Система поддержки принятия маркетинговых решений в торговом предприятии на основе методов Data Mining
Реферат
Дипломная работа: 115 страниц, 31 рисунок, 15 таблиц, 3 приложения, 87 источников.
Объект исследования: товарооборот торгового предприятия, его признаками – показатели его финансово-хозяйственной деятельности (максимальная прибыль и минимальные убытки), а исследуемым свойством – ликвидность товарных остатков на складе.
Цель работы: разработка и внедрение на предприятии оптово-розничной торговли фармацевтическими препаратами оригинальной информационной системы поддержки принятия решений (СППР), позволяющей повысить эффективности хозяйственной деятельности предприятия путем снижения объема статистического учета, уменьшения издержек товарооборота и рационального использования денежных ресурсов.
В качестве СППР применена прогнозирующая система на основе трехслойной нейронной сети, предназначенная для обнаружения скрытых закономерностей потребительского спроса во временных рядах динамики продаж. В задаче прогнозирование рассматривается в целях планирования управления запасами.
Разработанный программный продукт предназначен для использования в составе учетно-аналитической системы программ «1С: Предприятие 7.7» и может быть применен в качестве СППР при осуществлении хозяйственной деятельности, связанной с ведением оптово-розничной торговли. Применение данной системы при планировании закупок повышает эффективность распределения средств и снижает вероятность финансовых потерь, что, в конечном итоге, выражается в положительном экономическом результате.
ОПТОВО-РОЗНИЧНАЯ ТОРГОВЛЯ, ФАРМАЦЕВТИЧЕСКИЙ ПРЕПАРАТ, ПОДДЕРЖКА ПРИНЯТИЯ РЕШЕНИЙ, АНАЛИЗ ДАННЫХ, ПРОГНОЗИРОВАНИЕ ВРЕМЕННЫХ РЯДОВ, НЕЙРОННЫЕ СЕТИ, DATA MINING
Содержание
TOC \o "1-3" Введение................................................................................................................................... PAGEREF _Toc530454717 \h 7
1. аНАЛИЗ ПРОБЛЕМНОЙ ОБЛАСТИ И ПОСТАНОВКА ЗАДАЧИ........................... PAGEREF _Toc530454718 \h 9
1.1 Анализ хозяйственной деятельности торгового фарм. предприятия...................... PAGEREF _Toc530454719 \h 9
1.2 Постановка задачи...................................................................................................... PAGEREF _Toc530454720 \h 11
1.3 Обзор систем и технологий автоматизации процессов принятия решений........ PAGEREF _Toc530454721 \h 12
1.3.1 Технология поддержки и принятия решений.................................................. PAGEREF _Toc530454722 \h 12
1.3.2 Системы поддержки принятия решений.......................................................... PAGEREF _Toc530454723 \h 16
1.3.3 Data Mining........................................................................................................... PAGEREF _Toc530454724 \h 16
1.3.4 Прогнозирующие системы................................................................................. PAGEREF _Toc530454725 \h 16
2. определение проблемы и методы прогнозирования....................... PAGEREF _Toc530454726 \h 16
2.1 Определение проблемы прогнозирования............................................................... PAGEREF _Toc530454727 \h 16
2.2 Анализ методов прогнозирования............................................................................ PAGEREF _Toc530454728 \h 16
2.3 Прогнозирование временных рядов......................................................................... PAGEREF _Toc530454729 \h 16
2.4 Решение задачи применением ИНС......................................................................... PAGEREF _Toc530454730 \h 16
3. Разработка СППР........................................................................................................ PAGEREF _Toc530454731 \h 16
3.1 Общие требования к разрабатываемой системе...................................................... PAGEREF _Toc530454732 \h 16
3.2 Разработка логической структуры СППР................................................................ PAGEREF _Toc530454733 \h 16
3.3 Этапы обработки данных........................................................................................... PAGEREF _Toc530454734 \h 16
3.4 Определение параметров ИНС.................................................................................. PAGEREF _Toc530454735 \h 16
3.5 Разработка программного продукта.......................................................................... PAGEREF _Toc530454736 \h 16
4. Организационно-экономическая часть.................................................. PAGEREF _Toc530454737 \h 16
4.1 Описание характеристик программного продукта................................................. PAGEREF _Toc530454738 \h 16
4.1.1 Характеристика программного продукта......................................................... PAGEREF _Toc530454739 \h 16
4.1.2 Особенности продукта....................................................................................... PAGEREF _Toc530454740 \h 16
4.1.3 Система сервиса.................................................................................................. PAGEREF _Toc530454741 \h 16
4.1.4 Патентная чистота............................................................................................... PAGEREF _Toc530454742 \h 16
4.1.5 Гарантии и защита потребительских качеств.................................................. PAGEREF _Toc530454743 \h 16
4.2 Рынки сбыта................................................................................................................ PAGEREF _Toc530454744 \h 16
4.2.1 Сегментирование рынка по потребителям...................................................... PAGEREF _Toc530454745 \h 16
4.2.2 Параметрическая сегментация рынка............................................................... PAGEREF _Toc530454746 \h 16
4.2.3 Многофакторная сегментация продукта.......................................................... PAGEREF _Toc530454747 \h 16
4.3 Планирование ресурсов............................................................................................. PAGEREF _Toc530454748 \h 16
4.3.1 Материальные ресурсы и оборудование.......................................................... PAGEREF _Toc530454749 \h 16
4.3.2 Расчёт затрат на разработку продукта............................................................... PAGEREF _Toc530454750 \h 16
4.3.3 Расчёт затрат на тиражирование и договорной цены продукта.................... PAGEREF _Toc530454751 \h 16
4.4 Стратегия маркетинга................................................................................................. PAGEREF _Toc530454752 \h 16
4.5 Анализ безубыточности производства и сбыта программного продукта............ PAGEREF _Toc530454753 \h 16
5. Охрана труда.............................................................................................................. PAGEREF _Toc530454754 \h 16
5.1 Анализ условий труда................................................................................................ PAGEREF _Toc530454755 \h 16
5.2 Техника безопасности................................................................................................. PAGEREF _Toc530454756 \h 16
5.3 Производственная санитария и гигиена труда........................................................ PAGEREF _Toc530454757 \h 16
5.4 Меры пожарной профилактики................................................................................. PAGEREF _Toc530454758 \h 16
Выводы..................................................................................................................................... PAGEREF _Toc530454759 \h 16
Перечень ссылок................................................................................................................ PAGEREF _Toc530454760 \h 16
Приложение А. Исходный код библиотеки ActiveX............................ PAGEREF _Toc530454761 \h 16
Приложение Б. Исходный код скрипта подключения библиотеки ActiveX к системе “1C:Предприятие”............................................................................................ PAGEREF _Toc530454762 \h 16
Приложение В. Основные элементы интерфейса пользователя системы……………………………………………………………………………………. PAGEREF _Toc530454763 \h 16
Введение
Современная экономика немыслима без эффективного управления. Управленческая деятельность в современных условиях выступает как один из важнейших факторов функционирования и развития объектов экономики. Эта деятельность постоянно изменяется и совершенствуется в соответствии с объективными требованиями рынка, усложнением хозяйственных связей, новациями в сфере научно-технического прогресса, и повышением роли человеческого фактора.
Успех управления во многом определяется эффективностью принятия интегрированных решений, которые учитывают самые разносторонние факторы и тенденции динамики их развития. В условиях нестабильности ситуации рыночной экономики принятие решений по управлению объектами экономической деятельности является сложнейшей задачей. И если предметом изучения являться основной хозяйствующий субъект экономики – предприятие, в частности, эффективность его деятельности, то вся сложность поставленной задачи вполне очевидна.
Задачи управления требуют умения использовать и обрабатывать большие объемы информации, проводить в различных разрезах и плоскостях ее анализ, моделировать бизнес-процессы и экономические ситуации, а также структурировать и представлять информационный материал для последующего принятия управленческих решений.
Перед лицом, принимающим решение (ЛПР), встает проблема изучения и обобщения всей совокупности факторов, от которых зависит нормальное функционирование рассматриваемой экономической системы. Одна из проблем, с которой сталкивается ЛПР при проведении оперативного анализа деятельности предприятия, заключается в сложности восприятия больших массивов данных, содержащихся в учетных системах. Существенную же роль в процессе принятия решений ЛПР играет оперативность и качество выполнения вышеперечисленных требований, что сегодня представляется затруднительным без применения современных информационных технологий[1] (ИТ), таких как технологии оперативного анализа распределенных данных (OLAP-технологии), сетевые технологии общего доступа, различные статистические пакеты, геоинформационные системы (ГИС-технологии), системы поддержки принятия решений (СППР) и т.п.
Не последнюю роль в улучшении качества принятии решений играют научно-технические новации в области ИТ, а также информация, содержащая новые научные знания, сведения об изобретениях и технических новинках. Это непрерывно пополняемый фонд технических решений и растущий потенциал знаний, практическое и своевременное использование, которого обеспечивает предприятию высокий уровень конкурентоспособности на рынке.
Бизнес-процессы предприятия, включая и процессы принятия решений, можно сделать более производительными, используя соответствующие информационные технологии, существующие уже сегодня. Применение информационной техники прямым образом меняет качество последних, позволяя персоналу предприятия и ЛПР использовать больший объем информации, и устраняет некоторые наиболее трудоемкие операции анализа и принятия решений.
Для успешного решения управленческих проблем используются методы, которые позволяют свести большие массивы информации к небольшому количеству репрезентативных статистических характеристик. А качественная информация, т.е. релевантная, точная и своевременная информация, естественно, является необходимым условием для принятия качественного решения. Улучшение качества информации, имеющейся в момент принятия решения, позволяет ЛПР принять обоснованное, своевременное и правильное решение.
В последние годы сформировалось и активно используется новое направление в области автоматизации управленческого труда – системы поддержки принятия решений.
СППР являются человеко-машинными системами, которые позволяют лицам, принимающим решения, использовать данные, знания, объективные и субъективные модели для анализа и решения неструктурированных и слабо формализуемых задач. Применение методологии поддержки принятия решений даёт возможность: формализовать процесс нахождения решения на основе имеющихся данных (процесс порождения вариантов решения); ранжировать критерии и давать критериальные оценки физическим параметрам, влияющим на решаемую проблему (возможность оценить варианты решений); использовать формализованные процедуры согласования при принятии коллективных решений; использовать формальные процедуры прогнозирования последствий принимаемых решений; выбирать вариант, приводящий к оптимальному решению проблемы.
Однако процессы управления в рамках любого конкретного объекта экономики всегда носят свой специфический характер, определяемый как видом деятельности, так и масштабами решаемых задач. По этой причине готовые тиражируемые решения не всегда полностью соответствуют некоторым параметрам или требованиям конкретного хозяйствующего субъекта, а это зачастую не обеспечивает информационную поддержку принятия решения в полном объеме. Что, в свою очередь, приводит к необходимости разработки оригинальных систем и подсистем, учитывающих специфику внутренних требований.
Настоящая дипломная работа является примером такого применения современных информационных технологий в области управления предприятием. Её целью является построение на основе методов Data Mining модуля системы поддержки принятия маркетинговых решений в торговом предприятии, наиболее полно отвечающей потребностям предприятия и классу решаемых задач.
1.
1.1 хозяйственной деятельности торгового фарм. предприятия
Основным видом хозяйственной деятельности исследуемого объекта экономики является оптовая торговля фармацевтическими препаратами на рынке г. Нью-Васюки, Задунайской и смежных областей. Этот вид хозяйственной деятельности характеризуется наличием трех основных операционных этапов: закупка – хранение – отпуск товара. Обеспечением этой технологической цепи на предприятия занимаются три его отдела: отдел закупок, отдел продаж и склад ( REF _Ref530428480 \h Рис. 1.1). Каждый отдел возглавляется начальником, в подчинении которого находятся менеджеры и технический персонал.
Рис. STYLEREF 1 \s 1. SEQ Рис. \* ARABIC \s 1 1 Структура исследуемого предприятия
Весь процесс документооборота на предприятии автоматизирован. В качестве инструмента информационной поддержки используется компьютеры на базе платформы Intel PIII – PIV и локальная компьютерная сеть технологии Ethernet 10Base–T, объединяющая сервер под управлением операционной системы MS Windows 2000 Server и 10 рабочих станций под управлением MS Windows 2000 Professional, рассредоточенных по отделам. При этом для офисной работы на предприятии используется следующее программное обеспечение: MS Office 2000 и клиент-серверный вариант поставки системы программ «1С: Предприятие 7.7» с комплексной конфигурацией. Основным и единственным хранилищем учетных данных в этом случае является внутренняя база данных учетно-аналитической системы программ «1С: Предприятие 7.7».
Предприятие работает по пятидневной рабочей неделе и ежедневно осуществляет несколько операций закупки и отпуска товара.
Технологический цикл оптово-розничной торговли медикаментами, да и сам фармацевтический сектор экономики имеют свои особенности и специфику.
Специфика рынка медикаментов заключается в том, что на отдельные виды препаратов или их группы спрос подвержен ощутимым колебаниям, связанных с:
·
·
·
·
·
Особенности ведения оптовой или розничной торговли медикаментами таковы, что при осуществлении закупочных операций необходимо учитывать строго определённый срок годности фарм. препаратов и сопоставлять его с периодом реализации запаса последних. Несоблюдение этого требования влечет за собой или значительные финансовые убытки от списания неликвидного товара или издержки правового характера (вплоть до лишения лицензии на торговлю).
Из выше сказанного явствует, что процесс принятия решения о количестве закупаемого препарата того или иного вида является важнейшим этапом в осуществлении этого вида торговой деятельности, а в условиях неопределенности и противоречивости критериев является и архи сложной задачей, решение которой может быть обосновано применением специальных средств прогнозирования и параметрической оптимизации.
Выявление закономерностей покупательного спроса, формируемого неявными и слабо формализуемыми причинами, с помощью традиционных средств статистического учета и применяемой в рамках этого предприятия учетно-аналитической бухгалтерской информационной системы «1С: Предприятие 7.7» является долговременным и трудоемким делом.
Программы системы «1С: Предприятие 7.7» считаются сегодня самым популярным на территории СНГ и стран Балтии средством автоматизации, чем и объясняется её широкое применение. Эта система программ является универсальным средством автоматизации всех видов учета на предприятиях и в организациях всех отраслей и видов собственности. Она содержит всего три основные компоненты: «Бухгалтерський учт», «Оперативный учет» и «Расчет», которые основаны на единой технологической платформе, имеют схожие принципы функционирования и тесно интегрированы друг с другом.
Компонент «Бухгалтерский учёт» ориентирован на решение задач бухгалтерского учета, прежде всего на отражение хозяйственных операций в системе счетов бухгалтерского учета.
Компонент «Расчет» ориентирован на решение задач, требующих выполнения сложных, периодически повторяющихся и взаимосвязанных в динамике расчетов (заработной платы, разного рода компенсаций, расчет стоимости заказов и т.д.).
Компонент «Оперативный учет» является универсальным средством решения задач учета наличия и движения различного рода средств и ресурсов.
Вследствие своей универсальности эта бухгалтерская система программ от фирмы «1С» реализует лишь общие стандартные функции статистического учета и анализа и не учитывает специфики конкретного её применения, что не отвечает в полной мере внутренним потребностям предприятия, специализирующегося на торговле фарм. препаратами. Однако, учитывая особенности внутреннего ценообразования в Совдепии, применение готовых пакетов и компьютерных программ особенно иностранного производства из-за высокой стоимости последних (2000-5000$) экономически не целесообразно. К тому же зачастую эти программы имеют значительно больший объем и вычислительную мощность, нежели это необходимо для решения указанного класса задач внутри предприятия.
В сложившихся обстоятельствах применяемые на предприятии методы ведения статистического учета не соответствует динамике ситуации этого сектора экономики и не способствует оперативному принятию качественных стратегических и тактических решений поведения на рынке. В связи, с чем возникает потребность в разработке своей оригинальной системы поддержки принятия маркетинговых решений, обладающей способностью прогнозировать объемы будущих продаж и предлагать ЛПР варианты наиболее выгодного вложения средств.
Таким образом, целью данной дипломной работы является разработка и внедрение на предприятии оптово-розничной торговли фармацевтическими препаратами оригинальной информационной системы поддержки принятия решений, позволяющей повысить эффективности хозяйственной деятельности предприятия путем снижения объема статистического учета, уменьшения издержек товарооборота и рационального использования денежных ресурсов.
1.2
Исходя из цели данной дипломной работы были поставлены следующие задачи:
·
·
·
·
·
·
·
·
1.3
1.3.1
Характеристика и назначение
Процесс принятия решения – это получение и выбор наиболее оптимальной альтернативы с учетом просчета всех последствий.
При выборе альтернатив – надо выбирать ту, которая наиболее полно отвечает поставленной цели, но при этом приходится учитывать большое количество противоречивых требований и, следовательно, оценивать выбранный вариант решения по многим критериям.
Процесс принятия решения заключается в следующем:
·
·
·
·
·
·
·
Главной особенностью информационной технологии поддержки принятия решений является качественно новый метод организации взаимодействия человека и компьютера. Выработка решения, что является основной целью этой технологии, происходит в результате итерационного процесса ( REF _Ref23260477 \h 1.2
1.
2.
Рис. STYLEREF 1 \s 1. SEQ Рис. \* ARABIC \s 1 2 ИТ поддержки принятия решений как итерационный процесс.
Окончание итерационного процесса происходит по воле человека. В этом случае можно говорить о способности информационной системы совместно с пользователем создавать новую информацию для принятия решений.
Особенностями информационной технологии поддержки принятия решений является ряд ее отличительных характеристик:
·
·
·
·
Информационная технология поддержки принятия решений может использоваться на любом уровне управления. Кроме того, решения, принимаемые на различных уровнях управления, часто должны координироваться. Поэтому важной функцией и систем, и технологий является координация лиц, принимающих решения, как на разных уровнях управления, так и на одном уровне.
Основные компоненты
Рассмотрим структуру системы поддержки принятия решений ( REF _Ref23256802 \h 1.3
Рис. STYLEREF 1 \s 1. SEQ Рис. \* ARABIC \s 1 3 Основные компоненты ИТ поддержки принятия решений.
В состав системы поддержки принятия решений (СППР) входят три главных компоненты: база данных, база моделей и программная подсистема, состоящая из системы управления базой данных (СУБД) и системы управления интерфейсом.
База данных играет роль хранилища информации, используемой непосредственно для расчетов при помощи математических моделей. Основная часть информации поступает от информационной системы операционного уровня.
Помимо данных об операциях предприятия для эффективного функционирования СППР требуются ещё внутренние данные (данные о движении персонала, инженерные данные и т.п.) и данные из внешних источников (данные о конкурентах, национальной и мировой экономике), которые должны быть своевременно собраны, введены и обработаны.
Для эффективного их использования имеются две возможности, предварительной обработки:
1.
2.
Второй вариант более предпочтителен для предприятия, производящих большое количество коммерческих операций. Обработанные данные при этом для повышения надежности и быстрого доступа хранятся обычно в файлах за пределами СППР.
В настоящее время широко исследуется вопрос о включении в базу данных еще одного источника данных – документов, включающих в себя записи, письма, контракты, приказы и т.п. Содержание этих документов, обработанное по ключевым характеристикам (поставщикам, потребителям, датам, видам услуг и др.), становиться новым мощным источником информации.
Система управления данными должна обладать следующими возможностями:
·
·
·
·
·
База моделей. Целью создания моделей являются описание некоторого объекта или процесса. Использование моделей обеспечивает проведение анализа в системах поддержки принятия решений. Модели, базируясь на математической интерпретации проблемы, при помощи определенных алгоритмов способствуют нахождению информации полезной для принятия правильных решений.
По назначению модели подразделяются на системы поддержки генерации решений (СПГР) и системы поддержки выбора решений (СПВР).
СПГР можно разделить на эвристические и оптимизационные. Эвристические модели позволяют находить варианты решений на базе известных правил, принципов и аналогов или описывают поведение процесса. Оптимизационные позволяют находить экстремумы некоторых показателей, и предназначены для целей управления (оптимизации). В оптимизационных СППР используются методы структурного синтеза и параметрической оптимизации.
СПВР предназначены для выбора эффективных вариантов решений, сгенерированных любым из вышеперечисленных методов, либо поступивших извне. Эти системы базируются на методах многокритериального анализа и экспертных оценок.
По способу оценки модели классифицируются на детерминистские, использующие оценку переменных одним числом при конкретных значениях исходных данных, и стохастические, оценивающие переменные несколькими параметрами вследствие того, что исходные данные заданы вероятностными характеристиками.
Ввиду недороговизны детерминистские модели более популярны, чем стохастические, их легче строить и использовать. К тому же часто с их помощью получается вполне достаточная информация для принятия решения.
По области возможных приложений модели разбиваются на специализированные, предназначенные для использования только одной системой, и универсальные – для использования несколькими системами. Специализированные модели обладают большей точностью, более дорогие и применяются обычно для описания уникальных систем.
В СППР база моделей может состоять из стратегических, тактических, оперативных и математических моделей, а также моделей в виде совокупности модельных блоков, модулей и процедур, используемых как элементы для их построения ( REF _Ref23256802 \h 1.3
Стратегические модели используются на высших уровнях управления для установления целей организации, объемов ресурсов, необходимых для их достижения, а также политики приобретения и использования этих ресурсов. Они могут быть также полезны при выборе вариантов размещения предприятий, прогнозировании политики конкурентов и т.п. Для стратегических моделей характерны значительная широта охвата, множество переменных, представление данных в сжатой агрегированной форме. Часто эти данные базируются на внешних источниках и могут иметь субъективный характер. Горизонт планирования в стратегических моделях, как правило, измеряется в годах. Эти модели обычно детерминистские, описательные, специализированные для использования на одной определенной предприятие.
Тактические модели применяются на среднем уровне управления для распределения и контроля использования имеющихся ресурсов (финансовое планирование, планирование требований к работникам, планирование увеличения продаж, построение схем компоновки предприятий). Эти модели применимы обычно лишь к подразделениям предприятия (например, к системе производства и сбыта) и могут также включать в себя агрегированные показатели. Временной горизонт, охватываемый тактическими моделями, – от одного месяца до двух лет. Здесь также могут потребоваться данные из внешних источников, на основное внимание при реализации данных моделей должно быть уделено внутренним данным предприятия. Обычно тактические модели реализуются как детерминистские, оптимизационные и универсальные.
Оперативные модели используются на низших уровнях управления для поддержки принятия оперативных решений с горизонтом, измеряемым днями и неделями. Возможные применения этих моделей включают в себя ведение дебиторских счетов и кредитных расчетов, календарное производственное планирование, управление запасами и, как правило, детерминистские, оптимизационные и универсальные.
Математические модели состоят их совокупности модельных блоков, модулей и процедур, реализующих математические методы. Сюда могут входить процедуры линейного программирования, статистического анализа временных рядов, регрессионного анализа и т.п. Модельные блоки, модули и процедуры могут использоваться как поодиночке, так и комплексно для построения и поддержания моделей.
Система управления базой моделей должна обладать следующими возможностями:
·
·
·
Система управления интерфейсом. Эффективность и гибкость информационной технологии принятия решений во многом зависят от характеристик интерфейса СППР. Интерфейс определяют: способы диалога с пользователем и его знания в предметной области. Совершенствование интерфейса СППР определяется прогрессом в развитии каждого из этих указанных компонентов.
Интерфейс СППР должен обладать следующими возможностями:
·
·
·
·
В настоящее время наиболее распространены следующие формы диалога с пользователем: запросно-ответный режим, командный режим, различные меню, машинная графика, мультипликация, машинная речь и голосовое управление. Каждая форма в зависимости от типа задачи, особенностей пользователя и принимаемого решения может иметь свои достоинства и недостатки.
Для эффективного представления информации, ее визуализации все большее применение получают ГИС-технологии, которые также могут быть успешно использованы на начальной стадии анализа и классификации информации.
Современные геоинформационные системы представляют собой новый класс интегрированных информационных систем, в основу которых заложена технология систем автоматизированного проектирования и интеграции процессов обработки информации на базе географических данных.
Карты позволяют изображать и динамику происходящих событий, т.е. передавать пользователям информацию об обстановке в режиме реального времени
Особое значение имеет принятие идеологии построения слоев (плоскостей) представления частей графического изображения, позволяющих создавать и отображать в одном слое те составляющие изображения, которые имеют единую тематическую направленность.
ГИС, как и другие информационные технологии, подтверждают, что лучшая информированность помогает принять эффективное и более обоснованное решение. Однако, ГИС – это не инструмент для выдачи решений, а средство, повышающее эффективность процедуры принятия решений. Требуемая для принятия решений информация может быть представлена в лаконичной картографической форме с дополнительными текстовыми пояснениями, графиками и диаграммами. Наличие доступной для восприятия и обобщения информации позволяет менеджерам сосредоточить свои усилия на поиске решения, не тратя значительного времени на сбор и осмысливание данных.
1.3.2
Архитектура СППР
Очевидно, что принимаемые решения о стратегии и тактике деятельности и развития субъекта предпринимательской деятельности должны быть тщательно продуманы и обоснованы. В экономических системах это важно, так как принимаемые решения касаются живых людей, их материального и духовного состояния. На сегодняшний день принятие решений ЛПР в основном базируется на личном опыте и интуиции.
Экономические системы сложны, и их поведение трудно предсказать из-за наличия огромного количества прямых и обратных связей, часто неочевидных с первого взгляда. Человек не способен справиться с задачей такой размерности, с чем и возникла необходимость обеспечить информационно-аналитическую поддержку принятия решений. Сравнительный анализ вариантов решений (различных прогнозов, стратегий развития и т.д.) становится невозможным без компьютерных систем поддержки принятия решений.
Системы поддержки принятия решений и соответствующая им информационная технология появились усилиями в основном американских ученых в конце 70-х – начале 80-х гг., чему способствовали широкое распространение персональных компьютеров, стандартных пакетов прикладных программ, а также успехи в создании систем искусственного интеллекта.
Концепция СППР включает целый ряд средств, объединенных общей целью – способствовать принятию рациональных и эффективных управленческих решений.
Система поддержки принятия решений – это диалоговая автоматизированная система, использующая правила принятия решений и соответствующие модели с базами данных, а также интерактивный компьютерный процесс моделирования. Она предназначена для решения задач классификации большого количества вариантов (альтернатив) или выбора из них наилучших вариантов на основе информации, получаемой от лица, принимающего решения.
Основу СППР составляют комплекс взаимосвязанных моделей с соответствующей информационной поддержкой исследования, интеллектуальные и экспертные системы, включающие опыт решения задач управления и обеспечивающие участие коллектива экспертов в процессе выработки рациональных решений.
В СППР используются современные методы математической теории принятия решений, позволяющие обрабатывать не только количественную, но и качественную информацию. Применяемые методы обеспечивают:
1.
2.
3.
Схема движения информационных потоков при использовании СППР представлена на REF _Ref23268452 \h 1.4
Рис. STYLEREF 1 \s 1. SEQ Рис. \* ARABIC \s 1 4 Схема движения информационных потоков при использовании СППР.
Зачастую СППР обладают свойством универсальности и могут быть адаптированы к решению различных задач, характеризующихся следующими особенностями:
·
·
·
Условиями такой адаптации являются обеспечение доступа к данным, а также разработка и ввод в систему методик сравнения альтернатив.
Основными этапами работы ЛПР с системой являются:
·
·
·
·
·
·
·
·
На REF _Ref23265014 \h 1.5
Рис. STYLEREF 1 \s 1. SEQ Рис. \* ARABIC \s 1 5 Архитектурно-технологическая схема СППР
Первоначально информация хранится в оперативных базах данных OLTP-систем. Агрегированная информация организуется в многомерное хранилище данных. Затем она используется в процедурах многомерного анализа (OLAP) и для интеллектуального анализа данных (ИАД).
Хранилища данных
Любое принятие решений должно основываться на реальных данных об объекте управления. Такая информация обычно хранится в оперативных базах данных OLTP-систем. Эти оперативные данные не подходят для целей анализа, так как для анализа и принятия стратегических решений в основном нужна агрегированная информация. Кроме того, для целей анализа необходимо иметь возможность быстро манипулировать информацией, представлять ее в различных аспектах, производить различные нерегламентированные запросы к ней, что затруднительно реализовать на оперативных данных по соображениям производительности и технологической сложности. Решением данной проблемы является создание отдельного хранилища данных, содержащего агрегированную информацию в удобном виде.
Актуальность проблемы хранения и быстрого поиска данных привела к появлению такого понятия как Data Warehouse – Хранилище данных (ХД). Создание единых Хранилищ данных предполагает использование технологий статистической обработки данных для их предварительного анализа, определения состава и структуры тематических рубрик.
Целью построения хранилища данных является интеграция, актуализация и согласование оперативных данных из разнородных источников для формирования единого непротиворечивого взгляда на объект управления в целом. При этом в основе концепции хранилищ данных лежит признание необходимости разделения наборов данных, используемых для транзакционной обработки, и наборов данных, применяемых в системах поддержки принятия решений. Такое разделение возможно путем интеграции разъединенных в различных системах обработки данных (СОД) и внешних источниках детализированных данных в едином хранилище, их согласования и агрегации.
Эффективность использования Хранилища достигается внедрением новейших технологий для сбора, структуризации, хранения, организации доступа, обновления и защиты данных.
Концепция хранилищ данных предполагает не просто единый логический взгляд на данные организации, а действительную реализацию единого интегрированного источника данных. Альтернативным по отношению к этой концепции способом формирования единого взгляда на корпоративные данные является создание виртуального источника, опирающегося на распределенные базы данных различных СОД. При этом каждый запрос к такому источнику динамически транслируется в запросы к исходным базам данных, а полученные результаты на лету согласовываются, связываются, агрегируются и возвращаются к пользователю. Однако, при внешней элегантности, такой способ обладает рядом существенных недостатков.
Время обработки запросов к распределенному хранилищу значительно превышает соответствующие показатели для централизованного хранилища. Кроме того, структуры баз данных СОД, рассчитанные на интенсивное обновление одиночных записей, в высокой степени нормализованы, поэтому в аналитическом запросе к ним требуется объединение большого числа таблиц, что также приводит к снижению быстродействия.
Интегрированный взгляд на распределенное корпоративное хранилище возможен только при выполнении требования постоянной связи всех источников данных в сети. Таким образом, временная недоступность хотя бы одного из источников может либо сделать работу информационно-аналитической системы (ИАС) невозможной, либо привести к ошибочным результатам.
Выполнение сложных аналитических запросов над таблицами СОД потребляет большой объем ресурсов сервера БД и приводит к снижению быстродействия СОД, что недопустимо, так как время выполнения операций в СОД часто весьма критично.
Различные СОД могут поддерживать разные форматы и кодировки данных, данные в них могут быть несогласованны. Очень часто на один и тот же вопрос может быть получено несколько вариантов ответа, что может быть связано с асинхронностью моментов обновления данных, отличиями в трактовке отдельных событий, понятий и данных, изменением семантики данных в процессе развития предметной области, ошибками при вводе, утерей фрагментов архивов и т. д. В таком случае цель – формирование единого непротиворечивого взгляда на объект управления – может не быть достигнута.
Главным же недостатком является практическая невозможность обзора длительных исторических последовательностей, ибо при физическом отсутствии центрального хранилища доступны только те данные, которые на момент запроса есть в реальных БД связанных СОД. Основное назначение СОД – оперативная обработка данных, поэтому они не могут позволить себе роскошь хранить данные за длительный (более нескольких месяцев) период; по мере устаревания данные выгружаются в архив и удаляются из транзакционной БД. Что касается аналитической обработки, для нее как раз наиболее интересен взгляд на объект управления в исторической ретроспективе.
Таким образом, хранилище данных функционирует по следующему сценарию. По заданному регламенту в него собираются данные из различных источников – баз данных систем оперативной обработки. В хранилище поддерживается хронология: наравне с текущими хранятся исторические данные с указанием времени, к которому они относятся. В результате необходимые доступные данные об объекте управления собираются в одном месте, приводятся к единому формату, согласовываются и, в ряде случаев, агрегируются до минимально требуемого уровня обобщения.
На основе хранилища данных возможно составление отчетности для руководства, анализ данных с помощью OLAP-технологий и интеллектуальный анализ данных (Data Mining).
OLAP-технологии
Разработка Хранилища невозможна без использования технологий оперативного анализа распределенных данных (OLAP-технологий), которая обеспечивает построение многомерных моделей базы данных, иерархическое представление информации, выполнение сложных аналитических расчетов, динамическое изменение структуры отчета, обновление базы данных.
В основе концепции оперативной аналитической обработки (OLAP) лежит многомерное представление данных. Термин OLAP ввел в 1993 году E. F. Codd. В своей статье он рассмотрел недостатки реляционной модели (в первую очередь невозможность объединять, просматривать и анализировать данные с точки зрения множественности измерений, то есть самым понятным для корпоративных аналитиков способом) и определил общие требования к системам OLAP, расширяющим функциональность реляционных СУБД и включающим многомерный анализ как одну из своих характеристик.
По Кодду, многомерное концептуальное представление (multi-dimensional conceptual view) является наиболее естественным взглядом управляющего персонала на объект управления. Оно представляет собой множественную перспективу, состоящую из нескольких независимых измерений, вдоль которых могут быть проанализированы определенные совокупности данных. Одновременный анализ по нескольким измерениям данных определяется как многомерный анализ. Каждое измерение включает направления консолидации данных, состоящие из серии последовательных уровней обобщения, где каждый вышестоящий уровень соответствует большей степени агрегации данных по соответствующему измерению. Так, измерение «исполнитель» может определяться направлением консолидации, состоящим из уровней обобщения «предприятие – подразделение – отдел – служащий», а измерение «время» может даже включать два направления консолидации – «год – квартал – месяц – день» и «неделя – день», поскольку счет времени по месяцам и по неделям несовместим. В этом случае становится возможным произвольный выбор желаемого уровня детализации информации по каждому из измерений.
Операция спуска (drilling down) соответствует движению от высших ступеней консолидации к низшим и, напротив, операция подъема (rolling up) означает движение от низших уровней к высшим.
Интеллектуальный анализ данных
Наибольший интерес в СППР представляет интеллектуальный анализ данных, так как он позволяет провести наиболее полный и глубокий анализ проблемы, дает возможность обнаружить скрытые взаимосвязи, принять наиболее обоснованное решение.
Современный уровень развития аппаратных и программных средств с некоторых пор сделал возможным повсеместное ведение баз данных оперативной информации на разных уровнях управления. В процессе своей деятельности промышленные предприятия, корпорации, ведомственные структуры, органы государственной власти и местного самоуправления накопили большие объемы данных. Они хранят в себе большие потенциальные возможности по извлечению полезной аналитической информации, на основе которой можно выявлять скрытые тенденции, строить стратегию развития, находить новые решения.
Интеллектуальный анализ данных (Data Mining) – это процесс поддержки принятия решений, основанный на поиске в данных скрытых закономерностей (шаблонов информации). При этом накопленные сведения автоматически обобщаются до информации, которая может быть охарактеризована как знания.
В общем случае процесс ИАД состоит из трёх стадий:
I.
II.
III.
Новыми компьютерными технологиями, образующими ИАД являются экспертные и интеллектуальные системы, методы искусственного интеллекта, базы знаний, базы данных, компьютерное моделирование, нейронные сети, нечеткие системы. Современные технологии ИАД позволяют создавать новое знание, выявляя скрытые закономерности, прогнозируя будущее состояние систем.
Основным методом моделирования экономического развития предприятия является метод имитационного моделирования, который позволяет исследовать структуру предприятия с помощью экспериментального подхода. Это дает возможность на модели проиграть различные стратегии развития, сравнить альтернативы, учесть влияние многих факторов, в том числе с элементами неопределенности.
Перспективно применение в СППР комбинированных методов принятия решений в сочетании с методами искусственного интеллекта и компьютерным моделированием, различные имитационно-оптимизационные процедуры, принятие решений в сочетании с экспертными процедурами.
1.3.3
Основы технологии Data Mining
В основу современной технологии Data Mining[2] (discovery-driven data mining) положена концепция шаблонов (паттернов), отражающих фрагменты многоаспектных взаимоотношений в данных [ REF _Ref24994646 \r \h подвыборкам данных, которые могут быть компактно выражены в понятной человеку форме. Важное положение технологии – нетривиальность разыскиваемых шаблонов. Это означает, что найденные шаблоны должны отражать неочевидные, неожиданные (unexpected) регулярности в данных, составляющие так называемые скрытые знания (hidden knowledge). Выявлено, что сырые данные (raw data) могут содержать глубинный пласт знаний, при грамотной раскопке которого могут быть обнаружены необходимые закономерности. Поиск шаблонов производится методами, не ограниченными рамками априорных предположений о структуре выборке и виде распределений значений анализируемых показателей.
Выделяют пять стандартных типов закономерностей, которые позволяют выявлять методы Data Mining: ассоциация, последовательность, классификация, кластеризация и прогнозирование.
Ассоциация имеет место в том случае, если несколько событий связаны друг с другом. Например, исследование, проведенное в супермаркете, может показать, что 65% купивших кукурузные чипсы берут также и "кока-колу", а при наличии скидки за такой комплект "колу" приобретают в 85% случаев. Располагая сведениями о подобной ассоциации, менеджерам легко оценить, насколько действенна предоставляемая скидка.
Если существует цепочка связанных во времени событий, то говорят о последовательности. Так, например, после покупки дома в 45% случаев в течение месяца приобретается и новая кухонная плита, а в пределах двух недель 60% новоселов обзаводятся холодильником.
С помощью классификации выявляются признаки, характеризующие группу, к которой принадлежит тот или иной объект. Это делается посредством анализа уже классифицированных объектов и формулирования некоторого набора правил.
Кластеризация отличается от классификации тем, что сами группы заранее не заданы. С помощью кластеризации средства Data Mining самостоятельно выделяют различные однородные группы данных.
Основой для всевозможных систем прогнозирования служит историческая информация, хранящаяся в БД в виде временных рядов. Если удается построить найти шаблоны, адекватно отражающие динамику поведения целевых показателей, есть вероятность, что с их помощью можно предсказать и поведение системы в будущем.
Классы систем Data Mining
Data Mining является мульти-дисциплинарной областью, возникшей и развивающейся на базе достижений прикладной статистики, распознавания образов, методов искусственного интеллекта, теории баз данных и др. Возникновение различных классов Data Mining ( REF _Ref23500739 \h Рис. 1.6) связано с новым витком в развитии средств и методов обработки данных.
Рис. STYLEREF 1 \s 1. SEQ Рис. \* ARABIC \s 1 6 Классы систем Data Mining.
Отсюда обилие методов и алгоритмов, реализованных в различных действующих системах Data Mining. Многие из таких систем интегрируют в себе сразу несколько подходов. Тем не менее, как правило, в каждой системе имеется какая-то ключевая компонента, на которую делается главная ставка.
Статистические пакеты
Последние версии почти всех известных статистических пакетов включают наряду с традиционными статистическими методами также элементы Data Mining. Но основное внимание в них уделяется все же классическим методикам – корреляционному, регрессионному, факторному анализу и другим. Детальный обзор пакетов для статистического анализа приведен на страницах Центрального экономико-математического института http://is1.cemi.rssi.ru/ruswin/publication/ep97001t.php.
Недостатком систем этого класса считают требование к специальной подготовке пользователя. Также отмечают, что мощные современные статистические пакеты являются слишком "тяжеловесными" для массового применения в финансах и бизнесе. К тому же часто эти системы весьма дороги – от $1000 до $15000.
Есть еще более серьезный принципиальный недостаток статистических пакетов, ограничивающий их применение в Data Mining. Традиционные методы математической статистики оказались полезными главным образом для проверки заранее сформулированных гипотез (verification-driven data mining) и для “грубого” разведочного анализа, составляющего основу оперативной аналитической обработки данных (online analytical processing, OLAP), в которой главными фигурантами служат усредненные характеристики выборки. Эти характеристики при исследовании реальных сложных жизненных феноменов часто являются фиктивными величинами. Концепция усреднения по выборке – есть основное ограничение этих методов, приводящее к операциям над фиктивными величинами. Большинство же методов, входящих в состав пакетов опираются на статистическую парадигму.
Сравнительный анализ целевых задач при использовании методов OLAP и Data Mining приведен в REF _Ref23510440 \h 1.1
Таблица STYLEREF 1 \s 1. SEQ Таблица \* ARABIC \s 1 1 Примеры формулировок задач при использовании методов OLAP и Data Mining
|
OLAP |
Data Mining |
|
Каковы средние показатели травматизма для курящих и некурящих? |
Встречаются ли точные шаблоны в описаниях людей, подверженных повышенному травматизму? |
|
Каковы средние размеры телефонных счетов существующих клиентов в сравнении со счетами бывших клиентов (отказавшихся от услуг телефонной компании)? |
Имеются ли характерные портреты клиентов, которые, по всей вероятности, собираются отказаться от услуг телефонной компании? |
|
Какова средняя величина ежедневных покупок по украденной и не украденной кредитной карточке? |
Существуют ли стереотипные схемы покупок для случаев мошенничества с кредитными карточками? |
В качестве примеров наиболее мощных и распространенных статистических пакетов можно назвать SAS (компания SAS Institute), SPSS (SPSS), STATGRAPICS (Manugistics), STATISTICA, STADIA и другие.
Системы рассуждений на основе аналогичных случаев
Идея систем case based reasoning (CBR) – на первый взгляд крайне проста. Для того чтобы сделать прогноз на будущее или выбрать правильное решение, эти системы находят в прошлом близкие аналоги наличной ситуации и выбирают тот же ответ, который был для них правильным. Поэтому этот метод еще называют методом "ближайшего соседа" (nearest neighbour). В последнее время распространение получил также термин memory based reasoning, который акцентирует внимание, что решение принимается на основании всей информации, накопленной в памяти.
Системы CBR показывают неплохие результаты в самых разнообразных задачах. Главным их минусом считают то, что они вообще не создают каких-либо моделей или правил, обобщающих предыдущий опыт, – в выборе решения они основываются на всем массиве доступных исторических данных, поэтому невозможно сказать, на основе каких конкретно факторов CBR системы строят свои ответы.
Другой минус заключается в произволе, который допускают системы CBR при выборе меры "близости". От этой меры самым решительным образом зависит объем множества прецедентов, которые нужно хранить в памяти для достижения удовлетворительной классификации или прогноза [ REF _Ref24994867 \r \h
Примеры систем, использующих CBR, – KATE tools (Acknosoft, Франция), Pattern Recognition Workbench (Unica, США).
Алгоритмы ограниченного перебора
Алгоритмы ограниченного перебора были предложены в середине 60-х годов М.М. Бонгардом для поиска логических закономерностей в данных. С тех пор они продемонстрировали свою эффективность при решении множества задач из самых различных областей.
Эти алгоритмы вычисляют частоты комбинаций простых логических событий в подгруппах данных. Примеры простых логических событий: X = a; X < a; X > a; a < X < b и др., где X – какой либо параметр, “a” и “b” – константы. Ограничением служит длина комбинации простых логических событий. На основании анализа вычисленных частот делается заключение о полезности той или иной комбинации для установления ассоциации в данных, для классификации, прогнозирования и пр.
Наиболее ярким современным представителем этого подхода является система WizWhy предприятия WizSoft. Хотя автор системы Абрахам Мейдан не раскрывает специфику алгоритма, положенного в основу работы WizWhy, по результатам тщательного тестирования системы были сделаны выводы о наличии здесь ограниченного перебора (изучались результаты, зависимости времени их получения от числа анализируемых параметров и др.).
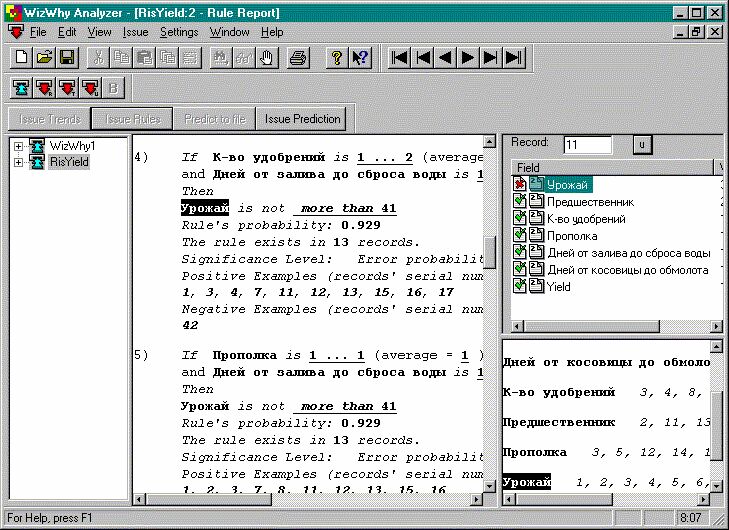{kind=link}
Рис. STYLEREF 1 \s 1 SEQ Рис. \* ARABIC \s 1 7 Система WizWhy обнаружила правила, объясняющие низкую урожайность некоторых сельскохозяйственных участков
Автор WizWhy утверждает, что его система обнаруживает все логические if-then правила в данных. На самом деле это, конечно, не так. Во-первых, максимальная длина комбинации в if-then правиле в системе WizWhy равна 6, и, во-вторых, с самого начала работы алгоритма производится эвристический поиск простых логических событий, на которых потом строится весь дальнейший анализ. Поняв эти особенности WizWhy, нетрудно было предложить простейшую тестовую задачу, которую система не смогла вообще решить. Другой момент – система выдает решение за приемлемое время только для сравнительно небольшой размерности данных.
Тем не менее, система WizWhy является на сегодняшний день одним из лидеров на рынке продуктов Data Mining. Это не лишено оснований. Система постоянно демонстрирует более высокие показатели при решении практических задач, чем все остальные алгоритмы. Стоимость системы около $ 4000, количество продаж – 30000.
Деревья решений (decision trees)
Деревья решения являются одним из наиболее популярных подходов к решению задач Data Mining. Они создают иерархическую структуру классифицирующих правил типа "ЕСЛИ... ТО..." (if-then), имеющую вид дерева. Для принятия решения, к какому классу отнести некоторый объект или ситуацию, требуется ответить на вопросы, стоящие в узлах этого дерева, начиная с его корня. Вопросы имеют вид "значение параметра A больше x?". Если ответ положительный, осуществляется переход к правому узлу следующего уровня, если отрицательный – то к левому узлу; затем снова следует вопрос, связанный с соответствующим узлом.
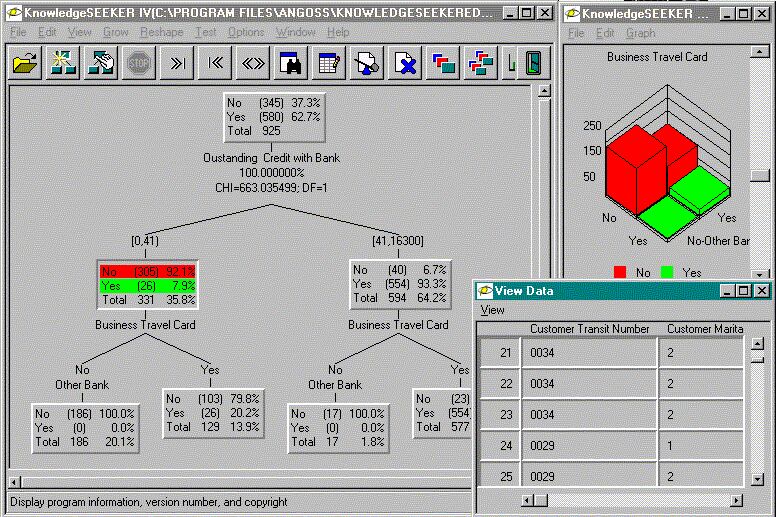{kind=link}
Рис. STYLEREF 1 \s 1 SEQ Рис. \* ARABIC \s 1 8 Система KnowledgeSeeker обрабатывает банковскую информацию
Популярность подхода связана как бы с наглядностью и понятностью. Но деревья решений принципиально не способны находить “лучшие” (наиболее полные и точные) правила в данных. Они реализуют наивный принцип последовательного просмотра признаков и “цепляют” фактически осколки настоящих закономерностей, создавая лишь иллюзию логического вывода.
Вместе с тем, большинство систем используют именно этот метод. Самыми известными являются See5/С5.0 (RuleQuest, Австралия), Clementine (Integral Solutions, Великобритания), SIPINA (University of Lyon, Франция), IDIS (Information Discovery, США), KnowledgeSeeker (ANGOSS, Канада). Стоимость этих систем варьируется от 1 до 10 тыс. долл.
Эволюционное программирование
Проиллюстрируем современное состояние данного подхода на примере системы PolyAnalyst – отечественной разработке, получившей сегодня общее признание на рынке Data Mining. В данной системе гипотезы о виде зависимости целевой переменной от других переменных формулируются в виде программ на некотором внутреннем языке программирования. Процесс построения программ строится как эволюция в мире программ (этим подход немного похож на генетические алгоритмы). Когда система находит программу, более или менее удовлетворительно выражающую искомую зависимость, она начинает вносить в нее небольшие модификации и отбирает среди построенных дочерних программ те, которые повышают точность. Таким образом система "выращивает" несколько генетических линий программ, которые конкурируют между собой в точности выражения искомой зависимости. Специальный модуль системы PolyAnalyst переводит найденные зависимости с внутреннего языка системы на понятный пользователю язык (математические формулы, таблицы и пр.).
Другое направление эволюционного программирования связано с поиском зависимости целевых переменных от остальных в форме функций какого-то определенного вида. Например, в одном из наиболее удачных алгоритмов этого типа – методе группового учета аргументов (МГУА) зависимость ищут в форме полиномов. В настоящее время из продающихся в России систем МГУА реализован в системе NeuroShell компании Ward Systems Group.
Стоимость систем до $ 5000.
Генетические алгоритмы
Data Mining не основная область применения генетических алгоритмов. Их нужно рассматривать скорее как мощное средство решения разнообразных комбинаторных задач и задач оптимизации. Тем не менее генетические алгоритмы вошли сейчас в стандартный инструментарий методов Data Mining, поэтому они и включены в данный обзор.
Первый шаг при построении генетических алгоритмов – это кодировка исходных логических закономерностей в базе данных, которые именуют хромосомами, а весь набор таких закономерностей называют популяцией хромосом. Далее для реализации концепции отбора вводится способ сопоставления различных хромосом. Популяция обрабатывается с помощью процедур репродукции, изменчивости (мутаций), генетической композиции. Эти процедуры имитируют биологические процессы. Наиболее важные среди них: случайные мутации данных в индивидуальных хромосомах, переходы (кроссинговер) и рекомбинация генетического материала, содержащегося в индивидуальных родительских хромосомах (аналогично гетеросексуальной репродукции), и миграции генов. В ходе работы процедур на каждой стадии эволюции получаются популяции со все более совершенными индивидуумами.
Генетические алгоритмы удобны тем, что их легко распараллеливать. Например, можно разбить поколение на несколько групп и работать с каждой из них независимо, обмениваясь время от времени несколькими хромосомами. Существуют также и другие методы распараллеливания генетических алгоритмов.
Генетические алгоритмы имеют ряд недостатков. Критерий отбора хромосом и используемые процедуры являются эвристическими и далеко не гарантируют нахождения “лучшего” решения. Как и в реальной жизни, эволюцию может “заклинить” на какой-либо непродуктивной ветви. И, наоборот, можно привести примеры, как два неперспективных родителя, которые будут исключены из эволюции генетическим алгоритмом, оказываются способными произвести высокоэффективного потомка. Это особенно становится заметно при решении задач высокой размерности со сложными внутренними связями.
Примером может служить система GeneHunter фирмы Ward Systems Group. Его стоимость – около $1000.
Искусственные нейронные сети
Это большой класс систем, архитектура которых имеет аналогию с построением нервной ткани, состоящей из биологической клеток – нейронов. В одной из наиболее распространенных архитектур, многослойном персептроне с обратным распространением ошибки, имитируется работа нейронов в составе иерархической сети, где каждый нейрон более высокого уровня соединен своими входами с выходами нейронов нижележащего слоя ( REF _Ref23519944 \h 1.9
Рис. STYLEREF 1 \s 1. SEQ Рис. \* ARABIC \s 1 9 Двухслойная нейронная сеть без обратных связей
На нейроны самого нижнего слоя подаются значения входных параметров, на основе которых нужно принимать какие-то решения, прогнозировать развитие ситуации и т. д. Эти значения рассматриваются как сигналы, передающиеся в следующий слой, ослабляясь или усиливаясь в зависимости от числовых значений (весов), приписываемых межнейронным связям. В результате на выходе нейрона самого верхнего слоя вырабатывается некоторое значение, которое рассматривается как ответ – реакция всей сети на введенные значения входных параметров. Для того чтобы сеть можно было применять в дальнейшем, ее прежде надо "натренировать" на полученных ранее данных, для которых известны и значения входных параметров, и правильные ответы на них. Тренировка состоит в подборе весов межнейронных связей, обеспечивающих наибольшую близость ответов сети к известным правильным ответам.
Основным недостатком парадигмы ИНС является необходимость иметь очень большой объем обучающей выборки. Другой существенный недостаток заключается в том, что даже натренированная нейронная сеть представляет собой черный ящик. Знания, зафиксированные как веса нескольких сотен межнейронных связей, совершенно не поддаются анализу и интерпретации человеком (известные попытки дать интерпретацию структуре настроенной ИНС выглядят неубедительными – система “KINOsuite-PR”).
Примеры нейросетевых систем – BrainMaker (CSS), NeuroShell (Ward Systems Group), OWL (HyperLogic), Statistica Neural Networks (StatSoft). Стоимость их довольно значительна: $1500–8000.
Системы для визуализации многомерных данных
В той или иной мере средства для графического отображения данных поддерживаются всеми системами Data Mining. Вместе с тем, весьма внушительную долю рынка занимают системы, специализирующиеся исключительно на этой функции. Примером здесь может служить программа DataMiner 3D словацкой фирмы Dimension5 (5-е измерение) REF _Ref23520948 \h 1.10
Рис. STYLEREF 1 \s 1. SEQ Рис. \* ARABIC \s 1 10 Визуализация данных системой DataMiner 3D
В подобных системах основное внимание сконцентрировано на дружелюбности пользовательского интерфейса, позволяющего ассоциировать с анализируемыми показателями различные параметры диаграммы рассеивания объектов (записей) базы данных. К таким параметрам относятся цвет, форма, ориентация относительно собственной оси, размеры и другие свойства графических элементов изображения. Кроме того, системы визуализации данных снабжены удобными средствами для масштабирования и вращения изображений. Стоимость систем визуализации может достигать нескольких сотен долларов.
Бизнес-приложения Data Mining
Сфера применения Data Mining не имеет ограничений [ REF _Ref24994882 \r \h Data Mining играют ведущую роль. Особенность этих областей заключается в их сложной системной организации. Они относятся главным образом к надкибернетическому уровню организации систем [ REF _Ref24994902 \r \h REF _Ref24994913 \r \h стационарны и часто отличаются высокой размерностью.
Сегодня методы Data Mining заинтриговали и коммерческие предприятия, развертывающие проекты на основе информационных хранилищ данных. Опыт многих таких предприятий показывает, что отдача от использования Data Mining может достигать 1000%. Например, известны сообщения об экономическом эффекте, в 10–70 раз превысившем первоначальные затраты от 350 до 750 тыс. дол. [ REF _Ref24994932 \r \h Data Mining в сети универсамов в Великобритании.
Data Mining представляют большую ценность для руководителей и аналитиков в их повседневной деятельности. С применением методов Data Mining можно получить ощутимые преимущества в конкурентной борьбе.
Розничная торговля
Предприятия розничной торговли сегодня собирают подробную информацию о каждой отдельной покупке, используя кредитные карточки с маркой магазина и компьютеризованные системы контроля. Вот типичные задачи, которые можно решать с помощью Data Mining в сфере розничной торговли:
· анализ покупательской корзины (анализ сходства) предназначен для выявления товаров, которые покупатели стремятся приобретать вместе. Знание покупательской корзины необходимо для улучшения рекламы, выработки стратегии создания запасов товаров и способов их раскладки в торговых залах;
· исследование временных шаблонов помогает торговым предприятиям принимать решения о создании товарных запасов;
· создание прогнозирующих моделей дает возможность торговым предприятиям узнавать характер потребностей различных категорий клиентов с определенным поведением, например, покупающих товары известных дизайнеров или посещающих распродажи. Эти знания нужны для разработки точно направленных, экономичных мероприятий по продвижению товаров.
Банковское дело
Достижения технологии Data Mining используются в банковском деле для решения следующих распространенных задач:
· выявление мошенничества с кредитными карточками. Путем анализа прошлых транзакций, которые впоследствии оказались мошенническими, банк выявляет некоторые стереотипы такого мошенничества.
· сегментация клиентов. Разбивая клиентов на различные категории, банки делают свою маркетинговую политику более целенаправленной и результативной, предлагая различные виды услуг разным группам клиентов.
· прогнозирование изменений клиентуры. Data Mining помогает банкам строить прогнозные модели ценности своих клиентов, и соответствующим образом обслуживать каждую категорию.
Телекоммуникации
В области телекоммуникаций методы Data Mining помогают компаниям более энергично продвигать свои программы маркетинга и ценообразования, чтобы удерживать существующих клиентов и привлекать новых. Среди типичных мероприятий отметим следующие:
· анализ записей о подробных характеристиках вызовов. Назначение такого анализа – выявление категорий клиентов с похожими стереотипами пользования их услугами и разработка привлекательных наборов цен и услуг;
· выявление лояльности клиентов. Data Mining можно использовать для определения характеристик клиентов, которые, один раз воспользовавшись услугами данной компании, с большой долей вероятности останутся ей верными. В итоге средства, выделяемые на маркетинг, можно тратить там, где отдача больше всего.
Страхование
Страховые компании в течение ряда лет накапливают большие объемы данных. Здесь обширное поле деятельности для методов Data Mining:
· выявление мошенничества. Страховые компании могут снизить уровень мошенничества, отыскивая определенные стереотипы в заявлениях о выплате страхового возмещения, характеризующих взаимоотношения между юристами, врачами и заявителями;
· анализ риска. Путем выявления сочетаний факторов, связанных с оплаченными заявлениями, страховщики могут уменьшить свои потери по обязательствам. Известен случай, когда в США крупная страховая компания обнаружила, что суммы, выплаченные по заявлениям людей, состоящих в браке, вдвое превышает суммы по заявлениям одиноких людей. Компания отреагировала на это новое знание пересмотром своей общей политики предоставления скидок семейным клиентам.
Медицина
Известно много экспертных систем для постановки медицинских диагнозов. Они построены главным образом на основе правил, описывающих сочетания различных симптомов различных заболеваний. С помощью таких правил узнают не только, чем болен пациент, но и как нужно его лечить. Правила помогают выбирать средства медикаментозного воздействия, определять показания – противопоказания, ориентироваться в лечебных процедурах, создавать условия наиболее эффективного лечения, предсказывать исходы назначенного курса лечения и т. п. Технологии Data Mining позволяют обнаруживать в медицинских данных шаблоны, составляющие основу указанных правил.
Молекулярная генетика и генная инженерия
Пожалуй, наиболее остро и вместе с тем четко задача обнаружения закономерностей в экспериментальных данных стоит в молекулярной генетике и генной инженерии. Здесь она формулируется как определение так называемых маркеров, под которыми понимают генетические коды, контролирующие те или иные фенотипические признаки живого организма. Такие коды могут содержать сотни, тысячи и более связанных элементов.
На развитие генетических исследований выделяются большие средства. В последнее время в данной области возник особый интерес к применению методов Data Mining. Известно несколько крупных фирм, специализирующихся на применении этих методов для расшифровки генома человека и растений.
Прикладная химия
Методы Data Mining находят широкое применение в прикладной химии (органической и неорганической). Здесь нередко возникает вопрос о выяснении особенностей химического строения тех или иных соединений, определяющих их свойства. Особенно актуальна такая задача при анализе сложных химических соединений, описание которых включает сотни и тысячи структурных элементов и их связей.
Предметно-ориентированные аналитические системы
Предметно-ориентированные аналитические системы очень разнообразны. Наиболее широкий подкласс таких систем, получивший распространение в области исследования финансовых рынков, носит название "технический анализ". Он представляет собой совокупность нескольких десятков методов прогноза динамики цен и выбора оптимальной структуры инвестиционного портфеля, основанных на различных эмпирических моделях динамики рынка. Эти методы часто используют несложный статистический аппарат, но максимально учитывают сложившуюся своей области специфику (профессиональный язык, системы различных индексов и пр.). На рынке имеется множество программ этого класса. Как правило, они довольно дешевы (обычно $300–1000).
1.3.4
Прогноз и цели его использования
Ключевым моментом принятия решения в управлении экономическим объектом является прогнозирование. Прогноз – это предсказание будущих событий. Целью прогнозирования является уменьшение риска при принятии решения.
Конечная эффективность любого решения зависит от последовательности событий, возникающих уже после принятия решения. Возможность предсказать неуправляемые аспекты этих событий перед принятием решения позволяет сделать наилучший выбор. Поэтому системы планирования и управления, обычно, реализуют функцию прогноза.
Польза прогноза в улучшении принимаемых решений зависит от горизонта прогнозирования и формы прогноза также как и от его точности. При этом прибыль должна измеряться для всей системы управления как единого целого, и прогнозирование – только один элемент этой системы.
Прогнозирующая система должна выполнять две основные функции: генерацию прогноза и управление прогнозом.
Генерация прогноза включает получение данных для уточнения модели прогнозирования, проведение прогнозирования, учет мнения экспертов и предоставление результатов прогноза ЛПР. Управление прогнозом включает в себя наблюдение процесса прогнозирования для определения неконтролируемых условий и поиск возможности для улучшения производительности прогнозирования. Важным компонентом функции управления является тестирование путевого сигнала. Функция управления прогнозом также должна периодически определять производительность прогнозирования и предоставлять результаты соответствующему менеджеру. Соотношения между генерацией прогноза и управлением прогнозом показано на Рис. 1.11.
SHAPE \* MERGEFORMAT
|
Генерация прогноза |
|
Управление прогнозом |
|
Мнение ЛПР |
|
Прогноз |
|
Модифицированный прогноз |
|
Исторические данные |
|
Текущие наблюдения |
Рис. STYLEREF 1 \s 1. SEQ Рис. \* ARABIC \s 1 11 Соотношения между генерацией прогноза и управлением прогнозом.
Как правило, прогноз имеет некоторую неточность. Ошибка зависит от используемой прогнозирующей системы. С увеличением затрачиваемых на прогноз ресурсов растет и его точность, а убытки, связанные с неопределенностью при принятии решений, снижаются. Стоимость прогноза увеличивается по мере того, как уменьшаются убытки от неопределенности ( REF _Ref23700752 \h 1.12
Концептуальный поход, проиллюстрированный на REF _Ref23700752 \h 1.12
SHAPE \* MERGEFORMAT
|
оптимум |
|
затраты |
|
уровень ошибки |
|
стоимость прогнозирования |
|
стоимость ошибки |
|
общая стоимость |
Рис. STYLEREF 1 \s 1. SEQ Рис. \* ARABIC \s 1 12 График иллюстрирующий соотношение и эффективность затрат на прогнозирование.
Конечно, стоимость является важным элементом при оценке и сравнении методов прогнозирования. Ее можно разделить на одноразовые затраты на разработку и установку системы и затраты на ее эксплуатацию. Что касается затрат на эксплуатацию, то разные прогнозирующие процедуры могут очень сильно отличаться по стоимости получения данных, эффективности вычислений и уровню действий, необходимых для поддержания системы.
Поскольку прогнозирование никогда не сможет полностью устранить риск при принятии решений, необходимо явно определять неточность прогноза. Обычно, принимаемое решение определяется результатами прогноза с учетом возможной ошибки прогнозирования. Можно также сравнивать методы прогнозирования с точки зрения реакции на постоянные изменения во временной последовательности, описывающей процесс, и стабильности при случайных и кратковременных изменениях.
Это предполагает, что прогнозирующая система должна обеспечивать определение ошибки прогнозирования, также как и само прогнозирование. Такой подход значительно снижает риск объективно связанный с процессом принятия решений.
Необходимо отметить, что прогнозирование это не конечная цель. Прогнозирующая система это часть большой системы менеджмента и как подсистема, она взаимодействует с другими компонентами системы, играя немалую роль в получаемом результате.
Примеры ситуаций [ REF _Ref24994948 \r \h
Управление материально-производственными запасами
В управлении запасами запасных частей на ремонтном предприятии совершенно необходимо оценить степень используемости каждой детали. На основе этой информации определяется необходимое количество запасных частей. Кроме того, необходимо оценить ошибку прогнозирования. Эта ошибка может быть оценена, например, на основе данных о времени, которое понадобилось для доставки деталей, которых не было на складе.
Планирование производства
Для того, чтобы планировать производство семейства продуктов, возможно, необходимо спрогнозировать продажу для каждого наименования продукта, с учетом времени доставки, на несколько месяцев вперед. Эти прогнозы для конечных продуктов могут быть потом преобразованы в требования к полуфабрикатам, компонентам, материалам, рабочим и т.д. Таким образом, на основании прогноза может быть построен график работы целой группы предприятий.
Финансовое планирование
Финансового менеджера интересует, как будет изменяться денежный оборот компании с течением времени. Менеджер, может пожелать узнать, в какой период времени в будущем оборот компании начнет падать, с тем, чтобы принять соответствующее решение уже сейчас.
Разработка расписания персонала
Менеджер почтовой компании должен знать прогноз количества обрабатываемых писем, с тем, чтобы обработка производилась в соответствии с расписанием персонала и производительностью оборудования.
Планирование нового продукта
Решение о разработке нового продукта обычно требует долговременного прогноза того, каким спросом он будет пользоваться. Этот прогноз не менее важен, чем определение инвестиций необходимых для его производства.
Управление технологическим процессом
Прогнозирование также может быть важной частью систем управления технологическими процессами. Наблюдая ключевые переменные процесса и используя их для предсказания будущего поведения процесса, можно определить оптимальное время и длительность управляющего воздействия. Например, некоторое воздействие в течение часа может повышать эффективность химического процесса, а потом оно может снижать эффективность процесса. Прогнозирование производительности процесса может быть полезно при планировании времени окончания процесса и общего расписания производства.
2.
2.1
Результаты прогнозирования используются для поддержки принятия решений. Следовательно, природа принимаемых решений определяет большинство желаемых характеристик прогнозирующей системы. Изучение предметной области должно помочь найти ответы на вопросы о том, что нужно прогнозировать, какую форму должен принять прогноз, какие временные элементы включаются и какова желательная точность прогноза.
Первый аспект проблемы прогнозирования связан с тем, что при определении предмета прогнозирования, указываются переменные, которые анализируются и предсказываются. Здесь очень важен требуемый уровень детализации, на который влияет множество факторов: базис прогнозирования, доступность и точность данных, стоимость анализа и предпочтения ЛПР. Если требуется разнородная результирующая информация нельзя однозначно выбрать анализируемые переменные. В ситуациях, когда наилучший набор переменных неясен, необходимо пробовать разные альтернативы и выбрать один из вариантов, дающий наилучшие результаты. Обычно так осуществляется выбор при разработке прогнозирующих систем, основанных на анализе исторических данных.
Точность прогноза, требуемая для конкретной проблемы, оказывает огромное влияние на прогнозирующую систему. Важнейшей характеристикой системы управления является ее способность добиваться оптимальности при работе с неопределенностью.
Посредством данных, необходимых для прогнозирующей системы, в систему может подаваться и ошибка, поэтому необходимо редактировать входные данные системы для того, чтобы устранить очевидные или вероятные ошибки. Конечно, небольшие ошибки идентифицировать будет невозможно, но они обычно не оказывают значительного влияния на прогноз. Более значительные ошибки легче найти и исправить. Прогнозирующая система также не должна реагировать на необычные, экстраординарные наблюдения.
Второй важный аспект проблемы прогнозирования – это определение следующих трех параметров: периода прогнозирования, горизонта прогнозирования и интервала прогнозирования. Период прогнозирования – это основная единица времени, на которую делается прогноз. Горизонт прогнозирования – это число периодов в будущем, которые покрывает прогноз. Наконец, интервал прогнозирования – частота, с которой делается новый прогноз. Часто интервал прогнозирования совпадает с периодом прогнозирования. В этом случае прогноз пересматривается каждый период, используя требование за последний период и другую текущую информацию в качестве базиса для пересматриваемого прогноза. Если горизонт всегда имеет одну и ту же длину (Т-периодов) и прогноз пересматривается каждый период, то говорят, что прогноз осуществляется на основе движущего горизонта. В этом случае, репрогнозируется требование для Т-1 периода и делаем оригинальный прогноз для периода Т.
Выбор периода и горизонта прогнозирования обычно диктуется условиями принятия решений в области, для которой производится прогноз. Для того чтобы прогнозирование имело смысл, горизонт прогнозирования должен быть не меньше, чем время, необходимое для реализации решения принятого на основе прогноза. Таким образом, прогнозирование очень сильно зависит от природы принимаемого решения. В некоторых случаях, время, требуемое на реализацию решения, не определено. Существует методы работы в условиях подобной неопределенности, но они повышают вариацию ошибки прогнозирования. Поскольку с увеличением горизонта прогнозирования точность прогноза, обычно, снижается, часто мы можем улучшить процесс принятия решения, уменьшив время, необходимое на реализацию решения и, следовательно, уменьшив горизонт и ошибку прогнозирования.
Интервал прогнозирования часто определяется операционным режимом системы обработки данных, которая обеспечивает информацию о прогнозируемой переменной. В том случае, если уровень продаж сообщается ежемесячно, возможно для еженедельного прогноза продаж этих данных недостаточно и интервал прогнозирования месяц – является более обоснованным. При определении интервала прогнозирования необходимо выбирать между риском не идентифицировать изменения в прогнозируемом процессе и стоимостью прогноза. Если используется значительный период прогнозирования, то можно работать достаточно длительное время в соответствии с планами, основанными на, возможно, уже бессмысленном прогнозе. С другой стороны, если используется более короткий интервал, то приходиться оплачивать не только стоимость прогнозирования, но и затраты на изменение планов, с тем, чтобы они соответствовали новому прогнозу. Наилучший интервал прогнозирования зависит от стабильности процесса, последствий использования неправильного прогноза, стоимости прогнозирования и репланирования.
Третьим аспектом прогнозирования является требуемая форма прогноза. Обычно при прогнозировании проводится оценка ожидаемого значения переменной, плюс оценка вариации ошибки прогнозирования или промежутка, на котором сохраняется вероятность содержания реальных будущих значений переменной. Этот промежуток называется предсказуемым интервалом.
В некоторых случаях не так важно предсказание конкретных значений прогнозируемой переменной, как предсказание значительных изменений в ее поведении. Такая задача возникает, например, при управлении технологическими процессами, когда необходимо предсказывать момент перехода процесса в неуправляемое состояние.
Существует ряд других факторов, которые также необходимо принимать во внимание при рассмотрении проблемы прогнозирования.
Один из них связан с процессом, генерирующим переменную. Если известно, что процесс стабилен, или существуют постоянные условия, или изменения во времени происходит медленно – прогнозирующая система для такого процесса может достаточно сильно отличаться от системы, которая должна производить прогнозирование неустойчивого процесса с частыми фундаментальными изменениями. В первом случае, необходимо активное использование исторических данных для предсказания будущего, в то время как во втором лучше сосредоточиться на субъективной оценке и прогнозировании для определения изменений в процессе.
Еще один фактор – это доступность данных. Исторические данные необходимы для построения прогнозирующих процедур; будущие наблюдения служат для проверки прогноза. Количество, точность и достоверность этой информации важны при прогнозировании. Кроме этого необходимо исследовать представительность этих данных.
И, наконец, два важных фактора проблемы прогнозирования – возможности и интерес людей, которые делают и используют прогноз. В идеале, историческая информация анализируется автоматически, и прогноз представляется ЛПР для возможной модификации. Введение эксперта в процесс прогнозирования является очень важным, но требует сотрудничества опытных менеджеров. Далее прогноз передается ЛПР, которые используют его при принятии решений и могут получить реальную пользу от его использования.
Необходимо также отметить вычислительные ограничения прогнозирующих систем. Если изредка прогнозируется несколько переменных, то в системе возможно применение более глубоких процедур анализа, чем если необходимо часто прогнозировать большое число переменных. В последней ситуации, необходимо большое внимание уделить разработке эффективного управления данными.
2.2
Методы прогнозирования можно разделить на два класса квалитативные и квантитативные, в зависимости от того, какие математические методы используются.
Квалитативные процедуры производят субъективную оценку, основанную на мнении экспертов. Обычно, это формальная процедура для получения обобщенного предсказывания, на основе ранжирования и обобщения мнения экспертов. Эти процедуры основываются на опросах, тестах, оценке эффективности продаж и исторических данных, но процесс, с помощью которого получается прогноз остается субъективным.
С другой стороны, квантитативные процедуры прогнозирования явно объявляют – каким образом получен прогноз. Четко видна логика и понятны математические операции. Эти методы производят исследование исторических данных для того, чтобы определить глубинный процесс, генерирующий переменную и, предположив, что процесс стабилен, использовать знания о нем для того, чтобы экстраполировать процесс в будущее. К квантитативным процедурам прогнозирования относятся методы, основанные на статистическом анализе, анализе временных последовательностей, байесовском прогнозировании, наборе фрактальных методов, нейронных сетях.
Используется два основных типа моделей: модели временных последовательностей и причинные модели.
Временные последовательности – это упорядоченные во времени последовательности наблюдений (реализаций) переменной. Переменная наблюдается через дискретные промежутки времени.
Анализ временных последовательностей включает описание процесса или феномена, который генерирует последовательность, и использует для прогнозирования переменной только исторические данные об ее изменении. Для предсказания временных последовательностей, необходимо представить поведение процесса в виде математической модели, которая может быть распространена в будущем. Для этого необходимо, чтобы модель хорошо представляла наблюдения в любом локальном сегменте времени, близком к настоящему. Обычно нет необходимости иметь модель, которая представляла бы очень старые наблюдения, так как они не характеризуют настоящий момент. Также нет необходимости представлять наблюдения в далеком будущем, т.е. через промежуток времени больший, чем горизонт прогнозирования. После того, как будет сформирована корректная модель для обработки временной последовательности, можно разрабатывать соответствующие средства прогнозирования.
Большинство моделей прогнозирования временных последовательностей разрабатываются для представления этих вариантов последовательностей: константных, тренда, периодических (циклических), или их комбинаций.
Кроме этих моделей существуют их варианты, появляющиеся, когда в процессе, генерирующем переменную, возникают глубинные изменения. Например:
·
·
·
Так как эти три типа изменений достаточно часто встречаются на практике, то необходимо, чтобы прогнозирующая система идентифицировала постоянные изменения и подстраивала модель прогнозирования под изменения в процессе.
Причинные модели используют связь между интересующей временной последовательностью и одной или более другими временными последовательностями. Если эти другие переменные коррелируют с предметной переменной и если существуют причины для этой корреляции, модели прогнозирования, описывающие эти отношения, могут быть очень полезными. В этом случае, зная значение коррелирующих переменных, можно построить модель прогноза зависимой переменной.
Серьезным ограничением использования причинных моделей является требование того, чтобы независимая переменная была известна ко времени, когда делается прогноз.
Другое ограничение причинных методов – большое количество вычислений и данных, которое необходимо сравнивать.
Практически, прогнозирующие системы часто используют комбинацию квантитативных и квалитативных методов. Квантитативные методы используются для последовательного анализа исторических данных и формирование прогноза. Это придает системе объективность и позволяет эффективно организовать обработку исторических данных. Данные прогноза далее становятся входными данными для субъективной оценки опытными менеджерами, которые могут модифицировать прогноз в соответствии с их взглядами на информацию и их восприятие будущего.
На выбор соответствующего метода прогнозирования, влияют следующие факторы:
1)
2)
3)
4)
5)
6)
7)
8)
Полезным средством при оценке различных методов прогнозирования является симуляция. Метод симуляции основан на ретроспективном использовании исторических данных. Для каждого метода прогнозирования берется некоторая точка в прошлом и, начиная с нее, вплоть до текущего момента времени проводится симуляция прогнозирования. Измеренная ошибка прогнозирования может быть использована для сравнения методов прогнозирования. Если предполагается, что будущее отличается от прошлого, может быть создана псевдоистория, основанная на субъективном взгляде на будущую природу временной последовательности, и использована при симуляции.
2.3 Прогнозирование временных рядов
Фундаментальное предположение о временном ряде
Наблюдаются величины X = X(t), X(t) = (x1(t), x2(t), K, … , xp(t))T, p ≥ 1, и Y = Y(t), Y(t) = (y1(t), y2(t), K, … , yq(t))T, q ≥ 0, в дискретные моменты времени t1 < t2 < K < tk < K.
Обычно рассматривается ситуация, когда наблюдения производятся через равные промежутки времени. В этом случае можно записать: t1 = t0 + 1 ∙ ∆t, t1 = t0 + 2 ∙ ∆t, t1 = t0 + k ∙ ∆t и т.д., где t0 – некоторый начальный момент времени, ∆t – минимальный промежуток времени между наблюдениями.
Задача прогнозирования временного ряда заключается в том, чтобы по его известному участку {ti, X(ti), Y(ti)}Ti =1 оценить будущие значения величины X.
Прежде чем перейти к непосредственному решению данной задачи, необходимо сформулировать ряд фундаментальных предположений о природе временного ряда, в рамках которых можно будет применять ту или иную схему прогнозирования:
·
·
·
·
Разложение временного ряда на компоненты
Одно из направлений анализа временных рядов связано с разложением его на компоненты при изучении причин, порождающих изменения. В общем виде временной ряд можно искусственно разложить на следующие составляющие: скачки, тренд, периодические колебания относительно тренда с различной размерностью, случайные помехи и шумы. После исключения из временного ряда скачков, тренда и периодических компонент его можно описать стационарным процессом и применить хорошо развитые квантитативные методы анализа стационарных временных рядов, идея которых состоит в следующем.
Один и тот же предиктор (№1) с разной точностью моделирует разные участки временного ряда. В то же время существует другой предиктор (№2), который на одних участках временного ряда предсказывает лучше, чем предиктор №1, а на других – хуже или так же. Так можно задать целый набор предикторов, которые будут иметь свои особенности. Для прогнозирования выбирается состоящий из последних нескольких значений этого ряда предиктор, который лучше остальных спрогнозирует некоторый участок временного ряда. При правильной настройке системы можно добиться лучшего качества прогнозирования по сравнению с каждым предиктором из заданного набора в отдельности.
Иллюстрация этого подхода представлена на REF _Ref24713978 \h 2.1
Рис. STYLEREF 1 \s 2. SEQ Рис. \* ARABIC \s 1 1 Разложение временного ряда на компоненты
Здесь предиктор №1 имеет вид a1 ∙ sin(a2t + a3) + a4, где a1, K, a4 – настроечные коэффициенты, которые для каждого отдельного участка временного ряда рассчитываются отдельно. Предиктор №2 имеет вид a1t + a2, где a1, a2 – коэффициенты, настраиваемые по аналогичной схеме. Символами «№1» и «№2» обозначены участки временного ряда, на которых предиктор с соответствующим номером имеет лучшие прогнозирующие свойства.
Две основные проблемы, которые необходимо решить при разложении временного ряда на компоненты, заключаются в определении набора предикторов и правила выбора одного из них для прогнозирования некоторого участка временного ряда. Обычно эти проблемы для реальных временных рядов решаются эмпирически.
Предикторы
Ключевым в задаче прогнозирования является понятие «адаптивный предиктор». Предиктором F называется любая вычислительная схема, которая позволяет по значениям одних параметров (входных) получать значения других (выходных).
В качестве выходных задаются те параметры, значения которых нужно спрогнозировать, т. е. в нашем случае это – будущие значения временного ряда. Если, кроме входных параметров, для расчета также используются настроечные коэффициенты, то такой предиктор называют адаптивным. Его применяют тогда, когда имеется некоторый поток данных, к которому нужно постоянно адаптировать работу предиктора. Один из способов, чтобы сделать это, заключается в изменении значений набора настроечных коэффициентов, производимом с помощью некоторой процедуры настройки.
Набор входных и выходных параметров определяет тип предиктора. Если в качестве входных параметров используются значения предыстории временного ряда, то предиктор называется авторегрессионным, например предиктор: где параметр d определяет глубину предыстории или количество элементов временного ряда, используемых для предсказания его будущего значения. Если в качестве аргумента предиктора используется параметр времени t, то предиктор называется трендовым, например: .
Это — наиболее распространенные типы предикторов. Остальные типы предикторов будем относить к категории «другие». Классификация предикторов приведена на REF _Ref24716712 \h 2.2
Рис. STYLEREF 1 \s 2. SEQ Рис. \* ARABIC \s 1 2 Классификатор предикторов
По определенным признакам все адаптивные предикторы можно объединить в семейства и классы. Семейство представляет некоторую наиболее общую закономерность, например: многочлены, сплайны, нейронные сети, рациональные функции и т. д. Семейство состоит из множества классов, каждый из которых представляет конкретный вид зависимости для данного семейства; при этом каждый класс может рассматриваться в качестве нового семейства, которое также может состоять из классов.
Семейства предикторов, с помощью которых с заданной точностью можно аппроксимировать любую непрерывную функцию, называются семействами универсальных предикторов. К таким семействам можно отнести: многочлены, рациональные функции, сплайны, нейронные сети. Во всех случаях имеет место последовательность вложенных семейств: для многочленов – по степени, для рациональных функций – по максимальной степени числителя и знаменателя, для сплайнов – по числу узлов, для нейронных сетей – по числу нейронов. Данный способ формирования зависимостей может быть положен в основу классификационной схемы семейств адаптивных предикторов.
К семействам адаптивных предикторов, которые могут быть использованы для решения задачи предсказания временного ряда относятся: линейные тренды, квадратичные тренды, тренды k-го порядка, линейные авторегрессионные предикторы, квадратичные авторегрессионные предикторы, авторегрессионные предикторы k-го порядка, нейронные сети и другие адаптивные предикторы. К последней группе принадлежат все предикторы, не вошедшие в перечисленный выше список.
На предиктор могут накладываться ограничения, например, ограничения в виде набора неравенств на значения настроечных коэффициентов предиктора; ограничения на применение процедуры настройки предиктора (настройка допускается только на заданном участке временного ряда, во всех остальных случаях – настроечные коэффициенты не меняются, даже если процедура настройки активирована).
Для прогнозирования будущих значений временного ряда используется процедура прогнозирования. С ней тесно связаны такие понятия, как «глубина прогноза» и «горизонт прогнозирования». Разность времени между моментами начала прогнозирования и его концом будем называть глубиной прогноза. Глубину, при которой прогноз производится с заданной точностью, будем называть горизонтом прогнозирования. Наиболее просто процедура прогнозирования выглядит для трендовых предикторов – в качестве аргумента предиктора нужно указать момент времени, на который требуется получить прогноз, например для момента времени T + 1 прогноз вычисляется следующим образом:
(2.1)
При решении задачи прогнозирования временного ряда адаптивным предиктором активно применяется процедура настройки, или обучения [ REF _Ref24994959 \r \h выборку – таблицу, в которой одна часть столбцов описывает значения входных параметров, а другая – значения выходных параметров. Строку такой таблицы называют примером, который обозначают парой (xk, yk), где k – номер примера в выборке 1 ≤ k ≤ N, N – объем выборки, yk – значения выходных параметров, xk – значения входных параметров. Требуется, чтобы предиктор по значениям входных параметров с заданной точностью предсказывал значения выходных параметров для всех примеров выборки. Различают три вида выборок: обучающая, валидационная и тестовая. Первая используется для обучения предиктора, вторая — для выбора его оптимальной архитектуры и/или момента остановки обучения. Наконец, третья, которая вообще не использовалась в обучении, служит для контроля качества прогноза обученного предиктора.
Рассмотрим некоторый адаптивный предиктор: . Настройка этого предиктора F на заданную выборку производится путем подбора настроечных коэффициентов , при этом для определения качества работы предиктора на обучающей выборке будем использовать функцию оценки H, или, просто оценку. В этом случае задача поиска оптимального набора настроечных коэффициентов сводится к оптимизационной задаче: минимизации функции оценки H на обучающей выборке. Перечислим некоторые виды оценок, которые могут быть применены для настройки предикторов:
·
· ε. Оценки с люфтом ε, где ε – требуемая точность, позволяют прекращать оптимизацию, если достигнута заданная величина невязок;
· εi, зависящими от номера выходного сигнала;
·
·
·
В процессе настройки требуется оценить работу предиктора на всей выборке. Для этого на основе отдельных оценок формируется оценка всей выборки. Для этого может применяться простое суммирование:
(2.2)
или его обобщение — суммирование с весами:
(2.3)
где wk ≥ 0 – вес k-го примера.
Веса wk используются для управления вкладом каждого примера в целевое решение и могут применяться в следующих случаях:
1. Примеры выборки имеют различную информативность.
2. Неравнозначность примеров, представленных в выборке.
Аналогичные оценки могут быть использованы для оценки работы предиктора на валидационной и тестовой выборках. Решением оптимизационной задачи будет набор настроечных коэффициентов из множества допустимых значений A, обеспечивающих глобальный минимум функции H().
Затем обученный предиктор проверяется на тестовой выборке и делается вывод о качестве предсказания. Качество прогноза предиктором временного ряда во многом зависит от обучающей выборки, функции оценки и используемого семейства адаптивных предикторов, поэтому проблемы их выбора являются одними из наиболее важных.
Совокупность предиктора, ограничений, процедуры настройки и прогнозирования называется предикторной схемой, обозначается символом «П» и описывать следующим образом:
П = (φ, ПН, ПП, ОП) (2.4)
где φ – предиктор, ПН – процедура настройки, ПП –процедура прогнозирования, ОП – ограничения предиктора.
Прогнозирование значений временного ряда
Общая схема прогнозирования временного ряда содержит два этапа: подготовительный и основной. На первом этапе происходит сбор информации о предсказывающих свойствах каждой из предикторных схем, а на втором – прогнозирование участка временного ряда предикторной схемой, которая показала лучшие предсказывающие свойства.
Подготовительный и основной этапы представлены соответственно на REF _Ref530358275 \h 2.3
SHAPE \* MERGEFORMAT
|
да |
|
t > T |
|
Определение набора предикторных схем Ф = {П1, П2, Пγ } |
|
t : = t + 1 |
|
Прогнозирование временного ряда |
|
Настройка набора предикторных схем на участок |
|
t : = 1 |
|
нет |
|
Подготовительный этап |
|
t : = T |
|
Выбор предикторной схемы для прогнозирования П = ПравилоВыбора(Ф, Х, |
|
Вывод результатов прогнозирования |
|
Настройка предикторных схем на участок |
|
Прогнозирование временного ряда |
|
t : = t + 1 |
|
Завершить? |
|
да |
|
нет |
|
Основной этап |
Рис. STYLEREF 1 \s 2. SEQ Рис. \* ARABIC \s 1 3 Схема подготовительного и основного этапов
Для определения предикторной схемы с лучшими предсказывающими свойствами используется правило выбора. Это правило на основе реальных и прогнозных значений временного ряда оценивает работу (согласно некоторому критерию H) каждой предикторной схемы из набора Ф, а затем выбирает лучшую из них. Предикторная схема, выбранная с помощью данного правила, называется ведущей. Используем следующее правило: для прогнозирования временного ряда в момент времени t будет применяться предикторная схема с минимальным значением критерия H на данный момент; если таких схем несколько, то выбирается любая из них. Формально это записывается таким образом:
(2.5)
Можно привести несколько примеров критериев оценки качества работы предикторных схем: модуль ошибки предсказания, взвешенная сумма квадратов ошибок предсказания и взвешенная сумма ошибок предсказания с разной глубиной прогноза.
Если некоторый предиктор с заданной точностью предсказывает достаточно длинный участок временного ряда, то с высокой степенью уверенности можно говорить о том, что используемый предиктор на данном участке достаточно точно описывает динамику этого ряда. Если после некоторого шага ошибка предсказания начинает существенно возрастать, то можно говорить о нарушении закономерности, зафиксированной в данном предикторе, и появлении разладки. Разладка может свидетельствовать о нарушении закономерности в динамике этого ряда.
Для практических приложений может представлять интерес следующее правило выбора. Если выбрана некоторая предикторная схема, то она остается ведущей до тех пор, пока выдаваемый ею прогноз удовлетворяет заданному пользователем критерию. Если ошибка предсказания временного ряда начинает существенно возрастать, то это означает, что данная предикторная схема непригодна для дальнейшего прогнозирования. В этом случае будем говорить о разладке – ситуации, когда ведущая предикторная схема не удовлетворяет некоторому заданному критерию качества.
Понятие «разладка» подробно рассмотрено в работах [ REF _Ref24994982 \r \h REF _Ref24994991 \r \h M0 и M1, при этом считается, что временной ряд до разладки имеет модель M0, а после нее – модель M1. Разладка определяется как момент переключения между моделями M0 и M1.
Классическим примером описания разладки является случай, когда элементы временного ряда xt задаются нормальным распределением, и тогда разладка заключается в изменении значения математического ожидания в некоторый неизвестный момент времени (момент разладки t0).
Рассматриваемые разладки – это участки смены моделей. Сами модели понимаются как предикторные схемы, дающие удовлетворительное описание ряда.
Принципиальный момент: точки разладки зависят от используемых классов предикторов и могут смещаться, исчезать и возникать при изменении этих классов. Разладка – это изменение закономерности, а множество всех используемых закономерностей заранее определено.
Теорема Такенса и погружение
Задача предсказания временного ряда может быть сведена к типовой задаче аппроксимации функции многих переменных по заданной выборке с помощью процедуры погружения этого ряда в многомерное пространство. Смысл ее заключается в формировании набора примеров, состоящих из значений временного ряда в последовательные моменты времени:
(2.6)
Для динамических систем доказана следующая теорема Такенса [ REF _Ref24995008 \r \h X(t) определяются произвольной функцией состояния такой системы, то существует такая глубина предыстории d, которая обеспечивает однозначное предсказание следующего значения временного ряда. Считается, что при достаточно большой величине d можно гарантировать однозначное прогнозирование будущих значений ряда от его d предыдущих значений: . Выбор величины d может быть произведен эмпирическим методом.
Сложность применения данной теоремы заключается в следующем. Во-первых, при сделанных фундаментальных предположениях о природе временного ряда его зависимость не фиксирована, а может изменяться. В частности, может изменяться глубина предыстории X(t); при попытке восстановить такую зависимость предиктором с фиксированным X(t) в одном случае при большей реальной глубине предыстории будет наблюдаться нехватка параметров, в другом — часть параметров будут мешающими. В обоих случаях качество прогноза будет ухудшаться. Во-вторых, объем выборки может оказаться недостаточным, чтобы достаточно точно восстановить зависимость. Кроме того, может изменяться горизонт прогнозирования, в случае если прогноз производится на несколько шагов вперед. Эти и другие варианты нарушения закономерности во временном ряде сложной структуры могут привести к появлению разладок.
2.4
Одним из наиболее перспективных подходов к построению прогнозирующих систем является применение математического аппарата основной парадигмы искусственных нейронных сетей.
ИНС используется тогда, когда неизвестен точный вид связей между входами и выходами. Зависимость между значениями входных и выходных переменных находится в процессе обучения сети. Если сеть обучена правильно, она приобретает способность моделировать неизвестную функцию, связывающую значения входных и выходных переменных, и впоследствии такую сеть можно использовать для прогнозирования в ситуации, когда выходные значения неизвестны.
Задачи предсказания или прогнозирования являются, по-существу, задачами построения регрессионной зависимости выходных данных от входных. Нейронные сети могут эффективно строить сильно нелинейные регрессионные зависимости. К тому же нейронные сети могут одновременно решать несколько задач регрессии и/или классификации.
Специфика такова, что, поскольку решаются в основном неформализованные задачи, то конечной целью решения является не построение понятной и теоретически обоснованной зависимости, а получение устройства-предсказателя.
Метод прогнозирования
На НС задача прогнозирования формализуется через задачу распознавания образов. Данные о прогнозируемой переменной за некоторый промежуток времени образуют образ, класс которого определяется значением прогнозируемой переменной в некоторый момент времени за пределами данного промежутка, т.е. значением переменной через интервал прогнозирования.
На этом подходе основан метод окон, предполагающий использование двух окон Wi и Wo с фиксированными размерами n и m соответственно ( REF _Ref530430979 \h 2.4
Рис. STYLEREF 1 \s 2. SEQ Рис. \* ARABIC \s 1 4 Иллюстрация метода окон
Эти окна, способны перемещаться с некоторым шагом по временной последовательности исторических данных, начиная с первого элемента, и предназначены для доступа к данным временного ряда, причем первое окно Wi, получив такие данные, передает их на вход нейронной сети, а второе – Wo – на выход. Получающаяся на каждом шаге пара:
Wi → Wo (2.7)
используется как элемент обучающей выборки (распознаваемый образ, или наблюдение).
Например, пусть есть данные о ежедневных продажах какого-нибудь фарм. препарата (k = 16):
100 94 90 96 91 94 95 99 95 98 100 97 99 98 96 98 … (2.8)
Пусть n = 4, m = 1, s = 1. С помощью метода окон для нейронной сети будет сгенерирована следующая обучающая выборка:
(2.9)
Каждый следующий вектор получается в результате сдвига окон Wi и Wo вправо на один элемент (s = 1). Предполагается наличие скрытых зависимостей во временной последовательности как множестве наблюдений. Нейронная сеть, обучаясь на этих наблюдениях и соответственно настраивая свои коэффициенты, пытается извлечь эти закономерности и сформировать в результате требуемую функцию прогноза P.
Прогнозирование осуществляется по тому же принципу, что и формирование обучающей выборки. При этом выделяются две возможности: одношаговое и многошаговое прогнозирование.
Многошаговое прогнозирование используется для осуществления долгосрочного прогноза и предназначено для определения основного тренда и главных точек изменения тренда для некоторого промежутка времени в будущем. При этом прогнозирующая система использует полученные (выходные) данные для моментов времени k+1, k+2 и т.д. в качестве входных данных для прогнозирования на моменты времени k+2, k+3 и т.д.
Предположим, система обучилась на временной последовательности (2.8). Затем она спрогнозировала k+1 элемент последовательности, например, равный 95, когда на ее вход был подан последний из известных ей образов (99, 98, 96, 98). После этого она осуществляет дальнейшее прогнозирование и на вход подается следующий образ (98, 96, 98, 95). Последний элемент этого образа является прогнозом системы. И так далее.
Одношаговое прогнозирование используется для краткосрочных прогнозов, обычно – абсолютных значений последовательности. Осуществляется прогноз только на один шаг вперед, но используется реальное, а не прогнозируемое значение для осуществления прогноза на следующем шаге.
Для временной последовательности (2.8). На шаге k + 1 система прогнозирует требование 95, хотя реальное значение должно быть 96. На шаге k + 2 в качестве входного образа будет использоваться образ (98, 96, 98, 96).
Как было сказано выше, результатом прогноза на НС является класс к которому принадлежит переменная, а не ее конкретное значение. Формирование классов должно проводиться в зависимости от того каковы цели прогнозирования. Общий подход состоит в том, что область определения прогнозируемой переменной разбивается на классы в соответствии с необходимой точностью прогнозирования. Классы могут представлять качественный или численный взгляд на изменение переменной.
Прогнозирование на НС обладает рядом недостатков. Необходимо иметь как достаточно много наблюдений для создания приемлемой модели. Это достаточно большое число данных и существует много случаев, когда такое количество исторических данных недоступно. Однако, необходимо отметить, что можно построить удовлетворительную модель на НС даже в условиях нехватки данных. Модель может уточняться по мере того, как свежие данные становится доступными.
Другим недостатком нейронных моделей – значительные затраты по времени и другим ресурсам для построения удовлетворительной модели. Эта проблема не очень важна, если исследуется небольшое число временных последовательностей.
Однако, несмотря на перечисленные недостатки, модель обладает рядом достоинств. Существует удобный способ модифицировать модель, по мере того как появляются новые наблюдения. Модель хорошо работает с временными последовательностями, в которых мал интервал наблюдений, т.е. может быть получена относительно длительная временная последовательность. По этой причине модель может быть использована в областях, где интересуют ежедневные или еженедельные наблюдения. Эти модели также используются в ситуациях, когда необходимо анализировать относительно небольшое число временных последовательностей.
Информационная ёмкость ИНС
Для сетей с числом слоев больше двух, он остается открытым. Как показано в [ REF _Ref24995019 \r \h Cd оценивается так:
Nw/Ny<Cd<Nw/Ny×log(Nw/Ny) (2.10)
где Nw – число подстраиваемых весов, Ny – число нейронов в выходном слое.
Следует отметить, что данное выражение получено с учетом некоторых ограничений. Во-первых, число входов Nx и нейронов в скрытом слое Nh должно удовлетворять неравенству Nx+Nh>Ny. Во-вторых, Nw/Ny>1000. Однако вышеприведенная оценка выполнялась для сетей с активационными функциями нейронов в виде порога, а емкость сетей с гладкими активационными функциями обычно больше [ REF _Ref24995019 \r \h Nx входами. В действительности распределение входных образов, как правило, обладает некоторой регулярностью, что позволяет НС проводить обобщение и, таким образом, увеличивать реальную емкость. Так как распределение образов, в общем случае, заранее не известно, мы можем говорить о такой емкости только предположительно, но обычно она раза в два превышает емкость детерминистскую.
В продолжение разговора о емкости НС логично затронуть вопрос о требуемой мощности выходного слоя сети, выполняющего окончательную классификацию образов. Дело в том, что для разделения множества входных образов, например, по двум классам достаточно всего одного выхода. При этом каждый логический уровень – "1" и "0" – будет обозначать отдельный класс. На двух выходах можно закодировать уже 4 класса и так далее. Однако результаты работы сети, организованной таким образом, можно сказать – "под завязку", – не очень надежны. Для повышения достоверности классификации желательно ввести избыточность путем выделения каждому классу одного нейрона в выходном слое или, что еще лучше, нескольких, каждый из которых обучается определять принадлежность образа к классу со своей степенью достоверности, например: высокой, средней и низкой. Такие НС позволяют проводить классификацию входных образов, объединенных в нечеткие (размытые или пересекающиеся) множества. Это свойство приближает подобные НС к условиям реальной жизни.
Архитектура нейронной сети
Среди различных структур нейронных сетей (НС) одной из наиболее известных является многослойная структура, в которой каждый нейрон произвольного слоя связан со всеми аксонами нейронов предыдущего слоя или, в случае первого слоя, со всеми входами НС. Такие НС называются полносвязными. Когда в сети только один слой, алгоритм ее обучения с учителем довольно очевиден, так как правильные выходные состояния нейронов единственного слоя заведомо известны, и подстройка синаптических связей идет в направлении, минимизирующем ошибку на выходе сети. По этому принципу строится, например, алгоритм обучения однослойного персептрона. В многослойных же сетях оптимальные выходные значения нейронов всех слоев, кроме последнего, как правило, не известны, и двухслойный или более персептрон уже невозможно обучить, руководствуясь только величинами ошибок на выходах НС. Один из вариантов решения этой проблемы – разработка наборов выходных сигналов, соответствующих входным, для каждого слоя НС, что, конечно, является очень трудоемкой операцией и не всегда осуществимо. Второй вариант – динамическая подстройка весовых коэффициентов синапсов, в ходе которой выбираются, как правило, наиболее слабые связи и изменяются на малую величину в ту или иную сторону, а сохраняются только те изменения, которые повлекли уменьшение ошибки на выходе всей сети. Третий вариант – распространение сигналов ошибки от выходов НС к ее входам, в направлении, обратном прямому распространению сигналов в обычном режиме работы.
Алгоритм обучения ИНС
После того, как определено число слоев и число элементов в каждом из них, необходими нйти значения весов и порогов сети, которые бы минимизировали ошибку прогноза, выдаваемого сетью. Для этого применяются процедуры обучения ИНС.
Одной из классических и самой распространенной процедурой обучения ИНС является алгоритм обратного распространения ошибки (back propagation), подробно описанный в [ REF _Ref24995054 \r \h REF _Ref24995063 \r \h REF _Ref24995078 \r \h REF _Ref24995087 \r \h REF _Ref24995104 \r \h REF _Ref24995125 \r \h REF _Ref24995136 \r \h
Согласно методу наименьших квадратов, минимизируемой целевой функцией ошибки НС является величина:
(2.11)
где – реальное выходное состояние нейрона j выходного слоя N нейронной сети при подаче на ее входы p-го образа; djp – идеальное (желаемое) выходное состояние этого нейрона.
Суммирование ведется по всем нейронам выходного слоя и по всем обрабатываемым сетью образам. Минимизация ведется методом градиентного спуска, что означает подстройку весовых коэффициентов следующим образом:
(2.12)
Здесь wij – весовой коэффициент синоптической связи, соединяющей i-ый нейрон слоя n-1 с j-ым нейроном слоя n, h – коэффициент скорости обучения, 0<h<1.
Как показано в [ REF _Ref24995149 \r \h
(2.13)
Здесь под yj, как и раньше, подразумевается выход нейрона j, а под sj – взвешенная сумма его входных сигналов, то есть аргумент активационной функции. Так как множитель dyj/dsj является производной этой функции по ее аргументу, из этого следует, что производная активационной функция должна быть определена на всей оси абсцисс. В связи с этим функция единичного скачка и прочие активационные функции с неоднородностями не подходят для рассматриваемых НС. В них применяются такие гладкие функции, как гиперболический тангенс или классическая сигмоида с экспонентой. В случае гиперболического тангенса
(2.14)
Третий множитель ¶sj/¶wij, очевидно, равен выходу нейрона предыдущего слоя yi(n-1).
Первый множитель в (2.13) легко раскладывается следующим образом [ REF _Ref24995149 \r \h
(2.15)
Здесь суммирование по k выполняется среди нейронов слоя n+1.
Введя новую переменную
(2.16)
получим рекурсивную формулу для расчетов величин dj(n) слоя n из величин dk(n+1) более старшего слоя n+1.
(2.17)
Для выходного же слоя
(2.18)
Запишем (2.12) в раскрытом виде:
(2.19)
Иногда для придания процессу коррекции весов некоторой инерционности, сглаживающей резкие скачки при перемещении по поверхности целевой функции, (2.19) дополняется значением изменения веса на предыдущей итерации
(2.20)
где m – коэффициент инерционности, t – номер текущей итерации.
Таким образом, полный алгоритм обучения НС с помощью процедуры обратного распространения строится так:
1.
(2.21)
где M – число нейронов в слое n-1 с учетом нейрона с постоянным выходным состояние m +1, задающего смещение; yi(n-1)=xij(n) – i-ый вход нейрона j слоя n.
yj(n) = f(sj(n)), где f(…) – сигмоид (2.22)
yq(0)=Iq, (2.23)
где Iq – q-ая компонента вектора входного образа.
2. d(N) для выходного слоя по формуле (2.18).
3. Dw(N) слоя N.
4. d(n) и Dw(n) для всех остальных слоев, n = N-1,...1.
5.
(2.24)
6.
Сети на шаге 1 попеременно в случайном порядке предъявляются все тренировочные образы, чтобы сеть, образно говоря, не забывала одни по мере запоминания других. Алгоритм иллюстрируется на REF _Ref24448780 \h 2.5
Рис. STYLEREF 1 \s 2. SEQ Рис. \* ARABIC \s 1 5 Диаграмма сигналов в сети при обучении по алгоритму back propagation
Из выражения (2.19) следует, что когда выходное значение yi(n-1) стремится к нулю, эффективность обучения заметно снижается. При двоичных входных векторах в среднем половина весовых коэффициентов не будет корректироваться [ REF _Ref8486251 \r \h
(2.25)
В процессе обучения может возникнуть ситуация, когда большие положительные или отрицательные значения весовых коэффициентов сместят рабочую точку на сигмоиде многих нейронов в область насыщения. Малые величины производной от логистической функции приведут в соответствие с (2.17) и (2.18) к остановке обучения, что парализует НС.
Во-вторых, применение метода градиентного спуска не гарантирует, что будет найден глобальный, а не локальный минимум целевой функции. Эта проблема связана еще с одной, а именно – с выбором величины скорости обучения. Доказательство сходимости обучения в процессе обратного распространения основано на производных, то есть приращения весов и, следовательно, скорость обучения должны быть бесконечно малыми, однако в этом случае обучение будет происходить неприемлемо медленно. С другой стороны, слишком большие коррекции весов могут привести к постоянной неустойчивости процесса обучения. Поэтому в качестве h обычно выбирается число меньше 1. Кроме того, для исключения случайных попаданий в локальные минимумы иногда, после того как значения весовых коэффициентов стабилизируются, h кратковременно сильно увеличивают, чтобы начать градиентный спуск из новой точки. Если повторение этой процедуры несколько раз приведет алгоритм в одно и то же состояние НС, можно более или менее уверенно сказать, что найден глобальный минимум.
Выбор и представление набора данных для ИНС
Если задача решается с помощью нейронной сети, то необходимо собрать данные для её обучения. Обучающий набор представляет собой ряд наблюдений, для которых указаны значения входных и выходных переменных. Выбор переменных осуществляется исходя из анализа предметной области. Необходимо выбирать такие переменные, которые предположительно влияют на результат.
Любая ИНС принимает на входе числовые значения и выдает на выходе также числовые значения. Поэтому перед подачей на вход сети данных их необходимо нормировать. Простую нормировку выполняют заменой каждой компоненты входного вектора данных xi величиной:
(2.26)
где max xi и min xi – соответственно максимальное и минимальное значение для данной компоненты, вычисленные по всей обучающей выборке. По этой же формуле пересчитываются и компоненты векторов ответов.
Если предполагается, что в дальнейшем поступят сильно отличающиеся данные, то min и max-величины задаются пользователем по его оценкам. Эти величины должны вводиться в момент создания сети и в дальнейшем не зависеть от обучающей выборки.
Функции активации элементов сети обычно выбираются таким образом, чтобы ее входной аргумент мог принимать произвольные значения, а выходные значения лежали в строго ограниченном диапазоне («сплющивание»). Выходные сигналы сети должны нормироваться в диапазон истинных значений по обращенным формулам.
Коль скоро выходные значения всегда принадлежат некоторой ограниченной области, а вся информация должна быть представлена в числовом виде, очевидно, что при решении реальных задач методами ИНС требуются этапы предварительной обработки – пре-процессирования и заключительной обработки – пост-процессирования данных [ REF _Ref24995192 \r \h
Нейронные сети могут эффективно работать с числовыми данными, лежащими в только определенном ограниченном диапазоне. Это создает проблемы в тех случаях, когда данные имеют нестандартный масштаб, включают пропущенные значения или являются номинальными или нечисловыми. Для устранения этой проблемы применяются следующие методы обработки:
·
· REF _Ref24995192 \r \h
·
За преобразование информации от выходных элементов в выходную переменную и представление результатов отвечает этап пост-процессирования.
3.
3.1
В данном случае принятия решений в торговой деятельности предприятия объектом исследования является товарооборот, его признаками – показатели его финансово-хозяйственной деятельности (максимальная прибыль и минимальные убытки), а исследуемым свойством – ликвидность товарных остатков на складе. Прогнозирование в задаче рассматривается в целях планирования управления запасами ( REF _Ref530434726 \h Рис. 3.1).
Рис. STYLEREF 1 \s 3. SEQ Рис. \* ARABIC \s 1 1 Кривая прогноза и динамики продаж
Таким образом, интерес решения задачи лежит в определении будущих продаж товара. Полагая именно такую направленность и учитывая особенности ведения бухгалтерского учета на предприятии, сформулируем основные принципы решения проблемы проектирования СППР:
·
·
·
·
·
·
3.2 СППР
Современные бухгалтерские системы – это системы поддержки принятия решений, предназначенные для квалифицированных специалистов и позволяющие не только автоматизировать все учетные задачи, но и получать своевременную и оперативную финансовую информацию для повышения эффективности управления предприятием. Учетная информация, накапливаемая в этих системах, представляет большую ценность для руководителей и аналитиков в их повседневной деятельности. Источником информации для проведения статистического анализа являются финансовые отчеты (бухгалтерский баланс предприятия, отчет о финансовых результатах, отчет о движении денежных средств, приложение к балансу).
Одним из наиболее перспективных направлений применения технологий интеллектуального анализа учетных данных являются бизнес-приложения в составе интегрированных бухгалтерских систем. И для обеспечения минимальных трудозатрат на разработку пользовательского интерфейса, минимизации объема программного кода и упрощения проблемы интеграции разработку намеченной системы прогнозирования решено было выполнить в качестве встраиваемого модуля в уже использующуюся учетно-аналитическую систему «1С: Предприятие 7.7».
Подобный подход ориентирован в основном на непрограммирующего пользователя и на решение конкретных задач. От пользователя этой системы при этом не требуется специальных знаний в области БД, факторного анализа или методов оптимизации.
Технология статистической обработки данных базируется на использовании многомерных статистических процедур, из которых наибольшее практическое применение получили методы кластерного анализа и прогнозирования временных рядов.
Выделить группы с однородными данными, расчленить информацию на однокачественные интервалы или, иными словами, сгруппировать данные по типу (типология исходной информации) – это начальный этап предварительного анализа данных, причем для различных объектов статистических измерений используют соответствующие средства типологической группировки.
Для временных рядов этим целям призвана служить периодизация – разбиение динамических рядов на интервалы однокачественного развития.
Основная проблема в задаче анализа и прогнозирования временных рядов заключается в построении модели, адекватно отражающей их динамику. Рыночный механизм, характеризующийся огромным количеством постоянно меняющихся связей, зависит от множества внешних факторов, способных существенно повлиять на всю структуру его зависимостей, причем воздействие может быть самым разнообразным.
Для решения проблемы прогнозирования удобнее выбрать практический подход и использовать технические средства анализа временных рядов и в качестве адаптивного предиктора использовать многослойную нейронную сеть.
Исходя из общих требований к системе п. REF _Ref25061729 \r \h 3.1, спецификации программы «1С: Предприятие 7.7» [ REF _Ref24995224 \r \h 23] и учитывая содержание п. REF _Ref530435160 \r \h 2 предполагается следующая идеология решения данной проблемы:
I. ActiveX компонент, содержащий программный код обработки.
II.
III.
IV. COM объекта и передачи в него данных для обработки.
3.3
Исходя из анализа предметной области определяем спецификацию необходимых для достижения поставленной цели переменных и сведений ( REF _Ref23510440 \h Таблица 1.1).
Таблица STYLEREF 1 \s 3. SEQ Таблица \* ARABIC \s 1 1 Спецификация исходных данных.
|
Переменная |
Обозначение |
Тип |
Формат |
|
Идентификатор |
ID |
Number |
Integer |
|
Кол-во |
Quantity |
Number |
Long Integer |
|
Текущий остаток |
Rest |
Number |
Long Integer |
|
Срок годности |
KeepingTerm |
Date/Time |
|
|
Дата производства |
MakingDate |
Date/Time |
|
|
Цена приобретения |
Cost |
Currency |
Double |
|
Цена продажи |
Price |
Currency |
Double |
|
Дата продажи |
SellingDate |
Date/Time |
|
|
Минимальная заводская упаковка |
PackingMin |
Number |
Long Integer |
Спецификация данных, необходимых для процедуры обучения ИНС, представлена в REF _Ref24891832 \h Таблица 3.2.
Таблица STYLEREF 1 \s 3. SEQ Таблица \* ARABIC \s 1 2 Данные для процедуры обучения ИНС
|
Переменная |
Тип |
Вид |
Диапазон значений |
|
|
ID |
ном. |
входная |
232 |
|
|
Quantity |
числ. |
входная/выходная |
min ÷ max |
|
|
Date |
Day |
числ. |
входная |
1 ÷ 31 |
|
Month |
числ. |
входная |
1 ÷ 12 |
Весь алгоритм обработки данных в системе СППР условно разбит на три этапа: пре-процессирование, основная обработка (прогноз) и пост-процессирование с представлением результата ЛПР.
До выполнения всех этапов обработки производятся необходимые настройки и изменения в конфигурации системы программ «1С: Предприятие 7.7», заключающиеся в создании определенной формы отчета, таблицы результатов, интерфейса пользователя и модулей обработки на встроенном языке программирования.
Первый этап:
1) SQL;
2)
3)
4)
5)
6)
Второй этап:
1)
2)
3)
4)
5)
6)
Третий этап:
1)
2) Rest);
3)
4)
5)
6)
7)
8)
3.4
Для определения оптимальных параметров нейронной сети был проведен ряд экспериментов. Целью экспериментов было прогнозирование объема будущих продаж. Для достижения данной цели было проведено исследование влияния представления исторических и прогнозируемых данных на ошибку прогнозирования. Также были рассмотрены вопросы влияния структуры НС на скорость обучения сети и ошибку прогнозирования. При этом ставились следующие задачи:
·
·
·
· оптимального размера окна;
· оптимальной структуры сети.
Каждый из экспериментов, проводился в четыре этапа.
Первым этапом было формирование обучающей выборки. На этом этапе определялся вид представления исторических и прогнозируемых данных и проводилось формирование наборов, подаваемых на входные нейроны и соответствующих им наборов снимаемых с выходов сети. Для автоматизации этого процесса формирования обучающих выборок был использован пакет MS Excel.
Вторым этапом проводилось обучение НС на основе сформированной на первом этапе обучающей выборки. Качество обучения характеризовалось ошибкой обучения, определяемой как суммарное квадратичное отклонение значений на выходах НС в обучающей выборке от реальных значений, полученных на выходах НС. Критерием прекращения обучения было прохождение сетью 1500 итераций или уменьшение ошибки на выходах сети на два порядка, по сравнению с первичной ошибкой. В том случае, если при описании опыта не указано, что произошло снижение ошибки на два порядка, обучение было остановлено по первому критерию.
На третьем этапе проводилось тестирование обучения сети. На вход подавалось порядка 4–5% наборов из обучающей выборки и определялось качество распознавания сети. Опыт считался успешным если относительная достоверность распознавания образов была не менее 80%.
На четвертом этапе проводилась симуляция прогнозирования. На вход сети подавались наборы, которые не были внесены в обучающую выборку, но результат по ним (прогноз) известен.
В целях формирования необходимого пространства признаков номинальная переменная ID представлена двоичным кодом со смещёнными уровнями [0, 1] → [–0.5, +0.5] для управления уровнями смещениями нейронов первого слоя.
Перед проведением первой процедуры обучения нейронной сети проводится формирование начальных значений матрицы синаптических весов сети путем холостого прогона обучения по переменной ID на «нулевой обучающей выборке», т.е. все значения переменных за исключением ID равны 0.
В целей обеспечения необходимых свойств экстраполяции ИНС и устранения эффекта переобучения сети в выходном слое применяем линейную функцию активации, которая не обладает областями насыщения, с невысоким коэффициентом обучаемости.
На основании формулы (2.10) и опытных данных были определены следующие параметры нейронной сети:
·
·
·
·
Архитектура нейронной сети, построенной по этим данным изображена на REF _Ref24926436 \h Рис. 3.2.
SHAPE \* MERGEFORMAT
|
1 |
|
2 |
|
3 |
|
28 |
|
I Слой |
|
1 |
|
2 |
|
3 |
|
21 |
|
II Слой |
|
1 |
|
2 |
|
3 |
|
14 |
|
III Слой |
|
Quantity t+∆t |
|
Quantity t+3∆t |
|
Quantity t+2∆t |
|
Quantity t+14∆t |
|
W0 |
|
Month |
|
Day |
|
Quantityt |
|
Quantityt+∆t |
|
Quantityt+2∆t |
|
Quantityt+13∆t |
|
Wi |
|
ID |
|
Двоичный код 0 – -0,5 1 – +0,5 |
Рис. STYLEREF 1 \s 3. SEQ Рис. \* ARABIC \s 1 2 Архитектура нейронной сети
В качестве
тестового примера был выбраны исторические данные, представляющие собой
временные ряды динамики продаж фарм. препаратов двух видов за год. Для
исследования был взят период с 1 октября
Для прогнозирования применялась трехслойная нейронная сеть по 28:21:14 нейронов в соответствующем слое, которая на основе четырнадцати предыдущих значений временного ряда предсказывала его следующее значение. В качестве нелинейного преобразователя использовалась сигмовидная функция с характеристическим коэффициентом [ REF _Ref8486251 \r \h 21]. Обучение НС осуществлялось по алгоритму обратного распространения ошибки методом скользящего окна из 14 примеров.
Результаты работы данной системы прогнозирования представлены на REF _Ref24732543 \h Рис. 3.3 .
Рис. STYLEREF 1 \s 3. SEQ Рис. \* ARABIC \s 1 3 Прогноз и динамика продажи двух фарм. препаратов за 1 год.
Верхние графики описывают динамику среднего значения спроса на препарат, а также прогноз, сделанный нейронной сетью. Нижние графики описывают ошибку предсказания, порог и сами разладки.
Данные примеры демонстрирует, что, несмотря на сложную динамику временных рядов, последние за исключением ограниченного числа участков могут успешно прогнозироваться с помощью сравнительно несложной модели нейронной сети.
Прогноз такого устройства непосредственно не является окончательным решением, т.е. – выходной сигнал НС будет оценивать ЛПР на основе своих знаний и опыта и формировать собственное экспертное заключение. На основе составленного НС прогноза ЛПР стратегического и тактического уровней получают возможность проанализировать динамику развития спроса, выявить неочевидные на первый взгляд взаимосвязи, сравнить различные альтернативы, проанализировать аномалии и принять наиболее обоснованное решение.
3.5
Исходя из содержания теоретической части, описывающей алгоритм прогнозирования с применением НС, её функционирования и обучения, весь процесс был записан и запрограммирован в терминах и операциях матричной алгебры с применением объектно-ориентированного (ОО) подхода.
Такой подход обеспечивает более быструю и компактную реализацию НС.
Во-первых, это позволяет создать гибкую, легко перестраиваемую иерархию моделей НС. Во-вторых, такая реализация наиболее прозрачна для программиста, и позволяет конструировать НС даже непрограммистам. В-третьих, уровень абстрактности программирования, присущий ОО языкам, в будущем будет расти, и реализация НС с ОО подходом позволит расширить их возможности.
Для решения поставленной задачи на основе технологии ИНС был разработан встраиваемый в «1С: Предприятие 7.7» программный модуль, предназначенный для прогнозирования и обнаружения скрытых закономерностей во временных рядах динамики продаж. Для прогнозирования был выбран адаптивный предиктор, построенный на основе многослойной нейронной сети.
Программа предназначена для совместного использования с системой программ «1C:Предприятие 7.7» и представляет собой библиотеку написанную по правилам ActiveX компонента на языке программирования Delphi. Для стыковки программы с системой «1C:Предприятие 7.7» используется специальный скрипт на внутреннем языке системы представленный в приложении Б. Скрипт загружает и инициализирует ActiveX компонент. Параметры для программы задаются изнутри системы «1C:Предприятие 7.7», и передаются в компонент как параметры при его инициализации.
Библиотека написана с использованием языка программирования Delphi 6 и дополнительных библиотек реализующих интерфейсы для программирования нейронных сетей “Neural Networks Component Library”.
В программе реализована библиотека классов для моделирования разнообразных нейронных сетей.
Классы с суффиксом ff, описываюте прямопоточные нейронные сети (feedforward), входят в состав не только сетей с обратным распространением – bp (backpropagation), но и других, например таких, как с обучением без учителя. Иерархия классов приведенной библиотеки приведена на REF _Ref24466901 \h 3.4
SHAPE \* MERGEFORMAT
|
TNeuralNetBP |
|
TLayerFF |
|
TNeuralNet |
|
TNeuron |
|
TLayerBP |
|
TNeuronBP |
|
TNeuronFF |
|
вхождение |
|
наследование |
Рис. STYLEREF 1 \s 3. SEQ Рис. \* ARABIC \s 1 4 Иерархия классов библиотеки для сетей обратного распространения
Основными классами программы являются:
TNeuron – Реализует все свойства и методы математического нейрона.
Этот класс содержит вектора весов и функцию активации для нейрона.
TNeuronBP - Реализует класс нейронов для сети back-propagation.
Этот класс имеет возможность изменения значения скорости обучения на заданной эпохе. Позволяет просматривать значение частной производной на предыдущей эпохе, значение коррекции веса на предыдущей эпохе. Позволяет задавать любую функцию активации.
TLayer – Реализует базовый класс слоя нейронов и содержит механизмы регулирования количества нейронов на слое.
TLayerBP – Реализует класс слоя для сети back-propagation. Содержит нейроны класса TNeuronBP.
TNeuralNet – Реализует базовый класс нейронной сети. Определяет массив слоёв, определяет число обучающих выборок.
TNeuralNetBP – Реализует базовый класс для сети back-propagation.
Позволяет задавать и просматривать следующие параметры: коэффициент крутизны пороговой сигмоидальной функции, желаемую размерность выхода нейронной сети, счетчик эпох (предъявление сети всех примеров из обучающей выборки) ,номер текущей эпохи, значение максимальной ошибки на обучающем множестве, значение максимальной ошибки на тестовом множестве, значение средней ошибки на обучающем множестве, коэффициент инерционности, число примеров в обучающем множестве и коэффициент скорости обучения.
В приложении А приведен исходный код программы, а интерфейс пользователя (форма отчета), реализованная средствами системы «1С: Предприятие 7.7» в приложении В.
Приведеная в приложении А библиотека классов и программ, позволяет реализовать полносвязные ИНС с обучением по алгоритму обратного распространения, разработана и использовалась в целях решения данной задачи, однако применима и в других приложениях, имеющих схожую специфику.
Программа компилировалась с помощью среды Borland Delphi 6.0 Enterprise Edition компилятором bcc32.
Разработанная библиотека классов позволяет создавать сети, способные решать широкий спектр задач, таких как построение экспертных систем, сжатие информации и многих других, исходные условия которых могут быть приведены к множеству парных, входных и выходных, наборов данных.
4.
В условиях рыночных отношений целью проектирования и разработки любой программно-технической системы является не только обеспечение её функциональных характеристик, но и её успешная продажа и получение прибыли.
Для достижения данной цели, необходимо исследовать существующий рынок потребителей продукции, выявить сегменты рынка, которым необходима разработанная система, исследовать продукцию конкурентов, составить бизнес-план[3] [ REF _Ref24997059 \r \h REF _Ref24997079 \r \h REF _Ref24997096 \r \h
В экономической части дипломного проекта используются элементы Бизнес-плана, которые включают расчеты по определению емкости рынка, его сегментации по параметрам, потребителям, ценовому фактору; составление сметы затрат на разработку программного продукта, его тиражирование и сбыт; расчет договорной цены и чистого дохода.
4.1
«Система поддержки принятия маркетинговых решений» является представителем целого класса подобных систем и направлена на увеличение эффективности анализа данных и оптимального принятия управленческих решений на их основе.
4.1.1
Наименование: “Система поддержки принятия маркетинговых решений”.
Назначение: упрощение процедуры принятия решения должностным лицом предприятия.
Область использования: программный продукт ориентирован на применение в предприятиях оптовой и розничной торговли.
Характеристика программного продукта представлена в REF _Ref22314749 \h 4.1
Таблица STYLEREF 1 \s 4. SEQ Таблица \* ARABIC \s 1 1 Характеристика программного продукта
|
Наименование |
Значение параметра |
|
Тип ПЭВМ |
IBM «Pentium-III 900» и выше |
|
Операционная система |
MS Windows 9х/2000/XP |
|
Модель |
Реляционная |
|
Среда программирования |
1C:Предприятие, Borland Delphi 6, SQL |
4.1.2
Программный продукт представляет собой приложение, разработанное с помощью программной среды RAD Borland Delphi 6.0 Enterprise Edition. Включает в себя таблицы с данными, формы для работы с данными, SQL- запросы, позволяющие осуществлять выборку необходимых данных, отчеты, представляющие собой формы выходных документов, макросы и модули на языке Visual Basic, позволяющие автоматизировать работу приложения, размещенного на локальном компьютере учреждения. Приложение работает в диалоговом режиме и отличается удобным пользовательским интерфейсом. Это обеспечивает гибкость системы, масштабируемость и быстрый доступ к ресурсам и данным. Использование передовых технологий диктует требования к технической базе. Для доступа к ресурсам и БД используются IBM совместимые персональные компьютеры с процессором Intel Pentium-166 и выше. Операционная система для ПК пользователей – MS Windows 9х/2000/ХР.
4.1.3
Программный продукт разработан под операционную систему MS Windows 9х/2000/ХР, представляющей собой интуитивно-понятный интерфейс. Также в системе предусмотрена защита от неправильного ввода данных.
4.1.4
При разработке товара использовались лицензионные копии системы, MS Windows 2000, «1С: Предприятие 7.7», Borland Delphi 6.0 Enterprise Edition.
4.1.5
Гарантируется правильное и надёжное функционирование программного продукта в нормальных условиях эксплуатации и при соблюдении правил использования ПЭВМ и руководства пользователя программного продукта. Обнаруженные ошибки в программном продукте во время его эксплуатации устраняются бесплатно.
4.2
4.2.1
Для исследования рынка сбыта необходимо произвести сегментацию рынка.
Сегментация – один из важнейших инструментов маркетинга. От правильности выбора сегмента рынка во многом зависит успех предприятия в конкурентной борьбе.
Сегмент рынка – это особым образом выделенная часть рынка, группа потребителей, продуктов или предприятий, обладающих определенными общими признаками.
Наиболее важными характеристиками сегментов являются:
1)
2)
3)
4)
5)
6)
Предлагаемый программный продукт ориентирован на следующие категории потребителей:
1)
2)
Одной из задач, решаемых в маркетинге, является определение потенциального покупателя, иначе говоря, производится сегментация рынка с целью выявления групп потребителей предлагаемого товара.
Разработанный программный продукт рассчитан на категорию лиц, связанных с постоянным анализом информации и дальнейшим принятием решения на её основе. Он ориентирован на должностных лиц и работников предприятий оптовой и розничной торговли всех форм собственности, а также пользователей непрограммистов ( REF _Ref22314946 \h 4.2
1)
2)
3)
Таблица STYLEREF 1 \s 4. SEQ Таблица \* ARABIC \s 1 2 Сегменты рынка по основным потребителям
|
Отрасли использования |
Потребители |
||
|
1 |
2 |
3 |
|
|
Предприятий оптовой торговли |
+ |
+ |
+ |
|
Предприятия розничной торговли |
+ |
+ |
+ |
Определим ёмкость сегментов рынка ( REF _Ref22315091 \h 4.3
Таблица STYLEREF 1 \s 4. SEQ Таблица \* ARABIC \s 1 3 Анализ ёмкости сегментов рынка Харьковской области
|
Отрасль использования |
Кол-во объектов |
Предполагаемое кол-во продаж по одному объекту |
Предполагаемая ёмкость рынка |
Код |
|
Предприятий оптовой торговли |
15 |
1 |
15 |
1 |
|
Предприятия розничной торговли |
25 |
1 |
25 |
2 |
|
ИТОГО: |
40 |
Примечание: Колонка 2 заполнена по данным Статистического управления Харьковской области; колонка 4 вычислена следующим образом: колонку 2 умножить на колонку 3.
На основании таблицы 3 можно сделать вывод о том, что предполагаемый рынок программного продукта “Система поддержки принятия маркетинговых решений” состоит из 2 сегментов, суммарная ёмкость рынка – 40.
4.2.2
При разработке программного продукта “Система поддержки принятия маркетинговых решений” учитывалась необходимость разработать приложение, которое было бы удобно не только с точки зрения программиста, но и с точки зрения пользователя-непрограммиста.
Кроме того, приложение ориентировано на графическую среду подобную операционной системе MS Windows 2000, которая в настоящее время является одной из самых удобных и дружественных для пользователя средой. Но, с другой стороны, MS Windows 2000 предъявляет более высокие требования к аппаратным средствам компьютера, чем MS-DOS, что очень важно для пользователей устаревших ЭВМ, используемых во многих отечественных учреждениях.
Одним из важнейших показателей является надёжность. В данной программе приняты все меры по повышению надёжности работы программными средствами.
Важную роль занимает гибкость программы, иначе говоря, какое количество времени необходимо для адаптации программы под конкретное учебное заведение. Разработанный программный продукт состоит из программных модулей, которые при изменении программы легко заменяются и добавляются, что приводит к уменьшению времени адаптации, а следовательно, к сокращению затрат на оплату работы программиста.
При выборе цены продукта следует учесть низкую платежеспособность субъектов отечественного рынка. Это означает, что продукт должен иметь низкую стоимость. Этот фактор исключительно важен, поскольку в качестве потенциальных покупателей рассматривается большое количество государственных учебных заведений, для которых цена зачастую является решающим фактором.
Таким образом, для проведения параметрического анализа выделим следующие характеристики продукта:
·
·
·
·
·
·
·
Параметрический анализ сегментации рынка в Харьковской области приведен в REF _Ref371875232 \h 4.4большое значение имеют цена, надёжность, интерфейс, гибкость и эффективность программного продукта, соответственно им назначенные оценки в баллах "5", "5", "5", "5" и "4". Сроки получения конечного продукта и требования к ЭВМ интересует их меньше, поэтому им назначены оценки "3", "3" соответственно.
Таблица STYLEREF 1 \s 4. SEQ Таблица \* ARABIC \s 1 4 Параметрическая сегментация рынка Харьковской области
|
Параметр |
Сегмент |
Итоговая оценка |
Удельный вес параметров, % |
|
|
1 |
2 |
|||
|
Надежность |
5 |
5 |
10 |
17,6 |
|
Интерфейс |
5 |
5 |
10 |
17,6 |
|
Эффективность конечного продукта |
4 |
5 |
9 |
16,5 |
|
Цена |
5 |
3 |
8 |
12,9 |
|
Сроки получения конечного продукта |
3 |
4 |
7 |
12,9 |
|
Гибкость |
5 |
3 |
8 |
12,9 |
|
Требования к ЭВМ |
3 |
2 |
5 |
9,4 |
|
ИТОГО: |
30 |
27 |
57 |
100 |
Вывод: наиболее важными характеристиками являются: надёжность, эффективность и интерфейс конечного продукта.
4.2.3
Для проведения многофакторной сегментации оценим характеристики продукта, соответствующие выбранным нами параметрам, по пятибалльной шкале. Полученную итоговую оценку продукта сравним с итоговыми оценками сегментов рынка.
Многофакторная сегментация продукта “Система поддержки принятия маркетинговых решений” приведена в REF _Ref371875253 \h 4.5
Таблица STYLEREF 1 \s 4. SEQ Таблица \* ARABIC \s 1 5 Многофакторная сегментация продукта
|
Параметр |
Сегмент |
Продукт |
|
|
1 |
2 |
||
|
Цена |
5 |
5 |
5 |
|
Надежность |
5 |
5 |
5 |
|
Интерфейс |
4 |
5 |
5 |
|
Гибкость |
5 |
3 |
4 |
|
Требования к ЭВМ |
3 |
4 |
4 |
|
Сроки получения конечного продукта |
5 |
3 |
4 |
|
Эффективность конечного продукта |
3 |
2 |
4 |
|
ИТОГО: |
30 |
27 |
31 |
Вывод: предлагаемый продукт согласуется по факторам со всеми сегментами.
4.3
4.3.1
Необходимо произвести расчет материальных затрат на разработку, тиражирование и распространение программы, а также себестоимости и возможной прибыли от продажи заказчику “Система поддержки принятия маркетинговых решений”. Расчет потребностей оборудования и материальных ресурсов для разработки программного продукта представлены соответственно в REF _Ref371875309 \h 4.6 REF _Ref371875326 \h 4.7
Таблица STYLEREF 1 \s 4. SEQ Таблица \* ARABIC \s 1 6 Потребности в оборудовании
|
Оборудование |
Количество единиц |
Стоимость аренды, грн. |
Примечание |
|
ПЭВМ IBM PC AT Pentium III |
1 |
210 |
Для отладки и тестирования ПО, документирование |
Кроме того, для разработки 1 копии программного продукта необходимо закупить следующие материалы:
Таблица STYLEREF 1 \s 4. SEQ Таблица \* ARABIC \s 1 7 Потребность в материалах и ПКИ для 1 копии продукта
|
Потребности в материалах и ПКИ |
Кол-во, шт. |
Цена за 1 шт., грн. |
Сумма, грн. |
Примечание |
|
Дискета |
1 |
2,60 |
2,60 |
Хранение исходных текстов программ и документации |
|
Бумага |
50 листов |
0,2 |
10,0 |
Распечатка документации |
|
Картридж для принтера |
0,025 |
10,5 |
0,26 |
Распечатка документации |
|
ИТОГО: |
12,86 |
Таким образом, для выполнения проектировочных работ необходимо материалов на сумму 12 грн. 86 копеек.
4.3.2
Рассчитаем затраты на разработку программного продукта. В REF _Ref22317179 \h 4.8
Таблица STYLEREF 1 \s 4. SEQ Таблица \* ARABIC \s 1 8 Расчет затрат на разработку продукта
|
Статья затрат |
Сумма, грн. |
|
Основные материалы и ПКИ, литература |
40,00 |
|
Размер ФОТ |
300,00 |
|
Премии |
- |
|
Затраты на отладку программы |
- |
|
Прочие прямые расходы на командировки, на рекламу, плата за аренду помещения (плата за электроэнергию), плата за аренду компьютера |
15,00 |
|
Отчисления в пенсионный фонд (32% ФОТ) |
96 |
|
Отчисления в соц. страх (2,5% ФОТ) |
7,5 |
|
Отчисления в фонд безработицы (2,5% ФОТ) |
7,5 |
|
Накладные расходы |
- |
|
Прочие |
- |
|
Суммарные затраты на разработку |
466 |
|
Суммарные затраты на разработку комплекса |
--------- |
|
Затраты на разработку единицы продукта |
10,64 |
4.3.3
Поскольку продукт должен продаваться, ему необходимо создать рекламу. Предусматривается реклама в газете «Что? Где? Почем?», где помещение модульной рекламы размером 50×82 мм с повтором в четырех номерах при наличии установленной скидки обойдется 80 грн. Рекламное сообщение в сети Internet общей длиной до 300 Кб можно дать без оплаты. Таким образом, расчет затрат на рекламу составляет 80 грн. ( REF _Ref371875508 \h 4.9
Таблица STYLEREF 1 \s 4. SEQ Таблица \* ARABIC \s 1 9 Расчет затрат на рекламу
|
Статья затрат |
Сумма, грн. |
|
1. Реклама в газете «Что? Где? Почем?» |
80 |
|
2. Реклама в Internet (сообщение до 300 Кб) |
бесплатно |
|
Итого: |
80 |
На основании приведенных выше таблиц и расчётов определим затраты на тиражирование и договорную цену продукта ( REF _Ref371875489 \h 4.10 постоянные расходы на рекламу и переменные затраты на материалы, оплата труда программисту -внедренцу и прочие накладные расходы.
Итак, договорная цена продукта составляет 311 грн., а затраты на тиражирование – 175,28 грн.
Таблица STYLEREF 1 \s 4. SEQ Таблица \* ARABIC \s 1 10 Расчёт затрат на тиражирование единицы продукта и договорной цены
|
Статья затрат |
Цена, грн. |
|
Материалы и ПКИ |
51,39 |
|
ФОТ программиста (на тиражирование) |
32,04 |
|
Затраты на рекламу |
80,00 |
|
Отчисления в пенсионный фонд (32% от ФОТ) |
10,25 |
|
Отчисления в соц. страх (2,5% ФОТ) |
0,80 |
|
Отчисления в фонд безработицы (2,5% от ФОТ) |
0,80 |
|
Аренда компьютера |
- |
|
ИТОГО затраты на тиражирование единицы продукта: |
175,28 |
|
Затраты на разработку единицы продукта |
32,05 |
|
Себестоимость одной копии |
207,33 |
|
Прибыль 20-50% |
103,66 |
|
Договорная цена |
311,00 |
|
Размер НДС (20% от ДЦ) |
62,20 |
|
Цена продукции с учетом НДС |
373,20 |
|
Налог на прибыль (30% от п.11) |
32,00 |
|
Чистая прибыль |
71,66 |
4.4
"Реклама – двигатель торговли", т.е. необходима реклама для реализации продукта «Система поддержки принятия маркетинговых решений», на выставках-продажах, с помощью газет, радио и телевидения, в специализированных изданиях, справочниках, а также с помощью дилеров. Реклама с помощью дилеров будет построена следующим образом. Дилеры находят потенциальных потребителей товара и предлагают бесплатно оказать помощь в разработке системы обработки информации. При этом необходимо указать, будет ли система надежной и простой в эксплуатации, достаточно эффективной, и будет ли разработана в кратчайшие сроки. Для получения системы с такими характеристиками предлагается купить программный продукт “Система поддержки принятия маркетинговых решений ”. Демонстрируются возможности этого продукта. Для этого выполняют часть работ по разработке системы, они должны быть произведены "мгновенно" и обладать достаточной эффективностью, высокой надежностью и простым пользовательским интерфейсом.
Реклама данного продукта будет проходить следующим образом. Представителями предприятия будут разосланы материалы о продукте. В этих материалах будет рассказано о продукте, будет предложена помощь в разработке системы обработки информации. При этом необходимо указать, что система является надежной и простой в эксплуатации, достаточно эффективной и разработана в кратчайшие сроки. Заинтересовавшимся потребителям будут продемонстрированы возможности этого продукта.
При продаже копии продукта организуют его послепродажное обслуживание, которое заключается в следующем:
·
·
·
· с ошибками на исправленную версию;
·
Для стимулирования сбыта товара предлагается применять следующую систему скидок:
·
·
·
4.5
Для определения минимального объема продаж, обеспечивающего прибыль, строим график безубыточности. На графике безубыточности отражают четыре зависимости:
·
·
·
·
Как видно из рисунка ( REF _Ref371875564 \h Рис. 4.1), точкой безубыточности на графике будет точка пересечения кривой прибыли TR(q) и кривой суммарных затрат TC(q). Она получается при продаже одной копии программного продукта при общей емкости рынка 15 шт., что свидетельствует о прибыльности разработки.
В результате проведенных расчетов можно сделать вывод о целесообразности разработки, производства и сбыта программного продукта “Система поддержки принятия маркетинговых решений”. Данный программный продукт конкурентоспособен.
Рис. STYLEREF 1 \s 4. SEQ Рис. \* ARABIC \s 1 1 График безубыточности
5.
5.1 условий труда
Проектирование разработанной системы велось в помещении,
имеющем размеры (6×6×3). Площадь
помещения
В помещении образована система «Человек – Машина – Среда». Выделим следующие элементы:
·
·
·
Согласно ДНАОП 0.00-1.31-99 [ REF _Ref24997410 \r \h 2, объем воздушного пространства 20м3. Следовательно, помещение, имеющее размеры (6×6×3) удовлетворяет этим требованиям.
В системе (ЧМС), при определенных условиях могут возникать следующие опасности: аномальный микроклимат, выполнение тяжелой умственной работы, недостаточная освещенность рабочего места, опасность поражения электрическим током.
Применительно к системе ЧМС при структурном подходе в качестве элементов выделяются человек-оператор и управляемая им техника (в данном случае ЭВМ), а при функциональном подходе – операции, осуществляемые человеком и техникой.
Основной особенностью системы защиты является то, что на результат ее работы влияет как поведение людей, так и состояние техники. Поэтому для нее характерен равноэлементный подход к анализу объекта исследования, когда человек и техника рассматриваются как равнозначные элементы системы.
В общем виде, взаимодействие работающих с производственной средой можно представить в виде некоторой кибернетической системы ЧМС ( REF _Ref371877997 \h 5.1
Под «машиной» в системе ЧМС понимается совокупность технических средств, используемых человеком оператором. В нашем случае это ЭВМ.
В данном случае под средой подразумеваются микроклиматические условия помещения, окружающее оборудование и другие материальные компоненты, а также отношения в коллективе, здоровье работающих, психологическая совместимость коллектива и пр.
«Человек-оператор» – это человек, осуществляющий трудовую деятельность, основу которой составляет управление объектом (процессом) с помощью информационной модели.
Рис. STYLEREF 1 \s 5. SEQ Рис. \* ARABIC \s 1 1 Структура системы ЧМС
1 – влияние «человека» на «среду»; 2 – влияние «среды» на физиологическое состояние «человека»; 3 – влияние «среды» на качество работы «человека»; 4 – влияние «машины» на состояние «среды»; 5 – влияние «среды» на качество работы машины; 6 – влияние «машины» на физиологическое состояние «человека»; 7 – связь выполняемой работы с физиологическим состоянием организма; 8 – влияние характера труда на интенсивность обмена веществ; 9 – взаимодействие людей между собой.
|
2 |
|
2 |
|
2 |
|
2 |
|
7 7 |
|
7 7 |
|
3 3 |
|
1 1 |
|
1 1 |
|
3 3 |
|
4 5 9 4 5 9 |
|
5 5 |
|
5 |
|
4 |
|
4 |
|
6 |
|
6 |
|
3 |
|
1 |
|
3 |
|
1 |
|
7 |
|
7 |
|
8 |
|
8 |
|
8 |
|
8 |
|
9 |
|
9 4 5 |
|
9 |
|
Человек (1) |
|
Ч1 Ч2 Ч3 |
|
Человек (2) |
|
Ч3 Ч2 Ч1 |
|
Человек (4) |
|
Ч3 Ч2 Ч1 |
|
Человек (3) |
|
Ч1 Ч2 Ч3 |
|
Машина |
|
Машина |
|
Машина |
|
Машина |
|
Среда |
Таблица STYLEREF 1 \s 5. SEQ Таблица \* ARABIC \s 1 1 Влияние ОВПФ на человека.
|
ОВПФ |
Источник |
Действие ОВПФ на человека |
Значение ОВПФ |
|
1 |
2 |
3 |
4 |
|
Вибрация, шум, ультразвук |
Внешняя среда, устройства документирования, устройства связи и передачи информации, средства оргтехники, люди |
Общие вибрации оказывают влияние на всё тело человека, местные – воздействуют на внутренние органы. Ультразвук влияет на снижение работоспособности человека. Шум воздействует на органы слуха. Вызывает раздражение, создает неудобство, речевого общения, снижает производительность труда, может быть причиной снижения слуха |
65 дБ(А) |
|
Недостаточная освещённость рабочего места |
Недостаточные размеры оконных проёмов, неправильно выполненное искусственное освещение, работа в тёмное время суток, солнечная радиация |
Правильно организованное освещение повышает работоспособность, недостаток ведёт к утомлению зрения и всего организма в целом, следствием чего может стать снижение работоспособности и ухудшение зрения |
200 лк |
|
Повышенная или пониженная температура воздуха |
Люди, система отопления, внешняя среда |
Вызывает ухудшение самочувствия работников и как следствие, снижение производительности труда |
>26°С |
|
Повышенное значение напряжения в электрической цепи, замыкание которой может произойти через тело человека |
Повреждённая изоляция электрических проводов, корпуса электрооборудования |
Поражение электрическим током, электротравмы и электроудары |
В помещении выполнено зануление с повторным заземлением нейтрали |
|
Электромагнитное излучение |
Монитор. |
Может вызвать снижение работоспособности, быструю утомляемость, головную боль |
<7 в/м |
|
Монотонность труда |
Однообразная работа |
Снижение внимательности, приводит к появлению брака и производственному травматизму |
|
|
Статические перегрузки. |
Длительное пребывание в одной позе |
Снижение работо-способности, развитие утомления |
|
|
Умственные перегрузки |
Неправильно организованный отдых |
Снижение работоспособности, утомление |
При анализе таблицы можно сделать вывод, что в данном помещении освещенность не удовлетворяет нормам. Следовательно, необходимо производить расчет освещенности.
5.2
В рассматриваемом помещении трехфазная сеть напряжением 220/380В с глухозаземленной нейтралью, частотой 50 Гц. В помещении выполнено зануление с повторным заземлением нейтрали.
Поражение человека электрическим током может иметь место в следующих случаях:
·
·
Согласно ПУЭ, рассматриваемое помещение по степени опасности поражения электрическим током относится к категории помещений без повышенной опасности, так как в помещении отсутствует сырость (относительная влажность воздуха до 60%) и токопроводящие полы (пол деревянный), токопроводящая пыль, отсутствует высокая температура и металлоконструкции здания, имеющие соединение с землей, закрыты деревянными решетками.
При работе в производственном помещении в целях предотвращения электротравматизма необходимо проводить ряд организационных и технических мероприятий, установленных действующими ПУЭ и стандартами. К организационным мероприятиям относится инструктаж.
Согласно ДНАОП 0.04-4.12-94 [ REF _Ref24997465 \r \h
·
·
·
Результаты инструктажей необходимо регистрировать в специальных журналах с росписью инструктируемого и инструктирующего.
Согласно ДНАОП 0.04 - 4.12 – 94 при необходимости могут быть и другие виды инструктажей.
Контроль состояния электрической сети и изоляции необходимо проводить 1 раз в год. При этом сопротивление изоляции не должно быть менее 0.5 МОм.
При выполнении технических мероприятий необходимо руководствоваться ПУЭ – 85 [ REF _Ref24997486 \r \h REF _Ref24997505 \r \h
5.3
Работы в производственном помещении согласно ГОСТ 12.1.005-88 [ REF _Ref24997528 \r \h
Таблица STYLEREF 1 \s 5 SEQ Таблица \* ARABIC \s 1 2Нормированные параметры микроклимата.
|
Период года |
Температура оС |
Относительная влажность, % |
Скорость движения воздуха, м/с |
|||
|
опт |
доп |
опт |
доп |
опт |
доп |
|
|
Холодный |
22-24 |
19-25 |
40-60 |
£ 75 |
£ 0.1 |
£ 0.1 |
|
Теплый |
23-25 |
22-28 |
40-60 |
£ 55 |
£ 0.1 |
0.1-0.2 |
Большое влияние на микроклимат оказывают источники теплоты, которыми являются ЭВМ и вспомогательное оборудование, приборы освещения, обслуживающий персонал. Необходимо учитывать и внешние источники тепла. К ним относят теплоту, поступающую через окна от солнечной радиации и приток теплоты через непрозрачные ограждающие конструкции. Т.к. в помещении в летнее время t>260C, то для поддержания установленных норм микроклимата в помещении необходимо применять кондиционеры. Применим кондиционер Samsung AQ12A1ME (SPLIT) с трубами, имеющий следующие характеристики:
·
·
·
·
В холодный период времени указанные метеоусловия поддерживаются системой центрального отопления.
Работы, выполняемые в помещении, относятся к работам
высокой точности. Размеры объекта различия 0.3 –
Расчет выполняется по методу коэффициента использования светового потока.
Необходимое значение светового потока определяется по формуле
(4.1)
где S – площадь помещения,
E – нормируемое значение освещённости, 400 лк;
z – коэффициент неравномерности, z = 1.1 – 1.2;
k – коэффициент запаса, который учитывает снижение освещенности k = 1.5;
ŋ – коэффициент использования светового потока.
n – число рядов светильников.
N – число светильников в ряду.
Для учёта размеров помещения и высоты подвеса светильников вычисляем индекс помещения
(4.2)
где hp = h - h0 - hсв – высота подвеса светильника над рабочей поверхностью;
h – высота помещения;
h0 – высота рабочей поверхности,
hсв – подвес светильника,
Подставив числовые значения, получим:
hp = 3 - 0.1 - 0.8 =
Т.к. помещение безпыльное, то коэффициенты отражения поверхностей помещения: потолка 70%, стен 50%, пола 30%.
С учетом индекса помещения и коэффициента отражения, коэффициент использования светового потока ŋ = 0.49.
Расстояние между рядами светильников:
L = λ·hp (4.3)
где λ – характерное расстояние между рядами (зависит от типа светильника и коэффициента z: при z = 1.1 для светильника УЛВИ – 4 λ = 1.3 – 1.4).
L = 1.3·2.1 =
Располагаем светильники вдоль короткой стороны помещения. Число рядов определяем по формуле
(4.4)
Расстояние между стеной и крайним светильником:
l=(0.3..0.5)L
l=0.3∙2.73=0,82 м.
Число светильников в ряду
(4.5)
где Fсв – световой поток всех ламп светильника.
Для светильника типа УЛВН – 4 с люминесцентными лампами ЛБ – 40 номинальный световой поток лампы Fл=2900 лм. Тогда номинальный световой поток всех ламп светильника
Fсв=4·Fл,
Fсв=4·2900=11600 лм.
Определим число светильников в ряду по формуле (4.5)
При длине одного светильника lсв=1.33 м общая длина
Lсв=3·1.33=3.99 м.
Это значение меньше ширины помещения (6м).
Выполним проверку геометрических размеров
L(n-1)+2l<А
2.73(2-1)+2·0.82=4.37.
Потребляемая светильником мощность
(4.6)
где nл – число ламп в светильнике; Рл – мощность потребляемая лампой.
Тогда ток в сети
(4.7)
где Uc – напряжение в сети. Uc=220 В.
Сечение проводов по экономической плотности тока согласно ПУЭ рассчитывается по формуле
(4.8)
где gэ – экономическая плотность, gэ=1.4 А/мм2. Тогда
Выбираем алюминиевые провода с поливинилхлоридной изоляцией сечением 4 мм2. Провода скрыты под штукатуркой.
Организация рабочего каждого места должна обеспечивать
соответствие всех элементов рабочего места и их расположения эргономическим
требованиям в соответствии с [
REF _Ref24998497 \r \h
План размещения светильников изображён на REF _Ref371876734 \h 5.2
SHAPE \* MERGEFORMAT
|
1,15 |
|
1,15 |
|
3,7 |
|
6 м |
|
6 м |
Рис. STYLEREF 1 \s 5. SEQ Рис. \* ARABIC \s 1 2 План размещения светильников
Для уменьшения перегрузки зрительных анализаторов экран
видеотерминала расположить на оптимальном расстоянии от глаз: при размере экрана
по диагонали
Трудовая деятельность в НИЛ относится к группе В (отладка программ, перевод и редактирования и др.) и установлена 8-часовая рабочая смена, иначе – продолжительность работ группы В превышает 4 ч и выполняемые работы относятся к III категории работ. Для уменьшения действия психофизиологических ОВФ (умственное перенапряжение, монотонность труда и эмоциональные перегрузки) для данной категории работ следует установить перерывы по 20 мин каждый через 2 ч после начала работ, через 1,5 ч и 2, 5 ч после обеденного перерыва или же по 5-15 мин через каждый час работы. Общая продолжительность перерывов (не считая обеденного) за 8-часовый день должна составлять 60 мин.
5.4
НИЛ расположена в здании, выполненном из железобетонных конструкций, при работе здесь применяются твердые сгораемые материалы, в помещении находятся твердые и волокнистые горючие вещества. Поэтому согласно СНиП 2.01.02-85 [ REF _Ref24997836 \r \h REF _Ref24997486 \r \h REF _Ref24997836 \r \h
Причиной пожара в НИЛ могут быть короткое замыкание электропроводки; неисправность ПЭВМ и другого электрооборудования; нагрев проводников; курение в неположенном месте.
Для предупреждения пожара необходимо проводить ряд технических и организационных мероприятий, направленных на соблюдение установленного режима эксплуатации электрической сети, оборудования и соблюдения правил пожарной профилактики.
В соответствии с требованиями ГОСТ 12.1.004-91 [ REF _Ref24997906 \r \h REF _Ref24997921 \r \h REF _Ref24997836 \r \h
·
·
·
·
·
·
·
·
В помещении 4 работающих, поэтому эвакуацию при пожаре следует проводить через рабочий выход. Дополнительного эвакуационного выхода помещение не имеет и его не требуется. Схему эвакуации разместить на видном месте у выхода из помещения (схема показана на REF _Ref24997756 \h 5.3
SHAPE \* MERGEFORMAT
|
Шкаф |
|
маршрут эвакуации |
|
Выход на лестницу |
|
Световые (оконные) проемы |
|
6 м |
|
1,5 м |
|
1 м |
|
1,5 м |
|
1 м |
|
1,5 м |
|
1,5 м |
|
2 м |
|
0,1 м |
|
Рабочее место 1 |
|
Рабочее место 2 |
|
Рабочее место 3 |
|
Рабочее место 4 |
|
Принтер |
|
2 |
Рис. STYLEREF 1 \s 5. SEQ Рис. \* ARABIC \s 1 3 Размещение рабочих мест и маршрут эвакуации при пожаре.
Выводы
В ходе выполнения настоящей дипломной работы была проведен следующий объем работ и получены такие результаты:
·
·
·
·
·
·
·
·
Разработанный и опробованный на практике в составе в учетно-аналитической системы программ «1С: Предприятие 7.7» модуль прогнозирующей системы может быть применен в качестве СППР при осуществлении хозяйственной деятельности, связанной с ведением оптово-розничной торговли. Применение данной системы при планировании закупок повышает эффективность распределения средств и снижает вероятность финансовых потерь, что, в конечном итоге, выражается в положительном экономическом результате.
Перечень ссылок
1.
2.
3. Knowledge Discovery Through Data Mining: What Is Knowledge Discovery? – Tandem Computers Inc., 1996.
4. Boulding K. E. General Systems Theory – The Skeleton of Science//Management Science, 2, 1956.
5.
6.
7.
Montgomery Montgomery , Lynwood
8. Горбань А. Н., Россиев Д. А. Нейронные сети на персональном компьютере. Новосибирск: Наука. Сибирская издательская фирма РАН. 1996. 276 с.
9. Ширяев А. Н. Статистический последовательный анализ. –М.: Наука. 1969. 229с.;
10. Никифоров И. В. Последовательное обнаружение изменения свойств временных рядов. –М.: Наука, 1983. 199с.
11. Takens F. Distinguishing deterministic and random systems // Nonlinear dynamics and turbulence. Ed. G. I. Barenblatt, G. Jooss, D. D. Joseph. N. Y.: Pitman, 1983. P. 314–333.
12. Bernard Widrow, Michael A. Lehr. 30 Years of Adaptive Neural Networks: Perceptron, Madaline, and Back propagation //Artificial Neural Networks: Concepts and Theory, IEEE Computer Society Press, 1992, pp.327-354.
13.
14.
15. Bardcev S.I., Okhonin V.A. The algorithm of dual functioning (back-propagation): general approach, vesions and applications. Krasnojarsk: Inst. of biophysics SB AS USSA - 1989.
16. Computing with neural circuits: a model.//Science, 1986.V. 233. p. 625-633.
17.
Kuzewski
Robert M., Myers Michael H., Grawford William J. Exploration of four word error
propagation as self organization structure.//IEEE Ist. Int. Conf. Neural
Networks, San Diego , Calif. June 21-24, 1987 .
V. 2. - San Diego , Calif.
18. Rumelhart B.E., Minton G.E., Williams R.J. Learning representations by back propagating error.// Wature, 1986. V. 323. p. 1016-1028.
19.
Takefuji
D.Y. A new model of neural networks for error correction.//Proc. 9th Annu Conf.
IEEE Eng. Med. and Biol. Soc., Boston, Mass., Nov. 13-16, 1987. V. 3, New York , N.Y.
20. Sankar K. Pal, Sushmita Mitra, Multilayer Perceptron, Fuzzy Sets, and Classification //IEEE Transactions on Neural Networks, Vol.3, N5,1992, pp.683-696.
21.
22. Statistica Neural Networks: Пер. с англ. –М.: Горячая линия – Телеком. 2000. –182с., ил.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36. Персептрон – системы распознавания образов.// К.: Наукова думка, 1972.
37. Нейронная сеть предсказывает курс доллара?// Компьютеры + программы – 1993 – N 6(7) – с. 10-13.
38.
39.
40. Пейперт С. Персептроны. –М.: Мир. 1971. 261с.
41. 1965. N 5. с. 40-50.
42. Принципы нейродинамики. –М.: Мир, 1965.
43.
44.
45.
46.
47.
48.
49. Батуро А. П. Кусочное прогнозирование и проблема обнаружения предвестников существенного изменения закономерности // Нейроинформатика и ее приложения: Материалы IX Всероссийского семинара / Под общ. ред. А. Н. Горбаня. Отв. за вып. Г. М. Цибульский. Красноярск: ИПЦ КГТУ, 2001. с. 15 – 16.
50. Carpenter G.A., Grossberg S. A massively parallel architecture for a self-organizing neural pattern recognition machine.//Comput. Vision Graphics Image Process. 1986. V. 37. p. 54-115.
51. Cohen M.A., Grossberg S. Absolute stability of global pattern formation and parallel memory storage by competitive neural networks//IEEE Trans. Syst., Man, Cybern. 1983. V. 13. N 5. P. 815-826.
52. Dayhoff J. Neural network architectures.//New-York:Van Nostrand reinhold, 1991.
53. Fogelman Soulie F. Neural networks,
state of the art, neural computing.// London
54. Fox G.C., Koller J.G. Code generation by a generalized neural networks: general principles and elementary examples.//J. Parallel Distributed Comput. 1989. V. 6. N 2. P. 388-410.
55. Hebb D.O. The organization of behaviour. N.Y.: Wiley, 1949.
56. Hopfield J.J. Neural networks and physical systems with emergent collective computational abilities.//Proc. Natl. Acad. Sci. 1984. V. 9. p. 147-169.
57. Hopfield J.J., Feinstein D.I., Palmer F.G. Unlearning has a stabilizing effect in collective memories//Nature. 1983. V.304. P. 141-152.
58. Hopfield J.J., Tank D.W. Neural computation of decision in optimization problems//Biol. Cybernet. 1985. V. 52. P. 141-152.
59. Rosenblatt F. The perseptron: a probabilistic model for information storage and organization in the brain//Psychol. Rev. 1958. V. 65. P. 386.
60.
Rosenblatt
F. Principles of neurodynamics. Spartan. ,
Washington
61. Бизнес-план - Ваша путеводная звезда. Для чего он нужен? Как его составить? Как им пользоваться? // Экономика и жизнь.-1991.- N 33.
62. Современный маркетинг /Под.ред. Е.К.Хруцкого.-М.:Прогресс,1991.
63. Котлер Дж. Маркетинговые исследования. – М.: Финансы и статистика, 1991.
64.
65. Правила охорони праці при експлуатації ЕОМ.
66.
67.
68.
69. .
70.
71.
72.
73.
74.
75.
76.
77.
78.
79.
80.
81.
82.
83.
84.
85.
Приложение А. Исходный код библиотеки ActiveX
Листинг 1 Файл Проекта NeroNet (ActiveX библиотека)
library NeroNet;
uses
ComServ,
Project1_TLB in 'Project1_TLB.pas',
Unit1 in '..\..\..Diplom Shevchenko\Unit1.pas' {ccsws: ActivXNeroObject};
exports
DllGetClassObject,
DllCanUnloadNow,
DllRegisterServer,
DllUnregisterServer;
{$R *.TLB}
{$R *.RES}
begin
end.
unit NeroNet.TLB;
{$TYPEDADDRESS OFF} // Unit must be compiled without type-checked pointers.
{$WARN SYMBOL_PLATFORM OFF}
{$WRITEABLECONST ON}
interface
uses ActiveX, Classes, Graphics, StdVCL, Variants, Windows;
// *********************************************************************//
// GUIDS declared in the TypeLibrary. Following prefixes are used:
// Type Libraries : LIBID_xxxx
// CoClasses : CLASS_xxxx
// DISPInterfaces : DIID_xxxx
// Non-DISP interfaces: IID_xxxx
// *********************************************************************//
const
// TypeLibrary Major and minor versions
Project1MajorVersion = 1;
Project1MinorVersion = 0;
LIBID_Project1: TGUID = '{84A0AF3F-B810-411A-B497-56A09CCA4ADF}';
IID_Iccsws: TGUID = '{4F689093-B2E4-41DF-A721-A66D3EB038D2}';
CLASS_ccsws: TGUID = '{AD17176A-01C0-4121-B709-F23C6365DC55}';
type
Iccsws = interface;
ccsws = Iccsws;
// *********************************************************************//
// Interface: Iccsws
// Flags: (256) OleAutomation
// GUID: {4F689093-B2E4-41DF-A721-A66D3EB038D2}
// *********************************************************************//
Iccsws = interface(IUnknown)
['{4F689093-B2E4-41DF-A721-A66D3EB038D2}']
end;
Coccsws = class
class function Create: Iccsws;
class function CreateRemote(const MachineName: string): Iccsws;
end;
implementation
uses ComObj;
class function Coccsws.Create: Iccsws;
begin
Result := CreateComObject(CLASS_ccsws) as Iccsws;
end;
class function Coccsws.CreateRemote(const MachineName: string): Iccsws;
begin
Result := CreateRemoteComObject(MachineName, CLASS_ccsws) as Iccsws;
end;
end.
Листинг 2 Библиотека ActivXNeroObject
unit Neural Net1;
{$WARN SYMBOL_PLATFORM OFF}
interface
uses
Windows, ActiveX, Classes, ComObj, Project1_TLB, StdVcl, NeuralBaseComp;
NeuralLibrary;
type
ActivXNeroObject = class(TTypedComObject, NeroCom)
protected
NeroNet : TLayerBP;
public
procedure StartCalculations;
end;
implementation
uses ComServ;
initialization
ActivXNeroObject.Create(ComServer, Tccsws, Class_ccsws,
ciMultiInstance, tmApartment);
procedure ActivXNeroObject.Create(ComServer, Tccsws, Class_ccsws,ciMultiInstance, tmApartment);
begin
StartCalculations;
end
procedure ActivXNeroObject.StartCalculations;
var
LibSystem : TLibSystem;
begin
NeroNet = TLayerBP.Create;
LibSystem.LoadData(NeroNet,'DataFile');
LibSystem.StartNet(NeroNet);
end;
end.
Листинг 3
unit NeroPas;
interface
const
DefaultAlpha = 1; // Параметр крутизны активационной функции
DefaultEpochCount = 10000; // Количество эпох для обучения
DefaultErrorValue = 0.05; // Ошибка по умолчанию для всех видов
DefaultHopfLayerCount = 2; // Количество слоев в сети Хопфилда
DefaultLayerCount = 0; // Минимальное количество слоев в сети back-propagation
DefaultMaxIterCount = 10; // Максимальное количество итераций в алгоритме Хопфилда
DefaultMomentum = 0.9; // Импульс - момент
DefaultNeuronCount = 0; // Количество нейронов в скрытом слое по умолчанию
DefaultPatternCount = 0; // Количество примеров
DefaultTeachRate = 0.1; // Скорость обучения
DefaultTeachIdentCount = 100; // Требуемый процент распознанных примеров из обучающего множества
DefaultTestIdentCount = 100; // Требуемый процент распознанных примеров из тестового множества
DefaultUseForTeach = 100; // Процент примеров используемых в качестве обучающего множества
DefaultDeltaBarAcceleratingConst = 0.095;
DefaultDeltaBarDecFactor = 0.85;
DefaultRPropInitValue = 0.1;
DefaultRPropMaxStepSize = 50;
DefaultRPropMinStepSize = 1E-6;
DefaultRPropDecFactor = 0.5;
DefaultRPropIncFactor = 1.2;
DefaultSuperSABDecFactor = 0.5;
DefaultSuperSABIncFactor = 1.05;
SensorLayer = 0; // Сенсорный слой
BiasNeuron = 1; // Смещение в сети back-propagation
Separators = ['.', ','];
Letters = ['a'..'z'];
Capitals = ['A'..'Z'];
DigitChars = ['0'..'9'];
SpaceChar = #9;
resourcestring
SFieldNorm = 'Не существует типа нормализации %d';
SFieldKind = 'Не существует типа поля %d';
SFieldIndexRange = 'Неправильно указан номер поля %d';
SInFieldCount = 'Неправильно установлено количество входных полей';
SInNeuronCount = 'Неправильно установлено количество входных нейронов';
SInVectorCount = 'Неправильно установлена размерность входного вектора';
SLayerRangeIndex = 'Неправильно указан номер слоя %d';
SNeuronRangeIndex = 'Неправильно указан номер нейрона %d';
SNeuronCount = 'Неправильно указано количество нейронов';
SOutFieldCount = 'Неправильно установлено количество выходных полей';
SOutNeuronCount = 'Неправильно установлено количество выходных нейронов';
SOutVectorCount = 'Неправильно установлена размерность выходного вектора';
SPatternRangeIndex = 'Выход за границы массива примеров %d';
SStreamCannotRead = 'Ошибка чтения из потока';
SWeightRangeIndex = 'Неправильно указан номер веса %d';
SWrongFileName = 'Неправильно указано имя файла %s';
SCannotBeNumber = 'Ошибка, выражение %s невозможно привести к числовому типу';
SBPStopCondition = 'Не задано условие останова процесса обучения';
type
TVectorInt = array of integer;
TVectorFloat = array of double;
TVectorString = array of string;
TMatrixInt = array of array of integer;
TMatrixFloat = array of array of double;
TNormalize = (nrmLinear, nrmSigmoid, nrmAuto, nrmNone,
nrmLinearOut, nrmAutoOut);
TNeuroFieldType = (fdInput, fdOutput, fdNone);
implementation
end.
Листинг 4 Основной файл проекта NeroSys
unit NeroSys;
interface
uses
Windows, Messages, SysUtils, Classes, Graphics, Controls,
Forms, Dialogs, PumpData, NeuralBaseTypes, IniFiles, Math;
type
// Классы исключений
EInOutDimensionError = class(Exception);
ENeuronCountError = class(Exception);
ENeuronNotEqualFieldError = class(Exception);
EBPStopCondition = class(Exception);
// Процедурные типы
TActivation = function (Value: double): double of object;
// Упреждающее объявление классов
TNeuron = class;
TLayer = class;
// Базовый класс нейрона
TNeuron = class(TObject)
private
FOutput: double;
// Вектор весов
FWeights: TVectorFloat;
// Указатель на слой в котором находится нейрон just in case
Layer: TLayer;
function GetWeights(Index: integer): double;
procedure SetWeights(Index: integer; Value: double);
procedure SetWeightCount(const Value: integer);
public
constructor Create(ALayer: TLayer); virtual;
destructor Destroy; override;
// Инициализация весов
procedure InitWeights; virtual;
// Взвешенная сумма
procedure ComputeOut(const AInputs: TVectorFloat); virtual;
property Output: double read FOutput write FOutput;
property WeightCount: integer write SetWeightCount;
property Weights[Index: integer]: double read GetWeights write SetWeights;
end;
// Класс нейрона для сети back-propagation
TNeuronBP = class(TNeuron)
private
// Локальная ошибка
FDelta: double;
// Значение скорости обучения на предыдущей эпохе
FLearningRate: TVectorFloat;
// Значение частной производной на предыдущей эпохе
FPrevDerivative: TVectorFloat;
// Значение коррекции веса на предыдущей эпохе
FPrevUpdate: TVectorFloat;
// Функция активации
FOnActivationF: TActivation;
// Производная функции активации
FOnActivationD: TActivation;
function GetPrevUpdate(Index: integer): double;
function GetPrevDerivative(Index: integer): double;
function GetLearningRate(Index: integer): double;
function GetPrevUpdateCount: integer;
procedure SetPrevDerivative(Index: integer; const Value: double);
procedure SetPrevDerivativeCount(const Value: integer);
procedure SetDelta(Value: double);
procedure SetPrevUpdate(Index: integer; Value: double);
procedure SetPrevUpdateCount(const Value: integer);
procedure SetLearningRate(Index: integer; const Value: double);
procedure SetLearningRateCount(const Value: integer);
public
destructor Destroy; override;
procedure ComputeOut(const AInputs: TVectorFloat); override;
property Delta: double read FDelta write SetDelta;
property LearningRate[Index: integer]: double read GetLearningRate write SetLearningRate; // Delta-Bar-Delta, SuperSAB
property LearningRateCount: integer write SetLearningRateCount;
property PrevDerivativeCount: integer write SetPrevDerivativeCount;
property PrevDerivative[Index: integer]: double read GetPrevDerivative write SetPrevDerivative; // QuickProp, Delta-Bar-Delta, SuperSAB
property PrevUpdateCount: integer read GetPrevUpdateCount write SetPrevUpdateCount;
property PrevUpdate[Index: integer]: double read GetPrevUpdate write SetPrevUpdate;
property OnActivationF: TActivation read FOnActivationF write FOnActivationF;
property OnActivationD: TActivation read FOnActivationD write FOnActivationD;
end;
// Базовый класс слоя
TLayer = class(TPersistent)
private
FNumber: integer;
// Размерность NeuronCount
FNeurons: array of TNeuron;
function GetNeurons(Index: integer): TNeuron;
function GetNeuronCount: integer;
procedure SetNeurons(Index: integer; Value: TNeuron);
procedure SetNeuronCount(Value: integer);
public
constructor Create(ALayerNumber: integer; ANeuronCount: integer); virtual;
destructor Destroy; override;
procedure Assign(Source: TPersistent); override;
property Neurons[Index: integer]: TNeuron read GetNeurons write SetNeurons;
property NeuronCount: integer read GetNeuronCount write SetNeuronCount;
end;
// Класс слоя для сети back-propagation
TLayerBP = class(TLayer)
private
function GetNeuronsBP(Index: integer): TNeuronBP;
procedure SetNeuronsBP(Index: integer; Value: TNeuronBP);
public
constructor Create(ALayerNumber: integer; ANeuronCount: integer); override;
destructor Destroy; override;
procedure Assign(Source: TPersistent); override;
property NeuronsBP[Index: integer]: TNeuronBP read GetNeuronsBP write SetNeuronsBP;
end;
// Базовый класс сети
TNeuralNet = class(TComponent)
private
// Массив слоев
FLayers: array of TLayer;
// Число выборок
FPatternCount: integer;
// Размерность FPatternCount, InputNeuronCount
FPatternsInput: TMatrixFloat;
// Размерность FPatternCount, OutputNeuronCount
FPatternsOutput: TMatrixFloat;
function GetLayers(Index: integer): TLayer;
function GetOutputNeuronCount: integer;
function GetPatternsOutput(PatternIndex: integer; OutputIndex: integer): double;
function GetPatternsInput(PatternIndex: integer; InputIndex: integer): double;
procedure SetLayers(Index: integer; Value: TLayer);
procedure SetPatternsInput(PatternIndex: integer; InputIndex: integer; Value: double);
procedure SetPatternsOutput(PatternIndex: integer; InputIndex: integer; Value: double);
protected
function GetLayerCount: integer; virtual;
function GetInputNeuronCount: integer; virtual;
procedure Clear; virtual;
procedure ResizeInputDim; virtual;
procedure ResizeOutputDim; virtual;
procedure SetPatternCount(const Value: integer); virtual;
procedure SetLayerCount(Value: integer); virtual;
property PatternCount: integer read FPatternCount write SetPatternCount;
public
destructor Destroy; override;
procedure AddLayer(ANeurons: integer); virtual; abstract;
procedure AddPattern(const AInputs: TVectorFloat; const AOutputs: TVectorFloat); overload; virtual;
procedure DeleteLayer(Index: integer); virtual; abstract;
procedure DeletePattern(Index: integer); virtual;
procedure Init(const ANeuronsInLayer: TVectorInt); overload; virtual;
property InputNeuronCount: integer read GetInputNeuronCount;
property LayerCount: integer read GetLayerCount write SetLayerCount;
property Layers[Index: integer]: TLayer read GetLayers write SetLayers;
property OutputNeuronCount: integer read GetOutputNeuronCount;
property PatternsInput[PatternIndex: integer; InputIndex: integer]: double read GetPatternsInput write SetPatternsInput;
property PatternsOutput[PatternIndex: integer; InputIndex: integer]: double read GetPatternsOutput write SetPatternsOutput;
procedure ResetPatterns; virtual;
end;
// Класс сети back-propagation
TNeuralNetBP = class(TNeuralNet)
private
// Коэффициент крутизны пороговой сигмоидальной функции
FAlpha: double;
// Флаг автоинициализации топологии сети
FAutoInit: boolean;
// Флаг продолжения обучения
FContinueTeach: boolean;
// Желаемый выход нейросети размерность OutputNeuronCount
FDesiredOut: TVectorFloat;
// Флаг остановки при достижении FEpochCount
FEpoch: boolean;
// Счетчик эпох (предъявление сети всех примеров из обучающей выборки)
FEpochCount: integer;
// Номер текущей эпохи
FEpochCurrent: integer;
// Значение ошибки, при которой пример считается распознанным
FIdentError: double;
// Значение максимальной ошибки на обучающем множестве
FMaxTeachResidual: double;
// Значение максимальной ошибки на тестовом множестве
FMaxTestResidual: double;
// Значение средней ошибки на обучающем множестве
FMidTeachResidual: double;
// Значение средней ошибки на тестовом множестве
FMidTestResidual: double;
// Ошибка на обучающем множестве
FTeachError: double;
// Коэффициент инерционности
FMomentum: double;
// Количество нейронов в слоях
FNeuronsInLayer: TStrings;
// Событие после инициализации
FOnAfterInit: TNotifyEvent;
FOnAfterNeuronCreated: TNotifyEvent;
// Событие после обучения
FOnAfterTeach: TNotifyEvent;
// Событие до инициализации
FOnBeforeInit: TNotifyEvent;
// Событие до начала обучения
FOnBeforeTeach: TNotifyEvent;
// Событие после прохождения одной эпохи
FOnEpochPassed: TNotifyEvent;
// Число примеров в обучающем множестве
FPatternCount: integer;
// Массив содержащий псевдослучайную последовательсность
FRandomOrder: TVectorInt;
// Счетчик распознанных примеров на обучающем множестве
FRecognizedTeachCount: integer;
// Счетчик распознанных примеров на обучающем множестве
FRecognizedTestCount: integer;
// Флаг остановки обучения
FStopTeach: boolean;
FTeachStopped: boolean;
// Коэффициент скорости обучения - величина градиентного шага
FTeachRate: double;
// Число примеров в тестовом множестве
FTestSetPatternCount: integer;
// Размерность FTestSetPatternCount, InputNeuronCount
FTestSetPatterns: TMatrixFloat;
// Размерность FTestSetPatternCount, InputNeuronCount
FTestSetPatternsOut: TMatrixFloat;
function GetDesiredOut(Index: integer): double;
function GetLayersBP(Index: integer): TLayerBP;
function GetTestSetPatterns(InputIndex, PatternIndex: integer): double;
function GetTestSetPatternsOut(InputIndex, PatternIndex: integer): double;
procedure NeuronCountError;
procedure NeuronsInLayerChange(Sender: TObject);
procedure SetAlpha(Value: double);
procedure SetDesiredOut(Index: integer; Value: double);
procedure SetEpochCount(Value: integer);
procedure SetLayersBP(Index: integer; Value: TLayerBP);
procedure SetMomentum(Value: double);
procedure SetTeachRate(Value: double);
procedure SetTestSetPatternCount(const Value: integer);
procedure SetTestSetPatterns(InputIndex, PatternIndex: integer; const Value: double);
procedure SetTestSetPatternsOut(InputIndex, PatternIndex: integer; const Value: double);
// Перетасовка набора данных
procedure Shuffle;
protected
function GetLayerCount: integer; override;
function GetOutput(Index: integer): double; virtual;
// Активационная функция
function ActivationF(Value: double): double; virtual;
// Производная активационной функции
function ActivationD(Value: double): double; virtual;
// Средняя квадратичная ошибка
function QuadError: double; virtual;
// Подстройка весов
procedure AdjustWeights; virtual;
// Рассчитывает локальную ошибку - дельту
procedure CalcLocalError; virtual;
// Проверка сети на тестовом множестве
procedure CheckTestSet; virtual;
procedure DoOnAfterInit; virtual;
procedure DoOnAfterNeuronCreated(ALayerIndex, ANeuronIndex: integer); virtual;
procedure DoOnAfterTeach; virtual;
procedure DoOnBeforeInit; virtual;
procedure DoOnBeforeTeach; virtual;
procedure DoOnEpochPassed; virtual;
// Инициализация весов сети псевдослучайными значениями
procedure InitWeights; virtual;
// Предъявление сети входных значений примера
procedure LoadPatternsInput(APatternIndex :integer); virtual;
// Предъявление сети входных значений примера
procedure LoadPatternsOutput(APatternIndex :integer); virtual;
// Распространяет сигнал в прямом направлении
procedure Propagate; virtual;
// Установка значений по умолчанию
procedure SetDefaultProperties; virtual;
procedure SetPatternCount(const Value: integer); override;
// Встряска сети
procedure ShakeUp; virtual;
property TeachStopped: boolean read FTeachStopped write FTeachStopped;
public
constructor Create(AOwner: TComponent); override;
destructor Destroy; override;
procedure AddLayer(ANeurons: integer); override;
procedure Compute(AVector: TVectorFloat); virtual;
procedure DeleteLayer(Index: integer); override;
procedure Init; reintroduce; overload;
procedure ResetLayers; virtual;
procedure TeachOffLine; virtual;
property DesiredOut[Index: integer]: double read GetDesiredOut write SetDesiredOut;
property EpochCurrent: integer read FEpochCurrent;
property IdentError: double read FIdentError write FIdentError;
property LayersBP[Index: integer]: TLayerBP read GetLayersBP write SetLayersBP;
property LayerCount: integer read GetLayerCount write SetLayerCount;
property Output[Index: integer]: double read GetOutput;
property StopTeach: boolean read FStopTeach write FStopTeach;
property TeachError: double read FTeachError;
property MaxTeachResidual: double read FMaxTeachResidual;
property MaxTestResidual: double read FMaxTestResidual;
property MidTeachResidual: double read FMidTeachResidual;
property MidTestResidual: double read FMidTestResidual;
property RecognizedTeachCount: integer read FRecognizedTeachCount;
property RecognizedTestCount: integer read FRecognizedTestCount;
property TestSetPatternCount: integer read FTestSetPatternCount write SetTestSetPatternCount;
property TestSetPatterns[InputIndex: integer; PatternIndex: integer]: double read GetTestSetPatterns write SetTestSetPatterns;
property TestSetPatternsOut[InputIndex: integer; PatternIndex: integer]: double read GetTestSetPatternsOut write SetTestSetPatternsOut;
published
property Alpha: double read FAlpha write SetAlpha;
property AutoInit: boolean read FAutoInit write FAutoInit;
property ContinueTeach: boolean read FContinueTeach write FContinueTeach;
property Epoch: boolean read FEpoch write FEpoch;
property EpochCount: integer read FEpochCount write SetEpochCount;
property Momentum: double read FMomentum write SetMomentum;
property NeuronsInLayer: TStrings read FNeuronsInLayer write FNeuronsInLayer;
property OnAfterInit: TNotifyEvent read FOnAfterInit write FOnAfterInit;
property OnAfterNeuronCreated: TNotifyEvent read FOnAfterNeuronCreated write FOnAfterNeuronCreated;
property OnAfterTeach: TNotifyEvent read FOnAfterTeach write FOnAfterTeach;
property OnBeforeInit: TNotifyEvent read FOnBeforeInit write FOnBeforeInit;
property OnBeforeTeach: TNotifyEvent read FOnBeforeTeach write FOnBeforeTeach;
property OnEpochPassed: TNotifyEvent read FOnEpochPassed write FOnEpochPassed;
property PatternCount: integer read FPatternCount write SetPatternCount;
property TeachRate: double read FTeachRate write SetTeachRate;
end;
// Класс сети back-propagation TNeuralNetExtended }
TNeuralNetExtended = class(TNeuralNetBP)
private
// Файл данных
FNeuroDataSource: TNeuroDataSource;
// Имя файла данных *.txt
FSourceFileName: TFileName;
// Имя конфигурационного файла *.nnw
FFileName: TFileName;
// Конфигурационный файл
FNnwFile: TIniFile;
// Поля
FFields: TNeuroFields;
// Количество доступных полей
FAvailableFieldsCount: integer;
FMaxTeachError: boolean;
FMaxTeachErrorValue: double;
FMaxTestError: boolean;
FMaxTestErrorValue: double;
FMidTeachError: boolean;
FMidTeachErrorValue: double;
FMidTestError: boolean;
FMidTestErrorValue: double;
FOptions: string;
FSettingsLoaded: boolean;
FTestAsValid: boolean;
FTeachIdent: boolean;
FTeachIdentCount: integer;
FTestIdent: boolean;
FTestIdentCount: integer;
FUseForTeach: integer;
FIdentError: double;
FRealOutputIndex: TVectorInt;
FRealInputIndex: TVectorInt;
function GetFields(Index: integer): TNeuroField;
function GetInputFieldCount: integer;
function GetOutputFieldCount: integer;
function GetRealInputIndex(Index: integer): integer;
function GetRealOutputIndex(Index: integer): integer;
procedure SetFields(Index: integer; Value: TNeuroField);
procedure SetFileName(Value: TFilename);
procedure SetAvailableFieldsCount(Value: integer);
procedure SetUseForTeach(const Value: integer);
procedure SetTeachIdentCount(const Value: integer);
procedure SetRealOutputIndex(Index: integer; const Value: integer);
procedure SetRealOutputIndexCount(const Value: integer);
procedure SetRealInputIndex(Index: integer; const Value: integer);
procedure SetRealInputIndexCount(const Value: integer);
protected
function GetOutput(Index: integer): double; override;
procedure DoOnBeforeTeach; override;
procedure DoOnEpochPassed; override;
procedure SetDefaultProperties; override;
public
constructor Create(AOwner: TComponent); override;
destructor Destroy; override;
procedure ComputeUnPrepData(AVector: TVectorFloat);
// Загружает данные из текстового файла
procedure LoadDataFrom;
// Загружает настройки сети
procedure LoadNetwork;
// Загружает настройки сети
procedure LoadPhase1;
// Загружает настройки сети
procedure LoadPhase2;
// Загружает настройки сети
procedure LoadPhase4;
// Нормализует набор данных
procedure NormalizeData;
// Сохраняет настройки сети
procedure SaveNetwork;
// Сохраняет настройки сети
procedure SavePhase1;
// Сохраняет настройки сети
procedure SavePhase2;
// Сохраняет настройки сети
procedure SavePhase4;
// Обучение нейронной сети
procedure Train;
property AvailableFieldsCount: integer read FAvailableFieldsCount write SetAvailableFieldsCount;
property Fields[Index: integer]: TNeuroField read GetFields write SetFields;
property InputFieldCount: integer read GetInputFieldCount;
property OutputFieldCount: integer read GetOutputFieldCount;
property SettingsLoaded: boolean read FSettingsLoaded write FSettingsLoaded;
property RealOutputIndex[Index: integer]: integer read GetRealOutputIndex write SetRealOutputIndex;
property RealOutputIndexCount: integer write SetRealOutputIndexCount;
property RealInputIndex[Index: integer]: integer read GetRealInputIndex write SetRealInputIndex;
property RealInputIndexCount: integer write SetRealInputIndexCount;
property NnwFile: TIniFile read FNnwFile write FNnwFile;
published
property FileName: TFileName read FFileName write SetFileName;
property IdentError: double read FIdentError write FIdentError;
property MaxTeachError: boolean read FMaxTeachError write FMaxTeachError;
property MaxTeachErrorValue: double read FMaxTeachErrorValue write FMaxTeachErrorValue;
property MaxTestError: boolean read FMaxTestError write FMaxTestError;
property MaxTestErrorValue: double read FMaxTestErrorValue write FMaxTestErrorValue;
property MidTeachError: boolean read FMidTeachError write FMidTeachError;
property MidTeachErrorValue: double read FMidTeachErrorValue write FMidTeachErrorValue;
property MidTestError: boolean read FMidTestError write FMidTestError;
property MidTestErrorValue: double read FMidTestErrorValue write FMidTestErrorValue;
property Options: string read FOptions write FOptions;
property SourceFileName: TFileName read FSourceFileName write FSourceFileName;
property TestAsValid: boolean read FTestAsValid write FTestAsValid;
property TeachIdent: boolean read FTeachIdent write FTeachIdent;
property TeachIdentCount: integer read FTeachIdentCount write SetTeachIdentCount;
property TestIdent: boolean read FTestIdent write FTestIdent;
property TestIdentCount: integer read FTestIdentCount write FTestIdentCount;
property UseForTeach: integer read FUseForTeach write SetUseForTeach;
end;
implementation
{$R *.RES}
{ TNeuron }
constructor TNeuron.Create(ALayer: TLayer);
begin
inherited Create;
// указатель на слой в котором находится нейрон
Layer := ALayer;
end;
destructor TNeuron.Destroy;
begin
WeightCount := 0;
FWeights := nil;
Layer := nil;
inherited;
end;
procedure TNeuron.ComputeOut(const AInputs: TVectorFloat);
var
i: integer;
begin
FOutput := 0;
// Подсчитывается взвешенная сумма нейрона
for i := Low(AInputs) to High(AInputs) do
FOutput := FOutput + FWeights[i] * AInputs[i];
end;
function TNeuron.GetWeights(Index: integer): double;
begin
try
Result := FWeights[Index];
except
on E: ERangeError do
raise E.CreateFmt(SWeightRangeIndex, [Index])
end;
end;
procedure TNeuron.InitWeights;
var
i: integer;
begin
// Инициализация весов нейрона
for i := Low(FWeights) to High(FWeights) do
FWeights[i] := Random
end;
procedure TNeuron.SetWeightCount(const Value: integer);
begin
SetLength(FWeights, Value);
end;
procedure TNeuron.SetWeights(Index: integer; Value: double);
begin
try
FWeights[Index] := Value;
except
on E: ERangeError do
raise E.CreateFmt(SWeightRangeIndex, [Index])
end;
end;
{ Конец описания TNeuron }
{ TNeuronBP }
destructor TNeuronBP.Destroy;
begin
FOnActivationF := nil;
FOnActivationD := nil;
PrevUpdateCount := 0;
FPrevUpdate := nil;
inherited;
end;
function TNeuronBP.GetLearningRate(Index: integer): double;
begin
Result := FLearningRate[Index];
end;
function TNeuronBP.GetPrevDerivative(Index: integer): double;
begin
Result := FPrevDerivative[Index];
end;
function TNeuronBP.GetPrevUpdateCount: integer;
begin
Result := High(FPrevUpdate) + 1;
end;
function TNeuronBP.GetPrevUpdate(Index: integer): double;
begin
Result := FPrevUpdate[Index];
end;
procedure TNeuronBP.ComputeOut(const AInputs: TVectorFloat);
begin
inherited;
// Задает смещение нейрона
FOutput := FOutput + Weights[High(AInputs) + 1];
FOutput := OnActivationF(FOutput);
end;
procedure TNeuronBP.SetDelta(Value: double);
begin
FDelta := Value;
end;
procedure TNeuronBP.SetLearningRate(Index: integer; const Value: double);
begin
FLearningRate[Index] := Value;
end;
procedure TNeuronBP.SetLearningRateCount(const Value: integer);
begin
SetLength(FLearningRate, Value)
end;
procedure TNeuronBP.SetPrevUpdate(Index: integer; Value: double);
begin
FPrevUpdate[Index] := Value;
end;
procedure TNeuronBP.SetPrevUpdateCount(const Value: integer);
begin
SetLength(FPrevUpdate, Value)
end;
procedure TNeuronBP.SetPrevDerivative(Index: integer; const Value: double);
begin
FPrevDerivative[Index] := Value;
end;
procedure TNeuronBP.SetPrevDerivativeCount(const Value: integer);
begin
SetLength(FPrevDerivative, Value)
end;
{ Конец описания TNeuronBP }
{ TLayer }
procedure TLayer.Assign(Source: TPersistent);
var
i: integer;
begin
FNumber := (Source as TLayer).FNumber;
NeuronCount := (Source as TLayer).NeuronCount;
// Создаются нейроны
for i := 0 to NeuronCount - 1 do
FNeurons[i] := TNeuron.Create(Self);
end;
constructor TLayer.Create(ALayerNumber: integer; ANeuronCount: integer);
var
i: integer;
begin
inherited Create;
FNumber := ALayerNumber;
NeuronCount := ANeuronCount;
for i := 0 to ANeuronCount - 1 do
FNeurons[i] := TNeuron.Create(Self);
end;
destructor TLayer.Destroy;
var
i: integer;
begin
for i := 0 to NeuronCount - 1 do
FNeurons[i].Free;
NeuronCount := 0;
FNeurons := nil;
inherited;
end;
function TLayer.GetNeuronCount: integer;
begin
Result := High(FNeurons) + 1;
end;
function TLayer.GetNeurons(Index: integer): TNeuron;
begin
Result := FNeurons[Index];
end;
procedure TLayer.SetNeuronCount(Value: integer);
begin
if Value <> High(FNeurons) + 1 then
SetLength(FNeurons, Value);
end;
procedure TLayer.SetNeurons(Index: integer; Value: TNeuron);
begin
try
FNeurons[Index] := Value;
except
on E: ERangeError do
raise E.CreateFmt(SNeuronRangeIndex, [Index])
end;
end;
{ TNeuralNetBP }
constructor TNeuralNetBP.Create(AOwner: TComponent);
var
i: integer;
begin
inherited;
FNeuronsInLayer := TStringList.Create;
for i := 0 to DefaultLayerCount do
AddLayer(DefaultNeuronCount);
TStringList(FNeuronsInLayer).OnChange := NeuronsInLayerChange;
AutoInit := True;
StopTeach := False;
TeachStopped := False;
NeuronsInLayerChange(Self);
SetDefaultProperties;
end;
destructor TNeuralNetBP.Destroy;
begin
FNeuronsInLayer.Free;
SetLength(FRandomOrder, 0);
FRandomOrder := nil;
SetLength(FDesiredOut, 0);
FDesiredOut := nil;
SetLength(FTestSetPatterns, 0, 0);
FTestSetPatterns := nil;
SetLength(FTestSetPatternsOut, 0, 0);
FTestSetPatternsOut := nil;
FOnAfterInit := nil;
FOnAfterTeach := nil;
FOnBeforeInit := nil;
FOnBeforeTeach := nil;
FOnEpochPassed := nil;
inherited;
end;
function TNeuralNetBP.GetLayersBP(Index: integer): TLayerBP;
begin
Result := FLayers[Index] as TLayerBP;
end;
function TNeuralNetBP.GetLayerCount: integer;
begin
Result := High(FLayers) + 1;
end;
function TNeuralNetBP.GetDesiredOut(Index: integer): double;
begin
Result := FDesiredOut[Index];
end;
function TNeuralNetBP.GetOutput(Index: integer): double;
begin
try
Result := LayersBP[LayerCount - 1].NeuronsBP[Index].Output;
except
on E: ERangeError do
raise E.CreateFmt(SNeuronRangeIndex, [Index])
end;
end;
function TNeuralNet.GetPatternsOutput(PatternIndex: integer; OutputIndex: integer): double;
begin
Result := FPatternsOutput[PatternIndex, OutputIndex];
end;
function TNeuralNetBP.QuadError: double;
var
i: integer;
begin
// рассчитывает среднеквадратичную ошибку
Result := 0;
for i := 0 to OutputNeuronCount - 1 do
Result := Result + sqr(LayersBP[LayerCount - 1].NeuronsBP[i].Output - DesiredOut[i]);
Result := Result/2;
end;
function TNeuralNetBP.ActivationF(Value: double): double;
begin
// Активационная функция - сигмоид
Result := 1/( 1 + exp(-FAlpha * Value) )
end;
function TNeuralNetBP.ActivationD(Value: double): double;
begin
// Производная сигмоиды
Result := FAlpha * Value * (1 - Value)
end;
function TNeuralNetBP.GetTestSetPatterns(InputIndex, PatternIndex: integer): double;
begin
Result := FTestSetPatterns[InputIndex, PatternIndex];
end;
function TNeuralNetBP.GetTestSetPatternsOut(InputIndex, PatternIndex: integer): double;
begin
Result := FTestSetPatternsOut[InputIndex, PatternIndex];
end;
procedure TNeuralNetBP.AddLayer(ANeurons: integer);
begin
if ANeurons < DefaultNeuronCount then
NeuronCountError
else
NeuronsInLayer.Add(IntToStr(ANeurons));
end;
procedure TNeuralNetBP.AdjustWeights;
var
i, j, k: integer;
xCurrentUpdate: double;
begin
// Подстройка весов начиная с первого слоя
for i := 1 to LayerCount - 1 do
for j := 0 to LayersBP[i].NeuronCount - 1 do
begin
for k := 0 to LayersBP[i-1].NeuronCount do
with LayersBP[i].NeuronsBP[j] do
begin
// корректирует вес соединяющий j-нейрон слоя i
// с k-нейроном слоя i-1: произведением дельта j-нейрона
// на выход k-нейрона слоя i-1
if k = LayersBP[i-1].NeuronCount then
// если это нейрон задающий смещение
xCurrentUpdate := -TeachRate * Delta + Momentum * PrevUpdate[k]
else
xCurrentUpdate := -TeachRate * Delta *
LayersBP[i-1].NeuronsBP[k].Output + Momentum * PrevUpdate[k];
Weights[k]:= Weights[k] + xCurrentUpdate;
PrevUpdate[k] := xCurrentUpdate;
end;
end
end;
procedure TNeuralNetBP.CalcLocalError;
var
i, j, k: integer;
begin
// Дельта-правило с последнего слоя до первого
for i := LayerCount - 1 downto 1 do
// для последнего слоя
if i = LayerCount - 1 then
for j := 0 to LayersBP[i].NeuronCount - 1 do
LayersBP[i].NeuronsBP[j].Delta := (LayersBP[i].NeuronsBP[j].Output-DesiredOut[j])
* ActivationD(LayersBP[i].NeuronsBP[j].Output)
else
for j := 0 to LayersBP[i].NeuronCount - 1 do
with LayersBP[i].NeuronsBP[j] do
begin
Delta := 0;
// Суммирует произведение локальной ошибки k-нейрона слоя i+1
// на вес соединяющий k-нейрон слоя i+1 с j-нейроном слоя i
for k := 0 to LayersBP[i+1].NeuronCount - 1 do
Delta := Delta + LayersBP[i+1].NeuronsBP[k].Delta *
LayersBP[i+1].NeuronsBP[k].Weights[j];
Delta := Delta * ActivationD(Output)
end;
end;
procedure TNeuralNetBP.CheckTestSet;
var
i, j: integer;
xArray: TVectorFloat;
xFirstTestSample: boolean;
xQuadError: double;
// функция рассчитывает среднеквадратичную ошибку
function QuadError(APatternCount: integer): double;
var
i: integer;
begin
Result := 0;
for i := 0 to OutputNeuronCount - 1 do
Result := Result + sqr(LayersBP[LayerCount - 1].NeuronsBP[i].Output - TestSetPatternsOut[APatternCount, i]);
Result := Result/2;
end;
begin
SetLength(xArray, InputNeuronCount);
xFirstTestSample := True;
FRecognizedTestCount := 0;
FMidTestResidual := 0;
FMaxTestResidual := 0;
for i := 0 to TestSetPatternCount - 1 do
begin
for j := 0 to InputNeuronCount - 1 do
xArray[j] := TestSetPatterns[i, j];
Compute(xArray);
xQuadError := QuadError(i);
// проверка - распознан ли пример из тестового множества
if xQuadError < IdentError then
Inc(FRecognizedTestCount);
FMidTestResidual := FMidTestResidual + xQuadError;
// максимальная ошибка на тестовом множестве
if xFirstTestSample then
begin
FMaxTestResidual := xQuadError;
xFirstTestSample := False;
end
else
if FMaxTestResidual < xQuadError then
FMaxTestResidual := xQuadError;
end;
// средняя ошибка на тестовом множестве
FMidTestResidual := FMidTestResidual/TestSetPatternCount;
SetLength(xArray, 0);
xArray := nil;
end;
procedure TNeuralNetBP.Compute(AVector: TVectorFloat);
var
i: integer;
begin
if InputNeuronCount <> High(AVector)+ 1 then
raise EInOutDimensionError.Create(SInNeuronCount);
for i := Low(AVector) to High(AVector) do
LayersBP[SensorLayer].NeuronsBP[i].Output := AVector[i];
Propagate;
end;
procedure TNeuralNetBP.DoOnAfterInit;
begin
if Assigned(FOnAfterInit) then
FOnAfterInit(Self);
end;
procedure TNeuralNetBP.DoOnAfterNeuronCreated(ALayerIndex, ANeuronIndex: integer);
var
i: integer;
begin
with LayersBP[ALayerIndex].NeuronsBP[ANeuronIndex] do
for i := 0 to PrevUpdateCount - 1 do
PrevUpdate[i] := 0;
if Assigned(FOnAfterNeuronCreated) then
FOnAfterNeuronCreated(Self);
end;
procedure TNeuralNetBP.DoOnAfterTeach;
begin
if Assigned(FOnAfterTeach) then
FOnAfterTeach(Self);
end;
procedure TNeuralNetBP.DoOnBeforeInit;
begin
if Assigned(FOnBeforeInit) then
FOnBeforeInit(Self);
end;
procedure TNeuralNetBP.DoOnBeforeTeach;
begin
if Assigned(FOnBeforeTeach) then
FOnBeforeTeach(Self);
end;
procedure TNeuralNetBP.DoOnEpochPassed;
begin
if Assigned(FOnEpochPassed) then
FOnEpochPassed(Self);
end;
procedure TNeuralNetBP.DeleteLayer(Index: integer);
var
i: integer;
begin
try
NeuronsInLayer.Delete(Index);
for i := Index to LayerCount - 2 do
LayersBP[i].Assign(LayersBP[i + 1]);
FLayers[LayerCount - 1].Free;
LayerCount := LayerCount - 1;
except
on E: ERangeError do
raise E.CreateFmt(SLayerRangeIndex, [Index])
end;
end;
procedure TNeuralNetBP.Init;
var
i, j: integer;
begin
DoOnBeforeInit;
if NeuronsInLayer.Count > 0 then
begin
LayerCount := NeuronsInLayer.Count;
// FLayers[0] нулевой слой, используется только поле Output
FLayers[0] := TLayerBP.Create(0, StrToInt(NeuronsInLayer.Strings[0]));
// для нулевого слоя не нужны весовые коэффициенты
for i := 1 to LayerCount - 1 do
begin
FLayers[i] := TLayerBP.Create(i, StrToInt(NeuronsInLayer.Strings[i]));
for j := 0 to StrToInt(NeuronsInLayer.Strings[i]) - 1 do
with LayersBP[i].NeuronsBP[j] do
begin
// задает количество элементов в векторе весов + смещение
WeightCount := LayersBP[i-1].NeuronCount + BiasNeuron;
// задает количество в векторе содержащем предыдущую коррекцию
// элементов + смещение
PrevUpdateCount := LayersBP[i-1].NeuronCount + BiasNeuron;
PrevDerivativeCount := LayersBP[i-1].NeuronCount + BiasNeuron; // для быстрых алгоритмов
LearningRateCount := LayersBP[i-1].NeuronCount + BiasNeuron; // для быстрых алгоритмов
OnActivationF := ActivationF;
OnActivationD := ActivationD;
Randomize;
DoOnAfterNeuronCreated(i, j);
end
end;
// устанавливает размерность массива выходов
// число нейронов в последнем слое = числу выходов
SetLength(FDesiredOut, OutputNeuronCount);
end;
DoOnAfterInit;
end;
procedure TNeuralNetBP.InitWeights;
var
i,j: integer;
begin
Randomize;
// Инициализация весов
for i := 1 to LayerCount - 1 do
for j := 0 to LayersBP[i].NeuronCount - 1 do
LayersBP[i].NeuronsBP[j].InitWeights;
end;
procedure TNeuralNetBP.LoadPatternsInput(APatternIndex :integer);
var
i: integer;
begin
for i := 0 to InputNeuronCount - 1 do
LayersBP[SensorLayer].NeuronsBP[i].Output := PatternsInput[APatternIndex, i];
end;
procedure TNeuralNetBP.LoadPatternsOutput(APatternIndex :integer);
var
i: integer;
begin
for i := 0 to OutputNeuronCount - 1 do
DesiredOut[i] := PatternsOutput[APatternIndex, i];
end;
procedure TNeuralNetBP.NeuronsInLayerChange(Sender: TObject);
begin
if AutoInit then
Init;
end;
procedure TNeuralNetBP.NeuronCountError;
begin
raise ENeuronCountError.Create(SNeuronCount)
end;
procedure TNeuralNetBP.Propagate;
var
i, j, xIndex: integer;
xArray: TVectorFloat;
begin
// Распространение сигнала в прямом направлении с первого слоя
for i := 1 to LayerCount - 1 do
begin
// формирование массива входов из выходов предыдущего слоя
SetLength(xArray, LayersBP[i-1].NeuronCount);
for xIndex := 0 to LayersBP[i-1].NeuronCount - 1 do
xArray[xIndex] := LayersBP[i-1].NeuronsBP[xIndex].Output;
// вычисление выхода нейрона
for j := 0 to LayersBP[i].NeuronCount - 1 do
with LayersBP[i].NeuronsBP[j] do
ComputeOut(xArray);
for xIndex := 0 to LayersBP[i-1].NeuronCount - 1 do
xArray[xIndex] := 0;
end;
SetLength(xArray, 0);
xArray := nil;
end;
procedure TNeuralNetBP.ResetLayers;
begin
Clear;
FNeuronsInLayer.Clear;
end;
procedure TNeuralNetBP.SetDesiredOut(Index: integer; Value: double);
begin
FDesiredOut[Index] := Value;
end;
procedure TNeuralNetBP.SetLayersBP(Index: integer; Value: TLayerBP);
begin
FLayers[Index] := Value as TLayerBP;
end;
procedure TNeuralNetBP.SetAlpha(Value: double);
begin
if (Value > 10) or (Value < 0.01) then
FAlpha := DefaultAlpha
else
FAlpha := Value;
end;
procedure TNeuralNetBP.SetTeachRate(Value: double);
begin
if (Value > 1) or (Value <= 0) then
FTeachRate := DefaultTeachRate
else
FTeachRate := Value;
end;
procedure TNeuralNetBP.SetTestSetPatterns(InputIndex, PatternIndex: integer; const Value: double);
begin
FTestSetPatterns[InputIndex, PatternIndex] := Value;
end;
procedure TNeuralNetBP.SetTestSetPatternsOut(InputIndex, PatternIndex: integer; const Value: double);
begin
FTestSetPatternsOut[InputIndex, PatternIndex] := Value;
end;
procedure TNeuralNetBP.SetTestSetPatternCount(const Value: integer);
begin
FTestSetPatternCount := Value;
SetLength(FTestSetPatterns, FTestSetPatternCount, InputNeuronCount);
SetLength(FTestSetPatternsOut, FTestSetPatternCount, OutputNeuronCount);
end;
procedure TNeuralNetBP.SetMomentum(Value: double);
begin
if (Value > 1) or (Value < 0) then
FMomentum := DefaultMomentum
else
FMomentum := Value;
end;
procedure TNeuralNetBP.SetEpochCount(Value: integer);
begin
if Value < 1 then
FEpochCount := 1
else
FEpochCount := Value;
end;
procedure TNeuralNetBP.ShakeUp;
var
i, j, k: integer;
begin
Randomize;
for i := 1 to LayerCount - 1 do
for j := 0 to LayersBP[i].NeuronCount - 1 do
for k := 0 to LayersBP[i-1].NeuronCount do
with LayersBP[i].NeuronsBP[j] do
Weights[k]:= Weights[k] + Random*0.1-0.05;
end;
procedure TNeuralNetBP.Shuffle;
var
i, j, xNewInd, xLast: integer;
xIsUnique : boolean;
begin
xNewInd := 0;
FRandomOrder[0] := Round(Random(FPatternCount));
xLast := 0;
for i := 1 to PatternCount - 1 do
begin
xIsUnique := False;
while not xIsUnique do
begin
xNewInd := Round((Random(FPatternCount)));
xIsUnique := True;
for j := 0 to xLast do
if xNewInd = FRandomOrder[j] then
xIsUnique := False;
end;
FRandomOrder[i] := xNewInd;
xLast := xLast +1;
end;
end;
procedure TNeuralNetBP.TeachOffLine;
var
j: integer;
xQuadError: double;
xNewEpoch: boolean;
begin
DoOnBeforeTeach;
if not ContinueTeach then
begin
// веса инициализируются, если сеть обучается с "нуля"
InitWeights;
FEpochCurrent := 1;
end;
Randomize;
SetLength(FRandomOrder, FPatternCount);
TeachStopped := False;
while (FEpochCurrent <= EpochCount) do
begin
FTeachError := 0;
FMaxTeachResidual := 0;
FRecognizedTeachCount := 0;
xNewEpoch := True;
Shuffle;
for j := 0 to PatternCount - 1 do
begin
LoadPatternsInput(FRandomOrder[j]);
LoadPatternsOutput(FRandomOrder[j]);
Propagate;
xQuadError := QuadError;
// проверка - распознан ли пример из обучающего множества
if xQuadError < IdentError then
Inc(FRecognizedTeachCount);
FTeachError := FTeachError + xQuadError;
// максимальная ошибка на обучающем множестве
if xNewEpoch then
begin
FMaxTeachResidual := xQuadError;
xNewEpoch := False;
end
else
if MaxTeachResidual < xQuadError then
FMaxTeachResidual := xQuadError;
CalcLocalError;
AdjustWeights;
end;
// средняя ошибка на обучающем множестве
FMidTeachResidual := TeachError/PatternCount;
// проверка сети на обобщение
if TestSetPatternCount > 0 then
CheckTestSet;
DoOnEpochPassed;
if StopTeach then
begin
TeachStopped := True;
Exit;
end;
Inc(FEpochCurrent);
end;
DoOnAfterTeach;
end;
procedure TNeuralNetBP.SetPatternCount(const Value: integer);
begin
FPatternCount := Value;
inherited;
end;
procedure TNeuralNetBP.SetDefaultProperties;
begin
// параметры устанавливаемые по умолчанию
Alpha := DefaultAlpha;
ContinueTeach := False;
Epoch := True;
EpochCount := DefaultEpochCount;
Momentum := DefaultMomentum;
TeachRate := DefaultTeachRate;
ResizeInputDim;
ResizeOutputDim;
end;
end.
Приложение Б. Исходный код скрипта подключения библиотеки ActiveX к системе “1C:Предприятие”
//Нейросеть - начало
Если флNero=1 Тогда
Если ПустоеЗначение(Нейросеть)=1 Тогда
Если ЗагрузитьВнешнююКомпоненту("NeroNet.dll")=0 Тогда
Возврат;
КонецЕсли;
НейроСеть=СоздатьОбъект("AddIn.NeroNet");
КонецЕсли;
НейроСеть.НачатьОпределениеКолонок();
Для с=1 по СписокГруппировок.РазмерСписка() Цикл
Идент=СписокГруппировок.ПолучитьЗначение(с);
НейроСеть.НоваяКолонка(Идент);
КонецЦикла;
НейроСеть.НоваяКолонка("Количество","Количество","Число");
НейроСеть.НоваяКолонка("Стоимость","Стоимость","Число");
НейроСеть.НоваяКолонка("Наименование товара"," Наименование товара ","Число");
НейроСеть.НоваяКолонка("Дата"," Дата "," Дата ");
НейроСеть.ЗавершитьОпределениеКолонок();
Прогресс="=>";
Загрузить_Данные_В_НейроСеть(1);
НейроСеть.Показать("Прогноз продажи по товарам");
Возврат;
КонецЕсли;
//НейроСеть – конец
Приложение В.
Рис. 1 Главное окно программы и экранная форма вызова внешнего отчета
Рис. 2 Основная экранная форма с элементами настройки
Рис. 3 Форма отчета прогноза
[1] Информационные технологии – совокупность методов, производственных процессов и программно-технических средств, объединенных в технологическую цепочку, обеспечивающую сбор, обработку, хранение, распространение (транспортировку) и отображение информации с целью снижения трудоемкости процессов использования информационного ресурса, а также повышения их надежности и оперативности.
[2] Data Mining – в переводе с английского означает "добыча данных". Альтернативное название – knowledge discovery in databases ("обнаружение знаний в базах данных" или "интеллектуальный анализ данных").
[3] Документ, позволяющий обосновать целесообразность разработки, производства, и сбыта продукции в условиях конкуренции.