Курсовая работа: Построение эконометрической модели и исследование проблемы автокорреляции с помощью тестов Бреуша-Годфри и Q-статистики
МИНИСТЕРСТВО ОБРАЗОВАНИЯ РЕСПУБЛИКИ БЕЛАРУСЬ
БЕЛОРУССКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ
Экономический факультет
Кафедра экономической информатики и математической экономики
Курсовая работа
Построение эконометрической модели и исследование проблемы автокорреляции с помощью тестов Бреуша-Годфри и Q-статистики
Студентки 3курса
Отделения экономической теории
Мурджикнели Евгении Михайловны
Научный руководитель
Васенкова Елена Игоревна
Минск, 2008
Содержание
Введение
Глава 1. Теоретическое обоснование модели и её анализа
1.1 Экономическое обоснование модели
1.2 Проблема автокорреляции: теория
Глава 2. Построение регрессионной модели и её анализ на проблему автокорреляции
Глава 3. Устранение автокорреляции
Заключение
Список использованных источников
Приложение 1
Приложение 2
Приложение 3
Введение
В данной работе будет построена регрессионная модель, которая основана на реальных статистических данных. Среди основных задач выделяются:
- построение качественной модели линейной регрессии и доказательство справедливости соответствующего ей теоретического уравнения экономической теории;
- демонстрация работы тестов Бреуша-Годфри и Q-теста, позволяющих определить наличие автокорреляции в модели;
- при обнаружении последней рассмотрение варианты корректирования модели, для того, чтобы выполнялись все предпосылки МНК.
Статистические данные использованных в работе показателей были взяты из Системы Национальных Счетов Российской Федерации. Это поквартальные данные с первого квартала 1999 года по 2-ой квартал 2008 года включительно.
Целью данной работы является доказательство существования определённой зависимости между экономическими показателями, а также более глубокое изучение проблемы автокорреляции в регрессионной модели.
Глава 1. Теоретическое обоснование модели и её анализа
1.1 Экономическое обоснование модели
Для построения регрессионной модели были выбраны следующие экономические показатели:
- ВВП(GDP) – показатель, измеряющий стоимость конечной продукции, произведённой резидентами данной страны за определённый период времени;
- потребительские расходы (Cons, потребление), которые включают в себя расходы домашних хозяйств на товары как длительного, так и текущего пользования (кроме расходов на покупку жилья), а также на услуги;
- инвестиции + государственные расходы (IG), которые включают производственные капиталовложения и расходы государства, например, такие как строительство школ, дорог или содержание армии;
Эти показатели объединены в уравнении, которое получило название основного макроэкономического тождества для закрытой экономики:
![]() (1)
(1)
В данной работе зависимость (1) будет доказываться на справедливость на основе статистических данных, а также будет использоваться в данной работе для построения модели, в которой возможно наличие автокорреляции.
1.2 Проблема автокорреляции: теорияАвтокорреляция (последовательная
корреляция) определяется как корреляция между наблюдаемыми показателями,
упорядоченными во времени. Автокорреляция чаще встречается в регрессионном
анализе при использовании данных временных рядов. В экономических задачах
встречается как положительная автокорреляция (![]() ),
так и отрицательная (
),
так и отрицательная (![]() ).
).
Основными причинами вызывающими появление автокорреляцию считают ошибки спецификации, инерцию в изменении экономических показателей (вследствие цикличности), эффект паутины (причина – временные лаги), а также сглаживание данных.
Среди последствий автокорреляции обычно выделяют следующие:
· Оценки параметров перестают быть эффективными;
· Оценка дисперсии регрессии является смещённой;
· Дисперсии оценок являются смещёнными, что приводит к увеличению t-статистик. Это может привести к признанию статистически значимыми объясняющие переменные, которые на самом деле таковыми не являются;
· Ухудшаются прогнозные качества модели.
Так как последствия автокорреляции для качества модели велики, то важно выявить наличие автокорреляции, что делается с помощью нескольких тестов. Чаще всего используются такие тесты, как метод рядов, критерий Дарбина-Уотсона, тест Бреуша-Годфри, Q-статистика, h-статистика.
Глава 2. Построение регрессионной модели и её анализ на проблему автокорреляции
Поскольку в данной работе при построении уравнения регрессии будут использоваться временные ряды, так как в них чаще встречается проблема автокорреляции, а не перекрёстные данные, то перед построением модели следует проверить ряды на стационарность.
Как видно из Рис.1 Приложения 1 все ряды исследуемых показателей не имеют постоянного математического ожидания, но имеют восходящий линейный тренд, из чего возможно сделать предварительный вывод о том, что ряды будут стационарными относительного тренда.
Для более глубокого анализа рядов на стационарность используются коррелограммы рядов, а также тесты «единичного корня». В данной работе будет рассмотрен тест Дики-Фуллера.
Очевидно, что все три ряда являются нестационарными, что можно определить по характерному рисунку «убывающей экспоненты» на графике автокорреляционной функции, а также первый выступающий лаг на графике частной автокорреляционной функции. Следовательно, проверку исходных рядов на стационарность следует дополнить тестом Дики-Фуллера. Результаты приведены ниже:
| ADF Test Statistic |
-20.99004 |
1% Critical Value* | -4.2412 |
|
|||||||
| 5% Critical Value |
-3.5426 |
|
|||||||||
| 10% Critical Value | -3.2032 |
|
|||||||||
| Dependent Variable: D(IG) |
|
||||||||||
| Method: Least Squares |
|
||||||||||
| Included observations: 35 after adjusting endpoints |
|
||||||||||
| Variable | Coefficient | Std. Error | t-Statistic | Prob. |
|
||||||
| D(IG(-1)) | -2.200495 | 0.104835 |
-20.99004 |
0.0000 |
|
||||||
| @TREND(1999:1) | 9.663892 | 2.439289 |
3.961766 |
0.0004 |
|
||||||
| Durbin-Watson stat |
2.352758 |
Prob(F-statistic) | 0.000000 |
|
|||||||
| ADF Test Statistic |
-5.278444 |
1% Critical Value* | -4.2412 |
|
|||||||
| 5% Critical Value |
-3.5426 |
|
|||||||||
| 10% Critical Value | -3.2032 |
|
|||||||||
| Dependent Variable: D(CONS) |
|
||||||||||
| Method: Least Squares |
|
||||||||||
| Included observations: 35 after adjusting endpoints |
|
||||||||||
| Variable | Coefficient | Std. Error | t-Statistic | Prob. |
|
||||||
| D(CONS(-1)) | -1.636006 | 0.309941 |
-5.278444 |
0.0000 |
|
||||||
| @TREND(1999:1) | 12.54844 | 3.021702 |
4.152773 |
0.0002 |
|
||||||
| Durbin-Watson stat |
2.101394 |
Prob(F-statistic) | 0.000000 |
|
|||||||
| ADF Test Statistic |
-9.618956 |
1% Critical Value* | -4.2412 | ||||||||
| 5% Critical Value |
-3.5426 |
||||||||||
| 10% Critical Value | -3.2032 | ||||||||||
| Dependent Variable: D(GDP) | |||||||||||
| Method: Least Squares | |||||||||||
| Included observations: 35 after adjusting endpoints | |||||||||||
| Variable | Coefficient | Std. Error | t-Statistic | Prob. | |||||||
| D(GDP(-1)) | -2.088636 | 0.217137 |
-9.618956 |
0.0000 | |||||||
| @TREND(1999:1) | 26.31412 | 6.414595 |
4.102226 |
0.0003 | |||||||
| Durbin-Watson stat |
2.486933 |
Prob(F-statistic) | 0.000000 | ||||||||
При помощи коррелограммы первых разностей данных всех трёх рядов обнаруживается, что необходимо ввести один лаг для всех рядов во вспомогательное уравнение теста. И после того, как был проведён тест Дики-Фуллера, выяснилось, что ряды интегрированы первого порядка или стационарны в первых разностях со спецификацией тренда и одним лагом.
Однако ряды IG и GDP имеют чётко видную сезонность, что видно на Рисунке 1 Приложения 1, поэтому для них дополнительного проводится тест Филипса-Перрона, данные которого находятся в Приложении 2.
Имеем:
- ряды нестационарны в уровнях, но стационарны в первых разностях;
- по имеющимся данным можно строить модель множественной классической линейной регрессии.
По предварительному анализу, можно сказать, что модель, которая будет построена, возможно, будет обладать проблемой автокорреляции вследствие цикличности показателей, используемых для построения уравнения регрессии. ВВП имеет дело с волнообразностью деловой активности, которая при построении модели может служить причиной автокорреляции.
Строим уравнение регрессии:
| Dependent Variable: GDP | ||||
| Method: Least Squares | ||||
| Date: 12/11/08 Time: 16:34 | ||||
| Sample: 1999:1 2008:2 | ||||
| Included observations: 38 | ||||
| GDP=C(1)+C(2)*Cons+C(3)*IG | ||||
| Coefficient | Std. Error | t-Statistic | Prob. | |
| C(1) |
90.71828 |
36.69767 |
2.472045 |
0.0184 |
| C(2) |
0.875856 |
0.076378 |
11.46745 |
0.0000 |
| C(3) |
1.190895 |
0.030510 |
39.03232 |
0.0000 |
| R-squared |
0.998324 |
Mean dependent var | 4283.858 | |
| Adjusted R-squared | 0.998228 | S.D. dependent var | 2609.517 | |
| S.E. of regression | 109.8386 | Akaike info criterion | 12.31156 | |
| Sum squared resid | 422257.9 | Schwarz criterion | 12.44084 | |
| Log likelihood | -230.9196 | Durbin-Watson stat |
0.589082 |
Уравнение регрессии выглядит следующим образом:
GDP=90.71828168+0.8758556601![]() Cons+1.190895181
Cons+1.190895181![]() IG (2)
IG (2)
После округления оно будет иметь следующий вид:
![]() (3)
(3)
Построенная модель имеет очень высокий коэффициент детерминации, что говорит о высоком качестве этой модели. Высокие значения имеют t-статистики, соответственно все объясняющие переменные данной модели значимы. Верны и коэффициенты при переменных, то есть они имеют верный знак и значение близкое к теоретическому уравнению (1). Высокое значение коэффициента С(1) и его статистическая значимость с экономической точки зрения может говорить о том, что в модель включено недостаточно переменных, что позже будет исправлено. Поэтому, прежде чем делать выводы о качестве и адекватности, следует проверить построенную модель на автокорреляцию и гетероскедастичность.
По статистике Дарбина-Уотсона уравнение имеет автокорреляцию, положительную (d1=1,373, du=1,594), откуда можно сделать вывод о наличии автокорреляции.
На проблему гетероскедастичности исследуем модель при помощи теста Вайта(no cross, cross):
|
White Heteroskedasticity Test: | ||||
|
F-statistic | 1.926499 | Probability | 0.129239 | |
|
Obs*R-squared |
7.193728 |
Probability | 0.125998 | |
|
|||||
|
Test Equation: | ||||
|
Dependent Variable: RESID^2 | ||||
|
Method: Least Squares | ||||
|
Date: 12/11/08 Time: 19:18 | ||||
|
Sample: 1999:1 2008:2 | ||||
|
Included observations: 38 | ||||
|
Variable | Coefficient | Std. Error | t-Statistic | Prob. |
|
C | -7329.568 | 8035.888 | -0.912104 | 0.3683 |
|
IG | -10.79329 | 22.84694 | -0.472417 | 0.6397 |
|
IG^2 | 0.000343 | 0.007396 | 0.046398 | 0.9633 |
|
CONS | 14.94592 | 10.01542 | 1.492291 | 0.1451 |
|
CONS^2 | -0.001335 | 0.001299 | -1.028002 | 0.3114 |
|
R-squared | 0.189309 | Mean dependent var | 11112.05 | |
|
Adjusted R-squared | 0.091043 | S.D. dependent var | 13500.26 | |
|
S.E. of regression | 12871.05 | Akaike info criterion | 21.88543 | |
|
Sum squared resid | 5.47E+09 | Schwarz criterion | 22.10090 | |
|
Log likelihood | -410.8231 | F-statistic | 1.926499 | |
|
Durbin-Watson stat | 1.289207 | Prob(F-statistic) | 0.129239 | |
| White Heteroskedasticity Test: | |||||
| F-statistic | 1.910945 | Probability | 0.120009 | ||
| Obs*R-squared |
8.737384 |
Probability | 0.120009 | ||
| Test Equation: | |||||
| Dependent Variable: RESID^2 | |||||
| Method: Least Squares | |||||
| Date: 12/11/08 Time: 19:20 | |||||
| Sample: 1999:1 2008:2 | |||||
| Included observations: 38 | |||||
| Variable | Coefficient | Std. Error | t-Statistic | Prob. | |
| C | -4788.651 | 8190.315 | -0.584672 | 0.5629 | |
| IG | 10.01788 | 27.71085 | 0.361515 | 0.7201 | |
| IG^2 | 0.043812 | 0.034248 | 1.279250 | 0.2100 | |
| IG*CONS | -0.034393 | 0.026471 | -1.299253 | 0.2031 | |
| CONS | 5.948824 | 12.09186 | 0.491969 | 0.6261 | |
| CONS^2 | 0.005437 | 0.005368 | 1.012743 | 0.3188 | |
| R-squared | 0.229931 | Mean dependent var | 11112.05 | ||
| Adjusted R-squared | 0.109608 | S.D. dependent var | 13500.26 | ||
| S.E. of regression | 12738.93 | Akaike info criterion | 21.88665 | ||
| Sum squared resid | 5.19E+09 | Schwarz criterion | 22.14522 | ||
| Log likelihood | -409.8464 | F-statistic | 1.910945 | ||
| Durbin-Watson stat | 1.168906 | Prob(F-statistic) | 0.120009 | ||
Для трактовки этого теста
используем «Obs*R-squared», которое сравниваем с соответствующим критическим
значением ![]() распределения со степенями
свобод равным количеству переменных в модели, то есть двум. Как и в тесте cross terms, так и в no cross terms наблюдаемое значение оказывается
меньше критического при уровнях значимости
распределения со степенями
свобод равным количеству переменных в модели, то есть двум. Как и в тесте cross terms, так и в no cross terms наблюдаемое значение оказывается
меньше критического при уровнях значимости ![]() ,01
и
,01
и ![]() ,005, из чего следует вывод
об отсутствии гетероскедастичности в построенной модели.
,005, из чего следует вывод
об отсутствии гетероскедастичности в построенной модели.
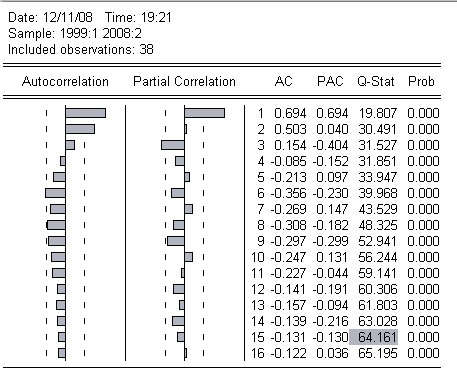
Проблему автокорреляции исследуем далее при помощи теста Бреуша-Годфри и Q-статистики Бокса-Льюнга. Результаты этих тестов представлены ниже:
| Breusch-Godfrey Serial Correlation LM Test: | ||||
| F-statistic | 33.14949 | Probability | 0.000002 | |
| Obs*R-squared |
18.75935 |
Probability | 0.000015 | |
| Test Equation: | ||||
| Dependent Variable: RESID | ||||
| Method: Least Squares | ||||
| Date: 12/11/08 Time: 19:17 | ||||
| Presample missing value lagged residuals set to zero. | ||||
| Variable | Coefficient | Std. Error | t-Statistic | Prob. |
| C(1) | 4.195415 | 26.50424 | 0.158292 | 0.8752 |
| C(2) | 0.046689 | 0.055735 | 0.837705 | 0.4080 |
| C(3) | -0.016381 | 0.022210 | -0.737543 | 0.4659 |
| RESID(-1) | 0.710963 | 0.123483 | 5.757559 | 0.0000 |
| R-squared | 0.493667 | Mean dependent var | -6.15E-13 | |
| Adjusted R-squared | 0.448991 | S.D. dependent var | 106.8287 | |
| S.E. of regression | 79.29897 | Akaike info criterion | 11.68363 | |
| Sum squared resid | 213803.1 | Schwarz criterion | 11.85601 | |
| Log likelihood | -217.9889 | Durbin-Watson stat | 1.935910 |
Q -статистика принимает нулевой гипотезу об отсутствии автокорреляции и строится по следующему уравнению:
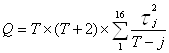 , (4)
, (4)
где j-номер соответствующего лага, ![]() -
автокорреляция при соответствующем лаге, T- количество измерений. При отсутствии автокорреляции
значения Q могут асимптотически приближаться к
соответствующему значению
-
автокорреляция при соответствующем лаге, T- количество измерений. При отсутствии автокорреляции
значения Q могут асимптотически приближаться к
соответствующему значению ![]() со
степенью свободы равной номеру лага. Q-статистика широко используется для определения того является ли ряд
белым шумом.
со
степенью свободы равной номеру лага. Q-статистика широко используется для определения того является ли ряд
белым шумом.
Как видно из
коррелограммы( Q-теста) первые
значения функции имеют достаточно большие значения, при том, что заметно их
последующее уменьшение при увеличении номера лага. Также на графике же
частичной автокорреляции заметен первый «выдающийся» лаг, и увеличение Q на большее значение, чем по таблицам
![]() распределения, что чётко
указывает на наличие автокорреляции в модели.
распределения, что чётко
указывает на наличие автокорреляции в модели.
При отсутствии автокорреляции Q‑статистика показала бы все значения функции, колеблющиеся около нуля, независимо от номера лага.
Для того чтобы окончательно убедиться в наличии автокорреляции в модели следует проанализировать результаты по тесту Бреуша-Годфри, в котором строится уравнение вида:
![]() (5)
(5)
В регрессионной модели, построенной на основании уравнения (5) рассматривается произведение коэффициента детерминации и количества измерений. За нулевую гипотезу принимается то, что все коэффициенты нового уравнения имеют нулевые значения, или статистически незначимы, то есть отсутствие автокорреляции. Альтернативная же гипотеза говорит о наличии в исходной модели проблемы автокорреляции
Таким образом, рассматриваем значение
«Obs*R-square» и сравниваем его с соответствующим критически значением из
таблиц распределения ![]() с количеством
степеней свободы равным 1, так как количество степеней свободы равно количеству
лагов (в данном случае один).
с количеством
степеней свободы равным 1, так как количество степеней свободы равно количеству
лагов (в данном случае один).
Наблюдаемое значение оказалось больше
критического(7.88 для ![]() =0.005),
следовательно принимается альтернативная гипотеза, что окончательно убеждает в
том, что в модели присутствует положительная (по Дарбину-Уотсону) автокорреляция
первого порядка.
=0.005),
следовательно принимается альтернативная гипотеза, что окончательно убеждает в
том, что в модели присутствует положительная (по Дарбину-Уотсону) автокорреляция
первого порядка.
- была построена регрессионная модель, с хорошими показаниями t-статистик и высоким коэффициентом детерминации;
- в модели отсутствует гетероскедастичность;
- тесты Бреуша-Годфри и Q-тест выявили в модели наличие автокорреляции;
- для улучшения качества модели, а так же её прогнозных свойств автокорреляцию следует устранить.
Глава 3. Устранение автокорреляции
Как известно широко используемыми методами усовершенствования модели с целью устранения автокорреляции являются:
- уточнение состава переменных, то есть устранение одной либо нескольких переменных или добавление переменных;
- изменение формы зависимости.
Если после ряда этих действий автокорреляция по-прежнему имеет место, то возможны некоторые преобразования, её устраняющие.
Для усовершенствования модели было решено добавь ещё одну переменную в анализ. Эта экзогенная переменная определяется как разность экспорта и импорта страны, и в экономической среде получила название чистого экспорта (EX-IM=NX).
Таким образом, в модели появляется третяя объясняющая переменная и зависимость принимает следующий вид:
![]() (6)
(6)
Данное уравнение является основным макроэкономическим тождеством для стран с открытой экономикой, какими и являются большинство стран мира.
При построении регрессионной модели были получены следующие данные:
| Dependent Variable: GDP | ||||
| Method: Least Squares | ||||
| Date: 12/11/08 Time: 19:23 | ||||
| Sample: 1999:1 2008:2 | ||||
| Included observations: 38 | ||||
| GDP=C(1)+C(2)*IG+C(3)*CONS+C(4)*NX | ||||
| Coefficient | Std. Error | t-Statistic | Prob. | |
| C(1) |
9.983102 |
15.40599 |
0.648001 |
0.5213 |
| C(2) |
1.041238 |
0.031994 |
32.54493 |
0.0000 |
| C(3) |
1.004281 |
0.017836 |
36.30674 |
0.0000 |
| C(4) |
0.890623 |
0.063486 |
14.02859 |
0.0000 |
| R-squared |
0.999753 |
Mean dependent var | 4283.858 | |
| Adjusted R-squared | 0.999731 | S.D. dependent var | 2609.517 | |
| S.E. of regression | 42.77300 | Akaike info criterion | 10.44899 | |
| Sum squared resid | 62204.00 | Schwarz criterion | 10.62137 | |
| Log likelihood | -194.5308 | Durbin-Watson stat |
2.338553 |
Уравнение регрессии после округления принимает следующий вид:
![]() (7)
(7)
Как видно из таблицы, все объясняющие переменные статистически значимы, а коэффициент детерминации очень высок. Все коэффициенты имеют верный знак и значение, которое очень приближено к значениям коэффициентов в основном макроэкономическом тождестве. С(1) статистически незначим, что можно проинтерпретировать таким образом, что новая модель наиболее приближена к исходному теоретическому уравнению (6). В качестве предварительного анализа на проблему автокорреляции легко заметить, что значение статистики Дарбина-Уотсона находится в области отсутствия автокорреляции (d1=1,318, du=1,656).
Из всего вышесказанного можно сделать следующие выводы:
- модель не имеет проблем спецификации, она качественна и адекватна по первоначальному анализу;
- предварительный анализ по статистике Дарбина-Уотсона указал на отсутствие автокорреляции.
Для того чтобы убедиться в отсутствии автокорреляции в модели проведём тест Бреуша-Годфри и проверим модель на Q- статистике:
| Breusch-Godfrey Serial Correlation LM Test: | ||||
| F-statistic | 1.250798 | Probability | 0.271476 | |
| Obs*R-squared |
1.387714 |
Probability | 0.238791 | |
| Test Equation: | ||||
| Dependent Variable: RESID | ||||
| Method: Least Squares | ||||
| Date: 12/11/08 Time: 19:25 | ||||
| Presample missing value lagged residuals set to zero. | ||||
| Variable | Coefficient | Std. Error | t-Statistic | Prob. |
| C(1) | -2.488241 | 15.50988 | -0.160429 | 0.8735 |
| C(2) | -0.011896 | 0.033604 | -0.353999 | 0.7256 |
| C(3) | 0.003454 | 0.018037 | 0.191509 | 0.8493 |
| C(4) | 0.007246 | 0.063584 | 0.113957 | 0.9100 |
| RESID(-1) | -0.208047 | 0.186023 | -1.118391 | 0.2715 |
| R-squared | 0.036519 | Mean dependent var | -1.42E-12 | |
| Adjusted R-squared | -0.080267 | S.D. dependent var | 41.00231 | |
| S.E. of regression | 42.61611 | Akaike info criterion | 10.46442 | |
| Sum squared resid | 59932.38 | Schwarz criterion | 10.67989 | |
| Log likelihood | -193.8240 | Durbin-Watson stat | 1.998121 |
| AC | PAC | Q-Stat | Prob | |
| 1 | -0.162 | -0.162 | 1.0715 | 0.301 |
| 2 | -0.156 | -0.187 | 2.0992 | 0.350 |
| 3 | 0.064 | 0.004 | 2.2754 | 0.517 |
| 4 | 0.387 | 0.394 | 8.9637 | 0.062 |
| 5 | -0.352 | -0.245 | 14.681 | 0.012 |
| 6 | -0.146 | -0.178 | 15.697 | 0.015 |
| 7 | 0.157 | 0.015 | 16.901 | 0.018 |
| 8 | 0.091 | -0.011 | 17.317 | 0.027 |
| 9 | -0.101 | -0.099 | 29.374 | 0.001 |
| 10 | 0.107 | 0.041 | 29.997 | 0.001 |
| 11 | 0.083 | -0.117 | 30.385 | 0.001 |
| 12 | -0.066 | -0.062 | 30.637 | 0.002 |
| 13 | -0.163 | 0.132 | 32.256 | 0.002 |
| 14 | 0.104 | -0.202 | 32.947 | 0.003 |
| 15 | 0.073 | -0.022 | 33.303 | 0.004 |
| 16 | -0.142 | -0.057 | 34.694 | 0.004 |
Видим, что значение
«Obs*R-squared» в статистике Бреуша-Годфри меньше соответствующего ему
критического значения ![]() =7.88 при
=7.88 при ![]() =0.005. Значения Q-статистики и графиков также указываю
на отсутствие автокорреляции в новой модели.
=0.005. Значения Q-статистики и графиков также указываю
на отсутствие автокорреляции в новой модели.
Заключение
Таким образом, после проделанной работы можно сделать следующие выводы:
- используя реальные поквартальные статистические данные российской Федерации с 1999 года по второй квартал 2008 года была доказана справедливость основного макроэкономического тождества;
- были построены две регрессионные модели для более детального анализа проблемы автокорреляции, в первой из которых было две экзогенных переменных, а во второй три;
- в первой из построенных моделей наблюдалась проблема положительной автокорреляции первого порядка, которая была первоначально обнаружена при помощи статистики Дарбина-Уотсона, и более тщательно исследована на примере тестов Бреуша-Годфри и Q-статистики;
- в первой модели также присутствовал «свободный член», статистически значимый коэффициент с(1), значение которого было слишком велико, что говорило о неполном соответствии построенного уравнения регрессии теоретическому уравнению;
- для устранения автокорреляции и усовершенствования модели была введена третья объясняющая переменная;
- вторая модель была проверена рядом тестов, после чего можно было заключить, что она качественна и не обладает проблемой автокорреляции, то есть данная проблема была устранена путём введения новой переменной в модель;
- в работе удалось проанализировать модели, обосновать их экономический смысл на базе знаний из курса экономической теории, а также улучшить одну из них.
Список использованных источников
1. Бородич С.А. Вводный курс эконометрики – Мн., 2000.
2. Eviews users guide 3.1.
3. www.gsk.ru
Приложение 1
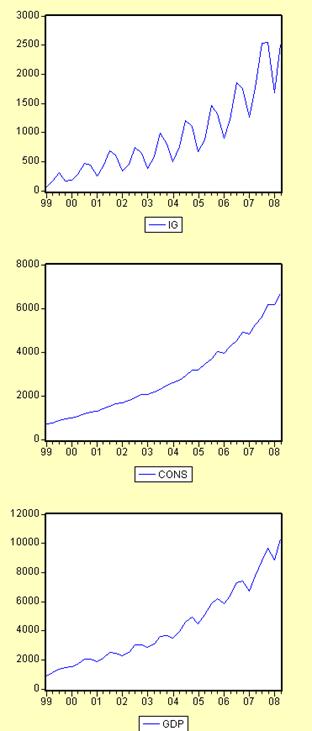
Рис. 1
Приложение 2
| ADF Test Statistic |
-5.278444 |
1% Critical Value* | -4.2412 | ||||||||||||
| 5% Critical Value |
-3.5426 |
||||||||||||||
| 10% Critical Value | -3.2032 | ||||||||||||||
| *MacKinnon critical values for rejection of hypothesis of a unit root. | |||||||||||||||
| Augmented Dickey-Fuller Test Equation | |||||||||||||||
| Dependent Variable: D(CONS) | |||||||||||||||
| Method: Least Squares | |||||||||||||||
| Date: 12/11/08 Time: 19:00 | |||||||||||||||
| Sample(adjusted): 1999:4 2008:2 | |||||||||||||||
| Included observations: 35 after adjusting endpoints | |||||||||||||||
| Variable | Coefficient | Std. Error | t-Statistic | Prob. | |||||||||||
| D(CONS(-1)) | -1.636006 | 0.309941 |
-5.278444 |
0.0000 | |||||||||||
| @TREND(1999:1) | 12.54844 | 3.021702 |
4.152773 |
0.0002 | |||||||||||
| R-squared | 0.719844 | Mean dependent var | 11.88857 | ||||||||||||
| Adjusted R-squared | 0.692732 | S.D. dependent var | 211.7761 | ||||||||||||
| S.E. of regression | 117.3913 | Akaike info criterion | 12.47611 | ||||||||||||
| Sum squared resid | 427201.9 | Schwarz criterion | 12.65387 | ||||||||||||
| Log likelihood | -214.3320 | F-statistic | 26.55085 | ||||||||||||
| Durbin-Watson stat |
2.101394 |
Prob(F-statistic) | 0.000000 | ||||||||||||
|
ADF Test Statistic |
-20.99004 |
1% Critical Value* | -4.2412 |
|
||||||||||
|
5% Critical Value |
-3.5426 |
|
||||||||||||
|
10% Critical Value | -3.2032 |
|
||||||||||||
|
*MacKinnon critical values for rejection of hypothesis of a unit root. |
|
|||||||||||||
|
|
||||||||||||||
|
|
||||||||||||||
|
Augmented Dickey-Fuller Test Equation |
|
|||||||||||||
|
Dependent Variable: D(IG) |
|
|||||||||||||
|
Method: Least Squares |
|
|||||||||||||
|
Date: 12/11/08 Time: 18:56 |
|
|||||||||||||
|
Sample(adjusted): 1999:4 2008:2 |
|
|||||||||||||
|
Included observations: 35 after adjusting endpoints |
|
|||||||||||||
|
Variable | Coefficient | Std. Error | t-Statistic | Prob. |
|
|||||||||
|
D(IG(-1)) | -2.200495 | 0.104835 |
-20.99004 |
0.0000 |
|
|||||||||
|
@TREND(1999:1) | 9.663892 | 2.439289 |
3.961766 |
0.0004 |
|
|||||||||
|
R-squared | 0.935547 | Mean dependent var | 19.71143 |
|
||||||||||
|
Adjusted R-squared | 0.929310 | S.D. dependent var | 541.9242 |
|
||||||||||
|
S.E. of regression | 144.0849 | Akaike info criterion | 12.88589 |
|
||||||||||
|
Sum squared resid | 643574.0 | Schwarz criterion | 13.06365 |
|
||||||||||
|
Log likelihood | -221.5031 | F-statistic | 149.9904 |
|
||||||||||
|
Durbin-Watson stat |
2.352758 |
Prob(F-statistic) | 0.000000 |
|
||||||||||
|
ADF Test Statistic |
-9.618956 |
1% Critical Value* | -4.2412 |
|
||||||||||
|
5% Critical Value |
-3.5426 |
|
||||||||||||
|
10% Critical Value | -3.2032 |
|
||||||||||||
|
*MacKinnon critical values for rejection of hypothesis of a unit root. |
|
|||||||||||||
|
|
||||||||||||||
|
|
||||||||||||||
|
Augmented Dickey-Fuller Test Equation |
|
|||||||||||||
|
Dependent Variable: D(GDP) |
|
|||||||||||||
|
Method: Least Squares |
|
|||||||||||||
|
Date: 12/11/08 Time: 19:12 |
|
|||||||||||||
|
Sample(adjusted): 1999:4 2008:2 |
|
|||||||||||||
|
Included observations: 35 after adjusting endpoints |
|
|||||||||||||
|
Variable | Coefficient | Std. Error | t-Statistic | Prob. |
|
|||||||||
|
D(GDP(-1)) | -2.088636 | 0.217137 |
-9.618956 |
0.0000 |
|
|||||||||
|
@TREND(1999:1) | 26.31412 | 6.414595 |
4.102226 |
0.0003 |
|
|||||||||
|
R-squared | 0.775601 | Mean dependent var | 33.28571 |
|
||||||||||
|
Adjusted R-squared | 0.753884 | S.D. dependent var | 717.4181 |
|
||||||||||
|
S.E. of regression | 355.9113 | Akaike info criterion | 14.69445 |
|
||||||||||
|
Sum squared resid | 3926860. | Schwarz criterion | 14.87221 |
|
||||||||||
|
Log likelihood | -253.1529 | F-statistic | 35.71550 |
|
||||||||||
|
Durbin-Watson stat |
2.486933 |
Prob(F-statistic) | 0.000000 |
|
||||||||||
|
PP Test Statistic | -6.168609 | 1% Critical Value* | -4.2324 | |||||||||||
|
5% Critical Value | -3.5386 | |||||||||||||
|
10% Critical Value | -3.2009 | |||||||||||||
|
*MacKinnon critical values for rejection of hypothesis of a unit root. | ||||||||||||||
|
|||||||||||||||
|
Lag truncation for Bartlett kernel: 1 | ( Newey-West suggests: 3 ) | |||||||||||||
|
Residual variance with no correction | 128108.6 | |||||||||||||
|
Residual variance with correction | 114483.1 | |||||||||||||
|
Phillips-Perron Test Equation | ||||||||||||||
|
Dependent Variable: D(IG) | ||||||||||||||
|
Method: Least Squares | ||||||||||||||
|
Date: 12/13/08 Time: 14:39 | ||||||||||||||
|
Sample(adjusted): 1999:3 2008:2 | ||||||||||||||
|
Included observations: 36 after adjusting endpoints | ||||||||||||||
|
Variable | Coefficient | Std. Error | t-Statistic | Prob. | ||||||||||
|
D(IG(-1)) | -1.133453 | 0.183759 | -6.168167 | 0.0000 | ||||||||||
|
|||||||||||||||
|
@TREND(1999:1) | 3.839129 | 5.997744 | 2.640095 | 0.1265 | ||||||||||
|
R-squared | 0.438149 | Mean dependent var | 20.35833 | |||||||||||
|
Adjusted R-squared | 0.510158 | S.D. dependent var | 534.1404 | |||||||||||
|
S.E. of regression | 373.8380 | Akaike info criterion | 14.76518 | |||||||||||
|
Sum squared resid | 4611909. | Schwarz criterion | 14.89714 | |||||||||||
|
Log likelihood | -262.7732 | F-statistic | 19.22581 | |||||||||||
|
Durbin-Watson stat | 2.134551 | Prob(F-statistic) | 0.000003 | |||||||||||
|
PP Test Statistic | -10.63290 | 1% Critical Value* | -4.2324 | |||||||||||
|
5% Critical Value | -3.5386 | |||||||||||||
|
10% Critical Value | -3.2009 | |||||||||||||
|
*MacKinnon critical values for rejection of hypothesis of a unit root. | ||||||||||||||
|
|||||||||||||||
|
Lag truncation for Bartlett kernel: 3 | ( Newey-West suggests: 3 ) | |||||||||||||
|
Residual variance with no correction | 200449.2 | |||||||||||||
|
Residual variance with correction | 30674.85 | |||||||||||||
|
|||||||||||||||
|
|||||||||||||||
|
Phillips-Perron Test Equation | ||||||||||||||
|
Dependent Variable: D(GDP) | ||||||||||||||
|
Method: Least Squares | ||||||||||||||
|
Date: 12/13/08 Time: 14:44 | ||||||||||||||
|
Sample(adjusted): 1999:3 2008:2 | ||||||||||||||
|
Included observations: 36 after adjusting endpoints | ||||||||||||||
|
Variable | Coefficient | Std. Error | t-Statistic | Prob. | ||||||||||
|
D(GDP(-1)) | -1.243348 | 0.182298 | -6.820400 | 0.0000 | ||||||||||
|
@TREND(1999:1) | 14.23606 | 7.613909 | 2.869744 | 0.0704 | ||||||||||
|
R-squared | 0.587667 | Mean dependent var | 34.34444 | |||||||||||
|
Adjusted R-squared | 0.562677 | S.D. dependent var | 707.1235 | |||||||||||
|
S.E. of regression | 467.6236 | Akaike info criterion | 15.21286 | |||||||||||
|
Sum squared resid | 7216171. | Schwarz criterion | 15.34482 | |||||||||||
|
Log likelihood | -270.8315 | F-statistic | 23.51620 | |||||||||||
|
Durbin-Watson stat | 2.209326 | Prob(F-statistic) | 0.000000 | |||||||||||
Приложение 3
| OBS | Nx | Cons | IG | GDP |
| 1999:1 | 123.9 | 708 | 69.4 | 901.3 |
| 1999:2 | 165.1 | 766.3 | 170.1 | 1101.5 |
| 1999:3 | 206.8 | 852.5 | 313.8 | 1373.1 |
| 1999:4 | 326.4 | 958.9 | 162 | 1447.3 |
| 2000:1 | 372.3 | 997.7 | 177 | 1527.4 |
| 2000:2 | 388.6 | 1045.1 | 283.2 | 1696.6 |
| 2000:3 | 372.2 | 1167.3 | 470.1 | 2037.8 |
| 2000:4 | 330 | 1266.7 | 435.4 | 2043.8 |
| 2001:1 | 357.1 | 1306.3 | 253.7 | 1900.9 |
| 2001:2 | 294.7 | 1412.7 | 409.6 | 2105 |
| 2001:3 | 274.5 | 1523.9 | 682.7 | 2487.9 |
| 2001:4 | 207.4 | 1643.9 | 617.1 | 2449.8 |
| 2002:1 | 235.7 | 1691 | 333.5 | 2259.5 |
| 2002:2 | 290.7 | 1779.9 | 456.4 | 2525.7 |
| 2002:3 | 329.7 | 1907 | 745.5 | 3009.2 |
| 2002:4 | 311.4 | 2070.9 | 635.1 | 3023.1 |
| 2003:1 | 414 | 2071.1 | 382.5 | 2850.7 |
| 2003:2 | 351.5 | 2165.8 | 580.3 | 3107.8 |
| 2003:3 | 360.2 | 2289.9 | 985.2 | 3629.8 |
| 2003:4 | 376.3 | 2497.9 | 807.1 | 3655 |
| 2004:1 | 425.5 | 2584.7 | 493 | 3516.8 |
| 2004:2 | 495 | 2714.9 | 760.3 | 3969.8 |
| 2004:3 | 557.5 | 2919.6 | 1206.5 | 4615.2 |
| 2004:4 | 608.5 | 3182.3 | 1099.1 | 4946.4 |
| 2005:1 | 617.1 | 3170.8 | 677.7 | 4459.7 |
| 2005:2 | 763.1 | 3460.5 | 876.4 | 5080.4 |
| 2005:3 | 788.8 | 3686.6 | 1470.5 | 5873 |
| 2005:4 | 790 | 4001 | 1314.1 | 6212.3 |
| 2006:1 | 961.6 | 3960.9 | 899.5 | 5845.3 |
| 2006:2 | 944.4 | 4239.8 | 1223.4 | 6361.3 |
| 2006:3 | 877.9 | 4520.5 | 1860.5 | 7280.6 |
| 2006:4 | 638.6 | 4894.8 | 1753.4 | 7392.5 |
| 2007:1 | 679.3 | 4818.8 | 1263.8 | 6747.9 |
| 2007:2 | 687.8 | 5231.2 | 1764.1 | 7749.1 |
| 2007:3 | 641.8 | 5599.9 | 2530 | 8826.6 |
| 2007:4 | 861.6 | 6161 | 2544.1 | 9663.7 |
| Моделирование формирования цен на земельные участки Московской области ... | |
|
риложение 2 80 Государственный университет Высшая школа экономики Факультет Экономики Кафедра Математические методы анализа в экономике ВЫПУСКНАЯ ... Adjusted R-squared 0.439584 S.D. dependent var 1.020056 Adjusted R-squared 0.407315 S.D. dependent var 1.020056 |
Раздел: Рефераты по экономической теории Тип: реферат |
| Обеспечение всемирной трансляции спортивных шахматных соревнований с ... | |
|
Содержание Введение 1. Общая часть 1.1 Характеристика структурного подразделения "Шахматный клуб" 1.2 Обзор шахматных систем-прототипов 1.3 Анализ ... Каждый модуль обязан иметь unit test - тест данного модуля; таким образом, в XP осуществляется regression testing (возвратное тестирование, "неухудшение качества" при добавлении ... var v = new Array("A", "B", "C", "D", "E", "F", "G", "H") |
Раздел: Рефераты по информатике, программированию Тип: дипломная работа |
| Система математических расчетов MATLAB | |
|
ГОСУДАРСТВЕННЫЙ ИНЖЕНЕРНЫЙ УНИВЕРСИТЕТ АРМЕНИИ MATLAB УЧЕБНОЕ ПОСОБИЕ Гаспарян Олег Николаевич Д.т.н, с.н.с 2005 СОДЕРЖАНИЕ Система математических ... Undefined function or variable 'sqt'. Второй пример представляет несимметричную матрицу, известную под названием "волшеб-ный квадрат" (magic square): |
Раздел: Рефераты по информатике, программированию Тип: учебное пособие |
| Regulation of international trade within the framework of the world ... | |
|
REGULATION OF INTERNATIONAL TRADE WITHIN THE FRAMEWORK OF THE WORLD TRADE ORGANIZATION Tashkent 2011 Foreword This textbook on the course "Regulation ... Some adjustments in the cost will be required as there may be some items of cost which are spread over products beyond those which have been exported, such as R&D costs, costs ... Most of the value of new medicines and other high technology products lies in the amount of invention, innovation, research, design and testing involved. |
Раздел: Рефераты по международным отношениям Тип: учебное пособие |
| Технический словарь | |
|
A.........................................................................................2 B ... critical region, critical section variable value |
Раздел: Топики по английскому языку Тип: топик |