Курсовая работа: Основы конфигурирования сетевых файловых систем (на примере NFS)
Содержание
Распределенные файловые системы
Общие свойства распределенных файловых систем
Вопросы разработки
Сетевая файловая система NFS
Взгляд со стороны пользователя
Цели разработки
Компоненты NFS
Отсутствие сохранения состояния
Общие сведения о работе и нагрузке NFS
Операции с атрибутами
Операции с данными
Сравнение приложений с разными наборами операций NFS
Характер рабочей нагрузки NFS
"Полностью активные" клиенты
Типовой пример использования NFS
NFS и клиентские ПК
Операционные системы реальной памяти
Более мелкие файлы
Менее требовательные клиенты
Клиент NFS
Взаимодействие с системой виртуальной памяти
Файловая система с репликацией данных (CFS)
Конфигурирование NFS-сервера
Исходные предпосылки
Конфигурация сети (локальной и глобальной)
Сетевая среда, определяемая профилем приложения
Использование высокоскоростных сетей для предотвращения перегрузки
NFS и глобальные сети
Выбор типа сети и количества клиентов
Потребление процессорных ресурсов
Конфигурации дисковой подсистемы и балансировка нагрузки
Организация последовательного доступа в NFS с интенсивным использованием данных
Организация произвольного доступа в NFS с интенсивными запросами атрибутов
Распределение нагрузки по доступу к дискам с помощью программного обеспечения типа Online:DiskSuit
Использование оптимальных зон диска
Заключительные рекомендации по конфигурированию дисков
Нестандартные требования к памяти
PrestoServe/NVSIMM
Обеспечение резервного копирования и устойчивости к неисправностям
Предварительная оценка рабочей нагрузки
Измерение существующих систем
Оценка нагрузки в отсутствие системы
Оценка среды с интенсивным использованием данных
Оценка среды с интенсивным использованием атрибутов
Распределенные файловые системы
Появившаяся в 70-х годах возможность объединения компьютеров в единую сеть произвела революцию в компьютерной промышленности. Эта возможность прежде всего вызвала желание организовать разделение доступа к файлам между различными компьютерами. Первые достижения в этой области были ограничены возможностью копирования целых файлов из одной машины в другую. В качестве примера можно указать программу UNIX-to-UNIX copy (uucp) и File Transfer Protocol (ftp). Однако эти решения не позволяли даже близко подойти к реализации доступа к файлам на удаленной машине, по своим возможностям напоминающего доступ к файлам на локальных дисках.
Только в середине 80-х годов появилось несколько распределенных файловых систем, которые обеспечили прозрачный доступ по сети к удаленным файлам. Это были Network File System (NFS) компании Sun Microsystems (1985), Remote File Sharing system (RFS) компании AT&T (1986) и Andrew File System (AFS) университета Карнеги-Меллона (1995). Эти три системы резко отличались друг от друга по целям разработки, архитектуре и семантике, хотя все они пытались решить одну и ту же фундаментальную проблему. Сегодня RFS доступна практически на всех системах, базирующихся на UNIX System V. Разработка ASF перешла корпорации Transarc, в которой она была развита и превращена в Distributed File System (DFS) - компоненнт распределенной вычислительной среды DSE (Distributed Computing Environment) Open Software Foundation. Но наибольшее распространение получила NFS, которая поддерживается на всех UNIX и многих "не UNIX" системах.
Общие свойства распределенных файловых систем
Традиционная централизованная файловая система позволяет множеству пользователей, работающих на одной системе, разделять доступ к файлам, хранящихся локально на этой машине. Распределенная файловая система расширяет эти возможности, позволяя разделять доступ к файлам пользователям на разных машинах, объединенных между собой с помощью сети. В основе распределенных файловых систем лежит модель клиент-сервер. В данном случае под клиентом понимается машина, которая обращается к некоторому файлу, а под сервером - машина, хранящая файлы и обеспечивающая к ним доступ. Некоторые системы требуют, чтобы клиенты и серверы были разными машинами, в то время как другие допускают, чтобы одна машина работала и как клиент, и как сервер.
Важно отметить различие между распределенными файловыми системами и распределенными операционными системами. Распределенная операционная система, подобная V или Amoeba, для пользователя выглядит как централизованная операционная система, но работает одновременно на нескольких машинах. Она может иметь файловую систему, которая разделяется всеми машинами системы. В отличие от них, распределенная файловая система представляет собой определенный слой программного обеспечения, который управляет связью между традиционными операционными системами и файловыми системами. Этот слой программных средств интегрируется с операционными системами мащин-хостов сети и обеспечивает сервис распределенного доступа к файлам для систем, которые имеют централизованное ядро.
Распределенные файловые системы имеют ряд важных свойств. Каждая конкретная система может обладать всеми или частью этих свойств. Это как раз и создает основу для сравнения различных архитектур между собой.
- Сетевая прозрачность - Клиенты должны иметь возможность обращаться к удаленным файлам пользуясь теми же самыми операциями, что и для доступа к локальным файлам.
- Прозрачность размещения - Имя файла не должно определять его местоположения в сети.
- Независимость размещения - Имя файла не должно меняться при изменении его физического меторасположения.
- Мобильность пользователя - Пользователи должны иметь возможность обращаться к разделяемым файлам из любого узла сети.
- Устойчивость к сбоям - Система должна продолжать функционировать при неисправности отдельного компонента (сервера или сегмента сети). Однако это может приводить к деградации производительности или к исключению доступа к некоторой части файловой системы.
- Масштабируемость - Система должна обладать возможностью масштабирования в случае увеличения нагрузки. Кроме того, должна существовать возможность постепенного наращивания системы путем добавления отдельных компонентов.
- Мобильность файлов - Должна быть возможность перемещения файлов из одного месторасположения в другое на работающей системе.
Вопросы разработки
Имеется несколько важных вопросов, которые рассматриваются при разработке распределенных файловых систем. Они касаются функциональных возможностей, семантики и производительности системы. Различные файловые системы можно сравнивать между собой, выясняя как они решают эти вопросы:
- Пространство имен - Некоторые распределенные файловые системы обеспечивают однородное пространство имен такое, что каждый клиент использует одно и то же путевое имя для доступа к данному файлу. Другие системы позволяют клиенту создавать свое пространство имен путем монтирования разделяемых поддеревьев к произвольным каталогам в иерархии файлов. Оба метода имеют свою привлекательность.
- Операции с сохранением и без сохранения состояний - Сервер сохраняющий состояния обеспечивает хранение информации об операциях клиента между запросами и использует эту информацию о состоянии для корректного обслуживания последующих запросов. Такие запросы как open или seek связаны с изменением состояний, так как кто-то должен запомнить информацию о том, какие файлы открыл клиент, а также все смещения в открытых файлах. В системе без сохранения состояний каждый запрос является "самодостаточным" и сервер не поддерживает устойчивых состояний о клиентах. Например, вместо того, чтобы поддерживать информацию о смещении в открытом файле сервер может требовать от клиента указания смещения в каждой операции чтения или записи. Серверы с сохранением состояний работают быстрее, поскольку они могут использовать знания о состоянии клиента для существенного уменьшения сетевого трафика. Однако они должны иметь и целый комплекс механизмов поддержания согласованного состояния системы и восстановления после ее отказа. Серверы без сохранения состояний более просты в разработке и реализации, но не дают такой высокой производительности.
- Семантика разделения - Распределенная файловая система должна определить семантику, которая применяется когда несколько клиентов одновременно обращаются к одному файлу. Семантика UNIX требует, чтобы все изменения, сделанные одним клиентом, были бы видны другим клиентам, когда они выдают следующий системный вызов read или write. Некоторые файловые системы обеспечивают "семантику сессии" (session semantics), при которой изменения становятся доступными другим клиентам на основе гранулированности системных вызовов open и close. А некоторые системы дают даже еще более слабые гарантии, например, интервал времени, который должен пройти прежде, чем изменения наверняка попадут к другим клиентам.
- Методы удаленного доступа - В простой модели клиент-сервер используется метод удаленного обслуживания, при котором каждое действие инициируется клиентом, а сервер просто представляет собой агента, который выполняет заявки клиента. Во многих распределенных системах, особенно в системах, сохраняющих состояние, сервер играет гораздо более активную роль. Он не только обслуживает запросы клиентов, но и участвует в работе механизма обеспечения когерентности, уведомляя клиентов о всех случаях, когда кэшированные в нем данные становятся недостоверными.
Сетевая файловая система NFS
Компания Sun Microsystems представила NFS в 1985 году как средство обеспечения прозрачного доступа к удаленным файловым системам. Помимо публикации протокола Sun лицензировала его базовую реализацию, которая была использована различными поставщиками для портирования NFS на разные операционные системы. С тех пор NFS стала фактически промышленным стандартом, который поддерживается действительно всеми вариантами системы UNIX, а также некоторыми другими системами, например, VMS и MS-DOS.
Архитектура NFS базируется на модели клиент-сервер. Файл-сервер представляет собой машину, которая экспортирует некоторый набор файлов. Клиентами являются машины, которые имеют доступ к этим файлам. Одна машина может для различных файловых систем выступать как в качестве сервера, так и в качестве клиента. Однако программный код NFS разделен на две части, что позволяет иметь только клиентские или только серверные системы.
Клиенты и серверы взаимодействуют с помощью удаленных вызовов процедур (rpc - remote procedure call), которые работают как синхронные запросы. Когда приложение на клиенте пытается обратиться к удаленному файлу, ядро посылает запрос в сервер, а процесс клиента блокируется до получения ответа. Сервер ждет приходящие запросы, обрабатывает их и отсылает ответы назад клиентам.
Взгляд со стороны пользователя
Сервер NFS экспортирует одну или несколько файловых систем. Каждая экспортируемая файловая система может быть либо целым разделом диска либо его поддеревом. (Различные варианты UNIX имеют свои собственные правила дробления экспортируемых систем. Некоторые из них могут, например, разрешать экспортировать только файловую систему целиком, другие - только одно одно поддерево в каждой файловой системе). Сервер может определить, обычно посредством строк в файле /etc/exports, какие клиенты могут иметь доступ к каждой экспортируемой файловой системе, а также разрешенный режим доступа к ней: "только чтение" или "чтение и запись".
Затем клиентские машины могут подмонтировать такую файловую систему или ее поддерево к любому каталогу в своей существующей иерархии файлов, точно так же, как они смогли бы смонтировать любую локальную файловую систему. Клиент может монтировать каталог с режимом "только чтение", даже если сервер экспортирует его в режиме "чтение и запись". NFS поддерживает два типа монтирования: жесткое и мякгое. От типа монтирования зависит поведение клиента в случае, если сервер не отвечает на запрос. Если файловая система смонтирована жестко, клиент продолжает повторные запросы до получения ответа. В случае мягкого монтирования клиент спустя некоторое время отказывается от повторных запросов и получает ошибку. Когда монтирование произведено, клиент может обращаться к файлам в удаленной файловой системе, используя те же самые операции, которые применяются к локальным файлам. Некоторые системы поддерживают также такой тип монтирования, поведение которого соответствует жесткому монтированию при организации повторных попыток смонтировать файловую систему, но оказывается мягким для последующих операций ввода/вывода.
Операции монтирования NFS менее ограничены по сравнению с операциями монтирования локальных файловых систем. Протокол не требует, чтобы вызывающий операцию монтирования пользователь был привилегированным, хотя большинству пользователей навязываются эти требования. (Например, ULTRIX компании Digital позволяет любому пользователю монтировать файловую систему NFS до тех пор, пока этот пользователь имеет права доступа по записи в каталог точки монтирования. Пользователь может монтировать ту же самую файловую систему к нескольким точкам дерева каталогов, даже к своему подкаталогу. Сервер может экспортировать только свои локальные файловые системы и не может пересекать свои собственные точки монтирования во время прохода по путевому имени. Таким образом, чтобы увидеть все файлы сервера, клиент должен смонтировать все его файловые системы.
На рисунке 4.1 приведен пример. Серверная система nfssrv имеет два диска. Она смонтировала диск 1 к каталогу /usr/local диска 0 и экспортировала каталоги /usr и /usr/local. Предположим, что клиент выполняет следующие четыре операции mount:
mount -t nfs nfssrv:/usr /usr
mount -t nfs nfssrv:/usr/u1 /u1
mount -t nfs nfssrv:/usr /users
mount -t nfs nfssrv:/usr/local /usr/local
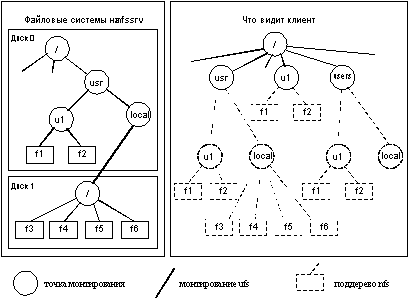
Рис.4.1. Монтирование файловых систем NFS
Все четыре операции монтирования будут успешно выполнены. На клиенте поддерево /usr отражает полное поддерево /usr на nfssrv, поскольку клиент также смонтировал /usr/local. Поддерево /u1 на клиенте отображает поддерево /usr/u1 на nfssrv. Этот пример иллюстрирует, что вполне законно можно монтировать подкаталог экспортированной файловой стстемы (это позволяют не все реализации). Наконец, поддерево /users на клиенте отображает только ту часть поддерева /usr сервера, которая размещена на диске 0. Файловая система диска 1 под /users/local не видна.
Цели разработки
Первоначальная разработка NFS имела следующие цели:
- NFS не должна ограничиваться операционной системой UNIX. Любая операционная система должна быть способной реализовать сервер и клиент NFS.
- Протокол не должен зависеть от каких либо определенных аппаратных средств.
- Должны быть реализованы простые механизмы восстановления в случае отказов сервера или клиента.
- Приложения должны иметь прозрачный доступ к удаленным файлам без использования специальных путевых имен или библиотек и без перекомпиляции.
- Для UNIX-клиентов должна поддерживаться семантика UNIX.
- Производительность NFS должна быть сравнима с производительностью локальных дисков.
- Реализация должна быть независимой от транспортных средств.
Компоненты NFS
Реализация NFS состоит из нескольких компонент. Некоторые из них локализованы либо на сервере, либо на клиенте, а некоторые используются и тем и другим. Некоторые компоненты не требуются для обеспечения основных функциональных возможностеей, но составляют часть расширенного интерфейса NFS:
- Протокол NFS определяет набор запросов (операций), которые могут быть направлены клиентом к серверу, а также набор аргументов и возвращаемые значения для каждого из этих запросов. Версия 1 этого протокола существовала только в недрах Sun Microsystems и никогда не была выпущена. Все реализации NFS (в том числе NFSv3) поддерживают версию 2 NFS (NFSv2), которая впервые была выпущена в 1985 году в SunOS 2.0. Версия 3 протокола была опубликована в 1993 году и реализована некоторыми фирмами-поставщиками. В таблице 3.1 приведен полный набор запросов NFS.
- Протокол удаленного вызова процедур (RPC) определяет формат всех взаимодействий между клиентом и сервером. Каждый запрос NFS посылается как пакет RPC.
- Расширенное представление данных (XDR - Extended Data Representation) обеспечивает машинно-независимый метод кодирования данных для пересылки через сеть. Все запросы RPC используют кодирование XDR для передачи данных. Следует отметить, что XDR и RPC используются для реализации многих других сервисов, помимо NFS.
- Программный код сервера NFS отвечает за обработку всех запросов клиента и обеспечивает доступ к экспортируемым файловым системам.
- Программный код клиента NFS реализует все обращения клиентской системы к удаленным файлам путем посылки серверу одного или нескольких запросов RPC.
- Протокол монтирования определяет семантику монтирования и размонтирования файловых систем NFS.
- NFS использует несколько фоновых процессов-демонов. На сервере набор демонов nfsd ожидают запросы клиентов NFS и отвечают на них. Демон mountd обрабатывает запросы монтирования. На клиенте набор демонов biod обрабатывает асинхронный ввод/вывод блоков файлов NFS.
- Менеджер блокировок сети (NLM - Network Lock Manager) и монитор состояния сети (NSM - Network Status Monitor) вместе обеспечивают средства для блокировки файлов в сети. Эти средства, хотя формально не связаны с NFS, можно найти в большинстве реализаций NFS. Они обеспечивают сервисы не возможные в базовом протоколе. NLM и NSM реализуют функционирование сервера с помощью демонов lockd и statd соответственно.
Отсутствие сохранения состояния
Возможно наиболее важной характеристикой протокола NFS является то, что сервер, чтобы работать корректно, не запоминает состояний и не нуждается ни в какой информации о своих клиентах. Каждый запрос является полностью независимым от других запросов и содержит всю необходимую информацию для его обработки. Серверу не нужно поддерживать никаких записей о прошлых запросах клиентов, за исключением необязательных возможностей, которые могут использоваться с целью кэширования данных или для сбора статистики.
Например, в протоколе NFS отсутствуют запросы по открыванию и закрыванию файлов, поскольку они создали бы информацию о состоянии, которая должна запоминаться сервером. По этой же причине, запросы read и write передают в качестве параметра начальное смещение, в отличие от операций read и write с локальными файлами, которые получают смещение из объекта "открытый файл".
Протокол без сохранения состояний упрощает восстановление после краха системы. Если отказывает клиентская система, никакого восстановления не требуется, поскольку сервер не поддерживает никакой устойчивой информации о клиенте. Если клиент перезагрузился, он может перемонтировать файловые системы и запустить приложения, которые обращаются к удаленным файлам. Серверу не нужно ни знать, ни беспокоиться об отказе клиента.
Если отказывает сервер, то клиент увидит, что на свои запросы он не получает ответы. Тогда он продолжает повторно посылать запросы до тех пор, пока сервер не перезагрузится. (Это справедливо только в случае жесткого монтирования (которое выполняется по умолчанию). При мягком монтировании клиент спустя некоторое время прекращает посылку запросов и возвращает приложению сообщение об ошибке). С этого момента времени сервер начнет получать запросы и может их обрабатывать, поскольку запросы не зависят ни от какой более ранней информации о состоянии. Когда наконец сервер ответит на запросы, клиент перестанет их повторно посылать. У клиента нет никаких средств определить, действительно ли сервер отказал и был перезагружен, или просто медленно выполняет операции.
Протоколы с сохранением состояния требуют реализации сложных механизмов восстановления после отказа. Сервер должен обнаруживать отказы клиента и ликвидировать все состояния, связанные с этим клиентом. Если отказывает и перезагружается сервер, он должен уведомить клиентов так, чтобы они могли заново создать свое состояние на сервере.
Главная проблема работы без сохранения состояния заключается в том, что сервер должен зафиксировать все изменения в стабильной памяти до посылки ответа на запрос. Это означает, что не только данные файла, но и все метаданные, такие как индексные дескрипторы или косвенные блоки должны быть сброшены на диск до возвращения результатов. В противном случае сервер может потерять данные, о которых клиент уверен, что они успешно записались на диск. (Отказ системы может привести к потере данных даже в локальной файловой системе, но в таких случаях пользователи знают об отказе и о возможности потерять данные). Работа без сохранения состояния связана также с другими недостатками. Она требует отдельного протокола (NLM) для обеспечения блокировки файлов. Кроме того, чтобы решить проблемы производительности операций синхронной записи большинство клиентов кэшируют данные и метаданные локально. Но это противоречит гарантиям протокола о соблюдении согласованного состояния.
Общие сведения о работе и нагрузке NFS
По крайней мере на системах Sun чистые серверы NFS представляют собой наиболее простые для конфигурирования широкомасштабные серверы, главным образом потому, что они работают с одним и тем же кодом операционной системы (имеется только одна реализация сервера NFS, которую можно найти на Sun, поскольку она представляет собой связанный с операционной системой продукт). Более того, сами по себе сервисы NFS относительно просты, так как NFS выполняет всего 18 операций, которые своей семантикой ограничены размещением удаленных файлов и обеспечением к ним доступа. Они намного менее сложны, например, по сравнению с сервисами реляционной базы данных, где имеются более 75 операций, определенных стандартом SQL, причем эти операции применяются к сложному набору единиц данных, которые включают структурные отношения. NFS решает только часть этих проблем и поэтому гораздо проще.
Ниже в таблице 3.1 представлены 18 операций NFS. Шесть из них являются основными и представляют громадное большинство реально выполняемых операций как по количеству, так и по потреблению ресурсов: getattr, setattr, lookup, readlink, read и write. Эти операции реализуют поиск и модификацию атрибутов файла, поиск имени файла, разрешение символических связей, а также чтение и запись данных соответственно. Можно явно выделить два принципиально разных набора операций: в частности, операции read и write манипулируют действительным содержимым файла, в то время как другие операции манипулируют атрибутами файлов. Отличия между этими наборами операций определяются прежде всего типом нагрузки, которая ложится при выполнении соответствующего запроса на серверные и сетевые ресурсы системы.
Таблица 4.1. Операции NFS
|
Операция |
Назначение операции |
| getattr | Получает атрибуты файла такие как тип, размер, права доступа и даты модификации |
| setattr | Изменяет значения атрибутов файла/каталога |
| root | Выбирает корень удаленной файловой системы в настоящее время не используется) |
| lookup | Разыскивает файл в каталоге и возвращает расширенный дескриптор файла |
| readlink | Следует символической связи на сервере |
| read | Читает блок данных размером 8 Кбайт |
| wrcache | Записывает блок данных размером 8 Кбайт в удаленный кэш (в настоящее время не используется) |
| write | Записывает блок данных размером 8 Кбайт |
| create | Создает индексный дескриптор файловой системы; может быть файлом или символической связью |
| remove | Удаляет индексный дескриптор файловой системы |
| rename | Изменяет строку имени каталога файла |
| link | Создает жесткую связь в удаленной файловой системе |
| symlink | Создает символическую связь в удаленной файловой системе |
| mkdir | Создает каталог |
| rmdir | Удаляет каталог |
| readdir | Читает строку каталога |
| fsstat | Выбирает динамическую информацию файловой системы |
| null | Ничего не делает; используется для тестирования и хронометража ответа сервера |
В каждой строке каталога файловой системы имеется некоторое количество характеристик, которые описывают файл или доступ к нему, такие как тип строки (файл, символическая связь, каталог), размер, даты обращений, права доступа и т.п. Большинство операций NFS связано с манипулированием этими атрибутами файла.
Операции с атрибутами
Операции с атрибутами создают для системы намного меньшую нагрузку, чем операции с данными. Поскольку размер атрибутов файла очень мал (пара сотен байтов на файл), большинство атрибутов файловой системы, связанных с активными файлами, будет буферизоваться (кэшироваться) в основной памяти сервера. Даже если атрибуты файла не кэшируются, они просто отыскиваются и читаются с диска. После того как атрибуты файла выбраны сервером для какого-либо клиента, обслуживание любого запроса к этим атрибутам заключается лишь в манипулировании битами кэшированных атрибутов и выполнении обычного сетевого протокола. Накладные расходы, связанные с сетевой обработкой этих операций сравнительно высоки, поскольку относительное количество полезных байтов данных в реально передаваемом пакете невелико. Атрибуты пересылаются небольшими пакетами (большинство имеют размер 64-128 байт). В результате операции с атрибутами потребляют относительно небольшую полосу пропускания сети.
Операции с данными
В отличие от операций с атрибутами, операции с данными по определению имеют размер 8 Кбайт. (Это размер блока данных, определенный NFS. Сравнительно недавно анонсированная версия протокола NFS+ допускает блоки данных размером до 4 Гбайт. Однако это существенно не меняет саму природу операций с данными). Кроме того, в то время как для каждого файла имеется только один набор атрибутов, количество блоков данных размером по 8 Кбайт в одном файле может быть большим (потенциально может достигать несколько миллионов). Для большинства типов NFS-серверов блоки данных обычно не кэшируются и, таким образом, обслуживание соответствующих запросов связано с существенным потреблением ресурсов системы. В частности, для выполнения операций с данными требуется значительно большая полоса пропускания сети: каждая операция с данными включает пересылку шести больших пакетов по Ethernet (двух по FDDI). В результате вероятность перегрузки сети представляет собой гораздо более важный фактор при рассмотрении операций с данными.
Как это ни удивительно, но в большинстве существующих систем доминируют операции с атрибутами, а не операции с данными. Если клиентская система NFS хочет использовать файл, хранящийся на удаленном файл-сервере, она выдает последовательность операций поиска (lookup) для определения размещения файла в удаленной иерархии каталогов, за которой следует операция getattr для получения маски прав доступа и других атрибутов файла; наконец, операция чтения извлекает первые 8 Кбайт данных. Для типичного файла, который находится на глубине четырех или пяти уровней подкаталогов удаленной иерархии, простое открывание файла требует пяти-шести операций NFS. Поскольку большинство файлов достаточно короткие (в среднем для большинства систем менее 16 Кбайт) для чтения всего файла требуется меньше операций, чем для его поиска и открывания. Последние исследования компании Sun обнаружили, что со времен операционной системы BSD 4.1 средний размер файла существенно увеличился от примерно 1 Кбайт до немногим более 8 Кбайт.
Для определения корректной конфигурации сервера NFS прежде всего необходимо отнести систему к одному из двух классов в соответствии с доминирующей рабочей нагрузкой для предполагаемых сервисов NFS: с интенсивными операциями над атрибутами или с интенсивными операциями над данными.
Сравнение приложений с разными наборами операций NFS
В общем случае приложения, обращающиеся к множеству небольших файлов, могут характеризоваться как выполняющие интенсивные операции над атрибутами. Возможно наилучшим примером такого приложения является классическая система разработки программного обеспечения. Большие программные системы обычно состоят из тысяч небольших модулей. Каждый модуль обычно содержит файл включения (include file), файл исходного кода, объектный файл и некоторый тип файла управления архивом (подобный SCCS или RCS). Большинство файлов имеют небольшой размер, часто в пределах от 4 до 100 Кбайт. Поскольку обычно во время обслуживания транзакции NFS запросчик блокируется, время обработки в таких приложениях определяется скоростью обработки сервером легковесных запросов атрибутов. В общем числе операций операции над данными занимают менее 40%. В большинстве серверов с очень интенсивным выполнением операций с атрибутами требуется только умеренная пропускная способность сети: пропускная способность сети Ethernet (10 Мбит/с) обычно является адекватной.
Большинство серверов домашних каталогов (home directory) попадают в категорию интенсивного выполнения операций с атрибутами: большинство хранимых файлов небольшие. Кроме того, что эти файлы имеют небольшой размер по сравнению с размером атрибутов, они дают также возможность клиентской системе кэшировать данные файла, устраняя необходимость их повторного восстановления с сервера.
Приложения, работающие с очень большими файлами, попадают в категорию интенсивного выполнения операций с данными. К этой категории относятся, например, приложения из области геофизики, обработки изображений и электронных САПР. В этих приложениях обычный сценарий использования NFS рабочими станциями или вычислительными машинами включает: чтение очень большого файла, достаточно длительную обработку этого файла (минуты или даже часы) и, наконец, обратную запись меньшего по размерам файла результата. Файлы в этих прикладных областях часто достигают размера 1 Гбайт, а файлы размером более 200 Мбайт являются скорее правилом, чем исключением. При обработке больших файлов доминируют операции, связанные с обслуживанием запросов данных. Для приложений с интенсивным выполнением операций с данными наличие достаточной полосы пропускания сети всегда критично.
Например, считается, что скорость передачи данных в среде Ethernet составляет 10 Мбит/с. Такая скорость кажется достаточно высокой, однако 10 Мбит/с составляет всего 1.25 Мбайт/с, и даже эта скорость на практике не может быть достигнута из-за накладных расходов протокола обмена и ограниченной скорости обработки на каждой из взаимодействующих систем. В результате реальная предельная скорость Ethernet составляет примерно 1 Мбайт/с. Но даже эта скорость достижима только почти в идеальных условиях - при предоставлении всей полосы пропускания Ethernet для передачи данных только между двумя системами. К несчастью такая организация оказывается малопрактичной, хотя в действительности нередко случается, что только небольшое число клиентов сети запрашивают данные одновременно. При наличии множества активных клиентов максимальная загрузка сети составляет примерно 35%, что соответствует агрегатированной скорости передачи данных 440 Кбайт/с. Сама природа такого типа клиентов, характеризующихся интенсивным выполнением операций с данными, определяет процесс планирования конфигурации системы. Она обычно определяет выбор cетевой среды и часто диктует тип предполагаемого сервера. Во многих случаях освоение приложений с интенсивным выполнением операций с данными вызывает необходимость перепрокладки сетей.
В общем случае считается, что в среде с интенсивным выполнением операций с данными, примерно более половины операций NFS связаны с пересылкой пользовательских данных. В качестве представителя среды с интенсивным выполнением операций с атрибутами обычно берется классическая смесь Legato, в которой 22% всех операций составляют операции чтения (read) и 15% - операции записи (write).
Характер рабочей нагрузки NFS
Если бы клиенты NFS постоянно выполняли запросы к серверам (или сетям), то в конфигурацию системы пришлось бы включить огромное число выделенных сетей Ethernet или большое число высокоскоростных сетей типа FDDI или FastEthernet. К счастью, обычно трафик NFS имеет достаточно взрывной характер. Клиенты могут выполнять интенсивные запросы к файл-серверам или сетям, но периоды такой интенсивной работы возникают довольно случайно и относительно не очень часто.
"Полностью активные" клиенты
Все остальное время клиенты генерируют либо небольшое число запросов, либо вообще обходятся без них. Везде далее по тексту мы будем называть клиента, который активно выполняет запросы, полностью активным клиентом. По разным причинам многие клиенты (в ряде случаев таковыми оказывается подавляющее большинство клиентов) часто оказываются не очень занятыми, тем самым не очень нагружая, либо вообще не нагружая свой сервер. Например, некоторые клиенты работают на достаточно мощных системах и могут кэшировать большинство, либо все свои данные. Другие системы используются только часть рабочего времени, и даже интенсивно используемые клиенты часто остаются полностью свободными в то время, когда их владельцы обедают или находятся на совещаниях.
Типовой пример использования NFS
В конце концов примеры использования большинства приложений показывают, что клиенты нагружают сервер очень неравномерно. Рассмотрим работу с типичным приложением. Обычно пользователь должен прежде всего считать двоичный код приложения, выполнить ту часть кода, которая отвечает за организацию диалога с пользователем, который должен определить необходимый для работы набор данных. Затем приложение читает набор данных с диска (возможно удаленного). Далее пользователь взаимодействует с приложением манипулируя представлением данных в основной памяти. Эта фаза продолжается большую части времени работы приложения до тех пор, пока в конце концов модифицированный набор данных не запишется на диск. Большинство (но не все) приложения следуют этой универсальной схеме работы, часто с повторяющимися фазами. Приведенные ниже рисунки иллюстрирую типичную нагрузку NFS.
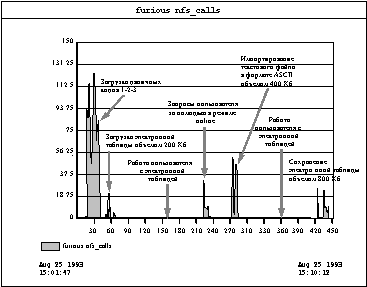
Рис. 4.2. Журнал трафика NFS в Sun
Net Manager для клиента на базе 486/33 PC,
использующего Lotus 1-2-3
На рисунке 4.2 показан фрагмент журнала SunNetManager для ПК 486/33, работающих под управлением MS-DOS. Взрывной характер нагрузки клиентов проявляется очень отчетливо: в короткие промежутки времени видны пики, достигающие 100 операций в секунду, но средняя нагрузка невелика - 7 операций в секунду, а типичная нагрузка возможно составляет около 1 операции в секунду. Этот график снимался с интервалом измерений в одну секунду, чтобы просмотреть скорость транзакций при мелкой грануляции.
Рисунок 4.3 показывает фрагмент журнала SunNetManager для бездискового клиента - SPARCstation ELC с 16 Мбайт памяти, выполняющей различные инструментальные программы автоматизации офисной деятельности. Относительно ровная нагрузка, отраженная на этом графике, является типичной для большинства клиентов (Lotus 1-2-3, Interleaf 5.3, OpenWindows DeskSet, электронной почты с очень большими файлами). Хотя имеются несколько случаев, когда требуется скорость 40-50 операций в секунду, все они имеют небольшую продолжительность (1-5 секунд). Усредненная по времени результирующая общая нагрузка намного ниже: в данном случае существенно ниже 1 операции в секунду, даже если не учитывать свободные ночные часы. На этом графике интервал измерений составляет 10 минут. Заметим, что это бездисковая система с относительно небольшой памятью. Нагрузка от клиентов, оснащенных дисками и большой оперативной памятью будет еще меньше.
Наконец, рисунок 4.4 показывает, как случайная природа работы различных клиентов приводит к эффекту сглаживания нагрузки на сервер. График показывает нагрузку на сервер двадцати бездисковых клиентов с памятью 16 Мбайт в течение десяти дней.
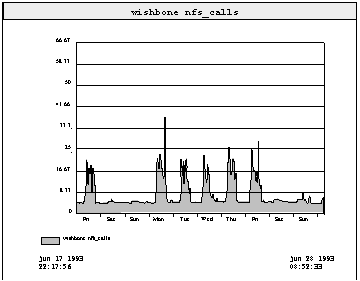
Рис. 4.4. Нагрузка NFS сервера
SPARCserver10 в течение 10 дней. Этот сервер обслуживает
20 бездисковых клиентов, в том числе клиента, показанного на рисунке 4.3.
NFS и клиентские ПК
В отличие от рабочих станций, которые работают под управлением UNIX или VMS, наиболее распространенные операционные системы персональных компьютеров MS-DOS и Windows 3.x не используют одноуровневую виртуальную память для выполнения операций с диском или виртуальных операций дискового ввода/вывода. Системы с одноуровневой виртуальной памятью, подобные Solaris, рассматривают все диски и виртуальный дисковый ввод/вывод как расширение памяти. В результате имеет место тенденция откладывать обращение к диску или сети до тех пор, пока это не окажется абсолютно необходимым. Обычно эта стратегия приводит к более равномерному распределению требований ввода/вывода. В системах с небольшой памятью это иногда приводит к большей активности ввода/вывода, хотя в системах с типовым размером памяти такая стратегия обеспечивает в среднем значительно меньшую общую активность ввода/вывода.
Операционные системы реальной памяти
Операционные системы персональных компьютеров используют более простую двухуровневую модель ввода/вывода, в которой основная память и ввод/вывод файлов управляются раздельно. На практике это приводит даже к еще меньшей нагрузке на подсистему ввода/вывода. Например, когда ПК под Windows вызывает для выполнения Lotus 1-2-3, весь 123.exe копируются в основную память системы. При этом в основную память копируется полный код объемом 1.5 Мбайт, даже если пользователь вслед за этим выполнит команду quit без выполнения любой другой функции. Во время выполнения приложения этот клиент не будет выдавать никаких дополнительных запросов на ввод/вывод этого файла, поскольку весь двоичный код находится резидентно в памяти. Даже если этот код свопируется Windows, он будет откачиваться на локальный диск, что приводит к отсутствию сетевого трафика.
В отличие от этого системы, базирующиеся на Solaris, при вызове приложения копируют в память функцию quit и только те функции, которые необходимы для выполнения его инициализации. Другие функции загружаются в страницы памяти позже, при действительном использовании, что дает существенную начальную экономию, а также распределяет во времени нагрузку на подсистему ввода/вывода. Если клиенту не хватает памяти, соответствующие страницы могут быть уничтожены и затем восстановлены с первоначального источника кодов программ (сетевого сервера), но это приводит к дополнительной нагрузке на сервер. В итоге, нагрузка на подсистему ввода/вывода сервера от ПК-клиентов носит гораздо более взрывной характер, чем для клиентов рабочих станций, выполняющих одни и те же приложения.
Более мелкие файлы
Другой характерной чертой пользовательской базы ПК является то, что файлы, используемые этими клиентами, существенно меньше по размеру, чем аналогичные файлы, используемые на рабочих станциях. Об очень немногих приложениях ПК можно сказать, что они характеризуются "интенсивным использованием данных" (см. разд. 3.1.3) главным образом потому, что управление памятью в операционных системах ПК сложно и ограничено по возможностям. Сама природа такой среды, связанная с интенсивной работой с атрибутами, определяет выбор конфигурации системы для решения проблем организации произвольного доступа.
Менее требовательные клиенты
Хотя наиболее быстрые ПК в настоящее время по производительности ЦП вполне могут оспорить превосходство рабочих станций начального уровня, типовой ПК оказывается значительно менее требовательным сетевым клиентом, чем типичная рабочая станция. Частично это происходит из-за того, что подавляющее большинство существующих ПК все еще базируются на более медленных процессорах 386 (и даже 286), а более медленные процессоры как правило работают с менее требовательными приложениями и пользователями. Более того, эти более медленные процессоры, работающие даже на полной скорости, просто генерируют запросы менее быстро, чем рабочие станции, поскольку внутренние шины и сетевые адаптеры таких ПК не настолько хорошо оптимизированы по сравнению с соответствующими устройствами систем большего размера. Например типовые адаптеры Ethernet ISA, доступные в 1991 году были способны поддерживать скорость передачи данных только на уровне 700 Кбайт/с (по сравнению со скоростью более 1 Мбайт/с, которая достигалась во всех рабочих станциях 1991 года), а некоторые достаточно распространенные интерфейсные платы были способны обеспечивать скорость только на уровне примерно 400 Кбайт/с. Ряд ПК, в частности портативные, используют интерфейсы "Ethernet", которые реально подключаются через параллельный порт. Хотя такое подключение позволяет сэкономить слот шины и достаточно удобно, однако такой интерфейс Ethernet оказывается одним из самых медленных, поскольку многие реализации параллельного порта ограничены скоростью передачи данных 500-800 Кбит/с (60-100 Кбайт/с). Конечно когда в пользовательской базе стали превалировать ПК на базе процессора 486, оснащенные 32-битовыми сетевыми адаптерами DMA, эти различия постепенно стерлись, но полезно помнить, что подавляющее большинство клиентов PC-NFS (особенно в нашей стране) попадают в более старую, менее требовательную категорию. Возможности ПК на базе процессора 33 МГц 486DX, оснащенного 32-битовым интерфейсом Ethernet, продемонстрирована на рисунке 4.2.
Клиент NFS
Взаимодействие с системой виртуальной памяти
В базирующихся на UNIX системах, подобных Solaris, работа подсистемы клиента NFS эквивалентна работе дисковой подсистемы, а именно, она обеспечивает сервис менеджеру виртуальной памяти и, в частности, файловой системе на той же самой основе, что и дисковый сервис, за исключением того, что этот сервис осуществляется с привлечением сети. Это может показаться очевидным, но имеет определенное воздействие на работу системы NFS клиент/сервер. В частности, менеджер виртуальной памяти располагается между приложениями и клиентом NFS. Выполняемые приложениями обращения к файловой системе кэшируются системой виртуальной памяти клиента, сокращая требования клиента к вводу/выводу. Это можно увидеть на рисунке 4.5. Для большинства приложений больший объем памяти на клиенте приводит к меньшей нагрузке на сервер и более высокой общей (т.е. клиент/сервер) производительности системы. Это особенно справедливо для бездисковых клиентов, которые вынуждены использовать NFS в качестве внешнего запоминающего устройства для анонимной памяти.
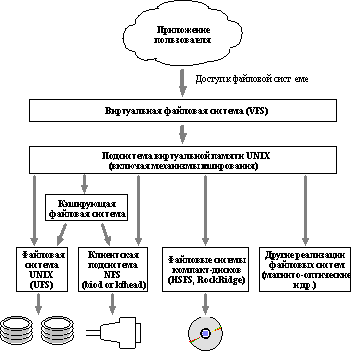
Рис. 4.5. Взаимодействие между приложением, файловой системой виртуальной памяти и NFS
Работа механизмов кэширования системы виртуальной памяти задерживает, а иногда и полностью отменяет работу NFS. Например, рассмотрим бездисковую рабочую станцию, выполняющую 1-2-3. Если и данные, и двоичные коды приложения размещаются удаленно, система должна будет, как и требуется, загрузить в страницы памяти выполняемые двоичные коды 1-2-3 с помощью NFS. Затем с помощью NFS в память будут загружены данные. Для большинства файлов 1-2-3 на типично сконфигурированной рабочей станции данные будут кэшироваться в памяти и оставаться там в течение значительного времени (скорее минуты, а не секунды). Если открывается и остается открытым временный файл, то само открытие файла выполняется немедленно как на клиенте, так и на сервере, но все обновления содержимого файла обычно кэшируются на некоторое время в клиенте перед передачей на сервер. В соответствии с семантикой UNIX-файла, когда файл закрывается все изменения должны быть записаны на внешнее запоминающее устройство, в данном случае на сервер NFS. В альтернативном варианте кэшированные записи могут записываться на внешнее запоминающее устройство с помощью демонов fsflush (Solaris 2.x) или udpated (Solaris 1.x). Как и в случае обычного дискового ввода/вывода, кэшированные данные ввода/вывода NFS остаются в памяти до тех пор, пока память не потребуется для каких-либо других целей.
Когда операция записи выдана в сервер, он должен зафиксировать эти данные в стабильной памяти перед последующей передачей. Однако на клиенте все происходит несколько иначе. Если снова происходит обращение к кэшированным данным, например, если в нашем примере снова обрабатываются некоторые текстовые страницы 1-2-3, то вместо выдачи запросов к серверу, обращение удовлетворяется прямо из виртуальной памяти клиента. Конечно когда клиенту не хватает памяти, для того чтобы выделить пространство для новых данных модифицированные страницы быстро записываются обратно на сервер, а немодифицированные страницы просто исключаются.
Файловая система с репликацией данных (CFS)
Начиная с версии Solaris 2.3 Sun предлагает новую возможность, называемую файловой системой с репликацией данных или кэширующей файловой системой (CFS - Cashed File System). В соответствии со стандартным протоколом NFS файлы выбираются блок за блоком прямо с сервера в память клиента и все манипуляции с ними происходят прямо в этой памяти. Данные записываются обратно на диск сервера. Программное обеспечение CFS располагается между кодом клиента NFS и методами доступа сервера NFS. Когда блоки данных получены кодом клиента NFS, они кэшируются в выделенной области на локальном диске. Локальная копия называется файлом переднего плана (front file), а копия сервера - файлом заднего плана (back file). Любое последующее обращение к кэшированному файлу выполняется к его копии на локальном диске, а не к копии, находящейся на сервере. По очевидным причинам такая организация может существенно уменьшить нагрузку на сервер.
К сожалению, CFS - это не исчерпывающее средство для снижения нагрузки на сервер. Во-первых, поскольку она действительно создает копии блоков данных, система должна обеспечивать определенные мероприятия для поддержания согласованного состояния этих копий. В частности, подсистема CFS периодически проверяет атрибуты файла заднего плана (периодичность такой проверки устанавливается пользователем). Если файл заднего плана был модифицирован, файл переднего плана вычищается из кэша и последующее обращение к (логическому) файлу приведет к тому, что он заново будет выбран с сервера и кэширован. К сожалению, большинство прикладных программ продолжают работать с целым файлом, а не с определенными блоками данных. Например, программы vi, 1-2-3 и ProEngineer читают и записывают свои файлы данных целиком, независимо от действительных целей пользователя. (Вообще говоря, программы, использующие для доступа к файлам команду mmap(2), не обращаются к файлу в целом, в то время как, программы, использующие команды read(2) и write(2), обычно это делают). Как следствие, CFS обычно кэширует весь файл. В результате файловые системы NFS, подвергающиеся частым изменениям, оказываются не очень хорошими кандидатами для CFS: файлы будут постоянно кэшироваться и очищаться, что в конце концов приводит к увеличению общего сетевого трафика, по сравнению с простой работой через NFS.
Проблема поддержания согласованного состояния кэшированных данных между клиентами и сервером приводит также к другой проблеме: когда клиент модифицирует файл, файл переднего плана аннулируется, а файл заднего плана соответствующим образом обновляется. Последующее обращение по чтению к этому файлу будет выбирать и снова кэшировать файл. Если обновление файлов является обычной практикой, этот процесс приводит к большему трафику, чем при работе стандартной NFS.
Поскольку CSF является относительно новой возможностью, к сожалению было сделано очень мало измерений ее поведения при действительном использовании. Однако, сама идея протокола CSF приводит к следующим рекомендациям:
- CSF следует использовать для файловых систем, из которых главным образом осуществляется чтение данных, например, для файловых систем разделяемых кодов приложений.
- CSF особенно полезна для разделения данных между относительно медленными сетями, например WAN, соединенных с помощью линий связи уровня менее чем Т1.
- CSF полезна и для высокоскоростных сетей, соединенных между собой маршрутизаторами, которые вносят задержку.
Конфигурирование NFS-сервера
Исходные предпосылки
Чтобы собрать достаточную и точную информацию для создания конфигурации сервера NFS необходимо ответить на следующие вопросы:
- Является ли нагрузка интенсивной по атрибутам или интенсивной по данным?
- Будут ли клиенты пользоваться кэширующей файловой системой для сокращения числа запросов?
- Сколько в среднем будет полностью активных клиентов?
- Какие типы клиентских систем предполагается использовать и под управлением каких операционных систем они работают?
- Насколько большие файловые системы предполагается использовать в режиме разделения доступа?
- Повторяются ли запросы разных клиентов к одним и тем же файлам (например, к файлам include), или они относятся к разным файлам?
- Каковы количество и тип предполагаемых для эксплуатации сетей? Является ли существующая конфигурация сети подходящей для соответствующего типа трафика?
- Достаточно ли в предполагаемой конфигурации сервера количество ЦП для управления трафиком, связанным с применяемыми сетями?
- Если используются территориальные сети (WAN), имеют ли среда передачи данных и маршрутизаторы достаточно малую задержку и высокую пропускную способность, чтобы обеспечить практичность применения NFS?
- Достаточно ли дисковых накопителей и главных адаптеров SCSI для достижения заданной производительности?
- Требуется ли применение программных средств типа Online:DiskSuit для адекватного распределения нагрузки по доступу к дискам между всеми доступными дисковыми накопителями?
- Если часто используются операции записи NFS, то имеются ли в конфигурации системы NVSIMM?
- Соответствует ли предполагаемая стратегия резервного копирования типу, числу и размещению на шине SCSI устройств резервного копирования?
Конфигурация сети (локальной и глобальной)
Возможно наиболее важным требованием к конфигурации NFS-сервера является обеспечение достаточной полосы пропускания и степени готовности сети. Это требование на практике трансформируется в необходимость создания конфигурации с соответствующим количеством и типом сетей и интерфейсов.
Сетевая среда, определяемая профилем приложения
Как отмечалось ранее, наиболее важным фактором, определяющим выбор конфигурации сети, является доминирующий тип операций NFS, используемых приложениями. Для приложений с интенсивной нагрузкой по данным требуется относительно небольшое количество сетей, но эти сети должны иметь большую полосу пропускания, как например, в сетях FDDI или CDDI. Эти требования могут удовлетворяться также с помощью сетей 100baseT (Ethernet 100 Мбит/с) или ATM (Asynchronous Transfer Mode 155 Мбит/с). Большинство интенсивных по атрибутам приложений работают и при наличии менее дорогой инфраструктуры, хотя может потребоваться большое количество сетей.
Принять решение по выбору типа сети сравнительно просто. Если для работы индивидуального клиента требуется агрегатированная скорость передачи данных, превышающая 1 Мбайт/с, или если для одновременной работы нескольких клиентов необходима полоса пропускания сети, превышающая 1 Мбайт/с, то такие приложения требуют применения высокоскоростных сетей. Реально эта цифра (1 Мбайт/с) искусственно завышена, поскольку она характеризует скорость передачи данных, которую вы гарантируете не превышать. Обычно более разумно рассматривать скорость сети Ethernet равной примерно 440 Кбайт/с, а не 1 Мбайт/с. (Обычно пользователи воспринимают Ethernet как "неотвечающую" уже примерно при 35% загрузке сети. Приведенная здесь цифра 440 Кбайт/с соответствует 35%-ной загрузке линии с пропускной способностью 1.25 Мбайт/с).
Если приложение в установившемся режиме работы не требует широкой полосы пропускания, то возможно будет достаточна менее скоростная сетевая среда типа Ethernet или TokenRing. Эта среда обеспечивает достаточную скорость передачи данных при выполнении операций lookup и getattr, которые доминируют в приложениях с интенсивным использованием атрибутов, а также относительно легкий трафик данных, связанный с таким использованием.
Использование высокоскоростных сетей для предотвращения перегрузки
Высокоскоростные сети наиболее полезны для обслуживания больших групп клиентов с интенсивной нагрузкой по данным скорее из-за более низкой стоимости инфраструктуры, а не по причине обеспечения максимальной пропускной способности при взаимодействии одной системы с другой. Причиной этого является текущее состояние протокола NFS, который в настоящее время работает с блоками данных длиной 8 Кбайт и обеспечивает предварительную выборку только 8 Кбайт (т.е. в одной операции с сервером можно определить максимально 16 Кбайт данных).
Общий эффект такой организации проявляется в том, что максимальная скорость передачи данных между клиентом и сервером, которые взаимодействуют через кольцо FDDI, составляет примерно 2.7 Мбайт/с. (Эта скорость достигается только при добавлении в файл /etc/system на клиенте оператора set nfs: nfs_async_threads = 16. Клиенты SunOS 4.1.x должны запускать 12 демонов biod, а не 8, как это делается по умолчанию). Эта скорость всего в три раза превосходит максимальную скорость, которую обеспечивает Ethernet несмотря на то, что скорость среды FDDI в десять раз больше. (NFS представляет собой протокол прикладного уровня (уровня 7 в модели OSI). Протоколы более низких уровней, такие как TCP и UDP могут работать с гораздо более высокими скоростями, используя те же самые аппаратные средства. Большая часть времени тратится на ожидание ответов и другую обработку прикладного уровня. Другие протоколы прикладного уровня, которые не рассчитаны на немедленное получение ответа и/или подтверждения, также могут эффективно использовать значительно более высокую скорость среды). Пиковая скорость при использовании 16 Мбит/с Token Ring составляет примерно 1.4 Мбайт/с. Сравнительно недавно была анонсирована новая версия протокола NFS+, которая устраняет этот недостаток, разрешая работу с блоками значительно больших размеров. NFS+ допускает пересылку блоков данных почти произвольных размеров. Клиент и сервер договариваются о максимальном размере блока при каждом монтировании файловой системы. При этом размер блока может увеличиваться до 4 Гбайт.
Главное преимущество 100-Мбитных сетей при работе с обычными версиями NFS заключается в том, что эти сети могут поддерживать много одновременных передач данных без деградации. Когда сервер пересылает по Ethernet данные клиенту со скоростью 1 Мбайт/с, то такая передача потребляет 100% доступной полосы пропускания сети. Попытки передачи по этой сети большего объема данных приводят к более низкой пропускной способности для всех пользователей. Те же самые клиент и сервер могут осуществлять пересылки данных со скоростью 2.7 Мбайт/с по кольцу FDDI, но в более высокоскоростной сети эта транзакция потребляет только 21% доступной полосы пропускания. Сеть может поддерживать пять или шесть пересылок одновременно без серьезной деградации.
Эту ситуацию лучше всего можно сравнить со скоростной магистралью. Когда движение небольшое (легкий трафик) скоростная магистраль с двумя полосами и ограничением скорости в 90 км в час почти так же хороша, как и восьмиполосная супермагистраль с ограничением скорости 120 км в час. Но когда движение очень интенсивное (тяжелый трафик) супермагистраль гораздо менее чувствительна к перегрузке.
Сеть FDDI также немного (примерно на 5%) более эффективна по сравнению с Ethernet и Token Ring в среде с интенсивной пересылкой данных, поскольку в ее пакете можно разместить больший объем полезных данных (4500 байт по сравнению с 1500 байт у Ethernet и 2048 байт у Token Ring). При пересылках данных объемом 8 Кбайт требуется обработать всего два пакета по сравнению с пятью-шестью для Token Ring или Ethernet. Но все эти рассуждения имеют смысл только для среды с интенсивной передачей данных, поскольку объем атрибутов при обработке соответствующих запросов настолько мал (по 80-128 байт), что для их передачи требуется только один пакет независимо от типа используемой сети. Если существующая на предприятии проводка сети заранее исключает возможность применения оптоволоконной среды FDDI, то существуют стандарты "FDDI по медным проводам" (CDDI), которые обеспечивают возможность предотвращения перегрузки сети при сохранении существующей разводки на основе витой пары.
Хотя ATM до сих пор не превратилась в повсеместно применяемую технологию, возможно в будущем она станет основным средством для среды с интенсивной пересылкой данных, поскольку она обеспечивает более высокую скорость передачи данных (в настоящее время определены скорости передачи данных 155 Мбит/с, 622 Мбит/с и 2.4 Гбит/с), а также использует топологию точка-точка, в которой каждое соединение клиент-хаб может работать со своей определенной скоростью среды.
NFS и глобальные сети
В реальной жизни часто возникают ситуации, когда клиенты и серверы NFS могут располагаться в разных сетях, объединенных маршрутизаторами. Топология сети может существенно отразиться на ощущаемой пользователем производительности сервера NFS и обеспечиваемого им сервиса. Эффективность обеспечения NFS-сервиса через комплексные сети должна тщательно анализироваться. Но по крайней мере известно, что можно успешно сконфигурировать сети и приложения в глобальных (wide-area) топологиях NFS.
Возможно наиболее важным вопросом в этой ситуации является задержка выполнения операций: время, которое проходит между выдачей запроса и получением ответа. Задержка выполнения операций в локальных сетях не столь критична, поскольку связанные с такими сетями сравнительно короткие расстояния не могут вызвать значительных задержек в среде передачи данных. В глобальных сетях задержки выполнения операций могут происходить просто при транспортировке пакетов из одного пункта в другой. Задержка передачи пакетов складывается из нескольких составляющих:
- Задержка маршрутизатора: маршрутизаторы затрачивают некоторое конечное (и часто существенное) время на выполнение собственно маршрутизации пакетов из одной сети в другую. Заметим, что при построении большинства глобальных сетей (даже при прокладке линий между двумя соседними зданиями) используются по крайней мере два маршрутизатора. На рисунке 4.6 представлена топология типичного университетского кампуса, в котором обычно между клиентом и сервером устанавливаются три или даже четыре маршрутизатора.
- Задержка передачи по сети: физическая среда, используемая для передачи пакетов через глобальные сети, часто может вносить свою собственную существенную задержку, превосходящую по величине задержку маршрутизаторов. Например, организация спутниковых мостов часто связана с появлением очень больших задержек.
- Ошибочные передачи: глобальные сети возможно на порядок величины более восприимчивы к ошибкам передачи, чем большинство локальных сетей. Эти ошибки вызывают значительный объем повторных пересылок данных, что приводит как к увеличению задержки выполнения операций, так и к снижению эффективной пропускной способности сети. Для сетей, сильно подверженных ошибкам передачи, размер блока данных NFS часто устанавливается равным 1 Кбайт, вместо нормальных 8 Кбайт. Это позволяет сократить объем данных, которые должны повторно передаваться в случае появления ошибки.
Если обеспечивается приемлемый уровень безошибочных передач данных, файловый сервис по глобальным сетям вполне возможен. Наиболее часто в конфигурации таких сетей используются высокоскоростные синхронные последовательные линии связи точка-точка, которые подсоединяются к одной или нескольким локальным сетям на каждом конце. В США такие последовательные линии связи обычно имеют скорость передачи данных 1.544 Мбит/с (линия T1) или 56 Кбит/с. Европейские коммуникационные компании предлагают немного большие скорости: 2.048 Мбит/с (линия E1) или 64 Кбит/с соответственно. Доступны даже более высокоскоростные линии передачи данных. Эти арендуемые линии, известные под названием T3, обеспечивают скорость передачи до 45 Мбит/с (5.3 Мбайт/с). На сегодня большинство линий T3 частично используются для передачи данных.

Рис. 4.6. Типичная топология сети при организации связи между зданиями
На первый взгляд кажется, что эти линии значительно более медленные по сравнению с локальными сетями, к которым они подсоединяются. Однако в действительности быстрые последовательные линии (Т1) обеспечивают пропускную способность гораздо более близкую к реальной пропускной способности локальных сетей. Это происходит потому, что последовательные линии могут использоваться почти со 100% загрузкой без чрезмерных накладных расходов, в то время как сети Ethernet обычно насыщаются уже примерно при 440 Кбайт/с (3.5 Мбит/с), что всего примерно вдвое превышает пропускную способность линии Т1. По этой причине файловый сервис по высокоскоростным последовательным линиям связи возможен и позволяет передавать данные с приемлемыми скоростями. В частности, такая организация оказывается полезной при передаче данных между удаленными офисами. В приложениях с интенсивной обработкой атрибутов работа NFS по глобальным сетям может быть успешной, если задержка выполнения операций не является критичной. В глобальной сети короткие пакеты передаются через каждый сегмент достаточно быстро (при высокой пропускной способности), хотя задержки маршрутизации и самой среды часто вызывают значительную задержку выполнения операций.
Выводы:
- Для реализации глобальных сервисов NFS подходят последовательные линии Т1, Е1 или Т3.
- Для большинства применений NFS линии со скоростями передачи 56 и 64 Кбит/с обычно оказываются недостаточно быстрыми.
- При организации NFS через глобальные сети существуют проблемы с задержками сети и маршрутизации. Пропускная способность сети обычно не вызывает проблем.
- Для существенного сокращения трафика по глобальной сети, можно использовать на клиентских системах кэширующую файловую систему (CFS), если только в этом трафике не доминируют операции записи NFS.
Выбор типа сети и количества клиентов
Учитывая вышеизложенные соображения, для определения надлежащего типа и числа сетей могут быть использованы следующие эмпирические правила:
- Если в приложении доминируют операции с данными, следует выбрать сеть FDDI или какую-нибудь другую высокоскоростную сеть. Если по материально-техническим причинам прокладка оптоволоконных кабелей не представляется возможной, следует рассмотреть возможность реализации FDDI на витых парах. При создании новой системы следует иметь в виду, что для сетей ATM используются те же самые кабели, что и для FDDI.
- В конфигурации сети необходимо предусмотреть одно кольцо FDDI для каждых 5-7 клиентов, одновременно полностью активных в смысле NFS и интенсивно работающих с данными. Следует помнить, что очень немногие интенсивные по данным приложения непрерывно генерируют запросы к серверу NFS. В типичных интенсивных по данным приложениях автоматизации проектирования электронных устройств и системах исследования земных ресурсов это часто позволяет иметь до 25-40 клиентов на кольцо.
- В системах с интенсивным использованием данных, где существующая система кабелей вынуждает использовать Ethernet, следует предусмотреть отдельную сеть Ethernet для каждых двух активных клиентов и максимально 4-6 клиентов на одну сеть.
- Если приложение связано с интенсивной обработкой атрибутов, то вполне достаточно построения сетей Ethernet или Token Ring.
- В среде с интенсивным использованием атрибутов следует иметь одну сеть Ethernet на 8-10 полностью активных клиентов. Неблагоразумно превышать уровень 20-25 клиентов на Ethernet независимо от требований из-за резкой деградации, возникающей в случае активности многих клиентов. В качестве контрольной точки с точки зрения здравого смысла можно считать, что Ethernet способен поддерживать 250-300 NFS-операций в секунду на тесте SPECsfs_97 (LADDIS) даже с высоким уровнем коллизий. Неразумно превышать уровень 200 операций NFS в секунду в установившемся режиме.
- Следует конфигурировать одну сеть TokenRing для каждых 10-15 полностью активных клиентов в среде с интенсивным использованием атрибутов. Если необходимо, к сети Token Ring можно подключать 50-80 клиентов благодаря превосходным характеристикам этого типа сети по устойчивости к деградации при тяжелой нагрузке (по сравнению с Ethernet).
- Для систем, которые обеспечивают сервис нескольким классам пользователей имеют смысл смешанные конфигурации сетей. Например, и FDDI, и Token Ring подходят для сервера, который поддерживает как приложения, связанные с отображением документов (интенсивные по данным), так и группу ПК, выполняющих приложение финансового анализа (возможно интенсивное по атрибутам).
Потребление процессорных ресурсов
Поскольку многие компьютеры представляют собой универсальные системы, которые допускают достаточно большое расширение количества подключенным к ним периферийных устройств, почти всегда существует возможность сконфигурировать систему так, что основным ограничивающим фактором станет процессор. В среде NFS мощность процессора расходуется непосредственно для обработки протоколов IP, UDP, RPC и NFS, а также для управления устройствами (дисками и сетевыми адаптерами) и манипуляциями с файловой системой (грубо можно считать, что потребление процессорного времени нарастает пропорционально в соответствии с указанным здесь порядком).
Например, компания Sun рекомендует следующие эмпирические правила для конфигурирования NFS-серверов:
- Если у заказчика преобладает интенсивная по атрибутам среда и имеется менее 4-6 сетей Ethernet или Token Ring, то для работы в качестве NFS-сервера вполне достаточно однопроцессорной системы. Для систем меньшего размера с одной-двумя сетями достаточно процессорной мощности машины начального уровня SPARCserver 4. Для очень большой интенсивной по атрибутам среды со многими сетями рекомендуются двухпроцессорные системы подобные SPARCstation 20 Мodel 502 или двухпроцессорные конфигурации SPARCserver 1000 или SPARCcenter 2000.
- Если среда интенсивная по данным, то рекомендуется конфигурировать по два процессора SuperSPARC с SuperCashe на каждую высокоскоростную сеть (подобную FDDI). Если существующие ограничения по организации кабельной проводки диктуют использование в такой среде Ethernet, то рекомендуется конфигурировать один процессор SuperSPARC на каждые 4 сети Ethernet или Token Ring.
Конфигурации дисковой подсистемы и балансировка нагрузки
Подобно конфигурации сети, конфигурация дисков определяется типом клиентов. Производительность дисковых накопителей меняется в широких пределах в зависимости от реализации требуемых от них методов доступа. Произвольный доступ по своей природе почти всегда некэшируем и требует, чтобы осуществлялось позиционирование дисковой каретки фактически для каждой операции ввода/вывода (механическое перемещение, которое существенно снижает производительность). При организации последовательного доступа, особенно последовательных обращений по чтению, требуется намного меньшее количество механических перемещений каретки диска на каждую операцию (обычно одно на цилиндр, примерно 1 Мбайт), что дает гораздо более высокую пропускную способность.
Организация последовательного доступа в NFS с интенсивным использованием данных
Опыт показывает, что большинство обращений к файлам в среде с интенсивным использованием данных являются последовательными, даже на серверах, которые поставляют данные многим клиентам. При этом, как правило, операционная система выполняет большую работу по организации доступа к своим устройствам. Поэтому если необходимо обеспечить сервис для приложений с интенсивным использованием данных следует выбирать конфигурацию для работы в последовательной среде.
Например, в свое время диск емкостью 2.9 Гбайт был самым быстрым диском Sun для последовательных приложений. Он мог обеспечивать обмен данными через файловую систему со скоростью 4.25 Мбайт/с. Это был также самый емкий диск Sun и поэтому оказывался наиболее удобным для хранения больших объемов данных. Высокая скорость обмена данными по отношению к скорости шины SCSI (пиковая пропускная способность шины составляет 20 Мбайт/с) определяет оптимальную конфигурацию дисковой подсистемы: 4-5 активных дисков емкостью 2.9 Гбайт на один главный адаптер (DWI/S). Если требуется дополнительная емкость для хранения данных, то подключение большего числа дисков на каждый главный адаптер вполне допустимо, но это не даст увеличения производительности дисковой подсистемы.
Диски 2.9 Гбайт в системах Sun размещаются на устанавливаемых в стойку шасси (до 6 дисковых накопителей на шасси). Каждое шасси может быть подключено к двум независимым главными адаптерами SCSI. Такая возможность очень рекомендуется для конфигурирования серверов, обслуживающих клиентов, выполняющих интенсивные запросы к данным. Чтобы обеспечить максимальную емкость дисковой памяти до 12 дисков могут быть сконфигурированы на одном адаптере DWI/S. Однако максимальная производительность достигается только с 4-5 накопителями.
В среде с последовательным доступом достаточно просто подсчитать, сколько дисков потребуется для обслуживания пиковой нагрузки. Каждый полностью активный клиент может потребовать от дисковой подсистемы пропускной способности до 2.7 Мбайт/с. (Здесь предполагается использование высокоскоростных сетей со скоростью передачи в среде 100 Мбит/с и выше). Хорошее первое приближение дает обеспечение одного 2.9 Гбайт диска для каждых трех полностью активных клиентов. Предлагается именно такое соотношение, хотя каждый диск может передавать данные со скоростью более 4 Мбайт/с, а клиенты запрашивают только 2.7 Мбайт/с, поскольку работа двух активных клиентов на одном диске будет вызывать постоянное перемещение каретки вперед и назад между группами цилиндров (или даже файловыми системами) и приводить к существенно более низкой пропускной способности. Чтобы сбалансировать работу дисков, а также ускорить некоторые типы пересылок данных можно использовать специальное программное обеспечение типа Online:DiskSuit 2.0 (разд. 4.3.4.3). Если в качестве сетевой среды применяется Ethernet или 16 Мбит Token Ring, то достаточно одного диска на каждого полностью активного пользователя. Если используется NFS+, это отношение сильно меняется, поскольку NFS+ обеспечивает индивидуальную пропускную способность в режиме клиент/сервер примерно на скорости сетевой среды.
Организация произвольного доступа в NFS с интенсивными запросами атрибутов
В отличие от среды с интенсивным использованием данных, действительно все обращения к файлам в среде с интенсивным использованием атрибутов приводят к произвольному доступу к дискам. Когда файлы небольшие, в доступе к данным доминирует выборка строк каталогов, строк индексных дескрипторов и нескольких первых косвенных блоков (требуется позиционирование, чтобы получить действительно все куски мета-информации), а также каждого блока данных пользователя. В результате каретка диска тратит значительно больше времени "рыская" между различными кусками мета-информации файловой системы, чем на собственно выборку данных пользователя.
Как следствие, критерии выбора конфигурации для интенсивной по атрибутам NFS существенно отличаются от критериев для среды с интенсивным использованием данных. Поскольку в общем времени, которое требуется для выполнения операции произвольного ввода/вывода доминирует время позиционирования каретки диска, общая пропускная способность диска в этом режиме оказывается намного меньше, чем в режиме последовательного доступа. Например, типовой дисковый накопитель 1993 года выпуска способен работать со скоростью 3.5-4 Мбайт/с в последовательном режиме доступа, но обеспечивает выполнение только 60-72 операций произвольного доступа в секунду, что соответствует примерно скорости 500 Кбайт/с. При этих условиях шина SCSI оказывается гораздо меньше занятой, что позволяет сконфигурировать на ней намного больше дисков, прежде чем встанет вопрос о перегрузке шины.
Кроме того, одной из задач выбора конфигурации системы является обеспечение наибольшего разумного числа дисковых накопителей, поскольку именно оно определяет число дисковых кареток, которые представляют собой ограничивающий фактор в дисковой подсистеме. К счастью, сама природа интенсивных по атрибутам приложений предполагает, что требования к объему дисковой памяти сравнительно небольшие (по отношению к интенсивным по данным приложениями). В этих условиях часто бывает полезно включать в конфигурацию системы вместо одного большого диска два или даже четыре диска меньшей емкости. Хотя такая конфигурация обойдется несколько дороже в пересчете на мегабайт памяти, ее производительность существенно повысится. Например, два диска емкостью 1.05 Гбайт стоят примерно на 15% дороже, чем один диск емкостью 2.1 Гбайт, но они обеспечивают более чем в два раза большую пропускную способность произвольного ввода/вывода. Примерно тоже самое отношение остается справедливым между дисками емкостью 535 Мбайт и диском 1.05 Гбайт (см. таблицу 4.2).
Таким образом, для интенсивной по атрибутам среды лучше конфигурировать большее число небольших дисков, подсоединенных к умеренному числу главных адаптеров SCSI. Диск емкостью 1.05 Гбайт имеет прекрасное фирменное программное обеспечение, которое сводит к минимуму загрузку шины SCSI. Диск емкостью 535 Мбайт имеет сходные характеристики. Рекомендуемая конфигурация - это 4-5 полностью активных 535 Мбайт или 1 Гбайт дисков на одну шину SCSI, хотя 6 или 7 дисков также могут работать не вызывая серьезных конфликтов на шине.
Таблица 4.2. Характеристики некоторых дисковых накопителей
|
Емкость |
Время |
Среднее время |
Количество операций в секунду, Мбайт/с |
|
|
|
Произвольный |
| 535 Мб | 5.56 мс | 12 мс | 57, 0.456451, 3.6 |
| 1.05 Гб | 5.56 мс | 11 мс | 67, 0.536480, 3.8 |
| 2.1 Гб | 5.56 мс | 11 мс | 62, 0.496494, 4.0 |
| 2.9 Гб | 5.56 мс | 10.5 мс | 72, 0.576521, 4.2 |
В очень больших системах с интенсивным использованием атрибутов, которые требуют использования дисков емкостью 2.9 Гбайт (по причинам конструкции сервера или объема данных), оптимальная производительность достигается при 8 полностью активных дисках на шине fast/wide SCSI, хотя могут быть установлены и 9 или 10 дисковых накопителей только с небольшой деградацией времени ответа ввода/вывода. Как и в интенсивных по данным системах, конфигурирование большего числа накопителей на шине SCSI обеспечивает дополнительную емкость памяти, но не дает дополнительных результатов производительности.
Сложно дать какие-либо специальные рекомендации по числу дисковых кареток, которые требуются в интенсивной по атрибутам среде, поскольку нагрузки меняются в широких пределах. В такой среде время ответа сервера зависит от того, насколько быстро атрибуты могут быть найдены и переданы клиенту. Опыт показывает, что часто оказывается полезно конфигурировать по крайней мере один дисковый накопитель на каждых двух полностью активных клиентов, чтобы минимизировать задержки выполнения этих операций, но задержка может быть сокращена и с помощью установки дополнительной основной памяти, позволяющей кэшировать часто используемые атрибуты. По этой причине диски меньшей емкости часто оказываются более предпочтительны. Например, лучше использовать 8 дисков емкостью 535 Мбайт вместо двух дисков емкостью 2.1 Гбайт.
Распределение нагрузки по доступу к дискам с помощью программного обеспечения типа Online:DiskSuit
Одной из общих проблем серверов NFS является плохая балансировка нагрузки между дисковыми накопителями и дисковыми контроллерами. Например, для поддержки некоторого числа бездисковых клиентов часто используется конфигурация системы с тремя дисками. Первый диск содержит операционную систему сервера и двоичные коды приложений; второй диск - файловые системы root и swap для всех бездисковых клиентов, а третий диск - домашние каталоги пользователей бездисковых клиентов. Такая конфигурация сбалансирована скорее по логическому принципу, а не по реальной физической нагрузке на диски. В такой среде диск, хранящий область подкачки (swap) для бездисковых клиентов, обычно оказывается намного более загруженным, чем любой из двух других дисков: этот диск почти все время будет загружен на 100%, а другие два в среднем на 5%. Подобные принципы распределения часто применяются также и для работы в другой среде.
Для обеспечения прозрачного распределения доступа по нескольким дисковым накопителям с успехом можно использовать функции расщепления и/или зеркалирования, которые поддерживаются специальным программным обеспечением типа Online:DiskSuit. (Конкатенация дисков достигает минимальной степени балансировки нагрузки, но только когда диски являются относительно полными). В среде с интенсивным использованием данных расщепление с небольшим перекрытием обеспечивает увеличение пропускной способности дисков, а также распределение нагрузки обслуживания. Расщепление дисков существенно улучшает также производительность операций последовательного чтения и записи. Хорошим начальным приближением для определения величины перекрытия является отношение 64 Кбайт/число дисков в полосе. В среде с интенсивным использованием атрибутов, для которых характерен произвольный доступ, установленное по умолчанию перекрытие (один цилиндр диска) является наиболее подходящим.
Хотя функция зеркалирования дисков в DiskSuit прежде всего разработана для обеспечения устойчивости к отказам, побочным эффектом ее использования является улучшение времени доступа и уменьшение нагрузки на диски за счет предоставления доступа к двум или трем копиям одних и тех же данных. Это особенно справедливо для среды, в которой доминируют операции чтения. Операции записи на зеркальных дисках обычно выполняются более медленно, поскольку для каждой запрошенной логической операции в действительности необходимо выполнить две или три операции записи.
В настоящее время в компьютерной промышленности рекомендуется максимальная степень загрузки каждого дискового накопителя на уровне 60-65%. (Степень загрузки диска можно выяснить с помощью команды iostat(1)). Обычно на практике не удается заранее спланировать распределение данных так, чтобы обеспечить этот рекомендованный уровень загрузки дисков. Для этого необходимо выполнить несколько итераций, которые включают съем статистики и соответствующую реорганизацию данных. Более того, следует отметить, что типовое распределение нагрузки на диски со временем меняется, причем иногда радикально. Поэтому распределение данных, которое обеспечивало даже очень хорошую работу системы во время инсталляции, может давать очень слабые результаты год спустя. При оптимизации распределения данных на существующем наборе дисковых накопителей имеется множество других соображений второго порядка.
Использование оптимальных зон диска
Многие диски, которые сегодня поставляются компаниями-поставщиками компьютеров, пользуются механизмами кодирования, которые получили название "записи битовых зон - zone bit recording"). Этот тип кодирования позволяет использовать геометрические свойства вращающегося диска упаковывать больше данных на тех частях поверхности диска, которые находятся дальше от его центра. Практический эффект заключается в том, что количество адресов с меньшими номерами (которые соответствуют внешним цилиндрам диска) превосходят количество адресов с большими номерами. Обычно это в пределе составляет 50%. Такой способ кодирования в большей степени сказывается на производительности последовательного доступа к данным (например, для диска 2.1 Гбайт указывается диапазон скоростей передачи данных 3.5-5.1 Мбайт/с), но он также сказывается на производительности произвольного доступа к диску. Данные, расположенные на внешних цилиндрах диска, не только проходят быстрее под головками чтения/записи (поэтому и скорость передачи данных выше), но эти цилиндры также просто больше по размеру. Заданное количество данных можно распределить по меньшему числу больших цилиндров, что приведет к меньшему числу механических перемещений каретки.
Заключительные рекомендации по конфигурированию дисков
Основные правила по конфигурированию дисков можно обобщить следующим образом:
- В среде с интенсивным использованием данных следует конфигурировать от 3 до 5 полностью активных 2.9 Гбайт дисков на каждый главный адаптер fast/wide SCSI. Необходимо предусматривать по крайней мере 3 дисковых накопителя на каждого активного клиента при использовании сети FDDI, или один дисковод для каждого активного клиента в сетях Ethernet или Token Ring.
- В среде с интенсивным использованием атрибутов следует конфигурировать примерно по 4-5 полностью активных 1.05 Гбайт или 535 Мбайт дисков на каждый главный адаптер SCSI. Необходимо предусматривать по крайней мере один дисковод для каждых двух полностью активных клиентов (в любой сетевой среде).
- К каждому главному адаптеру могут подключаться дополнительные накопители без существенной деградации производительности до тех пор, пока количество обычно активных накопителей на шине SCSI не превысит указаний, приведенных выше.
- Для распределения нагрузки доступа по многим дискам можно рекомендовать использование программного обеспечения типа Online:DiskSuit 2.0.
- Если это возможно, следует пользоваться наиболее быстрыми зонами на диске.
Нестандартные требования к памяти
Поскольку во многих UNIX-системах (например, в Solaris) реализовано кэширование файлов в виртуальной памяти, большинство пользователей склонны конфигурировать серверы NFS очень большой подсистемой основной памяти. Однако примеры типичного использования файлов клиентами NFS показывают, что данные восстанавливаются из буферного кэша в действительности относительно редко и дополнительная основная память обычно не обязательна.
В типичных серверах предоставляемое клиентам пространство на диске намного превышает размер основной памяти системы. Повторные запросы к блоками данных удовлетворяются скорее путем чтения из памяти, а не с диска. К сожалению, большинство клиентов работает со своими собственными файлами и редко пользуются общими разделяемыми файлами. Более того, большинство приложений обычно читают файл данных целиком в память, а затем закрывают его. В результате клиент редко обращается к первоначальному файлу снова. Если никто из других клиентов не воспользуется тем же самый файлом прежде, чем произойдет перезапись данных в кэш, то это означает, что кэшированные данные никогда снова не используются. Правда какие-либо дополнительные накладные расходы, связанные с кэшированием этих данных и последующим их неиспользованием, отсутствуют. Если требуется память для кэширования других страниц данных, в соответствующие страницы просто происходит запись новых данных. Не обязательно сбрасывать страницу на диск, поскольку представление памяти, которое предстоит сохранить, уже находится на диске. Конечно мало пользы от хранения в памяти старой страницы, которая повторно не используется. Когда объем свободной памяти снижается ниже уровня 1/16 всего объема памяти, страницы, неиспользованные в недавнем прошлом, становятся доступными для повторного использования.
Самым большим исключением из этих эмпирических правил является временный рабочий файл, который часто открывается в начале и закрывается в конце работы. Поскольку файл остается для клиента открытым, страницы данных, связанные с этим файлом, остаются отображенными (и кэшированными) в памяти клиента. Подсистема виртуальной памяти клиента использует сервер в качестве резервного хранилища временного файла. Если клиент не имеет достаточного объема физической памяти для хранения этих страниц в собственном кэше, некоторые или все страницы данных будут откачены или заменены новым содержимым при выполнении последующих операций, а повторные обращения к этим данным будут приводить к выдаче операции чтения NFS для восстановления этих данных. В этом случае способность сервера кэшировать такие данные является определенным преимуществом.
Операции записи не могут использовать все преимущества механизма кэширования UNIX на сервере, поскольку протокол NFS требует, чтобы любая операция записи на удаленный диск выполнялась полностью синхронно, чтобы гарантировать согласованное состояние даже в случае выхода сервера из строя. Операция записи называется синхронной в этом смысле, поскольку логическая операция с диском в целом полностью завершается прежде, чем она будет подтверждена. Хотя данные кэшированы, операции записи NFS не выигрывают от буферизации и откладывания момента записи, которые обычно выполняются при реализации операций записи UNIX. Заметим, что клиент может и обычно выполняет операции записи в кэш точно таким же способом, что и любую другую операцию дискового ввода/вывода. Клиент в любом случае способен контролировать когда результаты операции записи сбрасываются на "диск" независимо от того, является ли диск локальным или удаленным.
Возможно самым простым и наиболее полезным является эмпирическое правило, которое называется "правилом пяти минут". Это правило широко используется при конфигурировании серверов баз данных, значительно большая сложность которых делает очень трудным определение размера кэша. Существующее в настоящее время соотношение между ценами подсистемы памяти и дисковой подсистемы показывает, что экономически целесообразно кэшировать данные, к которым осуществляются обращения более одного раза каждые пять минут.
В заключении приведем несколько простых эмпирических правил, которые позволяют выбрать конфигурацию памяти в серверах NFS:
- Если сервер в основном обеспечивает пользовательскими данными многих клиентов, следует конфигурировать относительно минимальную память. Для небольших коллективов обычно ее объем составляет 32 Мбайта, а для больших коллективов - примерно 128 Мбайт. В мультипроцессорных конфигурациях всегда необходимо предусматривать по крайней мере 64 Мбайт на каждый процессор. Приложения с интенсивным использованием атрибутов обычно выигрывают от увеличенного объема памяти несколько больше, чем приложения с интенсивным использованием данных.
- Если на сервере выделяется пространство для хранения временных файлов приложений, которые очень интенсивно работают с этими файлами (хорошим примером является Verilog фирмы Cadence), следует конфигурировать память сервера равной примерно сумме размеров активных временных файлов, используемых на сервере. Например, если размер временного файла клиента составляет примерно 5 Мбайт и предполагается, что сервер будет обслуживать 20 полностью активных клиентов, следует установить (20 клиентов х 5 Мбайт) = 100 Мбайт дополнительной памяти (конечно 128 Мбайт представляет собой наиболее удобную цифру, которую легко конфигурировать). Однако часто этот временный файл может быть размещен в локальном справочнике типа /tmp, что приведет к значительно более высокой производительности клиента, а также к существенному уменьшению сетевого трафика.
- Если главной задачей сервера является хранение только выполняемых файлов, следует конфигурировать память сервера примерно равной суммарному объему интенсивно используемых двоичных файлов. При этом нельзя забывать о библиотеках! Например, сервер предполагающийся для хранения /usr/openwin для некоторого коллектива сотрудников должен иметь достаточно памяти, чтобы кэшировать Xsun, cmdtool, libX11.so, libxwiew.so и libXt.so. Это приложение NFS значительно отличается от более типового сервера тем, что оно все время поставляет одни и те же файлы всем своим клиентам, а потому способно эффективно кэшировать эти данные. Обычно клиенты не используют каждую страницу всех двоичных кодов, а потому разумно в конфигурации сервера предусмотреть только такой объем памяти, которого достаточно для размещения часто используемых программ и библиотек.
- Размер памяти может быть выбран исходя из правила пяти минут: 16 Мбайт для ОС плюс объем памяти для кэширования данных, к которым будут происходить обращения чаще, чем один раз в пять минут.
Поскольку серверы NFS не выполняют пользовательских процессов, большого пространства подкачки (swap) не нужно. Для таких серверов пространства подкачки объемом примерно 50% от размера основной памяти более чем достаточно. Заметим, что большинство этих правил прямо противоположены тому, что все ожидают.
PrestoServe/NVSIMM
Дисковые операции по своей природе связаны с механическими перемещениями головок диска, поэтому они выполняются медленно. Обычно UNIX буферизует операции записи в основной памяти и позволяет выдавшему их процессу продолжаться, в то время как на операционную систему ложится задача физической записи данных на диск. Синхронный принцип операций записи в NFS означает, что они обычно выполняются очень медленно (значительно медленнее, чем операции записи на локальный диск). Если клиент выдает запрос записи, требуется, чтобы сервер обновил на диске сами данные, а также все связанные с ними метаданные файловой системы. Для типичного файла необходимо выполнить до 4 записей на диск: каждая операция должна обновить сами данные, информацию в каталоге файла, индицирующую дату последней модификации, и косвенный блок; если файл большой, то потребуется также обновить второй косвенный блок. Прежде, чем подтвердить завершение запроса записи NFS, сервер должен выполнить все эти обновления и гарантировать, что они действительно находятся на диске. Операция записи NFS часто может продолжаться в течение 150-200 миллисекунд (три или четыре синхронных записи, больше чем по 40 миллисекунд каждая), по сравнению с обычными 15-20 миллисекундами для записи на локальный диск.
Для того чтобы существенно ускорить операции записи NFS, серверы могут использовать стабильную память (non-volatile RAM - NVRAM). Эта дополнительная возможность опирается на тот факт, что протокол NFS просто требует, чтобы данные операции записи NFS были бы зафиксированы в стабильной памяти вместо их фиксации на диске. До тех пор, пока сервер возвращает данные, которые подтверждены предыдущими операциями записи, он может сохранять эти данные любым доступным способом.
PrestoServe и NVRAM в точности реализуют эту семантику. При установке этих устройств в сервер драйвер устройства NVRAM перехватывает запросы синхронных операций записи на диск. Данные не посылаются прямо в дисковое устройство. Вместо этого, результаты операций записи фиксируются в стабильной памяти и подтверждаются как завершенные. Это намного быстрее, чем ожидание окончания механической операции записи данных на диск. Спустя некоторое время данные фиксируются на диске.
Поскольку одна логическая операция записи NFS выполняет три или четыре синхронные дисковые операции, использование NVRAM существенно ускоряет пропускную способность операций записи NFS. В зависимости от условий (состояния файловой системы, наличия других запросов к диску, размера и месторасположения записи и т.п.) использование NVRAM ускоряет операции записи NFS в 2-4 раза. Например, типичная пропускная способность при выполнении операций записи NFS под управлением ОС Solaris 2 составляет примерно 450 Кбайт/с. При использовании NVRAM скорость повышается примерно до 950 Кбайт/с и даже несколько выше, если используется сетевая среда более быстрая, чем Ethernet. Никаких улучшений времени выполнения операций чтения NVRAM не дает.
С точки зрения дисковой подсистемы или клиентов NFS дополнительные возможности PrestoServe и NVSIMM функционально эквивалентны. Основная разница заключается в том, что NVSIMM более эффективны, поскольку они требуют меньше манипуляций с данными. Поскольку плата PrestoServe физически размещается на шине SBus, требуется, чтобы данные копировались на нее через периферийную шину. В отличие от этого, NVSIMM размещаются прямо в основной памяти. Записываемые на диск данные не копируются в NVSIMM через периферийную шину. Такое копирование может быть выполнено очень быстро с помощью операций память-память. По этим причинам NVSIMM оказываются предпочтительными в ситуациях, когда обе возможности NVSIMM и PrestoServe оказываются доступными.
В связи с важностью получаемого ускорения Sun рекомендует использование NVRAM действительно во всех своих системах, которые обеспечивают универсальный сервис NFS. Единственным исключением из этого правила являются серверы, которые обеспечивают только сервис по чтению файлов. Наиболее характерным примером такого использования являются серверы, хранящие двоичные коды программ для большого коллектива клиентов. (В Sun он известен как сервер /usr/dist или softdist).
Поскольку драйвер устройства NVSIMM/PrestoServe должен находится на диске в корневой файловой системе, ускорение с помощью NVRAM не может быть получено для работы с самой корневой файловой системы. Драйвер NVRAM должен успевать откачивать модифицированные буфера на диск прежде, чем станет активным любой другой процесс. Если бы и корневая файловая система была ускорена, она могла бы оказаться "грязной" (модифицированной) после краха системы, и драйвер NVRAM не мог бы загрузиться.
Еще одно важное соображение при сравнении серверов, которые оборудованы NVRAM и без него, заключается в том, что использование такого ускорения обычно снижает максимальную пропускную способность системы примерно на 10%. (Системы, использующие NVRAM, должны управлять кэшем NVRAM и поддерживать в согласованном состоянии копии в кэше и на диске). Однако время ответа системы существенно улучшается (примерно на 40%). Например, максимальная пропускная способность SPARCserver 1000 на тесте LADDIS без NVSIMM составляет 2108 операций в секунду с временем ответа 49.4 мс. Таже система с NVSIMM может выполнять только примерно 1928 операций в секунду, но среднее время ответа сокращается примерно до 32 мс. Это означает, что клиенты NFS воспринимают сервер, оборудованный NVRAM, гораздо более быстрым, чем сервер без NVRAM, хотя общая пропускная способность системы несколько сократилась. К счастью, величина 10% редко оказывается проблемой, поскольку возможности максимальной пропускной способности большинства систем намного превышают типовые нагрузки, которые вообще находятся в диапазоне 10-150 операций в секунду на сеть.
Обеспечение резервного копирования и устойчивости к неисправностям
Проблемы резервного копирование файловых систем и обеспечения устойчивости к неисправностям для NFS сервера совпадают с аналогичными проблемами, возникающими при эксплуатации любой другой системы. Некоторые рекомендации по организации резервного копирования и обеспечению устойчивости к неисправностям можно обобщить следующим образом:
- Простые, сравнительно небольшие резервные копии могут изготавливаться с помощью одного или двух ленточных накопителей. Местоположение этих накопителей на шине SCSI не имеет особого значения, если они не активны в течение рабочих часов системы.
- Создание полностью согласованных резервных копий требует блокировки файловой системы для предотвращения ее модификации. Для выполнения таких операций необходимы специальные программные средства, подобные продукту Online:Backup 2.0. Как и в предыдущем случае, местоположение устройств резервного копирования на шинах SCSI не имеет особого значения, если само копирование выполняется вне рабочего времени.
- Зеркалированные файловые системы дают возможность пережить полные отказы дисков и, кроме того, обеспечивают возможность непрерывного доступа к системе даже во время создания полностью согласованных резервных копий. Зеркалирование приводит к очень небольшим потерям пропускной способности дисков на операциях записи (максимально на 7-8% при произвольном, и на 15-20% при последовательном доступе; в системах с большим числом пользователей, каковыми являются большинство серверов, можно надеяться, что эти цифры уменьшатся вдвое). Зеркалирование автоматически улучшает пропускную способность при выполнении операций чтения.
- При создании зеркалированных файловых систем каждое зеркало должно конфигурироваться на отдельной шине SCSI.
- Если резервное копирование должно выполняться в течение обычных рабочих часов системы, то устройство копирования должно конфигурироваться либо на своей собственной шине SCSI, либо на той же шине SCSI, что и выключенное из работы зеркало (отдельное и неактивное), чтобы обойти ряд проблем с обеспечением заданного времени ответа.
- Когда требуется быстрое восстановление файловой системы в среде с интенсивным использованием атрибутов следует предусмотреть в конфигурации NVRAM.
- В среде с интенсивным использованием данных необходимо исследовать возможность применения высокоскоростных механических устройств типа стэккеров лент и устройств массовой памяти.
Предварительная оценка рабочей нагрузки
Проведение работ по оценке нагрузки на будущую систему оказывается не очень точным, но часто вполне хорошим приближением, которое пользователь может получить заранее. Для этого используются два основных подхода. Более предпочтительный метод заключается в измерении параметров существующей системы. Этот метод обеспечивает некоторую уверенность в точности оценки нагрузки по крайней мере на текущий момент времени, хотя нельзя конечно гарантировать, что нагрузка при эксплуатации системы в будущем останется эквивалентной существующей. Альтернативным методом является грубый расчет. Он полезен, когда в распоряжении пользователя отсутствуют необходимые для измерения системы.
Чтобы создать достаточно точную конфигурацию системы необходимо знать две вещи: смесь операций NFS и общую пропускную способность системы. Смесь операций NFS позволяет показать, является ли система интенсивной по атрибутам или по данным.
Измерение существующих систем
Имеется много разнообразных механизмов для измерения существующих систем. Самый простой из них - это просто использовать команду nfsstat(8), которая дает информацию о смеси операций. Поскольку эти статистические данные могут быть заново устанавливаться в ноль посредством флага -z, команда nfsstat может также использоваться для измерения пропускной способности системы с помощью скрипта Shell, подобного показанному ниже.
#!/bin/sh
nfsstat -z >/dev/null #zero initial counters
while true
do
sleep 10
nfsstat - z -s #show the statistics
done
Выход показывает количество NFS-вызовов, которые были обслужены в заданном интервале и, следовательно, скорость, с которой обрабатываются операции NFS. Следует иметь в виду, что при тяжелых нагрузках команда sleep может в действительности "спать" намного больше, чем запрошенные 10 секунд, что приводит к неточности данных (т.е. переоценке количества запросов). В этих случаях должно использоваться какое-либо более точное средство. Имеется много таких средств, среди которых можно указать SunNetManager, NetMetrix от Metrix и SharpShooter от AIM Technologies. Все эти средства позволяют выяснить пропускную способность системы под действительной нагрузкой и смесь операций. Для вычисления средней пропускной способности обычно требуется некоторая последующая обработка данных. Для этого можно воспользоваться разнообразными средствами (awk(1), электронная таблица типа WingZ или 1-2-3).
Оценка нагрузки в отсутствие системы
Если для проведения измерений существующая система не доступна, часто оказывается возможной примерная оценка, основанная на предполагаемом использовании системы. Выполнение такой оценки требует понимания того, каким объемом данных будет манипулировать клиент. Этот метод достаточно точен, если приложение попадает в категорию систем с интенсивным использованием данных. Некоторая разумная оценка обычно может быть также сделана и для среды с интенсивным использованием атрибутов, но множество факторов делает такую оценку несколько менее точной.
Оценка среды с интенсивным использованием данных
Первый шаг для получения такой оценки заключается в определении полностью активного запроса типового клиента. Для этого необходимо понимание поведения клиента. Если нагрузка интенсивная по данным, то имеет смысл просто просуммировать количество предполагаемых операций чтения и записи и взять это число в качестве нагрузки для каждого клиента. Операции с атрибутами обычно являются несущественными для рабочей нагрузки, в которой доминируют операции с данными (с одной стороны, они составляют лишь небольшой процент всех операций, а с другой стороны, эти операции задают серверу минимальное количество работы по сравнению с объемом работы, который необходимо выполнить для выборки данных).
Например, рассмотрим клиентскую рабочую станцию, выполняющую приложение, которое осуществляет поиск областей с заданной температурой в некотором объеме жидкости. Типовой набор данных для решения этой задачи составляет 400 Мбайт. Обычно он читается порциями по 50 Мбайт. Каждая порция проходит полную обработку прежде, чем приложение переходит к следующей. Обработка каждого сегмента занимает примерно 5 минут времени ЦП, а результирующие файлы, которые записываются на диск имеют размер около 1 Мбайта. Предположим, что в качестве сетевой среды используется FDDI. Максимальная нагрузка на NFS будет возникать, когда клиент читает каждую порцию объемом 50 Мбайт. При максимальной скорости 2.5 Мбайт/с клиент будет полностью активным примерно в течение двадцати секунд, выполняя 320 операций чтения в секунду. Поскольку каждый запуск программы занимает примерно 40 минут (или 2400 секунд) времени, и на один прогон требуется (400 + 1) Мb х 125 ops/Mb = 50,125 ops, средняя скорость равна примерно 20 ops/sec. Сервер должен будет обеспечивать обслуживание пиковой скорости запросов (320 ops/sec) в течение примерно 20 секунд из каждых 5 минут, или примерно в течение 7% времени. Из этого упражнения можно извлечь три порции полезной информации: среднюю скорость активных запросов (20 ops/sec), пиковую скорость запросов (320 ops/sec) и вероятность того, что пиковая скорость требуется. На базе этой информации может быть сформирована оценка общей скорости запросов. Если в конфигурации системы будет 10 клиентов, то средняя скорость запросов составит 200 ops/sec. (Эту скорость не следует сравнивать с результатами теста LADDIS, поскольку в данном случае смеси операций очень отличаются). Вероятность того, что два клиента будут требовать работы с пиковой скоростью одновременно составляет примерно 0.07 х 0.07 = 0.049, или примерно 5%, а три клиента будут требовать пикового обслуживания только в течение 0.034% времени. Таким образом, из этой информации разумно вывести следующие заключения:
- Поскольку вероятность того, что три клиента будут одновременно активными, намного меньше 1%, максимальная нагрузка будет превышать индивидуальную пиковую нагрузку в 2-3 раза.
- Требуется только одна сеть, поскольку максимальная предполагаемая нагрузка составляет только 3 х 2.5 Mb/sec = 7.5 MB/s, т.е. намного ниже максимальной полосы пропускания сети FDDI (12.5 MB/sec).
- Поскольку в любой момент времени полностью активными будут только два или три клиента, требуется по крайней мере от 3 до 6 дисковых накопителей (хотя для типовых файлов размером по 400 MB очень вероятно, что потребуется более 6 дисков просто для хранения данных).
- Требуется по крайней мере два главных адаптера SCSI.
- Поскольку в состав системы входит одна высокоскоростная сеть, то рекомендуется использовать сервер с двумя процессорами SuperSPARC/SuperCashe.
- Поскольку маловероятно, что очень большой кэш файлов окажется полезным для работы такого сервера, требуется минимальный объем основной памяти - 128 Мбайт вполне достаточно.
- Если требуется сравнительно небольшая ферма дисков, например, объемом около 16 Гбайт, то система SPARCstation 10 Model 512 очень хорошо сможет справиться с этой задачей, поскольку один слот SBus требуется для интерфейса FDD небольшая ферма дисков, например, объемом около 16 Гбайт, то система SPARCstation 10 Model 512 очень хорошо сможет справиться с этой задачей, поскольку один слот SBus требуется для интерфейса FDDI, а оставшиеся три слота могут использоваться для установки главных адаптеров SCSI, чтобы обеспечить в общей сложности 4 интерфейса FSBE/S, к каждому из которых подключается дисковые накопители общей емкостью по 4.2 Гбайт. Однако для этого приложения может лучше подойти система SPARCserver 1000, которая обеспечит большую емкость памяти: система с двумя системными платами позволяет создать конфигурацию с семью главными адаптерами SCSI и емкостью дисковой памяти более 28 Гбайт (по одному многодисковому устройству емкостью 4.2 Гбайт на каждую плату FSBE/S, не считая четырех встроенных дисков емкостью по 535 Мбайт). В случае, если потребуется большая емкость дисков, можно сконфигурировать систему SPARCcenter 2000 с двумя системными платами, чтобы обеспечить реализацию шести интерфейсов DWI/S и до 12 шасси с дисками емкостью по 2.9 Гбайт - примерно 208 Гбайт памяти.
- Во все предлагаемые системы можно установить NVSIMM без использования слотов SBus, и все они легко поддерживают установку двух требуемых процессоров. Использование NVSIMM вообще не очень важно, поскольку пропорция операций записи слишком мала (меньше, чем 1:400, или 0.25%).
Заметим, что при выборе конфигурации системы для приложений с интенсивным использованием данных вообще говоря не очень полезно сравнивать предполагаемые скорости запросов с рейтингом предполагаемого сервера по SPECsfs_097, поскольку смеси операций отличаются настолько, что нагрузки нельзя сравнивать. К счастью, такая оценка обычно оказывается достаточно точной.
Оценка среды с интенсивным использованием атрибутов
В предыдущем примере предполагалось, что нагрузка NFS от операций с атрибутами была пренебрежимо мала по сравнению с операциями с данными. Если же это не так, например, в среде разработки программного обеспечения, необходимо сделать некоторые предположения относительно предполагаемой смеси команд NFS. В отсутствии другой информации, в качестве образца можно принять, например, так называемую смесь Legato. В тесте SPECsfs_097 (известной также под названием LADDIS) используется именно эта смесь, в которой операции с данными включают 22% операций чтения и 15% операций записи.
Рассмотрим клиентскую рабочую станцию, наиболее интенсивная работа которой связана с перекомпиляцией программной системы, состоящей из исходного кода объемом 25 Мбайт. Известно, что рабочие станции могут скомпилировать систему примерно за 30 минут. В процессе компиляции генерируется примерно 18 Мбайт промежуточного объектного кода и двоичные коды. Из этой информации мы можем заключить, что клиентская система будет записывать на сервер 18 Мбайт и читать по крайней мере 25 Мбайт (возможно больше, поскольку почти треть исходного кода состоит из файлов заголовков, которые включены посредством множества исходных модулей). Для предотвращения повторного чтения этих файлов включений может использоваться кэширующая файловая система. Предположим, что используется CFS. Во время "конструирования" необходимо передать 33 Мбайт действительных данных, или 33 Мb х 125 ops/Mb = 4125 операций с данными за 30 минут (1800 секунд), что примерно соответствует скорости 2.3 ops/sec. (Здесь предполагается, что каждая операция выполняется с данными объемом 8 Kb, поэтому для пересылки 1 Mb данных требуется 125 операций). Поскольку эта работа связана с интенсивным использованием атрибутов, необходимо оценить существенное количество промахивающихся операций с атрибутами. Предположив, что смесь операций соответствует смеси Legato, общая скорость будет примерно равна:
Объем читаемых данных * 125
NFSops/sec = или
22%
Объем записываемых данных * 125
NFSops/sec = .
15%
В данном случае скорость равна: (25 Мb по чтению х 125ops/Mb) / 22% / 1800 секунд, или 7.89 ops/sec. Для проверки мы также имеем (18 Мb по записи х 125 ops/Mb) / 15% / 1800 секунд, или 8.33 ops/sec. В данном случае соотношение операций чтения и записи очень похоже на смесь Legato, но это может быть и не так, например, если были открыты файлы программы просмотра исходного текста (размер файлов программы просмотра исходного текста (source brouser files) часто в 4-6 раз превосходит размер исходного кода). В этом случае у нас нет способа оценки пиковой нагрузки.
Если имеются двадцать рабочих станций, работающие в описанном выше режиме, мы можем составить следующие заключения:
- Даже при совершенно невероятном условии, когда все двадцать рабочих станций полностью активны все время, общая скорость запросов составляет 8.33 ops/sec x 20 клиентов, или 166 ops/sec, т.е. ниже максимума в 200 ops/sec, который поддерживает Ethernet. Осторожные люди сконфигурируют для такой нагрузки две сети, но если материально-технические соображения заранее это исключают, то и одной сети вероятно будет достаточно.
- Поскольку нагрузка относительно легкая, система SPARCstation 10 Model 40 оказывается более, чем адекватной. (Даже в самом плохом случае, имеются только две сети). Процессорной мощности системы SPARCclassic также обычно вполне достаточно.
- Хотя общее количество данных очень невелико (25 Мбайт исходного кода и 18 Мбайт объектного кода; даже двадцать полных копий составляют только 660 Мбайт), то в рекомендуемую конфигурацию дисков можно включить два диска по 535 Мбайт. В предположении, что используется CFS, может быть достаточно и одного диска, поскольку файлы заголовков не будут часто читаться с сервера (они будут кэшироваться клиентами).
- При одном или двух дисках данных одной шины SCSI полностью достаточно.
- Объем данных очень маленький и большинство из них будут читаться и пересылаться многим клиентам многократно, поэтому конечно стоит сконфигурировать достаточно памяти, чтобы все эти данные кэшировать: 16 Мбайт базовой памяти под ОС, плюс 25 Мбайт для кэширования исходных кодов в конфигурации 48-64 Мбайт.
- Поскольку в этой среде операции записи достаточно часты, NVSIMM или PrestoServe являются существенными.
- Для окончательного варианта системы можно выбрать либо станцию начального уровня SPARCstation 10, либо хорошо сконфигурированную станцию SPARCclassic. Для контроля с точки зрения здравого смысла заметим, что максимальная скорость запросов в 166 ops/sec на 75% меньше показателей SPARCclassic (236 ops/sec) на тесте LADDIS (вспомните, что скорость 166 ops/sec предполагала, что все 20 клиентов полностью активны все время, хотя реальные журналы использования систем показывают, что этого никогда не бывает); Максимальная требуемая нагрузка наполовину меньше той, которую показывает SPARCstation 10 Model 40 на тесте LADDIS (411 ops/sec). Сравнение с показателем LADDIS соответствует ситуациям с интенсивным использованием атрибутов, поскольку результаты LADDIS используют интенсивную по атрибутам смесь операций.
Таблица 4.3. Показатели LADDIS для
различных NFS-серверов Sun под управлением Solaris 2.3. Немного (на 5%) более
высокие скорости достижимы при использовании FDDI,
немного меньшие скорости - при использовании 16 Мбит Token Ring.
|
Платформа |
Результат |
Примечания по конфигурации |
| SPARCclassic | 236 оп/с, 50 мс | 64 Мб RAM, 4 диска на 2 FSBE/S, 2 сети |
|
SPARCstation 10 |
411 оп/с, 49 мс | 128 Мб RAM, 8 дисков на 4 FSBE/S, 2 сети |
|
SPARCstation 10 |
520 оп/с, 46 мс | 128 Мб RAM, 8 дисков на 4 FSBE/S, 2 сети |
|
SPARCstation 10 |
472 оп/с, 49 мс | 128 Мб RAM, 12 дисков на 4 FSBE/S, 3 сети |
|
SPARCstation 10 |
741 оп/с, 48 мс | 128 Мб RAM, 12 дисков на 4 FSBE/S, 3 сети |
|
SPARCserver 1000 |
1410 оп/с, 41 мс | 256 Мб RAM, 4 Мб NVSIMM, 24 диска на 4 DWI/S, 6 сетей на 2 SQEC/C |
|
SPARCserver 1000 |
1928 оп/с, 42 мс | 480 Мб RAM, 4 Мб NVSIMM, 24 диска на 4 DWI/S, 8 сетей на 2 SQEC/C |
|
SPARCcenter 2000 |
2080 оп/с, 32 мс | 448 Мб RAM, 8 Мб NVSIMM, 48 дисков на 8 DWI/S, 12 сетей на 3 SQEC/C |
|
SPARCcenter 2000 |
2575 оп/с, 49 мс | 512 Мб RAM, 60 дисков на 8 DWI/S, 12 сетей на 2 SQEC/C |
Последняя возможность: использование похожей нагрузки
Если отсутствует система для проведения измерений и поведение приложения не очень хорошо понятно, можно сделать оценку базируясь на похожей прикладной нагрузке, показанной в таблицах 4.4 - 4.6. Эти данные дают некоторое представление и примеры измеренных нагрузок NFS. Это не означает, что они дают определенную картину того, какую нагрузку следует ожидать от определенных задач. В частности, заметим, что приведенные в этих таблицах данные представляют собой максимальные предполагаемые нагрузки от реальных клиентов, поскольку эти цифры отражают только тот период времени, когда система активно выполняет NFS-запросы. Как отмечено выше в разд. 3.1.4, системы почти никогда не бывают полностью активными все время. Примечательным исключением из этого правила являются вычислительные серверы, которые в действительности представляют собой непрерывно работающие пакетные машины. Например, работа системы 486/33, выполняющей 1-2-3, показана в таблице 4.2 и на рис. 4.2. Хотя представленная в таблице пиковая нагрузка равна 80 ops/sec, из рисунка ясно, что общая нагрузка составляет меньше 10% этой скорости и что средняя за пять минут нагрузка значительно меньше 10 ops/sec. При усреднении за более длительный период времени, нагрузка ПК примерно равна 0.1 ops/sec. Большинство рабочих станций класса SPARCstation2 или SPARCstation ELC дают в среднем 1 op/sec, а большинство разумных эквивалентов клиентов SPARCstation 10 Model 51, Model 512, HP 9000/735 или RS6000/375 - 1-2 ops/sec. Конечно эти цифры существенно меняются в зависимости от индивидуальности пользователя и приложения.
Таблица 4.4. Оценка нагрузки полностью активных клиентов NFS на бизнес-приложениях (операция/с и продолжительность этапов)
| Тип плат-формы | Тип сети |
1-2-3 (электронная |
Interleaf |
||
|
|
Старт | Загру-зка | Сохра-нение |
СтартОткрытие документа Сохранение документа
|
| 486/33 | Ethernet | 80/30 | 50/25 | 13/60 | 40/12525/3 14/8 15/60 |
| SS10-40 | Ethernet | 101/17 | 48/20 | 13/60 | 55/3325/3 25/3 45/19 |
| IBM 560 | Ethernet |
|
- |
|
40/3025/3 25/3 38/23 |
| HP 847 | Ethernet |
|
- |
|
57/2721/3 19/5 40/22 |
Таблица 4.5. Оценка нагрузки полностью активных клиентов NFS на приложениях САПР (операция/с и продолжительность этапов)
|
Тип |
Тип сети | Verilog (50K вентилей) | Журнал Pro/EЖурнал SDRC Ideas AutoCAD Site-3D |
| SS10-41 | Ethernet | 5.1/602 | 3.22/74917.9/354 8/180 |
| IBM 375 | Ethernet | 6.8/390 | -18.5/535 11/167 |
| HP 730 | Ethernet | 7.2/444 | 3.05/86021.5/295 10.5/170 |
| SGI Crim | Ethernet | - | 3.25/78022.8/280 - |
Таблица 4.6. Оценка нагрузки полностью активных клиентов NFS на приложениях разработки ПО (операция/с и продолжительность этапов)
|
Тип |
Тип сети |
"make |
find /tree- name thingcp -pr tree remote dump 8MB core |
| SS10-40 | Ethernet | 43/190 | 122/431127/62 24/41 |
| SS10-40 | FDDI | 58/177 | 139/378135/58 26/37 |
| SS2000 12cpu | Ethernet | 211/22 | -- - |
| IBM 560 | Ethernet | 65/317 | 112/47558/158 8/3 |
| HP 847 | Ethernet | 53/173 | 145/363180/43 14/71 |