Курсовая работа: Современная криптография
Проблема защиты информации путем ее преобразования, исключающего ее прочтение посторонним лицом волновала человеческий ум с давних времен. История криптографии - ровесница истории человеческого языка. Более того, первоначально письменность сама по себе была криптографической системой, так как в древних обществах ею владели только избранные.
Священные книги Древнего Египта, Древней Индии тому примеры.
С широким распространением письменности криптография стала формироваться как самостоятельная наука. Первые криптосистемы встречаются уже в начале нашей эры. Так, Цезарь в своей переписке использовал уже более менее систематический шифр, получивший его имя.
Бурное развитие криптографические системы получили в годы первой и второй мировых войн. Начиная с послевоенного времени и по нынешний день появление вычислительных средств ускорило разработку и совершенствование криптографических методов.
Почему проблема использования криптографических методов в информационных системах (ИС) стала в настоящий момент особо актуальна?
С одной стороны, расширилось использование компьютерных сетей, в частности глобальной сети Internet, по которым передаются большие объемы информации государственного, военного, коммерческого и частного характера, не допускающего возможность доступа к ней посторонних лиц.
С другой стороны, появление новых мощных компьютеров, технологий сетевых и нейронных вычислений сделало возможным дискредитацию криптографических систем еще недавно считавшихся практически не раскрываемыми.
В первой главе данной работы можно познакомиться с основными понятиями современной криптографии, требованиям к ним, возможностями ее практического применения.
Во второй главе работы с протоколами распределения криптографических ключей, понятием электронной подписи и протоколами электронной подписи..
Третья глава данной работы рассказывает о хэш-функциях и (методах) алгоритмах их построения.
В четвертой главе будет рассказано о модернизации электронной подписи Эль Гамаля и задаче дискретного логарифмирования.
Глава 1. Основные понятия современной криптографии
Проблемой защиты информации путем ее преобразования занимается криптология (kryptos - тайный, logos - наука). Криптология разделяется на два направления - криптографию и криптоанализ. Цели этих направлений прямо противоположны.
Криптография занимается поиском и исследованием математических методов преобразования информации.
Сфера интересов криптоанализа - исследование возможности расшифровывания информации без знания ключей.
В этой работе основное внимание будет уделено криптографическим методам.
Современная криптография включает в себя четыре крупных раздела:
Симметричные криптосистемы.
Криптосистемы с открытым ключом.
Системы электронной подписи.
Управление ключами.
Основные направления использования криптографических методов - передача конфиденциальной информации по каналам связи (например, электронная почта), установление подлинности передаваемых сообщений, хранение информации (документов, баз данных) на носителях в зашифрованном виде.
Криптография дает возможность преобразовать информацию таким образом, что ее прочтение (восстановление) возможно только при знании ключа.
В качестве информации, подлежащей шифрованию и дешифрованию, будут рассматриваться тексты, построенные на некотором алфавите. Под этими терминами понимается следующее.
Алфавит - конечное множество используемых для кодирования информации знаков.
Текст - упорядоченный набор из элементов алфавита.
В качестве примеров алфавитов, используемых в современных ИС можно привести следующие:
алфавит Z33 - 32 буквы русского алфавита и пробел;
алфавит Z256 - символы, входящие в стандартные коды ASCII и КОИ-8;
бинарный алфавит - Z2 = {0,1};
восьмеричный алфавит или шестнадцатеричный алфавит;
Шифрование - преобразовательный процесс: исходный текст, который носит также название открытого текста, заменяется шифрованным текстом.
Дешифрование - обратный шифрованию процесс. На основе ключа шифрованный текст преобразуется в исходный.
Ключ - информация, необходимая для беспрепятственного шифрования и дешифрования текстов.
Криптографическая система представляет собой семейство T преобразований открытого текста. Члены этого семейства индексируются, или обозначаются символом k; параметр k является ключом. Пространство ключей K - это набор возможных значений ключа. Обычно ключ представляет собой последовательный ряд букв алфавита.
Криптосистемы разделяются на симметричные и с открытым ключом.
В симметричных криптосистемах и для шифрования, и для дешифрования используется один и тот же ключ.
В системах с открытым ключом используются два ключа - открытый и закрытый, которые математически связаны друг с другом. Информация шифруется с помощью открытого ключа, который доступен всем желающим, а расшифровывается с помощью закрытого ключа, известного только получателю сообщения. Термины распределение ключей и управление ключами относятся к процессам системы обработки информации, содержанием которых является составление и распределение ключей между пользователями.
Электронной (цифровой) подписью называется присоединяемое к тексту его криптографическое преобразование, которое позволяет при получении текста другим пользователем проверить авторство и подлинность сообщения.
Криптостойкостью называется характеристика шифра, определяющая его стойкость к дешифрованию без знания ключа (т.е. криптоанализу). Имеется несколько показателей криптостойкости, среди которых:
количество всех возможных ключей;
среднее время, необходимое для криптоанализа.
Преобразование Tk определяется соответствующим алгоритмом и значением параметра k. Эффективность шифрования с целью защиты информации зависит от сохранения тайны ключа и криптостойкости шифра.
Требования к криптосистемам
Процесс криптографического закрытия данных может осуществляться как программно, так и аппаратно. Аппаратная реализация отличается существенно большей стоимостью, однако ей присущи и преимущества: высокая производительность, простота, защищенность и т.д. Программная реализация более практична, допускает известную гибкость в использовании.
Для современных криптографических систем защиты информации сформулированы следующие общепринятые требования:
зашифрованное сообщение должно поддаваться чтению только при наличии ключа;
число операций, необходимых для определения использованного ключа шифрования по фрагменту шифрованного сообщения и соответствующего ему открытого текста, должно быть не меньше общего числа возможных ключей;
число операций, необходимых для расшифровывания информации путем перебора всевозможных ключей должно иметь строгую нижнюю оценку и выходить за пределы возможностей современных компьютеров (с учетом возможности использования сетевых вычислений);
знание алгоритма шифрования не должно влиять на надежность защиты;
незначительное изменение ключа должно приводить к существенному изменению вида зашифрованного сообщения даже при использовании одного и того же ключа;
структурные элементы алгоритма шифрования должны быть неизменными;
дополнительные биты, вводимые в сообщение в процессе шифрования, должен быть полностью и надежно скрыты в шифрованном тексте;
длина шифрованного текста должна быть равной длине исходного текста;
не должно быть простых и легко устанавливаемых зависимостью между ключами, последовательно используемыми в процессе шифрования;
любой ключ из множества возможных должен обеспечивать надежную защиту информации;
алгоритм должен допускать как программную, так и аппаратную реализацию, при этом изменение длины ключа не должно вести к качественному ухудшению алгоритма шифрования.
Глава 2. Протоколы распределения криптографических ключей и протоколы электронной подписи.
Системы с открытым ключом .
Как бы ни были сложны и надежны криптографические системы - их слабое мест при практической реализации - проблема распределения ключей. Для того, чтобы был возможен обмен конфиденциальной информацией между двумя субъектами ИС, ключ должен быть сгенерирован одним из них, а затем каким-то образом опять же в конфиденциальном порядке передан другому. Т.е. в общем случае для передачи ключа опять же требуется использование какой-то криптосистемы.
Для решения этой проблемы на основе результатов, полученных классической и современной алгеброй, были предложены системы с открытым ключом.
Суть их состоит в том, что каждым адресатом ИС генерируются два ключа, связанные между собой по определенному правилу. Один ключ объявляется открытым, а другой закрытым. Открытый ключ публикуется и доступен любому, кто желает послать сообщение адресату. Секретный ключ сохраняется в тайне.
Исходный текст шифруется открытым ключом адресата и передается ему. Зашифрованный текст в принципе не может быть расшифрован тем же открытым
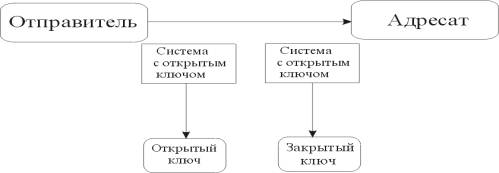 |
ключом. Дешифрование сообщение возможно только с использованием закрытого ключа, который известен только самому адресату.
Криптографические системы с открытым ключом используют так называемые необратимые или односторонние функции, которые обладают следующим свойством: при заданном значении x относительно просто вычислить значение f(x), однако если y=f(x), то нет простого пути для вычисления значения x.
Множество классов необратимых функций и порождает все разнообразие систем с открытым ключом. Однако не всякая необратимая функция годится для использования в реальных ИС.
В самом определении необратимости присутствует неопределенность. Под необратимостью понимается не теоретическая необратимость, а практическая невозможность вычислить обратное значение используя современные вычислительные средства за обозримый интервал времени. Поэтому чтобы гарантировать надежную защиту информации, к системам с открытым ключом (СОК) предъявляются два важных и очевидных требования:
1. Преобразование исходного текста должно быть необратимым и исключать его восстановление на основе открытого ключа.
2. Определение закрытого ключа на основе открытого также должно быть невозможным на современном технологическом уровне. При этом желательна точная нижняя оценка сложности (количества операций) раскрытия шифра.
Алгоритмы шифрования с открытым ключом получили широкое распространение в современных информационных системах. Так, алгоритм RSA стал мировым стандартом де-факто для открытых систем и рекомендован МККТТ.
Вообще же все предлагаемые сегодня криптосистемы с открытым ключом опираются на один из следующих типов необратимых преобразований:
Разложение больших чисел на простые множители.
Вычисление логарифма в конечном поле.
Вычисление корней алгебраических уравнений.
Алгоритм Диффи-Хеллмана.
Диффи и Хелман предложили для создания криптографических систем с открытым ключом функцию дискретного возведения в степень.
Необратимость преобразования в этом случае обеспечивается тем, что достаточно легко вычислить показательную функцию в конечном поле Галуа состоящим из p элементов. (p - либо простое число, либо простое в любой степени). Вычисление же логарифмов в таких полях - значительно более трудоемкая операция.
Если y=ax,, 1 < x < p-1, где - фиксированный элемент поля GF(p), то x=loga y над GF(p). Имея x, легко вычислить y. Для этого потребуется 2 ln(x+y) операций умножения.
Обратная задача вычисления x из y будет достаточно сложной. Если p выбрано достаточно правильно, то извлечение логарифма потребует вычислений, пропорциональных
L(p) = exp { (ln p ln ln p)0.5 }
Для обмена информацией первый пользователь выбирает случайное число x1, равновероятное из целых 1,...,p-1. Это число он держит в секрете, а другому пользователю посылает число
y1 = ax1 mod p
Аналогично поступает и второй пользователь, генерируя x2 и вычислив y2, отправляя его первому пользователю.
В результате этого они могут вычислять k12 = ax1x2 mod p.
Для того, чтобы вычислить k12, первый пользователь возводит y2 в степень x1. То же делает и второй пользователь. Таким образом, у обоих пользователей оказывается общий ключ k12, который можно использовать для шифрования информации обычными алгоритмами. В отличие от алгоритма RSA, данный алгоритм не позволяет шифровать собственно информацию.
Не зная x1 и x2, злоумышленник может попытаться вычислить k12, зная только перехваченные y1 и y2. Эквивалентность этой проблемы проблеме вычисления дискретного логарифма есть главный и открытый вопрос в системах с открытым ключом. Простого решения до настоящего времени не найдено. Так, если для прямого преобразования 1000-битных простых чисел требуется 2000 операций, то для обратного преобразования (вычисления логарифма в поле Галуа) - потребуется около 1030 операций.
Как видно, при всей простоте алгоритма Диффи-Хелмана, его недостатком является отсутствие гарантированной нижней оценки трудоемкости раскрытия ключа.
Кроме того, хотя описанный алгоритм позволяет обойти проблему скрытой передачи ключа, необходимость аутентификации остается. Без дополнительных средств, один из пользователей не может быть уверен, что он обменялся ключами именно с тем пользователем, который ему нужен. Опасность имитации в этом случае остается.
В качестве обобщения сказанного о распределении ключей следует сказать следующее. Задача управления ключами сводится к поиску такого протокола распределения ключей, который обеспечивал бы:
возможность отказа от центра распределения ключей;
взаимное подтверждение подлинности участников сеанса;
подтверждение достоверности сеанса механизмом запроса-ответа,
использование для этого программных или аппаратных средств;
использование при обмене ключами минимального числа сообщений.
Иерархические схемы распределения ключей.
Рассмотрим следующую задачу.
Пусть абоненты сети связи не равноправны между собой, а разделены на "классы безопасности" C1,C2,…,Cn. На множестве этих классов определен некоторый частичный порядок; если Cj < Ci, то говорят, что Ci доминирует Cj , т.е. имеет более высокий уровень безопасности, чем Cj . Задача состоит в том, чтобы выработать секретные ключи ki для каждого класса Ci таким образом, чтобы абонент из Ci мог вычислить kj в том и только в том, когда Ci ³ Cj.
Эта задача была решена в общем виде Эклом и Тейлором в связи с проблемой контроля доступа. В их методе каждый класс безопасности получает, кроме секретного, также и открытый ключ, который вместе с секретным ключом класса, доминирует данный, позволяет последнему вычислить секретный ключ данного класса.
![]() Для случая, когда
частичный порядок является деревом,
имеется схема Сандху [San], которая позволяет добавлять новые
классы безопасности без изменения ключей существующих классов.
Для случая, когда
частичный порядок является деревом,
имеется схема Сандху [San], которая позволяет добавлять новые
классы безопасности без изменения ключей существующих классов.
![]() Приведем описание иерархической схемы
распределения ключей, предложенной Ву и Чангом для случая, когда частичный
порядок является деревом.
Приведем описание иерархической схемы
распределения ключей, предложенной Ву и Чангом для случая, когда частичный
порядок является деревом.
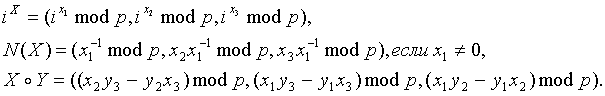 |
Пусть p – большое простое число, V = Zp ´ Zp ´Zp – множество всех трехмерных векторов над Zp . Если i Î Zp , X = (x1,x2,x3), Y = (y1,y2,y3) Î V, то определим следующие векторы из V:
Предположим, что каждому классу безопасности сопоставлен идентификатор
i Î Zp {0}; класс с идентификатором i мы будем обозначать через Ci . Ввиду того, что частичный порядок на множестве классов безопасности является деревом, для описания протокола достаточно описать процедуры выработки секретного ключа для корневого класса безопасности (т.е. класса с наиболее высоким уровнем безопасности) и для произвольного класса Cj при условии, что секретный ключ для класса Ci , непосредственно доминирующего Cj (т.е. такого, что Cj < Ci и не существует класса Cr такого, что Cj < Cr < Ci), уже выработан.
Для корневого класса безопасности (например C1) выбирается произвольный секретный ключ Ki Î V {(0,0,0)}.
Пусть класс Ci доминирует класс Cj и для Ci уже выработан секретный ключ Ki Î V. Тогда в качестве секретного ключа для Cj выбирается вектор
![]() где Pj
– вектор из V,
выбранный случайно так, чтобы было определено.
где Pj
– вектор из V,
выбранный случайно так, чтобы было определено.
После чего вектор Pj делается общедоступным.
Таким образом, в процессе выполнения протокола для каждого класса безопасности Ci вырабатывается секретный ключ Ki и открытый ключ Pj (кроме корневого класса). Если теперь Cj < Ci, то абонент из Ci может вычислить Kj следующим образом.
Существует цепь классов безопасности Ci = Cro>Cr1>…>Crn = Cj, где Cl-1 непосредственно доминирует Cl для всех L = 1,…,n. Абонент Ci, зная Ki и Pr1, вычисляет по формуле (**), затем, зная Kr1 и Pr2, вычисляет Kr2 по той же формуле и т.д.; после n шагов будет вычислен Krn = Kj.
Электронная подпись
В чем состоит проблема аутентификации данных?
В конце обычного письма или документа исполнитель или ответственное лицо обычно ставит свою подпись. Подобное действие обычно преследует две цели.
Во-первых, получатель имеет возможность убедиться в истинности письма,
сличив подпись с имеющимся у него образцом. Во-вторых, личная подпись является юридическим гарантом авторства документа. Последний аспект особенно важен при заключении разного рода торговых сделок, составлении доверенностей, обязтельств и т.д.
Если подделать подпись человека на бумаге весьма непросто, а установить авторство подписи современными криминалистическими методами - техническая деталь, то с подписью электронной дело обстоит иначе. Подделать цепочку битов, просто ее скопировав, или незаметно внести нелегальные исправления в документ сможет любой пользователь.
С широким распространением в современном мире электронных форм документов (в том числе и конфиденциальных) и средств их обработки особо актуальной стала проблема установления подлинности и авторства безбумажной документации.
Итак, пусть имеются два пользователя Александр и Борис.
От каких нарушений и действий злоумышленника должна защищать система аутентификации.
Отказ (ренегатство).
Александр заявляет, что он не посылал сообщение Борису, хотя на самом деле он все-таки посылал.
Для исключения этого нарушения используется электронная (или цифровая) подпись.
Модификация (переделка).
Борис изменяет сообщение и утверждает, что данное (измененное) сообщение послал ему Александр.
Подделка.
Борис формирует сообщение и утверждает, что данное (измененное) сообщение послал ему Александр.
Активный перехват.
Владимир перехватывает сообщения между Александром и Борисом с целью их скрытой модификации.
Для защиты от модификации, подделки и маскировки используются цифровые сигнатуры.
Маскировка (имитация).
Владимир посылает Борису сообщение от имени Александра .
В этом случае для защиты также используется электронная подпись.
Повтор.
Владимир повторяет ранее переданное сообщение, которое Александра посылал ранее Борису . Несмотря на то, что принимаются всевозможные меры защиты от повторов, именно на этот метод приходится большинство случаев незаконного снятия и траты денег в системах электронных платежей.
Наиболее действенным методом защиты от повтора являются
использование имитовставок,
учет входящих сообщений.
Протоколы электронной подписи
Протоколы (схемы) электронной подписи являются основными криптографическим средством обеспечения целостности информации.
Схема Эль Гамаля.
Пусть обоим участникам протокола известны некоторое простое число p, некоторой порождающей g группы Z*p и некоторая хэш-функция h.
Подписывающий выбирает секретный ключ x ÎR Z*p-1 и вычисляет открытый ключ y = g-x mod p. Пространством сообщений в данной схеме является Zp-1 .
Для генерации подписи нужно сначала выбрать uÎR Zp-1. Если uÏR Z*p-1 (что проверяется эффективно), то необходимо выбрать новое u. Если же u ÎR Z*p-1 , то искомой подписью для сообщения m является пара (r,s), где r = gu mod p и
s = u-1(h(m) +xr) mod (p-1). Параметр u должен быть секретным и может быть уничтожен после генерации подписи.
Для проверки подписи (r,s) для сообщения m необходимо сначала проверить условия r Î Z*p и s Î Zp-1 . Если хотя бы одно из них ложно, то подпись отвергается. В противном случае подпись принимается и только тогда, когда gh(m) º yrrs(mod p ).
Вера в стойкость схемы Эль Гамаля основана на (гипотетической) сложности задачи дискретного логарифмирования по основанию g.
Схема Фиата – Шамира.
Для ее обеспечения центр обеспечения безопасности должен выбрать псевдослучайную функцию f, криптографическую хэш-функцию h, а также выбрать различные большие простые числа p, q и вычислить n = pq. Число n и функции f и h являются общедоступными и публикуются центром, а числа p и q должны быть секретными. Кроме того, схема использует два натуральных параметра l и t.
Для каждого пользователя центр обеспечения безопасности генерирует идентификационную информацию I, содержащую, например, имя пользователя, его адрес, идентификационный номер и т. п., и для каждого j = 1,…,l вычисляет
yi = f(I,j), отбирает среди них квадратичные вычеты по модулю n (изменив обозначения, мы считаем, что yi для всех j = 1,…,l являются квадратичными вычетами по млдулю n), и вычисляет xi – наименьший квадратичный корень по модулю n из yi-1 mod n. Числа yi играют роль открытого ключа, а xi – секретного. Так как эти ключи вычисляются с использованием I, схема Фивта – Шамира относится к схемам, основанным на идентификационной информации (identity based). В другом варианте схемы Фиата – Шамира сразу выбираются (псевдослучайным образом) параметру yi. На практике идентификационная информация I и/или открытый ключ (y1,…,yl) каждого пользователя помещаются в некоторый справочник, доступный всем пользователям для чтения, но не доступный для записи. Для обеспечения аутентичности, данные в этом справочнике заверяются подписью центра обеспечения безопасности. Секретный ключ (x1,…,xl) и идентификационная информация I могут быть помещены на интеллектуальную карточку пользователя.
Для генерации подписи для обеспечения m подписывающий
выбирает uiÎR Zn (каждое ui – независимо друг от друга) и вычисляет ri = ui2 mod n для i = 1,…,t;
вычисляет h(m,r1,…,rt) и полагает биты eij(i = 1,…,t, j = 1,…,t) равными первым lt битам h(m,r1,…,rt);
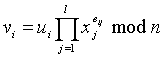
вычисляет для i = 1,…,t.
Искомой подписью для сообщения m является набор (eij, vi | i = 1,…,t, j = 1,…,l)
Для проверки подписи (eij, vi | i = 1,…,t, j = 1,…,l) для сообщения m подписывающий
вычисляет vj = h(I,j) для j = 1,…,l или берет их из общедоступного справочника и сравнивает их с имеющимися в подписи (если обнаружено несовпадение – подпись отвергается);
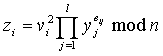
вычисляет для i = 1,…,t.
Подпись принимается тогда и только тогда, когда первые lt битов h(m,z1,…,zt) равны eij.
Несомненным достоинством схемы Фмата – Шамира является отсутствие дискретного экспонентрирования, что делает схему весьма эффективной. Но с другой стороны, в этой схеме длины ключей и подписи значительно больше, чем в схемах типа Эль Гамаля.
Схема стандарта электронной подписи ANSI США (DSA)
Эта схема аналогична схеме Эль Гамаля, но несколько эффективнее, так как в ней порядок g меньше, чем в схеме Эль Гамаля. Пусть в открытом доступе имеются некоторые простые числа p,q такие, что q | p-1, а также элемент g порядка q группы Z*q и хэш-функция h, действующая из пространства сообщений в Z*q .Параметры p,q,g и хэш-функция h могут быть выбраны центром обеспечения безопасности. Подписывающий выбирает секрктный ключ x ÎR Zq и вычисляет открытый ключ y = gx mod p. Для генерации подписи для сообщения m нужно выбрать u ÎR Z*q {1} и вычислить r = gu mod p mod q и s = u-1 (h(m) +xr) mod q. Параметр u должен быть секретным и может быть уничтожен после вычисления r и s. Если r = 0 или s = 0, то выбираются новое значение u и процесс генерации подписи повторяется. В противном случае (r,s) – искомая подпись для сообщения m.
Для проверки подписи (r,s) для сообщения m необходимо сначала проверить условие 0 < r < q и 0 < s <q. Если хотя бы одно из них ложно, то подпись отвергается. В противном случае подпись принимается тогда и только тогда, когда
gvh(m)yvr mod p mod q = r, где v = s-1 mod q.
Схема стандарта электронной подписи ГОСТ.
Пусть p,q,g,h,x,y имеют тотже смысл, что и в схеме DSA. Для генерации подписи для сообщения m нужно выбрать u ÎR Z*q {1} и вычислить
r = gu mod p mod q и s = u-1 (h(m) +xr) mod q. Параметр u должен быть секретным и может быть уничтожен после вычисления r и s. Если r = 0 или s = 0, то выбираются новое значение u и процесс генерации подписи повторяется. В противном случае (r,s) – искомая подпись для сообщения m.
Для проверки подписи (r,s) для сообщения m необходимо сначала проверить условие 0 < r < q и 0 < s <q. Если хотя бы одно из них ложно, то подпись отвергается. В противном случае подпись принимается тогда и только тогда, когда
gwsy-wr mod p mod q = r, где w = h(m)-1 mod q.
Схема RSA .
В схеме RSA подписывающий выбирает два различных больших простых числа p и q, которые играют роль секретного ключа, и публикует открытый ключ (n,e), где
n = pq, а e – некоторое число, взаимно простое с j(n) = (p-1)(q-1) (j - функция Эйлера). Подписью для сообщения m является s(m) = h(m)d mod n , где
d = e-1 mod j(n)(очевидно, что, зная p и q, можно эффективно вычислить d) и h – хэш-функция. Проверка подписи s для сообщения m состоит в проверке сравнения
se º h(m) (mod n) .
Схема RSA достаточно эффективна и широко используется на практике. Вера в стойкость схемы основана на (гипотетической) трудности задачи факторизации целых чисел.
Глава 3. Хэш-функции.
Хэш-функции являются необходимым элементом ряда криптографических схем. Под этим термином понимаются функции, отображающие сообщения произвольной длинны (иногда длинна сообщения ограничена, но достаточно большим числом) в значения фиксированной длинны. Последние часто называют хэш-кодами. Таким образом, у всякой хэш-функции h имеется большое количество коллизий, т.е. пар значений x ¹ y таких, что h(x) = h(y). Основное требование, предъявляемое к хеш-функциям, состоит в отсутствии эффективных алгоритмов поиска коллизий.
В ряде криптографических приложений, особенно в схемах электронной цифровой подписи, необходимым элементом является криптографически стойкая
хэш-функция.
Практические методы построения хэш-функций можно условно разделить на три группы: на основе какого-либо алгоритма шифрования, на основе какой-либо известной вычислительно трудной математической задачи и методы построения "с нуля".
Наиболее эффективной с точки зрения программной реализации, оказываются хэш-функции построенные "с нуля".
В данной дипломной работе в качестве алгоритма построения хэш-функции использовался алгоритм Ривеста MD5, который будет описан ниже.
Универсальные семейства хэш-функций.
Понятие универсального семейства хэш-функций было введено в 1979 г. Картером и Вегманом [CW].
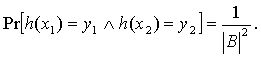 |
Определение 1. Пусть А и В - два конечных множества и H - семейство функций из А в В. H называется универсальным семейством хэш-функций если для любых х1 ¹ х2 Î А и y1,y2 Î В
Вероятность берется по случайному равновероятному выбору функции h из семейства Н.
Обычно предполагается, что мощность образа (множества В) меньше, чем мощность прообраза (А), и что хэш-функции "сжимают" входные слова. Как правило, рассматриваются семейства хэш-функций, которые переводят множество всех двоичных строк длины п в множество всех двоичных строк длины m, где m < п. Говоря неформально, универсальное семейство хэш-функций — это метод "перемешивания" с сокращением длины строк, при котором выходные значения распределены равномерно.
Семейство хэш-функций из определения 1 принято назвать 2-универсалъным семейством. Если в этом определении заменить пары значений x и y на наборы из k значений, то получим определение k-универсального семейства хэш-функций .
Лемма о композиции [DeSY]. Пусть H1 и Н2 - 2-универсальные семейства, хэш-функций, действующих из C1 в C2 и из С2 в С3 соответственно.
Тогда
Н = {h == h2 о h1 | h1 Î H1, h2 Î H2},
где o обозначает композицию, является 2-универсальным семейством хэш-функции, действующих из C1 в C3.
Нас эти семейства интересуют в основном как инструмент для определения и построения семейств односторонних хэш-функций.
С прикладной точки зрения универсальные семейства хэш-функций должны удовлетворять некоторым дополнительным требованиям.
Во-первых, хэш-функции должны быть эффективно вычислимыми. Часто это требование включают в определение универсального семейства и формализуют следующим образом.
![]()
![]()
![]() У каждой хэш-функции h Î H имеется достаточно короткое описание h и существуют два эффективных алгоритма, первый из
которых по запросу и выдает случайное h Î H, а второй по h аргументу x вычисляет h{x).
У каждой хэш-функции h Î H имеется достаточно короткое описание h и существуют два эффективных алгоритма, первый из
которых по запросу и выдает случайное h Î H, а второй по h аргументу x вычисляет h{x).
Во-вторых, во многих случаях требуются семейства хэш-функций, которые определяются не на строках только данной фиксированной длины, а на строках всех длин (или бесконечной последовательности длин). В этом случае множество Нп, которое действует согласно определению 1 на строках длины п, называют коллекцией хэш-функций, а универсальным семейством называют {Нп}.
В-третьих, для криптографических приложений иногда требуется так называемое свойство доступности коллизий (collision accessibility). Оно требует существования эффективного алгоритма, который по данным х1 и х2 выбирает h Î H такую, что
h(х1) = h(х2), равновероятным образом среди всех функций из Н, удовлетворяющих этому свойству.
Пусть F = GF(2k) и chop: {0,1}k ® {0,1}k-1 - функция, которая просто отбрасывает последний бит. Тогда семейство хэш-функций {chop(ax+b)} является 2-универсальным и удовлетворяет свойству доступности коллизий.
Пусть А = {0,1}n и В {0,1}m. Для х Î {0,1}n и у Î {0,1}n+m-1 определим конволюцию у о х элементов у и х как вектор длины m, i-я координата которого
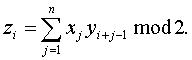 |
определяется по формуле
Тогда семейство H = { (a о х) Å b | a Î {0,1}n+m-1 , b Î {0,1}m} представляет собой универсальное семейство хэш-функций.
Семейства односторонних хэш-функций.
Пусть {n1i} и { n0i} - две возрастающие последовательности натуральных чисел такие) что для всех i n1i ³ n0i и существует такой полином q, что q(n0i,) ³ n1.
(такие последовательности полиномиально связаны).
Пусть Нk - коллекция функций такая, что для всех h Î Hk
![]() и
пусть .
и
пусть .
Предположим, что А - вероятностный алгоритм, работающий за поли-номиальное время, который на входе k выдает строку x Î {0,1}n1k, называемую исходным значением, и затем для данной случайной h Î Hk пытается найти у Î {0,1}n1k такое, что h{x) = h{y), но х ¹ у.
Определение 2. Семейство U называется универсальным семейством односторонних хэш-функций, если для всех полиномов р, для всех полиномиальных вероятностных алгоритмов А и всех достаточно больших k выполняются следующие условия:
x Î {0,1}n1k - исходное значение для А, то
Рг[А(h,x) = у, h{x) - h(y), у ¹ х] < 1/p(n1k),
где вероятность берется по всем h из Hk и по всем случайным выборам алгоритма А.
2. Для любой h Î Hk существует описание h. полиномиальной (от n1k) длины такое, что по этому описанию и по х значение h(x) вычислимо за полиномиальное время.
3. Коллекция Hk доступна, т. е. существует алгоритм G, который на входе k равномерно по вероятности генерирует описание функции h Î Hk .
Заметим, что Hk рассматривается как набор описаний функций: два разных описания могут соответствовать одной и той же функции.
В данном определении А - это машина Тьюринга (однородная модель). Определение универсального семейства односторонних хэш-функций, а котором А - полиномиальная схема (неоднородная модель) формулируется аналогично, но в п. 1 вероятность берется только по выбору h из Hk.
Также заметим, что это семейство называется семейством хэш-функций с трудно обнаружимыми коллизиями.
Алгоритмы построения хэш-функций.
N –хэш.
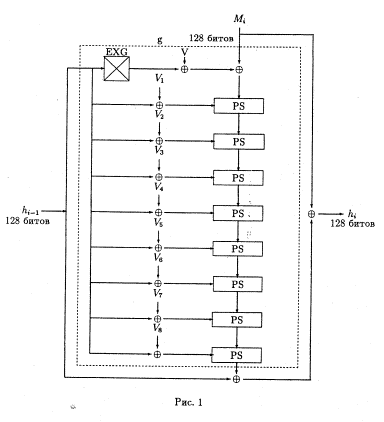
Алгоритм разработан Nippon Telephone & Telegraph. N- хэш использует блоки длинной 128 бит, размешивающую функцию. На вход пошаговой хэш-функции в качестве аргумента поступают очередной блок сообщения Mi длинной 128 бит и хэш-код hi-1 предыдущего шага.
h0 = I, где I – синхропосылка.
hi = g(Mi,hi-1) Å Mi Å hi-1.
Хэш-кодом всего сообщения объявляется хэш-код, получаемый в результате преобразования последнего блока текста.
Функция g вначале меняет местами старшие и младшие части (по 64 бита каждая) хэш-кода предыдущего шага, покоординатно складывая полученное значение с величиной 1010…..1010 и текущим блоком текста Mi. Полученная величина поступает на вход каскада из N (n = 8) преобразующих функций. Вторым аргументом каждой из преобразующих функций является хэш-код предыдущего шага, сложенный покоординатно с одной из восьми констант.
На рисунке 1 использованы следующие условные обозначения:
EXG –старшая и младшая части входного блока меняются местами;
V =1010…1010 (128 бит) в двоичной записи.
Vj = d||Aj1||d||Aj2||d||Aj3||d||Aj4; здесь || обозначает конкатенацию бинарных строк;
d = 00…00 в двоичной записи;
Ajk = 4 * (j-1) + k (k = 1,2,3,4: Ajk длинной 8 бит);
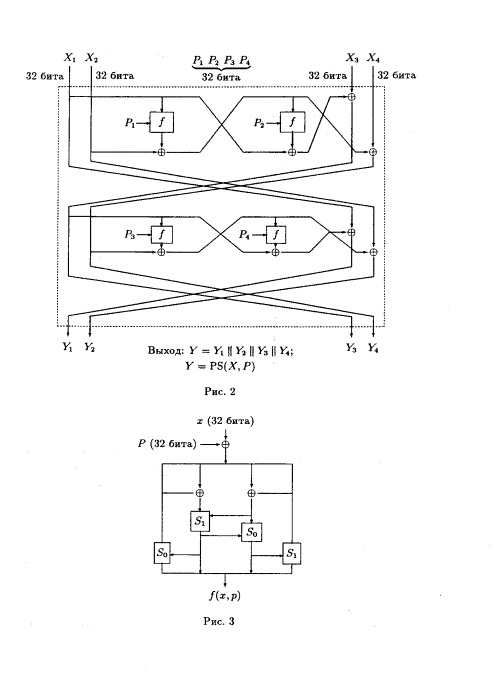
PS – преобразующая функция.
На рисунке 2 представлена схема преобразующей функции. Каждый из аргументов при этом разбивается на 4 блока:X1||X2||X3||X4, P= P1||P2||P3||P4, схема вычисления функции f представлена на рисунке 3.
S0(a,b) = (левый циклический сдвиг на 2 бита) ((a+b)mod256):
S1(a,b) = (левый циклический сдвиг на 2 бита) ((a+b+1)mod256):
Результат действия преобразующей функции PS предыдущего шага становится входным аргументом очередной преобразующей функции PS.
Процесс, показанный на рис.1, завершается покоординатным суммированием по модулю 2 результата действия последней преобразующей функции PS, хэш-кода предыдущего шага и блока хэшируемого текста.
 |
 |
MD5.
В этом алгоритме размер хэш-кода равен 128 битам.
После ряда начальных действий MD5 разбивает текст на блоки длинной 512 битов, которые, в свою очередь делятся на 16 подблоков по 32 бита. Выходом алгоритма являются 4 блока по 32 бита, конкатенация которых образует 128-битовый хэш-код.
Сначала текст дополняется таким образом, чтобы длина получаемого текста, выраженная в битах, стала на 64 меньше числа, кратного 512.
Дополнение осуществляется приписыванием к концу сообщения единицы и затем необходимого числа нулей (в бинарном представлении). Затем к тексту приписывается 64-битовое представление длины исходного сообщения. Таким образом, получается текст, длина которого кратна 512 битам. Инициализируются 4 переменных размером по 32 бита;
А = 01 23 45 67;
В = 89 AB CD EF;
С = FE DC BA 98;
D = 76 54 32 10.
Далее начинает работу основной цикл алгоритма. Основной цикл повторяется столько раз, сколько блоков по 512 битов присутствует в хэшируемом сообщении.
Создаются копии инициализированных переменных: АА для А, ВВ для В, СС для С, DD для D.
Каждый основной цикл состоит из 4 раундов. В свою очередь, каждый раунд состоит из 16 операторов. Все операторы однотипны и имеют вид:
u = v + ((F(v, w, z) + Mj + tj) << Sj).
Здесь: u, v, w и z суть А, В, С и. D в зависимости от номера раунда и номера оператора в раунде.
Mj обозначает j-тый подблок обрабатываемого блока. В каждом раунде порядок обработки очередным оператором подблоков определяется задаваемой в явном виде подстановкой на множестве всех подблоков (их, также как и операторов, 16).
ti обозначают зафиксированные случайные константы, зависящие от номера раунда и номера оператора в раунде.
<<si, обозначает левый циклический сдвиг аргумента на si, битов. Величины сдвигов также зависят от номера раунда и номера оператора в раунде.
F(v,w,z) - некоторая функция (фиксированная для каждого раунда), действующая покоординатно на биты своих трех аргументов..
В первом, раунде действует функция F{X,Y,Z) = XY / (not X)Z.
Во втором раунде действует функция G(X,Y,Z) = XZ / (not Z)Y.
В третьем раунде действует функция Н{Х,Y,Z)Å = ХÅY ÅZ.
В четвертом раунде действует функция I(Х,Y,Z) = YÅ(X / (not Z)).
Функции подобраны таким образом, чтобы при равномерном и независимом распределении битов аргументов выходные биты были бы также распределены равномерно и независимо.
Основной цикл алгоритма завершается суммированием полученных А, В, С и D и накапливаемых АА, ВВ, СС и DD, после чего алгоритм переходит к обработке нового блока данных. Выходом алгоритма является конкатенация получаемых после последнего цикла А, В, С и D.
Схемы хэширования, использующие алгоритмы блочного шифрования.
Идея использовать алгоритм блочного шифрования [Schnr], для построения надежных схем хэширования выглядит естественной. Напрашивается мысль использовать алгоритм блочного шифрования в режиме "с зацеплением" при нулевой синхропосылке.
При этом считать хэш-кодом последний шифрблок. Очевидно, что на роль DES-алгоритма здесь годится произвольный блочный шифр.
Однако при таком подходе возникают две проблемы. Во-первых, размер блока большинства блочных шифров (для DESa — 64 бита) недостаточен для того, чтобы хэш-функция была устойчива против метода на основе парадокса дня рождения. Во-вторых, предлагаемый метод требует задания некоторого ключа, на котором происходит шифрование. В дальнейшем этот ключ необходимо держать в секрете, ибо злоумышленник, зная этот ключ и хэш-значение, может выполнить процедуру в обратном направлении. Следующим шагом в развитии идеи использовать блочный шифр для хэширования является подход, при котором очередной блок текста подается в качестве ключа, а хэш-значение предыдущего шага — в качестве входного блока. Выход алгоритма блочного шифрования является текущим хэш-значением (схема Рабина). Существует масса модификаций этого метода, в том числе хэш-функции, выход которых в два раза длиннее блока.
В ряде модификаций промежуточное хэш-значение суммируется покоординатно по модулю 2 с блоком текста. В этом случае подразумевается, что размер ключа и блока у шифра совпадают. В литературе встречаются 12 различных схем хэширования для случая, когда размер ключа и блока у шифра совпадают:
1) Hi = EMi(Hi-1) Å H i-1 (схема Дэвиса — Мейера);
2) Hi = Енi-1(Мi) Å H i-1 Å Mi (схема Миягучи);
3) Hi = Енi-1(Мi) ÅМi, (схема Матиаса, Мейера, Осиаса);
4) Hi = Енi-1(H i-1 Å Mi) Å H i-1 Å Mi;
5) Hi = Енi-1(H i-1 Å Mi) Å Mi;
6) Hi = ЕMi(Mi Å H i-1) Å MiÅ H i-1;
7) Hi = ЕMi (H i-1) Å MiÅ H i-1;
8) Hi = ЕMi (Mi Å H i-1) Å H i-1;
9) Hi = Енi-1Å Mi(Mi) Å Hi-1;
10) Hi = Енi-1Å Mi(Hi-1) Å Hi-1;
11) Hi = Енi-1Å Mi(Mi) Å Mi;
12) Hi = Енi-1Å Mi(Hi-1) Å Mi;
где Ek(M) обозначает результат применения алгоритма блочного шифрования с ключом k к блоку М.
Во всех подобных схемах полагают Н0 = Iн, где Iн — начальное значение. Для алгоритмов блочного шифрования с размером ключа в два раза большим чем размер шифруемого блока (например, IDEA) в 1992 году была предложена модифицированная схема Дэвиса—Мейера:
Н0 = Iн, где Iн — начальное значение;
Нi = Енi-1,Mi(Hi-1).
Стойкость подобных схем зависит от криптографических и иных свойств алгоритмов блочного шифрования, лежащих в их основе. В частности, даже если алгоритм шифрования является стойким, некоторые из предложенных схем обладают коллизиями [MOI]. К подобным эффектам могут приводить такие свойства алгоритма шифрования как комплиментарность
(шифрование инвертированного открытого текста на инвертированном ключе приводит к инвертированному шифртексту), наличие слабых и полуслабых ключей и т. п.
Еще одной слабостью указанных выше схем хэширования является то, что размер хэш-кода совпадает с размером блока алгоритма шифрования.
Чаще всего размер блока недостаточен для того, чтобы схема была стойкой против атаки на базе "парадокса дня рождения". Поэтому были предприняты попытки построения хэш-алгоритмов на базе блочного шифра с размером хэш-кода в k раз (как правило, k = 2) большим, чем размер блока алгоритма шифрования:
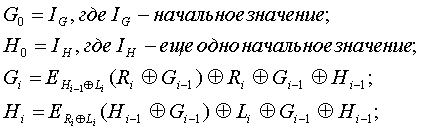 |
Схема Приниля — Босселэра — Гувертса — Вандервалле [PrBGV]
где Li, Ri, — левая и правая половины очередного блока хэшируемого текста. Хэш-кодом является конкатенация последних значений Gi, Hi.
Глава 4. Модернизация электронной подписи Эль Гамаля. Задача дискретного логарифмирования.
Модернизация электронной подписи Эль Гамаля.
Также, как и в обычной схеме, секретный ключ x ÎR Z*p-1 и открытый ключ y = g-x mod p. Пространством сообщений в данной схеме является Zp-1 .
Подписывающие выбирают случайные u1,…un , так, чтобы они были взаимно простые (т.е gcd (un,p-1) = 1).
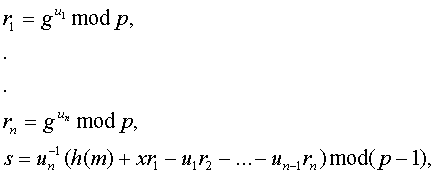 |
Тогда
Подписью в этом случае является набор (r1,…,rn,s) .
![]() Для проверки подписи
(r1,…,rn,s) для сообщения m необходимо сначала проверить
условия r1,…,rn Î Z*p и s Î
Zp-1 . Если хотя бы одно из них ложно, то подпись отвергается. В противном
случае подпись принимается и только тогда, когда .
Для проверки подписи
(r1,…,rn,s) для сообщения m необходимо сначала проверить
условия r1,…,rn Î Z*p и s Î
Zp-1 . Если хотя бы одно из них ложно, то подпись отвергается. В противном
случае подпись принимается и только тогда, когда .
Идея метода состоит в том, что можно подписывать коллективом из n человек, что значительно усложнит задачу раскрытия этой подписи т.к. нам неизвестны все u1,…un .
Задача дискретного логарифмирования.
Задача дискретного логарифмирования – одно из наиболее популярных задач, используемых в целях криптографии. Это объясняется высокой сложностью ее решения в некоторых группах.
Постановка задачи.
Пусть G – некоторая мультипликативно записываемая группа, а a и b – некоторые элементы этой группы, связанные равенством b = an при некотором целом n. Любое целое x, удовлетворяющее уравнению b = ax, называется дискретным логарифмом элемента b по основанию a. Задача дискретного логарифмирования в группе G состоит в отыскании по данным a и b вышеуказанного вида некоторого дискретного логарифма b по основанию a. Если a имеет бесконечный порядок, то дискретный логарифм любого элемента по основанию a определен однозначно. В противном случае все дискретные логарифмы b по основаниям a можно получить из некоторого такого дискретного логарифма x0 по формуле x = x0 + km, где km – порядок элемента a, а параметр k пробегает Z.
Для криптографических приложений наиболее важна задача дискретного логарифмирования в мультипликативных группах конечных полей GF(q) и колец Zn Как известно, группа GF(q)* циклическая и имеет порядок q –1, поэтому если в качестве a берется некоторый порождающий этой группы, то дискретный логарифм любого элемента GF(q)* по основанию a существует и определен однозначно. Если логарифмировать по фиксированному основанию, которое является порождающим g группы GF(q)*, то можно находить дискретные логарифмы по произвольному основанию. Действительно, чтобы найти дискретный логарифм x элемента b по основанию a, достаточно вычислить дискретные логарифмы y и z элементов a и b по основанию a и решить уравнение xy = z(mod q – 1) относительно z. Для краткости обозначим дискретный логарифм y произвольного элемента gÎGF(q)* по основанию a, удовлетворяющий неравенству 0 < y < q – 2, через log. Очевидно, что log – взаимно однозначное отображение GF(q)* на Zq-1, удовлетворяющее обычному свойству логарифма: log gh = (log g + log h) mod (q-1) для произвольных g,h ÎGF(q)*.
Алгоритм Гельфонда.
![]() В настоящее время не известно полиномиальных
алгоритмов дискретного логарифмирования в произвольной группе GF(q)*.
Изложенный ниже алгоритм применим к произвольной группе GF(q)* и имеет
сложность O(q0,5+e)
В настоящее время не известно полиномиальных
алгоритмов дискретного логарифмирования в произвольной группе GF(q)*.
Изложенный ниже алгоритм применим к произвольной группе GF(q)* и имеет
сложность O(q0,5+e)
Положить
Вычислить c = aH .
Построить наборы (cu|uÎ{0,1,…,H}) и (bav|uÎ{0,1,…,H}) элементов GF(q)*.
![]() Найти некоторый
элемент, входящий в оба набора. Если cu = bav – такой элемент, то это значит,
что и log b = (Hu –v) mod (q – 1) –
искомый дискретный логарифм b по основанию a.
Найти некоторый
элемент, входящий в оба набора. Если cu = bav – такой элемент, то это значит,
что и log b = (Hu –v) mod (q – 1) –
искомый дискретный логарифм b по основанию a.
Отметим, что любой элемент xÎ{0,1,…,q-2} представим в виде x = Hu-v при некоторых u,vÎ{0,1,…,H}.Поэтому элемент входящий в оба набора из этапа 3 алгоритма, существуют.
Заключение
Выбор для конкретных ИС должен быть основан на глубоком анализе слабых и сильных сторон тех или иных методов защиты. Обоснованный выбор той или иной системы защиты, в общем-то, должен опираться на какие-то критерии эффективности. К сожалению, до сих пор не разработаны подходящие методики оценки эффективности криптографических систем.
Наиболее простой критерий такой эффективности - вероятность раскрытия ключа или мощность множества ключей. По сути, это то же самое, что и криптостойкость. Для ее численной оценки можно использовать также и сложность раскрытия шифра путем перебора всех ключей.
Однако этот критерий не учитывает других важных требований к криптосистемам:
невозможность раскрытия или осмысленной модификации информации на основе анализа ее структуры,
совершенство используемых протоколов защиты,
минимальный объем используемой ключевой информации,
минимальная сложность реализации (в количестве машинных операций), ее стоимость,
высокая оперативность.
Желательно конечно использование некоторых интегральных показателей, учитывающих указанные факторы.
Часто более эффективным при выборе и оценке криптографической системы является использование экспертных оценок и имитационное моделирование.
В любом случае выбранный комплекс криптографических методов должен сочетать как удобство, гибкость и оперативность использования, так и надежную защиту от злоумышленников циркулирующей в ИС информации.
Автор выражает благодарность своему научному руководителю Блинкову Юрию Анатольевичу за неоценимую помощь в написании данной работы.
Список литературы
Diffie W., Hellman M. E. New directions in cryptography. IEEE transactions on Information Theory IT-22. 1976. 644-654 p.
Buchberger B. Groebner Bases: on Algorithmic Method in Polynomial Ideal Theory. In: Recent Trends in Multidimensional System Theory, Bose, N.K. (ed.), Reidel, Dordrecht. 1985. 184-232 p.
Rivest R. L., Shamir A., Adleman L., method for obtaining digital signatures and public-key cryptosystems, Commun. ACM, v. 21, №2, 1978, 120-126
Rivest R. L., The MD5 messege digest algorythm, RFC 1321, April, 1992
Блинков Ю. А., Мыльцин В. Л. Использование базисов полиномиальных идеалов при построении односторонних функций. В кн.: Современные проблемы теории функций и их приложения.– Саратов: Изд-во Сарат. ун-та, 1997.
| Баричев С. Криптография без секретов | |
|
Баричев С. Криптография без секретов 42 От автора Эта книга - краткое введение в криптографию. С одной стороны, здесь изложен материал, который ... Итак, в реальных системах алгоритм RSA реализуется следующим образом: каждый пользователь выбирает два больших простых числа, и в соответствии с описанным выше алгоритмом выбирает ... Александр генерирует секретный ключ а и вычисляет открытый ключ y = gа mod p. Если Борис хочет послать Александру сообщение m, то он выбирает случайное число k, меньшее p и ... |
Раздел: Рефераты по информатике, программированию Тип: реферат |
| Защита персональных данных с помощью алгоритмов шифрования | |
|
Оглавление Введение Глава I. Криптология 1.1 Шифрование - метод защиты информации 1.2 История развития криптологии 1.3 Криптология в наши дни 1.4 ... Партнер P1, получив В, вычисляет Kx = Bx mod n, а партнер P2 вычисляет Ky = Ay mod n. Алгоритм гарантирует, что числа Ky и Kx равны и могут быть использованы в качестве секретного ... Общедоступными ключами являются y, g и p, а секретным ключом является х. Для подписи сообщения M выбирается случайное число k, которое является простым по отношению к p-1. После ... |
Раздел: Рефераты по информатике, программированию Тип: курсовая работа |
| Криптографические методы защиты информации | |
|
МИНИСТЕРСТВО ОБРАЗОВАНИЯ РОССИЙСКОЙ ФЕДЕРАЦИИ Муниципальное образовательное учреждение "Средняя образовательная школа № 4 с углубленным изучением ... Например, Unix-программа ssh-keygen по умолчанию генерирует ключи длиной 1024 бита).Определим параметр n как результат перемножения р и q. Выберем большое случайное число и назовем ... Алгоритм реализуется в течение 16 аналогичных циклов шифрования, где на I-ом цикле используется цикловой ключ Ki , представляющий собой алгоритмически вырабатываемую выборку 48 ... |
Раздел: Рефераты по информатике, программированию Тип: реферат |
| Розробка імовірнісної моделі криптографічних протоколів | |
|
МІНІСТЕРСТВО ВНУТРІШНІХ СПРАВ УКРАЇНИ НАЦІОНАЛЬНИЙ УНІВЕРСИТЕТ ВНУТРІШНІХ СПРАВ ФАКУЛЬТЕТ управління ТА інформатики КАФЕДРА ЗАХИСТУ ІНФОРМАЦІЇ І ... Дійсно, легко обчислити j(n) = (p - 1)(q - 1), а потім d = e-1 (mod j(n))) Якщо р і q невідомі, то обчислення значення зворотної функції практично неможливе, а знайти p і q по n ... Хай а - відкритий текст, z - ключ, y - шифрований текст, Е(а, z) - криптограма, одержана в результаті шифрування відкритого тексту а на ключі z. |
Раздел: Рефераты по информатике, программированию Тип: дипломная работа |
| Теория остатков | |
|
МИНИСТЕРСТВО ОБРАЗОВАНИЯ РЕСПУБЛИКИ БЕЛАРУСЬ Учреждение образования "Гомельский государственный университет имени Франциска Скорины " Математический ... r = x - yq = ( au 1 + bv 1 ) - ( au 2 + bv 2 ) q = a ( u 1 - u 2 q )+ b ( v 1 - v 2 q ) P . Ну возьмите вы алгоритм Евклида, найдите те самые пресловутые u , v Z такие, что au+vm=1 , умножьте это равенство на b : aub+vmb=b , откуда немедленно следует: aub b(mod m ... |
Раздел: Рефераты по математике Тип: дипломная работа |