графических адаптеров в ближайшие годы вполне хватит БП мощностью 500–600 Вт от именитого производителя. Однако примерный уровень энергопотребления и, соответственно, модель устройства, подбираются индивидуально. Не раз БП становились проблемой в системе, когда компьютер то перезагружался, то вообще не включался. Проблемы с БП, могут носить симптомы неправильной работы любых компонентов системы. Поэтому на БП экономить не стоит, тем более что при разгоне, он может понести большую нагрузку.
Разгон процессора. Программы
Пользователю, желающему научиться разгонять процессоры, следует обзавестись диагностическими и тестовыми программами.Мне очень удобно использовать СPU-Z и Lavalys Everest Ultimate. Новичку в этом деле будет довольно легко освоить программу СPU-Z. СPU-Z. Программа предназначена для отображения информации о процессоре, материнской плате и оперативной памяти. С помощью утилиты CPU-Z можно узнать:- Название процессора, модель и его производитель.- Поддерживаемые CPU наборы инструкций и спецификации.- Напряжение питания.- Размер, скорость, технологию, местонахождение кэша L1, L2, L3.- BIOS, чипсет, память, параметры AGP материнской платы.- Размер, тип, временные характеристики и спецификацию установленной оперативной памяти. Программа точно определяет основные характеристики процессора: наименование(Name), тип ядра (Code Name) и степпинг (Stepping), используемый разъем (Package), поддержку тех или иных мультимедийных инструкций (Instructions), объем и параметры кэш-памяти (Cache). CPU-Z предоставляет данные о текущих режимах работы: частоты процессора (Core Speed) и шины (BusSpeed), множитель (Multiplier), питающее напряжение (Voltage). Имеется информация об объеме и текущем режиме работы ОЗУ, содержимом SPD-блоков модулей памяти. Дополнительно – базовые сведения о материнской плате и отдельный бенчмарк латентности памяти.
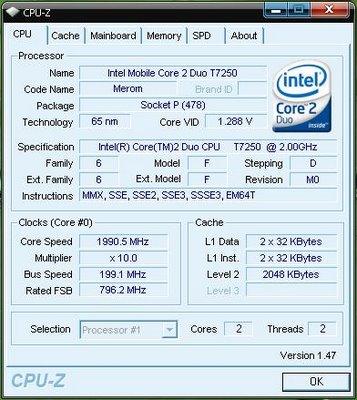
Возможности Lavalys Everest Ultimate
Список заявленных возможностей у программы Everest, даже у бесплатной версии, внушительный:
-более 40 информационных модулей;
-база данных по 38 тыс. устройств;
-полная информация о тактовых частотах– как исходных, так и текущих, установленных средствами разгона;
-база данных ссылок на сайты производителей устройств, на информационные сайты с тестами, драйверами;
-три встроенных бенчмарка для подсистемы памяти;
-серьезный генератор отчетов;
-возможность подключения плагинов;
-поддержка 30 языков в интерфейсе.
Программа позволяет получить следующую полезную информацию:
-производитель чипсет, если возможно – модель материнской платы; -тактовые частоты процессора, памяти, системных шин; -названия, параметры работы всех системных и периферийных устройств; -расширенная информация о процессоре, памяти, жестких дисках, 3D-ускорителе; -разнообразные параметры программной среды: ОС, драйверы, процессы, системные файлы и т.д.;
-информация о поддержке видеокартой возможностей OpenGL и DirectX. Следует заметить, что Everest на данный момент совместима только с операционными системами Microsoft серий Windows. Поддержка ОС типа Unix/Linux, ОС для мобильных устройств и карманных компьютеров не реализована. Ценность Everest Собственно, перечисленные выше возможности в том или ином виде присутствуют практически у всех информационных программ. В чем же тогда ценность Everest?
И дело не столько в том, что Everest способна выдать огромный объем всевозможной информации. Программа Sandra, а также другие конкуренты тоже собирают немало сведений о системе, тоже анализируют программную среду, тоже имеют коллекцию ссылок и базу данных. Однако у Everest есть ряд положительных черт, самая важная из которых, на мой взгляд – разделение информации по способу ее получения. Everest не смешивает данные, считанные программой из портов и конфигурационных регистров устройств напрямую, прочитанные из системного реестра, найденные базе данных и полученные из пула DMI. Данные из разных источников отличаются разной степенью достоверности, детальности, актуальности и т.д. Everest не отбрасывает одну информацию в пользу другой, которую считает более достоверной. Напротив, информация из разных источников собирается в разных подпунктах. Второй плюс Everest – минимум пустой и малозначительной информации. Почти все сведения даются лаконично, отмечено самое существенное и важное, перечисление малопонятных режимов и параметров практически исключены. Скажем, о 3D-ускорителе Everest сообщит название и кодовое имя чипа, частоту, объем и частоту памяти, ширину шины памяти, количество пиксельных и вершинных процессоров, поддержку шейдеров, технологию производства, теоретические данные по fillrate и другие полезные сведения. Информацией о поддержке прорисовки линий, дуг, окружностей, разных видов закраски и копирования блоков и т.п. он вас нагружать не будет, так как возможности ускорения 2D давно поддерживаются всеми видеокартами.Интерфейс программы – тоже большой плюс. Минимум ненужной графики, удобная древовидная структура, обновление некоторых параметров «на лету», ряд полезных настроек – дизайн программы производит положительное впечатление. При том Everest в базовой версии не претендует на роль программы-твикера, не содержит так называемых «диагностических» модулей, реальная ценность которых сомнительна.
Intel запатентовала защиту от разгона
Компания Intel получила патент на технологию защиты процессоров от несанкционированного разгона. Заявка на патент была подана 29 сентября 1999 г., а положительное решение о выдаче патента за номером 6,535,988 было принято 18 марта 2003 г. В патенте описываются принципы работы новой системы защиты от разгона и несколько вариантов ее практического воплощения Система защиты от разгона состоит из нескольких микросхем. Принцип ее действия основан на сравнении текущей рабочей частоты процессора, которую можно менять в достаточно широких пределах, с частотой эталонного тактового генератора, которую изменить значительно сложнее. Помимо генератора эталонных тактовых импульсов, схема включает чип, сравнивающий рабочую частоту процессора с эталонной и, в зависимости от результатов сравнения, выдающий определенный сигнал. Этот сигнал поступает на другой чип, который в случае, если процессор разогнан, принудительно отключает или замедляет его. В патенте описывается несколько вариантов работы системы. В одном случае, отключение процессора достигается за счет отключения его питания, в другом — за счет прекращения подачи на него импульсов от тактового генератора. Всего в патенте описано восемь схем системы защиты от разгона процессоров. Одной из причин, побудивших Intel разработать систему защиты от разгона, стали случаи перемаркировки процессоров недобросовестными дилерами и производителями компьютеров. Не секрет, что производители чипов часто маркируют их заниженными частотами. Купив такие чипы по дешевке, дилеры могли перемаркировать их, и продать как более быстрые. Кроме того, в Intel не одобряют разгон процессоров, так как он может приводить к их нестабильной работе. К настоящему времени Intel справилась с проблемой перемаркировки процессоров, аппаратно заблокировав множитель, показывающий, во сколько раз внутренняя частота процессора выше частоты системной шины. Однако разгон процессора путем увеличения частоты системной шины остается возможным. Этот способ не подходит для массовой перемаркировки процессоров: его можно использовать только с уже готовым компьютером. Захочет ли Intel с помощью этой технологии бороться с энтузиастами разгона, покажет время.
Разгон процессора. Что еще нужно знать
Путем разгона можно получить прирост производительности в 10-50% (иногда и более). Если ваш компьютер работает в целом неплохо, но количество кадров в секунду в новой игре у вас 25-30, то тут может помочь разгон. С его помощью можно будет выбить, предположим, нормальные 30-40 кадров (возможно придётся в добавок и видеокарту разогнать немного).
Зависимость разгона от технологии изготовления (0.18мкм, 0.13мкм и. т. п.).
Чем меньше технология, тем меньше размеры самого кристалла и его энергопотребление. Следовательно, ниже тепловыделение. Этот параметр представлен в микрометрах: чем меньше число, тем лучше будут разгонные качества данного ядра (а, значит, и самого процессора). Нужно помнить, что если производитель уже довел частоту ядра изготовленного по какой-то технологии почти до верхней границы, то разогнать процессор будет сложно. К примеру, Celeron (ядро Mendocino) 333Mhz часто разгоняется аж до 600 МГц, а Celeron 533Mhz (то же ядро) разогнать получается часто только до 600Mhz - эта частота фактически предел для ядра.
По шине процессор эффективнее разгонять, так как разгоняются при этом память и шина AGP (шина видеокарты). Следовательно, повышается пропускная способность всех этих шин, а это очень полезно. Но если вы хотите минимизировать возможные последствия от разгона, то можете ограничиться повышением коэффициента, если есть такая возможность (процессоры Intel её не имеют).
Не стоит разгонять ноутбуки. Просто в ноутбуке затруднено охлаждение и все очень точно подогнано под какой-то более-менее определённый процессор. Возможности разгона чаще всего очень малы, а могут и вообще отсутствовать. Надо помнить, что при разгоне увеличивается потребляемая мощность и тепловыделение процессора, а следовательно у ноутбука сокращается срок работы от батарей и увеличивается температура.
Стоит брать память известных производителей, она дороже, но стабильнее при разгоне. Наиболее удачными и популярными являются модули Kingston, Infineon, Hyundai (Hynix), Samsung и др. Если есть возможность, лучше поставить память с запасом, т. е. на плату, в штатном режиме работающую с памятью на 333Mhz, взять память, которая держит 400Mhz. Это даст гарантию отсутствия ошибок при разгоне памяти до данной частоты. Ну и любителям форсировать свою систему стоит подумать о том, чтоб обзавестись оверклокерской памятью. Очень не рекомендуется повышать напряжение более чем на 25%, это может быть фатально для процессора. А лучше ограничится 10-15%. Смысл в этом часто есть: повышается стабильность работы и открывается возможность разогнать побольше.
При разгоне естественно температура будет увеличиваться, даже если вы не будете поднимать напряжение. Вообще рекомендуется поставить какую либо программу мониторинга температуры. Лучше родную (поставляющуюся с материнской платой), но можно и какую-либо универсальную вроде MBProbe, Motherboard Monitor и др. А если в биосе есть функция отключения / предупреждения при превышении какой-то температуры, то лучше ей воспользоваться - установить 70 градусов в качестве такой температуры, например. Сколько ватт мощности потребляет ваш процессор (чем больше - тем больше греется) можно посмотреть например при помощи программы Everest она так же показывает температуру процессора и материнской платы и винчестера и т. д. (при условии наличия термодатчиков).
Нужен при нормальном форсировании и хороший кулер с удачным алюминиевым радиатором. Кулеры с медными радиаторами могут быть значительно лучше из-за лучшей теплопроводности меди, но они иногда сильно хуже по причине непродуманной конструкции. Из фирм-производителей можно посоветовать Thermaltake, Titan, CoolerMaster, Zalman(показывает очень хорошие результаты в тестированиях). Так называемый NoName лучше не брать: процессор может сильно пострадать из-за остановившегося, или просто плохого кулера. Стоит так же отметить, что бежать в магазин и менять боксовый кулер от процессора на самый крутой не всегда нужно, он не так плох. Ну а если вам его недостаточно, то можно и сменить. Можно применять так же жидкий азот(любителям поставить рекорд разгона, но при этом нужна довольно серьезная модификация материнской платы, требует хороших знаний и желания повесить материнскую плату на стенку, в качестве трофея, после успешного эксперимента), водяное охлаждение и некоторые другие методы. Первое вообще не реально в наших условиях. Второй вариант более реален, но требует самостоятельного изготовления системы охлаждения или покупки её за весьма немалые деньги (не менее 100$). Причём это не самый надёжный способ: если что-то протечёт, почти гарантирован выход чего-нибудь из строя. А если остановится кулер, то пострадает только процессор (ну, в худшем случае ещё и материнская плата). Но ничего лучше водяного охлаждения для экстремального разгона в домашних условиях пока не придумали. Естественно большое значение имеет корпус. Нужно брать корпус с горизонтально расположенным блоком питания и наибольшим количеством мест под дополнительные вентиляторы.
После разгона. Лучше всего запустить какое-то приложение типа 3Dmark на парочку часов. Если после длительного прогона тестов ошибок не возникло, то все, скорее всего, удачно. Можно поэкспериментировать с архивацией и последующей разархивацией больших объёмов данных (>=500Mb) при помощи WinRAR. Если появились ошибки в контрольной сумме (CRC error), то нужно выяснять источник ошибки. Им может быть процессор, память, а иногда материнская плата. Так же есть полезная программа под названием CPU Stability Test, её нужно запустить надолго и если не повиснет, значит с процессором все OK. Память стоит отдельно проверить программой вроде TestMem под DOS.
Последствия неудачного разгона. В первую очередь процессор - он может сгореть. Ну и, естественно, сокращается срок службы всех комплектующих, подвергающихся разгону. На штатной частоте процессор служит в теории где-то 10 лет, а на повышенной меньше. Но сейчас это не актуально, так как больше 5 лет процессор обычно и не используется (он безнадёжно устаревает за это время, так что о этом не волнуемся. Оперативная память не особо страдает от разгона, но часто является источником ошибок. Пострадать может винчестер, но уже сразу по двум причинам: на него может повлиять понижение/повышение напряжения, выдаваемого слабым блоком питания, или он может не выдержать повышения шины PCI (частоты больше 40Mhz нежелательны). Действие первой причины я имел счастье сам наблюдать у моего старого винчестера, он угробился от нехватки питания всего за пол года (Samsung, отработал без ошибок 4 года). Некоторые модели IDE-дисков, поддерживающие Ultra DMA, чувствительны к частоте шины PCI и при выставлении нестандартных частот иногда возможна потеря данных. При этом сам жесткий диск как правило остается работоспособным, однако в некоторых случаях могут пострадать сервометки, после чего винчестер будет проще выбросить, чем пытаться исправить (вероятность этого невелика). Избежать подобных проблем обычно можно изменением режима работы винчестера - заставив его работать исключительно в PIO режиме. Но это не рекомендуется, система будет хуже работать - дополнительная нагрузка на процессор делает почти бессмысленным разгон в этом случае. Так что если разгоняете сильно, то запаситесь БП с запасом мощности (300W) и будьте осторожны с повышением шины PCI. Выход из строя видеокарты и других плат от повышения частот работы их шины (что пока почти неизбежно при разгоне системной шины) маловероятен, но возможен. Могут быть попорчены ваши программы, которые вы будете запускать для тестирования. Иногда от неудачной попытки разгона перестаёт загружаться Windows, в случае если важные файлы были повреждены из-за ошибок процессора. Решить эту проблему можно в большинстве случаев только переустановкой ОС (или при помощи функции "repair" в Setup`е, если у вас Win2K/XP).
Процессор сгорел? Стоит убедиться, что дело именно в процессоре. Если из корпуса идёт дым и пахнет палёным, возможно так и есть. Но если компьютер просто не загружает Windows, выводится только заставка BIOS или он пищит (в случае отказа / отсутствия процессора компьютер не пищит), то причина в другом. Например, в контроллере IDE или видеокарте. Стоит попробовать вытащить из разъемов на материнской плате шлейфы жестких дисков и CD-ROM, а также все платы. Следует помнить, что некоторые экземпляры могут просто не запуститься на той частоте FSB, которую вы поставили. В таком случае нужно снизить разгон. Тогда может помочь обнуление настроек BIOS (если разгоняли с его помощью), его можно осуществить воспользовавшись соответствующим джампером на материнской плате (на всех современных платах он присутствует) или временным отключением батарейки (еcли джампера все же нет). Все настройки при этом примут изначальное положение.
FPU, Ядро,Степпинг
FPU, это Floating Point Unit.
А проще говоря, блок, производящий операции с плавающей точкой (часто говорят запятой) или математический сопроцессор. FPU помогает основному процессору выполнять математические операции над вещественными числами. Здесь следует уточнить, что сначала он применялся опционально, в качестве дополнительного процессора. Непосредственно в кристалл процессора FPU был впервые интегрирован в 1989 году (процессор Intel 80486).
Ядро. Ядром называют сам процессорный кристалл, ту часть, которая непосредственно является "процессором". Сам кристалл у современных моделей имеет небольшие размеры, а размеры готового процессора увеличиваются очень сильно за счет его корпусировки и разводки. Процессорный кристалл можно увидеть, например, у процессоров Athlon, у них он не закрыт. У P4 вся верхняя часть скрыта под теплорассеивателем (который так же выполняет защитную функцию, сам по себе кристалл не так уж прочен). Процессоры, основанные на разных ядрах, это можно сказать разные процессоры, они могут отличаться по размеру кэш памяти, частоте шины, технологии изготовления и т. п. В большинстве случаев, чем новее ядро, тем лучше процессор разгоняется. В качестве примера можно привести P4, существуют два ядра - Willamette и Northwood. Первое ядро производилось по 0.18мкм технологии и работало исключительно на 400Mhz шине. Самые младшие модели имели частоту 1.3Ghz, максимальные частоты для ядра находились немного выше 2,2Ghz. Своими разгонными качествами эти процессоры особо не славились. Позже был выпущен Northwood. Он уже был выполнен по 0.13мкм технологии и поддерживал шину в 400 и 533Mhz, а также имел увеличенный объём кэш памяти. Переход на новое ядро позволил значительно увеличить производительность и максимальную частоту работы. Младшие процессоры Northwood прекрасно разгоняются, но фактически разгонный потенциал этих процессоров основан на более "тонком" техпроцессе.
Степпинг означает поколение ядра процессора. При исправлении мелких недочетов или ошибок в микрокоде выпускается новая модификация, или поколение, процессорного ядра при этом сохраняются архитектура кристалла и сама технология производства в целом. По логике, чем больше степпинг, тем стабильнее себя ведет и лучше разгоняется процессор.
Платформы 2008-2009 Intel
Будущее мобильных платформ AMD, которое обещает стать высокоинтегрированным вплоть до размещения на одном кристалле вычислительных и графических ядер. Компания, кстати, вводит новый термин для обозначения подобных процессоров – APU (Accelerated Processing Unit). Это означает, что интегрироваться на кристалл с процессором будет не только графическое ядро, но и любой другой специализированный ускоритель. Директор по технологиям Intel Патрик Гелсингер в рамках краткой пресс-конференции 18 марта рассказал о планах корпорации по выпуску новых многоядерных процессоров. В основном речь шла о 4- и 6-ядерных серверных и настольных процессорах. Он сообщил, что во второй половине текущего года на рынке появятся серверные процессоры Xeon с кодовым названием Dunnington. Эти чипы будут изготавливаться по 45-нанометровой технологии, иметь шесть ядер и общий кэш третьего уровня большого размера (по имеющейся информации, 16 Мб). Благодаря поддержке системы FlexMigration, серверы на основе процессоров Dunnington можно будет добавлять в единую динамическую виртуальную инфраструктуру, поддерживающую миграцию виртуальных машин. Далее Патрик Гелсингер остановился на будущих серверных чипах Itanium, известных под названием Tukwila. Ожидается, что Tukwila станет первым процессором на рынке, насчитывающим более двух миллиардов транзисторов. Чип получит четыре ядра и будет работать на тактовой частоте до 2 ГГц, а объем кэш-памяти составит 30 Мб. При таких характеристиках Tukwila будет потреблять примерно на 25% больше энергии по сравнению со своим предшественником - чипом Montvale.
Важным этапом в развитии аппаратных платформ Intel, по словам Гелсингера, станет появление новой архитектуры Nehalem. В Intel отмечают, что переход на архитектуру Nehalem позволит добиться значительного повышения производительности при одновременном снижении энергопотребления. Платформа Nehalem будет использовать новую системную архитектуру QuickPath Interconnect, включающую встроенный контроллер памяти и усовершенствованные каналы связи между компонентами. Процессоры на основе Nehalem получат от двух до восьми ядер и благодаря технологии Simultaneous Multi-threading смогут одновременно обрабатывать от четырех до шестнадцати потоков инструкций. Объем кэш-памяти третьего уровня сможет достигать 8 Мб.
Подробнее о настольных системах и Nehalem
Процессоры Nehalem придут на смену Penryn. Они будут выпускаться по 45- нм техпроцессу и, как говорят источники, возможно, поступят в продажу под маркетинговым названием Core 3. Nehalem имеет несколько модификаций: Nehalem-EP/EN/EX. Появление на рынке Nehalem-EP ожидается во второй половине следующего года. В состав новой платформы Intel будет входить также чипсет с кодовым именем Tylerburg.Индекс EP расшифровывается как Efficient Performance (эффективная производительность), такие процессоры будут использоваться в одно- и двухпроцессорных системах с низким энергопотреблением. EN (Entry) - индекс, обозначающий принадлежность процессора к начальному уровню в линейке, EX (Expandable) к процессорам, которые могут быть использованы в системах с количеством CPU до 32-х .Следующее за Yorkfield поколение процессоров носит кодовое имя Bloomfield. Yorkfield является частью архитектуры Penryn, отличающейся от нынешней Core, главным образом, используемым техпроцессом - 45 нм. Bloomfield же будет построен на обновленной архитектуре Nehalem, использующей тот же техпроцесс, но имеющей существенные отличия. Среди них - интегрированный в процессор контроллер памяти и обновленная версия HyperThreading, позволяющая четырём ядрам таких процессоров обрабатывать 8 потоков одновременно. Они будут использовать 1366-контактный разъём Socket B.Gainstown - новое кодовое имя процессоров Nehalem. Они будут предназначены для высокопроизводительных настольных систем. В числе ключевых особенностей Bloomfield и Gainstown - 8 Мб кэш-памяти третьего уровня и наличие встроенного контроллера памяти, поддерживающего трёхканальные(!) конфигурации DDR3, работающей на частоте 1333 МГц. Gainstown вместе с чипсетами Tylersburg будут использоваться в высокопроизводительных двухпроцессорных настольных системах. Соединение наборов системной логики и процессоров будет происходить по шине QuickPath Interconnect (QPI) по схеме: каждый процессор с одним из чипсетов, процессоры между собою и чипсеты между собою. Tylersburg, в свою очередь будет поддерживать до 36 линий PCI Express 2.0, за счет чего в одной системе может быть реализовано до четырёх интерфейсов PCIe x16 и пара - PCIe x4.Bloomfield же будет позиционироваться в сегмент однопроцессорных систем высокой производительности. И Gainstown и Bloomfield будут выпускаться в разъёме LGA1366, а значит, долгожитель LGA755 начнет собираться на покой в четвертом квартале следующего года. Термальный пакет у первых Nehalem будет составлять 130 Вт -столько же, сколько и у нынешних флагманских CPU Intel.

Фотографии инженерного образца процессора Intel Nehalem были размещены недавно на сайте Xtremesystems. На фото Nehalem-EP находится слева, а справа — Intel Core 2 Extreme QX9770. Обратим внимание на изменившуюся форму контактных площадок: Материнская плата Gigabyte 7TESN-RN с двумя сокетами LGA1366 для этого процессора, оборудованная 12 разъёмами DDR3-памяти (по шесть на каждый CPU):

В операциях с плавающей точкой Nehalem вдвое, а в целочисленных операция в полтора раза быстрее, чем Xeon X5482 (Harpertown). Одной из причин такого прироста производительности является применение 3-канального контроллера DDR3-памяти (на каждый процессор), благодаря чему пропускная способность шины памяти перестанет быть «бутылочным горлышком». Кроме того, использование технологии SMT (Symmetric Multi-Threading, симметричная многопоточность) позволит Nehalem обрабатывать одновременно 8 потоков. Патрик Гелсингер также отметил, что процессоры Intel следующего поколения будут поддерживать новый набор векторных инструкций AVX (Advanced Vector Extensions), которые позволят ускорить выполнение операций с плавающей запятой. Кроме того, Гелсингер заметил, что позднее в этом году Intel планирует показать чип, разрабатывающийся в рамках проекта Larrabee. Инициатива Larrabee предполагает создание многоядерного процессора, построенного на основе усовершенствованной архитектуры х86. Первые версии чипа, предположительно, будут насчитывать от 16 до 24 ядер, и работать на тактовой частоте около 2 ГГц.Intel, по неофициальной информации, выпустит свой первый четырехядерный процессор для ноутбуков в третьем квартале. По крайней мере, об этом сообщает DigiTimes со ссылкой на источники среди производителей материнских плат.Первым чипом Intel с четырьмя ядрами станет модель Core 2 Extreme QX9300. Этот процессор будет производиться по 45-нанометровой технологии и работать на тактовой частоте в 2,53 ГГц при частоте системной шины 1066 МГц. Объем кэш-памяти второго уровня составит 12 Мб, а максимальное значение рассеиваемой тепловой энергии (TDP) для модели Core 2 Extreme QX9300 будет равно 45 Вт. Процессор Core 2 Extreme QX9300 войдет в линейку чипов для новой мобильной платформы Intel Centrino 2 (кодовое название Montevina). Первые процессоры для этой платформы, как ожидается, будут выпущены в июне. По слухам, Intel представит более десяти чипов с частотами от 1,2 до 2,8 ГГц. Максимальное значение рассеиваемой тепловой энергии новых процессоров, в зависимости от модификации, будет варьироваться между 5,5 и 45 Вт.Помимо процессоров Intel, как ожидается, выпустит для аппаратной платформы Centrino 2 три набора системной логики с обозначениями GM45, GM47 и PM45. Чипсеты GM45/47 будут поддерживать процессоры с частотой системной шины 667 МГц и 1066 МГц, память DDR2/DDR3, а также получат интегрированный графический контроллер. Что касается набора логики PM45, то у него встроенного графического ядра не будет. Помимо этого, в начале марта Intel официально представила новое семейство процессоров Atom, предназначенных для использования в так называемых мобильных интернет-устройствах (MID) и недорогих компьютерах. В линейку Atom на начальном этапе войдут чипы, ранее известные под кодовыми именами Silverthorne и Diamondville. Процессоры Silverthorne станут одной из основных составляющих аппаратной платформы Intel Menlow для ультрапортативных компьютеров (UMPC). Чипы Silverthorne будут производиться по 45-нанометровой технологии, иметь площадь всего 25 мм2 и насчитывать 47 миллионов транзисторов. Intel называет процессор Silverthorne самым маленьким чипом (с архитектурой х86), который корпорация создавала за последние 15-17 лет. Что касается Diamondville, то этот процессор будет построен на основе ядра Silverthorne и найдет применение, преимущественно, в дешевых портативных компьютерах с небольшим энергопотреблением. Intel отмечает, что максимальное значение рассеиваемой тепловой энергии (TDP) для процессоров линейки Atom составит от 0,6 до 2,5 Вт. Работать чипы будут на тактовой частоте до 1,8 ГГц. Не исключено, что в перспективе Atom найдут применение в устройствах бытовой электроники, тонких клиентах и встраиваемой технике. Вместе с чипами Atom корпорация Intel представила новую торговую марку Centrino Atom, под которой на рынок поступит аппаратная платформа Menlow. В состав этой платформы, помимо процессора Atom, войдут чипсет с интегрированным графическим адаптером и контроллер беспроводной связи. Устройства на основе аппаратной платформы Centrino Atom должны поступить в продажу в текущем году. Между тем, в рамках выставки Computex Taipei 2008, которая будет проходить в период с 3 по 7 июня, Intel намерена показать платформу Montevina для портативных компьютеров. На рынке данная платформа будет продвигаться под торговой маркой Centrino 2.В июне Intel намерена представить более десяти процессоров и несколько наборов системной логики для мобильной платформы Centrino 2 (кодовое название Montevina). При этом, как ожидается, в продажу поступят мобильные чипы Core 2 Duo стандартного форм-фактора, а также процессоры уменьшенного размера для тонких и легких ноутбуков.
Семейство чипов Core 2 Duo стандартного форм-фактора пополнится пятью двуядерными моделями - P8400, P8600, P9500, T9400 и T9600. Все процессоры будут производиться по 45-нанометровой технологии, и иметь частоту системной шины 1066 МГц. Тактовая частота чипов составит от 2,26 ГГц до 2,8 ГГц, объем кэш-памяти второго уровня - от 3 Мб до 6 Мб. Максимальное значение рассеиваемой тепловой энергии (TDP) для моделей с буквой “Р” в обозначении составит 25 Вт, для чипов с буквой “Т” в названии - 35 Вт. Поставляться процессоры будут по цене от 209 до 530 долларов в оптовых партиях. В линейку чипов уменьшенного размера на начальном этапе войдут модели Core 2 Duo U3300, SU9300, SU9400, SL9300, SL9400, SP9300 и SP9400. Частота чипов с обозначениями U3300 и SU9300 составит 1,2 ГГц, значение TDP - 5,5 Вт и 10Вт, соответственно. Модель SU9400 будет обладать схожими с SU9300 характеристиками, но работать на частоте в 1,4 ГГц. Частоты чипов SL9300, SL9400, SP9300 и SP9400 составят от 1,6 ГГц до 2,4 ГГц. Максимальное значение рассеиваемой тепловой энергии будет равно 17 Вт для моделей SL9300 и SL9400 и 25 Вт - для процессоров SP9300 и SP9400. Стоимость чипов, в зависимости от модификации, составит от 262 до 316 долларов в крупнооптовых партиях. Помимо процессоров Intel, как ожидается, выпустит три набора системной логики с обозначениями GM45, GM47 и PM45. Чипсеты GM45/47 будут поддерживать процессоры с частотой системной шины 667 МГц и 1066 МГц, память DDR2/DDR3, а также получат интегрированный графический контроллер. Что касается набора логики PM45, то у него встроенного графического ядра не будет.
О серверных прцессорах Xeon и Itanium нового поколения. В Интернете появилась неофициальная информация о планах корпорации Intel по выпуску новых серверных процессоров Xeon с кодовым названием Dunnington. Чипы Dunnington получат не четыре, как раньше сообщалось, а шесть ядер на основе микроархитектуры Core (класса Penryn). Каждые пара ядер будет иметь 3 Мб кэш-памяти второго уровня, кроме того, у Dunnington будет общий кэш третьего уровня размером в 16 Мб. При производстве процессоров Dunnington будет применяться 45-нанометровая технология, максимальное значение рассеиваемой тепловой энергии (TDP) для новых чипов Xeon не должно превысить 130 Вт.В конце текущего года Intel планирует начать поставки новых серверных процессоров Itanium с кодовым названием Tukwila. Tukwila станет первым чипом на рынке, насчитывающим более двух миллиардов транзисторов. Процессор получит четыре ядра и будет работать на тактовой частоте до 2 ГГц, а объем кэш-памяти составит 30 Мб. Отмечается, что при таких характеристиках Tukwila будет потреблять примерно на 25% больше энергии по сравнению со своим предшественником - чипом Montvale.При изготовлении новых серверных процессоров Itanium корпорация Intel планирует использовать 65-нанометровую технологию, а не более “тонкий” 45-нанометровый техпроцесс. Впрочем, последователь Itanium, чип с кодовым названием Poulson, будет изготавливаться уже по 32-нанометровой методике. Правда, ожидать появления Poulson на рынке стоит лишь в 2010-2011 годах. Кроме того, технического директора Intel Джастин Раттнер рассказал о новых процессорах с кодовым названием Silverthorne, которые станут одной из основных составляющих аппаратной платформы Intel Menlow для ультрапортативных компьютеров (UMPC). Раттнер назвал Silverthorne самым маленьким чипом (с архитектурой х86), который корпорация Intel создавала за последние 15-17 лет. Процессоры Silverthorne будут производиться по 45-нанометровой технологии, и работать на тактовой частоте до 2 ГГц при частоте системной шины 533 МГц. Энергопотребление Silverthorne не превысит 2 Вт.Intel демонстрирует процессоры Tukwila и Silverthorne на Международной конференции по твердотельным схемам ISSCC 2008 (International Solid State Circuits Conference), которая в эти дни проходит в Сан-Франциско (Калифорния, США).И, наконец можно кое-что сказать о будущем техпроцессов для производства чипов. Стратегия, получившая название Tick Tock, оказалась для Intel весьма успешной. Ее суть заключается в том, что каждый четный год компания представляет новую архитектуру, а каждый нечетный — уменьшает ее до следующих норм техпроцесса. Начало было положено выпуском 65-нм архитектуры (Core), которая недавно была «сжата» до 45 нм (Penryn). В четвертом квартале Intel представит другой 45-нм продукт (Nehalem), который в 2009 году уступит место своей «сжатой» до 32-нм версии (Westmere). В свою очередь, 32-нм Sandy Bridge выйдет в 2010. На этой отметке заканчивались ранее опубликованные «роадмэпы». На слайде, оказавшемся в распоряжении источника, видно еще два продукта — пока не имеющие имен 22-нм процессоры. Один из них появится на рынке в 2011 году, и будет представлять собой «сжатый» вариант Sandy Bridge, второй, также 22-нм, будет построен на новой архитектуре и выйдет в 2012 году. Указанные сроки вполне согласуются со сроками, обозначенными в планах Intel по освоению технологии EUV в производстве 22-нм логических чипов.
Платформы 2008-2009 AMD
В начале 2009 года, если верить слайду, а на самом деле, согласно документам AMD, лишь к его середине платформу Puma сменит платформа Shrike (сорокопут, хищная такая птичка). Для платформы Shrike предусмотрен 45-нм процессор Swift (стриж, летает со скоростью до 100 км/ч). Процессор Swift будет представлять собой размещённые на общем кристалле два или три вычислительных ядра и ядро графического процессора. Концепция Fusion, таким образом, упростится до перевода внешнего интерфейса на внутренний. Никакой специальной интеграции для графического ядра не будет. Прирост быстродействия AMD надеется получить за счёт сокращения длин соединительных проводников (паразитных ёмкостей и т.п.).

Отдельно стоит отметить появление в составе платформы Shrike модулей UWB, хотя компания продолжает упорно игнорировать WiMAX. А ведь у последнего перспектив побольше будет.
Серверы и рабочие станции
Не сейчас и не в следующем году, но на рынке рабочих станций и серверов всё же появятся платформы AMD. Как сегодня 65-нм Opteron "Barcelona" комплектуются чипсетами NVIDIA и Broadcom, так в середине следующего и в начале 2009 года ими же будут комплектоваться 45-нм процессоры Shanghai. Начиная со второго квартала 2009 года AMD перейдёт на собственный чипсет RD8xx и можно будет говорить о единой платформе компании, хотя имя у неё всё ещё нет:
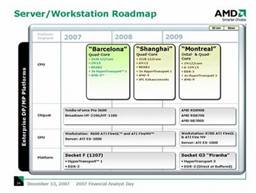
В состав "Платформы 2009" войдут четырёх- и восьмиядерные 45-нм процессоры под кодовым именем "Montreal". Эти решения будут иметь по 1 МБ кэш-памяти второго уровня на ядро и 6 или 12 МБ кэш-памяти третьего уровня. Заявляется не только о поддержке регистровой памяти DDR3, но и обычной небуферизированной. В качестве сокета процессоров Montreal компанией предложен Socket G3 с кодовым именем "Piranha".Системный чипсет серверной платформы представлен будет северными мостами RD890S и RD870S, а также южным мостом SB700S. Графическая составляющая рабочих станций будет основана на FireGL-версиях ATI R7xx, а серверов – ATI ES-1000.ОфисныеВ данном случае компания пошла по проверенному её соперницей пути и планирует представить нечто похожее на платформу Intel vPro. На первых порах, впрочем, AMD не имеет возможности выпустить специальным образом доработанный системный чипсет, как это для ниши корпоративных систем сделала Intel. Чипсеты Intel с индексом Q (965Q, Q35 и т.д.), напомним, поддерживают Trust-модули для организации доверенных вычислений и технологию удалённого администрирования AMT, как и несколько других уникальных технологий. В будущем AMD планирует выпустить аналогичное решение. По всей видимости, сейчас оно скрывается под названием SB700+. Но мы забегаем вперёд. Начнём с того, что в первом квартале 2008 года AMD представит первую корпоративную платформу под кодовым именем Perseus. Офисные платформы AMD. Планы на 2008-2009 годы. "Персей" объединит в себе все 65-нм процессоры архитектуры K10 с упором на трёхядерные Toliman и двухядерные Kuma, интегрированный чипсет RS780 с южным мостом SB700 и опционально видеокарты поколения R6xx. В последнем случае гарантируется включение режима Hybrid Graphics – совместная работа интегрированного и дискретного видеоядер. По предварительным тестам, кстати, на младших решениях эффект прироста производительности от Hybrid Graphics достигает 40%.Пока всё вышеперечисленное один в один совпадает с описанием массовой домашней платформы Cartwheel (см. новость выше). Теперь о различиях. Платформа Perseus будет поддерживать две уникальных технологии: DASH – открытый аналог технологии Intel AMT (Advanced Management Technology) разрабатываемый группой DMTF (Distributed Management Task Force) индустриального альянса DMWG (Desktop Mobile Work Group); и Trusted Platform Module – модули и расширения одноимённой индустриальной группы занимающейся безопасными вычислениями.
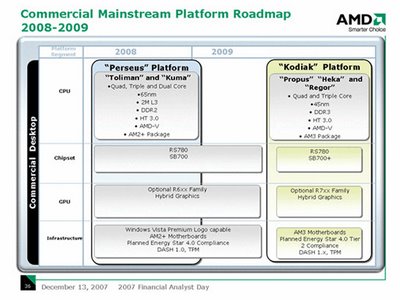
Ещё одним отличием от домашней платформы станет несколько больший срок рыночной жизни Perseus. Второе поколение корпоративной платформы сменит своего предшественника через полтора года – в середине 2009 нас ждёт выход платформы Kodiak. Это уже "география", хотя у меня слово Кодиак прочно ассоциируется с большими генномодифицированными медведями, так в своё время повлиял замечательный рассказ "Исследовательский отряд" Лейнстера Мюррея (Leinster Murray). Это была, пожалуй, первая опубликованная в советской прессе боевая фантастика (сборник "На суше и на море" за 1960 год). Платформа Kodiak пересядет на 45-нм процессоры AMD с акцентом на трёхядерные Heka и двухядерные Propus и Regor. Здесь у компании снова неувязка. Ниже на слайде мы видим отсутствие в списке двухядерных решений. Только четырёхядерные и трёхядерные. Интегрированный северный мост RS780 получит обновлённый южный мост SB700+, хотя к этому времени у компании будет мост SB800 (см. новость о платформе для энтузиастов). Можно предположить, мост с "плюсом" вберёт в себя контроллер для работы с TPM-модулями и будет хранить ключи шифрования, как и поддерживать технологию управления ресурсами ПК. Офисные платформы AMD также войдут в ряды борцов с парниковым эффектом – все они поддержат спецификации Energy Star 4.0.
Настольная платформа для энтузиастов одной из первых появилась в планах AMD. Формировалась она серией "первых блинов" в виде двухпроцессорных решений 4x4, Quad FX и FASN8. Наконец, формальный выход четырёхъядерных процессоров Phenom дал возможность AMD представить "человеческую" игровую платформу Spider, объединившую в себе материнские платы на настольных чипсетах компании, четырёхъядерные процессоры Phenom и от одной до четырёх видеокарт семейства Radeon HD 3800 (технология CrossFireX). В представленном виде платформа Spider просуществует до середины 2008 года. Летом или осенью следующего года AMD надеется выпустить первые 45-нм настольные процессоры, и вооружённый ими Spider превратится в Leo:
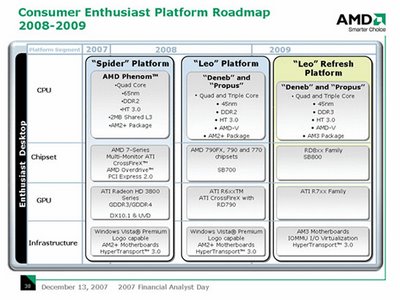
Первые 45-нм четырёхядерные процессоры AMD Deneb и двухядерные Propus выйдут в исполнении Socket AM2+ с поддержкой памяти DDR2. Надо отметить, причисление двухядерных процессоров к "лику" производительных выглядит необъяснимо. На слайде легко заметно отсутствие характеристики "двухядерные" в описании процессоров платформы Leo, что справедливо для систем максимальной производительности. В то же время, помимо четырёхядерных процессоров, Leo обещает поддержать трёхядерные процессоры компании. К тому времени у AMD появятся серийные 65-нм трёхядерные процессоры Toliman. Станет ли Propus трёхядерным или произошла банальная ошибка, нам ещё предстоит узнать. Надеемся, AMD всё же тщательно готовилась к встрече с аналитиками и оплошности не допустила. Вполне возможно, первые 45-нм процессоры компании окажутся настолько редкими, что никуда кроме как в производительные системы больше не попадут. Системные чипсеты платформы Spider всем составом перекочуют в платформу Leo (северные мосты AMD 790FX, AMD 790X, AMD 770 и южный мост SB700). Опциональных вариантов для графической подсистемы не предусмотрено – только адаптеры поколения R6xx с режимом CrossFireX на платах с чипсетами 790FX/790X.Весной 2009 года платформа Leo обновится до Leo Refresh. В её состав войдут 45-нм AM3 процессоры с поддержкой памяти DDR3 – четырёхядерные Deneb и (опять!) двухядерные Propus, а также трёхядерные процессоры. На тот момент трёхядерники AMD получат решения под кодовым именем Heka. Что тут "опция": Propus или Heka, снова непонятно. Наконец, в 2009 году производительные платы получат новое семейство чипсетов, состоящее из северных мостов RD8xx и южного SB800, а также графические адаптеры нового семейства ATI R7xxx.Массовые настольные. Итак, компания AMD меняет платформенную стратегию. От открытых конфигураций с привлечением чипсетов NVIDIA и VIA микропроцессорный разработчик практически целиком переключается на компоненты собственной разработки. Данная стратегия является частью плана компании возвращения к прибыльности – рост продаж всеми доступными средствами. Интересно, как воспримут перемены тайваньские производители материнских плат. Мы от них регулярно слышали "стоны" по поводу жёсткости Intel, которая теми или иными маркетинговыми ухищрениями навязывала Тайваню комплекты Centrino. Но взамен Intel оказывала такую мощную рекламную поддержку платформе, на которую AMD сегодня вряд ли способна.
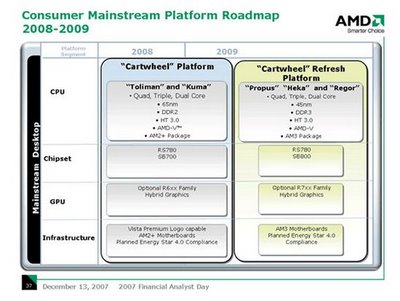
В качестве процессоров платформы Cartwheel будут задействованы четырёх-, трёх- и двухядерные процессоры архитектуры K10. Четыре ядра в семействе моделей Phenom зимой освободятся от ошибок. В конце февраля AMD планирует анонсировать трёхядерные процессоры Toliman, а весной платформу Cartwheel осчастливят двухядерные Kuma. Отметим, имя Phenom компания по каким-то соображениям не приводит в списке поддерживаемых процессоров. Этот бренд, очевидно, зарезервирован для более мощных платформ, а для Cartwheel является лишь опцией. Предварительные характеристики процессоров можно обнаружить по приведенным выше ссылкам. Обобщая: 65-нм техпроцесс, Socket AM2+, память DDR2, технология виртуализации AMD-V, шина HyperTransport 3.0. В качестве системного чипсета платформы Cartwheel заявлен ожидаемый зимой интегрированный северный мост RS780 с DirectX10-ядром и южный мост SB700. Тип видеокарты для массовой платформы жёстко не задаётся. Это опция. Компания рекомендует использовать в составе Cartwheel графический адаптер поколения R6хх, но подразумевает, что видеокарты на чипах NVIDIA или графические адаптеры других поколений AMD (ATI) устанавливать не возбраняется. О чём надо помнить, совместная работа интегрированного видеоядра и дискретной видеокарты – режим Hybrid Graphics, гарантируется только в связке с адаптерами поколения R6хх. Мультипроцессорный графический режим CrossFireX не предусмотрен даже опционально, хотя четырёхядерные процессоры, как отмечено выше, для Cartwheel предусмотрены. В целом, гарантируется соответствие сертификату Vista Premium и даётся обещание вписаться в требования Energy Star 4.0. Также Cartwheel унаследует мультимедийные оболочки "AMD Live!".Платформа Cartwheel просуществует до весны 2009 года, когда будет заменена обновлённой Cartwheel Refresh. На смену 65-нм процессорам придут 45-нм Socket AM3: трёхядерные Heka и двухядерные Propus и Regor. Последняя пара, заметим, ожидается во второй половине 2008 года. Однако надеяться на широкое распространение 45-нм процессоров AMD до начала 2009 года бессмысленно. Как следует из графика, настольный чипсет RS780 окажется долгожителем – минимум два года на рынке! В 2009 году обновится только южный мост – в состав Cartwheel Refresh войдёт SB800. И выхода очередного поколения графических процессоров R7xx ещё ждать и ждать.
Dunnington - первые шестиядерные процессоры Intel
Если придерживаться хронологического порядка появления новых продуктов Intel, nj то стоит сперва поговорить о шестиядерных процессорах под кодовым обозначением Dunnington. Эти чипы будут основаны на базе 45-нм версии микроархитектуры Core и, судя по всему, станут последними представителями поколения Penryn.Чипы Dunnigton являются решениями для многопроцессорных серверов и будут представлены в рамках платформы Caneland под брендом Intel Xeon. Для производства шестиядерных чипов Intel применит 45-нм технологию с использованием металлических затворов и High-K диэлектриков, что позволит разместить на одном кристалле 1,9 млрд транзисторов. Все шесть ядер совместно с массивами ячеек кэш-памяти разместятся на одном кристалле, хотя ранее некоторые обозреватели полагали, что Intel просто упакует три двуядерных кристалла Wolfdale в один корпус. В процессорах Dunnington применена концепция многоуровневого разделяемого кэша. На каждую пару ядер приходится по одному массиву ячеек кэш-памяти второго уровня емкостью 3 Мб, соответственно, общий объем кэша L2 достигает 9 Мб. Также на кристалле разместится разделяемый кэш третьего уровня, емкость которого будет составлять до 16 Мб. Отметим, что предшественники Dunnington, четырехядерные чипы серии Xeon 7300 (Tigerton) для многопроцессорных серверов, имеют до 8 Мб кэша L3.Из других технических особенностей Dunnington, известных нам сегодня, отметим шину FSB с производительностью 1066 мегатранзакций в секунду, схему 40-разрядной адресации физической памяти; привычную корпусировку mPGA604; TDP 130 Вт; поддержку технологии виртуализации VT FlexMigration с широкими возможностями совместимости и поддержкой миграции на будущие платформы с архитектурой Core или последующими микроархитектурами. По официальным данным, дата релиза намечена на второе полугодие 2008. Учитывая, что шестиядерные чипы должны стать неким промежуточным решением между современными четыёхъядерными Xeon (Core) и процессорами следующего поколения микроархитектуры Nehalem, которые должны появиться в четвертом квартале текущего года, выход в свет Dunnington можно ожидать уже в третьем или самом начале четвертого квартала
Список использованной литературы
1. Гук. М. Процессоры intel от 8086 до Pentium; С-Питербург -“Питер Паблишинг” – 1997.
2. Обзор процессоров и шин ПВМ; Москва – 1995.
3. http://www.amd.com
4. http://www.intel.com
5. http://www.yandex.ru
| Сравнительные характеристики современных аппаратных платформ | |
|
Содержание Процессоры с архитектурой 80x86 и Pentium Особенности процессоров с архитектурой SPARC компании Sun Microsystems SuperSPARC hyperSPARC ... Интерфейс кэш-памяти второго уровня процессора R10000 поддерживает 128-битовую магистраль данных, которая может работать с тактовой частотой до 200 МГц, обеспечивая скорость обмена ... Специальная магистраль данных шириной в 128 бит осуществляет пересылки данных на внутренней тактовой частоте процессора 200 МГц, обеспечивая максимальную скорость передачи данных ... |
Раздел: Рефераты по информатике, программированию Тип: доклад |
| Кэш-память | |
|
Государственный университет информационно - коммуникационных технологий Курсовая работа на тему: Кэш-память практическое задание: Дефрагментация диска ... Процессор Pentium III компании Intel имеет кэш-память первого уровня емкостью 32 Кбайт на микросхеме процессора и либо кэш-память второго уровня емкостью 256 Кбайт на микросхеме ... Дополнительная кэш-память третьего уровня ведет начало от серверных процессоров Xeon MP на 0,13-микронном ядре Gallatin и не имеет ничего общего с грядущим 90-нанометровым Prescott ... |
Раздел: Рефераты по информатике, программированию Тип: курсовая работа |
| Микропроцессоры для пользователей | |
|
Днепропетровский государственный технический университет железнодорожного транспорта Кафедра "КИТ" Доклад на тему: "Микропроцессоры для пользователя ... OverDrive процессор для систем i486SX содержит модуль операций над целыми числами, модуль операций над числами с плавающей точкой, модуль управления памятью и 8К кэш-памяти на ... Первые модели процессора Pentium работали на частоте 60 и 66 МГц и общались со своей внешней кэш-памятью второго уровня по 64-битовой шине данных, работающей на полной скорости ... |
Раздел: Рефераты по компьютерным наукам Тип: реферат |
| ... организации параллелизма выполнения машинных команд в процессорах | |
|
Министерство образования и науки Российской Федерации Федеральное агентство по образованию Южно-Уральский государственный университет Кафедра ... Так, если в процессоре Pentium длина конвейера составляла 5 ступеней (при максимальной тактовой частоте 200 МГц), то в Pentium-4 - уже 20 ступеней (при максимальной тактовой ... Аппаратная реализация VLIW-процессора очень проста: несколько небольших функциональных модулей (сложения, умножения, ветвления и т.д.), подключенных к шине процессора, и несколько ... |
Раздел: Рефераты по информатике, программированию Тип: курсовая работа |
| Исследование архитектуры современных микропроцессоров и вычислительных ... | |
|
РЕФЕРАТ Отчет о НИРС: 53 c., 28 рис., 5 источников Объект исследования - архитектура современных микропроцессоров и вычислительных систем. Цель работы ... Например, в Pentium III появились команды нового типа, обеспечивающие: запись данных из регистров в память, минуя кэш; чтение данных из памяти в регистры, минуя кэш; запись данных ... Отличительная особенность Power4 - наличие кэш-памяти второго уровня, разделяемой двумя процессорами кристалла, а также внешними процессорами других кристаллов через линки шириной ... |
Раздел: Рефераты по информатике, программированию Тип: дипломная работа |