Курсовая работа: Генетические алгоритмы в задаче оптимизации действительных параметров
Содержание
Введение
1. Эволюция в природе
1.1 Естественный отбор
1.2 Задачи оптимизации
2. Генетический алгоритм
2.1 История развития ГА
2.2 Общий вид генетического алгоритма
2.3 Генетические операторы
2.4 Достоинства и недостатки стандартных и генетических методов
3. Влияние параметров генетического алгоритма на
эффективность поиска
3.1 Операторы кроссовера и мутации
3.2 Выбор родительской пары
3.3 Механизм отбора
4. Наиболее актуальные проблемы ГА и интересные модификации ГА
5. Пример ГА: Решение Диофантова уравнения
5.1. Заголовок класса
5.2 Функция Fitness
5.3 Функция Likelihood
5.4 Функции Breeding
5.5 Функция Solve
5.6 Функция Main
Заключение
Список использованной литературы
Приложение «Текст main.cpp
Приложение Б «Текст Diophantine.h
Введение
Идея генетических алгоритмов заимствована у живой природы и состоит в организации эволюционного процесса, конечной целью которого является получение оптимального решения в сложной комбинаторной задаче. Разработчик генетических алгоритмов выступает в данном случае как "создатель", который должен правильно установить законы эволюции, чтобы достичь желаемой цели как можно быстрее.
Поскольку качество решения обычно оценивается некоторой оценочной функцией, ГА также называют методом оптимизации многоэкстремальных функций. Никакой дополнительной информации о решаемой задаче ГА больше не имеет. В процессе эволюции популяция вырабатывает качества, необходимые для выживания и приспособления, и которые одновременно и являются оптимальным решением.
На сегодняшний день генетические алгоритмы доказали свою конкурентоспособность при решении многих NP-трудных задач и особенно в практических приложениях, где математические модели имеют сложную структуру и применение стандартных методов типа ветвей и границ, динамического или линейного программирования крайне затруднено. Они позволяют решать задачи прогнозирования, классификации, поиска оптимальных вариантов, и совершенно незаменимы в тех случаях, когда в обычных условиях решение задачи основано на интуиции или опыте, а не на строгом (в математическом смысле) ее описании.
Генетический алгоритм - это простая модель эволюции в природе, реализованная в виде компьютерной программы. В нем используются как аналог механизма генетического наследования, так и аналог естественного отбора. При этом сохраняется биологическая терминология в упрощенном виде. Представим себе искусственный мир, населенный множеством существ (особей), причем каждое существо — это некоторое решение нашей задачи. Будем считать особь тем более приспособленной, чем лучше соответствующее решение (чем большее значение целевой функции оно дает). Тогда задача максимизации целевой функции сводится к поиску наиболее приспособленного существа. Конечно, мы не можем поселить в наш виртуальный мир все существа сразу, так как их очень много. Вместо этого мы будем рассматривать много поколений, сменяющих друг друга. Теперь, если мы сумеем ввести в действие естественный отбор и генетическое наследование, то полученный мир будет подчиняться законам эволюции. Заметим, что, в соответствии с нашим определением приспособленности, целью этой искусственной эволюции будет как раз создание наилучших решений. Очевидно, эволюция — бесконечный процесс, в ходе которого приспособленность особей постепенно повышается. Принудительно остановив этот процесс через достаточно долгое время после его начала и выбрав наиболее приспособленную особь в текущем поколении, мы получим не абсолютно точный, но близкий к оптимальному ответ. Такова, вкратце, идея генетического алгоритма.
эволюция генетический хромосома
1. Эволюция в природе
1.1 Естественный отбор
Можно сказать, что эволюция - это процесс оптимизации всех живых организмов. Ключевую роль в эволюционной теории играет естественный отбор. Его суть состоит в том, что наиболее приспособленные особи лучше выживают и приносят больше потомства, чем менее приспособленные. Заметим, что сам по себе естественный отбор еще не обеспечивает развития биологического вида. Действительно, если предположить, что все потомки рождаются примерно одинаковыми, то различные поколения будут отличаться только по численности, но не по приспособленности. Поэтому очень важно изучить, каким образом происходит наследование, т. е. как свойства потомка зависят от свойств родителей. Основной закон наследования интуитивно понятен каждому — он состоит в том, что потомки похожи на родителей. В частности, потомки более приспособленных родителей будут, скорее всего, одними из наиболее приспособленных в своем поколении. Чтобы понять, на чем основана эта похожесть, нам потребуется немного углубиться в строение животной клетки — в мир генов и хромосом. Почти в каждой клетке любого животного имеется набор хромосом, несущих информацию об этом животном. Основная часть хромосомы — нить ДНК (молекула дезоксирибонуклеиновой кислоты), которая состоит из четырех видов специальных соединений — нуклеотидов, идущих в определенной последовательности. Нуклеотиды обозначаются буквами A, T, C и G, и именно порядок их следования кодирует все генетические свойства данного организма. Говоря более точно, ДНК определяет, какие химические реакции будут происходить в данной клетке, как она будет развиваться и какие функции выполнять. Ген — это отрезок цепи ДНК, отвечающий за определенное свойство особи, например за цвет глаз, тип волос, цвет кожи и т. д. Вся совокупность генетических признаков человека кодируется посредством примерно 60 тыс. генов, суммарная длина которых составляет более 90 млн. нуклеотидов. Различают два вида клеток: половые (такие, как сперматозоид и яйцеклетка) и соматические. В каждой соматической клетке человека содержится 46 хромосом. Эти 46 хромосом — на самом деле 23 пары, причем в каждой паре одна из хромосом получена от отца, а вторая — от матери. Парные хромосомы отвечают за одни и те же признаки — например, отцовская хромосома может содержать ген черного цвета глаз, а парная ей материнская — ген голубоглазости. Существуют определенные законы, управляющие участием тех или иных генов в развитии особи. В частности, в нашем примере потомок будет черноглазым, так как ген голубых глаз является «слабым» (рецессивным) и подавляется геном любого другого цвета.
В половых клетках хромосом только 23, и они непарные. При оплодотворении происходит слияние мужской и женской половых клеток и образуется клетка зародыша, содержащая как раз 46 хромосом. Какие свойства потомок получит от отца, а какие — от матери? Это зависит от того, какие именно половые клетки участвовали в оплодотворении. Дело в том, что процесс выработки половых клеток (так называемый мейоз) в организме подвержен случайностям, благодаря которым потомки все же во многом отличаются от своих родителей. При мейозе, в частности, происходит следующее: парные хромосомы соматической клетки сближаются вплотную, затем их нити ДНК разрываются в нескольких случайных местах и хромосомы обмениваются своими частями.
Этот процесс обеспечивает появление новых вариантов хромосом и носит название «кроссинговер». Каждая из вновь появившихся хромосом окажется затем внутри одной из половых клеток, и ее генетическая информация может реализоваться в потомках данной особи. Второй важный фактор, влияющий на наследственность, — это мутации, которые выражаются в изменении некоторых участков ДНК. Мутации также случайны и могут быть вызваны различными внешними факторами, такими, как радиоактивное облучение. Если мутация произошла в половой клетке, то измененный ген может передаться потомку и проявиться в виде наследственной болезни либо в других новых свойствах потомка. Считается, что именно мутации являются причиной появления новых биологических видов, а кроссинговер определяет уже изменчивость внутри вида (например, генетические различия между людьми).
1.2 Задачи оптимизации
Как уже было отмечено выше, эволюция — это процесс постоянной оптимизации биологических видов. Теперь мы в состоянии понять, как происходит этот процесс. Естественный отбор гарантирует, что наиболее приспособленные особи дадут достаточно большое потомство, а благодаря генетическому наследованию мы можем быть уверены, что часть этого потомства не только сохранит высокую приспособленность родителей, но будет обладать и некоторыми новыми свойствами. Если эти новые свойства окажутся полезными, то с большой вероятностью они перейдут и в следующее поколение. Таким образом, происходит накопление полезных качеств и постепенное повышение приспособляемости биологического вида в целом. Зная, как решается задача оптимизации видов в природе, мы теперь применим похожий метод для решения различных реальных задач. Задачи оптимизации — наиболее распространенный и важный для практики класс задач. Их приходится решать каждому из нас либо в быту, распределяя свое время между различными делами, либо на работе, добиваясь максимальной скорости работы программы или максимальной доходности компании — в зависимости от должности. Среди этих задач есть решаемые простым путем, но есть и такие, точное решение которых найти практически невозможно. Введем обозначения и приведем несколько классических примеров. Как правило, в задаче оптимизации мы можем управлять несколькими параметрами (обозначим их значения через x1, x2, ..., xn, а нашей целью является максимизация (или минимизация) некоторой функции, f(x1, x2, ..., xn), зависящей от этих параметров. Функция f называется целевой функцией. Например, если требуется максимизировать целевую функцию «доход компании», то управляемыми параметрами будут число сотрудников компании, объем производства, затраты на рекламу, цены на конечные продукты и т. д. Важно отметить, что эти параметры связаны между собой — в частности, при уменьшении числа сотрудников скорее всего упадет и объем производства. Конечно, математики издавна занимались подобными задачами и разработали несколько методов их решения. В случае если целевая функция достаточно гладкая и имеет только один локальный максимум (унимодальная), то оптимальное решение можно получить методом градиентного спуска. Идея этого метода состоит в том, что оптимальное решение получается итерациями. Берется случайная начальная точка, а затем в цикле происходит сдвиг этой точки на малый шаг, причем шаг делается в том направлении, в котором целевая функция растет быстрее всего. Недостатком градиентного алгоритма являются слишком высокие требования к функции — на практике унимодальность встречается крайне редко, а для неправильной функции градиентный метод часто приводит к неоптимальному ответу. Аналогичные проблемы возникают и с применением других математических методов. Во многих важных задачах параметры могут принимать лишь определенные значения, причем во всех остальных точках целевая функция не определена. Конечно, в этом случае не может быть и речи о ее гладкости, и требуются принципиально другие подходы. Таким образом, возникает необходимость в каком-либо новом методе оптимизации, пригодном для практики. Здесь и появляется необходимость в каких-то новых методах решения, например таких, как генетический алгоритм.
2. Генетический алгоритм
2.1 История развития ГА
То, что называется стандартным генетическим алгоритмом, было впервые подробно описано и исследовано в работе де Джонга. Он проанализировал простую схему кодирования генов битовыми строками фиксированной длины и соответствующих генетических операторов, выполнил значительное количество численных экспериментов, сравнивая результаты с оценками, предсказываемыми теоремой Холланда. Важность этой работы определяется прежде всего ее строгим и системным характером, ясностью изложения и представления результатов, выбранным уровнем абстракции и упрощения, позволяющим избежать ненужной детализации. Кроме того, в этой работе подчеркивалась необходимость проведения дальнейших исследований более сложных схем представления генотипа и операций над ним. Последующие работы де Джонга продемонстрировали его интерес к проблемам, которые требовали менее структурированных схем представления гена.
Другой отправной точкой развития исследований по генетическим алгоритмам была публикация в 1975 году книги Холланда "Adaptation in Natural and Artificial Systems". Эта книга заложила теоретический фундамент для работы де Джонга и всех последующих работ, математически обосновав идею близких подмножеств внутри генотипа, процессов гибели и селективного воспроизведения. Цели этой книги были достаточно широкими. Хотя доказательства основных утверждений были представлены для генов фиксированной длины и соответствующих простых операторов, это не ограничивало развитие представленного подхода на случаи более богатые по своим возможностям. Например, Холланд обсуждал возможность применения операторов внутрихромосомной дупликации, удаления и сегрегации участков хромосомы.
Тем не менее, большинство последующих исследователей восприняло теоретические результаты, содержащиеся в этих работах слишком буквально, и разрабатывали различные модификации стандартного генетического алгоритма, исследованного де Джонгом.
Только небольшая часть исследователей предприняла усилия по разработке альтернативных схем. Среди них выделяются детектор паттернов Кавичио, работа Франца по инверсии, игрок в покер Смита.
Исследование Кавичио, нацеленное на разработку детектора распознавания образов было одним из первых, использующих гены переменной длины. Расположенные на плоскости двоичные пиксели, способные различать свет и темноту, нумеровались и объединялись в подмножества, образующие разные детекторы, которые затем использовались некоторым априорно заданным алгоритмом для распознавания образов. При этом не возникало использование одного и того же пикселя дважды или не использования пикселя.
Смит использовал правила, оперирующие строками переменной длины, создавая модель машинного игрока в покер. Его LS-1 система использовала модифицированный кроссинговер, который располагал точки кроссинговера как на границах строк, кодирующих правила, так и внутри них. Он также включил в алгоритм оператор инверсии, надеясь, что это поможет более эффективно распределять правила внутри строки.
Несколько ранее Смита, Франц рассмотрел возможность смещения отдельных подмножеств битов внутри строки в своей работе по нелинейной оптимизации. К сожалению, из-за неудачного выбора вида функции оптимизации (которая легко оптимизировалась и простым генетическим алгоритмом без использования инверсии) не было показано реальных преимуществ нового алгоритма по сравнению с общепринятым. Тем не менее, эту работу можно считать одной из первых, начавших применение более гибких схем генетических алгоритмов.
Другие исследователи предложили различные модификации схем генетического переупорядочивания внутри строки, когда используется кроссинговер. Одновременно был проведен ряд исследований, развивавших теорию Холланда, и продемонстрированы новые генетические операторы. Однако вопрос об их преимуществах и тщательном сравнении со стандартным генетическим алгоритмом продолжает оставаться открытым.
2.2 Общий вид генетического алгоритма
Вначале ГА-функция генерирует определенное
количество возможных решений. Задается функция оптимальности ![]() , определяющая эффективность
каждого найденного решения, для отслеживания выхода решения из допустимой области
в функцию можно включить штрафной компонент. Каждое решение кодируется как вектор
x, называемый хромосомой. Его элементы
– гены, изменяющиеся в определённых позициях, называемых аллелями. Геном – совокупность
всех хромосом. Генотип – значение генома.
, определяющая эффективность
каждого найденного решения, для отслеживания выхода решения из допустимой области
в функцию можно включить штрафной компонент. Каждое решение кодируется как вектор
x, называемый хромосомой. Его элементы
– гены, изменяющиеся в определённых позициях, называемых аллелями. Геном – совокупность
всех хромосом. Генотип – значение генома.
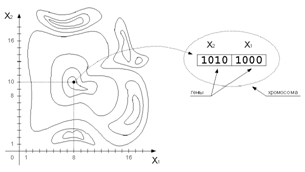
Рис. 2. Структура хромосомы
Обычно хромосомы представляются в двоичном целочисленном виде или двоичном с плавающей запятой. В некоторых случаях более эффективно будет использование кода Грея (табл. 1), в котором изменение одного бита в любой позиции приводит к изменению значения на единицу. Для некоторых задач двоичное представление естественно, для других задач может оказаться полезным отказаться от двоичного представления. В общем случае выбор способа представления параметров задачи в виде хромосомы влияет на эффективность решения.
Таблица 1. Код Грея
| Целое | Двоичный код | Код Грея |
| 0 | 0000 | 0000 |
| 1 | 0001 | 0001 |
| 2 | 0010 | 0011 |
| 3 | 0011 | 0010 |
| 4 | 0100 | 0110 |
| 5 | 0101 | 0111 |
| 6 | 0110 | 0101 |
| 7 | 0111 | 0100 |
| 8 | 1000 | 1100 |
| 9 | 1001 | 1101 |
| 10 | 1010 | 1111 |
| 11 | 1011 | 1110 |
| 12 | 1100 | 1010 |
| 13 | 1101 | 1011 |
| 14 | 1110 | 1001 |
| 15 | 1111 | 1000 |
Популяция – совокупность решений на конкретной итерации,
количество хромосом в популяции ![]() задаётся изначально и в процессе обычно
не изменяется. Для ГА пока не существует таких же чётких математических основ, как
для НС, поэтому при реализации ГА возможны различные вариации.
задаётся изначально и в процессе обычно
не изменяется. Для ГА пока не существует таких же чётких математических основ, как
для НС, поэтому при реализации ГА возможны различные вариации.
1. Начальная популяция ![]() — конечный набор допустимых
решений задачи. Эти решения могут быть выбраны случайным образом или получены с
помощью вероятностных жадных алгоритмов. Как мы увидим ниже, выбор начальной популяции
не имеет значения для сходимости процесса, однако формирование "хорошей"
начальной популяции (например, из множества локальных оптимумов) может заметно сократить
время достижения глобального оптимума. Это отличается от стандартных методов, когда
начальное состояние всегда одно и то же.
— конечный набор допустимых
решений задачи. Эти решения могут быть выбраны случайным образом или получены с
помощью вероятностных жадных алгоритмов. Как мы увидим ниже, выбор начальной популяции
не имеет значения для сходимости процесса, однако формирование "хорошей"
начальной популяции (например, из множества локальных оптимумов) может заметно сократить
время достижения глобального оптимума. Это отличается от стандартных методов, когда
начальное состояние всегда одно и то же.
2.
Каждая хромосома популяции xi оценивается функцией эффективности
![]() , и ей в соответствии
с этой оценкой присваивается вероятность воспроизведения Pi.- Вычисление
коэффициента выживаемости (fitness).
, и ей в соответствии
с этой оценкой присваивается вероятность воспроизведения Pi.- Вычисление
коэффициента выживаемости (fitness).
3. В соответствии с вероятностями воспроизведения Pi генерируется новая популяция хромосом, причём с большей вероятностью воспроизводятся наиболее эффективные элементы. Популяция следующего поколения в большинстве реализаций генетических алгоритмов содержит столько же особей, сколько начальная, но в силу отбора приспособленность в ней в среднем выше. Воспроизведение осуществляется при помощи генетических операторов кроссинговера (скрещивание) и мутации.
4. Если найдено удовлетворительное решение, процесс останавливается, иначе продолжается с шага 2.
Жизненный цикл популяции - это несколько случайных скрещиваний и мутаций, в результате которых к популяции добавляется какое-то количество новых индивидуумов.
2.3 Генетические операторы
Стандартные операторы для всех типов генетических алгоритмов это: селекция, скрещивание и мутация.
Оператор отбора [селекция]. Служит для создания промежуточной популяции
![]() . В промежуточную
популяцию копируются хромосомы из текущей популяции в соответствии с их вероятностью
воспроизведения Pi. Существуют различные
схемы отбора, самая популярная из них – пропорциональный отбор:
. В промежуточную
популяцию копируются хромосомы из текущей популяции в соответствии с их вероятностью
воспроизведения Pi. Существуют различные
схемы отбора, самая популярная из них – пропорциональный отбор: 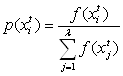 .
.
Простейший пропорциональный отбор - рулетка (roulette-wheel selection, Goldberg, 1989c) - отбирает особей с помощью n "запусков" рулетки. Колесо рулетки содержит по одному сектору для каждого члена популяции. Размер i-ого сектора пропорционален соответствующей величине Ps(i). При таком отборе члены популяции с более высокой приспособленностью с большей вероятность будут чаще выбираться, чем особи с низкой приспособленностью.
Для устранения зависимости от положительных значений и влияний больших чисел используется масштабирование оценок или ранжирование.
При турнирной селекции формируется случайное подмножество из элементов популяции и среди них выбирается один элемент с наибольшим значением целевой функции. Турнирный отбор реализует n турниров, чтобы выбрать n особей. Каждый турнир построен на выборке k элементов из популяции, и выбора лучшей особи среди них. Наиболее распространен турнирный отбор с k=2.
Турнирная селекция имеет определенные преимущества перед пропорциональной, так как не теряет своей избирательности, когда в ходе эволюции все элементы популяции становятся примерно равными по значению целевой функции. Пропорциональный отбор не гарантирует сохранности лучших результатов, достигнутых в какой-либо популяции, и для преодоления такого явления используется элитный отбор - несколько лучших индивидуумов переходят в следующее поколение без изменений, не участвуя в кроссинговерe и отборе.
Операторы селекции строятся таким образом, чтобы с ненулевой вероятностью любой элемент популяции мог бы быть выбран в качестве одного из родителей. Более того, допускается ситуация, когда оба родителя представлены одним и тем же элементом популяции.
В любом случае каждое следующее поколение будет в среднем лучше предыдущего. Когда приспособленность индивидуумов перестает заметно увеличиваться, процесс останавливают и в качестве решения задачи оптимизации берут наилучшего из найденных индивидуумов.
Отбор в генетическом алгоритме тесно связан с принципами естественного отбора в природе следующим образом:
Таблица
| Приспособленность индивидуума | Значение целевой функции на этом индивидууме. |
| Выживание наиболее приспособленных | Популяция следующего поколения формируется в соответствии с целевой функцией. Чем приспособленнее индивидуум, тем больше вероятность его участия в кроссовере, т.е. размножении. |
Воспроизведение. Служит для создания следующей популяции на основе промежуточной ![]() при помощи операторов
кроссинговера и мутации, которые имеют случайный характер. Каждому элементу промежуточной
популяции
при помощи операторов
кроссинговера и мутации, которые имеют случайный характер. Каждому элементу промежуточной
популяции ![]() ,
если надо подбирается партнёр и вновь созданная хромосома помещается в новую популяцию.
,
если надо подбирается партнёр и вновь созданная хромосома помещается в новую популяцию.
Оператор кроссинговера (в литературе по генетическим алгоритмам также употребляется название кроссовер или скрещивание) - операция, при которой две хромосомы обмениваются своими частями. Производит обмен генетического материала между родителями для получения потомков. Кроссинговер смешивает "генетический материал" двух родителей, причем можно ожидать, что приспособленность родителей выше средней в предыдущем поколении, так как они только что прошли очередной раунд борьбы за выживание. Это аналогично соперничеству настоящих живых существ, где лишь сильнейшим удается передать свои (предположительно хорошие) гены следующему поколению. Важно, что кроссинговер может порождать новые хромосомы, ранее не встречавшиеся в популяции. Простейший одноточечный кроссинговер (рис. 3) производит обмен частями, на которые хромосома разбивается точкой кроссинговера. Одноточечный кроссовер работает следующим образом. Сначала, случайным образом выбирается одна из l-1 точек разрыва. Точка разрыва - участок между соседними битами в строке. Обе родительские структуры разрываются на два сегмента по этой точке. Затем, соответствующие сегменты различных родителей склеиваются и получаются два генотипа потомков. Двухточечный кроссинговер обменивает кусок строки, попавшей между двумя точками. Предельным случаем является равномерный кроссинговер, в результате которого все биты хромосом обмениваются с некоторой вероятностью. Этот оператор служит для исследования новых областей пространства и улучшения существующих (приспособление).
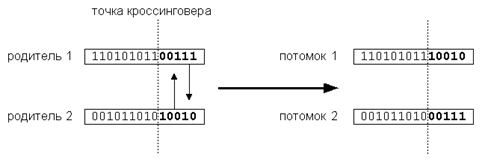
Рис. 3. Кроссинговер
Все типы кроссинговера обладают общим свойством: они контролируют баланс между дальнейшим использованием уже найденных хороших подобластей пространства и исследованием новых подобластей. Достигается это за счет неразрушения общих блоков внутри хромосом-родителей, сохраняющем "хорошие" паттерны, и одновременном исследовании новых областей в результате обмена частями строк (хромосом). Совместное использование отбора и кроссинговера приводит к тому, что области пространства, обладающие лучшей средней оптимальностью, содержат больше элементов популяции, чем другие. Таким образом, эволюция популяции направляется к областям, содержащим оптимум с большей вероятностью, чем другие.
Оператор мутации [Случайное изменение одной или нескольких позиций в хромосоме]
К каждому биту хромосомы с небольшой вероятностью ![]() применяется мутация – т.е. бит (аллель)
изменяет значение (для двоичного представления - на противоположный) - (рис. 4).
Мутация нужна для расширения пространства поиска (исследование) и предотвращения
невосстановимой потери бит в аллелях. Мутации вносят новизну и предотвращают невосстановимую
потерю аллелей в определенных позициях, которые не могут быть восстановлены кроссинговером,
тем самым ограничивая преждевременное сжатие пространства поиска. Циклическое применение
последовательности отбор-мутация направляет эволюцию элементов популяции к наиболее
хорошим точкам пространства поиска.
применяется мутация – т.е. бит (аллель)
изменяет значение (для двоичного представления - на противоположный) - (рис. 4).
Мутация нужна для расширения пространства поиска (исследование) и предотвращения
невосстановимой потери бит в аллелях. Мутации вносят новизну и предотвращают невосстановимую
потерю аллелей в определенных позициях, которые не могут быть восстановлены кроссинговером,
тем самым ограничивая преждевременное сжатие пространства поиска. Циклическое применение
последовательности отбор-мутация направляет эволюцию элементов популяции к наиболее
хорошим точкам пространства поиска.
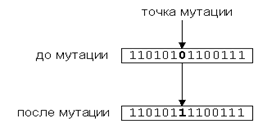
Рис. 4. Мутация
Существует также оператор воспроизведения, называемый инверсией, который заключается в реверсировании бит между двумя случайными позициями, однако для большинства задач он не имеет практического смысла и поэтому неэффективен.
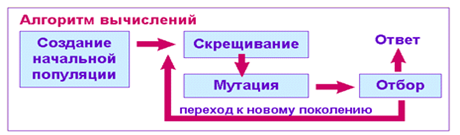
Рис. 5. Блок-схема генетического алгоритма
Работа ГА представляет собой итерационный процесс, который продолжается до тех пор, пока не выполнятся заданное число поколений или какой-либо иной критерий останова. На каждом поколении ГА реализуется отбор пропорционально приспособленности, кроссовер и мутация. Блок-схема генетического алгоритма достаточно проста (рис.5)
2.4. Достоинства и недостатки стандартных и генетических методов
Генетический алгоритм - новейший, но не единственно возможный способ решения задач оптимизации. С давних пор известны два основных пути решения таких задач - переборный и локально-градиентный. У этих методов свои достоинства и недостатки, и в каждом конкретном случае следует подумать, какой из них выбрать.
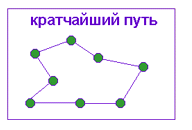
Рис.
Рассмотрим достоинства и недостатки стандартных и генетических методов на примере классической задачи коммивояжера. Суть задачи состоит в том, чтобы найти кратчайший замкнутый путь обхода нескольких городов, заданных своими координатами. Оказывается, что уже для 30 городов поиск оптимального пути представляет собой сложную задачу, побудившую развитие различных новых методов (в том числе нейросетей и генетических алгоритмов).
Каждый вариант решения (для 30 городов) - это числовая строка, где на j-ом месте стоит номер j-ого по порядку обхода города. Таким образом, в этой задаче 30 параметров, причем не все комбинации значений допустимы. Естественно, первой идеей является полный перебор всех вариантов обхода.
Рис
Переборный метод наиболее прост по своей сути и тривиален в программировании. Для поиска оптимального решения (точки максимума целевой функции) требуется последовательно вычислить значения целевой функции во всех возможных точках, запоминая максимальное из них. Недостатком этого метода является большая вычислительная стоимость. В частности, в задаче коммивояжера потребуется просчитать длины более 1030 вариантов путей, что совершенно нереально. Однако, если перебор всех вариантов за разумное время возможен, то можно быть абсолютно уверенным в том, что найденное решение действительно оптимально.
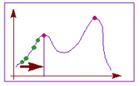
Рис.
Второй популярный способ основан на методе градиентного спуска. При этом вначале выбираются некоторые случайные значения параметров, а затем эти значения постепенно изменяют, добиваясь наибольшей скорости роста целевой функции. Достигнув локального максимума, такой алгоритм останавливается, поэтому для поиска глобального оптимума потребуются дополнительные усилия.
Градиентные методы работают очень быстро, но не гарантируют оптимальности найденного решения. Они идеальны для применения в так называемых унимодальных задачах, где целевая функция имеет единственный локальный максимум (он же - глобальный). Легко видеть, что задача коммивояжера унимодальной не является.

Рис.
Типичная практическая задача, как правило, мультимодальна и многомерна, то есть содержит много параметров. Для таких задач не существует ни одного универсального метода, который позволял бы достаточно быстро найти абсолютно точное решение.
Однако, комбинируя переборный и градиентный методы, можно надеяться получить хотя бы приближенное решение, точность которого будет возрастать при увеличении времени расчета.
Генетический алгоритм представляет собой именно такой комбинированный метод. Механизмы скрещивания и мутации в каком-то смысле реализуют переборную часть метода, а отбор лучших решений - градиентный спуск.
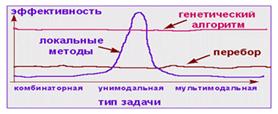
Рис
На рисунке показано, что такая комбинация позволяет обеспечить устойчиво хорошую эффективность генетического поиска для любых типов задач.
Итак, если на некотором множестве задана сложная функция от нескольких переменных, то генетический алгоритм - это программа, которая за разумное время находит точку, где значение функции достаточно близко к максимально возможному. Выбирая приемлемое время расчета, мы получим одно из лучших решений, которые вообще возможно получить за это время.
Однако, ГА, как и другие методы эволюционных вычислений, не гарантирует обнаружения глобального решения за полиномиальное время. ГА-мы не гарантируют и того, что глобальное решение будет найдено, но они хороши для поиска "достаточно хорошего" решения задачи "достаточно быстро". Там, где задача может быть решена специальными методам, почти всегда такие методы будут эффективнее ГА и в быстродействии и в точность найденных решений. Главным же преимуществом ГА-мов является то, что они могут применяться даже на сложных задачах, там, где не существует никаких специальных методов. Даже там, где хорошо работаю существующие методики, можно достигнуть улучшения сочетанием их с ГА.
3. Влияние параметров генетического алгоритма на эффективность поиска
3.1 Операторы кроссовера и мутации
Наиболее традиционным подходом является отход от традиционной схемы "размножения", используемой в большинстве реализованных ГА-мах и повторяющих классическую схему. Классическая схема предполагает ограничение численности потомков путем использования так называемой вероятности кроссовера. Такая модель придает величине, соответствующей численности потомков, вообще говоря, недетерминированный характер. Есть метод предлагающий отойти от вероятности кроссовера и использовать фиксированное число брачных пар на каждом поколении, при этом каждая брачная пара "дает" двух потомков. Такой подход хорош тем, что делает процесс поиска более управляемым и предсказуемым в смысле вычислительных затрат.
В качестве генетических операторов получения новых генотипов потомков, используя генетическую информацию хромосомных наборов родителей мы применяем два типа кроссоверов - одно- и двухточечный. Вычислительные эксперименты показали, что даже для простых функций нельзя говорить о преимуществе того или иного оператора. Более того, было показано, что использование механизма случайного выбора одно- или двух точечного кроссовера для каждой конкретной брачной пары подчас оказывается более эффективным, чем детерминированный подход к выбору кроссоверов, поскольку достаточно трудно определить который из двух операторов более подходит для каждого конкретного ландшафта приспособленности. Использование же случайного выбора преследовало целью, прежде всего сгладить различия этих двух подходов и улучшить показатели среднего ожидаемого результата. Для всех представленных тестовых функций так и произошло, - случайного выбор оказался эффективнее худшего.
Повышение эффективности поиска при использовании случайного выбора операторов кроссовера повлияло на то, чтобы применить аналогичный подход при реализации процесса мутагенеза новых особей, однако в этом случае преимущество перед детерминированным подходом не так очевидно в силу традиционно малой вероятности мутации. В основном вероятность мутации составляет 0.001 - 0.01.
3.2 Выбор родительской пары
Первый подход самый простой - это случайный выбор родительской пары ("панмиксия"), когда обе особи, которые составят родительскую пару, случайным образом выбираются из
всей популяции, причем любая особь может стать членом нескольких пар. Несмотря на простоту, такой подход универсален для решения различных классов задач. Однако он достаточно критичен к численности популяции, поскольку эффективность алгоритма, реализующего такой подход, снижается с ростом численности популяции. Второй способ выбора особей в родительскую пару - так называемый селективный. Его суть состоит в том, что "родителями" могут стать только те особи, значение приспособленности которых не меньше среднего значения приспособленности по популяции, при равной вероятности таких кандидатов составить брачную пару. Такой подход обеспечивает более быструю сходимость алгоритма. Однако из-за быстрой сходимости селективный выбор родительской пары не подходит тогда, когда ставиться задача определения нескольких экстремумов, поскольку для таких задач алгоритм, как правило, быстро сходится к одному из решений. Кроме того, для некоторого класса задач со сложным ландшафтом приспособленности быстрая сходимость может превратиться в преждевременную сходимость к квазиоптимальному решению. Этот недостаток может быть отчасти компенсирован использованием подходящего механизма отбора, который бы "тормозил" слишком быструю сходимость алгоритма. Другие два способа формирования родительской пары, на которые хотелось бы обратить внимание, это инбридинг и аутбридинг. Оба эти метода построены на формировании пары на основе близкого и дальнего "родства" соответственно. Под "родством" здесь понимается расстояние между членами популяции как в смысле геометрического расстояния особей в пространстве параметров. В связи с этим будем различать генотипный и фенотипный (или географический) инбридинг и аутбридинг. Под инбридингом понимается такой метод, когда первый член пары выбирается случайно, а вторым с большей вероятностью будет максимально близкая к нему особь. Аутбридинг же, наоборот, формирует брачные пары из максимально далеких особей. Использование генетических инбридинга и аутбридинга оказалось более эффективным по сравнению с географическим для всех тестовых функций при различных параметрах алгоритма. Наиболее полезно применение обоих представленных методов для многоэкстремальных задач. Однако два этих способа по-разному влияют на поведение генетического алгоритма. Так инбридинг можно охарактеризовать свойством концентрации поиска в локальных узлах, что фактически приводит к разбиению популяции на отдельные локальные группы вокруг подозрительных на экстремум участков ландшафта, напротив аутбридинг как раз направлен на предупреждение сходимости алгоритма к уже найденным решениям, заставляя алгоритм просматривать новые, неисследованные области.
3.3 Механизм отбора
Обсуждение вопроса о влиянии метода создания родительских пар на поведение генетического алгоритма невозможно вести в отрыве от реализуемого механизма отбора при формировании нового поколения. Наиболее эффективные два механизма отбора элитный и отбор с вытеснением.
Идея элитного отбора, в общем, не нова, этот метод основан на построении новой популяции только из лучших особей репродукционной группы, объединяющей в себе родителей, их потомков и мутантов. В основном это объясняют потенциальной опасностью преждевременной сходимости, отдавая предпочтение пропорциональному отбору. Быстрая сходимость, обеспечиваемая элитным отбором, может быть, когда это необходимо, с успехом компенсирована подходящим методом выбора родительских пар, например аутбридингом. Именно такая комбинация "аутбридинг - элитный отбор" является одной из наиболее эффективных.
Второй метод, на котором хотелось бы остановиться, это отбор вытеснением. Будет ли особь из репродукционной группы заноситься в популяцию нового поколения, определяется не только величиной ее приспособленности, но и тем, есть ли уже в формируемой популяции следующего поколения особь с аналогичным хромосомным набором. Из всех особей с одинаковыми генотипами предпочтение сначала, конечно же, отдается тем, чья приспособленность выше. Таким образом, достигаются две цели: во-первых, не теряются лучшие найденные решения, обладающие различными хромосомными наборами, а во-вторых, в популяции постоянно поддерживается достаточное генетическое разнообразие. Вытеснение в данном случае формирует новую популяцию скорее из далеко расположенных особей, вместо особей, группирующихся около текущего найденного решения. Этот метод особенно хорошо себя показал при решении многоэкстремальных задач, при этом помимо определения глобальных экстремумов появляется возможность выделить и те локальные максимумы, значения которых близки к глобальным.
4. Наиболее актуальные проблемы ГА и интересные модификации ГА
Неудачный выбор упорядочивания и кодирования битов в хромосоме может вызвать преждевременное схождение к локальному оптимуму, ведя алгоритм по ложному пути. Для преодоления этого недостатка можно выбирать способ кодирования основываясь на дополнительной информации о задаче. Существуют так же мобильные ГА, с переменной длиной хромосом. Для некоторых задач такое представление естественно, для других надо вводить специальные правила чтения хромосом. Вместо оператора кроссинговера используются операторы разрезания строк (CUT), вероятность которого повышается с увеличением длины строки, и оператор сцепления строк (SPLICE), который выбирает из популяции два куска и сцепляет их в один кусок. Популяция представляет собой совокупность пере- и недоопределённых строк. Правила чтения таких строк могут быть, например такими: в переопределённой строке при чтении слева направо не учитываются уже использованные гены, а в недоопределённых строках отсутствующие места заимствуются у лучшего элемента.
Проблема баланса исследования новых областей и приспособления к найденным. Это необходимо для предотвращения преждевременной сходимости к локальному оптимуму. Используются модифицированные способы отбора хромосом в промежуточную популяцию (отказ от вероятностных принципов в пользу элитного и отбора с вытеснением) и выбора родительской пары (случайный, селективный, на основе близкого или дальнего родства).
Интересные результаты может дать сочетание ГА с другими методами. И в заключение остановимся на том, когда же следует использовать генетические алгоритмы. В одних обстоятельствах они хороши, в других - не очень. В общем случае генетические алгоритмы не находят оптимального решения очень трудных задач. Если оптимальное решение задачи (например, ЗКВ с очень большим числом городов) не может быть найдено традиционными способами - например, методом сцепления ветвей (branch and bound method), - то и генетический алгоритм вряд ли найдет оптимум. С другой стороны, вполне возможно, что генетический алгоритм найдет достаточно хорошее решение. В конце концов, коммивояжеру в любом случае надо ехать продавать свои товары, даже если мы не уверены в абсолютной оптимальности маршрута! Но есть примеры, когда в очень трудных задачах, в том числе и в ЗКВ, с помощью генетических алгоритмов были получены очень хорошие решения.
В двух случаях генетические алгоритмы очень хороши. Первый случай: когда не известен способ точного решения задачи. Если мы знаем, как оценить приспособленность хромосом, то всегда можем заставить генетический алгоритм решать эту задачу. Второй случай: когда способ для точного решения существует, но он очень сложен в реализации, требует больших затрат времени и денег, то есть, попросту говоря, дело того не стоит. Пример - создание программы для составления персонального расписания на основе техники покрытия множеств с использованием линейного программирования.
Несмотря на то, что конструирование хромосом и фитнес-функций может потребовать значительных усилий, генетические алгоритмы легко реализуются даже с нуля и способны решать широкий круг задач. Используя аналогию с развитием живых организмов от простых форм к более сложным, генетические алгоритмы приблизились к тому, чтобы стать общим методом решения задач. Другие "природоподобные" парадигмы, такие как моделирование отжига (simulated annealing) и табу-поиск (taboo search), тоже позволяют решать аналогичные задачи.
5. Пример ГА: Решение Диофантова уравнения
Рассмотрим диофантово (только целые решения) уравнение: a+2b+3c+4d=30, где a, b, c и d - некоторые положительные целые. Применение ГА за очень короткое время находит искомое решение (a, b, c, d). Конечно, Вы можете спросить: почему бы не использовать метод грубой силы: просто не подставить все возможные значения a, b, c, d (очевидно, 1 <= a,b,c,d <= 30) ? Архитектура ГА-систем позволяет найти решение быстрее за счет более 'осмысленного' перебора. Мы не перебираем все подряд, но приближаемся от случайно выбранных решений к лучшим. Для начала выберем 5 случайных решений: 1 =< a,b,c,d =< 30. Вообще говоря, мы можем использовать меньшее ограничение для b,c,d, но для упрощения пусть будет 30.
Таблица 2: 1-е поколение хромосом и их содержимое
| Хромосома | (a,b,c,d) |
| 1 | (1,28,15,3) |
| 2 | (14,9,2,4) |
| 3 | (13,5,7,3) |
| 4 | (23,8,16,19) |
| 5 | (9,13,5,2) |
Чтобы вычислить коэффициенты выживаемости (fitness), подставим каждое решение в выражение a+2b+3c+4d. Расстояние от полученного значения до 30 и будет нужным значением.
Таблица 3: Коэффициенты выживаемости первого поколения хромосом (набора решений)
| Хромосома | Коэффициент выживаемости |
| 1 | |114-30|=84 |
| 2 | |54-30|=24 |
| 3 | |56-30|=26 |
| 4 | |163-30|=133 |
| 5 | |58-30|=28 |
Так как меньшие значения ближе к 30, то они более желательны. В нашем случае большие численные значения коэффициентов выживаемости подходят, увы, меньше. Чтобы создать систему, где хромосомы с более подходящими значениями имеют большие шансы оказаться родителями, мы должны вычислить, с какой вероятностью (в %) может быть выбрана каждая. Одно решение заключается в том, чтобы взять сумму обратных значений коэффициентов, и исходя из этого вычислять проценты. (Заметим, что все решения были сгенерированы Генератором Случайных Чисел - ГСЧ).
Таблица 4: Вероятность оказаться родителем
| Хромосома | Подходящесть |
| 1 | (1/84)/0.135266 = 8.80% |
| 2 | (1/24)/0.135266 = 30.8% |
| 3 | (1/26)/0.135266 = 28.4% |
| 4 | (1/133)/0.135266 = 5.56% |
| 5 | (1/28)/0.135266 = 26.4% |
Для выбора 5-и пар родителей (каждая из которых будет иметь 1 потомка, всего - 5 новых решений), представим, что у нас есть 10000-сторонняя игральная кость, на 880 сторонах отмечена хромосома 1, на 3080 - хромосома 2, на 2640 сторонах - хромосома 3, на 556 - хромосома 4 и на 2640 сторонах отмечена хромосома 5. Чтобы выбрать первую пару кидаем кость два раза и выбираем выпавшие хромосомы.
Таблица 5: Симуляция выбора родителей
| Хромосома отца | Хромосома матери |
| 3 | 1 |
| 5 | 2 |
| 3 | 5 |
| 2 | 5 |
| 5 | 3 |
Каждый потомок содержит информацию о генах и отца и от матери. Вообще говоря, это можно обеспечить различными способами, однако в нашем случае можно использовать т.н. "кроссовер" (cross-over). Пусть мать содержит следующий набор решений: a1,b1,c1,d1, а отец - a2,b2,c2,d2, тогда возможно 6 различных кросс-оверов (| = разделительная линия):
Таблица 6: Кроссоверы между родителями
| Хромосома-отец | Хромосома-мать | Хромосома-потомок |
| a1 | b1,c1,d1 | a2 | b2,c2,d2 | a1,b2,c2,d2 or a2,b1,c1,d1 |
| a1,b1 | c1,d1 | a2,b2 | c2,d2 | a1,b1,c2,d2 or a2,b2,c1,d1 |
| a1,b1,c1 | d1 | a2,b2,c2 | d2 | a1,b1,c1,d2 or a2,b2,c2,d1 |
Есть достаточно много путей передачи информации потомку, и кроссовер - только один из них. Расположение разделителя может быть абсолютно произвольным, как и то, отец или мать будут слева от черты. А теперь попробуем проделать это с нашими потомками
Таблица 7: Симуляция кроссоверов хромосом родителей
| Хромосома-отец | Хромосома-мать | Хромосома-потомок |
| (13 | 5,7,3) | (1 | 28,15,3) | (13,28,15,3) |
| (9,13 | 5,2) | (14,9 | 2,4) | (9,13,2,4) |
| (13,5,7 | 3) | (9,13,5 | 2) | (13,5,7,2) |
| (14 | 9,2,4) | (9 | 13,5,2) | (14,13,5,2) |
| (13,5 | 7, 3) | (9,13 | 5, 2) | (13,5,5,2) |
Теперь мы можем вычислить коэффициенты выживаемости (fitness) потомков.
Таблица 8: Коэффициенты выживаемости потомков (fitness)
| Хромосома-потомок | Коэффициент выживаемости |
| (13,28,15,3) | |126-30|=96 |
| (9,13,2,4) | |57-30|=27 |
| (13,5,7,2) | |57-30|=22 |
| (14,13,5,2) | |63-30|=33 |
| (13,5,5,2) | |46-30|=16 |
Средняя приспособленность (fitness) потомков оказалась 38.8, в то время как у родителей этот коэффициент равнялся 59.4. Следующее поколение может мутировать. Например, мы можем заменить одно из значений какой-нибудь хромосомы на случайное целое от 1 до 30. Продолжая таким образом, одна хромосома, в конце концов, достигнет коэффициента выживаемости 0, то есть станет решением. Системы с большей популяцией (например, 50 вместо 5-и сходятся к желаемому уровню (0) более быстро и стабильно.
5.1 Заголовок класса
#include <stdlib.h>
#include <time.h>
#include<stdio.h>
#define MAXPOP 25
struct gene
{
int alleles[4];
int fitness;
float likelihood; // Тест на равенство
operator==(gene gn)
for (int i=0;i<4;i++)
{
if (gn.alleles[i] != alleles[i]) return false;
}
return true;
class CDiophantine
public:
CDiophantine(int, int, int, int, int); // Конструктор с коэффициентами при а,b,c,d
int Solve(); // Вычисляет решение уравнения
gene GetGene(int i)
{ return population[i];}
protected:
int ca,cb,cc,cd; // Коэффициенты при а,b,c,d
int result;
gene population[MAXPOP]; // Массив из генов - популяция
int Fitness(gene &); // Функция приспособленности
void GenerateLikelihoods(); // Вычисляет вероятности воспроизведения
float MultInv();
int CreateFitnesses();
void CreateNewPopulation();
int GetIndex(float val);
gene Breed(int p1, int p2);
Существуют две структуры: gene и класс CDiophantine. gene используется для слежения за различными наборами решений. Создаваемая популяция - популяция ген. Эта генетическая структура отслеживает свои коэффициенты выживаемости и вероятность оказаться родителем. Также есть небольшая функция проверки на равенство, просто чтобы сделать кое-какой другой код покороче. Теперь по функциям:
5.2 Функция Fitness
Вычисляет коэффициент выживаемости (приспособленности - fitness) каждого гена. В нашем случае это - модуль разности между желаемым результатом и полученным значением. Этот класс использует две функции: первая вычисляет все коэффициенты, а вторая - поменьше (желательно сделать ее inline) вычисляет коэффициент для какого-то одного гена.
CDiophantine::Fitness(gene &gn) //Вычисляет коэффициет приспособленности для данного гена
{
int total = ca * gn.alleles[0] + cb * gn.alleles[1] + cc * gn.alleles[2] + cd * gn.alleles[3];
return gn.fitness = abs(total - result);
}
int CDiophantine::CreateFitnesses() // Возвращает номер гена в популяции ,
{ // кот. явл. решением данного ур-я
float avgfit = 0;
int fitness = 0;
for(int i=0;i<MAXPOP;i++)
{
fitness = Fitness(population[i]);
// avgfit += fitness;
if (fitness == 0)
{
return i;
}
}
return 0; //Возвращает 0 ,если среди генов данной популяции не нашлось решения
}
Заметим, что если fitness = 0, то найдено решение - возврат. После вычисления приспособленности (fitness) нам нужно вычислить вероятность выбора этого гена в качестве родительского.
5.3 Функция Likelihood
Как и было объяснено, вероятность вычисляется как сумма обращенных коэффициентов, деленная на величину, обратную к коэффициенту данному значению. Вероятности кумулятивны (складываются), что делает очень легким вычисления с родителями. Например:
Таблица
| Хромосома | Вероятность |
| 1 | (1/84)/0.135266 = 8.80% |
| 2 | (1/24)/0.135266 = 30.8% |
| 3 | (1/26)/0.135266 = 28.4% |
| 4 | (1/133)/0.135266 = 5.56% |
| 5 | (1/28)/0.135266 = 26.4% |
В программе, при одинаковых начальных значениях, вероятности сложатся: представьте их в виде кусков пирога. Первый ген - от 0 до 8.80%, следующий идет до 39.6% (так как он начинает 8.8). Таблица вероятностей будет выглядеть приблизительно так:
Таблица
| Хромосома | Вероятность (smi = 0.135266) |
| 1 | (1/84)/smi = 8.80% |
| 2 | (1/24)/smi = 39.6% (30.8+8.8) |
| 3 | (1/26)/smi = 68% (28.4+39.6) |
| 4 | (1/133)/smi = 73.56% (5.56+68) |
| 5 | (1/28)/smi = 99.96% (26.4+73.56) |
Последнее значение всегда будет 100. Имея в нашем арсенале теорию, посмотрим на код. Он очень прост: преобразование к float необходимо для того, чтобы избежать целочисленного деления. Есть две функции: одна вычисляет smi, а другая генерирует вероятности оказаться родителем.
float CDiophantine::MultInv()
{
float sum = 0;
for(int i=0;i<MAXPOP;i++)
{
sum += 1/((float)population[i].fitness);
}
return sum; //Сумма обратных коэффициентов приспособленности всех генов в популяции
}
void CDiophantine::GenerateLikelihoods() //Генерирует вероятности воспроизведения
{
float multinv = MultInv();
float last = 0;
for(int i=0;i<MAXPOP;i++)
{
population[i].likelihood = last = last + ((1/((float)population[i].fitness) / multinv) * 100);
}
}
Итак, у нас есть и коэффициенты выживаемости (fitness) и необходимые вероятности (likelihood). Можно переходить к размножению (breeding).
5.4 Функции Breeding
Функции размножения состоят из трех: получить индекс гена, отвечающего случайному числу от 1 до 100, непосредственно вычислить кроссовер двух генов и главной функции генерации нового поколения. Рассмотрим все эти функции одновременно и то, как они друг друга вызывают. Вот главная функция размножения:
CDiophantine::CreateNewPopulation() {
gene temppop[MAXPOP];
for(int i=0;i<MAXPOP;i++)
{
int parent1 = 0,parent2 = 0, iterations = 0;
while(parent1 == parent2 || population[parent1] == population[parent2])
{
parent1 = GetIndex((float)(rand() % 101));
parent2 = GetIndex((float)(rand() % 101));
if (++iterations > MAXPOP) break; // В этом случае родителей выбираем случайно
}
temppop[i] = Breed(parent1, parent2); // Процесс размножения
}
for(i=0;i<MAXPOP;i++)
population[i] = temppop[i];
}
Итак, первым делом мы создаем случайную популяцию генов. Затем делаем цикл по всем генам. Выбирая гены, мы не хотим, чтобы они оказались одинаковы (ни к чему скрещиваться с самим собой :), и вообще - нам не нужны одинаковые гены (operator = в gene). При выборе родителя, генерируем случайное число, а затем вызываем GetIndex. GetIndex использует идею куммулятивности вероятностей (likelihoods), она просто делает итерации по всем генам, пока не найден ген, содержащий число:
int CDiophantine::GetIndex(float val) // По данному числу от 0 до //100 возвращает
{ // номер необходимого гена в популяции
float last = 0;
for(int i=0;i<MAXPOP;i++)
{
if (last <= val && val <= population[i].likelihood) return i;
else last = population[i].likelihood;
}
return 4;
}
Возвращаясь к функции CreateNewPopulation(): если число итераций превосходит MAXPOP, она выберет любых родителей. После того, как родители выбраны, они скрещиваются: их индексы передаются вверх на функцию размножения (Breed). Breed function возвращает ген, который помещается во временную популяцию. Вот код:
gene CDiophantine::Breed(int p1, int p2)
{
int crossover = rand() % 3+1; //Число от 1 до 3 - генерируем точку кроссовера.
int first = rand() % 100; // Какой родитель будет первым ?
gene child = population[p1]; // Инициализировать ребенка первым родителем
int initial = 0, final = 4;
if (first < 50) initial = crossover;
// Если первый родитель р1(вероятность этого 50%) -
// начинаем с точки кроссовера
else final = crossover; // Иначе - заканчиваем на точке кроссовера
for(int i=initial;i<final;i++)
{ // Кроссовер
child.alleles[i] = population[p2].alleles[i];
if (rand() % 101 < 5) child.alleles[i] = rand() % (result + 1);
// 5% - мутация
}
return child; // Возвращаем ребенка
}
void CDiophantine::CreateNewPopulation() {
gene temppop[MAXPOP];
for(int i=0;i<MAXPOP;i++)
{
int parent1 = 0,parent2 = 0, iterations = 0;
while(parent1 == parent2 || population[parent1] == population[parent2])
{
parent1 = GetIndex((float)(rand() % 101));
parent2 = GetIndex((float)(rand() % 101));
if (++iterations > MAXPOP) break; // В этом случае родителей выбираем случайно
}
temppop[i] = Breed(parent1, parent2); // Процесс размножения
}
for(i=0;i<MAXPOP;i++)
population[i] = temppop[i];
}
В конце концов мы определим точку кросс-овера. Заметим, что мы нехотим, чтобы кросс-овер состоял из копирования только одного родителя. Сгенерируем случайное число, которое определит наш кроссовер. Остальное понятно и очевидно. Добавлена маленькая мутация, влияющая на скрещивание. 5% - вероятность появления нового числа.
5.5 Функция Solve
Теперь уже можно взглянуть на функцию Solve(). Она всего лишь итеративно вызывает вышеописанные функции. Заметим, что мы присутствует проверка: удалось ли функции получить результат, используя начальную популяцию. Это маловероятно, однако лучше проверить.
int CDiophantine::Solve()
{
int fitness = -1;
// Создаем начальную популяцию
srand((unsigned)time(NULL));
for(int i=0;i<MAXPOP;i++)
{ // Аллели хромосом заполняем произвольными числами от 0 до result
for (int j=0;j<4;j++)
{
population[i].alleles[j] = rand() % (result + 1);
}
}
if (fitness = CreateFitnesses())
{
return fitness;
}
int iterations = 0;
while (fitness != 0 || iterations < 50)
{ // Считаем до тех пор пока решение не будет найдено или к-во итераций более 50
GenerateLikelihoods();
CreateNewPopulation();
if (fitness = CreateFitnesses())
{
printf("iterations %d \n",iterations);
return fitness;
}
iterations++;
}
return -1;
}
5.6 Функция Main
Рассмотрим код главной функции:
#include <iostream.h>
#include <conio.h>
#include "diophantine.h"
void main() {
CDiophantine dp(1,2,3,4,30);
int ans;
ans = dp.Solve();
if (ans == -1) {
cout << "Solution not found." << endl;
} else {
gene gn = dp.GetGene(ans);
cout << "The solution set to a+2b+3c+4d=30 is:\n";
cout << "a = " << gn.alleles[0] << "." << endl;
cout << "b = " << gn.alleles[1] << "." << endl;
cout << "c = " << gn.alleles[2] << "." << endl;
cout << "d = " << gn.alleles[3] << "." << endl;
} getch();
}
Заключение
Изложенный подход является эвристическим, т. е. показывает хорошие результаты на практике, но плохо поддается теоретическому исследованию и обоснованию. Естественно задать вопрос — следует ли пользоваться такими алгоритмами, не имеющими строгого математического обоснования? Как и в вопросе о нейронных сетях, здесь нельзя ответить однозначно. С одной стороны, в математике существует достаточно большой класс абсолютно надежных (в смысле гарантии получения точного решения) методов решения различных задач. С другой стороны, речь идет о действительно сложных практических задачах, в которых эти надежные методы часто неприменимы. Нередко эти задачи выглядят настолько необозримыми, что не предпринимается даже попыток их осмысленного решения. Например, фирма, занимающаяся транспортными перевозками, в современных условиях российского бизнеса скорее предпочтет нанять лишних водителей и повысить цены на свои услуги, чем оптимизировать маршруты и расписания поездок. На западном рынке, где уже давно действуют законы более или менее честной конкуренции, оптимальность деятельности компании значительно влияет на ее доходы и даже может стать решающим фактором для ее выживания. Поэтому любые идеи, позволяющие компании стать «умнее» своих конкурентов, находят там широкое применение. Генетические алгоритмы — реализация одной из наиболее популярных идей такого рода. Эта популярность вызвана, по-видимому, исключительной красотой подхода и его близостью к природному механизму. Подобным образом популярность нейросетевой технологии подогревается во многом ее сходством с работой мозга. По-настоящему активное развитие эвристических подходов, как мы видим, непосредственно связано с развитием свободного рынка и экономики в целом.
Список использованной литературы
1. Кантор И.А.(перевод) Введение в ГА и Генетическое Программирование -http://www. algolist.manual.ru
2. Скурихин А.Н. Генетические алгоритмы . Новости искусственного интеллекта - 1995, №4, с. 6-46.
3. Хэзфилд Р. , Кирби Л. Искусство программирования на C – К .:DIAsoft ,2001.
4. Поспелов Д.А. Информатика. Энциклопедический словарь для начинающих - М:Педагогика-Пресс, 1994, - 350 с.
5. Курс лекций по предмету "Основы проектирования систем с искусственным интеллектом" / Сост. Сотник С.Л. –URL:http://www.neuropower.de
6. Кузнецов О.П. О некомпьютерных подходах к моделированию интеллектуальных процессов мозга – Москва, Институт проблем управления РАН
7. Самоорганизующиеся нейронные сети и их применение – URL:http://www.chat.ru/~neurolab
8. Редько В.Г. Курс лекций "Эволюционная кибернетика" – URL:http://inet.keldysh.ru/BioCyber/Lectures.php
9. Головко В.А. Нейроинтеллект: Теория и применения Книга 1 Организация и обучение нейронных сетей с прямыми и обратными связями - Брест:БПИ, 1999, - 260 с.
10. Головко В.А. Нейроинтеллект: Теория и применения Книга 2 Самоорганизация, отказоустойчивость и применение нейронных сетей - Брест:БПИ, 1999, - 228 с.
11. А.Н. Генетические алгоритмы . Новости искусственного интеллекта - 1995, №4, с. 6-46.
12. С.А. Исаев Генетические алгоритмы - эволюционные методы поиска -URL: http://rv.ryazan.ru/~bug/library/ai/isaev/2/part1.php
13. Д.И. Батищев, С.А. Исаев Оптимизация многоэкстремальных функций с помощью генетических алгоритмов -URL:http://bspu.secna.ru/Docs/~saisa/ga/summer97.php
14. Group Method of Data Handling - URL: http://www.inf.kiev.ua/GMDH-home
15. Береснев В. Л., Гимади Э. Х., Дементьев В. Т. Экстремальные задачи стандартизации.- Новосибирск: Наука, 1978.
16. Гэри В., Джонсон Д. Вычислительные машины и труднорешаемые задачи.- М.: Мир, 1982.
17. Лима-ле-Фариа А. Эволюция без отбора: Автоэволюция формы и функции.- Москва, "Мир", 1991.
Приложение А
Текст main.cpp
#include <iostream.h>
#include <conio.h>
#include "diophantine.h"
#define MAXPOP 25
void main() {
CDiophantine dp(1,2,3,4,30);
int ans;
ans = dp.Solve();
if (ans == -1) {
cout << "Solution not found." << endl;
} else {
gene gn = dp.GetGene(ans);
cout << "The solution set to a+2b+3c+4d=30 is:\n";
cout << "a = " << gn.alleles[0] << "." << endl;
cout << "b = " << gn.alleles[1] << "." << endl;
cout << "c = " << gn.alleles[2] << "." << endl;
cout << "d = " << gn.alleles[3] << "." << endl;
} getch();
}
Приложение Б
Текст Diophantine.h
#include <stdlib.h>
#include <time.h>
#include<stdio.h>
//#define MAXPOP 25
struct gene
{
int alleles[4];
int fitness;
float likelihood;
// Тест на равенство
operator==(gene gn)
{
for (int i=0;i<4;i++)
{
if (gn.alleles[i] != alleles[i]) return false;
}
return true;
}
};
class CDiophantine
{
public:
CDiophantine(int, int, int, int, int); // Конструктор с коэффициентами при а,b,c,d
int Solve(); // Вычисляет решение уравнения
gene GetGene(int i)
{ return population[i];}
protected:
int ca,cb,cc,cd; // Коэффициенты при а,b,c,d
int result;
gene population[MAXPOP]; // Массив из генов - популяция
int Fitness(gene &); // Функция приспособленности
void GenerateLikelihoods(); // Вычисляет вероятности воспроизведения
float MultInv();
int CreateFitnesses();
void CreateNewPopulation();
int GetIndex(float val);
gene Breed(int p1, int p2);
};
CDiophantine::CDiophantine(int a, int b, int c, int d, int res) : ca(a), cb(b), cc(c), cd(d), result(res) {}
int CDiophantine::Solve()
{
int fitness = -1;
// Создаем начальную популяцию
srand((unsigned)time(NULL));
for(int i=0;i<MAXPOP;i++)
{ // Аллели хромосом заполняем
// произвольными числами от 0 до result
for (int j=0;j<4;j++)
{
population[i].alleles[j] = rand() % (result + 1);
}
}
if (fitness = CreateFitnesses())
{
return fitness;
}
int iterations = 0;
while (fitness != 0 || iterations < 50)
{ // Считаем до тех пор пока решение
// не будет найдено или к-во итераций более 50
GenerateLikelihoods();
CreateNewPopulation();
if (fitness = CreateFitnesses())
{
printf("iterations %d \n",iterations);
return fitness;
}
iterations++;
}
return -1;
}
int CDiophantine::Fitness(gene &gn) // Вычисляет коэффициет
// приспособленности для данного гена
{
int total = ca * gn.alleles[0] + cb * gn.alleles[1] + cc * gn.alleles[2] + cd * gn.alleles[3];
return gn.fitness = abs(total - result);
}
int CDiophantine::CreateFitnesses() // Возвращает номер гена в популяции ,
{ // кот. явл. решением данного ур-я
float avgfit = 0;
int fitness = 0;
for(int i=0;i<MAXPOP;i++)
{
fitness = Fitness(population[i]);
// avgfit += fitness;
if (fitness == 0)
{
return i;
}
}
return 0; //Возвращает 0 ,если среди генов данной
// популяции не нашлось решения
}
float CDiophantine::MultInv()
{
float sum = 0;
for(int i=0;i<MAXPOP;i++)
{
sum += 1/((float)population[i].fitness);
}
return sum; //Сумма обратных коэффициентов
// приспособленности всех генов в популяции
}
void CDiophantine::GenerateLikelihoods() //Генерирует вероятности воспроизведения
{
float multinv = MultInv();
float last = 0;
for(int i=0;i<MAXPOP;i++)
{
population[i].likelihood = last = last + ((1/((float)population[i].fitness) / multinv) * 100);
}
}
int CDiophantine::GetIndex(float val) // По данному числу от 0 до 100 возвращает
{ // номер необходимого гена в популяции
float last = 0;
for(int i=0;i<MAXPOP;i++)
{
if (last <= val && val <= population[i].likelihood) return i;
else last = population[i].likelihood;
}
return 4;
}
gene CDiophantine::Breed(int p1, int p2)
{
int crossover = rand() % 3+1; // Число от 1 до 3 - генерируем точку кроссовера.
int first = rand() % 100; // Какой родитель будет первым ?
gene child = population[p1]; // Инициализировать ребенка первым родителем
int initial = 0, final = 4;
if (first < 50) initial = crossover; // Если первый родитель р1(вероятность этого 50%) -
// начинаем с точки кроссовера
else final = crossover; // Иначе - заканчиваем на точке кроссовера
for(int i=initial;i<final;i++)
{ // Кроссовер
child.alleles[i] = population[p2].alleles[i];
if (rand() % 101 < 5) child.alleles[i] = rand() % (result + 1);// 5% - мутация
}
return child; // Возвращаем ребенка
}
void CDiophantine::CreateNewPopulation() {
gene temppop[MAXPOP];
for(int i=0;i<MAXPOP;i++)
{
int parent1 = 0,parent2 = 0, iterations = 0;
while(parent1 == parent2 || population[parent1] == population[parent2])
{
parent1 = GetIndex((float)(rand() % 101));
parent2 = GetIndex((float)(rand() % 101));
if (++iterations > MAXPOP) break; // В этом случае
// родителей выбираем случайно
}
temppop[i] = Breed(parent1, parent2); // Процесс размножения
}
for(i=0;i<MAXPOP;i++)
population[i] = temppop[i];
}
| ... к бронхиальной астме и туберкулезу по генам ферментов метаболизма ... | |
|
РОССИЙСКАЯ АКАДЕМИЯ МЕДИЦИНСКИХ НАУК СИБИРСКОЕ ОТДЕЛЕНИЕ ТОМСКИЙ НАУЧНЫЙ ЦЕНТР ГОСУДАРСТВЕННОЕ УЧРЕЖДЕНИЕ НАУЧНО-ИССЛЕДОВАТЕЛЬСКИЙ ИНСТИТУТ ... Тем не менее, установление генов предрасположенности и изучение их совместной работы, выявление особенностей взаимодействия с факторами негенетической природы в развитии МФЗ, для ... В целом, результаты анализа частот аллелей и генотипов генов GSTT1, GSTM1, GSTP1, CYP2E1 и CYP2C19 у жителей г. Томска показывают значения близкие для европеоидных популяций, что ... |
Раздел: Рефераты по медицине Тип: дипломная работа |
| Структурно-функциональная организация генетического материала | |
|
СТРУКТУРНО-ФУНКЦИОНАЛЬНАЯ ОРГАНИЗАЦИЯ ГЕНЕТИЧЕСКОГО МАТЕРИАЛА Содержание 1. Наследственность и изменчивость - фундаментальные свойства живого 2 ... На популяционно-видовом уровне организации жизни наследственность проявляется в поддержании постоянного соотношения различных генетических форм в ряду поколений организмов данной ... Причиной множественного аллелизма являются случайные изменения структуры гена (мутации), сохраняемые в процессе естественного отбора в генофонде популяции. |
Раздел: Рефераты по биологии Тип: дипломная работа |
| Значение мутаций в эволюции живого мира | |
|
МОРДОВСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ ИМЕНИ Н.П. ОГАРЁВА Институт дополнительного образования Факультет: "Управления и права" специальность ... Было показано, что все наследственные изменения, служащие материалом для эволюции, обязаны мутациям (комбинативная изменчивость, возникающая путём образования новых сочетаний генов ... Мутационный процесс изменяет гены и порядок их расположения в хромосомах и тем самым увеличивает генетическое разнообразие популяций. |
Раздел: Рефераты по биологии Тип: реферат |
| Билеты по биологии 11 класс | |
|
Билет № 1 1. 1. Клеточное строение организмов. Клетка - единица строения каждого организма. Одноклеточные организмы, их строение и жизнедеятельность ... Виды мутаций - генные (изменение последовательности нуклеотидов в гене) и хромосомные (увеличение или уменьшение числа хромосом, потеря их части). 1) возникновение у особей мутаций; 2) скрещивание этих особей и распространение в популяции мутаций - причина ее неоднородности; 3) действие различных форм борьбы за существование ... |
Раздел: Рефераты по биологии Тип: реферат |
| Математические модели в естествознании | |
|
... генетики. 2. Законы Менделя 3. Закон Харди- Вайнберга 4. Принцип стационарности. Кадрильный закон. Неизбежность концепции гена. Вопрос о группах ... Итак, более половины мутаций будут потеряны потомками за два поколения, Можно рассчитать вероятность потери мутации и в последующих поколениях. Если популяция многочисленна, то фактор дрейфа генов оказывает весьма незначительное влияние на частоты аллелей по сравнению с процессами отбора, мутации и миграции. |
Раздел: Рефераты по математике Тип: шпаргалка |