Реферат: Экспертные системы. Классификация экспертных систем. Разработка простейшей экспертной системы
Введение
Экспертные системы (ЭС) возникли как значительный практический результат в применении и развитии методов искусственного интеллекта (ИИ)- совокупности научных дисциплин, изучающих методы решения задач интеллектуального (творческого) характера с использованием ЭВМ.
Область ИИ имеет более чем сорокалетнюю историю развития. С самого начала в ней рассматривался ряд весьма сложных задач, которые, наряду с другими, и до сих пор являются предметом исследований: автоматические доказательства теорем, машинный перевод (автоматический перевод с одного естественного языка на другой), распознавание изображений и анализ сцен, планирование действий роботов, алгоритмы и стратегии игр.
ЭС- это набор программ, выполняющий функции эксперта при решении задач из некоторой предметной области. ЭС выдают советы, проводят анализ, дают консультации, ставят диагноз. Практическое применение ЭС на предприятиях способствует эффективности работы и повышению квалификации специалистов.
Главным достоинством экспертных систем является возможность накопления знаний и сохранение их длительное время. В отличии от человека к любой информации экспертные системы подходят объективно, что улучшает качество проводимой экспертизы. При решении задач, требующих обработки большого объема знаний, возможность возникновения ошибки при переборе очень мала.
При создании ЭС возникает ряд затруднений. Это прежде всего связано с тем, что заказчик не всегда может точно сформулировать свои требования к разрабатываемой системе. Также возможно возникникновение трудностей чисто психологического порядка: при создании базы знаний системы эксперт может препятствовать передаче своих знаний, опасаясь, что впоследствии его заменят “машиной”. Но эти страхи не обоснованы, т. к. ЭС не способны обучаться, они не обладают здравым смыслом, интуицией. Но в настоящее время ведутся разработки экспертных систем, реализующих идею самообучения. Также ЭС неприменимы в больших предметных областях и в тех областях, где отсутствуют эксперты.
Экспертная система состоит из базы знаний (части системы, в которой содержатся факты), подсистемы вывода (множества правил, по которым осуществляется решение задачи), подсистемы объяснения, подсистемы приобретения знаний и диалогового процессора .
При построении подсистем вывода используют методы решения задач искусственного интеллекта.
Глава 1. Экспертные системы, их особенности.
Применение экспертных систем.
1.1. Определение экспертных систем. Главное достоинство и назначение экспертных систем.
Экспертные системы (ЭС)- это яркое и быстро прогрессирующее направление в области искусственного интеллекта(ИИ). Причиной повышенного интереса, который ЭС вызывают к себе на протяжении всего своего существования является возможность их применения к решению задач из самых различных областей человеческой деятельности. Пожалуй, не найдется такой проблемной области, в которой не было бы создано ни одной ЭС или по крайней мере, такие попытки не предпринимались бы.
ЭС- это набор программ или программное обеспечение, которое выполняет функции эксперта при решении какой-либо задачи в области его компетенции. ЭС, как и эксперт-человек, в процессе своей работы оперирует со знаниями. Знания о предметной области, необходимые для работы ЭС, определенным образом формализованы и представлены в памяти ЭВМ в виде базы знаний, которая может изменяться и дополняться в процессе развития системы.
ЭС выдают советы, проводят анализ, выполняют классификацию, дают консультации и ставят диагноз. Они ориентированы на решение задач, обычно требующих проведения экспертизы человеком-специалистом. В отличие от машинных программ, использующий процедурный анализ, ЭС решают задачи в узкой предметной области (конкретной области экспертизы)на основе дедуктивных рассуждений. Такие системы часто оказываются способными найти решение задач, которые неструктурированны и плохо определены. Они справляются с отсутствием структурированности путем привлечения эвристик, т. е. правил, взятых “с потолка”, что может быть полезным в тех системах, когда недостаток необходимых знаний или времени исключает возможность проведения полного анализа.
Главное достоинство ЭС- возможность накапливать знания, сохранять их длительное время, обновлять и тем самым обеспечивать относительную независимость конкретной организации от наличия в ней квалифицированных специалистов. Накопление знаний позволяет повышать квалификацию специалистов, работающих на предприятии, используя наилучшие, проверенные решения.
Практическое применение искусственного интеллекта на машиностроительных предприятиях и в экономике основано на ЭС, позволяющих повысить качество и сохранить время принятия решений, а также способствующих росту эффективности работы и повышению квалификации специалистов.
1.2. Отличие ЭС от других программных продуктов.
Основными отличиями ЭС от других программных продуктов являются использование не только данных, но и знаний, а также специального механизма вывода решений и новых знаний на основе имеющихся. Знания в ЭС представляются в такой форме, которая может быть легко обработана на ЭВМ. В ЭС известен алгоритм обработки знаний, а не алгоритм решения задачи. Поэтому применение алгоритма обработки знаний может привести к получению такого результата при решении конкретной задачи, который не был предусмотрен. Более того, алгоритм обработки знаний заранее неизвестен и строится по ходу решения задачи на основании эвристических правил. Решение задачи в ЭС сопровождается понятными пользователю объяснениями, качество получаемых решений обычно не хуже, а иногда и лучше достигаемого специалистами. В системах, основанных на знаниях, правила (или эвристики), по которым решаются проблемы в конкретной предметной области, хранятся в базе знаний. Проблемы ставятся перед системой в виде совокупности фактов, описывающих некоторую ситуацию, и система с помощью базы знаний пытается вывести заключение из этих фактов (см.. рис.1).

база знаний

входная механизм заключения
 информация
вывода
информация
вывода
рис.1
Качество ЭС определяется размером и качеством базы знаний (правил или эвристик). Система функционирует в следующем циклическом режиме: выбор (запрос) данных или результатов анализов, наблюдения, интерпретация результатов, усвоение новой информации, выдвижении с помощью правил временных гипотез и затем выбор следующей порции данных или результатов анализов (рис.2). Такой процесс продолжается до тех пор, пока не поступит информация, достаточная для окончательного заключения.
В любой момент времени в системе существуют три типа знаний:
- Структурированные знания- статические знания о предметной области. После того как эти знания выявлены, они уже не изменяются.
- Структурированные динамические знания- изменяемые знания о предметной области. Они обновляются по мере выявления новой информации.
- Рабочие знания- знания, применяемые для решения конкретной задачи или проведения консультации.
Все перечисленные выше знания хранятся в базе знаний. Для ее построения требуется провести опрос специалистов, являющихся экспертами в конкретной предметной области, а затем систематизировать, организовать и снабдить эти знания указателями, чтобы впоследствии их можно было легко извлечь из базы знаний.

Результаты анализов
и входные данные


выбор и ввод
исходных данных


 наблюдения
пользователи
наблюдения
пользователи
интерпретация правила

 гипотезы
усвоение
вывод
гипотезы
усвоение
вывод
заключения
рис.2 Схема работы ЭС.
1.3. Отличительные особенности. Экспертные системы первого и второго поколения.
1. Экспертиза может проводиться только в одной конкретной области. Так, программа, предназначенная для определения кон-
фигурации систем ЭВМ, не может ставить медицинские диагнозы.
2. База знаний и механизм вывода являются различными компонентами. Действительно, часто оказывается возможным сочетать механизм вывода с другими базами знаний для создания новых ЭС. Например, программа анализа инфекции в крови может быть применена в пульманологии путем замены базы знаний, используемой с тем же самым механизмом вывода.
3. Наиболее подходящая область применения- решение задач дедуктивным методом. Например, правила или эвристики выражаются в виде пар посылок и заключений типа “если-то”.
4. Эти системы могут объяснять ход решения задачи понятным пользователю способом. Обычно мы не принимаем ответ эксперта, если на вопрос “Почему ?” не можем получить логичный ответ. Точно так же мы должны иметь возможность спросить систему, основанную на знаниях, как было получено конкретное заключение.
5. Выходные результаты являются качественными (а не количественными).
6. Системы, основанные на знаниях, строятся по модульному принципу, что позволяет постепенно наращивать их базы знаний.
Компьютерные системы, которые могут лишь повторить логический вывод эксперта, принято относить к ЭС первого поколения. Однако специалисту, решающему интеллектуально сложную задачу, явно недостаточно возможностей системы, которая лишь имитирует деятельность человека. Ему нужно, чтобы ЭС выступала в роли полноценного помощника и советчика, способного проводить анализ нечисловых данных, выдвигать и отбрасывать гипотезы, оценивать достоверность фактов, самостоятельно пополнять свои знания, контролировать их непротиворечивость, делать заключения на основе прецедентов и, может быть, даже порождать решение новых, ранее не рассматривавшихся задач. Наличие таких возможностей является характерным для ЭС второго поколения, концепция которых начала разрабатываться 9-10 лет назад. Экспертные системы, относящиеся ко второму поколению, называют партнерскими, или усилителями интеллектуальных способностей человека. Их общими отличительными чертами является умение обучаться и развиваться, т.е. эволюционировать.
В экспертных системах первого поколения знания представлены следующим образом:
1) знаниями системы являются только знания эксперта, опыт накопления знаний не предусматривается.
2) методы представления знаний позволяли описывать лишь статические предметные области.
3) модели представления знаний ориентированы на простые области.
Представление знаний в экспертных системах второго поколения следующее:
1) используются не поверхностные знания, а более глубинные. Возможно дополнение предметной области.
2) ЭС может решать задачи динамической базы данных предметной области.
1.4. Области применения экспертных систем.
Области применения систем, основанных на знаниях, могут быть сгруппированы в несколько основных классов: медицинская диагностика, контроль и управление, диагностика неисправностей в механических и электрических устройствах, обучение.
а) Медицинская диагностика.
Диагностические системы используются для установления связи между нарушениями деятельности организма и их возможными причинами. Наиболее известна диагностическая система MYCIN, которая предназначена для диагностики и наблюдения за состоянием больного при менингите и бактериальных инфекциях. Ее первая версия была разработана в Стенфордском университете в середине 70-х годов. В настоящее время эта система ставит диагноз на уровне врача-специалиста. Она имеет расширенную базу знаний, благодаря чему может применяться и в других областях медицины.
б) Прогнозирование.
Прогнозирующие системы предсказывают возможные результаты или события на основе данных о текущем состоянии объекта. Программная система “Завоевание Уолл-стрита” может проанализировать конъюнктуру рынка и с помощью статистических методов алгоритмов разработать для вас план капиталовложений на перспективу. Она не относится к числу систем, основанных на знаниях, поскольку использует процедуры и алгоритмы традиционного программирования. Хотя пока еще отсутствуют ЭС, которые способны за счет своей информации о конъюнктуре рынка помочь вам увеличить капитал, прогнозирующие системы уже сегодня могут предсказывать погоду, урожайность и поток пассажиров. Даже на персональном компьютере, установив простую систему, основанную на знаниях, вы можете получить местный прогноз погоды.
в) Планирование.
Планирующие системы предназначены для достижения конкретных целей при решении задач с большим числом переменных. Дамасская фирма Informat впервые в торговой практике предоставляет в распоряжении покупателей 13 рабочих станций, установленных в холле своего офиса, на которых проводятся бесплатные 15-минутные консультации с целью помочь покупателям выбрать компьютер, в наибольшей степени отвечающий их потребностям и бюджету. Кроме того, компания Boeing применяет ЭС для проектирования космических станций, а также для выявления причин отказов самолетных двигателей и ремонта вертолетов. Экспертная система XCON, созданная фирмой DEC, служит для определения или изменения конфигурации компьютерных систем типа VAX и в соответствии с требованиями покупателя. Фирма DEC разрабатывает более мощную систему XSEL, включающую базу знаний системы XCON, с целью оказания помощи покупателям при выборе вычислительных систем с нужной конфигурацией. В отличие от XCON система XSEL является интерактивной.
г) Интерпретация.
Интерпретирующие системы обладают способностью получать определенные заключения на основе результатов наблюдения. Система PROSPECTOR, одна из наиболее известных систем интерпретирующего типа, объединяет знания девяти экспертов. Используя сочетания девяти методов экспертизы, системе удалось обнаружить залежи руды стоимостью в миллион долларов, причем наличие этих залежей не предполагал ни один из девяти экспертов. Другая интерпретирующая система- HASP/SIAP. Она определяет местоположение и типы судов в тихом океане по данным акустических систем слежения.
д) Контроль и управление.
Системы, основанные на знаниях, могут применятся в качестве интеллектуальных систем контроля и принимать решения, анализируя данные, поступающие от нескольких источников. Такие системы уже работают на атомных электростанциях, управляют воздушным движением и осуществляют медицинский контроль. Они могут быть также полезны при регулировании финансовой деятельности предприятия и оказывать помощь при выработке решений в критических ситуациях.
е) Диагностика неисправностей в механических и электрических устройствах.
В этой сфере системы, основанные на знаниях, незаменимы как при ремонте механических и электрических машин (автомобилей, дизельных локомотивов и т.д.), так и при устранении неисправностей и ошибок в аппаратном и программном обеспечении компьютеров.
ж) Обучение.
Системы, основанные на знаниях, могут входить составной частью в компьютерные системы обучения. Система получает информацию о деятельности некоторого объекта (например, студента) и анализирует его поведение. База знаний изменяется в соответствии с поведением объекта. Примером этого обучения может служить компьютерная игра, сложность которой увеличивается по мере возрастания степени квалификации играющего. Одной из наиболее интересных обучающих ЭС является разработанная Д.Ленатом система EURISCO, которая использует простые эвристики. Эта система была опробована в игре Т.Тревевеллера, имитирующая боевые действия. Суть игры состоит в том, чтобы определить состав флотилии, способной нанести поражение в условиях неизменяемого множества правил. Система EURISCO включила в состав флотилии небольшие, способные провести быструю атаку корабли и одно очень маленькое скоростное судно и постоянно выигрывала в течение трех лет, несмотря на то, что в стремлении воспрепятствовать этому правила игры меняли каждый год.
Большинство ЭС включают знания, по содержанию которых их можно отнести одновременно к нескольким типам. Например, обучающая система может также обладать знаниями, позволяющими выполнять диагностику и планирование. Она определяет способности обучаемого по основным направлениям курса, а затем с учетом полученных данных составляет учебный план. Управляющая система может применяться для целей контроля, диагностики, прогнозирования и планирования. Система, обеспечивающая сохранность жилища, может следить за окружающей обстановкой, распознавать происходящие события (например, открылось окно), выдавать прогноз (вор-взломщик намеревается проникнуть в дом) и составлять план действий (вызвать полицию).
1.5. Критерий использования ЭС для решения задач.
Существует ряд прикладных задач, которые решаются с помощью систем, основанных на знаниях, более успешно, чем любыми другими средствами. При определении целесообразности применения таких систем нужно руководствоваться следующими критериями.
1. Данные и знания надежны и не меняются со временем.
2. Пространство возможных решений относительно невелико.
3. В процессе решения задачи должны использоваться формальные рассуждения. Существуют системы, основанные на знаниях, пока еще не пригодные для решения задач методами проведения аналогий или абстрагирования (человеческий мозг справляется с этим лучше). В свою очередь традиционные компьютерные программы оказываются эффективнее систем, основанных на знаниях, в тех случаях, когда решение задачи связано с применением процедурного анализа. Системы, основанные на знаниях, более подходят для решения задач, где требуются формальные рассуждения.
4. Должен быть по крайней мере один эксперт, который способен явно сформулировать свои знания и объяснить свои методы применения этих знаний для решения задач.
В таблице один приведены сравнительные свойства прикладных задач, по наличию которых можно судить о целесообразности использования для их решения ЭС.
Таблица 1. Критерий применимости ЭС.
| применимы | неприменимы |
|
Не могут быть построены строгие алгоритмы или процедуры, но существуют эвристические методы решения. |
Имеются эффективные алгоритмические методы. |
| Есть эксперты, которые способны решить задачу. | Отсутствуют эксперты или их число недостаточно. |
|
По своему характеру задачи относятся к области диагностики, интерпретации или прогнозирования. |
Задачи носят вычислительный характер. |
| Доступные данные “зашумленны”. | Известны точные факты и строгие процедуры. |
|
Задачи решаются методом формальных рассуждений. |
Задачи решаются прецедурными методами, с помощью аналогии или интуитивно. |
| Знания статичны (неизменны). | Знания динамичны (меняются со временем). |
В целом ЭС не рекомендуется применять для решения следующих типов задач:
- математических, решаемых обычным путем формальных преобразований и процедурного анализа;
- задач распознавания, поскольку в общем случае они решаются численными методами;
- задач, знания о методах решения которых отсутствуют (невозможно построить базу знаний).
1.6. Ограничения в применение экспертных систем..
Даже лучшие из существующих ЭС, которые эффективно функционируют как на больших, так и на мини-ЭВМ, имеют определенные ограничения по сравнению с человеком-экспертом.
1. Большинство ЭС не вполне пригодны для применения конечным пользователем. Если вы не имеете некоторого опыта работы с такими системами, то у вас могут возникнуть серьезные трудности. Многие системы оказываются доступными только тем экспертам, которые создавали из базы знаний.
2. Вопросно-ответный режим, обычно принятый в таких системах, замедляет получение решений. Например, без системы MYCIN врач может (а часто и должен) принять решение значительно быстрее, чем с ее помощью.
3. Навыки системы не возрастают после сеанса экспертизы.
4. Все еще остается проблемой приведение знаний, полученных от эксперта, к виду, обеспечивающему их эффективную машинную реализацию.
5. ЭС не способны обучаться, не обладают здравым смыслом. Домашние кошки способны обучаться даже без специальной дрессировки, ребенок в состоянии легко уяснить, что он станет мокрым, если опрокинет на себя стакан с водой, однако если начать выливать кофе на клавиатуру компьютера, у него не хватит “ума” отодвинуть ее.
6. ЭС неприменимы в больших предметных областях. Их использование ограничивается предметными областями, в которых эксперт может принять решение за время от нескольких минут до нескольких часов.
7. В тех областях, где отсутствуют эксперты (например, в астрологии), применение ЭС оказывается невозможным.
8. Имеет смысл привлекать ЭС только для решения когнитивных задач. Теннис, езда на велосипеде не могут являться предметной областью для ЭС, однако такие системы можно использовать при формировании футбольных команд.
9. Человек-эксперт при решении задач обычно обращается к своей интуиции или здравому смыслу, если отсутствуют формальные методы решения или аналоги таких задач.
Системы, основанные на знаниях, оказываются неэффективными при необходимости проведения скрупулезного анализа, когда число “решений” зависит от тысяч различных возможностей и многих переменных, которые изменяются во времени. В таких случаях лучше использовать базы данных с интерфейсом на естественном языке.
1.7. Преимущества ЭС перед человеком - экспертом.
Системы, основанные на знаниях, имеют определенные преимущества перед человеком-экспертом.
1. У них нет предубеждений.
2. Они не делают поспешных выводов.
3. Эти системы работают систематизировано, рассматривая все детали, часто выбирая наилучшую альтернативу из всех возможных.
4. База знаний может быть очень и очень большой. Будучи введены в машину один раз, знания сохраняются навсегда. Человек же имеет ограниченную базу знаний, и если данные долгое время не используются, то они забываются и навсегда теряются.
Системы, основанные на знаниях, устойчивы к “помехам”. Эксперт пользуется побочными знаниями и легко поддается влиянию внешних факторов, которые непосредственно не связаны с решаемой задачей. ЭС, не обремененные знаниями из других областей, по своей природе менее подвержены “шумам”. Со временем системы, основанные на знаниях, могут рассматриваться пользователями как разновидность тиражирования- новый способ записи и распространения знаний. Подобно другим видам компьютерных программ они не могут заменить человека в решении задач, а скорее напоминают орудия труда, которые дают ему возможность решат задачи быстрее и эффективнее.
6. Эти системы не заменяют специалиста, а являются инструментом в его руках.
1.8. История развития экспертных систем.
1.8.1. Основные линии развития ЭС.
Наиболее известные ЭС, разработанные в 60-70-х годах, стали в своих областях уже классическими. По происхождению, предметным областям и по преемственности применяемых идей, методов и инструментальных программных средств их можно разделить на несколько семейств.
1. META-DENDRAL.Система DENDRAL позволяет определить наиболее вероятную структуру химического соединения по экспериментальным данным (масс- спектрографии, данным ядерном магнитного резонанса и др.).M-D автоматизирует процесс приобретения знаний для DENDRAL. Она генерирует правила построения фрагментов химических структур.
2. MYCIN-EMYCIN-TEIREIAS-PUFF-NEOMYCIN. Это семейство медицинских ЭС и сервисных программных средств для их построения.
3. PROSPECTOR-KAS. PROSPECTOR- предназначена для поиска (предсказания) месторождений на основе геологических анализов. KAS- система приобретения знаний для PROSPECTOR.
4. CASNET-EXPERT. Система CASNET- медицинская ЭС для диагностики выдачи рекомендаций по лечению глазных заболеваний. На ее основе разработан язык инженерии знаний EXPERT, с помощью которой создан ряд других медицинских диагностических систем.
5. HEARSAY-HEARSAY-2-HEARSAY-3-AGE. Первые две системы этого ряда являются развитием интеллектуальной системы распознавания слитной человеческой речи, слова которой берутся из заданного словаря. Эти системы отличаются оригинальной структурой, основанной на использовании доски объявлений- глобальной базы данных, содержащей текущие результаты работы системы. В дальнейшем на основе этих систем были созданы инструментальные системы HEARSAY-3 и AGE (Attempt to Generalize- попытка общения) для построения ЭС.
6. Системы AM (Artifical Mathematician- искусственный математик) и EURISCO были разработаны в Станфордском университете доктором Д. Ленатом для исследовательских и учебных целей. Ленат считает, что эффективность любой ЭС определяется закладываемыми в нее знаниями. По его мнению, чтобы система была способна к обучению, в нее должно быть введено около миллиона сведений общего характера. Это примерно соответствует объему информации, каким располагает четырехлетний ребенок со средними способностями. Ленат также считает, что путь создания узкоспециализированных ЭС с уменьшенным объемом знаний ведет к тупику.
В систему AM первоначально было заложено около 100 правил вывода и более 200 эвристических алгоритмов обучения, позволяющих строить произвольные математические теории и представления. Сначала результаты работы системы были весьма многообещающими. Она могла сформулировать понятия натурального ряда и простых чисел. Кроме того, она синтезировала вариант гипотезы Гольдбаха о том, что каждое четное число, большее двух, можно представить в виде суммы двух простых чисел. До сих пор не удалось ни найти доказательства данной гипотезы, ни опровергнуть ее. Дальнейшее развитие системы замедлилось и было отмечено, что несмотря на проявленные на первых порах “математические способности”, система не может синтезировать новых эвристических правил, т.е. ее возможности определяются только теми эвристиками, что были в нее изначально заложены.
При разработке системы EURISCO была предпринята попытка преодолеть указанные недостатки системы AM. Как и в начале эксплуатации AM, первые результаты, полученные с помощью EURISCO, были эффективными. Сообщалось, что система EURISCO может успешно участвовать в очень сложных играх. С ее помощью в военно-стратегической игре, проводимой ВМФ США, была разработана стратегия, содержащая ряд оригинальных тактических ходов. Согласно одному из них, например предлагалось взрывать свои корабли, получившие повреждения. При этом корабли, оставшиеся неповрежденными, получает необходимое пространство для выполнения маневра.
Однако через некоторое время обнаружилось, что система не всегда корректно переопределяет первоначально заложенные в нее правила. Так, например, она стала нарушать строгое предписание обращаться к программистам с вопросами только в определенное время суток. Т.о., система EURISCO, так же как и ее предшественница, остановилась в своем развитии, достигнув предела, определенного в конечном счете ее разработчиком.
С 1990 года доктор Ленат во главе исследовательской группы занят кодированием и вводом нескольких сот тысяч элементов знаний, необходимых, по его мнению, для создания “интеллекту-
альной” системы. Этот проект назван Cyc (“Цик”, от английского слова enciklopaedia).
1.8.2. Проблемы, возникающие при созданииЭС. Перспективы разработки.
С 70-х годов ЭС стали ведущим направлением в области искусственного интеллекта. При их разработке нашли применение методы ИИ, разработанные ранее: методы представления знаний, логического вывода, эвристического поиска, распознавания предложений на естественном языке и др. Можно утверждать, что именно ЭС позволили получить очень большой коммерческий эффект от примения таких мощных методов. В этом - их особая роль.
Каталог ЭС и инструментальных программных средств для их разработки, опубликованный в США в 1987 году, содержит более 1000 систем (сейчас их уже значительно больше). В развитых зарубежных странах сотни фирм занимаются их разработкой и внедрением. Имеются и отечественные разработки ЭС, в том числе - нашедший промышленное применение.
Однако уже на начальных этапах выявились серьезные принципиальные трудности, препятствующие более широкому распространению ЭС и серьезно замедляющие и осложняющие их разработку. Они вполне естественных и вытекают из самих принципов разработки ЭС.
Первая трудность возникает в связи с постановкой задач. Большинство заказчиков, планируя разработку ЭС, в следствие недостаточной компетентности в вопросах применения методов ИИ, склонна значительно преувеличивать ожидаемые возможности системы. Заказчик желает увидеть в ней самостоятельно мыслящего эксперта в исследуемой области, способного решать широкий круг задач. Отсюда и типичные первоначальные постановки задачи по созданию ЭС: “Разработать ЭС по обработке изображения”; “Создать медицинские ЭС по лечению заболеваний опорно-двигательного аппарата у детей”. Однако, как уже отмечалось, мощность эвристических методов решения задач при увеличении общности их постановки резко уменьшается. Поэтому наиболее целесообразно (особенно при попытке создания ЭС в области, для которой у разработчиков еще нет опыта создания подобных систем) ограничиться для начала не слишком сложной обозримой задачей в рассматриваемой области, для решения которой нет простого алгоритмического способа (то есть неочевидно, как написать программу для решения этой задачи, не используя методы обработки знаний). Кроме того, важно, чтобы уже существовала сложившаяся методика решения этой задачи “вручную” или какими-либо расчетными методами. Для успешной разработки ЭС необходимы не только четкая и конкретная постановка задач, но и разработка подробного (хотя бы словесного) описания “ручного” (или расчетного) метода ее решения. Если это сделать затруднительно, дальнейшая работа по построению ЭС теряет смысл.
Вторая и основная трудность - проблема приобретения (усвоения) знаний. Эта проблема возникает при “передаче” знаний, которыми обладают эксперты-люди, ЭС. Разумеется для того, чтобы “обучить” им компьютерную систему, прежде всего требуется сформулировать, систематизировать и формализовать эти знания “на бумаге”. Это может показаться парадоксальным, но большинство экспертов (за исключением, может быть, математиков), успешно используя в повседневной деятельности свои обширные знания, испытывают большие затруднения при попытке сформулировать и представить в системном виде хотя бы основную часть этих знаний: иерархию используемых понятий, эвристики, алгоритмы, связи между ними. Оказывается, что для подобной формализации знаний необходим определенный систематический стиль мышления, более близкий математикам и программистам, чем, например, юристам и медикам. Кроме того, необходимы, с одной стороны, знания в области математической логики и методов представления знаний, с другой - знания возможности ЭВМ, из программного обеспечения, в частности, языков и систем программирования.
Таким образом, выясняется, что для разработки ЭС необходимо участие в ней особого рода специалистов, обладающих указанной совокупностью знаний и выполняющих функции “посредников” между экспертами в предметной области и компьютерными (экспертными) системами. Они получили название инженеры знаний (в оригинале - knowledge engineers), а сам процесс разработки ЭС и других интеллектуальных программ, основанных на представлении и обработке знаний - инженерией знаний (knowledge engineering). В развитых зарубежных странах специальность “инженер знаний” введена во многих вузах, в нашей стране основы инженерии знаний изучаются пока в рамках специализаций по системному программированию. Функции эксперта и инженера знаний редко совмещаются в одном лице. Чаще функции инженера знаний выполняет разработчик ЭС. Как показал опыт многих разработок, для первоначального приобретения знаний, в которых участвуют эксперты, инженеры знаний и разработчики ЭС, требуется активная работа всех трех категорий специалистов. Она может длиться от нескольких недель до нескольких месяцев.
На этапе приобретения знаний могут возникнуть трудности и психологического порядка: эксперт может препятствовать передаче своих знаний ЭС, полагая, что это снизит его престиж как специалиста и создаст предпосылки для замены его “машиной”. Однако эти опасения лишены оснований: ЭС “уверенно” работает лишь в типовых ситуациях, а также удобна в случаях, когда человек находится в состоянии стресса, в наиболее сложных ситуациях, требующих нестандартных рассуждений и оценок, эксперт- человек незаменим.
Третья серьезная трудность- в очень большой трудоемкости создания ЭС : требуется разработать средства управления базой знаний, логического вывода, диалогового взаимодействия с пользователем и т.д. Объем пограммирования столь велик, а программы столь сложны и нетрадиционны, что имеет смысл, как это принято сейчас при разработке больших программ, на первом этапе создать демонстрационный прототип системы - предварительный вариант, в котором в упрощенном виде реализованы лишь ее основные планируемые возможности и которая будет служить для заказчика подтверждниением того, что разработка ЭС для решения данной задачи принципиально возможна, а для разработчиков- основой для последующего улучшения и развития системы.
Одной из причин неудач в создании ЭС стала недооценка авторами ЭС объемов и роли неявных знаний. Системы, базы знаний которых создавались на основе справочников, в лучшем случае так справочниками и остались. Большинство же таких систем оказывались даже хуже справочников, так как сковывали исследовательскую мысль пользователя. Вторым “узким местом” ЭС оказалась модель, на которой были основаны их первые экземпляры, и лишь модель знаний, принимающая вид пороговой направленной иерархической сети с возможностью выбора в конечном из логических узлов (где каждая отдельная ситуация похожа на дерево с листьями), может стать базой для построения ЭС.
Когда стала очевидной полная непригодность этих систем и созданного для них специаллизированного аппаратного оборудования, многие обозреватели пришли к выводу, что существующая технология создания ЭС была тупиковым направлением в развитии информационных технологий. В последнее десятилетие ЭС возродились в виде систем с базой знаний, которые тесно переплетались с существующими деловыми системами. Их используют в здравоохранении, страховании, банковском деле и других областях, чтобы с помощью правил и объектовнакапливать опыт,повысить качество принимаемых решений. Базы знаний встроенысегодня в наиболее современные крупные системы. Они находятся в самой сердцевине программ- агентов, осуществляющих поиск в сети Internet, и помогают коллективам пользователей справиться с поитоками информации.
Рассмотрим факторы, стимулировавшие развитие систем с базами знаний:
- компании, добившиеся значительной экономии денежных средств благодаря технологии баз знаний, развивают и выстраивают ее в специальные бизнес- процессы, которые были бы просто невозможны без компьютерной экспертизы;
- разработаны новые технологии создания баз знаний, является необходимым средством, которое может изменить бизнес- поцесс;
- современные системы реализованы не наспециализирован-ном, а на стандартном оборудовании.
Объединение всех видов программных продуктов и их отдельных компонентов в единую ЭС признано экономически выгодным, так как прменение ЭС позволяет существенно сократить расходы на подготовку квалифицированного персонала, дальнейшую проверку работоспособности и надежности разрабатываемых и исследовательских систем, а также уменьшить время проектирования и(или) исследования.
Объектная технология, на основе которой могут создаваться и развиваться современные ЭС,- значительный шаг вперед по сравнению с CASE- средствами, т.к. она похожа на наше восприятие окружающей действительности. Наше представ- ление о моделировании меняется, то же самое происходит и с объектами, поэтому сопровождение программируемых объектов может выполнятся аналогично приспособлению наших умозрительных образов к изменению окружающих условий. Данная технология прекрасно подходит аналитикам и программистам. т.к. очень напоминает стратегию решения проблем и соответствует мыслительным процессам людей, считающихся экспертами в своей области.
Чтобы стать экспертом, специалисту нужен инструментарий, имитирующий мышление эксперта. Разработка парадигмы превращается из задачи, чуждой мышлению человека, в знакомое, привычное и легко выполняемое задание.
Как работают эксперты? Следуя принципам, заложенным в объектно- ориентированные технологии, они подразумевают проблемы на объекты или классы объектов. По мере накопления знаний в определенной области они делают обобщения, ориентируясь на выделенные объекты или классы объектов. Некоторые обобщения имеют иерархическую структуру, где свойства высших объектов наследуются объекта-
ми низшего уровня. Сущность может соответствовать нескольким классам объектов и взаимодействовать с различными объектами или классами. По мере того как знания эксперта углубляются, на их основе формируются новые ассоциации, а отдельные уровни иерархии пропадают или расширяются.
Методика объектно- ориентированного программирования основана на модели, напоминающей образы, возникающие в мозгу аналитика, которая представляет предметы и процессы в виде объектов и связей между ними. Наблюдая событие, эксперт легко выделяет знакомые образы. Для решения проблем он испытывает конкретные правила, рассматривая при этом исследуемую проблему под определенным ракурсом.
При разработке систем автоматизированного проектирования (САПР) уже нельзя обойтись без ЭС; их использование признано экономически выгодным.
С середины 80-х годов наиболее популярные системы с базами знаний создавались с ориентацией на стандартное оборудование. В этом ключ к пониманию причин успеха современной технологии баз знаний. Опыт показывает, что системы с базами знаний необходимо встраивать в самые важные бизнесс- процессы и организовывать работу персонала так, чтобы он мог максимально использовать их преимущества для достижения наилучших результатов.
Глава 2. Структура систем, основанных на знаниях
2.1. Критерий пользователя ЭС
Структура ЭС изображена на схеме:


пользователь

 эксперт
+ диалоговый
эксперт
+ диалоговый

 инженер
знаний процессор
инженер
знаний процессор


 подсистема
подсистема
подсистема
подсистема

 приобретения
база знаний
вывода
приобретения
база знаний
вывода
 знаний
знаний
 подсистема
подсистема
объяснения
рис.3
Экспертные системы имеют две категории пользователей и два отдельных “входа”, соответствующих различным целям взаимодействия пользователей с ЭС:
1)обычный пользователь (эксперт), которому требуется консультация ЭС- диалоговый сеанс работы с ней, в процессе которой она решает некоторую экспертную задачу. Диалог с ЭС осуществляется через диалоговый процессор- специальную компоненту ЭС. Существуют две основные формы диалога с ЭС- диалог на ограниченном подмножестве естественного языка ( с использованием словаря- меню (при котором на каждом шаге диалога система предлагает выбор профессионального лексикона экспертов) и диалог на основе из нескольких возможных действий);
экспертная группа инженерии знаний, состоящая из экспертов в предметной области и инженеров знаний. В функции этой группы входит заполнение базы знаний, осуществляемое с помощью специализированной диалоговой компоненты ЭС - подсистемы приобретения знаний, которая позволяет частично автоматизировать этот процесс.
2.2. Подсистема приобретения знаний
Подсистема приобретения знаний предназначена для добавления в базу знаний новых правил и модификации имеющихся. В ее задачу входит приведение правила к виду, позволяющему подсистеме вывода применять это правило в процессе работы. В более сложных системах предусмотрены еще и средства для проверки вводимых или модифицируемых правил на непротиворечивость с имеющимися правилами.
2.3. База знаний
База знаний- наиболее важная компонента экспертной системы, на которой основаны ее «интеллектуальные способности». В отличие от всех остальных компонент ЭС, база знаний- «переменная » часть системы, которая может пополняться и модифицироваться инженерами знаний и опыта использование ЭС, между консультациями (а в некоторых системах и в процессе консультации). Существует несколько способов представления знаний в ЭС, однако общим для всех них является то, что знания представлены в символьной форме (элементарными компонентами представления знаний являются тексты, списки и другие символьные структуры). Тем самым, в ЭС реализуется принцип символьной природы рассуждений, который заключается в том, что процесс рассуждения представляется как последовательность символьных преобразований.
Наиболее распространенный способ представления знаний - в виде конкретных фактов и правил, по которым из имеющихся фактов могут быть выведены новые. Факты представлены, например, в виде троек:
(АТРИБУТ ОБЪЕКТ ЗНАЧЕНИЕ).
Такой факт означает, что заданный объект имеет заданный атрибут (свойства) с заданным значением. Например, тройка (ТЕМПЕРАТУРА ПАЦИЕНТ1 37.5) представляет факт «температура больного, обозначаемого ПАЦИЕНТ1, равна 37.5». В более простых случаях факт выражается неконкретным значением атрибута, а каким либо простым утверждением, которое может быть истинным или ложным, например: «Небо покрыто тучами». В таких случаях факт можно обозначить каким-либо кратким именем (например, ТУЧИ) или использовать для представления факта сам текст соответствующей фразы.
Правила в базе знаний имеют вид:
ЕСЛИ А ТО S, где А- условие; S- действие. Действие S исполняется, если А истинно. Наиболее часто действие S, так же, как и условие, представляет собой утверждение, которое может быть выведено системой (то есть становится ей известной), если истинно условие правила А.
Правила в базе знаний служат для представления эвристических знаний (эвристик), т.е. неформальных правил рассуждения, вырабатываемых экспертом на основе опыта его деятельности.
Простой пример правила из повседневной жизни:
ЕСЛИ небо покрыто тучами
ТО скоро пойдет дождь.
В качестве условия A может выступать либо факт(как в данном примере), либо несколько фактов A1,...,AN, соединенные логической операцией и:
A1 и A2 и ... и AN.
В математической логике такое выражение называется коньюнкцией. Оно считается истинным в том случае, если истинны все его компоненты. Пример предыдущего правила с более сложным условием:
ЕСЛИ
небо покрыто тучами и барометр падает
ТО
скоро пойдет дождь. (Правило 1).
Действия, входящие в состав правил, могут содержать новые факты. При применении таких правил эти факты становятся известны системе, т.е. включаются в множество фактов, которое называется рабочим множеством. Например, если факты «Небо покрыто тучами» и «Барометр падает» уже имеются в рабочем множестве, то после применения приведенного выше правила в него также включается факт «Скоро пойдет дождь».
Если система не может вывести некоторый факт, истинность или ложность которого требуется установить, то система спрашивает о нем пользователя. Например:
ВЕРНО ЛИ, ЧТО небо покрыто тучами?
При получении положительного ответа от пользователя факт «Небо покрыто тучами» включается в рабочем множество.
Существуют динамические и статические базы знаний. Динамическая база знаний изменяется со временем. Ее содержимое зависит и от состояния окружающей. Новые факты, добавляемые в базу знаний, являются результатом вывода, который состоит в применении правил к имеющимся фактам.
В системах с монотонным выводом факты, хранимые в базе знаний, статичны, то есть не изменяются в процессе решения задачи. В системах с немонотонным выводом допускается изменение или удаление фактов из базы знаний. В качестве примера системы с немонотонным выводом можно привести ЭС, предназначенную для составления перспективного плана капиталовложения компании. В такой системе по вашему желанию могут быть изменены даже те данные, которые после вывода уже вызвали срабатывание каких-либо правил. Иными словами имеется возможность модифицировать значения атрибутов в составе фактов, находящихся в рабочей памяти. Изменение фактов в свою очередь приводит к необходимости удаления из базы знаний заключений, полученных с помощью упомянутых правил. Тем самым вывод выполняется повторно для того, чтобы пересмотреть те решения, которые были получены на основе подвергшихся изменению фактов.
2.4. Подсистема вывода
2.4.1 Подсистема вывода,способы логического вывода
Подсистема вывода - программная компонента экспертных систем, реализующая процесс ее рассуждений на основе базы знаний и рабочего множества. Она выполняет две функции: во-первых, просмотр существующих фактов из рабочего множества и правил из базы знаний и добавление (по мере возможности) в рабочее множество новых фактов и, во-вторых, определение порядка просмотра и применения правил. Эта подсистема управляет процессом консультации, сохраняет для пользователя информацию о полученных заключениях, и запрашивает у него информацию, когда для срабатывания очередного правила в рабочем множестве оказывается недостаточно данных.
Цель ЭС - вывести некоторый заданный факт, который называется целевым утверждением (то есть в результате применения правил добиться того, чтобы этот факт был включен в рабочее множество), либо опровергнуть этот факт (то есть убедиться, что его вывести невозможно, следовательно, при данном уровне знаний системы он является ложным). Целевое утверждение может быть либо «заложено» заранее в базу знаний системы, либо извлекается системой из диалога с пользователем.
Работа системы представляет собой последовательность шагов, на каждом из которых из базы выбирается некоторое правило, которое применяется к текущему содержимому рабочего множества. Цикл заканчивается, когда выведено либо опровергнуто целевое утверждение. Цикл работы экспертной системы иначе называется логическим выводом Логический вывод может происходить многими способами, из которых наиболее распространенные - прямой порядок вывода и обратный порядок вывода.
Прямой порядок вывода- от фактов, которые находятся в рабочем множестве, к заключению. Если такое заключение удается найти, то оно заносится в рабочее множество. Прямой вывод часто называют выводом, управляемым данными.
Для иллюстрации добавим к нашему примеру базы знаний о погоде еще одно правило:
ЕСЛИ скоро пойдет дождь
ТО нужно взять с собой зонтик. (правило 2)
Предположим также, что факты «Небо покрыто тучами» и «Барометр падает» имеются в рабочем множестве, а целью системы является ответ на вопрос пользователя:
«Нужно взять с собой зонтик?»
При прямом выводе работа системы будет протекать следующим образом:
Шаг 1. Рассматривается правило 1. Его условие истинно, так как оба элемента коньюнкции имеются в рабочем множестве. Применяем правило 1; добавляем к рабочему множеству факт ”Скоро пойдет дождь”.
Шаг 2. Рассматривается правило 2. Его условие истинно, т.к. утверждение из условия имеется в рабочем множестве. Примеряем правило 2; добавляем к рабочему множеству факт “Нужно взять с собой зонтик”. Целевое утверждение выведено.
Обратный порядок вывода: заключения просматриваются до тех пор, пока не будет обнаружены в рабочей памяти или получены от пользователя факты, подтверждающие одно из них. В системах с обратным выводом вначале выдвигается некоторая гипотеза, а затем механизм вывода в процессе работы, как бы возвращается назад, переходя от нее к фактам, и пытается найти среди них те, которые подтверждают эту гипотезу. Если она оказалась правильной, то выбирается следующая гипотеза, детализирующая первую являющаяся по отношению к ней подцелью. Далее отыскиваются факты, подтверждающие истинность подчиненной гипотезы. Вывод такого типа называется управляемым целями. Обратный поиск применяется в тех случаях, когда цели известны и их сравнительно немного.
В рассматриваемом примере вывод целевого утверждения “Нужно взять с собой зонтик” обратной цепочкой рассуждений выполняется следующим образом:
Шаг 1. Рассматривается правило 1. Оно не содержит цели в правой части. Переходим к правилу 2.
Шаг 2. Рассматривается правило 2. Оно содержит цель в правой части правила. Переходим к правой части правила и рассматриваем в качестве текущей цели утверждения “Скоро пойдет дождь”.
Шаг 3. Текущей цели нет в рабочем множестве. Рассмотрим правило 1, которое содержит цель в правой части. Обе компоненты его условия имеются в рабочем множестве, так что условие истинно. Применяем привило 1; в результате выводим утверждение “Скоро пойдет дождь”; которое было нашей предыдущей целью.
Шаг 4. Применяем правило 2, условием которого является данное утверждение. Получаем вывод исходного утверждения.
Заметим, что для упрощения ситуации мы предположили, что в обоих случаях факты “Небо покрыто тучами” и “Барометр падает” уже известны системе. На самом деле система выясняет истинность или ложность факта, входящего в условие некоторого правила, спрашивая об этом пользователя в тот момент, когда она пытается применить правило.
Приведенный пример сознательно выбран очень простым и не отражающим многих проблем, связанных с организацией вывода в экспертной системе. В частности, из примера может создаться впечатление, что прямая цепочка рассуждений эффективнее, чем обратная, что на самом деле, вообще говоря, не так. Эффективность той или иной стратегии вывода зависит от характера задачи и содержимого базы знаний. В системах диагностики чаще применяется прямой вывод, в то время как в планирующих системах более эффективным оказывается обратный вывод. В некоторых системах вывод основывается на сочетании обратного и ограниченно- прямого. Такой комбинированный метод получил название циклического.
Рис 4. Стратегия вывода.
Поиск в глубину

 Обратный
вывод
Прямой
вывод
Обратный
вывод
Прямой
вывод

 4
Начало 1
4
Начало 1



 3
поиска
2
3
поиска
2

 5 2 Начало
3
5 2 Начало
3

 6 1 поиска
4
6 1 поиска
4

 7
7


Заключения

 Заключения
Заключения


Поиск в ширину
Начало
 8 Начало
поиска 1
8 Начало
поиска 1
 поиска
12
поиска
12
 7
2
13
7
2
13
1
11

 6
3
6
3
 2
10
2
10


 5
4
5
4
 3
9
3
9
4
5
 8
8
6
Заключения
7
Выше уже отмечалось, что механизм вывода включает в себя два компонента- один из них реализует собственно вывод, другой управляет этим процессом. Компонент вывода выполняет первую задачу, рассматривая имеющиеся правила и факты из рабочего множества и добавляя в него новые факты при срабатывании какого-нибудь правила. Управляющий компонент определяет порядок применения правил. Рассмотрим каждый из этих компонентов более подробно.
2.4.2. Компонент вывода
Его действия основаны на применении правила вывода, обычно называемого модус поненс, суть которого состоит в следующем: пусть известно, что истинно утверждение А и существует правило вида «Если А, то В», тогда утверждение В так же истинно. Правила срабатывают, когда находятся факты, удовлетворяющие их левой части: если истинна посылка, то должно быть истинно и заключение.
Хотя в принципе на первый взгляд кажется, что такой вывод легко может быть реализован на компьютере, тем не менее на практике человеческий мозг все равно оказывается более эффективным при решении задач. Рассмотрим, например, простое предложение:
Мэри искала ключ.
Здесь для слова «ключ» допустимы как минимум два значения «родник» и «ключ от квартиры». В следующих же двух предложениях одно и то же слово имеет совершенно разные значения:
Мы заблудились в чаще.
Нужно чаще ходить в театр.
Понять факты становиться еще сложнее, если они являются составными частями продукций, которые используют правило модус поненс для вывода заключения. Приведем такой пример:
ЕСЛИ Белый автомобиль легко заметить ночью
И Автомобиль Джека белый
ТО Автомобиль Джека легко заметить ночью
Это заключение легко выведет даже ребенок, но оно оказывается не под силу ни одной из современных ЭС.
Компонент вывода должен обладать способностью функционировать при любых условиях. Механизм вывода должен быть способен продолжить рассуждение и со временем найти решение даже при недостатке информации. Это решение может и не быть точным, однако система ни в коем случае не должна останавливаться из-за того, что отсутствует какая-либо часть входной информации.
2.4.3. Управляющий компонент.
Этот компонент определяет порядок применения правил, а также устанавливает, имеются ли еще факты, которые могут быть изменены в случае продолжения консультации. Управляющий компонент выполняет четыре функции:
1. Сопоставление- образец правила сопоставляется с имеющимися фактами;
2. Выбор- если в конкретной ситуации могут быть применены сразу несколько правил, то из них выбирается одно, наиболее подходящее к заданному критерию (разрешение конфликта).
3. Срабатывание- если образец правила при сопоставлении совпал с какими- либо фактами из рабочего множества, то правило срабатывает.
4. Действие- рабочее множество подвергается изменению путем добавления в него заключения сработавшего правила. Если в правой части правила содержится указание на какое- либо действие, то оно выполняется (как, например, в системах обеспечения безопасности информации).
Интерпретатор правил работает циклически. В каждом цикле он просматривает все правила, чтобы выявить среди них те посылки, которые совпадают с известными на данный момент фактами из рабочего множества. Интерпретатор определяет также порядок применения правил. После выбора правило срабатывает, его заключение заносится в рабочее множество, и затем цикл повторяется сначала.
В одном цикле может сработать только одно правило. Если несколько правил успешно сопоставлены с фактами, то интерпретатор производит выбор по определенному критерию единственного правила, которое и срабатывает в данном цикле. Цикл работы интерпретатора схематически представлен на рис.5.





 сопоставление
конфликтное
критерий
сопоставление
конфликтное
критерий
 множество
выбора правил
множество
выбора правил

разрешение

 конфликта
конфликта
 рабочее
база
рабочее
база
множество правил

 выполняемое
действие
выполняемое
действие

 правило
правило
рис.5 Цикл работы интерпретатора
Информация из рабочего множества последовательно сопоставляется с посылками правил для выявления успешного сопоставления. Совокупность отобранных правил составляет так называемое конфликтное множество. Для разрешения конфликта интерпретатор имеет критерий, с помощью которого он выбирает единственное правило после чего оно срабатывает. Это выражается в занесении фактов, образующих заключение правила, в рабочее множество или в изменении критерия выбора конфликтующих правил. Если же в заключение правила входит название какого-нибудь действия, то оно выполняется (например, подается звуковой сигнал, начинает выполнятся процедура и т.д.).
Новые данные, введенные в систему сработавшим правилом, в свою очередь могут изменить критерий выбора правила. В том случае, если, напри-
мер, компьютерная система, предназначенная для игры в шахматы, разыгрывает партию за двух игроков, то она может принять решение придерживаться атакующей стратегии через ход, т.е. атаковать будет один из партнеров. Если вы сами играете с этой системой, то в какой- то момент она может перейти к использованию оборонительной стратегии (по крайней мере временно), а затем опять вернуться к наступательной игре. Изменение критерия основывается на заключениях, полученных после анализа положения на доске, которое представлено в рабочем множестве системы, а также правил игры (статичес-
ких структурных знаний) и структурных динамических знаниях (эвристиках).
В действительности ЭС не располагают процедурами, которые могли бы построить в пространстве состояний сразу весь путь решения задачи. Более того, зачастую даже не удается определить, имеется ли вообще какое- нибудь решение задачи. Тем ни менее поиск решения выполняется, поскольку движением в пространстве состояний управляют скрытые или виртуальные процедуры. Они получили название демонов, поскольку во время работы системы находятся в “засаде” и активизируются только тогда, когда их просят о помощи, т.е. на самом деле ведут себя как добрые демоны.
Свое название демоны получили от “демона Максвелла”- действующего лица одного из мысленных экспериментов, предложенного его автором для критики законов термодинамики. Другим их прообразом является Пандемониум Оливера Селфриджа- первой модели человека, в котором деятельность биологической системы представлялась как работа вызываемых по образцу демонов. Если же воспользоваться научной терминологией, то такие управляющие процедуры получили название недетерминированных. Это означает, что траектория поиска решения в пространстве состояний полностью определяется данными.
При разработке управляющего компонента механизма (подсистемы) вывода необходимо решить вопрос о том, по какому критерию следует выбирать правило, которое будет применено в конкретном цикле.
Уже на ранней стадии разработки ЭС необходимо знать, что будет вводить конечный пользователь. Это нужно для того, чтобы убедиться, будет ли система достаточно практична и сможет ли она вжиться в среду, в которой ей предстоит работать.
Участие пользователя выражается в следующем:
- конкретные задачи. Пользователь, сталкиваясь с конкретными проблемами, может объяснить возникновение проблем и предложить возможные варианты их решения;
- общение. Интерфейс пользователя должен соответствовать словарю пользователя и уровню его подготовки;
- установление связей. Знакомство пользователя с причинами и последствиями, вызывающими то или иное действие в процессе функционирования системы, неоценимо в определении взаимосвязей фактов в базе знаний;
- обратная связь. Отличительной особенностью удобной в использовании ЭС является ее способность объяснить конечному пользователю ход своих рассуждений.
2.5. Диалог с ЭС. Объяснение.
Поскольку системы, основанные на знаниях, реализуются на компьютерах, то и входная информация воспринимается или в виде, понятном компьютеру, т.е. в битах и байтах. Однако для того чтобы мог взаимодействовать неподготовленный пользователь, в нее требуется включить средства общения на естественном языке. Подавляющее большинство систем, основанных на знаниях, обладают достаточно примитивным интерфейсом на естественном языке- допустимые входные сообщения пользователя ограничены набором понятий, содержащихся в базе знаний.
Итак, на примере простой ЭС и базы знаний диалог пользователя с системой можно представить себе следующим образом:
Система: Вы хотите узнать, нужно ли взять с собой зонтик?
Пользователь: Да.
Система: Верно ли, что небо покрыто тучами?
Пользователь: Да.
Система: Верно ли, что барометр падает?
Пользователь: Да.
Система: (после некоторого “размышления”) Нужно взять с собой зонтик.
Как видно из этого примера, в ходе консультации инициатива диалога принадлежит системе, а сама консультация у ЭС выглядит так же, как и консультация у эксперта- человека: задается ряд вопросов и на основании их анализа выдается экспертное заключение. Однако в отличие от беседы со специалистом, диалог с ЭС имеет свои психологические особенности: большинство пользователей (по вполне понятным причинам, таким, как отсутствие опыта работы на компьютерах, лаконичность диалога с ЭС, отсутствие пояснений в ходе консультации и другим) склонны меньше доверять “мнению” ЭС, чем мнению “живого” эксперта.
Чтобы удостовериться в “разумности” и “компетентности” ЭС, пользователь может обратиться к ее подсистеме объяснения.
Для того, чтобы понять как она работает, нам необходимо рассмотреть вопрос о том в какой форме ЭС хранить информацию о процессе своих рассуждений.
В ЭС принято представлять процесс логического вывода в виде схемы, которая называется деревом вывода. В нашем примере дерево вывода будет иметь вид:

Нужно взять с собой зонтик.
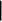
правило 2

Скоро пойдет дождь.
правило 1
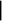
Небо покрыто тучами. Барометр падает.
Здесь в простых рамках приведены узлы дерево вывода, соответствующие фактам, в двойных- узлы, соответствующие названием правил. Сверху от узла- правила изображен факт, находящийся в его правой части (в принятой терминологии- предок узла- правила). Листья дерева (узлы, образующие его нижний “ярус”), соответствуют фактам, истиностные значения которых запрашиваются у пользователя, или первоначально известным фактам из базы знаний, корень дерева (самый верхний узел)- целевому утверждению.
В процессе консультации ЭС строит дерево вывода и хранит его в памяти в некоторой внутренней форме. Успешному применению правила соответствует добавление узла с его именем, потомками которого являются узлы, соответствующие некоторым из уже выведенных фактов, а предком- новый узел, соответствующий факту, содержащемуся в правой части правила.
Рассмотрим теперь работу подсистемы объяснения. Для получения объяснения в процессе консультации пользователь может “перехватить инициативу” диалога в тот момент, когда система задает очередной вопрос, “переспро-
сив” в ответ систему, почему она его задала. Таким образом, вместо ответа на вопрос системы, пользователь может задать ей встречный вопрос:
ПОЧЕМУ?
(“ Почему система задала такой вопрос?”). Система интерпретирует вопрос “Почему?” в “понятных” ей терминах дерева вывода, поднимаясь по нему на один ярус выше и находя правило, для применения которого система задает этот вопрос. Пользователю выдается информация об этом правиле, о состоянии вычисления его условиям о заключении данного правила (текущей цели).
Пусть в нашем примере диалога с ЭС пользователь вместо ответа на вопрос системы: “Верно ли, что барометр падает?” задает ей встречный вопрос: ”ПОЧЕМУ?”. ЭС обращается к подсистеме объяснения, которая выдает пользователю следующее сообщение:
[1.0] Эта информация необходима, чтобы установить, что скоро пойдет дождь.
Ранее было установлено, что :
[1.1] Небо покрыто тучами.
Следовательно, если:
[1.2] Барометр падает, то скоро пойдет дождь.
(Правило 1).
Двойные номера в квадратных скобках имеют следующий смысл. Для облегчения работы пользователя подсистема объяснения нумерует свои ответы (номер ответа, в данном случае- 1. является первой цифрой номера), а в каждом ответе- нумерует также утверждения, о которых в нем идет речь. Пользователь может использовать двойные номера для ссылок на утверждения, не выписывая их явно. Например, номер 1.1 обозначает утверждение “Небо покрыто тучами”.
Допустим, что пользователь хочет еще дальше проследить логику рассуждений системы и узнать, почему ей необходимо установить, скоро ли пойдет дождь. Для этого он может повторно задать ей вопрос:
ПОЧЕМУ?
(“Почему необходимо установить, что скоро пойдет дождь?”). Второй ответ системы аналогичен первому; в нем указывается, что это необходимо для применения правила 2 с целью установить, что нужно взять с собой зонтик:
[2.0] Эта информация необходима, чтобы установить, что нужно взять с собой зонтик. Если:
[2.1] Скоро пойдет дождь, то нужно взять с собой зонтик.
(Правило 2).
Утверждение [2.0] является исходным целевым утверждением системы. Таким образом, теперь ход рассуждений системы пользователю полностью понятен. Вопрос “ПОЧЕМУ?” позволяет проследить ход рассуждений системы от посылок к заключениям. Однако для более детального осмысления процесса вывода удобно было бы иметь возможность изучать его и в противоположном порядке- от заключений к посылкам. Для этого служит другой вопрос, который также “понимает” подсистема объяснений:
КАК N?
где N- номер утверждения, выданный подсистемой объяснения на одном из предыдущих шагов диалога. Например, в ответ на вопрос:
КАК 2.0?
“Как получен утверждение 2.0?” подсистема объяснения выдает информацию в правиле, которое было применено для его получения:
[3.1] Используется правило 2, заключением которого является, что нужно взять с собой зонтик.
Чтобы получить более подробную информацию о том, как было использовано правило 2, следует повторно задать вопрос “КАК?”:
КАК 3.1?
“Как было использовано правило 2?”. Ответ системы:
Ранее установлено, что:
[4.1] Скоро пойдет дождь.
Следовательно, нужно взять с собой зонтик.
Выясним теперь, как получено утверждение 4.1:
КАК 4.1?
Ответ системы:
[5.1] Используется правило 1, заключением которого является, что скоро пойдет дождь. Наконец, выясним. как использовано правило 1:
КАК 5.1?
Ответ системы:
Ранее установлено, что:
[6.1] Небо покрыто тучами.
[6.2] Барометр падает.
Следовательно скоро пойдет дождь.
Как были получены утверждения 6.1 и 6.2 пользователь помнит, поскольку он отвечал на вопросы системы относительно этих утверждений. Если все же он задаст системе вопрос КАК 6.1? или КАК 6.2?, то система напомнит ему об этом.
Описанная модель объяснения используется в системе MYCIN. Достоинством ее является возможность получения объяснения любого шага работы системы, недостатком- жесткая привязка к дереву вывода. Для пользователя- непрограммиста такой способ объяснения может показаться излишне детализованным и слишком формальным, а нужно было бы объяснение на “более высоком уровне”- с точки зрения здравого смысла и без углубления в детали. Подобные модели объяснения только начинают появляться в ЭС и требуют более сложной организации знаний.
Глава 3. Стратегии управления выводом
3.1. Разработка стратегии.
Одним из важных вопросов, возникающих при проектировании управляющей компоненты систем, основанных на знаниях, является выбор метода поиска решения, т.е. стратегии вывода. От выбранного метода поиска будет зависеть порядок применения и срабатывания правил. Процедура выбора сводится к определению направления поиска и способа его осуществления. Процедуры, реализующие поиск, обычно “зашиты” в механизм вывода, поэтому в большинстве систем инженеры знаний не имеют к ним доступа и, следовательно, не могут в них ничего изменять по своему желанию.
При разработке стратегии управления выводом необходимо ответить на два вопроса:
1. Какую точку в пространстве состояний принять в качестве исходной? Дело в том, что еще до начала поиска решения система, основанная на знаниях, должна каким- то образом выбрать исходную точку поиска- в прямом или обратном направлении.
2. Как повысить эффективность поиска решения? Чтобы добиться повышения эффективности поиска решения, необходимо найти эвристики разрешения конфликтов, связанных с существованием нескольких возможных путей для продолжения поиска в пространстве состояний, поскольку требуется отбросить те из них, которые заведомо не ведут к искомому решению.
3.2. Повышение эффективности поиска
В системах, база знаний которых насчитывает сотни правил, весьма желательным является использование какой- либо стратегии управления выводом, позволяющей минимизировать время поиска решения и тем самым повысить эффективность вывода. К числу таких стратегий относятся поиск в глубину, поиск в ширину, разбиение на подзадачи и альфа- бета алгоритм.
а) Сопоставление методов поиска в глубину и ширину.
Суть поиска в глубину состоит в том, что при выборе очередной подцели в пространстве состояний предпочтение всегда, когда это возможно, отдается той, которая соответствует следующему, более детальному уровню описания задачи.
Пространство состояний- это граф, вершины которого соответствуют ситуациям, встречающимся в задаче (“проблемные ситуации”), а решение задачи сводится к поиску пути в этом графе.
При поиске в ширину, напротив, система проанализирует все признаки, находящиеся на одном уровне пространства состояний, и лишь затем перейдет к признакам следующего уровня детальности.
Специалисты в какой- либо узкой области выше оценивают поиск в глубину, поскольку он позволяет собрать воедино все признаки, связанные с выдвинутой гипотезой. Универсалы же отдают предпочтение поиску в ширину, т.к. в этом случае анализ не ограничивается заранее очерченным кругом признаков. Особенности пространства поиска во многом определяют целесообразность применения той или иной стратегии: например, программы для игры в шахматы строятся на основе поиска в ширину, поскольку при использовании поиска в глубину число анализируемых ходов может быть и очень большим.
б) Альфа- бета алгоритм.
Задача сводится к уменьшению пространства состояний путем удаления в нем ветвей, не перспективных для поиска успешного решения. Поэтому просматриваются только те вершины, в которые можно попасть в результате следующего шага, после чего неперспективные направления исключаются из дальнейшего рассмотрения. Например, если цвет предмета, который мы ищем, не красный, то его бессмысленно искать среди красных предметов. Альфа- бета алгоритм нашел широкое применение в основном в системах, ориентированных на различные игры, например в шахматных прграммах.
в) Разбиение на подзадачи.
При такой стратегии в исходной задаче выделяются подзадачи, решение которых рассматривается как достижение промежуточных целей на пути к конечной цели. Если удается правильно понять сущность задачи и оптимально разбить ее на систему иерархически связанных целей- подцелей, то можно добиться того, что путь к ее решению в пространстве поиска будет минимален. Однако если задача является плохо стрктурированной, то сделать это невозможно.
При сведении задачи к подзадачам производится исследовании исходной задачи с целью выделения такого множества подзадач, чтобы решение некоторого определенного подмножества этих подзадач содержало в себе решение исходной задачи.
Рассмотрим, например, задачу о проезде на автомобиле из Пало-Альто (штат Калифорния) в Кембридж (штат Массачусетс). Эта задача может быть сведена, скажем, к следующим подзадачам:
Подзадача 1. Проехать из Пало-Альто в Сан-Франциско.
Подзадача 2.Проехать из Сан-Франциско в Чикаго.
Подзадача 3. Проехать из Чикаго в Олбани.
Подзадача 4. Проехать из Олбани в Кембридж.
Здесь решение всех четырех подзадач обеспечило бы некоторое решение первоначальной задачи.
Каждая из подзадач может быть решена с применением какого-либо метода. К ним могут быть применены методы, использующие пространство состояний, или же их можно проанализировать с целью выделения для каждой своих подзадач и т.д. Если продолжить процесс разбиения возникающих подзадач на еще более мелкие, то в конце концов мы прийдем к некоторым элементарным задачам, решение которых может считаться тривиальным.
На каждом из этапов может возникнуть несколько альтернативных множеств подзадач, к которым может быть сведена данная задача. Т.к. некоторые из этих множеств в конечном итоге, возможно, не приведут к окончательному решению задачи, то, как правило, для решения первоначальной задачи необходим поиск в пространстве множеств подзадач.
г) Использование формальной логики при решении задач.
Часто для решения задач либо требуется проведение логического анализа в определенном объеме, либо поиск решения существенно отличается после такого анализа. Иногда такой анализ показывает, что определенные проблемы
неразрешимы. В игре в пятнадцать, например, можно доказать, что целевая конфигурация (1) не может быть получена из начальной конфигурации (2).
1. 2.
| 15 | 14 | 13 | 12 |
| 11 | 10 | 9 | 8 |
| 7 | 6 | 5 | 4 |
| 3 | 2 | 1 1 |
| 1 | 2 | 3 | 4 |
| 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 |
| 13 | 14 | 15 |
3.3. Представление задач в пространстве состояний
3.3.1. Описание состояний
Чтобы построить описание задачи с использованием пространства состояний, мы должны иметь определенное представление о том, что собой состояния в этой задаче. В игре в пятнадцать выбор в качестве состояний различных конфигураций из фишек достаточно очевиден. Но процесс решения задачи, в котором решение ищется без реального перемещения настоящих фишек, может работать лишь с описанием конфигураций, а не с самими конфигурациями. Таким образом важным этапом построения какого- либо описания задачи с использованием пространства состояний является выбор некоторой конкретной формы описания состояний этой задачи.
В сущности любая структура величин может быть использована для описания состояний. Это могут быть строки символов, векторы, двухмерные массивы, деревья и списки. Часто выбираемая форма описания имеет сходство с некоторым физическим свойством решаемой задачи. Так, в игре в пятнадцать естественной формой описания состояний может быть массив 4х4. Выбирая форму описания состояний, нужно позаботиться и о том, чтобы применение оператора, преобразующего одно описание в другое, оказалось бы достаточно легким.
3.3.2 Операторы. Состояния и операторы.
По-видимому самый прямолинейный подход при поиске решения для игры в пятнадцать состоит в попытке перепробовать различные ходы, пока не удастся получить целевую конфигурацию. Такого рода попытка по существу связана с поиском при помощи проб и ошибок. (Мы предполагаем, что такой поиск может быть выполнен в принципе, скажем, на некоторой вычислительной машине, а не с привлечением реальной игры в пятнадцать). Отправляясь от начальной конфигурации, мы могли бы построить все конфигурации, возникающие в результате выполнения каждого из возможных ходов, затем построить следующее множество конфигураций после применения следующего хода и т.д., пока не будет достигнута целевая конфигурация.
Для обсуждения такого сорта методов поиска решения оказывается полезным введение понятий состояний и операторов для данной задачи. Для игры в пятнадцать состояние задачи- это просто некоторое конкретное расположение фишек. Начальная и целевая конфигурации представляют собой соответственно начальное и целевое состояния. Пространство состояний, достижимых из начального состояния, состоит из всех тех конфигураций фишек, которые могут быть образованны в результате допустимых правилами перемещений фишек. Многие задач имеют чрезвычайно большие (если не бесконечные) пространства состояний.
Оператор преобразует одно состояние в другое. Игру в пятнадцать естественно всего интерпретировать как игру, имеющую четыре оператора, соответствующие следующим ходам: передвинуть пустую клетку (пробел) влево, вверх, вправо, вниз. В некоторых случаях оператор может оказаться неприложимым к какому- то состоянию. На языке состояний и операторов решение некоторой проблемы есть последовательность операторов, которая преобразует начальное состояние в целевое.
Пространство состояний, достижимых из данного начального состояния, полезно представлять себе в виде графа, вершины которого соответствуют этим состояниям. Вершины такого графа связаны между собой дугами, отвечающими операторам.
Про метод решения задач, основанный на понятиях состояний и операторов, можно было бы сказать, что это подход к задаче с точки зрения пространства состояний.
Операторы приводят одно состояние в другое. Таким образом, их можно рассматривать как функции, определенные на множестве состояний и принимающие значения из этого множества. Так как наши процессы решения задач основаны на работе с описанием состояний, то мы будем предполагать, что операторы- функций этих описаний, а их значения- новые описания. В общем случае мы будем предполагать, что операторы- это вычисления, преобразующие одни описания состояний в другие.
Во все наши процедуры исследования пространства состояний входит построение новых описаний состояний, исходя из старых с последующей проверкой новых описаний состояний, с тем чтобы убедиться, не описывают ли они состояние, отвечающее поставленной цели. Часто это просто проверка того, соответствует ли некоторое описание состояния данному целевому описанию состояния, но иногда должна быть произведена более сложная проверка. Например, для игры в пятнадцать целью может быть создание конфигурации из фишек, в которой в верхних двух рядах не будет фишек с номерами, превосходящими 12. Во всяком случае, то свойство, которому должно удовлетворять описание состояния, для того чтобы это состояние было целевым, должно быть охарактеризовано исчерпывающим образом.
В некоторых задачах оптимизации недостаточно найти любой путь, ведущий к цели, а необходимо найти путь, оптимизирующий некоторый критерий (например, минимизирующий число применений операторов). С такими задачами проще всего работать, сделав так, чтобы поиск не оканчивался до сих пор, пока не будет найдено некоторое оптимальное решение.
Таким образом, мы видим, что для полного представления задачи в пространстве состояний необходимо задать:
а) форму описания состояний и, в частности, описание начального состояния;
б) множество операторов и их воздействий на описания состояний;
в) свойства описания целевого состояния.
Пространство состояний полезно представлять себе в виде направленного графа.
3.4.3. Запись в виде графа.
Граф состоит из множества (не обязательно конечного) вершин. Некоторые пары вершин соединены с помощью дуг, и эти дуги направлены от одного члена этой пары к другому. Такие графы носят название направленных графов. Если некоторая дуга направлена от вершины ni к вершине nj, то говорят, что вершина nj является дочерней для вершины ni, а вершина ni является родительской вершиной для nj. Может оказаться, что наши две вершины будут дочерними друг для друга; в этом случае пара направленных дуг называется иногда ребром графа. В случае, когда граф используется для представления пространства состояний, с его вершинами связывают описание состояний, а с его дугами- операторы.
Последовательность вершин ni1,ni2,...,nik., в которой каждая вершина nij дочерняя для ni,j-1, j=2,k, называется путем длины k от вершины ni1, к вершине nik. Если существует путь, ведущий от вершины ni к вершине nj, то вершину nj называют достижимой из вершины ni или потомком вершины ni . В этом случае вершина ni называется также предком для вершины nj. Видно, что проблема нахождения последовательности операторов, преобразующих одно состояние в другое, эквивалентна задаче поиска пути на графе.
Глава 4. Методы поиска в пространстве состояний
4.1. Процессы поиска на графе
Граф определяется как множество вершин вместе с множеством ребер, причем каждое ребро задается парой вершин. Если ребра направлены, то их также называют дугами. Дуги задаются упорядоченными парами. Такие графы называются направленными. Ребрам можно приписывать стоимости, имена или метки произвольного вида, в зависимости от конкретного приложения.
При формулировке задачи решение получается в результате применения операторов к описаниям состояний до тех пор, пока не будет получено выражение, описывающее состояние, которое соответствует достижению цели. Все методы перебора, которые мы будем обсуждать, могут быть смоделированы с помощью следующего теоретико- графового процесса:
Начальная вершина соответствует описанию начального состояния. Вершины, непосредственно следующие за данной, получаются в результате использования операторов, которые применимы к описанию состояния. Пусть Г- некоторый специальный оператор, который строит все вершины, непосредственно следующие за данной. Мы будем называть процесс применения оператора Г к вершине раскрытием вершины.
От каждой такой последующей вершины к породившей ее идут указатели. Эти указатели позволяют найти путь назад к начальной вершине, уже после того как обнаружена целевая вершина.
Для вершин, следующих за данной, делается проверка, не являются ли они целевыми вершинами. Если целевая вершина еще не найдена, то продолжается процесс раскрытия вершин (и установки указателей). Когда же целевая вершина найдена, эти указатели просматриваются в обратном направлении- от цели к началу, в результате чего выявляется путь решения. Тогда операторы над описаниями состояний, связанные с дугами этого пути, образуют решающую последовательность.
Этапы, указанные выше, описывают просто основные элементы процесса перебора. При полном описании процесса перебора нужно еще задать порядок, в котором следует раскрывать вершины. Если вершины раскрываются в том же порядке, в котором они порождаются, то получается процесс, который называется полным перебором, Если же сначала раскрывается всегда та вершина, которая была построена самой последней, то получается процесс перебора в глубину. Процессы полного перебора в глубину можно назвать также процедурами слепого перебора, поскольку расположение цели не влияет на порядок, в котором раскрываются вершины.
Возможно, однако, что у нас имеется некоторая эвристическая информация о глобальном характере графа и общем расположении цели поиска. Такого рода информация часто может быть использована для того, чтобы “подтолкнуть” поиск в сторону цели, раскрывая в первую очередь наиболее перспективные вершины.
Рассмотрим более подробно методы слепого перебора. Деревом называется граф, каждая вершина которого имеет ровно одну непосредственно предшествующую ей (родительскую) вершину, за исключением выделенной вершины, называемой корнем дерева, которая вовсе не имеет предшествующих ей вершин. Таким образом, корень дерева служит начальной вершиной. Для перебора деревья проще графов прежде всего потому, что при построении новой вершины мы можем быть уверены, что она никогда раньше не строилась и никогда не будет построена вновь. Таким образом, путь от корня до данной вершины единственен.
4.2. Методы перебора
4.2.1. Методы полного перебора
В методе полного перебора вершины раскрываются в том порядке, в котором они строятся. Простой алгоритм полного перебора на дереве состоит из следующей последовательности шагов:
1) Поместить вершину в список, называемый ОТКРЫТ.
2) Если список ОТКРЫТ пуст, то на выход подается сигнал о неудаче поиска, в противном случае переходить к следующему шагу.
3) Взять первую вершину из списка ОТКРЫТ и перенести ее в
список ЗАКРЫТ; назовем эту вершину n.
4) Раскрыть вершину n, образовав все вершины, непосредственно следующие за n. Если непосредственно следующих вершин нет, то переходить сразу же к шагу (2). Поместить имеющиеся непосредственно следующие за n вершины в конец списка ОТКРЫТ и построить указатели, ведущие от них назад к вершине n.
5) Если какие- нибудь из этих непосредственно следующих за n вершин являются целевыми вершинами, то на выход выдать решение, получающееся просмотром вдоль указателей; в противном случае переходить к шагу (2).
В этом алгоритме предполагается, что начальная вершина не удовлетворяет поставленной цели, хотя нетрудно ввести этап проверки такой возможности. Блок- схема алгоритма показана на рис.6. Вершины и указатели, построенные в процессе перебора, образуют поддерево всего неявно определенного дерева пространства состояний. Мы будем называть такое поддерево деревом перебора.

В методе полного перебора непременно будет найден самый короткий путь к целевой вершине при условии, что такой путь вообще существует. (Если такого пути нет, то в указанном методе будет объявлено о неуспехе в случае конечных графов, а в случае бесконечных графов алгоритм никогда не кончит свою работу.)

Пуск

Поместить S в список
ОТКРЫТ



 нет
да
нет
да



 Пуст
ли список
Неудача
Пуст
ли список
Неудача
ОТКРЫТ?

Взять первую вершину из списка ОТКРЫТ
и поместить ее в список ЗАКРЫТ.
Обозначить эту вершину через n

Раскрыть n. Поместить дочерние
вершины в конец списка ОТКРЫТ.
Провести от них к n указателю.



 нет
Являются
ли да
нет
Являются
ли да



 какие-либо
из Успех
какие-либо
из Успех
дочерних вершин
целевыми?
рис.6 Блок- схема программы алгоритма полного перебора
для дерева.
4.2.2 Метод равных цен.
Могут встретится задачи, в которых решению предъявляются какие-то иные требования, отличные от требования получения наикратчайшей последовательности операторов. Присваивание дугам деревьев определенных цен (с последующим нахождением решающего пути, имеющего минимальную стоимость) соответствует многим из таких обещанных критериев. Более общий вариант метода полного перебора, называемый методом равных цен, позволяет во всех случаях найти некоторый путь от начальной вершины к целевой, стоимость которого минимальна. В то время как в выше описанном алгоритме распространяются линии равной длины пути от начальной вершины, в более общем алгоритме, который будет описан ниже, распространяются линии равной стоимости пути. Предполагается, что нам задана функция стоимости c(ni,nj), дающая стоимость перехода от вершины ni к некоторой следующей за ней вершине nj.
В методе равных цен для каждой вершины n в дереве перебора нам нужно помнить стоимость пути, построенного от начальной вершины s к вершине n. Пусть g(n)- стоимость от вершины s к вершине n в дереве перебора. В случае деревьев перебора мы можем быть уверены, что g(n) является к тому же стоимостью того пути, который имеет минимальную стоимость (т.к. этот путь единственный).
В методе равных цен вершины раскрываются в порядке возрастания стоимости g(n). Этот метод характеризуется такой последовательностью шагов:
1) Поместить начальную вершину s в список, называемый ОТКРЫТ. Положить g(s)=0.
2) Если список ОТКРЫТ пуст, то на выход подается сигнал о неудаче поиска, в противном случае переходить к следующему шагу.
3) Взять из списка ОТКРЫТ ту вершину, для которой величина g имеет наименьшее значение, и поместить ее в список ЗАКРЫТ. Дать этой вершине название n. (В случае совпадения значений выбирать вершину с минимальными g произвольно, но всегда отдавая предпочтение целевой вершине.)
4) Если n есть целевая вершина, то на выход выдать решающий путь, получаемый путем просмотра назад в соответствии с указателями; в противном случае переходить к следующему шагу.
5) Раскрыть вершину n, построив все непосредственно следующие за ней вершины. (Если таковых нет переходить к шагу (2).) Для каждой из такой непосредственно следующей (дочерней) вершины ni вычислить стоимость g(n), положив g(ni)=g(n)+c(n,ni). Поместить эти вершины вместе с соответствующими им только что найденными значениями g в список ОТКРЫТ и построить указатели, идущие назад к n.
6) Перейти к шагу (2).
Блок- схема этого алгоритма показана на рис.7. Проверка того, является ли некоторая вершина целевой, включена в эту схему так, что гарантируется обнаружение путей минимальной стоимости.
Алгоритм, работающий по методу равных цен, может быть также использован для поиска путей минимальной длины, если просто положить стоимость каждого ребра равной единице. Если имеется несколько начальных вершин, о алгоритм просто модифицируется: на шаге (1) все начальные вершины помещаются в список ОТКРЫТ. Если состояния, отвечающие поставленной цели, могут быть описаны явно, то процесс перебора можно пустить в обратном направлении, приняв целевые вершины в качестве начальных и используя обращение оператора Г.

Пуск

Поместить s в список ОТКРЫТ.
Положить g(s)=0.


 нет
Пуст ли да
нет
Пуст ли да



 список
неудача
список
неудача
ОТКРЫТ?


Взять из списка ОТКРЫТ вершину
с наименьшим значением g
и поместить ее в список ЗАКРЫТ.
Обозначить ее через n.






 нет
Является ли
n да успех
нет
Является ли
n да успех
вершиной цели?

Раскрыть n. Вычислить значение g
для дочерних вершин.
Поместить эти вершины в список ОТКРЫТ.
Провести от них указатели к n.

рис.7 Блок- схема программы алгоритма равных цен для деревьев.
4.3 Метод перебора в глубину.
В методах перебора в глубину прежде всего раскрываются те вершины, которые были построены последними. Определим глубину вершины дереве следующим образом:
Глубина корня дерева равна нулю.
Глубина любой последующей вершины равна единице плюс глубина вершины, которая непосредственно ей предшествует.
Таким образом, вершиной, имеющей наибольшую глубину в дереве перебора, в данный момент служит та, которая должна в этот момент быть раскрыта.
Такой подход может привести к процессу, разворачивающемуся вдоль некоторого бесполезного пути, поэтому нужно ввести некоторую процедуру возвращения. После того как в ходе процесса строится вершина с глубиной, превышающей некоторую граничную глубину, мы раскрываем вершины наибольшей глубины, не превышающей этой границы и т.д.
Метод перебора в глубину определяется следующей последовательностью шагов:
1) Поместить начальную вершину в список, называемый ОТКРЫТ.
2) Если список ОТКРЫТ пуст, то на выход подается сигнал о неудаче поиска, в противном случае перейти к шагу (3).
3) Взять первую вершину из списка ОТКРЫТ и перенести в список ЗАКРЫТ. Дать этой вершине название n.
4) Если глубина вершины n равна граничной глубине, то переходить к (2), в противном случае к (5).
5) Раскрыть вершину n, построив все непосредственно следующие за ней вершины. Поместить их (в произвольном порядке) в начало списка ОТКРЫТ и построить указатели, идущие от них к n.
6) Если одна из этих вершин целевая, то на выход выдать решение , просматривая для этого соответствующие указатели, в противном случае переходить к шагу (2).
На рис.8 приведена блок- схема для метода перебора в глубину.

Пуск

Поместить s в список ОТКРЫТ.

 нет
Пуст ли да
нет
Пуст ли да

 список
неудача
список
неудача
ОТКРЫТ?
Взять первую вершину из списка
ОТКРЫТ
и поместить ее в список ЗАКРЫТ.
Обозначить ее через n.


да Равна ли глубина нет



 n граничной
глубине
n граничной
глубине

Раскрыть n. Вычислить значение g
для дочерних вершин.
Поместить эти вершины в список ОТКРЫТ.
Провести от них указатели к n


Являются ли


 нет
какие- либо
да
нет
какие- либо
да
из дочерних вершин успех
целевыми?
рис.8 Блок-схема программы алгоритма поиска в глубину для деревьев.
В алгоритме поиска в глубину сначала идет перебор вдоль одного пути, пока не будет достигнута максимальная глубина, затем рассматриваются альтернативные пути той же или меньшей глубины, которые отличаются от него лишь последним шагом, после чего рассматриваются пути, отмечающимися последними двумя шагами, и т.д.
4.4. Изменение при переборе на произвольных графах
При переборе на графах, а не на деревьях, нужно внести некоторые естественные изменения в указанные алгоритмы. В простом методе полного перебора не нужно вносить никаких изменений, следует лишь проверять, не находиться ли уже вновь построенная вершина в список ОТКРЫТ или ЗАКРЫТ по той причине, что она уже строилась раньше в результате раскрытия какой- то вершины. Если это так, то ее не нужно вновь помещать в список ОТКРЫТ.
Прежде чем делать какие- либо изменения в алгоритме перебора в глубину, нужно нужно решить, что понимать под глубиной вершины в графе. Согласно обычному определению, глубина вершины равна единице плюс глубина наиболее близкой родительской вершины, причем глубина начальной вершины предполагается равной нулю. Тогда поиск в глубину можно было бы получить, выбирая для раскрытия самую глубокую вершину списка ОТКРЫТ (без превышения граничной глубины). Когда порождаются вершины, уже имеющиеся в списке ОТКРЫТ, либо в списке ЗАКРЫТ, пересчет глубины такой вершины может оказаться необходимым.
Даже в том случае, когда перебор осуществляется на полном графе, множество вершин и указателей, построенное в процессе перебора , тем не менее образуют дерево. (Указатели указывают только на одну порождающую вершину.)
4.5. Обсуждение эвристической информации
Методы слепого перебора, полного перебора или поиска в глубину являются исчерпывающими процедурами поиска путей к целевой вершине. В принципе эти методы обеспечивают решение задачи поиска пути, но часто эти методы невозможно использовать, поскольку при переборе прийдется раскрыть слишком много вершин. Прежде чем нужный путь будет найден. Т.к. всегда имеются практические ограничения на время вычисления и объем памяти, то нужны другие методы, более эффективные. чем методы слепого перебора.
Для многих задач можно сформулировать правила, позволяющие уменьшить объем перебора. Все такие правила, используемые для ускорения поиска, зависят от специфической информации о задаче, представляемой в виде графа. Будем называть такую информацию эвристической информацией (помогающей найти решение) и называть использующие ее процедуры поиска эвристическими методами поиска. Один из путей уменьшить перебор состоит в выборе более “информированного” оператора Г, который не строит много не относящихся к делу вершин. Этот способ применим как в методе полного перебора, так и в методе перебора в глубину. Другой путь состоит в использовании эвристической информации для модификации шага (5) алгоритма перебора в глубину. Вместо того, чтобы размещать вновь построенные вершины в произвольном порядке в начале списка ОТКРЫТ, их можно расположить в нем некоторым определенным образом, зависящим от эвристической информации. Так, при переборе в глубину в первую очередь будет раскрываться та вершина, которая представляется наилучшей.
Более гибкий (и более дорогой) путь использования эвристической информации состоит в том, чтобы, согласно некоторому критерию, на каждом шаге переупорядочивать вершины списка ОТКРЫТ. В этом случае перебор мог бы идти дальше в тех участках границы, которые представляются наиболее перспективными. Для того, чтобы применить процедуру упорядочения, нам необходима мера, которая позволяла бы оценивать “перспективность” вершин. Такие меры называют оценочными функциями.
Иногда удается выделить эвристическую информацию (эвристику), уменьшающую усилия, затрачиваемые на перебор (до вершины, меньшей скажем, чем при поиске методом равных цен), без потери гарантированной возможности найти путь, обладающий наименьшей стоимостью. Чаще же используемые эвристики сильно уменьшают объем работы, связанной с перебором, ценой отказа от гарантии найти путь наименьшей стоимости в некоторых или во всех задачах.
4.5. Использование оценочных функций
Как мы уже отмечали, обычный способ использования эвристической информации связан с употреблением упорядочения перебора оценочных функций. Оценочная функция должна обеспечивать возможность ранжирования вершин- кандидатов на раскрытие- с тем, чтобы выделить ту вершину, которая с наибольшей вероятностью находится на лучшем пути к цели. Оценочные функции строились на основе различных соображений. Делались попытки определить вероятность того, что вершина расположена на лучшем пути. Предлагалось также использовать расстояние и другие меры различия между произвольной вершиной и множеством целевых вершин.
Предположим, что задана некоторая функция f, которая могла бы быть использована для упорядочения вершин перед их раскрытием. Через f(n) обозначим значение этой функции на вершине n. Эта функция совпадает с оценкой стоимости того из путей, идущих от начальной вершины к целевой и проходящих через вершину n, стоимость которого - наименьшая (из всех таких путей).
Условимся располагать вершины, предназначенные для раскрытия, в порядке возрастания их значений функции f. Тогда можно использовать некоторый алгоритм (подобный алгоритму равных цен), в котором для очередного раскрытия выбирается та вершина списка ОТКРЫТ, для которой значение f оказывается наименьшим. Будем называть такую процедуру алгоритм упорядоченного перебора.
Чтобы этот алгоритм упорядоченного перебора был применен для перебора на произвольных графах (а не только на деревьях), необходимо предусмотреть в нем возможность работы в случае построения вершин, которые уже имеются либо в списке ОТКРЫТ, либо в списке ЗАКРЫТ. При использовании некоторой произвольной функции f нужно учесть, что величина f для некоторой вершины из списка ЗАКРЫТ может понизится. если к ней найден новый путь (f(n) может зависеть от пути из s к n даже для вершин из списка ЗАКРЫТ). Следовательно, мы должны тогда перенести такие вершины назад в список ОТКРЫТ и позаботиться об изменении направлений соответствующих указателей.
После принятия этих необходимых мер алгоритм упорядоченного поиска может быть представлен такой последовательностью шагов:
1) Поместить начальную вершину s в список, называемый ОТКРЫТ, и вычислить f(s).
2) Если список ОТКРЫТ пуст, то на выход дается сигнал о неудаче; в противном случае переходи к следующему этапу.
3) Взять из списка ОТКРЫТ ту вершину, для которой f имеет наименьшее значение, и поместить ее в список ЗАКРЫТ. Дать этой вершине название n. (В случае совпадения значений выбирать вершину с минимальными f произвольно, но всегда отдавая предпочтение целевой вершине.)
4) Если n есть целевая вершина, то на выход выдать решающий путь, получаемый прослеживанием соответствующих указателей; в противном случае переходить к следующему шагу.
5) Раскрыть вершину n, построив все непосредственно следующие за ней вершины. (Если таковых нет переходить к шагу (2).) Для такой дочерней вершины ni вычислить значение f(ni).
6) Связать с теми из вершин ni , которых еще нет в списках ОТКРЫТ или ЗАКРЫТ, только что прочитанные значения f(ni). Поместить эти вершины в список ОТКРЫТ и провести от них к вершине n указатели.
7) Связать с теми из непосредственно следующих за n вершинами. которые уже были в списке ОТКРЫТ или ЗАКРЫТ, меньшие из прежних или только что вычисленных значений f. Поместить в список ОТКРЫТ те из непосредственно следующих за n вершин, для которых новое значение f оказалось ниже, и изменить направление указателей от всех вершин, для которых значение f уменьшилось, направив их к n..
8) Перейти к (2).
Общая структура алгоритма идентична структуре алгоритма равных цен (см. рис. 7), поэтому мы не приводим для него блок-схему. Отметим, что множество вершин и указателей, порождаемых этим алгоритмом, образует дерево (дерево перебора), причем на концах этого дерева расположены вершины из списка ОТКРЫТ.
4.6. Использование других эвристик..
4.6.1. Перебор этапами.
Использование эвристической информации может существенно уменьшить объем перебора, необходимого для поиска приемлемого пути. Следовательно, ее использование, позволяет осуществлять перебор на гораздо больших графах. и тем не менее могут возникнуть случаи, когда имеющаяся в нашем распоряжении память оказывается исчерпанной раньше, чем будет найден удовлетворительный путь. В этих случаях может быть полезным не отказываться полностью от продолжения перебора, а “отсечь” часть ветвей дерева, построенного к этому моменту в процессе перебора, освободив тем самым пространство памяти, необходимое для углубления перебора.
Такой процесс перебора может осуществляться этапами, которые отделяются друг от друга операциями отсечения дерева, необходимыми для освобождения памяти. В конце каждого этапа удерживается некоторое подмножество открытых вершин, например вершины с наименьшими значениями f. Наилучшие пути к этим вершинам запоминаются, а остальная часть дерева отбрасывается. Затем начинается перебор ва, уже от этих “лучших” открытых вершин. Этот процесс продолжается до тех пор, пока либо будет найдена целевая вершина, либо будут исчерпаны все ресурсы. Хотя весь процесс заканчивается построением некоторого пути, тем не менее у нас нет теперь гарантии, что этот путь будет оптимальным.
4.6.2. Ограничение числа дочерних вершин.
Другой путь уменьшения перебора, состоит в том, чтобы использовать более информированный оператор Г, который не порождал бы слишком много ненужных вершин, а порождал бы лишь вершины, расположенные на оптимальном пути, снимая тем самым полностью необходимость перебора.
Один из приемов, который может позволить снизить требуемый объем перебора, состоит в том, чтобы сразу же после раскрытия вершины отбросить почти все дочерние вершины, оставив лишь небольшое их число с наименьшими значениями функции f. Конечно, отброшенные вершины могут оказаться расположенными на наилучших (и даже только на наилучших) путях, так что только эксперимент может определить пригодность такого метода отсечения ветвей графа для конкретных задач.
4.6.3. Поочередное построение дочерних вершин.
Когда вершины, непосредственно следующие за некоторой, вычисляются с помощью операторов в пространстве состояний, то очевидно, что эти последующие вершины могут строиться по отдельности и независимо друг от друга. Кроме того, существуют случаи, когда применение всех применимых операторов было бы очень расточительно в смысле вычислительных затрат. Как указывалось выше, более информированный оператор Г выделял бы несколько наиболее перспективных операторов и строил бы только те последующие вершины, которые возникают в результате их применения. Более гибкий подход состоит в том, чтобы сначала допускать применение самого перспективного оператора (что приведет к одно из последующей вершине), оставляя в дальнейшем возможность в процессе перебора построить и другие вершины, непосредственно следующие за данной. Для того, чтобы воспользоваться этой идеей вместе с оценочными функциями для упорядочения вершин, в алгоритм упорядоченного перебора следует внести соответствующие изменения.
Список литературы:
1. И. Братко. Программирование на языке Пролог для искусст-
венного интеллекта.- М.: Мир, 1990.
2. Г. Долин. Что такое ЭС.- Компьютер Пресс, 1992/2.
3. Д. Р. Малпасс. Реляционный язык Пролог и его применение.
4. Д. Н. Марселлус. Программирование экспертных систем на Турбо Прологе.- М.: Финансы и статистика, 1994.
5. К. Нейлор. Как построить свою экспертную систему.- М.: Энергоатомиздат, 1991.
6. Н. Д. Нильсон. Искусственный интеллект. Методы поиска решений.- М.: Мир, 1973.
7. В. О. Сафонов. Экспертные системы- интеллектуальные помощники специалистов.- С.-Пб: Санкт-Петербургская организация общества “Знания” России, 1992.
8. К. Таунсенд, Д. Фохт. Проектирование и программная реализация экспертных систем на персональных ЭВМ.- М.: Финансы и статистика, 1990.
9. В. Н. Убейко. Экспертные системы.- М.: МАИ, 1992.
10. Д. Уотермен. Руководство по экспертным системам.- М.: Мир, 1980.
11. Д. Элти, М. Кумбс. Экспертные системы: концепции и примеры.- М.: Финансы и статистика, 1987.
Содержание
Глава 1. Экспертные системы, их особенности. Применение экспертных систем. История развития.
1.1. Определение экспертных систем. Главное достоинство и назначение
экспертных систем.
1.2. Отличие экспертных систем от других программных продуктов.
1.3. Отличительные особенности. Экспертные системы первого и второ-
го поколения.
1.4. Области применения.
а) Медицинская диагностика.
б) Прогнозирование.
в) Планирование.
г) Интерпретация.
д) Контроль и управление.
е) Диагностика неисправностей в механических и электрических
устройствах.
ж) Обучение.
1.5. Критерии использования экспертных систем для решения задач.
1.6. Ограничения в применении экспертных систем.
1.7. Преимущества экспертных систем перед человеком-экспертом.
1.8. История развития экспертных систем.
1.8.1. Основные линии развития экспертных систем.
1.8.2. Проблемы, возникающие при создании экспертных систем.
Перспективы развития.
Глава 2. Структура систем, основанных на знаниях.
2.1. Категории пользователей экспертных систем.
2.2. Подсистема приобретения знаний.
2.3. База знаний.
2.4. Подсистема вывода.
2.4.1. Подсистема вывода, способы логического вывода.
2.4.2. Компонента вывода.
2.4.3. Управляющий компонент.
2.5. Диалог с экспертной системой.Объяснение.
Глава 3. Стратегии управления выводом.
3.1. Разработка стратегии управления выводом.
3.2. Повышение эффективности поиска.
а) Сопоставление методов поиска в глубину и в ширину.
б) Альфа-бета алгорнтм.
в) Разбиение на подзадачи.
г) Использование формальной логики при решении задач.
3.3. Представление задач в пространстве состояний.
3.3.1. Описание состояний.
3.3.2. Состояния и операторы.
3.3.3. Запись в виде графа.
Глава 4. Методы поиска в пространстве состояний.
4.1. Процессы поиска на графе.
4.2. Методы полного перебора.
4.2.1.Метод полного перебора.
4.2.2. Метод равных цен.
4.3. Метод перебора в глубину.
4.4. Изменения при переборе на произвольных графах.
4.5. Обсуждение эвристической информации.
4.6. Использование оценочных функций.
4.7. Использование других эвристик.
4.7.1. Перебор этапами.
4.7.2. Ограничение числа дочерних вершин.
4.7.3. Поочередное построение дочерних вершин.
Приложение 1.
Приложение 2.