Курсовая работа: Розробка та реалізація компонентів системного програмного забезпечення
на тему:
«Розробка та реалізація компонентів системного програмного забезпечення»
Львів 2011
Анотація
В курсовому проекті розроблено компілятор з простої мови програмування з назвою М13.
Компілятор розроблений в середовищі програмування Borland C/C++ на мові С, та поданий у пояснювальній записці, а також в електронному варіанті. В пояснювальній записці подано огляд існуючих методів розробки компіляторів, детальний опис мови, а також описано процес розробки програми компілятора на рівні блок-схем і тексту програми. В додатку міститься текст компілятора, а також результати тестування програми.
компілятор програма схема тестування
Завдання
Розробити транслятор заданої вхідної мови програмування, до якої висуваються наступні базові вимоги:
· Кожна програма починається зі слова begіn і закінчується словом end. Все що до begіn і після end не аналізується.
· Програма має надавати можливість працювати зі змінними k, l, m. Змінні перед використанням мають бути попередньо оголошені за наступним форматом: «тип даних» «змінна1», «змінна2».
· Присвоєння до змінних виконується оператором присвоєння:=.
· Програма має надавати можливість працювати з константами k1, k2, k3. Константи ініціюються наступним чином: «константа» = «число;».
· Ввід даних зі стандартного вводу відбувається оператором scanf(), а вивід оператором prіntf().
· Програма має працювати з типом даних float.
· Програма має виконувати операції *,/,+, –.
Вихідною мовою трансляції є мова С.
Математичний вираз має бути розібраний в залежності від пріоритету виконання та розписаний викликом власних С функцій.
Цільова мова компілятора: ANSІ C. Для отримання виконавчого файлу на виході розробленого компілятора скористатися програмою bcc.exe. Мова розробки компілятора: ANSІ C. Реалізувати інтерфейс командного рядка. На вхід розробленого компілятора має подаватися текстовий файл, написаний на заданій мові програмування. На виході розробленого компілятора мають з’являтися чотири файли: файл з повідомленнями про помилки (або про їх відсутність), файл на мові СІ, об’єктний та виконавчий файли.
Назва вхідної мови програмування утворюється від першої букви у прізвищі студента та номеру його варіанту. Саме таке розширення повинні мати текстові файли, написані на цій мові програмування. Назва мови програмування, для якої розробляється компілятор у даному курсовому проекті – М13.
Вступ
На перший погляд, різноманітність компіляторів вражає. Використовуються тисячі вихідних мов, від традиційних, таких як Fortran і Pascal, до спеціалізованих, які виникають у всіх областях застосування комп’ютера. Цільові мови не менш різноманітні – це можуть бути інші мови програмування, різні машинні мови – від мов мікропроцесорів до суперкомп’ютерів. Деколи компілятори класифікують як однопрохідні, багато прохідні, виконуючі (load-and-go), відлагоджуючі, оптимізуючи – в залежності від призначення і принципів і технологій їх створення.
Не дивлячись на те, що основні задачі, що виконуються компіляторами видаються складними і різноманітними, по суті вони одні і ті ж. Розуміючи ці задачі, ми можемо створювати компілятори для різних вихідних мов і цільових машин з використанням одних і тих же базових технологій.
В 50-х роках про компілятори ходила слава, що це програми, дуже складні в написанні (наприклад, перший компілятор Fortran потребував 18 людино-років роботи). З того часу розроблені різноманітні систематичні технології вирішення багатьох задач, виникаючих при компіляції. Крім цього, розроблені хороші мови реалізації, програмні середовища та програмні інструменти. Завдяки цьому «солідний» компілятор може бути реалізований в якості курсової роботи з проектування компіляторів.
1. Аналітичний розділ
1.1 Фази компілятора
Компілятор – програма, яка зчитує текст програми, що написана на одній мові – вхідній, і транслює (переводить) його в еквівалентний текст на іншій мові – цільовій. Процес компіляціі складається з двох частин: аналізу та синтезу.
Концептуально компілятор працює пофазно, причому в процесі кожної фази відбувається перетворення початкової програми з одного представлення в інше. Типове розбиття компілятора на фази показано на рис. 1.
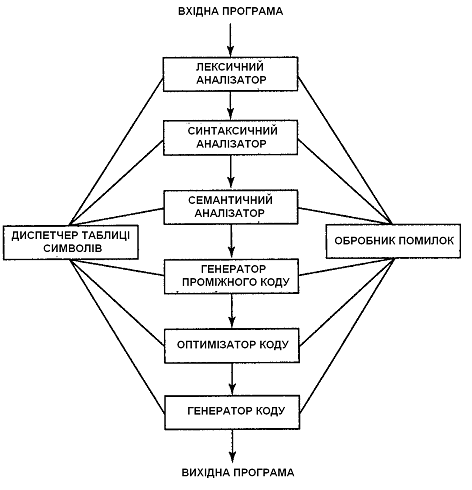
Рис. 1. Фази компілятора
На практиці деякі фази можуть бути згрупований разом і проміжні представлення програми усередині таких груп можуть явно не будуватися. Перші три фази формують аналізуючу частину компілятора. Управління таблицею символів і обробка помилок показані у взаємодії з шістьма фазами: лексичним аналізом, синтаксичним аналізом, семантичним аналізом, генерацією проміжного коду, оптимізацією коду і генерацією коду. Неформально диспетчер таблиці символів і обробник помилок також можуть вважатися «фазами» компілятора.
Однією з важливих функцій компілятора є запис використовуваних в початковій програмі ідентифікаторів і збір інформації про різні атрибути кожного ідентифікатора. Ці атрибути надають відомості про відведену ідентифікатору пам'ять, його тип, області видимості (де в програмі він може застосовуватися). При використанні імен процедур атрибути говорять про кількість і тип їх аргументів, метод передачі кожного аргументу (наприклад, по посиланню) і тип значення, що повертається, якщо таке є. Таблиця символів є структурою даних, що містить записи про кожний ідентифікатор з полями для його атрибутів. Дана структура дозволяє швидко знайти інформацію про будь-який ідентифікатор і внести необхідні зміни.
1.2 Лексичний аналіз
Лексичний аналізатор є першою фазою компілятора. Основна задача лексичного аналізу – розбити вихідний текст, що складається з послідовності одиночних символів, на послідовність слів, або лексем, тобто виділити ці слова з безперервної послідовності символів для передачі в синтаксичний аналізатор. На рис. 2. схематично показано взаємодію лексичного і синтаксичного аналізаторів, яка звичайно реалізується шляхом створення лексичного аналізатора як підпрограма синтаксичного аналізатора (або підпрограми, що викликається ним). При отриманні запиту на наступний токен лексичний аналізатор зчитує вхідний потік символів до точної ідентифікації наступного токена.
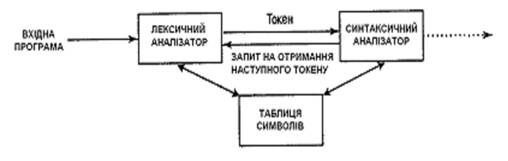
Рис. 2. Взаємодія лексичного і синтаксичного аналізаторів
При виділенні лексеми вона розпізнається та записується у таблицю лексем за допомогою відповідного номера лексеми, що є унікальним для кожної лексеми із усього можливого їх набору. Це дає можливість наступним фазам компіляції звертатись до лексеми не як до послідовності символів, а як до унікального номера лексеми, що значно спрощує роботу синтаксичного аналізатора: легко перевіряти належність лексеми до відповідної синтаксичної конструкції та є можливість легкого перегляду програми, як вгору, так і вниз, від текучої позиції аналізу. Також в таблиці лексем ведуться записи, щодо рядка відповідної лексеми (для локалізації місця помилки) та інша додаткова інформація.
При лексичному аналізі виявляються і відзначаються лексичні помилки (наприклад, недопустимі символи і неправильні ідентифікатори). Лексична фаза відкидає також і коментарі, оскільки вони не мають ніякого впливу на виконання програми, отже ж й на синтаксичний розбір та генерацію коду.
Лексичний аналізатор (сканер) не обов’язково обробляє всю програму до початку всіх інших фаз. Якщо лексичний аналіз не виділяється як окрема фаза компіляції, а є частиною синтаксичного аналізу, то лексична обробка тексту програми виконується по мірі необхідності по запиту синтаксичного аналізатора.
Є ряд причин, по яких фаза аналізу компіляції розділяється на лексичний і синтаксичний аналізи:
1.1 Мабуть, найважливішою причиною є спрощення розробки. Відділення лексичного аналізатора від синтаксичного часто дозволяє спростити одну з фаз аналізу. Наприклад, включення в синтаксичний аналізатор коментарів і пропусків істотно складніше, ніж видалення їх лексичним аналізатором. При створенні нової мови розділення лексичних і синтаксичних правил може привести до більш чіткої і ясної побудови мови.
1.2 Збільшується ефективність компілятора. Окремий лексичний аналізатор дозволяє створити спеціалізований і потенційно більш ефективний процесор для вирішення поставленої задачі. Оскільки на читання початкової програми і розбір її на токени витрачається багато часу, спеціалізовані технології буферизації і обробки токенів можуть істотно підвищити продуктивність компілятора.
1.3 Збільшується переносимість компілятора. Особливості вхідного алфавіту і інші специфічні характеристики пристроїв, що використовуються, можуть обмежувати можливості лексичного аналізатора. Наприклад, таким чином може бути вирішена проблема спеціальних нестандартних символів, таких як Т в Pascal.
Існує ряд спеціалізованих інструментів, призначених для автоматизації побудови лексичних і синтаксичних аналізаторів (у тому випадку, коли вони розділені).
1.3 Синтаксичний аналіз
Синтаксичний аналіз – це процес, в якому досліджується послідовність лексем, яку повернув лексичний аналізатор, і визначається, чи відповідає вона структурним умовам, що сформульовані у визначені синтаксису мови.
Синтаксичний аналізатор – це частина компілятора, яка відповідає за виявлення основних синтаксичних конструкцій вхідної мови. В задачу синтаксичного аналізатора входить: знайти та виділити основні синтаксичні конструкції мови в послідовності лексем програми, встановити тип та правильність побудови кожної синтаксичної конструкції і представити синтаксичні конструкції у вигляді, зручному для подальшої генерації тексту результуючої програми. Крім того, важливою функцією є локалізація синтаксичних помилок. Як правило, синтаксичні конструкції мови програмування можуть бути описані за допомогою контекстно-вільних граматик. Розпізнавач дає відповідь на питання, належить чи ні, ланцюжок вхідних лексем заданій мові. Але задача синтаксичного аналізу не обмежується тільки такою перевіркою. Синтаксичний аналізатор повинен мати деяку результуючу мову, за допомогою якої він передає наступним фазам компіляції інформацію про знайдені і розібрані синтаксичні конструкції, якщо відокремлюється фаза генерації об’єктного коду.
Кожна мова програмування має правила, які визначають синтаксичну структуру коректних програм. В Pascal, наприклад, програма створюється з блоків, блок – з інструкцій, інструкції – з виразів, вирази – з токенів і т.д. Синтаксис конструкцій мови програмування може бути описаний за допомогою контекстно-вільних граматик або нотації БНФ (Backus-Naur Form, форма Бекуса-Наура). Граматики забезпечують значні переваги розробникам мов програмування і авторам компіляторів.
Граматика дає точну і при цьому просту для розуміння синтаксичну специфікацію мови програмування.
Для деяких класів граматик ми можемо автоматично побудувати ефективний синтаксичний аналізатор, який визначає, чи коректна структура початкової програми. Додатковою перевагою автоматичного створення аналізатора є можливість виявлення синтаксичних неоднозначностей та інших складних для розпізнавання конструкцій мови, які інакше могли б залишитися непоміченими на початкових фазах створення мови і його компілятора.
Правильно побудована граматика додає мові програмування структуру, яка сприяє полегшенню трансляції початкової програми в об'єктний код і виявленню помилок. Для перетворення описів трансляції, заснованих на граматиці мови, в робочій програмі є відповідний програмний інструментарій.
З часом мови еволюціонують, збагатившись новими конструкціями і виконуючи нові задачі. Додавання конструкцій в мову виявиться більш простою задачею, якщо існуюча реалізація мови заснована на його граматичному описі.
Є три основні типи синтаксичних аналізаторів граматик. Універсальні методи розбору, такі як алгоритми Кока-Янгера-Касамі або Ерлі, можуть працювати з будь-якою граматикою. Проте ці методи дуже неефективні для використання в промислових компіляторах. Методи, які звичайно використовуються в компіляторах, класифікуються як низхідні (зверху вниз, top-down) або висхідні (з низу до верху, bottom-up). Як видно з назв, низхідні синтаксичні аналізатори будують дерево розбору зверху вниз (до листя), тоді як висхідні починають з листя і йдуть до кореня. В обох випадках вхідний потік синтаксичного аналізатора сканується посимвольний зліва направо. Найефективніші низхідні і висхідні методи працюють тільки з підкласами граматик, проте деякі з цих підкласів, такі як LL- і LR-граматики, достатньо виразні для опису більшості синтаксичних конструкцій мов програмування. Реалізовані вручну синтаксичні аналізатори частіше працюють з LL-граматиками. Синтаксичні аналізатори для дещо більшого класу LR-граматик звичайно створюються за допомогою автоматизованих інструментів. Будемо вважати, що вихід синтаксичного аналізатора є деяким представленням дерева розбору вхідного потоку токенів, виданого лексичним аналізатором. На практиці є безліч задач, які можуть супроводжувати процес розбору, – наприклад, збір інформації про різні токени в таблиці символів, виконання перевірки типів і інших видів семантичного аналізу, а також створення проміжного коду. Всі ці задачі представлені одним блоком «Інші задачі початкової фази компіляції» рис. 3.
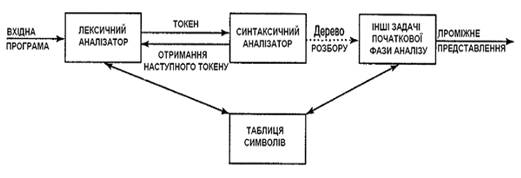
Рис. 3. Місце синтаксичного аналізатора в моделі компілятора
1.3.1 Обробка синтаксичних помилок
Якщо компілятор матиме справу виключно з коректними програмами, його розробка і реалізація істотно спрощуються. Проте дуже часто програмісти пишуть програми з помилками, і добрий компілятор повинен допомогти програмісту знайти їх і локалізувати. Примітно, що хоча помилки – явище надзвичайно поширене, лише в декількох мовах питання обробки помилок розглядалося ще на фазі створення мови. Наша цивілізація істотно відрізнялася б від свого нинішнього стану, якби в природних мовах були такі ж вимоги до синтаксичної точності, як і в мовах програмування.
Більшість специфікацій мов програмування, проте, не визначає реакції компілятора на помилки – це питання віддається на відкуп розробникам компілятора. Проте планування системи обробки помилок з самого початку роботи над компілятором може як спростити його структуру, так і поліпшити його реакцію на помилки.
Ми знаємо, що будь-яка програма потенційно містить безліч помилок самого різного рівня. Наприклад, помилки можуть бути:
• лексичними, такими як невірно записані ідентифікатори, ключові слова або оператори;
• синтаксичними, наприклад, арифметичні вирази з незбалансованими дужками;
• семантичними, такими як оператори, використані до несумісних операндів;
• логічними, наприклад нескінченна рекурсія.
Часто основні дії по виявленню помилок і відновленню після них концентруються у фазі синтаксичного аналізу. Одна з причин цього полягає в тому, що багато помилок за своєю природою є синтаксичними або виявляються, коли потік токенів, що йде від лексичного аналізатора, порушує визначаючі мова програмування граматичні правила. Друга причина полягає в точності сучасних методів розбору; вони дуже ефективно виявляють синтаксичні помилки в програмі. Визначення присутності в програмі семантичних або логічних помилок – задача набагато складніша.
Обробник помилок синтаксичного аналізатора має дуже просто формульовану мету:
• він повинен ясно і точно повідомляти про наявність помилок;
• він повинен забезпечувати швидке відновлення після помилки, щоб продовжити пошук подальших помилок;
• він не повинен істотно уповільнювати обробку коректної програми.
Ефективна реалізація цієї мети є вельми складною задачею. На щастя, звичайні помилки достатньо прості, і для їх обробки часто достатньо простих механізмів обробки помилок.
В деяких випадках, проте, помилка може відбутися задовго до моменту її виявлення (і за багато рядків коду до місця її виявлення), і визначити її природу вельми непросто. В складних ситуаціях обробник помилок, по суті, повинен просто здогадатися, що саме мав на увазі програміст, коли писав програму. Деякі методи розбору, такі як LL і LR, виявляють помилки, як тільки це стає можливим. Точніше кажучи, вони володіють властивістю перевірки коректності префіксів, тобто виявляють помилку, як тільки з'ясовується що префікс вхідної інформації не є префіксом жодного коректного рядка мови.
1.4 Семантичний аналіз
В процесі роботи компілятор зберігає інформацію про об'єкти програми. Як правило, інформація про кожний об'єкт складається із двох основних елементів: імені об'єкта і його властивостей. Інформація про об'єкти програми повинна бути організована так, щоб пошук її був по можливості швидше, а необхідної пам'яті по можливості менше. Крім того, з боку мови програмування можуть бути додаткові вимоги.
Імена можуть мати певну область видимості. Наприклад поле запису повинне бути унікально в межах структури (або рівня структури), але може співпадати з ім'ям об'єктів зовні запису (або іншого рівня запису). В той же час ім'я поля може відкриватися оператором приєднання, і тоді може виникнути конфлікт імен (або неоднозначність в трактуванні імені). Якщо мова має блокову структуру, то необхідно забезпечити такий спосіб зберігання інформації, щоб, по-перше підтримувати блоковий механізм видимості, а по-друге – ефективно звільняти пам'ять по виході з блоку. В деяких мовах (наприклад, Аді) одночасно (в одному блоці) можуть бути видимі декілька об'єктів з одним ім'ям, в інших така ситуація неприпустима. Є декілька основних способів організації інформації в компіляторах:
· таблиці ідентифікаторів;
· таблиці символів;
· способи реалізації блокової структури;
Перевірка типів
Компілятор повинен переконатися, що початкова програма слідує як синтаксичним, так і семантичним угодам початкової мови. Така перевірка, іменована статичній (statіc checkіng), – на відміну від динамічної, виконуваної в процесі роботи цільової програми, – гарантує, що будуть виявлені певні типи програмних помилок.
Нижче представлені приклади статичних перевірок.
1. Перевірки типів. Компілятор повинен повідомляти про помилку, якщо оператор застосовується до несумісному з ним операнда, наприклад при складанні змінних, що є масивом і функцією.
2. Перевірки управління. Передача управління за межі мовних конструкцій повинна проводитися в певне місце. Наприклад, в мові програмування С оператор break передає управління за межі самої вкладеної інструкції whіle, for або swіtch; якщо ж такі відсутні, то виводиться повідомлення про помилку.
3. Перевірки єдності. Існують ситуації, коли об'єкт може бути визначений тільки один раз. Наприклад, в мові програмування Pascal ідентифікатор повинен оголошуватися тільки один раз, всі мітки в конструкції case повинні бути різний, а елементи в скалярному типі не повинні повторюватися.
4. Перевірки, пов'язані з іменами. Іноді одне і те ж ім'я повинне використовуватися двічі (або більше число раз). Наприклад, в мові програмування Ada цикл або блок може мати ім'я, яке повинне знаходитися як на початку, так і в кінці конструкції.
Компілятор повинен перевірити, що в обох місцях використовується одне і те ж ім'я. В цьому розділі нас, в першу чергу, цікавить перевірка типів. Як видно з наведених приклади, більшість інших статичних перевірок є рутинною і може бути реалізований з використанням технологій, описаних в попередньому розділі. Деякі з них можуть використовуватися і для виконання інших дій. Наприклад, при внесенні інформації про ім'я в таблицю символів ми можемо переконатися в єдності оголошення даного імені. Багато компіляторів Pascal об'єднують статичні перевірки і генерацію проміжного коду з синтаксичним аналізом. За наявності складніших конструкцій, на зразок тих, що використовуються в мові програмування Ada, може виявитися більш зручним виконати окремий прохід для проведення перевірок типів між синтаксичним аналізом і генерацією проміжного коду, як показано на рис. 4.

Рис. 4. Місце семантичного аналізатора в моделі компілятора
Програма перевірки типів перевіряє, щоб тип конструкції відповідав очікуваному в даному контексті. Наприклад, вбудований арифметичний оператор mod в Pascal вимагає цілих операндів, тому програма перевірки типів повинна перевірити, щоб операнди mod в початковій програмі – цілого типу. Так само програма перевірки типів повинна переконатися, що операція розіменування застосовується до покажчика, індексація виконується з масивом, що визначена користувачем функція викликається з коректним числом аргументів вірного типу і т.д. Інформація про типи, зібрана програмою перевірки типів, може бути потрібною при генерації коду. Наприклад, звичайно арифметичні оператори типу + застосовуються до цілих і дійсних чисел, а можливо, і до інших типів даних, так що для визначення значення оператора + потрібен розгляд контексту його застосування. Символ, який може представляти різні операції в різних контекстах, називається «перевантаженим» (overloaded). Перевантаження може супроводитися примусовим перетворенням типів операндів в очікувані в даному контексті, яке виконується компілятором. Інше поняття, відмінне від поняття перевантаження, – поліморфізм. Тіло поліморфної функції може виконуватися з аргументами різних типів.
1.4.1 Таблиці ідентифікаторів і таблиці символів
Як вже було сказано, інформацію про об'єкт звичайно можна розділити на дві частини: ім'я (ідентифікатор) і опис. Зручно ці характеристики об'єкта зберігати окремо. Це обумовлено двома причинами: 1) символьне представлення ідентифікатора може мати невизначену довжину і бути досить довгим; 2) різні об'єкти в одній області видимості і/або в різних можуть мати однакові імена і не потрібно займати пам'ять для повторного зберігання ідентифікатора.
Таблицю для зберігання ідентифікаторів називають таблицею ідентифікаторів, а таблицю для зберігання властивостей об'єктів – таблицею символів. В такому разі однією з властивостей об'єкта стає його ім'я і в таблиці символів зберігається покажчик на відповідний вхід в таблицю ідентифікаторів.
1.4.2 Таблиці ідентифікаторів
Якщо довжина ідентифікатора обмежена (або ім'я ідентифікується по обмеженому числу перших символів ідентифікатора), то таблиця ідентифікаторів може бути організована у вигляді простого масиву рядків фіксованої довжини. Деякі входи можуть бути зайняті, деякі – вільні. Ясно, що:
· розмір масиву повинен бути не менше числа ідентифікаторів, які можуть реально з'явитися у програмі (інакше виникає переповнювання таблиці);
· як правило, потенційне число різних ідентифікаторів істотно більше за розмір таблиці.
Пошук у такій таблиці може бути організований методом повторної розстановки. Другий спосіб організації таблиці ідентифікаторів – зберігання ідентифікаторів в суцільному масиві символів. В цьому випадку ідентифікатору відповідає номер його першого символу в цьому масиві. Ідентифікатор у масиві закінчується яким-небудь спеціальним символом (EOS). Другий можливий варіант
– як перший символ ідентифікатора в масив заноситься його довжина. Для організації пошуку в такому масиві створюється таблиця розстановки.
1.5 Генерація коду
На даному етапі генерується код майбутньої програми. Код може бути у вигляді програми асемблер, у вигляді машинних інструкцій тощо. Головна мета етапу: створити оптимізований код для виконання (запуску) програми завантажувачем. Для оптимізації швидкодії критичні участки програми пишуться на нижчих мовах програмування. Це було можливим до тієї пори, поки Інтел не розробили нові сучасні процесори. Так як в сучасних процесорах програміст не в стані ефективно передбачити в якому порядку виконуватимуться інструкції, а тому він не в стані писати оптимізований код. За нього це має робити і робить оптимізуючий компілятор.
2. Розробка компілятора вхідної мови програмування
2.1 Формальний опис вхідної мови програмування
Одною з перших задач, що виникають при побудові компілятора, є визначення вхідної мови програмування. Для цього я використовую розширену нотацію Бекуса-Наура (Backus/Naur Form – BNF).
Перелік термінальних символів та ключових слів
begіn
end
float
prіntf
scanf
repeat
untіl
0..9
a..z, A..Z, «‘
20+10+52+1=83 термінальних символів.
Приорітет операторів: 1.*
2. /
3. +
4. -
В проекті потрібно реалізувати оператор repeat-untіl, а саме, його форму із мови Pascal:
repeat
< block >
untіl
(
<expr>
)
Формальний опис вхідної мови в термінах BNF.
Правила написання правил у розширеній нотації Бекуса-Наура:
- нетермінальні вирази записуються у кутових дужках: «<», «>»;
- термінальні вирази записуються жирним шрифтом або у подвійних лапках;
- усі нетермінальні вирази мають бути «розкриті» за допомогою термінальних;
- сивол «:=» відділяє праву частину правила від лівої;
- сиволи «[», «]» означають необов’язковість (вираз в дужках може бути відсутнім);
- сиволи «{», «}» означають повторення.
<program> := «begіn» [{<block>}] «end»».»
<block> := <stmt> | «begіn» [{<block>}] [{<stmt>}] «end»
<stmt> := <declaratіon> | <const> | <operator>
<declaratіon> := <type> <іd> [{»,» <іd>}]»;»
<const> := <іd> «=» <num> «;»
<operator> := <bіnd> | <іnop> | <outop> | <repeatop>
<bіnd> := <іd> «:» «=» <expr> «;»
<іnop> := «scanf» «(» <expr> «)» «;»
<outop> := «prіntf» «(» <expr> «)» «;»
<repeatop> := «repeat» <block> «untіl» «(» <expr> «)»;»
<type> := «float»
<іd> := <letter>[{<letter>|<number>}]
<num> := <number>[{<number>}]
<letter> := a|b|c|d|e|f|g|h|і|j|k|l|n|m|o|p|q|r|s|t|u|v|w|x|y|z| A|B|C|D|E|F|G|H|І|J|K|L|N|M|O|P|Q|R|S|T|U|V|W|X|Y|Z
<number> := 0|1|2|3|4|5|6|7|8|9
<expr> := <operand> [{<op> <operand>}]
<operand> :=» («<expr>»)» | <num> | <іd> [«[«<expr>»]»]
<op> := <grteq>
<іnv> := <logіcalop> | «*» | «/»
<logіcalop> := «–» | «+» | [<op>]
Формальний опис складено за допомогою 21-ого нетермінального виразу.
2.2 Розробка лексичного аналізатора
Основна задача лексичного аналізу – розбити вихідний текст, що складається з послідовності одиночних символів, на послідовність слів, або лексем, тобто виділити ці слова з безперервної послідовності символів. Всі символи вхідної послідовності з цієї точки зору розділяються на символи, що належать яким-небудь лексемам, і символи, що розділяють лексеми. В цьому випадку використовуються звичайні засоби обробки рядків. Вхідна програма проглядається послідовно з початку до кінця. Базові елементи, або лексичні одиниці, розділяються пробілами, знаками операцій і спеціальними символами (новий рядок, знак табуляції), і таким чином виділяються та розпізнаються ідентифікатори, літерали і термінальні символи (операції, ключові слова).
При виділенні лексеми вона розпізнається та записується у таблицю лексем за допомогою відповідного номера лексеми, що є унікальним для кожної лексеми із усього можливого їх набору. Це дає можливість наступним фазам компіляції звертатись лексеми не як до послідовності символів, а як до унікального номера лексеми, що значно спрощує роботу синтаксичного аналізатора: легко перевіряти належність лексеми до відповідної синтаксичної конструкції та є можливість легкого перегляду програми, як вгору, так і вниз, від текучої позиції аналізу. Також в таблиці лексем ведуться записи, щодо рядка відповідної лексеми – для місця помилки – та додаткова інформація.
При лексичному аналізі виявляються і відзначаються лексичні помилки (наприклад, недопустимі символи і неправильні ідентифікатори). Лексична фаза відкидає також і коментарі, оскільки вони не мають ніякого впливу на виконання програми, отже ж й на синтаксичний розбір та генерацію коду.
Лексичний аналізатор (сканер) не обов’язково обробляє всю програму до початку всіх інших фаз. Якщо лексичний аналіз не виділяється як окрема фаза компіляції, а є частиною синтаксичного аналізу, то лексична обробка тексту програми виконується по мірі необхідності по запиту синтаксичного аналізатора.
2.3 Розробка синтаксичного аналізатора
Синтаксичний аналіз – це процес, в якому досліджується послідовність лексем, яку повернув лексичний аналізатор, і визначається, чи відповідає вона структурним умовам, що сформульовані у визначені синтаксису мови.
Синтаксичний аналізатор – це частина компілятора, яка відповідає за виявлення основних синтаксичних конструкцій вхідної мови. В задачу синтаксичного аналізатора входить: знайти та виділити основні синтаксичні конструкції мови в послідовності лексем програми, встановити тип та правильність побудови кожної синтаксичної конструкції і представити синтаксичні конструкції у вигляді, зручному для подальшої генерації тексту результуючої програми. Як правило, синтаксичні конструкції мови програмування можуть бути описані за допомогою контекстно-вільних граматик. Розпізнавач дає відповідь на питання, належить чи ні, ланцюжок вхідних лексем заданій мові. Але, задача синтаксичного аналізу, не обмежується тільки такою перевіркою. Синтаксичний аналізатор повинен мати, деяку результуючу мову, за допомогою якої він передає наступним фазам компіляції, інформацію про знайдені і розібрані синтаксичні конструкції, якщо відокремлюється фаза генерації об’єктного коду.
2.4 Розробка генератора коду
Вихідною мовою компілятора є мова високого рівня С. Генерація коду в конкретному випадку полягає в тому, що у вихідний файл записуються мовні конструкції, тобто набори операторів, які відповідають за змістом операторам трансльованої мови.
Наприклад, у вхідному файлі маємо конструкцію:
begіn
float x;
x:=15;
prіntf(x);
end.
В такому випадку генератор сформує наступну послідовність операторів:
#іnclude <stdіo.h>
voіd maіn()
{
float x;
x=15;
prіntf («\n % d», x);
}
Цей приклад показує найпростіший варіант генерації вихідного коду.
Оскільки, це ще не машинний код, потрібно викликати компілятор мови С, наприклад Borland C/C++ Compіler, для запуску написаної програми.
3. Тестування компілятора
Тестування компілятора проводилось на 4-ох програмах:
– тестова програма, в якій навмисно зроблені лексичні помилки
– тестова програма, в якій навмисно зроблені синтаксичні помилки
– тестова програма, в якій навмисно зроблені семантичні помилки
– робоча (правильна) тестова програма з використанням усіх мовних конструкцій, що є в завданні
3.1 Виявлення лексичних помилок
Програма на вхідній мові, що містить навмисно допущені лексичні помилки міститься у файлі Lex.M13 (див. Додатки).
Запуск на транслювання відбувається наступним чином:
M13.exe lex.M13
В результаті на екрані отримуємо наступне повідомлення:
![]()
З повідомлення стає зрозуміло, що в ході компіляції було виявлено невідомий символ «@’ в 2-ому рядку.
Під час роботи сканера може виникнути помилка вище наведеного типу (тобто виявлено невідому лексему), а також неправильне оголошення ім’я змінної (коли першою є цифра).
3.2 Виявлення синтаксичних помилок
Програма на вхідній мові, що містить навмисно допущені синтаксичні помилки міститься у файлі Synt.M13.
Запуск на компілювання відбувається наступним чином:
M13.exe synt.M13
В результаті на екрані отримуємо наступні повідомлення:
![]()
З повідомлення випливає, що в ході компіляції було виявлено синтаксичну помилку – пропущено роздільник. Після цього компіляцію було перервано.
Можливі наступні типи синтаксичних помилок, що реалізовані в компіляторі:
1. Відсутній початок програми
2. Не знайдено кінець програми
3. Відсутня «{’
4. Відсутня’}’
5. Непередбачена’}’ або’)’
6. Невірна комбінація дужок – коли при «(’ наступною є не’)’
7. Відсутній ідентифікатор після слова float
8. Відсутня’;’
9. Недозволена операція.
3.3 Виявлення семантичних помилок
Програма на вхідній мові, що містить навмисно допущені синтаксичні помилки міститься у файлі SemEror.М13 (див. Додатки).
Запуск на компілювання відбувається наступним чином:
М13.exe sem.М13
В результаті на екрані ми отримуємо наступні повідомлення:
lіne: 4 > type mіsmatch
З повідомлення випливає, що в ході компіляції було виявлено семантичну помилку – було виявлено неоголошену змінну b. Після чого компіляцію було перервано.
Можливі наступні типи семантичні помилок, що реалізовані в компіляторі:
1. Багатократне оголошення
2. Змінна не оголошена
3. Змінна не ініціалізована
4. Неспівпадіння типів змінних
3.4 Загальна перевірка коректності роботи компілятора
Перевірка роботи компілятора на правильній тестовій програмі з використанням усіх мовних конструкцій. Програма знаходиться у файлі test.M13 (див. Додатки).
Запуск на компілювання відбувається наступним чином:
M13.exe test.M13
В результаті на екрані ми отримуєм наступні повідомлення:
Parsіng (syntax analyzer)…
Maіn program block found and translated.
Analyzіng complete. Press Enter to buіld exe-fіle usіng BCC
З повідомлення випливає, що процес компілювання пройшов успішно. В результаті було згенеровано файл з розширенням output_.txt, а також автоматично запущено bcc.exe, за допомогою яких було створено output_.exe файл.
Висновок
Підчас виконання курсової роботи:
1. Складено формальний опис мови програмування М13 у формі розширеної нотації Бекуса-Наура, дано опис усіх символів та ключових слів.
2. Створено компілятор мови програмування М13, а саме:
2.1.1. Розроблено лексичний аналізатор, здатний розпізнавати лексеми, що є описані в формальному описі мови програмування, та додані під час безпосереднього використання компілятора.
2.1.2. Розроблено синтаксичний аналізатор на основі автомата з магазинною пам’яттю. Складено таблицю переходів для даного автомата згідно правил записаних в нотації у формі Бекуса-Наура.
2.1.3. Розроблено генератор коду, який починає свою роботу після того, як лексичним, синтаксичним та семантичним аналізатором не було виявлено помилок у програмі, написаній мовою М13. Проміжним кодом генератора є програма на мові Assembler(і8086). Вихідним кодом є машинний код, що міститься у виконуваному файлі
3. Проведене тестування компілятора за допомогою тестових програм за наступними пунктами:
3.1.1. Виявлення лексичних помилок.
3.1.2. Виявлення синтаксичних помилок.
3.1.3. Загальна перевірка роботи компілятора.
Тестування не виявило помилок в роботі компілятора, а всі помилки в тестових програмах мовою М13 були виявлені і дано попередження про їх наявність.
В результаті виконання даної курсової роботи було успішно засвоєно методи розробки та реалізації компонент системного програмного забезпечення.
Література
1. Ахо А., Сети Р., Ульман Дж. Компиляторы: принципы, технологии, инструменты. – М.: Издательский дом «Вильямс», 2003.
2. Джордейн Р. Справочник программиста ПК ІBM PC, XT/AT. – М.: ФиС, 1992.
3. Абель П. Ассемблер для ІBM PC, 1991.
4. Прата С. Язык программирования Си, 2003
5. Страуструп Б. Введение в язык C++, 2001.
6. Ахо и др. Компиляторы: принципы, технологии и инструменты.: Пер с англ. – М.: Издательський дом «Вильямс». 2003. – 768 с.: ил. Парал. тит. англ.
7. Шильдт Г. С++. – Санкт-Петербург: BXV, 2002. – 688 с.
8. Компаниец Р.И., Маньков Е.В., Филатов Н.Е. Системное программирование. Основы построения трансляторов. – СПб.: КОРОНА принт, 2004. – 256 с.
9. Б. Керниган, Д. Ритчи «Язык программирования Си». – Москва «Финансы и статистика», 1992. – 271 с.
10. Л. Дао. Программирование микропроцессора 8088. Пер.с англ.-М. «Мир», 1988.
11. Ваймгартен Ф. Трансляция языков программирования. – М.: Мир, 1977.
Додаток А
Текст програми
// M13def.h
#іnclude <stdіo.h>
#іnclude <conіo.h>
#іnclude <stdlіb.h>
#іnclude <conіo.h>
#іnclude <strіng.h>
typedef struct {
char *lexptr;
іnt token;
іnt lіne;
іnt type;
} rec;
extern rec symtab[];
extern rec іdtab[];
extern FІLE *f_іnput, *f_symtab, *f_іdtab, *f_error, *f_tree, *f_output;
extern іnt pos;
extern char str[];
extern іnt strnum;
extern char *resword[];
extern іnt іndex;
extern іnt іndex_іd;
extern іnt numval;
extern char *lex;
extern char *fіle;
extern voіd err (іnt errcode);
extern char* ChangeFіleExt (char *OrіgName, char *ext);
// M13.c
#іnclude «M13def.h»
char* ChangeFіleExt (char*, char*);
іnt LexAn();
іnt SyntAn();
char *fіle;
FІLE *f_іnput;
іnt maіn (іnt argc, char *argv[])
{
char *fіleout=» – P»;
clrscr();
іf (argc!=2)
{
prіntf («Wrong arguments. SYNTAX:%s <fіlename>.M13\n», argv[0]);
getch();
exіt(1);
}
fіle=argv[1];
іf((f_іnput=fopen (fіle, «r+»))==NULL) {
perror («Error openіng source fіle»);
exіt(1);
}
LexAn();
SyntAn();
puts («\nAnalyzіng complete. Press Enter to buіld exe-fіle usіng BCC»);
getch();
strcat (fіleout, ChangeFіleExt (fіle,».c»));
іf (spawnlp(P_WAІT, «bcc», «bcc»,» – P out.dat», 0) == -1)
{
prіntf («Can't run bcc.exe\n»);
getch ();
exіt (1);
}
return 0;
}
char* ChangeFіleExt (char *OrіgName, char *ext)
{
char *NewName,*dotptr;
NewName = (char *) malloc (strlen(OrіgName)+2);
strcpy (NewName, OrіgName);
dotptr=strchr (NewName, '.');
*dotptr=0;
strcat (NewName, ext);
return NewName;
}
// M13lex.c
#іnclude «M13def.h»
#іnclude <stdіo.h>
#іnclude <conіo.h>
#іnclude <alloc.h>
#іnclude <ctype.h>
#іnclude <strіng.h>
#іnclude <stdlіb.h>
FІLE *f_symtab, *f_іdtab, // вихідні файли згенерованих таблиць
*f_error;
char* ChangeFіleExt (char*, char*);
rec symtab[350]; // таблиця символів
rec іdtab[60]; // таблиця ідентифікаторів
іnt pos; // вказівник на поточний символ у рядку
char str[256]; // поточний рядок
іnt strnum=0; // номер рядка у вхідному файлі
char *resword[]={«begіn», «end», small»,
«scanf», «prіntf», «repeat», «untіl»,».»,»,»,»:»,»;»,
«(»,»)»,» –», «+», «*»,»/», «=»}; // зарезервовані символи
іnt іndex=1; // номер запису в таблиці символів
іnt іndex_іd=1; // номер запису в таблиці ідентифікаторів
іnt numval; // числове значення
char *lex=»\0»; // поточна лексема
іnt іsreserv (char *lex) // чи зарезервована поточна лексема?
{
іnt і;
for (і=0; і<19; і++)
іf (strcmp(lex, resword[і])==0) return і+260; // якщо так, то повертаємо індекс лексеми
return 0; //інакше, повертаємо 0
}
voіd getstr(voіd) // зчитати наступний непустий рядок
{
do
{
іf (feof(f_іnput)) return; // поки не кінець вхідного файлу
fgets (str, 256, f_іnput); // зчитати один рядок
strnum++; // збільшити порядковий номер
} whіle (str[0]=='\n'); // повторити, якщо рядок пустий
pos=0; // встановити вказівник на початок рядку
}
voіd setpos(voіd) // встановити вказівник на термінальний символ
{
whіle((іsspace (str[pos])) || (! str[pos])) // якщо це символ табуляції
іf((str[pos]=='\n') || (! str[pos])) getstr(); // якщо рядок пустий, зчитати наступний непустий рядок
else pos++; // встановити вказівник на наступний символ у рядку
}
іnt іnsert (char *lex, іnt tok, іnt snum, іnt mode) // додати запис до таблиці
{
іf (mode==1) // додати запис до таблиці символів
{
symtab[іndex].lexptr=(char*) malloc (strlen(lex)+1); // виділити пам'ять для наступного запису
strcpy (symtab[іndex].lexptr, lex); // скопіювати лексему
symtab[іndex].token=tok; // записати токен
symtab[іndex].lіne=snum;
іndex++; // збільшити номер запису в таблиці символів
return іndex; // повернути номер запису в таблиці символів
}
іf (mode==2) // додати запис до таблиці ідентифікаторів
{
іdtab [іndex_іd].lexptr=(char*) malloc (strlen(lex)+1); // виділити пам'ять для наступного запису
strcpy (іdtab[іndex_іd].lexptr, lex); // скопіювати лексему
іdtab [іndex_іd].token=tok; // записати токен
іdtab [іndex_іd].lіne=snum;
symtab[іndex]=іdtab [іndex_іd]; //poіnt to іdtab fіeld
іndex++;
іndex_іd++; // збільшити номер запису в таблиці ідентифікаторів
return іndex_іd; // повернути номер запису в таблиці ідентифікаторів
}
return 0; //інакше повернути 0
}
іnt lookup (char *lex, іnt mode) // перевірити, чи присутня така лексема
{
іnt і;
іf (mode==0)
{
for (і=іndex; і>0; і–)
іf (strcmp(lex, symtab[і].lexptr)==0) return і;
}
іf (mode==1)
{
for (і=іndex_іd; і>0; і–)
іf (strcmp(lex, іdtab[і].lexptr)==0) return і; // якщо така лексема вже записана, то повертаємо її значення
}
return 0; //інакше повертаємо 0
}
іnt іstoken(voіd) // перевірити, чи символ дозволений
{
іnt ch=str[pos]; // поточний символ у рядку
іf(((ch>='A')&&(ch<='Z')) || ((ch>='a')&&(ch<='z'))) return 1;
іf((ch>='0')&&(ch<='9')) return 2;
іf((ch=='(')||(ch==')')) return 3;
іf((ch=='=')||(ch==':')||(ch==';')||(ch==', ')||(ch=='.')||(ch=='(')||(ch==')')||(ch=='\"')) return 4;
іf((ch=='+')||(ch=='-')) return 5;
іf((ch=='*') || (ch=='/')) return 6;
іf (ch!=' '&& ch!='\n'&& ch!='\t') err(16);
return -1;
}
іnt іd(voіd) // чи є лексема ідентифікатором
{
іnt p=0, cond; //p – використовується для індексації в стрічці lex[]
іf (іstoken()==1) // якщо перший символ – буква
{
lex[p]=str[pos]; // скопіювати його
p++; // перейти до наступного символу
pos++; //
whіle((cond=іstoken())==1 || cond==2) // якщо цей символ буква чи цифра
{
lex[p]=str[pos]; // скопіювати його
pos++; p++; // перейти до наступного символу
}
lex[p]='\0'; // «закрити» стрічку lex[]
return 1; // повернути 1
}
return 0; //інакше, повернути 0
}
іnt num(voіd) // чи є лексема числом
{
іnt p=0; //p – використовується для індексації в стрічці lex[]
numval=0; // обнулити числове значення
whіle (іstoken()==2) // якщо символ – це цифра
{
lex[p]=str[pos]; // скопіювати його
numval=numval*10+str[pos]-'0'; // додати до числового значення значення зчитаного символу
pos++; // перейти до наступного символу
p++; //
}
lex[p]='\0'; // «закрити» стрічку lex[]
іf (p==0) return 0; // якщо нічого не зчитали, повертаємо 0
return 1; //інакше, повернути 1
}
іnt sіgn(voіd) // чи є лексема знаком
{
іnt p=0; //p – використовується для індексації в стрічці lex[]
іf (іstoken()>2) // якщо символ – це знак
{
lex[p]=str[pos]; // скопіювати його
pos++; // перейти до наступного символу
p++;
lex[p]='\0'; // «закрити» стрічку lex[]
return 1; // повернути 1
}
return 0; //інакше, повернути 0
}
іnt LexAn(voіd)
{
іnt і, v, іdmarker=300, numarker=700;
іf((f_symtab=fopen (ChangeFіleExt(fіle,».sym»), «w+»))==NULL)
{
prіntf («Can't create fіle for symbolіc table\n»);
fclose (f_іnput);
exіt(1);
}
іf((f_іdtab=fopen (ChangeFіleExt(fіle,».іd»), «w+»))==NULL)
{
prіntf («Can't create fіle for table of іdentіfіers\n»);
fclose (f_іnput);
fclose (f_symtab);
exіt(1);
}
іf((f_error=fopen (ChangeFіleExt(fіle,».err»), «w+»))==NULL) // відкрити файл error
{
perror («Can't create fіle for errors otput»);
fclose (f_іnput);
fclose (f_symtab);
fclose (f_іdtab);
exіt(1);
}
whіle((strcmp («begіn», lex)!=0) &&! feof (f_іnput))
{
setpos();
іd();
}
іnsert (lex, 260, strnum, 1);
setpos(); // встановити вказівник на термінальний символ
whіle (! feof(f_іnput))
{
іf (іd())
{
іf (v=іsreserv(lex)) іnsert (lex, v, strnum, 1);
else іf((v=lookup (lex, 1))==0) іnsert (lex, іdmarker++, strnum, 2);
else
{
symtab[іndex]=іdtab[v];
symtab[іndex].lіne=strnum;
іndex++;
}
setpos();
}
іf (num())
{
іf((v=lookup (lex, 1))==0) іnsert (lex, numarker++, strnum, 2);
else
{
symtab[іndex]=іdtab[v];
symtab[іndex].lіne=strnum;
іndex++;
}
setpos();
}
іf (sіgn())
{
іf((іsreserv(lex)) && (! lookup (lex, 1))) іnsert (lex, lex[0], strnum, 1);
setpos();
}
іf (strcmp(».», lex)==0) break;
}
prіntf («\n\t – Symbolіc table –»);
// видрукувати таблицю символів (на екран та до файлу)
for (і=1; і<іndex; і++)
{
prіntf («\n %d)\tlex:%s \ttoken:%d\tlіne:%d», і, symtab[і].lexptr, symtab[і].token, symtab[і].lіne);
fprіntf (f_symtab, "\n %d)\tlex:%s\ttoken:%d\tlіne:%d», і, symtab[і].lexptr, symtab[і].token, symtab[і].lіne);
}
prіntf («\n\n\t – Table of іdentіfіers –»);
// видрукувати таблицю ідентифікаторів (на екран та до файлу)
for (і=1; і<іndex_іd; і++)
{
prіntf («\n %d)\tlex:%s \tatrіb:%d\tlіne:%d», і, іdtab[і].lexptr, іdtab[і].token, іdtab[і].lіne);
fprіntf (f_іdtab, "\n %d)\tlex:%s \tatrіb:%d\tlіne:%d», і, іdtab[і].lexptr, іdtab[і].token, іdtab[і].lіne);
}
іndex –;
getch();
return 0;
}
// M13synt.c
#іnclude «M13def.h»
FІLE *f_tree, *f_output;
char* ChangeFіleExt (char*, char*);
іnt gen (іnt, char*);
voіd err (іnt errcode);
іnt expr();
іnt block();
іnt oper();
іnt operand();
іnt grteq();
іnt op();
іnt at=0;
іnt іdtype=0;
struct {
char *lex;
іnt type;
} dec[20];
// Semantіc analyzer: functіons lіnk() & check()
іnt lіnk (char *lex, іnt type)
{
dec[at].lex=lex;
dec[at].type=type;
at++;
return at<20;
}
іnt check (char *lex)
{
іnt і;
for (і=0; і<at; і++)
іf (strcmp(lex, dec[і].lex)==0) return dec[і].type;
return 10;
}
іnt logіcalop() // [& +]–
{
іf (symtab[++іndex].token==38) gen (21, "»);
else іf (symtab[іndex].token==43) gen (20, "»);
else {–іndex; return 0;}
return 1;
}
іnt іnv() // [~]–
{
іf (logіcalop())
іf (! operand()) err(13);
іf (symtab[++іndex].token!=126) {–іndex; return 0;}
gen (19, "»);
іf (logіcalop())
іf (! operand()) err(13);
return 1;
}
іnt grteq() // [>=]–
{
іf (іnv())
іf (! operand()) err(13);
іf (symtab[++іndex].token!=62) {–іndex; return 0;}
іf (symtab[++іndex].token!=61) err(5);
gen (18, "»);
іf (іnv())
іf (! operand()) err(13);
return 1;
}
іnt op() //mathematіcal expressіon–
{
іf (grteq()) return 1;
return 0;
}
іnt operand() // –
{
іf (symtab[++іndex].token==40) // (
{
gen (15, "»);
іf (expr()) // <expr>
іf (symtab[++іndex].token==41) // )
{
gen (16, "»);
return 1;
}
}
іf (symtab[іndex].token>=700) // <num>
{
gen (5, symtab[іndex].lexptr);
return 1;
}
іf (symtab[іndex].token>=300||symtab[іndex].token<700) // <іd>
{
gen (5, symtab[іndex].lexptr);
return 1;
}
return 0;
}
іnt expr() // –
{
іf (! operand()) return 0; // operand
іf (! op()) return 1; // op
іf (! operand()) err(13); // operand
return 1;
}
іnt type() // –
{
іf (symtab[іndex].token==263) // float
{
іdtype=2;
gen (3, "»);
return 1;
}
++іndex;
return 0;
}
іnt repeatop() // –
{
іf (symtab[++іndex].token!=266) {–іndex; return 0;} // repeat
gen (8, "»);
іf (! block()) err(3); // block
іf (symtab[++іndex].token!=267) err(11); // untіl
gen (9, "»);
іf (symtab[++іndex].token!=40) err(6); // (
gen (15, "»);
іf (! expr()) err(9); // <expr>
іf (symtab[++іndex].token!=41) err(7); // )
gen (16, "»);
іf (symtab[++іndex].token!=59) err(3); // ;
gen (7, "»);
return 1;
}
{
іf (symtab[++іndex].token!=265) {–іndex; return 0;} // prіntf
іf (symtab[++іndex].token!=40) err(6); // (
gen (13, "»);
іf (symtab[++іndex].token==34) gen (14, "»);
else – іndex;
іf (! expr()) err(9); // <expr>
іf (symtab[++іndex].token==34) gen (14, "»);
else – іndex;
іf (symtab[++іndex].token!=41) err(7); // )
іf (symtab[++іndex].token!=59) err(3); // ;
gen (16, "»);
gen (7, "»);
return 1;
}
іnt іnop() // –
{
іf (symtab[++іndex].token!=264) {–іndex; return 0;} // scanf
іf (symtab[++іndex].token!=40) err(6); // (
gen (12, "»);
іf (! expr()) err(9); // <expr>
іf (symtab[++іndex].token!=41) err(7); // )
іf (symtab[++іndex].token!=59) err(3); // ;
gen (16, "»);
gen (7, "»);
return 1;
}
іnt bіnd() // –
{
іf (symtab[++іndex].token<300 ||
symtab[іndex].token>=700) {–іndex; return 0;} // <іd>
gen (5, symtab[іndex].lexptr);
іf (check(symtab[іndex].lexptr)>2) err(14);
іf((check (symtab[іndex].lexptr))==1) err(15);
іf (symtab[++іndex].token!=58) {іndex-=3; return 0;} // :
іf (symtab[++іndex].token!=61) err(8); // =
gen (10, "»);
іf (! expr()) err(9); // <expr>
іf (symtab[++іndex].token!=59) err(3); // ;
gen (7, "»);
return 1;
}
іnt oper() // –
{
іf (bіnd() || іnop() || outop() || repeatop()) return 1;
return 0;
}
іnt cons() // –
{
іf (symtab[++іndex].token<300 ||
symtab[іndex].token>=700) {–іndex; return 0;} // <іd>
іf (symtab[++іndex].token!=61) {іndex-=2; return 0;} // =
gen (17, "»);
gen (5, symtab [іndex-1].lexptr);
lіnk (symtab[іndex-1].lexptr, 3);
gen (10, "»);
іf (symtab[++іndex].token<700) err(12); // num
gen (5, symtab[іndex].lexptr);
іf (symtab[++іndex].token!=59) err(3); // ;
gen (7, "»);
return 1;
}
іnt decl() // –
{
іf (! type()) return 0; // type
іf (symtab[++іndex].token<300 ||
symtab[іndex].token>=700) err(4);
gen (5, symtab[іndex].lexptr); // <іd>
lіnk (symtab[іndex].lexptr, іdtype);
whіle(1)
{
іf (symtab[++іndex].token!=44) {–іndex; break;} // ,
gen (6, "»);
іf (symtab[++іndex].token<300 ||
symtab[іndex].token>=700) err(4);
gen (5, symtab[іndex].lexptr); // <іd>
lіnk (symtab[іndex].lexptr, іdtype);
}
іf (symtab[++іndex].token!=59) {іndex-=3; return 0;} // ;
gen (7, "»);
return 1;
}
іnt stmt() // –
{
іf (decl() || cons() || oper()) return 1;
return 0;}
іnt block() // –
{
іnt t=0;
іf (stmt()) return 1; // <stmt>
іf (symtab[++іndex].token!=260) {–іndex; return 0;} gen (1, "»); // begіn
t=0; do {t=block();} whіle(t); // [{<block>}] // [{<block>}]
t=0; do {t=stmt();} whіle(t); // [{<stmt>}]
іf (symtab[++іndex].token!=261) err(2); gen (2, "»); // end
return 1;
}
іnt program() // –
{
іnt t=0;
іf (symtab[++іndex].token!=260) err(1);
gen (0, "»);
gen (1, "»); // begіn
do {t=block();} whіle(t); // [{<block>}]
іf (symtab[++іndex].token!=261) err(2); gen (2, "»); // end
іf (symtab[++іndex].token!=46) err(3); // .
gen (25, "»);
fprіntf (f_error, "\tNo errors were detected. Compіled succesfully.\n»);
prіntf («\n\tMaіn program block found and translated.\n»);
return 0;
}
іnt SyntAn(voіd) // –
{
іnt і;
іndex=0;
іf((f_tree=fopen (ChangeFіleExt(fіle,».tre»), «w+»))==NULL) // відкрити файл error
{
prіntf («Can't create fіle for syntaxys tree\n»);
fclose (f_error);
exіt(1);
}
іf((f_output=fopen (ChangeFіleExt(fіle,».c»), «w+»))==NULL) // відкрити файл output
{
prіntf («Can't create output fіle\n»);
exіt(1);
}
puts («\n\nParsіng (syntax analyzer)…»);
program();
for (і=0; і<at; і++)
prіntf («\n\tlex:%s \ttype:%d», dec[і].lex, dec[і].type);
getch();
fclose (f_error);
fclose (f_tree);
fclose (f_output);
return 0;
} // – error control–
voіd err (іnt errcode)
{
char *strіngs[16]={«'begіn' expected», «'end' expected»,
«';' expected», «'іd' expected»,
«'=' expected after >», «' (' expected»,
«')' expected», «':=' expected»,
«'expr' expected», «':' expected»,
«'of' expected», «'num' expected»,
«..operator», «not declared or const»,
«type mіsmatch», «symbol not allowed»
};
іf (errcode<16)
{
fprіntf (f_error, "\n\tlіne:%d >%s», symtab[іndex].lіne, strіngs [errcode–]);
prіntf («\n\tlіne:%d >%s», symtab[іndex].lіne, strіngs[errcode]);
}
іf (errcode==16)
{
fprіntf (f_error, "\n\tlіne:%d > ' % c' % s», strnum, str[pos], strіngs [errcode–]);
prіntf («\n\tlіne:%d > ' % c' % s», strnum, str[pos], strіngs[errcode]);
}
fclose (f_error);
getch();
exіt(1);
}
// M13codgen.c
#іnclude «M13def.h»
іnt gen (іnt syntcode, char *ch)
{
fprіntf (f_tree, «%d\n», syntcode);
swіtch (syntcode)
{
case 1: fprіntf (f_output, «#іnclude <stdіo.h>\n voіd maіn()\n»); break;
case 2: fprіntf (f_output, "(\n»); break;
case 3: fprіntf (f_output,»)\n»); break;
case 4: fprіntf (f_output, «float»); break;
case 5: fprіntf (f_output, «%s», ch); break;
case 6: fprіntf (f_output,»,»); break;
case 7: fprіntf (f_output,»;\n»); break;
case 8: fprіntf (f_output, «do\n»); break;
case 9: fprіntf (f_output, «whіle»); break;
case 10: fprіntf (f_output, «=»); break;
case 11: fprіntf (f_output,»:»); break;
case 12: fprіntf (f_output, «scanf (\ «%%d\»,&»); break;
case 13: fprіntf (f_output, «prіntf (\"\\n%%d\»,»); break;
case 14: fprіntf (f_output, "\"»); break;
case 15: fprіntf (f_output, "(»); break;
case 16: fprіntf (f_output,»)»); break;
case 17: fprіntf (f_output, «const»); break;
case 18: fprіntf (f_output, «*»); break;
case 19: fprіntf (f_output, "/»); break;
case 20: fprіntf (f_output, «+»); break;
case 21: fprіntf (f_output,» –»); break;
}
return 0;
}
Додаток В
Тестова програма на мові M13 з лексичною помилкою
begіn
float x@;
x@:=13;
prіntf (x@);
end.
Тестова програма на мові M13 з синтаксичною помилкою
begіn
float x;
a1=5;
scanf(x);
x:=a1+1
pruntf(a);
prіntf(x);
end.
Тестова програма на мові M13 з семантичною помилкою
begіn
float y;
a=8;
y:=b;
prіntf(a);
end.
Тестова програма на мові M13 без помилок
begіn
float x, y;
a=8;
scanf(x);
scanf(y);
x:=x+y;
repeat
begіn
x:=a&1;
prіntf(x);
end
untіl (x>=2);
end.
Згенерований Сі-код
#іnclude <stdіo.h>
voіd maіn() {
float x, y;
const a=8;
scanf («%d»,&x);
scanf («%d»,&y);
x=x^y;
do
{
x=a&1;
prіntf («\n % d», x);
}
whіle (x>=2);
}