Реферат: Кодирование изображений
1.Цвет
Человеческий глаз состоит примерно из 7 млн. колбочек и 120 млн. палочек. Функция палочек заключается в “ночном зрении” - светочувствительности и приспособлении к окружающей яркости. Функция колбочек - “дневное зрение” - восприятие цвета, формы и деталей предмета. В них заложены три типа воспринимающих элементов, каждое из которых воспринимает световое излучение только определенной длины волн, соответствующих одному из трех основных цветов: красному, зеленому и синему. Остальные цвета и оттенки получаются смешением этих трех.
Человеческий глаз воспринимает цветовую информацию в диапазоне волн примерно от 380 нм (синий цвет) до 770 нм (красный цвет). Причем наилучшую чувствительность имеет в районе 520 нм (зеленый цвет).
На рисунке показана чувствительность глаза в зависимости от длины принимаемой волны. Область частот, левее синей - ультрафиолетовые волны, правее красной - инфракрасные волны.
Грассман привел законы природы цвета:
Трехмерность природы цвета. Глаз реагирует на три различных цветовых составляющих. Примеры: красный, зеленый и синий цвета; цветовой тон (доминирующая длина волны), насыщенность (чистоту) и яркость (светлость).
Четыре цвета всегда линейно
зависимы, то есть ![]() ,
где
,
где ![]() . Для
смеси двух цветов
. Для
смеси двух цветов ![]() и
и ![]() имеет
место равенство:
имеет
место равенство: ![]() .Если цвет
.Если цвет ![]() равен
цвету
равен
цвету ![]() и цвет
и цвет ![]() тоже
равен цвету
тоже
равен цвету ![]() , то
, то ![]() цвет
цвет
![]() равен цвету
равен цвету ![]() независимо
от структуры спектров энергии
независимо
от структуры спектров энергии ![]() .
.
Цветовое пространство непрерывно. Если в смеси трех цветов один непрерывно изменяется, а другие остаются постоянными, то цвет смеси будет меняться непрерывно.
Рассмотрим основные цветовые модели:
RGB.
Данная модель построена на основе строения глаза. Она идеально удобна для светящихся поверхностей (мониторы, телевизоры, цветные лампы и т.п.). В основе ее лежат три цвета: Red- красный, Green- зеленый и Blue- синий. Еще Ломоносов заметил, что с помощью этих трех основных цветов можно получить почти весь видимый спектр. Например, желтый цвет- это сложение красного и зеленого. Поэтому RGB называют аддитивной системой смешения цветов.
Чаще всего данную модель представляют в виде единичного куба с ортами: (1;0;0)- красный, (0;1;0)- зеленый, (0;0;1)- синий и началом (0;0;0)- черный. На рисунке показан куб и также распределение цветов вдоль указанных векторов.
CMY.
Данная модель применяется для отражающих поверхностей (типографских и принтерных красок, пленок и т.п.). Ее основные цвета: Cyan- голубой, Magenta- пурпурный и Yellow- желтый являются дополнительными к основным цветам RGB. Дополнительный цвет - разность между белым и данным, например, желтый = белый - синий.
Поэтому CMY называют субтрактивной системой смешения цветов. Например, при пропускании света пурпурный объект поглощается зеленая часть спектра, если далее пропустить через желтый объект, то поглотится синяя часть спектра и останется лишь красный цвет. Данный принцип используют светофильтры. На верхнем рисунке в кругах - основные цвета системы RGB, на пересечениях - их смешения. Аналогичным образом работают с красками художники, формируя необходимую палитру. На нижнем рисунке в кругах - основные цвета CMY, на пересечениях - смешения. Связь между RGB и CMY можно выразить через следующую формулу:
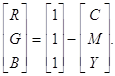
Наряду с системой CMY также часто применяют и ее расширение CMYK. Дополнительный канал K (от английского blacK) - черный. Он применяется для получения более “чистых” оттенков черного. В цветных принтерах чаще всего используется четыре красителя. Данная система широко применяется в полиграфии.
CIE .
Если имеется один контрольный цвет, то с помощью него можно получить некоторые цвета, варьируя данный контрольный по светлоте (при условии, что не используется цветовой тон и насыщенность). Данная процедура называется фотометрией и используется при создании монохроматических репродукций цветных изображений.
С помощью двух контрольных цветов можно получить гораздо больше цветов, но не все. Для получения видимого набора цветов используют три контрольных цвета, соблюдая условие, что они находятся в разных областях спектра. Рассмотрим следующий базис цветов:
Red- красный; лежит в области длинных видимых волн (`700 нм).
Green- зеленый; лежит в области средних видимых волн (`546 нм).
Blue- синий; лежит в области средних коротких волн (`436нм).
Рассмотрим цвет C:
![]() ,
,
r, g, b- относительные количества потоков базовых цветов, входящие в интервал [0; 1]. Но данным сложением можно уравнять не все цвета. Например, для получения сине-зеленого цвета объединяем синий и зеленый потоки цвета, но их сумма выглядит светлее, чем необходимый. Если попытаться сделать его темнее с помощью красного, то получим еще более светлый результирующий цвет, так как световые энергии складываются. То есть мы можем добавлять красный, для получения более светлого образца. Математически добавление красного цвета к поучаемому цвету соответствует вычитанию его из двух оставшихся базовых потоков (физически это невозможно, так как отрицательной интенсивности света не существует). Запишем уравнение следующим образом:
![]() .
.
На рисунке показаны функции r, g, b уравнения по цвету для монохроматических потоков цвета с длинами волн 436, 546, 770 нм. С их помощью можно уравнять все длины волн видимого спектра. На графике присутствует отрицательная область. Значения в данной области соответствуют “добавлению” инструментального цвета к синтезируемому. Изучением данных функций занимается колориметрия. Замечено, что один и тот же цвет можно получить разными наборами базисных цветов (r1, g1, b1) и (r2, g2, b2). То есть цвет можно уравнять различными составными источниками с неодинаковым спектральным распределением. (r1, g1, b1) и (r2, g2, b2)- метамеры.
Представим цвет С как вектор с составляющими rR, gG, bB. Пересечение вектора C с единичной плоскостью R+G+B=1 дает относительные веса его красной, зеленой и синей составляющих. Их также называют значениями или координатами цветности:
![]()
Заметим, ![]() .
Рассмотрим связь:
.
Рассмотрим связь: ![]() . Если функции
уравнивания по цвету перенести в трехмерное пространство, то результат не будет
целиком лежать в положительном октанте.
. Если функции
уравнивания по цвету перенести в трехмерное пространство, то результат не будет
целиком лежать в положительном октанте.
В 1931 был принят стандарт CIE (Commission International de l’Eclairage - Международная комиссия по освещению), в качестве основы которого был выбран двумерный цветовой график и набор из трех функций реакции глаза, исключающий отрицательной области и удобный для обработки. Гипотетические цвета CIE - X, Y и Z. Треугольник XYZ задан так, что в него входит видимый спектр. Координаты цветности CIE (x, y, z) задаются следующим образом:
![]()
![]()
![]() ,
,
и ![]() .
При проецировании треугольника
XYZ на плоскость (x, y) получаем
цветовой график CIE. Координаты x и y -
относительные количества трех основных цветов XYZ, требуемых
для составления нужного цвета.
Яркость определяется величиной Y, а X и Y подбираются
в соответствующем масштабе. Таким образом, триада (x, y, Y) задает
цвет. Обратное преобразование имеет вид:
.
При проецировании треугольника
XYZ на плоскость (x, y) получаем
цветовой график CIE. Координаты x и y -
относительные количества трех основных цветов XYZ, требуемых
для составления нужного цвета.
Яркость определяется величиной Y, а X и Y подбираются
в соответствующем масштабе. Таким образом, триада (x, y, Y) задает
цвет. Обратное преобразование имеет вид:
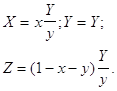
Комиссия решила ориентировать треугольник XYZ таким образом, что равные количества гипотетических основных цветов XYZ давали в сумме белый. На рисунке изображен цветовой график. Область на графике - видимое множество цветов. На контуре проставлены значения соответствующих длин волн в нм, соответствующие чистым, не разбавленным цветам. В центре области находится опорный белый цвет - точка равных энергий, с координатами x=y=0.33(3). Часто применяют следующие источники CIE:
| Название | Температура | x | y |
| Лампа с вольфрамовой нитью накаливания. | 2856К | 0.448 | 0.408 |
| Солнечный свет в полдень. | 5600К | 0.349 | 0.352 |
| Полуденное освещение при сплошной облачности. | 6300К | 0.310 | 0.316 |
| Опорный белый стандарт для мониторов и NTSC. | 6400К | 0.313 | 0.329 |
Система (x, y, Y) подчиняется законам Грассмана. На рисунке показана цветовая область графика CIE. Как видно, наибольшую площадь занимают цвета с преобладанием зеленого, что согласуется с чувствительной избирательностью человеческого глаза.
На цветовом графике CIE удобно демонстрировать цветовой охват различных систем и оборудования: телевидения, типографской печати, фотопленок и т.п. Цветовой обхват для аддитивных систем - треугольник с вершинами, соответствующими основным цветам RGB. Цвет, который можно получить в данной цветовой модели лежит внутри треугольника, цвета, лежащие вне - получить невозможно. Примеры цветовых обхватов для некоторых моделей можно увидеть на рисунке. Заметим, что для цветной пленки обхват есть криволинейный треугольник. Причина этого заключается в нелинейном (в данном случае логарифмическом) законе создания цветного изображения с помощью цветной пленки. Ниже приведена таблица основных цветов моделей в координатах цветового графика CIE:
| Модель | Цвет | x | y |
| CIE XYZ. |
Красный Зеленый Синий |
0.735 0.274 0.167 |
0.265 0.717 0.009 |
| Стандарт NTSC. |
Красный Зеленый Синий |
0.670 0.210 0.140 |
0.330 0.710 0.080 |
| Цветной монитор. |
Красный Зеленый Синий |
0.628 0.268 0.150 |
0.346 0.588 0.070 |
Координаты цветности CIE представляют точный стандарт определения цвета. Координаты цветности CIE полезны при передаче цветовой информации из одной цветовой модели в другую. Поэтому необходимо знать преобразование координат CIE в другие цветовые модели, а также и обратно. Например, преобразование RGB - CIE XYZ задается следующей формулой:
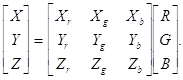 ,где
,где ![]() -
цвета для получения координаты единичного основного цвета R, аналогично
и для G и B. Если известны координаты цветности CIE x и
y для основных цветов RGB, то:
-
цвета для получения координаты единичного основного цвета R, аналогично
и для G и B. Если известны координаты цветности CIE x и
y для основных цветов RGB, то:
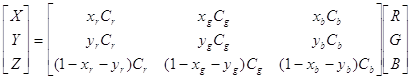 , где:
, где:
![]() - данные величины необходимы для полного
преобразования между системами основных цветов,
- данные величины необходимы для полного
преобразования между системами основных цветов, ![]() также
можно получить и следующим образом:
также
можно получить и следующим образом:
Известны ![]() -
яркости единичных количеств основных цветов:
-
яркости единичных количеств основных цветов:
![]() .
.
Известен ![]() - координаты
цветности опорного белого и его яркость:
- координаты
цветности опорного белого и его яркость:
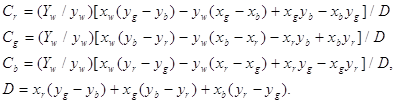
Обратное преобразование CIE XYZ в RGB задается как:
![]() , где
, где
![]() c элементами:
c элементами:
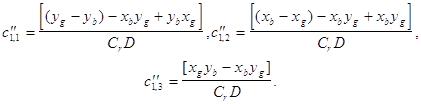
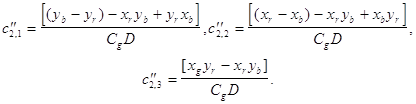
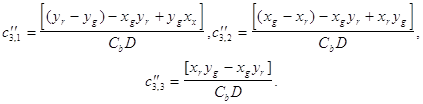
YIQ.
Для цветного телевидения стандарта NTSC было предъявлено два основных требования:
Быть в пределах установленного диапазона в 6 МГц,
Обеспечивать совместимость с черно-белым телевидением.
В 1953 была разработана система YIQ:
| Канал | Название | Занимаемый диапазон |
| Y | яркость | 4 МГц |
| I | синфазный | 1.4 МГц |
| Q | интегрированный | 0.6 МГц |
В канале Y яркость подобрана так, что она соответствует цветовой чувствительности глаза. Канал Y соответствует цветам от голубого до оранжевого (теплым тонам). Канал Q - от зеленого до пурпурного. В качестве опорного белого был взят источник с температурой 6500К. Преобразования между цветовыми системами RGB и YIQ:
RGB в YIQ:
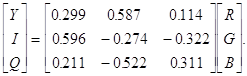
YIQ в RGB:
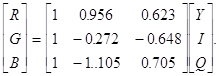
Помимо YIQ встречаются и другие цветовые модели в формате Яркость, 1-ый цветовой канал, 2-ой цветовой канал. Например, при цветовой коррекции используют формат LAB, в котором:
L(ightness)- яркость,
A- цветовой канал несущий цвета от зеленого до красного,
цветовой канал, отвечающий за цвета в сине-желтом диапазоне.
HLS и HSB
Рассмотрим другой подход при
описании цвета. В цвете можно выделить его тон - преобладающий
основной цвет (длину волны, преобладающей в излучении). Также рассмотрим
насыщенность цвета - чем она больше, тем “чище”
цвет (то есть ближе к тоновой волне), например, у белого цвета - насыщенность=
0, так как невозможно выделить его цветовой тон. Введем, наконец, для
завершения яркость (у черного цвета= 0, у белого=1). Таким образом, мы
построили трехмерное цветовое пространство HSV - Hue, Saturation, Volume (Тон, Насыщенность
и Яркость). Обычно его представляют в
виде конуса, изображенного на рисунке. Начало
координат - вершина конуса - черный цвет. Высота, направленная к
основанию - яркость. Точка пересечения высоты с основанием - белый цвет. На
высоте находятся оттенки серого цвета от черного (вершина конуса) к белому. На
окружности, ограничивающей основание конуса, находятся чистые цветовые тона: от
красного (![]() ), через зеленый (
), через зеленый (![]() ),
к синему (
),
к синему (![]() ). Радиус конуса - насыщенность цвета. С такой
системой работают художники, меняя насыщенность с помощью белой краски, его
оттенок с помощью черной и тон, комбинируя с основными цветами. HSV часто
представляют и в виде шестигранного конуса, у которого в основании лежит
правильный шестиугольник с вершинами, соответствующими следующим
цветам : красный - желтый - зеленый - голубой - синий -
пурпурный.
). Радиус конуса - насыщенность цвета. С такой
системой работают художники, меняя насыщенность с помощью белой краски, его
оттенок с помощью черной и тон, комбинируя с основными цветами. HSV часто
представляют и в виде шестигранного конуса, у которого в основании лежит
правильный шестиугольник с вершинами, соответствующими следующим
цветам : красный - желтый - зеленый - голубой - синий -
пурпурный.
Приведем формулы связи RGB и HSV, представленного в виде шестигранного конуса: HSV в RGB:
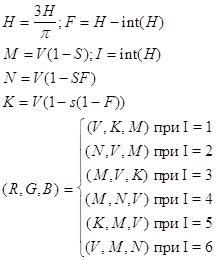
RGB в HSV:
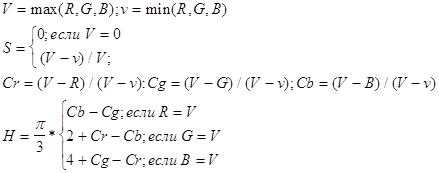
RGB в HLS:
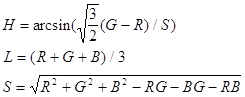
HLS в RGB:
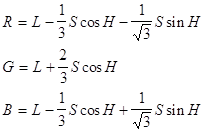
Пример перевода RGB в HSB. В данном формате RGB имеет на каждую из компонент R, G, B по 8 бит (256 уровней градации) - True Color. HSB представлен тремя плоскостями, соответствующими H, S, B, в виде черно/белых изображений с 256 уровнями градации серого.
Каналы: Н - тон, S - насыщенность, B - яркость.
Некоторые примечания к цветовым моделям
При цветовых преобразованиях необходимо также помнить, что между цветовыми моделями CIE, CMY, RGB, YIQ существуют аффинные преобразования, тогда, как между HLS и HSV- нет. Данное обстоятельство будет заметно, если изображение, содержащее непрерывные цветовые переходы, переводить, например, из HLS в RGB (на изображениях может появиться разрыв непрерывности).
2.Общая схема цифровой обработки изображений
Рассмотрим процесс обработки изображений в виде следующей последовательности:
Получение исходного, “сырого” изображения.
Фильтрация изображения.
Перевод изображения в необходимую цветовую модель.
Форматирование и индексирование изображения.
Разбивка на блоки.
Обработка графической информации, содержащейся в блоках.
Последовательное сжатие.
Энтропийное сжатие.
Данное деление не претендует на полноту, но дает общую картину процесса обработки. Некоторые этапы, например, 5, 7 или 8 можно пропустить. Перед каждым этапом, возможно, будет необходима специальная фильтрация. Этап 3 мы рассмотрели в предыдущей части. Другие этапы мы будем рассматривать не по порядку следования, а по возрастанию сложности, чтобы как можно реже ссылаться на материал последующих разделов.
Получение исходного , “сырого” изображения.
Изображения для обработки условно можно разбить на четыре класса:
Естественные, полученные путем сканирования, захвата теле или видео кадра, съемкой цифровой аппаратурой.
Изображения, нарисованные с использованием графического редактора на компьютере, назовем их компьютерными рисунками.
Трехмерные сцены, синтезированные с помощью специальных программ, таких как: CAD’ы (AutoCAD, ArchiCAD ...), 3D генераторы (3D Studio, LightWave ...) и т.п.
Изображения - визуализация данных, полученных как результат некоторого эксперимента, опыта, измерения (энцефалограмма, сейсмографическая карта ...).
Естественные изображения имеют некомпьютерное происхождение. В них почти нет резких цветовых переходов. Компьютерные рисунки, как в прочем и любые другие, подразделяются на два типа: растровые и векторные. В первом изображение хранится как прямоугольная матрица с элементами, характеризующими цветовые составляющие. В векторных изображение - последовательность команд для его построения. Пример команды - круг с центром в точке (100,100) и радиусом 50, текстурированный материалом под дерево. Преимущество растровых - простота воспроизведения и реалистичность, недостаток - большой занимаемый объем, проблемы с масштабированием. У векторных наоборот, преимущество - небольшой занимаемый объем, легкость масштабирования, недостаток - необходимость предварительной обработки перед воспроизведением и трудность создания реалистичных изображений. Трехмерные сцены вынесены в отдельный класс, так как в процессе их создания (например, прямой или обратной трассировкой луча, методом излучательности) можно получить дополнительные данные (характеристики прямого и диффузного отражения света, преломления ... объектов сцены) и использовать их при дальнейшей обработке. Изображения, как результат опыта и т.п. необходимо обработать, с целью выявить его особые характеристики, например, выделить часть изображения лежащую в заданном спектре и т.п. В дальнейшем мы будем рассматривать в основном растровые изображения.
Форматирование и индексирование изображения.
В данном разделе будем рассматривать изображение как прямоугольную матрицу A={ai,j} с N столбцами и M строками, где N - ширина изображения в пикселях, M - высота изображения в пикселях. Рассмотрим основные форматы, применяемые в компьютерной обработке изображений:
Черно-белый. Каждый элемент матрицы представлен одним битом. Если он равен единице, то он отождествляется с черным цветом, если равен нулю - с белым. Это самый простой формат, он применяется при печати газет, распознавании текстов и подписей.
Grayscale(градации серого).Отличие данного формата от предыдущего в том, что для каждого элемента матрицы отводится 8 битов (байт). Это позволит нам использовать 28=256 уровней серого цвета. Если ai,j=0, то имеем белый цвет, с возрастанием до 255 мы будем терять яркость и при ai,j=255 получим черный цвет. В промежутке от 0 до 255 будут располагаться серые цвета по правилу: чем ближе значение к 255, тем чернее будет серый. Данный формат позволяет получать довольно качественные черно-белые изображения. Значения ai,j содержат обратную яркость, т.е. значение (1 - L)*255, где L - яркость, которая может быть получена, например из RGB цветовых изображений по формуле:
L = aR + bG + cG,
где R,G,B лежат в интервале [0;1], а веса a, b, c в сумме дают единицу.
Иногда, для хранения grayscale изображений используют на точку 4-7 и 16 битов. В таком случае мы имеем 16-128 или 65536 оттенков серого цвета.
Многоканальные. В данном случае ai,j представлен в виде вектора с координатами используемой цветовой модели. Обычно вектор трехмерный, так как природа глаза реагирует на три различных цветовых составляющих. Каждый компонент вектора чаще всего занимает байт. Рассмотрим наиболее распространенные многоканальные форматы:
| Название | Соотношение бит | 1-ый компонент | 2-ой компонент | 3-ий компонент |
| RGB - Truecolor | 8:8:8 | Красный0-255 | Зеленый0..255 | Синий0-255 |
| RGB - Highcolor | 5:6:5/5:5:5 | Красный0-31 | Зеленый0.63/31 | Синий0-31 |
| RGB - Extended | 12:12:12/ 16:16:16 | Красный 0-4095/0-65535 | Зеленый 0-4095/0-65535 | Синий0-4095 /0-65535 |
| CMY | 8:8:8 | Голубой0-255 | Пурпур0-255 | Желтый0-255 |
| LAB | 8:8:8 | Яркость0-255 | Канал A 0-100% | Канал B 0-100% |
| YIQ | 8:8:8 | Яркость0-255 | Синфазный 0-255 | Интегрированный 0-255 |
| HLS | 8:8:8 |
Тон 0-3600 |
Яркость0-100% | Насыщенность 0-100% |
| HSB | 8:8:8 |
Тон 0-3600 |
Насыщенность 0-100% | Яркость0-100% |
Встречаются четырех и более мерные вектора, например, модель CMYK, она применяется, когда имеются четыре основных цветовых красителя. Двумерные модели называют дуплексами. Их применяют в полиграфии, например, при печати стандартного grayscale изображения, реально в промышленности оно будет выполнено лишь в ~50 градациях серого, и для повышения числа градаций вводят вторую краску.
Индексированный. Для уменьшения объемов изображения или для использования определенных цветов используют данный формат. Элемент матрицы ai,j является указателем на таблицу цветов. Число используемых цветов равно 2K, где K - количество бит, используемый для хранения элемента матрицы. Цвета в указываемой таблице могут кодироваться другим числом бит. Например, в 256 цветовых режимах видеоадаптеров выбирается 256 цветов из 262144 возможных, так как выбираемые цвета представляются в RGB формате и для каждой цветовой компоненты кодируется 6-ю битами. Существует много методов преобразования многоканальных изображения в индексированные (Error diffusion, ближайшего цвета ...).
Фильтрация изображения.
Понятие фильтрации в данном случае весьма обширно, и включает в себя любое преобразование графической информации. Фильтрация может быть задана не только в виде формулы, но и в виде алгоритма, его реализующая. Человек запоминает графическую информацию, в основном, в виде трех ее составляющих
Низкочастотные составляющие изображения. Они несут информацию о локализации объектов, составляющих изображения. Эта составляющая наиболее важна, так как связка глаз - мозг уделяет ей первостепенное внимание.
Высокочастотные составляющие изображения. Они отвечают за цветовые перепады - контуры изображения. Увеличивая их, мы повышаем резкость изображения.
Текстуры изображения. Чтобы понятно объяснить, что это такое проведем небольшой эксперимент. Расслабьтесь, вспомните интерьер вашего дома, например, письменный стол. Вы знаете его очертания, местоположение, цвет - это низкочастотные характеристики, вспомнили его заостренные углы, небольшую царапину где-нибудь ближе к его кромке - это высокочастотные составляющие. Также Вы знаете, что стол деревянный, но не можете в точности рассказать обо всех мельчайших деталях его поверхности, хотя общие характеристики (коричневый с темными впадинами, две области расхождения концентрических эллипсов от сучков) - наверняка. В данном случае в скобках - описание текстуры. Можно трактовать текстуру как характеристику участков в контурах изображения.
Будем рассматривать фильтры в виде квадратной матрицы A. Пусть исходное изображение X, а получаемое как результат фильтрации - Y. Для простоты будем использовать матрицы 3x3:
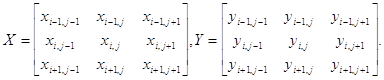
Рекурсивными фильтрами первого рода будут такие фильтры, выход Y которых формируется перемножением весовых множителей A с элементами изображения X. Для примера рассмотрим фильтры низких частот:
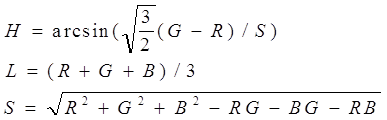 .
.
Фильтром низких частот пользуются часто для того, чтобы подавить шум в изображении, сделать его менее резким. Используя фильтр A3 , будем получать изображение Y следующим образом:
![]() Выход фильтра второго рода формируется аналогично
первому, плюс фильтра B:
Выход фильтра второго рода формируется аналогично
первому, плюс фильтра B:
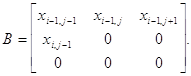
Для простоты рассмотрим
одномерный фильтр вида:![]() :
:
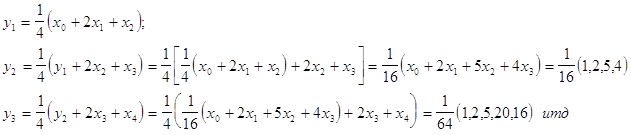 Рассмотрим
и другие фильтры:
Рассмотрим
и другие фильтры:
Высокочастотные (для подчеркивания резкости изображения):
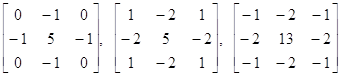
Для подчеркивания ориентации:
Подчеркивание без учета ориентации (фильтры Лапласа):
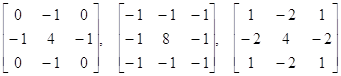 .
.
Корреляционный:
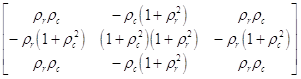 ,где
,где
![]() - коэффициенты корреляции между соседними элементами
по строке (столбцу). Если они равны нулю то отфильтрованное изображение будет
совпадать с исходным, если они равны единице, то фильтр будет эквивалентен
лапласиану. При обработке изображений очень часто используют последовательность
фильтров: низкочастотный + Лапласа. Часто используют и
нелинейную фильтрацию. Для контрастирования перепадов изображения используют
градиентный фильтр:
- коэффициенты корреляции между соседними элементами
по строке (столбцу). Если они равны нулю то отфильтрованное изображение будет
совпадать с исходным, если они равны единице, то фильтр будет эквивалентен
лапласиану. При обработке изображений очень часто используют последовательность
фильтров: низкочастотный + Лапласа. Часто используют и
нелинейную фильтрацию. Для контрастирования перепадов изображения используют
градиентный фильтр:
![]() , или
его упрощенный вид:
, или
его упрощенный вид:
![]() .
.
Еще один часто используемый нелинейный фильтр - Собела:
A0 ... A7 - входы, yi,j - результат фильтрации.
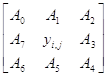
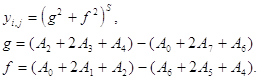
Рекурсивная версия :
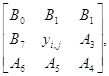 где B0
... B7 - выход
отфильтрованного изображения.
где B0
... B7 - выход
отфильтрованного изображения.
Нелинейная фильтрация - достаточно загадочная область цифровой обработки сигналов, многое еще в ней пока не изучено. Важность же ее не вызывает сомнений, потому, что окружающий нас мир по своей сути не так линеен, как порою хочется его нам интерпретировать.
3.Сжатие.
Изображения, в машинном представлении, - двумерная матрица N на M, где N - его ширина, M - высота. При сканировании обычно используют разрешение от 72 до 2400 dpi (dots per inch - точек на дюйм). Наиболее часто - 300 dpi. Если взять лист бумаги 21/29 см с изображением и отсканировать его в RGB Truecolor, то несжатое изображение будет занимать ~27300000 байтов или 26 Мбайт. Обычно в базах данных применяют изображения порядка от 320x240 до 640x480. Но и они занимают 76 до 900 Кбайт. А что, если таких изображений сотни, тысячи? В данном разделе рассмотрим методы сжатия. Они применительны для любых массивов данных, а не только для изображений. О методах сжатия, характерных только для изображений узнаем немного позже. Будем рассматривать статическое сжатие, то есть массив данных для сжатия целиком сформирован. Методы сжатия статического часто подразделяют на последовательное и энтропийное. Последовательное сжатие использует в работе наличие повторяющихся участков. Энтропийное используется с целью сокращения к минимуму избыточности информации. Последовательное применение этих методов позволяет получить хороший результат.
Последовательное сжатие.
Наиболее часто применяют метод RLE, суть которого рассмотрим на изображении. Почти в любом изображении, особенно в компьютерных рисунках, встречаются последовательности одинаковых байтов. Например, в участке изображения, в котором нарисована часть неба, идут подряд несколько значений голубого цвета. Для участка вида: ККККККККЗЗЗЗСЗССССССССС , где К- красный, З - зеленый, С - синий цвета, будет закодирован как (8,К),(4,З),С,З,(10,С). В скобках - пары количество повторений, значение байта. Вот как данный метод применяется в формате PCX. Декодирование: если код принадлежит множеству [192..255], то вычитаем из него 192 и получаем количество повторений следующего байта. Если же он меньше 192, то помещаем его в декодируемый поток без изменений. Оригинально кодируются единичные байты в диапазоне [192..255] - двумя байтами, например, чтобы закодировать 210 необходимо, представить его как (193, 210). Данный метод дает выигрыш в среднем в 2 раза. Однако для отсканированных изображений, содержащих плавные цветовые переходы (то есть повторяющиеся цепочки почти не встречаются), данный метод может преподнести сюрприз - размер массива с закодированным изображением будет больше исходного.
Наиболее распространены в настоящее время модификации алгоритма LZ (по имени их авторов - Лемпела и Зива). По сравнению с RLE сделан шаг вперед - будем искать в исходном материале не последовательности одинаковых видов, а повторяющихся цепочек символов. Повторяющие цепочки в кодированном сообщении хранятся как ссылка на первое появление данной цепочки. Например, в цепочке КЗСЗБСКЗСЗБ начиная с 7 символа, идет цепочка КЗСЗ, которую мы можем заменить ссылкой на 1-ый символ. Рассмотрим наиболее распространенные реализации алгоритма LZ:
LZ77 - при работе выдает тройки вида (A, B, C), где A - смещение (адрес предыдущей цепочки B байтов которой совпадают с кодируемой цепочкой), B - длина цепочки, C - первый символ в кодируемом массиве, следующий за цепочкой. Если совпадение не обнаружено то создается тройка вида (0, 0, С), где C - первый символ кодируемой цепочки. Недостаток такого подхода очевиден - при кодировании “редких” байтов мы “сжимаем” один байт в три. Преимущество - простота реализации, большая скорость декодирования.
LZSS - создает при работе вектора вида (флаг, C) и (флаг, A, B). Если битовый флаг=0, то следующий за ним C трактуется, как единичный байт и выдается в декодируемый массив. Иначе, когда флаг=1, то в декодируемый массив выдается цепочка длиною B по смещению A. LZSS кодирует намного более эффективно, по сравнению с LZ77, так как использует битовые флаги и мало проигрывает при кодировании одиночных символов. При кодировании строится словарь встречающихся цепочек в виде двоичного упорядоченного дерева. Скорость и простота алгоритма декодирования массива у LZSS также высока.
LZMX (упрощенный LZM) - данный алгоритм предназначен для скоростного кодирования и по эффективности уступает LZSS, заметно обгоняя его по скорости работы. При работе кодер LZMX формирует несколько векторов вида:
(0, A, несжатый поток) - где 00 -2х битовый флаг признака данного блока, A (7 битов с диапазоном в [1..127]) - длина следующего за ним несжатого потока в байтах..
(0, 0000000, A, B) - где, A - количество повторяющего байта B. То есть код RLE.
(1, A, B) - где A(7 битов с диапазоном в [1..127]) - длина декодируемой цепочки, B - ее смещение.
Для быстрого поиска повторяющихся цепочек используется хеш. Индекс - 12 битовый, вычисляется как [ (a*4) xor (b*2) ] xor c, где a, b, c - первые символы цепочки. Индекс дает смещение в массиве ранее встреченной цепочки с теми же первыми символами. Использование хеша и дает высокую скорость кодирования.
Декодирование также имеет большую скорость - читается бит - флаг, если он есть 0 и следующие за ним 7 битов также ноль, читаем следующие два байта - A и B и копируем в выходной массив байт B A - раз: если при флаге=0 следующие 7 битов=A больше нуля, то в выходной массив копируем A байтов следующих за A. И, наконец, если флаг установлен в единицу, то читаем A и следующий за ним байт B и копируем в выходной массив цепочку длиною A байт со смещения B.
Существуют и другие модификации алгоритма LZ (LZW, LZS, LZ78 ...). Общее свойство LZ - высокая скорость декодирования. Общая проблема - эффективность поиска кодируемых цепочек. Модификация данного алгоритма используется в графическом формате GIF.
Энтропийное сжатие.
Энтропийное сжатие в отличие от последовательного, в качестве информации о входном массиве использует только частоты встречаемости в нем отдельных байтов. Эту информацию он использует как при кодировании, так и при декодировании массива. Ее представляют в виде 256 компонентного вектора, координата i которого представляет собой сколько раз байт со значением i встречается в исходном массиве. Данный вектор занимает небольшое пространство и почти не влияет на степень компрессии. Многие методы энтропийного кодирования видоизменяют данный вектор в соответствии с используемым алгоритмом. Рассмотрим два наиболее часто используемых методов:
Метод Хаффмана. Данный метод сокращает избыточность массива, создавая при кодировании переменную битовую длину его элементов. Основной принцип таков: наиболее часто встречающемуся байту - наименьшую длину, самому редкому - наибольшую. Рассмотрим простейший пример кодирования методом Хаффмана - способ конечного нуля. Любой элемент кодируется цепочкой битов, состоящей из одних единиц и кончающийся нулем. Таким образом, самый частый закодируем одним битом - 0, следующий за ним по частоте как 10, далее - 110, 1110, 11110 и т.д. Процедура декодирования также очевидна.
Рассмотрим вышесказанное на примере. Пусть дана часть изображения длиной 80 бит - десять цветов и каждый из них закодирован одним байтом (индексированное 256 цветами изображение): КЗСГКСКБСК (где К - красный, З - зеленый и т.д.). Закодируем его. Построим таблицу частоты встречаемости цвета и кода ему соответствующего:
| Цвет | Частота | Код |
| К | 4 | 0 |
| З | 1 | 110 |
| С | 3 | 10 |
| Г | 1 | 1110 |
| Б | 1 | 11110 |
Таким образом, мы закодировали исходный массив как 0 110 10 1110 0 10 0 11110 10 0. Итого: длина выходного сообщения - 22 бита. Степень компрессии ~4.
Метод арифметического кодирования. Данный метод появился позднее. Его принцип - кодирование исходного массива одним числом. Часто входной массив разбивают на одинаковые небольшие участки и кодируют их по отдельности, получая в результате последовательность кодовых чисел. Закодируем предыдущий пример числом, лежащим в единичном диапазоне. Схема кодировки следующая. Строим таблицу частот, каждому элементу таблицы ставим в соответствие диапазон, равный его частоте поделенной на длину входного массива. Устанавливаем верхнюю границу ВГ в 1, нижнюю НГ в 1. Далее N раз выполняем следующую последовательность действий (где N - длина кодируемого участка или всего массива):
Читаем из массива очередной символ.
Установка текущего интервала. Интервал И = ВГ - НГ.
ВГ = НГ + И*ВГ символа (берем из таблицы).
НГ = НГ + И*НГ символа (берем из таблицы).
Рассмотрим на примере: КЗСГКСКБСК. Построим необходимую таблицу:
| Цвет | Частота | Нижняя граница НГ | Верхняя граница ВГ |
| К | 4 | 0 | 0.4 |
| З | 1 | 0.4 | 0.5 |
| С | 3 | 0.5 | 0.8 |
| Г | 1 | 0.8 | 0.9 |
| Б | 1 | 0.9 | 1 |
Теперь, собственно, сама процедура кодирования:
| Шаг | Символ | НГ | ВГ | Интервал |
| 0 | 0 | 1 | 1 | |
| 1 | К | 0 | 0.4 | 0.4 |
| 2 | З | 0.16 | 0.2 | 0.04 |
| 3 | С | 0.18 | 0.192 | 0.012 |
| 4 | Г | 0.1896 | 0.1908 | 0.0012 |
| 5 | К | 0.1896 | 0.19008 | 0.00048 |
| 6 | С | 0.18984 | 0.189984 | 0.000144 |
| 7 | К | 0.18984 | 0.1898976 | 0.0000576 |
| 8 | Б | 0.18989184 | 0.1898976 | 0.00000576 |
| 9 | С | 0.18989472 | 0.189896448 | 0.000001728 |
| 10 | К | 0.18989472 | 0.1898954112 | 0.0000006912 |
Таким образом, любое число в диапазоне [0.18989472 .. 0.1898954112] однозначно кодирует исходный массив. В двоичном дробном виде как 0.XXXXXXXX...Для хранения такого числа хватит n бит (размерность XXXXXXXX....), где n ближайшее целое, удовлетворяющее неравенству: 2n > Интервал-1=0.0000006912-1. Искомое n равно 21. То есть мы можем закодировать исходный массив 21 битом. В данном примере - 001100001001110111111. Процедура декодирования обратная и состоит в выполнении n раз следующего:
Ищем в таблице интервал, в который попадает наше число Ч, и выдаем символ в него входящий в декодируемый массив.
Интервал И = ВГ символа - НГ символа (оба значения - из таблицы).
Ч = (Ч - НГ) / И.
| Шаг | Число | Символ | НГ | ВГ | Интервал |
| 1 | 0.18989472 | К | 0 | 0.4 | 0.4 |
| 2 | 0.4747368 | З | 0.4 | 0.5 | 0.1 |
| 3 | 0.747368 | С | 0.5 | 0.8 | 0.3 |
| 4 | 0.82456 | Г | 0.8 | 0.9 | 0.1 |
| 5 | 0.2456 | К | 0 | 0.4 | 0.4 |
| 6 | 0.614 | С | 0.5 | 0.8 | 0.3 |
| 7 | 0.38 | К | 0 | 0.4 | 0.4 |
| 8 | 0.95 | Б | 0.9 | 1 | 0.1 |
| 9 | 0.5 | С | 0.5 | 0.8 | 0.3 |
| 10 | 0 | К | 0 | 0.4 | 0.4 |
В данном примере арифметический кодер “обогнал” метод Хаффмана на 1 бит. В отличие от метода Хаффмана трудоемкость алгоритма значительна. В чем же тогда “полезность” алгоритма? Рассмотрим последовательность КККККККС. При кодировании методом Хаффмана получим выходную последовательность длиной в 9 бит (можно и в 8, так как массив состоит из 2 разных байт). При арифметическом кодировании данную последовательность можно закодировать числом 0.4375 или в двоичном виде как 0111, занимающей 4 бита. То есть при арифметическом кодировании возможно получать плотность кодирования меньше бита на символ. Это свойство проявляется, когда во входном массиве частоты некоторых символов значительно выше остальных.
Обработка графической информации .
Для простоты изложения пусть изображение хранится в квадратной матрице X с элементами xi,j N строк на N столбцов. Для некоторых методов применяют разбивку исходного изображения на блоки. Обрабатывая матрицу, мы будем иметь временную сложность алгоритма как минимум кратной N3 . Для ее уменьшения поступают следующим образом: разбивают изображение на несколько малых размером n на n, n << N, каждое малое изображение будем обрабатывать отдельно. Тогда, вместо N3 будем иметь N2n сложность алгоритма.
В данном разделе будем рассматривать сжатие графической информации с потерями. То есть из сжатого выходного массива невозможно при декодировании получить исходный. Но будем сжимать таким образом, чтобы потери как можно меньше воспринимались глазом при демонстрации данной графической информации.
Самый первый способ, который приходит в голову, следующий. Уменьшим количество бит для хранения одного пикселя (элемента исходной матрицы). Пусть пикселы исходного изображения имеют формат RGB Truecolor 8:8:8 (на каждую цветовую составляющую отводится по 8 бит). Перекодируем изображение в формат 5:5:5 (то есть каждая цветовая составляющая будет иметь 25 =32 градации), отбрасывая младшие четыре бита изображения. Мы также можем использовать свойство глаза наиболее хорошо различать цвет в области зеленого и кодировать изображение в формат RGB 4:5:4 и каждый пиксел будет занимать два байта.
Можно пойти еще дальше: перевести исходное изображение в другую цветовую модель и отформатировать его. Например, в YIQ 6:3:3 - отводим на яркость 6 бит, на синфазный и интегрированный каналы по 3, используя то, что человеку более важна информация об интенсивности, нежели о цвете. При “жадном” кодировании, когда используем малое количество бит на пиксел, сразу после декодирования, перед выводом изображения можно провести так называемый anti-aliasing - сгладить резкие цветовые переходы, возникшие из-за малого числа градаций цветовых составляющих. Дальнейшее усовершенствование заключается в индексировании цветов. RGB Truecolor формат может поддерживать более 16 млн. цветов. Выберем n (обычно n - степень 2 ) индексных цветов cK так, чтобы минимизировали сумму:
![]() .
.
Далее создаем выходной массив B N на N, элемент которого bi,j равен
k, где k= m - номер цвета такой, что
выполняется ![]() .
Выходная информация - массив B
и собственно таблица индексных цветов c.
Результаты данного подхода можно посмотреть в разделе “Форматирование
и индексирование изображений”.
.
Выходная информация - массив B
и собственно таблица индексных цветов c.
Результаты данного подхода можно посмотреть в разделе “Форматирование
и индексирование изображений”.
Рассмотрим семейство кодеров изображения, основанных на отбросе коэффициентов преобразования. Все они используют разбивку на блоки. Пусть Y - получаемое изображение, A - матрица преобразования.
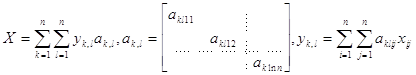 .
.
После преобразования, сохраняем только часть коэффициентов, за счет чего и осуществляется сжатие. Наиболее эффективным будет метод, минимизирующий оценку:
![]() . Самый
оптимальный метод - Карунена-Лоэва. Строки матрицы преобразования A -
нормированные собственные вектора Kx, то есть являются
решением уравнения вида Kxx
= ix, Kx = E{(x- Ex)(x-Ex)T}
- ковариация, E - мат. ожидание,
T - знак транспонирования. Коэффициенты преобразования y=Ax имеют
матрицу преобразования вида:
. Самый
оптимальный метод - Карунена-Лоэва. Строки матрицы преобразования A -
нормированные собственные вектора Kx, то есть являются
решением уравнения вида Kxx
= ix, Kx = E{(x- Ex)(x-Ex)T}
- ковариация, E - мат. ожидание,
T - знак транспонирования. Коэффициенты преобразования y=Ax имеют
матрицу преобразования вида:
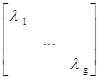 , где
..-
собственные значения Kx. Отбрасывая малые собственные значения получаем сжатие.
Данный метод, хотя и дает наименьшую ошибку приближения среди аналогичных
кодеров, используется редко, так как требует большого объема вычислений при
своей работе. Преобразование Карунена-Лоэва называют также оптимальным
кодированием. Рассмотрим другие кодеры данного семейства:
, где
..-
собственные значения Kx. Отбрасывая малые собственные значения получаем сжатие.
Данный метод, хотя и дает наименьшую ошибку приближения среди аналогичных
кодеров, используется редко, так как требует большого объема вычислений при
своей работе. Преобразование Карунена-Лоэва называют также оптимальным
кодированием. Рассмотрим другие кодеры данного семейства:
Фурье,![]() , для данного
преобразования существует алгоритм, с временной сложностью n2log2n. Преобразование Фурье представляет собой разложение по
спектру.
, для данного
преобразования существует алгоритм, с временной сложностью n2log2n. Преобразование Фурье представляет собой разложение по
спектру.
Дискретное косинусное преобразование (ДКП).
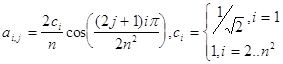 .Наиболее используемый
.Наиболее используемый
в настоящее время метод, так как он дает результат ошибку приближения чуть больше чем разложению Карунена-Лоэва. Существует алгоритм, реализующий данный метод со сложностью 2n2log2n-1.5n+4.
Симметричное преобразование Адамара.
![]() , где
, где
il и jl
- состояние разрядов двоичного
представление чисел i и j. Для n=2
матрица будет следующей: 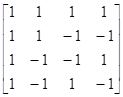 .
Хотя метод Адамара не дает столь хороших результатов как предыдущие, зато все
операции преобразование сводится к сложениям и вычитаниям.
.
Хотя метод Адамара не дает столь хороших результатов как предыдущие, зато все
операции преобразование сводится к сложениям и вычитаниям.
При отборе коэффициентов пользуются следующими способами:
Пороговый отбор. Отбрасываются коэффициенты, которые по модулю, ниже установленного порога.
Зональный отбор. Отбрасываются коэффициенты, принадлежащие к малокритичному спектру. Например, при ДКП или преобразовании Фурье можем отбросить часть коэффициентов, принадлежащих к высокочастотному спектру, так как чувствительность глаза выше в низкочастотной области.
Обычно отбрасываемые коэффициенты обнуляют. Далее применяют последовательное и энтропийное сжатие. Так работает алгоритм JPEG кодирования. Все это дает снижение размера массива, при приемлемом качестве изображения, в 5-16 раз. На приведенном примере использовалось исходное изображение в разрешении 240 на 362 пикселя в RGB Truecolor и занимало 240*362*3=260640 байт. Левое сжатое изображение занимает 46000 байт и внешне не отличается от исходного. Левое нижнее изображение имеет размер 8004 байт и имеет заметные резкие цветовые переходы в области неба. Правое нижнее изображение имеет размер 5401 байт (!) и хотя изображение стало слишком мозаичным, мы вполне можем понять его содержание. При использовании разбивок на блоки иногда возникает побочный эффект: становятся заметными границы блоков. Для борьбы с ним разбивку проводят так, чтобы блоки “наезжали” на границы соседних с ним блоков.
Другой принцип лежит в основе пирамидального кодирования. Пусть x(k,l) - исходное изображение. Получим из него его низкочастотную, с частотой среза f1, “версию” x1(k,l) с помощью локального усреднения с одномодовым гауссоподобным двумерным импульсным откликом. x1(k,l) можно рассматривать как предсказание для c. e1(k,l) = x(k,l) - x1(k,l) - ошибка предсказания, далее повторяем для частоты среза f2: e2(k,l) = x1(k,l) - x2(k,l) - ошибка предсказания меньше чем для e1 в f1/f2 раз. Получаем в итоге последовательность e1 ,e2 , .., et. На каждой итерации размерность изображения сокращается в fi /fi+1 раз. Данный метод уменьшает занимаемый размер в 10..20 раз при приемлемом качестве изображения. Но сложность алгоритма выше по сравнению с предыдущими методами.
Рассмотрим еще один метод сжатия изображения - выращивания областей, который в корне отличается от остальных. Он рассматривает изображение как набор граничащих друг с другом текстурных контуров, внутри каждого из которых нет резкого изменения уровня цветовой составляющей. Перед работой метода, возможно несколько раз придется произвести предобработку, заключающуюся в сокращении зернистости, но сохраняющей контуры в изображении (то есть малые перепады уровня усредняем, а большие - оставляем). Для этих целей обычно применяют обратный градиентный фильтр. Далее начинаем разметку областей. Область - часть изображения, пикселы которой обладают неким общим свойством - принадлежат к одной полосе частот, обладают близким значением определенной цветовой составляющей. Разметка осуществляется в два этапа:
Начиная с данного пикселя изображения, относительно его соседа проверяем: обладает ли он общим свойством области. Если это так, то он включается в данную область, и далее проверяются его соседи и т.д. Когда больше не остается элементов, смежных с данным контуром процедура останавливается и начинается снова для пикселей, не вошедших в данную область.
Уменьшение числа областей. Обычно в изображении 70% созданных областей содержатся в 4% изображения. Соседние области объединяют, если они обладают близкими свойствами, также удаляют незначительные (по размеру), области. Алгоритмы создания и удаления областей - задача не простая и может быть оптимизирована по многим направлениям различными способами. Именно от нее зависит дальнейшая эффективность алгоритма.
Рассмотрим собственно кодирование. Оно состоит из двух этапов: 1 - кодирование контуров и 2 - текстур, лежащих в них. Контуры представляются в виде матрицы с битовыми элементами, который равен 1, если точка входит в границу области - контур и 0 - иначе. Данную матрицу можно энтропийно сжать с эффективностью ~1.2 .. 1.3 бита на пиксел контура. Текстура (содержимое) каждой области приближается средним уровнем свойства ее области и двумерным полиномом (линейным, квадратным или кубическим - в зависимости от реализации и требований к качеству). При декодировании прибавим зернистость в текстуру с помощью гауссова псевдослучайного фильтра с уже известной среднеквадратичной ошибкой. Данный метод позволяет добиться сжатия изображения в 20..75 раз с приемлемым качеством изображения. Временные затраты при его реализации весьма велики. При работе данного метода мы также можем (с небольшими дополнительными вычислениями) параллельно перевести изображение в векторную форму.